LeetCode面试150——274H指数
题目难度:中等
默认优化目标:最小化平均时间复杂度。
Python默认为Python3。
目录
1 题目描述
2 题目解析
3 算法原理及代码实现
3.1 排序
3.2 排序时间优化(计数排序)
3.3 二分查找
参考文献
1 题目描述
给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。
根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指数 是指他(她)至少发表了 h 篇论文,并且 至少 有 h 篇论文被引用次数大于等于 h 。如果 h 有多种可能的值,h 指数 是其中最大的那个。
示例 1:
输入:citations = [3,0,6,1,5] 输出:3 解释:给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 3, 0, 6, 1, 5 次。由于研究者有 3 篇论文每篇 至少 被引用了 3 次,其余两篇论文每篇被引用 不多于 3 次,所以她的 h 指数是 3。
示例 2:
输入:citations = [1,3,1] 输出:1
提示:
-
n == citations.length -
1 <= n <= 5000 -
0 <= citations[i] <= 1000
2 题目解析
输入是数组citations(引用的英文),输出是h指数。citations的长度n代表总共发表的论文篇数,下标代表论文名,元素值代表论文被引用的次数。
h指数的意思为,citations中有h篇论文被引用次数超过了h次。如示例2中,h取1,至少发表了一篇论文引用次数超过1,h指数为1。h取2,至少发表了2篇论文引用次数超过2,不成立。h取3,至少发表了3篇论文引用次数超过3,不成立。
暴力求法是先计算citations长度n,然后每个元素去和n比大小,都大于则输出n,否则接着和n=n-1比大小,以此类推。平均时间复杂度为O(n!)。
3 算法原理及代码实现
3.1 排序
在暴力求法的基础上,我们先对citations排序,变成一个有序数组。假如是升序排序,一次循环从后向前遍历。
题目中至少就是大于的意思,比如至少大于 1次就是>0,至少大于h次就是>h。因此初始化h=0。citations[i]和h比大小,如果citations[i]大于h,h++,反之不执行任何操作。最后输出h即可。
平均时间复杂度为O(n log n)(采用快排),平均空间复杂度为O(1)。
C++代码实现
class Solution {
public:int hIndex(vector<int>& citations) {int n=citations.size();int h=0;
sort(citations.begin(),citations.end());
for(int i=n-1;i>=0;i--){if(citations[i]>h){h++;}}
return h;
}
};Python代码实现
class Solution:def hIndex(self, citations: List[int]) -> int:citations.sort()h = 0n = len(citations)for i in range(n-1, -1, -1):if citations[i] > h:h += 1return h3.2 排序时间优化(计数排序)
从3.1可以看到,平均时间复杂度和排序算法的时间复杂度相同。我们可以牺牲空间换时间,使用计数排序进一步降低时间复杂度。
新建一个计数数组counter,将citations中论文引用次数映射到counter中。映射规则如下:如果元素值大于n,counter[n]++;反之,对应引用次数的下标位置citations[i],计数数组counter[citations[i]]++。
平均时间复杂度为O(n),平均空间复杂度为O(n)。
C++代码实现如下
class Solution {
public:int hIndex(vector<int>& citations) {int n=citations.size();vector<int> counter(n+1);int h=0;
//计数排序for(int i=0;i<n;i++){if(citations[i]>n){counter[n]++;}else{counter[citations[i]]++;}}
for(int i=n;i>=0;i--){h+=counter[i];//引用至少h次的论文总数if(h>=i){//这里的i代表引用次数return i;}}
return 0;
}
};Python代码实现
class Solution:def hIndex(self, citations: List[int]) -> int:n = len(citations)counter = [0] * (n + 1)h = 0
# 计数排序for citation in citations:if citation > n:counter[n] += 1else:counter[citation] += 1
for i in range(n, -1, -1):h += counter[i] # 引用至少 h 次的论文总数if h >= i: # 这里的 i 代表引用次数return i
return 03.3 二分查找
设左边界为left,右边界为right,中点为mid。我们可以把原问题拆分成若干个子问题:判断至少有mid数大于mid。如果在区间[mid,right]满足,说明搜寻的h在右边,反之在左边。
平均时间复杂度O(n log n),平均空间复杂度O(1)
class Solution {
public:int hIndex(vector<int>& citations) {return binarySearch(citations, 0, citations.size());}
private:int binarySearch(vector<int>& citations, int left, int right) {if (left >= right) {return left;}
int mid = (left + right + 1) >> 1;int cnt = 0;for (int i = 0; i < citations.size(); i++) {if (citations[i] >= mid) {cnt++;}}
if (cnt >= mid) {return binarySearch(citations, mid, right);} else {return binarySearch(citations, left, mid - 1);}}
};
Python代码实现
class Solution:def hIndex(self, citations: List[int]) -> int:return self.binarySearch(citations, 0, len(citations))
def binarySearch(self, citations, left, right):if left >= right:return left
mid = (left + right + 1) // 2cnt = sum(1 for citation in citations if citation >= mid)
if cnt >= mid:return self.binarySearch(citations, mid, right)else:return self.binarySearch(citations, left, mid - 1)
参考文献
力扣面试经典150题
力扣官方题解
相关文章:

LeetCode面试150——274H指数
题目难度:中等 默认优化目标:最小化平均时间复杂度。 Python默认为Python3。 目录 1 题目描述 2 题目解析 3 算法原理及代码实现 3.1 排序 3.2 排序时间优化(计数排序) 3.3 二分查找 参考文献 1 题目描述 给你一个整数数组 citations …...
【Linux】Linux重定向指南:探索输出重定向与追加重定向的奥秘!
欢迎来到 CILMY23 的博客 🏆本篇主题为:Linux重定向指南:探索输出重定向与追加重定向的奥秘! 🏆个人主页:CILMY23-CSDN博客 🏆系列专栏:Python | C | C语言 | 数据结构与算法 | 贪…...
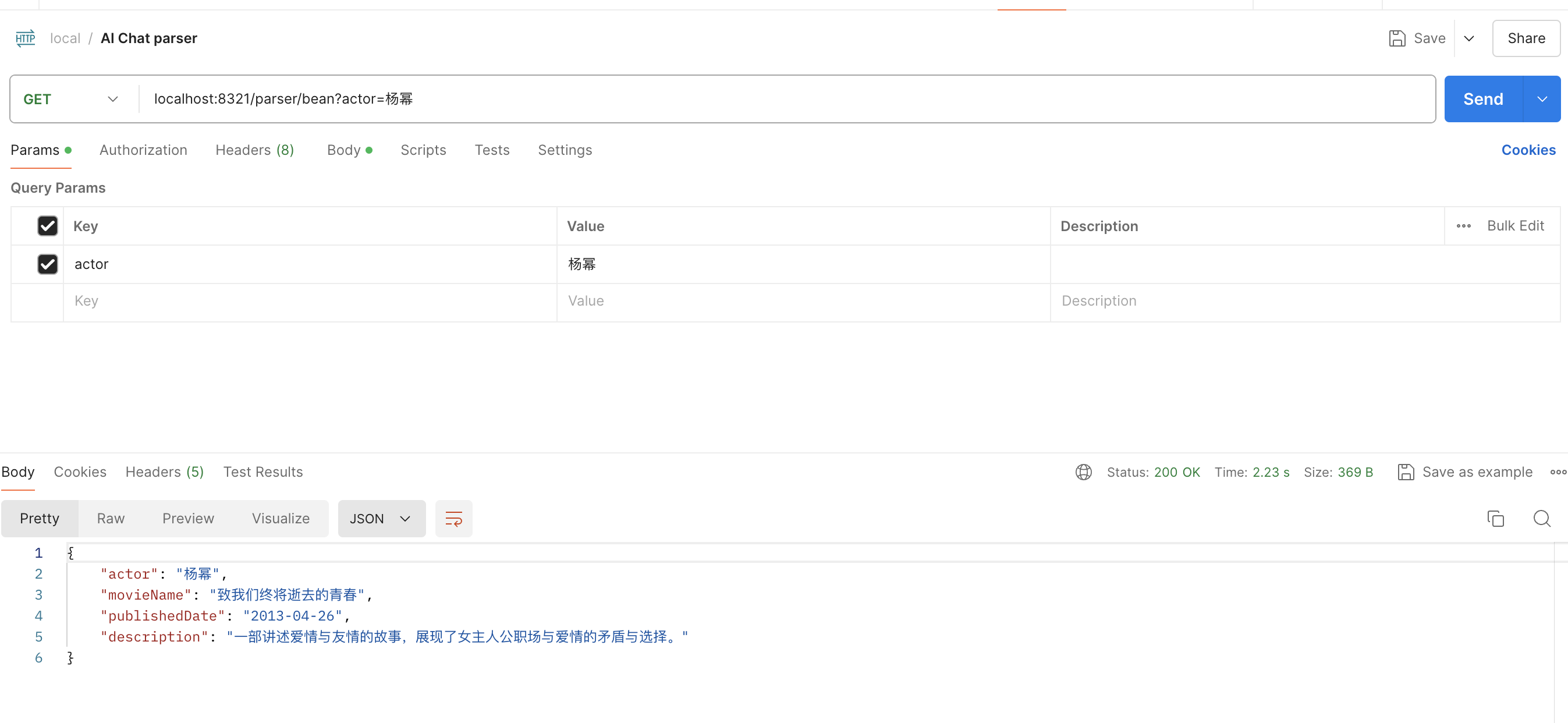
Spring AI -快速开发ChatGPT应用
Spring AI介绍 Spring AI是AI工程师的一个应用框架,它提供了一个友好的API和开发AI应用的抽象,旨在简化AI应用的开发工序,例如开发一款基于ChatGPT的对话、图片、音频等应用程序。 Spring AI已经集成了OpenAI的API,因此我们不需…...

Modern C++ 智能指针
Why? 原始指针存在缺陷,不符合现代编程语言的需要。 原始指针的缺陷: 指针指向一片内存,使用者无法得知到底是指向了什么,是数组还是对象?使用完指针是否需要销毁?什么时候销毁?如…...

Python的100道经典练习题,每日一练,必成大神!!!
Python的100道经典练习题是一个广泛而深入的学习资源,可以帮助Python初学者和进阶者巩固和提升编程技能 完整的100多道练习题可在下面图片免沸获取哦~ 整理了100道Python的题目,如果你是一位初学者,这一百多道题可以 帮助你轻松的使用Python…...

代码回滚命令
定位到当前分支 git branch回滚到指定的commit git reset --hard 85da0cb8322accad143cpush到远程分支 git push --force...
[ASIS 2019]Unicorn shop1
打开题目 随便输入信息看一下 操作失败,只让输入一个字符 不妨抓包看一下,信息,发现 从中可以发现源代码是如何处理price的 使用的是unicodedata.numeric() 但我们查看页面源码时,看到源码处理方式是utf-8 所以,前…...

LangChain与泛型编程:探索代码生成的新维度
LangChain与泛型编程:探索代码生成的新维度 在软件开发领域,泛型编程是一种允许创建可重用组件的技术,这些组件可以在多种数据类型上工作的编程范式。LangChain作为一个假设的编程辅助工具,如果存在,它可能会支持泛型…...

day25
一、进程间通信(IPC) 1.1 进程间通信的引入 1> 对于多个线程之间通信,我们可以使用临界资源来完成,通过一个线程任务对临界资源进行修改,另一个线程也可以使用已经修改过的临界资源,但是要注意使用…...

红黑树的概念和模拟实现[C++]
文章目录 红黑树的概念一、红黑树的性质红黑树原理二、红黑树的优势和比较 红黑树的模拟实现构建红黑树的数据结构定义节点的基本结构和初始化方式插入新节点插入新节点的颜色调整颜色和结构以满足红黑树性质 红黑树的应用场景 红黑树的概念 一、红黑树的性质 红黑树是一种自平…...

网络安全应急响应概述
前言 在网络安全领域,有一句广为人知的话:“没有绝对的安全”。这意味着任何系统都有可能被攻破。安全攻击的发生并不可怕,可怕的是从头到尾都毫无察觉。当系统遭遇攻击时,企业的安全人员需要立即进行应急响应,以将影响…...
【C++】链表操作技巧综合:重排链表(带你理顺链表的做题思路)
1.题目 2.算法思路 这是一道关于链表的综合题,一共涉及到三个步骤,其中每个步骤单拎出来就可以当一道单独的题目。所以需要大家对链表的操作十分熟悉,否则可能需要大量的时间做这道题目,而且还要很多的bug。 第一个步骤…...

行为型设计模式2:观察者/职责链/中介者/访问者
设计模式:观察者/职责链/中介者/访问者 (qq.com)...

叛逆,批判
1、对以往说法的批判之一(第一次这么公开批判是2004-2005年): 这部英文版的《数学百科全书》似乎是从俄语版翻译过来的?我查了三本引用的图书文献,都没有关于“nonsingular”和“singular”的类似下面的说法ÿ…...

Linux 命令,mkdir说明与使用
1:mkdir命令功用: 用于创建一个或多个目录,创建目录,必须在父目录中写上权限。 新目录的默认模式为0777,可以由系统或用的umask来修改。 2:命令构件: mkdir [options] directories 3:参数选项: -m&#x…...

24. 两两交换链表中的节点(Java)
目录 题目描述:示例 :代码实现: 题目描述: 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换&am…...

linux虚拟机设置固定ip
修改/etc/sysconfig/network-scripts目录下ifcfg-eth0文件,各虚拟机这个文件名不一致,ifcfg-XX格式 vim /etc/sysconfig/network-scripts/ifcfg-eth0BOOTPROTO设置为static,然后在最后添加固定IP地址和默认网关、DNS等配置,IP地址…...

mysql问题解决
1.etl数据同步时,发现连接不上要同步的数据库 解决方法:关闭mysql的ssl,步骤如下: 在MySQL中禁用SSL连接涉及修改服务器的配置文件(通常是my.cnf或my.ini,取决于你的操作系统和MySQL版本)。以…...

类和对象(下)C++
1.初始化列表 1.为什么有初始化列表,它的作用? ->初始化列表,是构造函数初始化的另一种形式。 ->在语法上面理解,初始化列表可以认定为是每个成员变量定义初始化的地方. ->引用成员变量,const成员变量&am…...

常用在线 Webshell 查杀工具推荐
一、简介 这篇文章将介绍几款常用的在线 Webshell 查杀工具,包括长亭牧云、微步在线云沙箱、河马和VirusTotal。每个工具都有其独特的特点和优势,用于帮助用户有效检测和清除各类恶意 Webshell,保障网站和服务器的安全。文章将深入探讨它们的…...

【JavaScript高级编程】拆解函数流水线 上郴
一、什么是setuptools? setuptools 是一个用于创建、分发和安装 Python 包的核心库。 它可以帮助你: 定义 Python 包的元数据(如名称、版本、作者等)。 声明包的依赖项,确保你的包能够正确运行。 构建源代码分发包&…...

PNGenc:面向MCU的45KB轻量级PNG编码器
1. PNGenc:面向资源受限MCU的轻量级PNG编码器深度解析1.1 设计背景与工程动因PNGenc并非对标准libpng的移植或裁剪,而是在“零依赖、零堆内存、零规格妥协”原则下,从PNG规范(ISO/IEC 15948:2003)和DEFLATE压缩算法&am…...

群晖7.2整合Jellyfin+alist+CloudDriver打造云端无盘影音库
1. 为什么需要云端无盘影音库? 最近几年,我发现越来越多的朋友开始在家里搭建私人影音库。传统的做法是在NAS里塞满硬盘,但随着4K、HDR等高码率资源的普及,本地存储很快就捉襟见肘。我自己就经历过几次硬盘爆满的尴尬,…...

MMC-HVDC仿真模型及柔性直流输电相关基础模型集合
MMC-HVDC仿真模型,pscad柔性直流输电仿真mmc仿真模型,双端mmc模型,MMC为21电平NLM和均压控制,还有多端如张北直流电网以及基本mmc逆变器,自己为毕业网上收集的一些觉得有用的基础模型最近在折腾MMC-HVDC仿真࿰…...

Arduino DHT11极简驱动库:单总线时序鲁棒性设计
1. 项目概述SL002_DHT11 是一款专为 Arduino 平台设计的轻量级 DHT11 温湿度传感器驱动库。其核心定位是“极简可用”——在保证功能完整性的前提下,最大限度降低资源占用与使用门槛。该库不依赖任何高级抽象层(如 Wire.h 或 SPI.h)ÿ…...

BFS入门经典
#include <cstring> #include <iostream> #include <algorithm> #include <queue>using namespace std;// pair<int,int> 用来存一个点的坐标 (x, y) typedef pair<int, int> PII;const int N 110;int n, m; // n 行 m 列 i…...

别再只盯着相角裕度了!深入理解增益裕度gm对系统鲁棒性的影响
别再只盯着相角裕度了!深入理解增益裕度gm对系统鲁棒性的影响 在控制系统的稳定性分析中,相角裕度(Phase Margin)常常是工程师们关注的焦点,而增益裕度(Gain Margin)则容易被忽视。这种偏重可能源于传统教材中简化案例的示范效应——在大多数…...

TMSpeech:Windows平台离线语音转文字的终极解决方案
TMSpeech:Windows平台离线语音转文字的终极解决方案 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 还在为会议记录而手忙脚乱吗?还在为在线课程笔记而烦恼吗?今天我要向你介绍一…...

SeqGPT-560M镜像免配置教程:无需pip install,直接运行Web服务
SeqGPT-560M镜像免配置教程:无需pip install,直接运行Web服务 本文介绍如何快速使用SeqGPT-560M镜像,无需任何环境配置,直接启动Web服务进行文本分类和信息抽取。 1. 什么是SeqGPT-560M? SeqGPT-560M是阿里达摩院推出…...

一条命令搞定OpenClaw部署?PPClaw的便利背后,你得先看清这些代价
先说结论PPClaw通过云端沙箱和命令行工具,确实能大幅降低OpenClaw的初始部署门槛,尤其适合快速验证场景。这种便利性背后,意味着你将依赖PPIO的特定环境,可能面临供应商锁定和长期成本不可预测的风险。对于需要深度定制或大规模生…...