BERT模型
BERT模型是由谷歌团队于2019年提出的 Encoder-only 的 语言模型,发表于NLP顶会ACL上。原文题目为:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》链接
在前大模型时代,BERT模型可以算是一个参数量比较大的预训练语言模型。在如今的大模型时代,LLM大多遵循GPT提出的Decoder-only的模型范式。BERT也可以算是时代的眼泪了。这篇文章以BERT原文为基础,回顾BERT模型的相关细节。
1 Introduction
BERT 全称为 Bidirectional Encoder Representations from Transformers。
BERT作为一个在大规模预料上预训练的语言模型,可以通过在后面只增加一层输出层并微调,就可以活动广泛下游任务上的SOTA模型
文中作者将NLP的任务分为两类:
- Sentence-Level tasks
- 通过对句子的整体分析来预测句子之间的关系
- 代表:自然语言推理 以及 转述
- Token-Level tasks
- 模型需要在 Token 层面产生细粒度的输出
- 代表:命名实体识别(Named entity recognition)、问答(question answering)
将预训练的语言表征(语言模型)用于下游任务的两种方法:feature-based 以及 fine-tuning
- feature-based approach: ELMo
- 使用包含预训练表征的任务特定架构做为额外特征
- Fine-tuning approach: OpenAI提出的GPT
- 引入最小任务特定参数,通过简单微调所有预训练参数,在下游任务上进行训练
文中提出,标准的语言模型是单向的,这限制了在预训练期间可以使用的架构的选择。例如:GPT 从左向右的架构:每个Token只能与之前的Token进行运算(通过引入casual mask,这也是Decoder模型的通常做法)
文章中指出:对于自然语言处理的任务:集成双向上下文至关重要。在Decoder-only大模型大行其道的今天,这个论断的有效性……
因此,BERT的预训练任务包括以下两部分,以捕获双向上下文:
- Masked language model
- 完形填空:mask输入中的一些Token,根据上下文预测原来的词
- Next Sentence Prediction
- 联合预训练文本对表示
2 Related Work
回顾了Transformer模型:

这里推荐一篇博客,把Transformer模型讲解得很清晰,而且结合了代码,名为:annotated-transformer
3 BERT
![![[Pasted image 20240421185749.png]]](https://i-blog.csdnimg.cn/direct/27c57e6b40be468493c279f22b51e094.png)
BERT模型分为两个阶段:
Pre-training:在不同的预训练任务上对无标签数据进行训练
Fine-tuning:首先使用预训练的参数进行初始化,并使用下游任务的标记数据对所有参数进行微调。每个下游任务都有单独的微调模型
两种规模的BERT模型,其配置以及总体的参数量
BERT-base:L 12,H 768,A 12,110M
BERT-large:L 24,H 1024,A 16,340M
在当年,参数量都还是M级,就已经决定模型很大了,现在都是B级的参数量了,汗-_-||
Input/Output Representations
输入表示:在一个Token序列里既可以表示一对句子,也可以表示单独一个句子
Token embeddings 采用 WordPiece技术
每个序列的第一个标记总是一个特殊的分类标记([CLS])。
该令牌对应的最终隐藏状态作为分类任务的聚合序列表示。
当句子对被打包到一个序列中时,区分句子的方法:
- 引入 [SEP] Token作为句子的分隔
- 为每个Token添加一个学习到的嵌入,指示它是属于句子A还是句子B

每个Token的输入表示 = Token Embeddings + segment Embeddings + position Embeddings
emdedding包含三部分
BERT的激活函数采用 GeLU 替代原始 Transformer 中的 ReLU
G E L U ( x ) = 0.5 × x × ( 1 + T a n h ( 2 / π × ( x + 0.044715 × x 3 ) ) ) GELU(x)=0.5\times x \times (1+Tanh(\sqrt{2/\pi}\times (x+0.044715\times x^3))) GELU(x)=0.5×x×(1+Tanh(2/π×(x+0.044715×x3)))
其函数图像如下图所示,与 ReLU不同,GeLU并不是将负数置为0,而是将其置为较小的负数,某种意义上是使得数据更平滑。
![![[Pasted image 20240421185915.png]]](https://i-blog.csdnimg.cn/direct/a198df0382204d54be03680f35f8b6d4.png)
3.1 Pre-training BERT
Task #1: Masked LM
简单地随机掩盖输入 Token 的某些百分比,然后预测那些被掩盖的 Token
mask Token 对应的最终隐藏向量被输入到词汇表上的输出 softmax 中,就像在标准LM中一样
文中,在每个序列中随机掩码所有 WordPiece Token 的15%
Mask Token的引入会使得 Pre-train 和 fine-tuning 之间存在不匹配的问题,因为 fine-tuning 过程中不会出现 [MASK] Token
缓解措施:并不总是用 [MASK] Token 来代替要被 “masked” 的词
训练数据生成器随机选择 15% 的 Token 位置进行预测。如果选择第 i 个Token,我们将第 i 个Token替换为
- 80%情况下,[MASK] Token
- 10%情况下,随机Token
- 10%情况下,不变
具体如下图:

该部分的 Loss 为:每个 Token 的最终隐藏向量 T i T_i Ti 将与原始 Token 的 交叉熵
Task #2: Next Sentence Prediction (NSP)
二值化的下一个句子预测任务
为每个预训练例子选择句子A和B,B有 50% 的可能性是 A (标记为 IsNext )之后的实际下一个句子,50% 的可能是从语料库中随机抽取的句子(标记为 NotNext)
![![[Pasted image 20240421185904.png]]](https://i-blog.csdnimg.cn/direct/53e50de2be9e436790a4a5601db67762.png)
损失函数为:
Training loss 是 平均掩蔽LM似然(Mean Masked LM likelihood) 和 平均下一个句子预测似然(Mean Next Sentence Prediction likelihood) 之和
预训练数据
BooksCorpus 以及 English Wikipedia
3.2 Fine-tuning BERT
FineTuning时,BERT传输所有参数来初始化下游任务模型参数,而无所谓下游任务是否需要 [CLS] Token
对于涉及文本对的应用,一种常见的模式是在应用双向交叉注意力之前对文本对进行独立编码
BERT使用自注意力机制将这两个阶段统一起来,因为编码一个具有自注意力的串联文本对有效地包含了两个句子之间的双向交叉注意力(按照 training 数据的处理方法,如果输入为文本对,通过 [SEP] Token 以及 Segment embedding 区别两个句子)
对于每个下游任务,我们只需将特定于任务的输入和输出 plug in BERT,并端到端地微调所有参数
对于Token级的NLP任务,需要将Token的隐层表示被输入到一个输出层,用于得到Token级别的任务输出
对于分类任务,只需将 [CLS] 表示送入输出层进行分类,得到分类结果
在GLEU任务上的微调结构:


4 Experiments
省略
看到这里啦,点赞关注不迷路哦~
O(∩_∩)O
相关文章:
BERT模型
BERT模型是由谷歌团队于2019年提出的 Encoder-only 的 语言模型,发表于NLP顶会ACL上。原文题目为:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》链接 在前大模型时代,BERT模型可以算是一个参数量比…...
技术的优势和挑战)
举例说明计算机视觉(CV)技术的优势和挑战
计算机视觉(CV)技术是通过计算机模拟和处理图像与视频数据来模拟人类视觉的能力。它可以带来许多优势,也面临一些挑战。 优势: 自动化:CV技术可以自动处理大量的图像和视频数据,从而提高工作效率和准确性。…...
Animate软件基础:关于补间动画中的图层
Animate 文档中的每一个场景都可以包含任意数量的时间轴图层。使用图层和图层文件夹可组织动画序列的内容和分隔动画对象。在图层和文件夹中组织它们可防止它们在重叠时相互擦除、连接或分段。若要创建一次包含多个元件或文本字段的补间移动的动画,请将每个对象放置…...

mac|安装hashcat(压缩包密码p解)
一、安装Macports(如果有brew就不用这一步) 根据官网文档:The MacPorts Project -- Download & Installation,安装步骤如下 1、下载MacPorts,这里我用的是tar.gz ,可以通过keka(keka安装在…...

【保姆级系列:锐捷模拟器的下载安装使用全套教程】
保姆级系列:锐捷模拟器的下载安装使用全套教程 1.介绍2.下载3.安装4.实践教程5.验证 1.介绍 锐捷目前可以通过EVE-NG来模拟自己家的路由器,交换机,防火墙。实现方式是把自己家的镜像导入到EVE-ng里面来运行。下面主要就是介绍如何下载镜像和…...

virtualbox7安装centos7.9配置静态ip
1.背景 我大概在一年之前安装virtualbox7centos7.9的环境,但看视频说用vagrant启动的窗口可以不用第三方工具(比如xshell、secure等)连接centos7.9,于是尝鲜试了下还可以,导致系统文件格式是vmdk了(网上有vmdk转vdi的方法…...

结构型设计模式:桥接/组合/装饰/外观/享元
结构型设计模式:适配器/代理 (qq.com)...

vLLM初识(一)
vLLM初识(一) 前言 在LLM推理优化——KV Cache篇(百倍提速)中,我们已经介绍了KV Cache技术的原理,从中我们可以知道,KV Cache本质是空间换时间的技术,对于大型模型和长序列…...

【Apache Doris】周FAQ集锦:第 18 期
【Apache Doris】周FAQ集锦:第 18 期 SQL问题数据操作问题运维常见问题其它问题关于社区 欢迎查阅本周的 Apache Doris 社区 FAQ 栏目! 在这个栏目中,每周将筛选社区反馈的热门问题和话题,重点回答并进行深入探讨。旨在为广大用户…...

docker部署可执行的jar
1.将项目打包,上传到服务器的指定目录 2.在该目录下创建Dockerfile文件 3.Dockerfile写入如下指令 # 基于哪个镜像 FROM java:8 # 拷贝文件到容器,也可以直接写成ADD xxxxx.jar /app.jar ADD springboot-file-0.0.1.jar file.jar RUN bash -c touch /…...

OpenCV||超详细的图像处理模块
一、颜色变换cvtColor dst cv2.cvtColor(src, code[, dstCn[, dst]]) src: 输入图像,即要进行颜色空间转换的原始图像。code: 转换代码,指定要执行的颜色空间转换类型。这是一个必需的参数,决定了源颜色空间到目标颜色空间的转换方式。dst…...

java面向对象期末总结
子类父类方法执行顺序?多态中和子类打印不一样; 子类在实现父类方法的时候没有用super关键字进行调用也会先执行父类的构造方法吗? 是的,当子类实例化时,先执行父类的构造方法,再执行子类的构造方法。即使在…...

文件搜索 36
删除文件 文件搜索 package File;import java.io.File;public class file3 {public static void main(String[] args) {search(new File("D :/"), "qq");}/*** 去目录搜索文件* param dir 目录* param filename 要搜索的文件名称*/public static void sear…...

IO多路转接
文章目录 五种IO模型fcntl多路转接selectpollepollepoll的工作模式 五种IO模型 阻塞IO: 在内核将数据准备好之前, 系统调用会一直等待. 所有的套接字, 默认都是阻塞方式.阻塞IO是最常见的IO模型。非阻塞IO: 如果内核还未将数据准备好, 系统调用仍然会直接返回, 并且返回EWOULD…...

基于深度学习的面部表情分类识别系统
:温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :) 1. 项目简介 面部表情识别是计算机视觉领域的一个重要研究方向, 它在人机交互、心理健康评估、安全监控等领域具有广泛的应用。近年来,随着深度学习技术的快速发展…...

日志远程同步实验
目录 一.实验环境 二.实验配置 1.node1发送方配置 (1)node1写udp协议 (2)重启服务并清空日志 2.node2接收方配置 (1)node2打开接受日志的插件,指定插件用的端口 (2ÿ…...

数据结构之《二叉树》(中)
在数据结构之《二叉树》(上)中学习了树的相关概念,还了解的树中的二叉树的顺序结构和链式结构,在本篇中我们将重点学习二叉树中的堆的相关概念与性质,同时试着实现堆中的相关方法,一起加油吧! 1.实现顺序结构二叉树 在…...
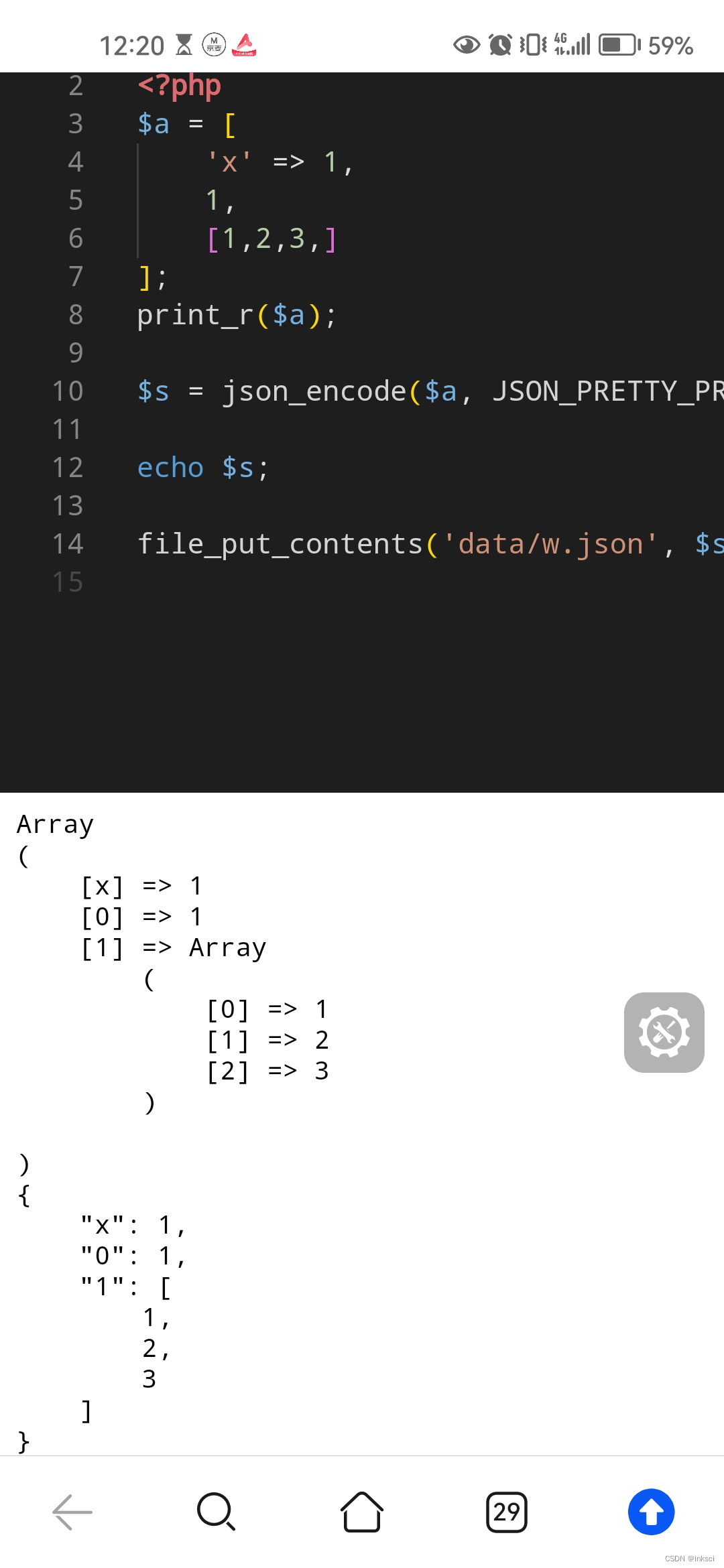
php json_encode 参数 JSON_PRETTY_PRINT
https://andi.cn/page/621642.html...

【UE 网络】Gameplay框架在DS架构中的扮演的角色
目录 0 引言1 核心内容1.1 Gameplay各部分创建的流程1.2 Gameplay框架在DS和客户端的存在情况1.3 数据是独立存在于DS和客户端的 2 Gameplay框架各自负责的功能2.1 GameMode2.2 GameState2.3 PlayerController2.4 PlayerState2.5 Pawn2.6 AIController2.7 Actor2.8 HUD2.9 UI &…...

【云原生】StatefulSet控制器详解
StatefulSet 文章目录 StatefulSet一、介绍与特点1.1、介绍1.2、特点1.3、组成部分1.4、为什么需要无头服务1.5、为什么需要volumeClaimTemplate 二、教程2.1、创建StatefulSet2.2、查看部署资源 三、StatefulSet中的Pod3.1、检查Pod的顺序索引3.2、使用稳定的网络身份标识3.3、…...

从“共和国之辉”到AI原生应用:一个关于“哥布林”诞生的技术启示录
从“共和国之辉”到AI原生应用:一个关于“哥布林”诞生的技术启示录 2025年7月,一篇名为《Where the goblins came from》的文章在Hacker News上引发了超过710票的热议。当大多数技术评论者将目光聚焦于AI模型的最新突破时,这篇来自OpenAI的文…...

3PEAK思瑞浦 TP2262-SR SOP8 运算放大器
特性 供电电压:3V至36V 低供电电流:每通道700uA 轨到轨输出 带宽:4MHz 斜率:15V/us 优异的EMI抑制性能 偏移电压:最大3毫伏 偏移电压温度漂移:2V/C 低噪声:1kHz时30nV/vHz 工作温度范围:-40C至125C...

Cursor AI 编程助手配置优化:一键安装与自定义指南
1. 项目概述:为什么需要一套现成的 Cursor 配置?如果你和我一样,是 Cursor 的重度用户,那么你肯定经历过这样的阶段:刚上手时,觉得这个 AI 驱动的 IDE 简直是神器,但随着项目越来越复杂…...

Linux桌面便签神器Sticky:3分钟告别灵感遗忘的终极解决方案
Linux桌面便签神器Sticky:3分钟告别灵感遗忘的终极解决方案 【免费下载链接】sticky A sticky notes app for the linux desktop 项目地址: https://gitcode.com/gh_mirrors/stic/sticky 你是否曾经有过这样的经历?在编码时突然想到一个绝妙的算法…...

二分查找算法:选择开区间还是闭区间?
如大家所熟悉的,在二分查找算法的实现过程中,通常会选择左闭右开区间 [st, ed) 或是全闭区间 [st, ed] 这两种搜索区间的表示方式。左闭右开区间比较符合大家的编程习惯,而全闭区间在解决某些问题上更加方便。首先看一下不同区间的选择对 主循…...

如何用Rusted PackFile Manager彻底重构全面战争模组开发工作流?
如何用Rusted PackFile Manager彻底重构全面战争模组开发工作流? 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: h…...

网盘直链下载助手:如何从九大主流网盘中一键获取真实下载地址?
网盘直链下载助手:如何从九大主流网盘中一键获取真实下载地址? 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / …...

SwiftHTTP文件上传完全指南:从基础到企业级应用
SwiftHTTP文件上传完全指南:从基础到企业级应用 【免费下载链接】SwiftHTTP Thin wrapper around NSURLSession in swift. Simplifies HTTP requests. 项目地址: https://gitcode.com/gh_mirrors/sw/SwiftHTTP 在iOS和macOS开发中,SwiftHTTP文件上…...

3步打造完美macOS菜单栏:Ice菜单栏管理终极指南
3步打造完美macOS菜单栏:Ice菜单栏管理终极指南 【免费下载链接】Ice Powerful menu bar manager for macOS 项目地址: https://gitcode.com/GitHub_Trending/ice/Ice 你是否厌倦了macOS菜单栏上杂乱无章的图标?想要一个整洁、高效且个性化的桌面…...
—— 递归树如何看懂分治算法的运行时间)
算法基础(十一)—— 递归树如何看懂分治算法的运行时间
1. 定位导航 前面已经学习了分治思想: 分解 → 解决 → 合并分治算法经常可以写成递归式。 例如归并排序: 先把数组拆成左右两半; 分别排序左右两半; 再合并两个有序数组。它的运行时间可以粗略写成: T(n)2T(n/2)n T(n…...