4.3.语言模型
语言模型
假设长度为 T T T的文本序列中的词元依次为 x 1 , x 2 , ⋯ , x T x_1,x_2,\cdots,x_T x1,x2,⋯,xT。 于是, x T x_T xT( 1 ≤ t ≤ T 1\le t\le T 1≤t≤T) 可以被认为是文本序列在时间步 t t t处的观测或标签。 在给定这样的文本序列时,语言模型(language model)的目标是估计序列的联合概率:
P ( x 1 , x 2 , ⋯ , x T ) P(x_1,x_2,\cdots,x_T) P(x1,x2,⋯,xT)
应用包括:
- 做预训练模型(BERT,GPT-3)
- 生成本文,给定前面几个词,不断的使用 x t ∼ p ( x t ∣ x 1 , ⋯ , x t − 1 ) x_t\sim p(x_t|x_1,\cdots,x_{t-1}) xt∼p(xt∣x1,⋯,xt−1)生成后续文本
- 判断多个序列中哪个更常见
1.使用计数来建模(n_gram)
假设序列长度为2,我们预测:
p ( x , x ′ ) = p ( x ) p ( x ′ ∣ x ) = n ( x ) n n ( x , x ′ ) n ( x ) p(x,x')=p(x)p(x'|x)=\frac{n(x)}{n}\frac{n(x,x')}{n(x)} p(x,x′)=p(x)p(x′∣x)=nn(x)n(x)n(x,x′)
其中 n n n是总次数, n ( x ) , n ( x , x ′ ) n(x),n(x,x') n(x),n(x,x′)是单个单词和连续单词对的出现次数
序列长度为3的情况也很容易: p ( x , x ′ , x ′ ′ ) = p ( x ) p ( x ′ ∣ x ) p ( x ′ ′ ∣ x , x ′ ) = n ( x ) n n ( x , x ′ ) n ( x ) n ( x , x ′ ) n ( x , x ′ , x ′ ′ ) p(x,x',x'')=p(x)p(x'|x)p(x''|x,x')=\frac{n(x)}{n}\frac{n(x,x')}{n(x)}\frac{n(x,x')}{n(x,x',x'')} p(x,x′,x′′)=p(x)p(x′∣x)p(x′′∣x,x′)=nn(x)n(x)n(x,x′)n(x,x′,x′′)n(x,x′)
显然我们得到了一种简单的建模方式:
p ( x t ∣ x 1 , ⋯ , x t ) = n ( x 1 , ⋯ , x t ) n p(x_t|x_1,\cdots,x_t)=\frac{n(x_1,\cdots,x_t)}{n} p(xt∣x1,⋯,xt)=nn(x1,⋯,xt)
但这样有个问题:
当序列很长时,因为文本量不够大,很可能 n ( x 1 , ⋯ , x T ) ≤ 1 n(x_1,\cdots,x_T)\le 1 n(x1,⋯,xT)≤1,即某些序列是合理的,但文本中没有出现。可以使用马尔科夫假设缓解这个问题:
- 一元语法: p ( x 1 , x 2 , x 3 , x 4 ) = n ( x 1 ) n n ( x 2 ) n n ( x 3 ) n n ( x 5 ) n p(x_1,x_2,x_3,x_4)=\frac{n(x_1)}n\frac{n(x_2)}n\frac{n(x_3)}n\frac{n(x_5)}n p(x1,x2,x3,x4)=nn(x1)nn(x2)nn(x3)nn(x5)与前面无关
- 二元语法: p ( x 1 , x 2 , x 3 , x 4 ) = n ( x 1 ) n n ( x 1 , x 2 ) n ( x 1 ) n ( x 2 , x 3 ) n ( x 2 ) n ( x 3 , x 4 ) n ( x 3 ) p(x_1,x_2,x_3,x_4)=\frac{n(x_1)}n \frac{n(x_1,x_2)}{n(x_1)} \frac{n(x_2,x_3)}{n(x_2)} \frac{n(x_3,x_4)}{n(x_3)} p(x1,x2,x3,x4)=nn(x1)n(x1)n(x1,x2)n(x2)n(x2,x3)n(x3)n(x3,x4)与前面一个词有关系
- 三元语法: p ( x 1 , x 2 , x 3 , x 4 ) = p ( x 1 ) p ( x 2 ∣ x 1 ) p ( x 3 ∣ x 1 , x 2 ) p ( x 4 ∣ x 2 , x 3 ) p(x_1,x_2,x_3,x_4)=p(x_1)p(x_2|x_1)p(x_3|x_1,x_2)p(x_4|x_2,x_3) p(x1,x2,x3,x4)=p(x1)p(x2∣x1)p(x3∣x1,x2)p(x4∣x2,x3)与前面两个词有关系
另一种常见的策略师执行某种形式的拉普拉斯平滑,具体方法是在所有计数中添加一个小常量,用 n n n表示训练集中的单词总数,用 m m m表示唯一单词的数量,这个方案有助于处理单元素问题

其中 ϵ 1 , ϵ 2 , ϵ 3 \epsilon_1,\epsilon_2,\epsilon_3 ϵ1,ϵ2,ϵ3是超参数,这样的模型很容易变得无效,原因如下:首先,我们需要存储所有的计数; 其次,这完全忽略了单词的意思。 例如,“猫”(cat)和“猫科动物”(feline)可能出现在相关的上下文中, 但是想根据上下文调整这类模型其实是相当困难的。 最后,长单词序列大部分是没出现过的, 因此一个模型如果只是简单地统计先前“看到”的单词序列频率, 那么模型面对这种问题肯定是表现不佳的。
2.语言模型和数据集的代码实现
import random
import torch
import re
from d2l import torch as d2ld2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt','090b5e7e70c295757f55df93cb0a180b9691891a')def read_time_machine(): # @save"""将时间机器数据集加载到文本行的列表中"""with open(d2l.download('time_machine'), 'r') as f:lines = f.readlines()return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]tokens = d2l.tokenize(read_time_machine())
# 因为每个文本行不一定是一个句子或一个段落,因此我们把所有文本行拼接到一起
corpus = [token for line in tokens for token in line]
vocab = d2l.Vocab(corpus)
print(vocab.token_freqs[:10])freqs = [freq for token, freq in vocab.token_freqs]
print(freqs[:10])
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',xscale='log', yscale='log')
d2l.plt.show()

词频图:词频以一种明确的方式迅速衰减,将前几个单词作为例外消除后(停用词,类似the,a,I,and之类的),生育的所有单词大致遵循双对数坐标图上的一条直线,这意味着单词的频率满足齐普夫定律(Zipf’s law),即第 i i i个最常用的频率 n i n_i ni为:
n i ∝ 1 n i n_i\propto \frac 1{n_i} ni∝ni1
等价于:
l o g n i = − α l o g i + c log\ n_i = -\alpha log\ i+c log ni=−αlog i+c
这意味着通过计数统计和平滑来建模单词是不可行的,因为这样建模的结果会大大高估尾部单词的频率。
多元语法
注意最新的d2l库中的Vocab类好像有问题,处理不了元组,将库中的Vocab类替换一下,再加上count_corpus函数就可以正常处理元组。
bigram_tokens = [pair for pair in zip(corpus[:-1], corpus[1:])]
bigram_vocab = d2l.Vocab(bigram_tokens)
print('二元:',bigram_vocab.token_freqs[:10])trigram_tokens = [triple for triple in zip(corpus[:-2], corpus[1:-1], corpus[2:])]
trigram_vocab = d2l.Vocab(trigram_tokens)
print('三元:',trigram_vocab.token_freqs[:10])bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',ylabel='frequency: n(x)', xscale='log', yscale='log',legend=['unigram', 'bigram', 'trigram'])
d2l.plt.show()

发现:
- 除了一元语法词,单词序列似乎也遵循齐普夫定律, 尽管公式中的指数𝛼更小 (指数的大小受序列长度的影响);
- 词表中n元组的数量并没有那么大,这说明语言中存在相当多的结构, 这些结构给了我们应用模型的希望;
- 很多n元组很少出现,这使得拉普拉斯平滑非常不适合语言建模。 作为代替,我们将使用基于深度学习的模型。
随机采样
# 随机采样
def seq_data_iter_random(corpus, batch_size, num_steps): #@save"""使用随机抽样生成一个小批量子序列"""# num_steps意思是取多少个token来进行预测# 从随机偏移量开始对序列进行分区,随机范围包括num_steps-1corpus = corpus[random.randint(0, num_steps - 1):]# 减去1,是因为我们需要考虑标签,最后一个样本没有可预测的数据num_subseqs = (len(corpus) - 1) // num_steps# 长度为num_steps的子序列的起始索引initial_indices = list(range(0, num_subseqs * num_steps, num_steps))# 在随机抽样的迭代过程中,# 来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻print(initial_indices)random.shuffle(initial_indices) # 打乱顺序,不会生成新的列表,在原列表上打乱的print(initial_indices)def data(pos):# 返回从pos位置开始的长度为num_steps的序列return corpus[pos: pos + num_steps]num_batches = num_subseqs // batch_sizefor i in range(0, batch_size * num_batches, batch_size): #后面一个是步长# 在这里,initial_indices包含子序列的随机起始索引initial_indices_per_batch = initial_indices[i: i + batch_size]X = [data(j) for j in initial_indices_per_batch]Y = [data(j + 1) for j in initial_indices_per_batch]yield torch.tensor(X), torch.tensor(Y)'''生成一个0到34的序列,假设批量大小为2,时间步数为5,这意味着可以生成(35-1)/5 = 6个特征-标签子序列对'''my_seq = list(range(35))
for X, Y in seq_data_iter_random(my_seq, batch_size=2, num_steps=5):print('X: ', X, '\nY:', Y)
顺序分区
def seq_data_iter_sequential(corpus, batch_size, num_steps): # @save"""使用顺序分区生成一个小批量子序列"""# 顺序分区保证不同批次内的子序列在原始序列上是连续的,不会跳过任何元素,这对某些任务(语言建模)可能更合适# X: tensor([[ 1, 2, 3, 4, 5],# [17, 18, 19, 20, 21]])# Y: tensor([[ 2, 3, 4, 5, 6],# [18, 19, 20, 21, 22]])# X: tensor([[ 6, 7, 8, 9, 10], 和[1,2,3,4,5]是连续的# [22, 23, 24, 25, 26]]) 和[17,18,19,20,21]是连续的# Y: tensor([[ 7, 8, 9, 10, 11],# [23, 24, 25, 26, 27]])# X: tensor([[11, 12, 13, 14, 15],# [27, 28, 29, 30, 31]])# Y: tensor([[12, 13, 14, 15, 16],# [28, 29, 30, 31, 32]])# 从随机偏移量开始划分序列offset = random.randint(0, num_steps)num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_sizeXs = torch.tensor(corpus[offset: offset + num_tokens])Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)num_batches = Xs.shape[1] // num_stepsfor i in range(0, num_steps * num_batches, num_steps):X = Xs[:, i: i + num_steps]Y = Ys[:, i: i + num_steps]print('X: ', X, '\nY:', Y)yield X, Y #返回一个值序列,而不是一次性返回所有值。for X, Y in seq_data_iter_sequential(my_seq, batch_size=2, num_steps=5):print('X: ', X, '\nY:', Y)包装
class SeqDataLoader: # @save"""加载序列数据的迭代器"""def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):if use_random_iter:self.data_iter_fn = d2l.seq_data_iter_randomelse:self.data_iter_fn = d2l.seq_data_iter_sequentialself.corpus, self.vocab = d2l.load_corpus_time_machine(max_tokens)self.batch_size, self.num_steps = batch_size, num_stepsdef __iter__(self):return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)def load_data_time_machine(batch_size, num_steps, # @saveuse_random_iter=False, max_tokens=10000):"""返回时光机器数据集的迭代器和词表"""data_iter = SeqDataLoader(batch_size, num_steps, use_random_iter, max_tokens)return data_iter, data_iter.vocabNLP BERT GPT等模型中 tokenizer 类别说明详解-腾讯云开发者社区-腾讯云 (tencent.com)
相关文章:
4.3.语言模型
语言模型 假设长度为 T T T的文本序列中的词元依次为 x 1 , x 2 , ⋯ , x T x_1,x_2,\cdots,x_T x1,x2,⋯,xT。 于是, x T x_T xT( 1 ≤ t ≤ T 1\le t\le T 1≤t≤T) 可以被认为是文本序列在时间步 t t t处的观测或标签。 在给定这样的文本…...
C++类和对象1)
(学习总结10)C++类和对象1
C类和对象1 一、类的定义1.类定义格式2.访问限定符3. 类域 二、实例化1.实例化概念2.对象大小 三、this指针四、C和C语言实现Stack对比 以下代码环境在 VS2022。 一、类的定义 1.类定义格式 class 为定义类的关键字,Stack 为类的名字, { } 中为类的主体…...
:Hadoop 基本概念与生态介绍)
进击大数据系列(一):Hadoop 基本概念与生态介绍
进击大数据系列(一):Hadoop 基本概念与生态介绍-腾讯云开发者社区-腾讯云 Hadoop 简介-CSDN博客 hadoop-common-3.2.1.jar hadoop-mapreduce-client-core-3.2.1.jar hadoop-hdfs-3.2.1.jar hadoop-core 依赖之间关系...

评价类算法--模糊综合评价算法模型
一.概述 二.经典集合和模糊集合的基本概念 经常采用向量表示法来进行表示 三.隶属函数的三种确定方法 其中,梯形分布用得最多 四.应用:模糊综合评价 对应一个指定的评语: 选择一个方案:...

哪些系统需要按照等保2.0进行定级?
等保2.0适用的系统类型 根据等保2.0的要求,需要进行定级的系统主要包括但不限于以下几类: 基础信息网络:包括互联网、内部网络、虚拟专用网络等。云计算平台/系统:涵盖公有云、私有云、混合云等多种部署模式的云服务平台。大数据…...

自注意力和位置编码
一、自注意力 1、给定一个由词元组成的输入序列x1,…,xn, 其中任意xi∈R^d(1≤i≤n)。 该序列的自注意力输出为一个长度相同的序列 y1,…,yn,其中: 2、自注意力池化层将xi当作key,value,query来…...
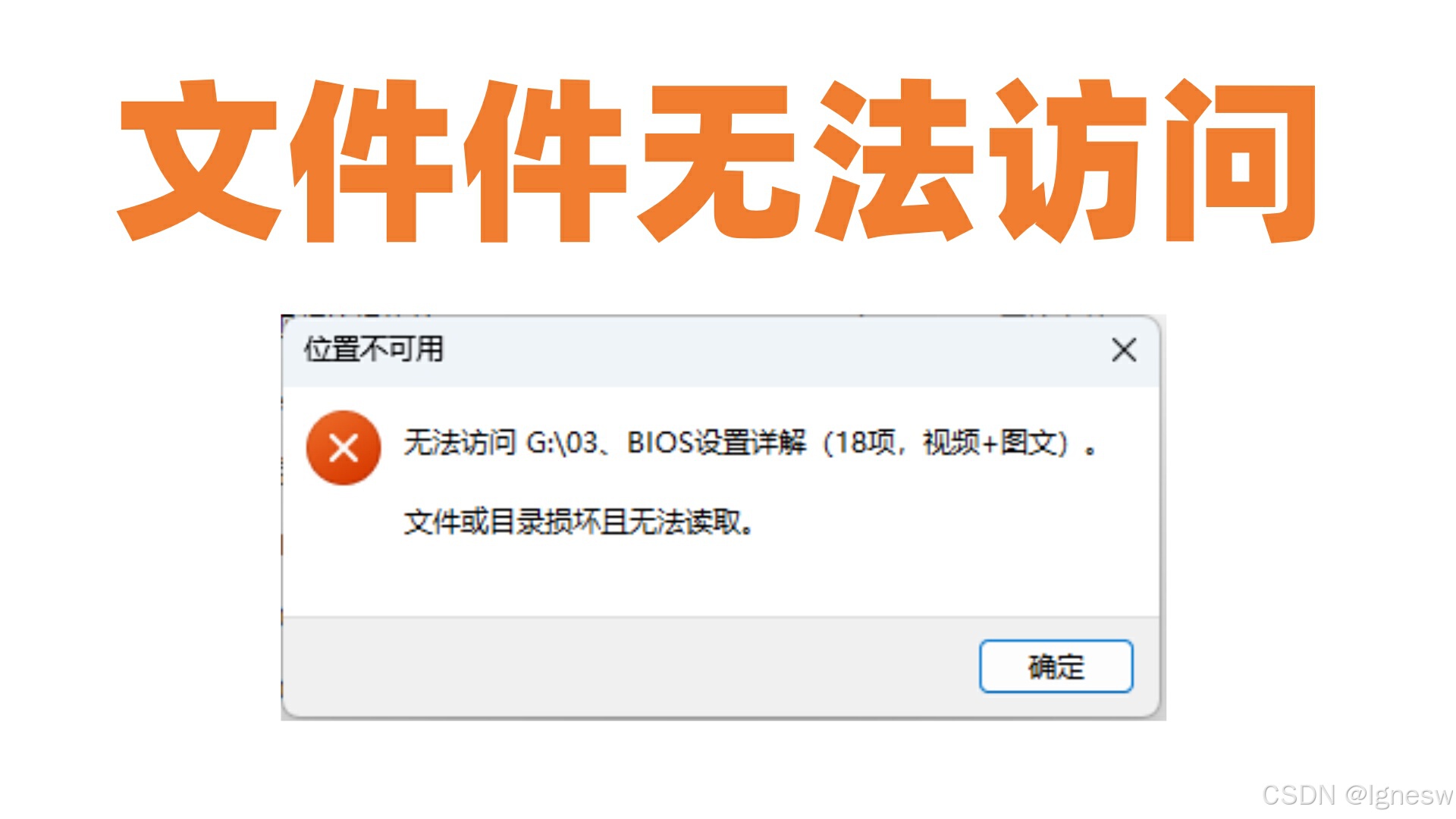
“文件夹提示无法访问?高效数据恢复策略全解析“
一、现象解析:文件夹为何提示无法访问? 在日常使用电脑的过程中,不少用户可能会突然遇到文件夹提示“无法访问”的尴尬情况。这一提示不仅阻断了对重要文件的即时访问,还可能预示着数据丢失的风险。造成这一现象的原因多种多样&a…...

结构开发笔记(一):外壳IP防水等级与IP防水铝壳体初步选型
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/140928101 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...

WPF Datagrid控件,获取某一个单元格中的控件
在WPF应用程序中,比如需要获取特定 DataGrid 单元格中的 TextBlock 控件,可以通过访问 DataGridRow 和 DataGridCell 对象。以下是一个例子,展示如何获取 DataGrid 的第二行第一列中的 TextBlock 控件,并修改其属性。 1. 在XAML中…...

P10838 『FLA - I』庭中有奇树
前言 本题解较为基础,推导如何得出二分解题思路。 题目大意 给出无根带权树,双方采取最佳策略,求节点S->T的最短路。 有两种操作: 我方至多可以使用一次传送,花费k元从a传送到b(ab不能相邻…...

WebRTC简介
WebRTC简介 WebRTC(Web Real-Time Communication)是一项开源的实时通信技术,它允许网页浏览器进行实时语音、视频和数据共享通信,而无需安装额外的插件或应用程序。WebRTC的出现极大地简化了实时通信的开发和部署过程,…...

一套直播系统带商城源码 附搭建教程
本站没搭建测试过,有兴趣的自己折腾了,内含教程! 功能介绍: 礼物系统:普通礼物、豪华礼物、热门礼物、守护礼物、幸运礼物 提现方式:统一平台提现日期及方式,方便用户执行充值提现操作 连麦…...
)
Netty 总结与补充(十)
简单介绍一下 Netty?你为什么会用到Netty?说说你对Netty的认识?为什么选用Netty来做通信框架? Netty 是一个高性能、异步事件驱动的 NIO 框架,它提供了对 TCP、UDP 和文件传输的支持,作为一个异步 NIO 框架…...

循环实现异步变同步的问题
一、背景 在开发中遇到在循环中调用异步接口的问题,导致页面渲染完成时,没有展示接口返回后拼接的数组数据。二、问题 在代码中使用了map进行循环,导致调用接口的时候处于异步。this.form.list.map(async el>{el.fileList [];if(el.pic…...

测试GPT4o分析巴黎奥运会奖牌数据
使用GPT4o快速调用python代码,生成数据图表 测试GPT4o分析巴黎奥运会奖牌数据 测试GPT4o分析巴黎奥运会奖牌数据 1.首先我们让他给我们生成下当前奥运奖牌数 2.然后我们直接让GPT帮我们运行python代码,并生成奥运会奖牌图表 3.我们还可以让他帮我们…...

TF卡(SD NAND)参考设计和使用提示
目录 电路设计 Layout 设计说明 贴片注意事项 电路设计 1、参考电路: R1~R5 (10K-100 kΩ)是上拉电阻,当SD NAND处于高阻抗模式时,保护CMD和DAT线免受总线浮动。 即使主机使用SD NAND SD模式下的1位模式,主机也应通过上拉电…...

电源芯片负载调整率测试方法、原理以及自动化测试的优势-纳米软件
在芯片设计研发领域,负载调整率作为稳压电源芯片的关键性能指标,直接关系到芯片的稳定性和可靠性,因此其测试和优化显得尤为重要。以下是对负载调整率测试原理、方法以及使用ATECLOUD-IC芯片测试系统优势的进一步阐述: 负载调整率…...

C++威力强大的助手 --- const
Welcome to 9ilks Code World (๑•́ ₃ •̀๑) 个人主页: 9ilk (๑•́ ₃ •̀๑) 文章专栏: C之旅 const是个奇妙且非比寻常的东西,博主从《Effective C》一书中认识到关于const更深层次的理解,写此博客进行巩固。 &#x…...

测试环境搭建整套大数据系统(十八:ubuntu镜像源进行更新)
镜像源更新为清华源 报错显示 解决方案 做好备份 cp /etc/apt/sources.list /etc/apt/sources.list.bak查看配置信息 sudo vim /etc/apt/sources.listsudo sed -i s/cn.archive.ubuntu.com/mirrors.aliyun.com/g /etc/apt/sources.list sudo apt update...

第128天:内网安全-横向移动IPCATSC 命令Impacket 套件CS 插件全自动
环境部署 案例一: 域横向移动-IPC-命令版-at&schtasks 首先是通过外网web访问到win2008,获得了win2008的权限,这一步不做演示 因为里面的主机都不出网,所以只能利用win2008进行正向或者反向连接 信息收集 域内用户信息&…...

Gofile批量下载自动化工具:5步实现高效文件管理解决方案
Gofile批量下载自动化工具:5步实现高效文件管理解决方案 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在当今数字化工作环境中,技术团队经常需要从…...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...

Sora 2 MOV导出画质崩坏真相:HDR10元数据丢失、BT.2020色域截断、帧率标志位误写——3大隐性缺陷紧急修复方案
更多请点击: https://intelliparadigm.com 第一章:Sora 2 MOV导出画质崩坏的系统性认知 Sora 2 在生成高保真视频后,导出为 MOV 格式时频繁出现色度抽样失真、动态范围压缩、帧间伪影加剧等现象,其本质并非单一环节失效ÿ…...

基于STM32WL与LoRaWAN的远程空气质量监测系统全栈开发实践
1. 项目概述:构建一个远程空气质量监测系统最近在做一个挺有意思的玩意儿:一个能自己找地方待着、靠太阳能供电,然后把周围空气数据悄无声息传回来的远程监测终端。核心想法很简单,就是想知道某个犄角旮旯,比如工厂周边…...

Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验
Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑上无法直接安装安卓应用而烦…...

软件测试行业的未来趋势:这3类测试将成为主流
随着数字化转型的深入推进,软件已经成为驱动各行业变革的核心生产力,从自动驾驶汽车到企业级云原生平台,从智慧医疗设备到工业互联网系统,软件的复杂度、规模和对安全性的要求都在呈指数级增长。作为软件质量保障的核心环节&#…...

机器学习赋能分子模拟:从数据驱动CV到自适应采样破解采样瓶颈
1. 项目概述与核心价值在分子模拟的世界里,我们常常面临一个根本性的困境:我们想理解一个复杂系统(比如一个蛋白质如何折叠,或者一个催化剂表面如何发生反应)的微观机理,但系统的相空间维度高得吓人——动辄…...
Windows任务栏透明化终极指南:5分钟掌握TranslucentTB完整设置技巧
Windows任务栏透明化终极指南:5分钟掌握TranslucentTB完整设置技巧 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 您是否厌倦…...

3个理由告诉你为什么选择哔哩下载姬:B站视频下载的终极解决方案
3个理由告诉你为什么选择哔哩下载姬:B站视频下载的终极解决方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印…...

从红宝石到光纤:固体激光器家族里,谁才是工业加工界的‘六边形战士’?
从红宝石到光纤:固体激光器家族里,谁才是工业加工界的‘六边形战士’? 在金属切割车间里,激光束正以毫米级精度划过不锈钢板;精密电子产线上,纳米级激光打标机为电路板刻印追溯码;汽车焊接工段…...