Flink 实时数仓(八)【DWS 层搭建(二)流量域、用户域、交易域搭建】
前言
今天的任务是完成流量域最后一个需求、用户域的两个需求以及交易域的部分需求;
1、流量域页面浏览各窗口汇总表
任务:从 Kafka 页面日志主题读取数据,统计当日的首页和商品详情页独立访客数。
注意:一般我们谈到访客,指的是 mid;而用户才是 uid;
1.1、思路
- 消费 Kafka dwd_traffic_page_log
- 过滤出 page_id = 'home' 或 'good_detail' 的数据
- 按照 mid 分组
- 使用状态编程为每个 mid 维护两个状态:首页的末次访问日期,商品详情页的末次访问日期
- 每新来一条数据就判断它的两个状态是否为 null
- 如果为 null,则给状态赋值
- 如果不为 null,则不做操作
- 当两个状态中有一个不为 null 时,发送数据到下游
- 每新来一条数据就判断它的两个状态是否为 null
- 开窗聚合(实时计算更新报表,这里开窗用的是 windowAll() ,因为上一步发送下来的数据已经不再是键控流了)
- 写出到 clickhouse
1.2、实现
1.2.1、创建 ck 表并创建 Java Bean
首先创建 ck 表结构,和前面的表一样,主要的字段就是:维度 + 度量值 (这里没有粒度,因为我们统计的是一个宏观的统计结果信息,到 ADS 都不用加工),这里的 stt 和 edt 依然是作为 ck 表的 order by 字段防止数据重复;ts 字段作为 ck 的版本字段;这里 order by 字段取窗口起止时间,因为窗口是基于事件时间的,所以不用担心任务挂了之后重复消费造成数据重复的问题,ck 会自动根据 order by 字段进行去重;
create table if not exists dws_traffic_page_view_window
(stt DateTime,edt DateTime,home_uv_ct UInt64,good_detail_uv_ct UInt64,ts UInt64
) engine = ReplacingMergeTree(ts)partition by toYYYYMMDD(stt)order by (stt, edt);创建 ck 表对应的 JavaBean:
@Data
@AllArgsConstructor
public class TrafficHomeDetailPageViewBean {// 窗口起始时间String stt;// 窗口结束时间String edt;// 首页独立访客数Long homeUvCt;// 商品详情页独立访客数Long goodDetailUvCt;// 时间戳Long ts;
}1.2.2、读取页面日志并过滤出首页与商品详情页
这里我们不仅要过滤还希望尽量顺便把数据转换为 JSONObject 格式,所以选用 flatMap 最为合适:
- 过滤出 page_id 为 home 或者 good_detail 的数据
// TODO 3. 读取 dwd_traffic_page_log 的数据String groupId = "dws_traffic_page_view_window";DataStreamSource<String> pageLog = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer("dwd_traffic_page_log", groupId));// TODO 4. 转为 json 并过滤出首页和商品详情页SingleOutputStreamOperator<JSONObject> filterDS = pageLog.flatMap(new FlatMapFunction<String, JSONObject>() {@Overridepublic void flatMap(String value, Collector<JSONObject> out) throws Exception {JSONObject jsonObject = JSON.parseObject(value);String page_id = jsonObject.getJSONObject("page").getString("page_id");if (page_id != null) {if (page_id.equals("home") || page_id.equals("good_detail")) {out.collect(jsonObject);}}}});1.2.3、提取事件时间并生成水位线
// TODO 5. 提取事件时间生成水位线filterDS.assignTimestampsAndWatermarks(WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() {@Overridepublic long extractTimestamp(JSONObject element, long recordTimestamp) {return element.getLong("ts");}}));1.2.4、状态编程过滤出独立访客
这里使用富函数的 flatMap,因为富函数中才有 open(在 open 方法中初始化状态)、close等方法,以及获取上下文对象(通过上下文对象给状态描述器设置ttl并初始化)等高级操作;
这里 flatMap 的输出类型我们设置为之前写好的 ck 表对应的 JavaBean ,方便直接插入到 ck中;
这里我们同样可以给状态设置一个 TTL 防止长时间访客未访问状态存储浪费;这里两个状态任意一个不为 null 即可输出:
// TODO 6. 状态编程(按照mid分组)过滤出独立访客KeyedStream<JSONObject, String> keyedStream = filterDS.keyBy(json -> json.getJSONObject("common").getString("mid"));SingleOutputStreamOperator<TrafficHomeDetailPageViewBean> trafficHomeDetailDS = keyedStream.flatMap(new RichFlatMapFunction<JSONObject, TrafficHomeDetailPageViewBean>() {private ValueState<String> homeLastVisit;private ValueState<String> detailLastVisit;@Overridepublic void open(Configuration parameters) throws Exception {StateTtlConfig ttlConfig = new StateTtlConfig.Builder(Time.days(1)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).build();ValueStateDescriptor<String> homeStateDescriptor = new ValueStateDescriptor<>("home-state", String.class);ValueStateDescriptor<String> detailStateDescriptor = new ValueStateDescriptor<>("detail-state", String.class);// 设置 TTLhomeStateDescriptor.enableTimeToLive(ttlConfig);detailStateDescriptor.enableTimeToLive(ttlConfig);homeLastVisit = getRuntimeContext().getState(homeStateDescriptor);detailLastVisit = getRuntimeContext().getState(detailStateDescriptor);}@Overridepublic void flatMap(JSONObject value, Collector<TrafficHomeDetailPageViewBean> out) throws Exception {// 获取状态数据以及当前数据中的日期String curDt = DateFormatUtil.toDate(value.getLong("ts"));String homeLastDt = homeLastVisit.value();String detailLastDt = detailLastVisit.value();long homeUvCt = 0;long goodDetailUvCt = 0;if (homeLastDt == null || !homeLastDt.equals(curDt)) {homeUvCt = 1;homeLastVisit.update(curDt);}if (detailLastDt == null || !detailLastDt.equals(curDt)) {goodDetailUvCt = 1;detailLastVisit.update(curDt);}if (homeUvCt == 1 || goodDetailUvCt == 1) {out.collect(new TrafficHomeDetailPageViewBean("", "",homeUvCt,goodDetailUvCt,value.getLong("ts")));}}});
1.2.5、开窗聚合并写入到 clickhouse
这里的窗口函数依旧是先用增量聚合函数,再用全量聚合函数(获得窗口信息);
注意:这里的 ts 字段是 clickhouse 表数据的版本字段,取系统时间即可;
// TODO 7. 开窗(windowAll聚合)聚合SingleOutputStreamOperator<TrafficHomeDetailPageViewBean> resultDS = trafficHomeDetailDS.windowAll(TumblingEventTimeWindows.of(org.apache.flink.streaming.api.windowing.time.Time.seconds(10))).reduce(new ReduceFunction<TrafficHomeDetailPageViewBean>() {@Overridepublic TrafficHomeDetailPageViewBean reduce(TrafficHomeDetailPageViewBean value1, TrafficHomeDetailPageViewBean value2) throws Exception {value1.setHomeUvCt(value1.getHomeUvCt() + value2.getHomeUvCt());value1.setGoodDetailUvCt(value1.getGoodDetailUvCt() + value2.getGoodDetailUvCt());return value1;}}, new AllWindowFunction<TrafficHomeDetailPageViewBean, TrafficHomeDetailPageViewBean, TimeWindow>() {@Overridepublic void apply(TimeWindow window, Iterable<TrafficHomeDetailPageViewBean> values, Collector<TrafficHomeDetailPageViewBean> out) throws Exception {TrafficHomeDetailPageViewBean next = values.iterator().next();next.setTs(System.currentTimeMillis());next.setStt(DateFormatUtil.toYmdHms(window.getStart()));next.setEdt(DateFormatUtil.toYmdHms(window.getEnd()));out.collect(next);}});// TODO 8. 写入到 clickhouseresultDS.addSink(ClickHouseUtil.getSinkFunction("insert into dws_traffic_page_view_window values(?,?,?,?,?)"));// TODO 9. 启动任务env.execute("DwsTrafficPageViewWindow");2、用户域用户登陆各窗口汇总表
任务:从 Kafka 页面日志主题读取数据,统计七日回流用户和当日独立用户数。
当日独立用户数很好求,和上面差不多,也是使用状态编程对 uid 保存状态去重即可。接下来我们主要分析七日回流用户怎么求:
2.1、思路分析
回流用户定义:之前的活跃用户,一段时间未活跃(流失),今日又活跃了。这里要求统计回流用户总数,规定当日登陆,且自上次登陆之后至少 7 日未登录的用户为回流用户。
1、消费页面浏览主题(dwd_traffic_page_log)登录用户过滤:
- 用户打开应用自动登录(cookie)
- uid != null && last_page_id = null (后面这个条件可以过滤掉没必要的数据)
- 用户在登录页登录
- uid != null && last_page_id = login
2、设置水位线、uid 分组之后进行状态编程
- 判断 lastLoginDt 是否为 null
- null:是今天的独立用户,但不是回流用户
- !=null
- 判断和今天是否相同
- 相同:丢弃
- 不同:是今天的独立用户,再判断今天-lastLoginDt >= 8?是回流用户:不是
- 判断和今天是否相同
2.2、代码实现
2.2.1、创建 ck 表并创建对应 JavaBean
这张表依然没有粒度,直接就是统计结果;我们去重的字段依然是窗口的起止时间:
create table if not exists dws_user_user_login_window
(stt DateTime,edt DateTime, back_ct UInt64,uu_ct UInt64,ts UInt64
) engine = ReplacingMergeTree(ts)partition by toYYYYMMDD(stt)order by (stt, edt);import lombok.AllArgsConstructor;
import lombok.Data;@Data
@AllArgsConstructor
public class UserLoginBean {// 窗口起始时间String stt;// 窗口终止时间String edt;// 回流用户数Long backCt;// 独立用户数Long uuCt;// 时间戳Long ts;
}2.2.2、 消费 dwd_traffic_page_log 主题
// TODO 3. 读取 dwd_traffic_page_log 的数据String groupId = "dws_user_user_login_window";DataStreamSource<String> pageLog = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer("dwd_traffic_page_log", groupId));
2.2.3、转换数据流为 JSON 格式并过滤出独立用户
// TODO 4. 转换为 json 格式 & 过滤出独立用户(uid!=null & last_page_id=null 或者 uid!=null & last_page_id=login)SingleOutputStreamOperator<JSONObject> filterDS = pageLog.flatMap(new RichFlatMapFunction<String, JSONObject>() {@Overridepublic void flatMap(String value, Collector<JSONObject> out) throws Exception {JSONObject jsonObject = JSONObject.parseObject(value);String uid = jsonObject.getJSONObject("common").getString("uid");String lastPageId = jsonObject.getJSONObject("page").getString("last_page_id");if (uid != null) {if (lastPageId == null || lastPageId.equals("login")) {out.collect(jsonObject);}}}});2.2.4、提取事件时间生成水位线
// TODO 5. 提取事件时间生成水位线filterDS.assignTimestampsAndWatermarks(WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() {@Overridepublic long extractTimestamp(JSONObject element, long recordTimestamp) {return element.getLong("ts");}}));2.2.5、使用状态编程过滤出独立用户
// TODO 6. 状态编程过滤出独立用户KeyedStream<JSONObject, String> keyedStream = filterDS.keyBy(json -> json.getJSONObject("common").getString("uid"));SingleOutputStreamOperator<UserLoginBean> userLoginDS = keyedStream.flatMap(new RichFlatMapFunction<JSONObject, UserLoginBean>() {private ValueState<String> lastLoginDtState;@Overridepublic void open(Configuration parameters) throws Exception {StateTtlConfig ttlConfig = new StateTtlConfig.Builder(Time.days(7)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).build();ValueStateDescriptor<String> lastLoginStateDescriptor = new ValueStateDescriptor<String>("last-login", String.class);lastLoginStateDescriptor.enableTimeToLive(ttlConfig);lastLoginDtState = getIterationRuntimeContext().getState(lastLoginStateDescriptor);}@Overridepublic void flatMap(JSONObject value, Collector<UserLoginBean> out) throws Exception {// 本次登录日期Long curTs = value.getLong("ts");String curDt = DateFormatUtil.toDate(curTs);// 上次登录日期String lastLoginDt = lastLoginDtState.value();long uuCt = 0L;long backCt = 0L;if (lastLoginDt == null) {uuCt = 1;lastLoginDtState.update(curDt);} else if (!lastLoginDt.equals(curDt)) {uuCt = 1;lastLoginDtState.update(curDt);// 判断相差是否 >= 8 天Long lastTs = DateFormatUtil.toTs(lastLoginDt);long days = (curTs - lastTs) / 1000 / 3600 / 24;backCt = days >= 8 ? 1 : 0;}if (uuCt != 0) {out.collect(new UserLoginBean("", "", backCt, uuCt, curTs));}}});
2.2.6、窗口聚合
和上一个需求一样,增量聚合函数和全量聚合函数配合着使用;
// TODO 6. 窗口聚合SingleOutputStreamOperator<UserLoginBean> resultDS = userLoginDS.windowAll(TumblingEventTimeWindows.of(org.apache.flink.streaming.api.windowing.time.Time.seconds(10))).reduce((record1, record2) -> {record1.setUuCt(record1.getUuCt() + record2.getUuCt());record2.setBackCt(record1.getBackCt() + record2.getBackCt());return record1;}, new AllWindowFunction<UserLoginBean, UserLoginBean, TimeWindow>() {@Overridepublic void apply(TimeWindow window, Iterable<UserLoginBean> values, Collector<UserLoginBean> out) throws Exception {UserLoginBean next = values.iterator().next();next.setStt(DateFormatUtil.toYmdHms(window.getStart()));next.setEdt(DateFormatUtil.toYmdHms(window.getEnd()));next.setTs(System.currentTimeMillis());out.collect(next);}});2.2.7、写出到 clickhouse
// TODO 7. 写入到 clickhouseresultDS.addSink(ClickHouseUtil.getSinkFunction("insert into dws_user_user_login_window values(?,?,?,?,?)"));// TODO 8. 启动任务env.execute("DwsUserUserLoginWindow");3、用户域用户注册各窗口汇总表
任务:从 DWD 层用户注册表中读取数据,统计各窗口注册用户数,写入 ClickHouse。
这个需求比较简单,因为我们之前在 DWD 层已经创建了用户注册事务事实表(包含字段:user_id,date_id,create_time,ts)
3.1、代码实现
这里教程中用的是 DataStream API ,但是我这里想用 Flink SQL 实现:
3.1.1、创建 dwd_user_register 表并生成水位线
注意:当原表中有更贴近事件时间的字段时,我们就尽量少用 Maxwell 的 ts 字段!
// TODO 3. 消费 Kafka dwd_user_register 主题(生成水位线)String groupId = "dws_user_user_register_window";tableEnv.executeSql("CREATE TABLE dwd_user_register " +"`user_id` string," +"`date_id` string," +"`create_time` string," +"`ts` string" +"time_ltz AS TO_TIMESTAMP(FROM_UNIXTIME(create_time/1000)), " +"WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND " +")" + MyKafkaUtil.getKafkaDDL("dwd_user_register",groupId));3.1.2、分组开窗聚合
用 Flink SQL 实现就简单多了,这里的聚合逻辑更简单,直接 count(*):
// TODO 4. 分组,开窗,聚合Table resultTable = tableEnv.sqlQuery("SELECT " +" date_format(tumble_start(time_ltz,interval '10' second),'yyyy-MM-dd HH:mm:ss') stt," +" date_format(tumble_end(time_ltz,interval '10' second),'yyyy-MM-dd HH:mm:ss') edt," +" count(*) register_ct," +" unix_timestamp() ts" +"FROM dwd_user_register " +"GROUP BY tumble(time_ltz,interval '10' second)");tableEnv.createTemporaryView("result_table",resultTable);3.1.3、创建 ck 表及其 Bean
create table if not exists dws_user_user_register_window
(stt DateTime,edt DateTime,register_ct UInt64,ts UInt64
) engine = ReplacingMergeTree(ts)partition by toYYYYMMDD(stt)order by (stt, edt);这里需要把动态表转为流,所以我们需要创建一个 Java Bean,对应上 ck 表的每个字段:
@Data
@AllArgsConstructor
public class UserRegisterBean {// 窗口起始时间String stt;// 窗口终止时间String edt;// 注册用户数Long registerCt;// 时间戳Long ts;
}3.1.4、将动态表转为流并写入到 clickhouse
// TODO 5. 将动态表转为流并写入到 clickhouseDataStream<UserRegisterBean> dataStream = tableEnv.toAppendStream(resultTable, UserRegisterBean.class);dataStream.addSink(ClickHouseUtil.getSinkFunction("insert into dws_user_user_register_window values (?,?,?,?)"));// TODO 6. 启动任务env.execute("DwsUserUserRegisterWindow");4、交易域加购各窗口汇总表
任务:从 Kafka 读取用户加购明细数据,统计每日各窗口加购独立用户数,写入 ClickHouse。
4.1、思路分析
思路很简单,还是根据 uid 进行 keyby,然后使用状态编程维护一个 lastCartAddDate,对数据进行判断:
- 如果 lastCartAddDate = null
- 写入状态
- 如果 lastCartAddDate != null
- 如果 lastCartAddDate != curDate
- 更新状态
- 否则丢弃
- 如果 lastCartAddDate != curDate
4.2、代码实现
这里不多介绍,和前面的逻辑都是一样的,只说明部分点:
- 我们在生成水位线的时候,应该尽可能的生成贴近事件时间的,而这里对于加购操作来说,它有两种情况:
- insert:就是加购,会影响的到 create_time 字段
- update:可能是加购,会影响到 operate_time 字段,我们在 DWD 层已经过滤过了:只要 sku_num 变大就是加购
- 所以这里我们的水位线可以取 operate_time 字段,取不到再取 create_time
// TODO 3. 读取 dwd_traffic_card_add 的数据String groupId = "dws_trade_cart_add_uu_window";DataStreamSource<String> cartAddLog = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer("dwd_trade_cart_add", groupId));//TODO 4. 转为 json 格式并SingleOutputStreamOperator<JSONObject> jsonDS = cartAddLog.map(JSONObject::parseObject);// TODO 5. 提取事件时间生成水位线jsonDS.assignTimestampsAndWatermarks(WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() {@Overridepublic long extractTimestamp(JSONObject element, long recordTimestamp) {String operate_time = element.getString("operate_time");if (operate_time != null){return DateFormatUtil.toTs(operate_time,true);}return DateFormatUtil.toTs(element.getString("create_time"));}}));// TODO 6. 按照用户id进行分组 & 过滤出独立用户KeyedStream<JSONObject, String> keyedStream = jsonDS.keyBy(json -> json.getJSONObject("common").getString("uid"));SingleOutputStreamOperator<CartAddUuBean> filterDS = keyedStream.flatMap(new RichFlatMapFunction<JSONObject, CartAddUuBean>() {private ValueState<String> lastCartAddDateState;@Overridepublic void open(Configuration parameters) throws Exception {StateTtlConfig ttlConfig = new StateTtlConfig.Builder(Time.days(1)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).build();ValueStateDescriptor<String> lastCartAddStateDescriptor = new ValueStateDescriptor<String>("last-cart-add", String.class);lastCartAddStateDescriptor.enableTimeToLive(ttlConfig);lastCartAddDateState = getRuntimeContext().getState(lastCartAddStateDescriptor);}@Overridepublic void flatMap(JSONObject value, Collector<CartAddUuBean> out) throws Exception {// 当前的时间戳Long curTs = value.getLong("ts");String curDate = DateFormatUtil.toDate(curTs);String lastCartAddDate = lastCartAddDateState.value();if (lastCartAddDate == null || !lastCartAddDate.equals(curDate)) {lastCartAddDateState.update(curDate);out.collect(new CartAddUuBean("","",1L,curTs));}}});// TODO 7. 开窗聚合(补充字段)SingleOutputStreamOperator<CartAddUuBean> resultDS = filterDS.windowAll(TumblingEventTimeWindows.of(org.apache.flink.streaming.api.windowing.time.Time.seconds(10))).reduce(new ReduceFunction<CartAddUuBean>() {@Overridepublic CartAddUuBean reduce(CartAddUuBean value1, CartAddUuBean value2) throws Exception {value1.setCartAddUuCt(value1.getCartAddUuCt() + value2.getCartAddUuCt());return value1;}}, new AllWindowFunction<CartAddUuBean, CartAddUuBean, TimeWindow>() {@Overridepublic void apply(TimeWindow window, Iterable<CartAddUuBean> values, Collector<CartAddUuBean> out) throws Exception {CartAddUuBean next = values.iterator().next();next.setStt(DateFormatUtil.toYmdHms(window.getStart()));next.setEdt(DateFormatUtil.toYmdHms(window.getEnd()));next.setTs(System.currentTimeMillis());out.collect(next);}});// TODO 8. 写出到 clickhouseresultDS.addSink(ClickHouseUtil.getSinkFunction("insert into dws_trade_cart_add_uu_window values (?,?,?,?)"));// TODO 9. 启动任务env.execute("DwsTradeCartAddUuWindow");5、交易域支付各窗口汇总表
任务:从 Kafka 读取交易域支付成功主题数据,统计支付成功独立用户数和首次支付成功用户数(第一次在平台消费)。
5.1、思路分析
如果一个用户是首次支付成功用户(既然是历史第一次下单操作,必然也是今天的第一次下单),那么他必然是今天的支付成功独立用户;所以我们只需要通过状态过滤出 lastPayDate = null 或者 lastPayDate != curDt 的用户(注意:这里的 lastPayDate 不能设置 TTL ,因为我们需要知道这个用户历史上有没有支付过,所以就不允许状态失效)
left join 实现过程:
假设 A 表作为主表与 B 表做等值左外联。当 A 表数据进入算子,而 B 表数据未至时会先生成一条 B 表字段均为 null 的关联数据ab1,其标记为 +I。其后,B 表数据到来,会先将之前的数据撤回,即生成一条与 ab1 内容相同,但标记为 -D 的数据,再生成一条关联后的数据,标记为 +I。这样生成的动态表对应的流称之为回撤流。
在 DWD 层的订单预处理表(dwd_trade_order_pre_process)生成过程中会形成回撤流,因为它需要对订单明细活动表和订单明细优惠券表进行 left join。而我们这里的支付成功依赖于 DWD 层支付成功事务事实表(dwd_trade_pay_detail_suc),该表又依赖于 DWD 层的下单事务事实表(dwd_trade_order_detail),所以这里我们需要考虑回撤流的问题:
回撤数据在 Kafka 中以 null 值的形式存在,只需要简单判断即可过滤。我们需要考虑的是如何对其余数据去重:
order_id = 1001
order_detail_id = 1001-a
order_detail_activity_id: a1SELECT ...
FROM
order_detail od
join order_info oi
onod.order_id = oi.id
left join order_detail_activity oa
onod.id = oa.order_detail_id上面我们有一个订单(id=1001),这个订单内只有一个商品并且参与了活动,那么由于 order_detail_activity 来得肯定要晚一些,所以可能会出现下面这种情况:
+/- order_id order_detail_id order_detail_activity_id+ 1001 1001-a null
- null null null
+ 1001 1001-a a1我们过滤 null 值指的是过滤上面操作是 '-' 的数据,因为回撤数据在 Kafka 中以 null 值的形式存在。而除了 null 值之外,我们还应该过滤掉旧的错误数据,由于 order_detail_activity 数据来得晚一些,导致flink 直接给字段 order_detail_activity_id 一个 null,所以我们应该把这个字段值删除;
但是,对于这个需求(求支付成功的用户数),其实我们也可以不做去重,放到最后再做去重,为什么呢?设想如果一个用户下了多个订单,而我们的支付成功表的粒度是商品,所以数据即使在 left join 之后对相同 order_detail_id 的数据做了去重,但是多个订单的话最终还有重复。
考虑到之后还可能遇到需要去重的需求(尤其是设计到金额的),这里我们还是练习一下如何实现去重:

5.2、代码实现
5.2.1、创建 clickhouse 表格及对应的 JavaBean
create table if not exists dws_trade_payment_suc_window
(stt DateTime,edt DateTime,payment_suc_unique_user_count UInt64,payment_new_user_count UInt64,ts UInt64
) engine = ReplacingMergeTree(ts)partition by toYYYYMMDD(stt)order by (stt, edt);import lombok.AllArgsConstructor;
import lombok.Data;@Data
@AllArgsConstructor
public class TradePaymentWindowBean {// 窗口起始时间String stt;// 窗口终止时间String edt;// 支付成功独立用户数Long paymentSucUniqueUserCount;// 支付成功新用户数Long paymentSucNewUserCount;// 时间戳Long ts;
}5.2.2、创建时间工具类
为了去重,我们需要对每一条数据都设置一个时间,因为对于重复数据,它们在原始表中的时间字段值都是一样的。
FlinkSQL 提供了几个可以获取当前时间戳的函数
- localtimestamp():返回本地时区的当前时间戳,返回类型为 TIMESTAMP(3)。在流处理模式下会对每条记录计算一次时间。而在批处理模式下,仅在查询开始时计算一次时间,所有数据使用相同的时间。
- current_timestamp():返回本地时区的当前时间戳,返回类型为 TIMESTAMP_LTZ(3)。在流处理模式下会对每条记录计算一次时间。而在批处理模式下,仅在查询开始时计算一次时间,所有数据使用相同的时间。
- now():与 current_timestamp 相同。
- current_row_timestamp():返回本地时区的当前时间戳,返回类型为 TIMESTAMP_LTZ(3)。无论在流处理模式还是批处理模式下,都会对每行数据计算一次时间。
这里,我们使用current_row_timestamp 来作为时间,我们需要给订单预处理表中添加:
current_row_timestamp() as row_op_ts-- 在建表语句中添加
row_op_ts TIMESTAMP_LTZ(3)那么,下单事务事实表来源于订单预处理表,支付成功事务事实表依赖于下单事务事实表,搜易当然也应该添加该字段。
import java.util.Comparator;public class TimestampLtz3CompareUtil {public static int compare(String timestamp1, String timestamp2) {// 数据格式 2022-04-01 10:20:47.302Z// 1. 去除末尾的时区标志,'Z' 表示 0 时区String cleanedTime1 = timestamp1.substring(0, timestamp1.length() - 1);String cleanedTime2 = timestamp2.substring(0, timestamp2.length() - 1);// 2. 提取小于 1秒的部分String[] timeArr1 = cleanedTime1.split("\\.");String[] timeArr2 = cleanedTime2.split("\\.");String microseconds1 = new StringBuilder(timeArr1[timeArr1.length - 1]).append("000").toString().substring(0, 3);String microseconds2 = new StringBuilder(timeArr2[timeArr2.length - 1]).append("000").toString().substring(0, 3);int micro1 = Integer.parseInt(microseconds1);int micro2 = Integer.parseInt(microseconds2);// 3. 提取 yyyy-MM-dd HH:mm:ss 的部分String date1 = timeArr1[0];String date2 = timeArr2[0];Long ts1 = DateFormatUtil.toTs(date1, true);Long ts2 = DateFormatUtil.toTs(date2, true);// 4. 获得精确到毫秒的时间戳long microTs1 = ts1 * 1000 + micro1;long microTs2 = ts2 * 1000 + micro2;long divTs = microTs1 - microTs2;return divTs < 0 ? -1 : divTs == 0 ? 0 : 1;}public static void main(String[] args) {System.out.println(compare("2022-04-01 11:10:55.040Z","2022-04-01 11:10:55.04Z"));}
}5.2.3、读取DWD支付成功事务事实表
读取DWD支付成功事务事实表并转为 JSON 格式,然后按照订单明细id进行分组(为了对回撤流的数据进行去重,根据相同明细id的时间进行判断)
// TODO 3. 读取 dwd_trade_pay_detail_suc 的数据String groupId = "dws_trade_payment_suc_window";DataStreamSource<String> paymentSucDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer("dwd_trade_pay_detail_suc", groupId));// TODO 4. 将数据转为JSON格式SingleOutputStreamOperator<JSONObject> jsonDS = paymentSucDS.flatMap(new RichFlatMapFunction<String, JSONObject>() {@Overridepublic void flatMap(String value, Collector<JSONObject> out) throws Exception {try {JSONObject jsonObject = JSONObject.parseObject(value);out.collect(jsonObject);} catch (Exception e) {// 可以选择输出到侧输出流e.printStackTrace();}}});// TODO 5. 按照订单明细id分组KeyedStream<JSONObject, String> keyedStream = jsonDS.keyBy(json -> json.getString("order_detail_id"));5.2.4、状态编程对回撤流中的数据去重
这里的回撤流是因为支付成功事务事实表需要用 订单明细 innner join 订单表 left join 订单明细活动 left join 订单明细活动造成的;
// TODO 6. 使用状态编程过滤最新数据输出(需要使用状态和定时器所以使用 process)SingleOutputStreamOperator<JSONObject> filterDS = keyedStream.process(new KeyedProcessFunction<String, JSONObject, JSONObject>() {private ValueState<JSONObject> lastPaySucDateState;@Overridepublic void open(Configuration parameters) throws Exception {lastPaySucDateState = getRuntimeContext().getState(new ValueStateDescriptor<>("last-pay-suc", JSONObject.class));}@Overridepublic void processElement(JSONObject value, Context ctx, Collector<JSONObject> out) throws Exception {JSONObject state = lastPaySucDateState.value();if (state == null) {lastPaySucDateState.update(value);// 注册定时器ctx.timerService().registerEventTimeTimer(ctx.timerService().currentProcessingTime() + 5000L);} else {String stateRt = state.getString("row_op_ts");String curRt = value.getString("row_op_ts");int compare = TimestampLtz3CompareUtil.compare(stateRt, curRt);if (compare != 1) { // 状态里的时间小lastPaySucDateState.update(value);}}}@Overridepublic void onTimer(long timestamp, OnTimerContext ctx, Collector<JSONObject> out) throws Exception {super.onTimer(timestamp, ctx, out);// 输出并清空状态数据JSONObject value = lastPaySucDateState.value();out.collect(value);lastPaySucDateState.clear();}});
5.2.5、提取事件时间并生成水位线
这里选择 callback_time ,它是支付成功后的回调时间;
// TODO 7. 提取事件时间生成水位线SingleOutputStreamOperator<JSONObject> jsonWithWmDS = filterDS.assignTimestampsAndWatermarks(WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() {@Overridepublic long extractTimestamp(JSONObject element, long recordTimestamp) {return DateFormatUtil.toTs(element.getString("callback_time"), true);}}));5.2.6、按照 user_id 分组并提取支付成功独立用户数和首次支付成功用户数
// TODO 8. 按照 user_id 分组KeyedStream<JSONObject, String> keyedByUidDS = jsonWithWmDS.keyBy(json -> json.getString("user_id"));// TODO 9. 提取独立支付成功用户数和首次支付成功用户数SingleOutputStreamOperator<TradePaymentWindowBean> tradePaymentDS = keyedByUidDS.flatMap(new RichFlatMapFunction<JSONObject, TradePaymentWindowBean>() {private ValueState<String> lastDtState;@Overridepublic void open(Configuration parameters) throws Exception {lastDtState = getRuntimeContext().getState(new ValueStateDescriptor<String>("lastDt", String.class));}@Overridepublic void flatMap(JSONObject value, Collector<TradePaymentWindowBean> out) throws Exception {String lastDt = lastDtState.value();String curDt = value.getString("callback_time").split(" ")[0];// 当日支付人数long pay = 0L;// 首次支付人数long newPay = 0L;// 判断状态是否为nullif (lastDt == null) {pay = 1;newPay = 1;lastDtState.update(curDt);} else if (!lastDt.equals(curDt)) {pay = 1;lastDtState.update(curDt);}// 写出if (pay == 1) {out.collect(new TradePaymentWindowBean("", "", newPay, pay, DateFormatUtil.toTs(curDt)));}}});5.2.7、开窗聚合并写出到 clickhouse
开窗是为了实时刷新到报表,聚合依然是那两个函数:增量聚合(聚合结果),全量聚合(补充窗口起止字段);
// TODO 10. 开窗,聚合SingleOutputStreamOperator<TradePaymentWindowBean> resultDS = tradePaymentDS.windowAll(TumblingEventTimeWindows.of(Time.seconds(10))).reduce(new ReduceFunction<TradePaymentWindowBean>() {@Overridepublic TradePaymentWindowBean reduce(TradePaymentWindowBean value1, TradePaymentWindowBean value2) throws Exception {value1.setPaymentSucNewUserCount(value1.getPaymentSucNewUserCount() + value2.getPaymentSucNewUserCount());value1.setPaymentSucUniqueUserCount(value1.getPaymentSucUniqueUserCount() + value2.getPaymentSucUniqueUserCount());return value1;}}, new AllWindowFunction<TradePaymentWindowBean, TradePaymentWindowBean, TimeWindow>() {@Overridepublic void apply(TimeWindow window, Iterable<TradePaymentWindowBean> values, Collector<TradePaymentWindowBean> out) throws Exception {TradePaymentWindowBean next = values.iterator().next();next.setTs(System.currentTimeMillis());next.setStt(DateFormatUtil.toYmdHms(window.getStart()));next.setEdt(DateFormatUtil.toYmdHms(window.getEnd()));out.collect(next);}});// TODO 11. 写出到 clickhouseresultDS.addSink(ClickHouseUtil.getSinkFunction("insert into dws_trade_payment_suc_window values(?,?,?,?,?)"));// TODO 12. 启动任务env.execute("DwsTradePaymentSucWindow");总结
今天的 DWS 层到此为止,剩下了还有几个需求估计还得 1~2 天完成,这一块要比之前都难一些,争取这周日前把实时数仓完结;然后下周开始把离线和实时再好好复习一遍;
相关文章:
Flink 实时数仓(八)【DWS 层搭建(二)流量域、用户域、交易域搭建】
前言 今天的任务是完成流量域最后一个需求、用户域的两个需求以及交易域的部分需求; 1、流量域页面浏览各窗口汇总表 任务:从 Kafka 页面日志主题读取数据,统计当日的首页和商品详情页独立访客数。 注意:一般我们谈到访客&…...

gitlab-runner /var/run/docker.sock connect permission denied
usermod -aG docker gitlab-runner sudo service docker restart参考:https://gitlab.com/gitlab-org/gitlab-runner/-/issues/3492...

网络安全 - 应急响应检查表
前言 本项目旨在为应急响应提供全方位辅助,以便快速解决问题。结合自身经验和网络资料,形成检查清单,期待大家提供更多技巧,共同完善本项目。愿大家在应急之路一帆风顺。 图片皆来源于网络,如有侵权请联系删除。 一…...
)
AD常用PCB设计规则介绍 (详细版)
AD09常用PCB设计规则介绍 电气设计规则用来设置在电路板布线过程中所遵循的电气方面的规则,包括安全间距、短路、未布线网络和未连接引脚这四个方面的规则: (1)、安全间距规则(clearance) 该规则用于设定在PCB设计中࿰…...

mysql主从服务配置
主从MySQL服务器 [rootlocalhost ~]# yum -y install ntpdate [rootlocalhost ~]# ntpdate cn.ntp.org.cn [rootlocalhost ~]# yum -y install rsync [rootlocalhost ~]# vim mysql.sh #!/bin/bash yum list installed |grep libaio if [ $? ne 0 ]; then yum -y install…...
Redis基础总结、持久化、主从复制、哨兵模式、内存淘汰策略、缓存
文章目录 Redis 基础Redis 是什么,有哪些特点为什么要使用 Redis 而不仅仅依赖 MySQLRedis 是单线程吗Redis 单线程为什么还这么快 Redis 数据类型和数据结构五种基本数据结构及应用场景其他数据类型Redis 底层数据结构 Redis 持久化数据不丢失的实现AOF 日志RDB 快…...

Java与Python优劣势对比:具体例子与深入分析
在软件开发的世界里,Java和Python是两座不可忽视的高峰。它们各自拥有独特的优势和应用场景,为开发者提供了多样化的选择。本文将通过具体例子,深入分析Java和Python在不同方面的表现,以期为读者提供更为详尽的参考。 1. 语法简洁…...

C++内存泄漏介绍
C内存泄漏(Memory Leak)是指程序在运行过程中,动态分配的内存没有被适当地释放或回收,导致这部分内存始终被占用,无法再被程序或其他程序使用。这种情况通常发生在使用了new或malloc等函数动态分配内存后,忘…...
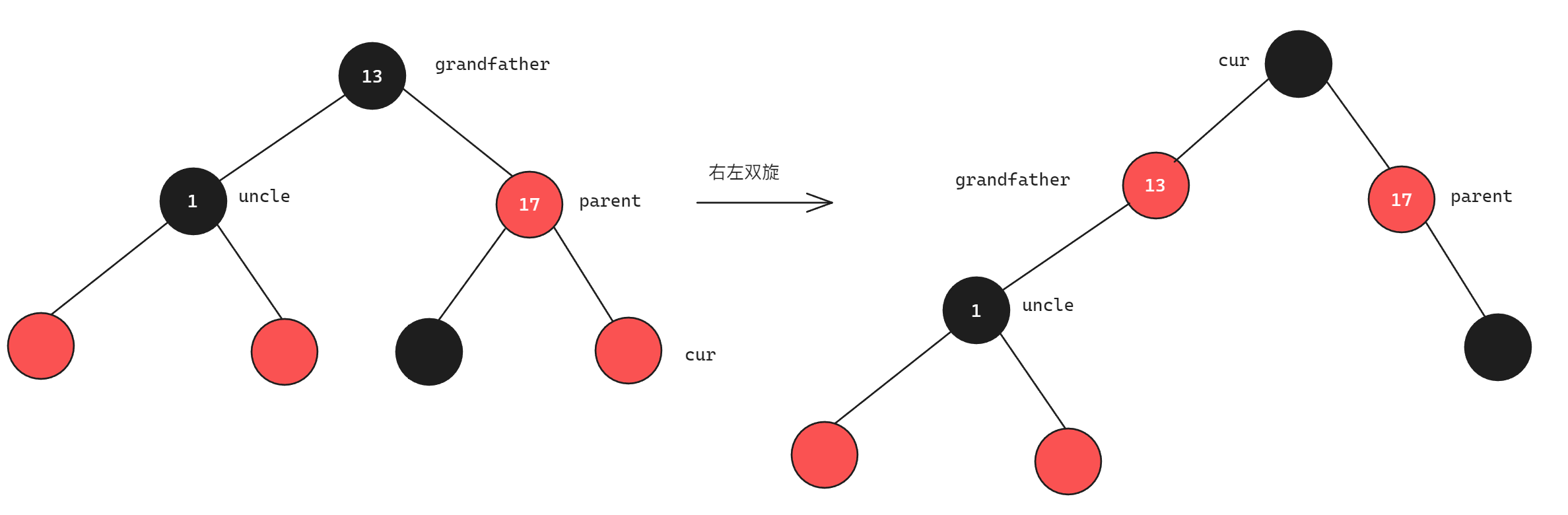
C++分析红黑树
目录 红黑树介绍 红黑树的性质与平衡控制关系 红黑树节点的插入 情况1:不需要调整 情况2:uncle节点为红色 情况3:uncle节点为黑色 总结与代码实现 红黑树的删除(待实现) 红黑树的效率 红黑树介绍 红黑树是第二种平衡二…...

mysql线上查询之前要性能调优
查询优化是数据库性能调优的关键方面,目的是减少查询的执行时间和资源消耗。以下是一些常见的查询优化技巧及其示例: 使用合适的索引 问题: 全表扫描导致查询缓慢优化: 为经常用于搜索条件的列添加索引示例: 假设有一…...

GPIO输出控制之LED闪烁、LED流水灯以及蜂鸣器应用案例
系列文章目录 STM32之GPIO(General Purpose Input/Output,通用型输入输出) 文章目录 系列文章目录前言一、LED和蜂鸣器简介1.1 LED1.2 蜂鸣器1.3 面包板 二、LED硬件电路2.1 低电平驱动电路2.2 高电平驱动电路 三、蜂鸣器硬件电路3.1 PNP型三…...

体系结构论文导读(三十四):Design of Reliable DNN Accelerator with Un-reliable ReRAM
文章核心 这篇文章主要讨论了一种在不可靠的ReRAM(阻变存储器)设备上设计可靠的深度神经网络(DNN)加速器的方法。文章提出了两种关键技术来解决ReRAM固有的不可靠性问题:动态定点(DFP)数据表示…...

WebStock会话
其实使用消息队列也可以实现会话,直接前端监听指定的队列,使用rabbitmq的分组还可以实现不同群聊的效果。 1、依赖搭建: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org…...

5_现有网络模型的使用
教程:现有网络模型的使用及修改_哔哩哔哩_bilibili 官方网址:https://pytorch.org/vision/stable/models.html#classification 初识网络模型 pytorch为我们提供了许多已经构造好的网络模型,我们只要将它们加载进来,就可以直接使…...

软件安全测试报告内容和作用简析,软件测试服务供应商推荐
在数字化时代,软件安全问题愈发凸显,安全测试显得尤为重要。软件安全测试报告是对软件系统在安全性方面进行评估和分析后的书面文件。该报告通常包含测试过程、测试发现、漏洞描述、风险评估及改进建议等重要信息。报告的目的是为了帮助开发团队及时发现…...

算法板子:树形DP、树的DFS——树的重心
思想: 代码: #include <iostream> #include <cstring> using namespace std;const int N 1e5 10;// vis标记当前节点是否被访问过; vis[1]true代表编号为1的节点被访问过 bool vis[N]; // h数组为邻接表; h数组上的每个坑位都串了一个单链…...
是一种特殊的数据类型,允许在相同的内存位置存储不同的数据类型。)
在C语言中,联合体或共用体(union )是一种特殊的数据类型,允许在相同的内存位置存储不同的数据类型。
在C语言中,union 是一种特殊的数据类型,允许在相同的内存位置存储不同的数据类型。这意味着 union 中的所有成员共享同一块内存空间,因此它们之间会相互覆盖。在你给出的 Acceleration_type union 定义中,包含了三种不同类型的成员…...

MS2201以太网收发电路
MS2201 是吉比特以太网收发器电路,可以实现超高速度的 全双工数据传输。它的通信遵从 IEEE 802.3 Gigabit Ethernet 协议 中的 10 比特接口的时序要求协议。 MS2201 支持数据传输速率从 1Gbps 到 1.85Gbps 。 主要特点 ◼ 电源电压: 2.5V 、 3.3V …...

乐乐音乐Kotlin版
简介 乐乐音乐Kotlin版,主要是基于ExoPlayer框架开发的Android音乐播放器,它支持lrc歌词和动感歌词(ksc歌词、krc歌词、trc歌词、zrce歌词和hrc歌词等)、多种格式歌词转换器及制作动感歌词、翻译歌词和音译歌词。 编译环境 Android Studio Jellyfish | …...

C语言——预处理和指针
C语言——预处理和指针 预处理宏宏定义宏的作用域带参的宏 文件包含条件编译 指针指针的概念指针的定义指针变量初始化指针一维整型数组 预处理 编程的流程分为:编辑、编译、运行、调试四个阶段; 预处理属于编译阶段,编译过程又可以分为&…...

如何在不同游戏中保持相同鼠标灵敏度:终极免费转换工具完整指南
如何在不同游戏中保持相同鼠标灵敏度:终极免费转换工具完整指南 【免费下载链接】SensitivityMatcher Script that can be used to convert your mouse sensitivity between different 3D games. 项目地址: https://gitcode.com/gh_mirrors/se/SensitivityMatcher…...

用C++打造经典小游戏:从猜拳到扫雷的实战指南
1. 为什么选择C开发经典小游戏? 很多初学者问我,为什么推荐用C来开发小游戏而不是Python或者JavaScript?这个问题我十年前刚开始学编程时也思考过。经过多年实战,我发现C有几个不可替代的优势:首先是性能,C…...

深度解析Windows 11系统优化:3大高效修复策略实战指南
深度解析Windows 11系统优化:3大高效修复策略实战指南 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher Windows 11更新后࿰…...

C#实现S7系列PLC上位机通信系统开发——使用VS2017进行数据读写、寄存器操控与IO通信助手
C#编写西门子S7系列PLC上位机通信,ⅤS2017编写,涵盖读写寄存器,中间继电器,外部IO读写。 数据采集好帮手。 无密码,无使用时间限制。一、系统概述 西门子S7系列PLC C#上位机通信系统是基于Visual Studio 2017开发环境&…...
Pixel Couplet Gen惊艳案例:神荼郁垒像素方块+物理卷轴动态渲染
Pixel Couplet Gen惊艳案例:神荼郁垒像素方块物理卷轴动态渲染 1. 项目概览 当AI技术遇上复古游戏美学,Pixel Couplet Gen为我们带来了一场视觉与文化的盛宴。这款基于ModelScope大模型的春联生成器,彻底颠覆了传统春联的设计语言ÿ…...

彻底告别Windows Defender烦恼:开源控制工具让你的电脑真正属于你
彻底告别Windows Defender烦恼:开源控制工具让你的电脑真正属于你 【免费下载链接】defender-control An open-source windows defender manager. Now you can disable windows defender permanently. 项目地址: https://gitcode.com/gh_mirrors/de/defender-con…...

AWS CDN 配置:实现非 www 域名自动跳转到 www.xxx.com
1. 为什么需要将非 www 域名跳转到 www 域名? 很多网站在运营过程中都会遇到一个经典问题:用户可能通过带 www 的域名(如 www.example.com)访问,也可能直接输入不带 www 的域名(如 example.com)…...

春联生成模型-中文-base效果实测:输入‘平安‘、‘富贵‘,对联寓意满满
春联生成模型-中文-base效果实测:输入平安、富贵,对联寓意满满 1. 模型效果初体验 春节将至,家家户户都开始准备贴春联。传统春联创作需要深厚的文学功底,而如今AI技术让这一过程变得简单有趣。今天我们要实测的是一款基于阿里达…...

Windows Defender终极移除指南:高效释放系统资源的13项完整方案
Windows Defender终极移除指南:高效释放系统资源的13项完整方案 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mi…...

Go语言怎么防SQL注入_Go语言SQL注入防护教程【深入】
必须使用参数占位符(如?或$1)而非字符串拼接来防止SQL注入;sql.RawBytes仅用于读取二进制字段,不可用于拼接SQL;动态表名/字段名需白名单校验;ORM应禁用Raw()并启用PrepareStmt;JSON中的SQL片段…...