Linux IPC解析:匿名命名管道与共享内存

目录
- 一.IPC机制介绍
- 二.匿名与命名管道
- 1.匿名管道
- 2.命名管道
- 3.日志
- 三.共享内存
- 三.System V 标准
- 1.System V简介
- 2.IPC在内核的数据结构设计
- 3.信号量
一.IPC机制介绍
IPC(Inter-Process Communication,进程间通信)是计算机系统中不同进程之间交换数据和同步操作的机制。由于现代计算机系统中,程序通常会由多个进程组成,这些进程可能需要相互通信以完成任务,因此IPC非常重要。
IPC主要功能:
- 数据交换:允许不同进程共享数据或传递信息。
- 同步:协调多个进程之间的操作,以避免竞态条件和资源冲突。
- 互斥:控制多个进程对共享资源的访问,确保同一时间只有一个进程能够访问资源
IPC主要机制:
- 管道(Pipes):匿名管道:用于相关进程之间的单向通信,如父子进程或兄弟进程。
命名管道(FIFO):用于不相关进程之间的双向或单向通信,具有一个路径名,可以在不同的进程之间共享。 - 消息队列(Message Queues):允许进程以消息的形式发送和接收数据,消息可以按照队列的顺序进行传递。
- 共享内存(Shared Memory):允许多个进程映射同一块物理内存区域,从而实现高速的数据共享和通信。
- 信号量(Semaphores):用于实现进程间的同步和互斥,以控制对共享资源的访问。
- 套接字(Sockets):尽管最常用于网络通信,套接字也可以用于同一台计算机上的进程间通信。
二.匿名与命名管道
1.匿名管道
管道是进程间通信的一种机制,通常用于将一个进程的输出数据传递给另一个进程的输入。管道可以分为两种主要类型:匿名管道和命名管道。
管道原理简易演示图:

上图所示,我们就将通信信道建立好了。那么我们具体应该如何编码实现呢?

pipe函数介绍:
pipe()函数创建一个管道,该管道提供了一对文件描述符:一个用于读操作,另一个用于写操作。数据从写端流向读端。
返回值:
- 成功:返回0。
- 失败:返回-1,并将errno设置为错误代码。
下面我们写一段代码用匿名管道简单实现父子进程的通信:
#include <iostream> // 包含输入输出流库
#include <cstdio> // 包含标准输入输出库
#include <string> // 包含C++字符串库
#include <cstring> // 包含C字符串处理库
#include <cstdlib> // 包含C标准库
#include <unistd.h> // 包含POSIX操作系统API
#include <sys/types.h> // 包含数据类型定义
#include <sys/wait.h> // 包含进程等待函数#define N 2 // 定义常量N为2
#define NUM 1024 // 定义常量NUM为1024,表示缓冲区大小using namespace std; // 使用标准命名空间// Writer函数,向管道写数据
void Writer(int wfd)
{string s = "i am father"; // 定义字符串spid_t self = getpid(); // 获取当前进程IDint number = 0; // 定义一个计数器number,初始值为0char buffer[NUM]; // 定义缓冲区bufferwhile (true) // 无限循环{sleep(1); // 休眠1秒buffer[0] = 0; // 将缓冲区第一个位置置为0snprintf(buffer, sizeof(buffer), "%s-%d-%d", s.c_str(), self, number++); // 格式化字符串并存入缓冲区cout << buffer << endl; // 输出缓冲区内容write(wfd, buffer, strlen(buffer)); // 将缓冲区内容写入管道if(number>=5) // 如果计数器number大于等于5,退出循环break;}
}// Reader函数,从管道读数据
void Reader(int rfd)
{char buffer[NUM]; // 定义缓冲区bufferwhile(true) // 无限循环{buffer[0] = 0; // 将缓冲区第一个位置置为0ssize_t n = read(rfd, buffer, sizeof(buffer)); // 从管道读取数据存入缓冲区if(n > 0) // 如果读取到的数据长度大于0{buffer[n] = 0; // 将缓冲区第n个位置置为0,表示字符串结束cout << "child get a message[" << getpid() << "]# " << buffer << endl; // 输出读取到的内容}else if(n == 0) // 如果读取到的数据长度为0,表示管道已关闭{printf("child read file done!\n"); // 输出读取完成信息break; // 退出循环}else break; // 如果读取错误,退出循环}
}int main()
{int pipefd[N] = {0}; // 定义一个数组pipefd,用于存放管道的文件描述符int n = pipe(pipefd); // 创建管道,返回值n小于0表示创建失败if (n < 0)return 1; // 如果创建管道失败,返回1pid_t id = fork(); // 创建子进程,返回值id小于0表示创建失败if (id < 0)return 2; // 如果创建子进程失败,返回2if (id == 0){// 子进程代码close(pipefd[1]); // 关闭管道的写端// IPC代码Reader(pipefd[0]); // 调用Reader函数,从管道读取数据close(pipefd[0]); // 关闭管道的读端exit(0); // 退出子进程}// 父进程代码close(pipefd[0]); // 关闭管道的读端// IPC代码Writer(pipefd[1]); // 调用Writer函数,向管道写入数据close(pipefd[1]); // 关闭管道的写端pid_t rid = waitpid(id, nullptr, 0); // 等待子进程结束if(rid < 0) return 3; // 如果等待失败,返回3sleep(5); // 休眠5秒return 0; // 返回0,表示程序成功结束
}
运行起来后我们可以观察到,父进程每隔一秒格式化字符串输入缓冲区,并打印缓冲区内容,接着写进管道,这时子进程就能读到管道的数据,并将内容打印出来,父进程写五次后退出,并且关闭了写端,这是读端读到结尾后退出进程后被父进程等待回收。
我们再来验证些特殊情况:
void Reader(int rfd)
{char buffer[NUM]; // 定义缓冲区bufferint _count =0;while(true) // 无限循环{buffer[0] = 0; // 将缓冲区第一个位置置为0ssize_t n = read(rfd, buffer, sizeof(buffer)); // 从管道读取数据存入缓冲区if(n > 0) // 如果读取到的数据长度大于0{buffer[n] = 0; // 将缓冲区第n个位置置为0,表示字符串结束cout << "child get a message[" << getpid() << "]# " << buffer << endl; // 输出读取到的内容}else if(n == 0) // 如果读取到的数据长度为0,表示管道已关闭{printf("child read file done!\n"); // 输出读取完成信息break; // 退出循环}else break; // 如果读取错误,退出循环_count++;if(_count>=2)break;}
}
让子进程只读两次后就退出,那这时候写端还是正常写的,那我们运行会出现什么情况呢?

可以看到读端关闭后,操作系统会杀掉正在运行的写端(通过信号杀掉)。
还有其他的情况:
1.读写端正常,管道被写满,写端就会阻塞等待。
2.读写端正常,管道为口,读端就会阻塞等待。
由上述情况我们可以总结:
- 进程间通信的原理是让不同的进程看到同一份资源
- 匿名管道需要在创建子进程之前创建,因为只有这样才能复制到管道的操作句柄,与具有亲缘关系的进程实现访问同一个管道通信
- 匿名管道只能单向通信
- 父子进程会进程协同,同步与互斥,为了保护数据安全
- 管道基于文件,文件的生命周期随进程
- 管道面向字节流
2.命名管道
命名管道(FIFO)是一种特殊的文件类型,用于在两个不相关的进程之间进行单向或双向通信。与匿名管道不同,命名管道存在于文件系统中,用路径和文件名标识唯一,可以被不相关的进程通过路径名来打开和使用。命名管道具有持久性,可以在创建之后长期存在,直到显式删除。

创建命名管道的函数mkfifo:
- pathname:命名管道的路径名,即文件系统中创建的命名管道的路径
- mode:设置管道的权限,与 open 或 chmod 的权限位相同,如 0666 表示读写权限
- 成功时返回 0
- 失败时返回 -1,并设置 errno 来指示错误类型
下面我们就利用命名管道实现两个无关系进程间的通信:
comm.hpp:
#pragma once#include <iostream>
#include <string>
#include <cerrno>
#include <cstring>
#include <cstdlib>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>#define FIFO_FILE "./myfifo"class Init
{
public:Init(){// 创建管道int n = mkfifo(FIFO_FILE, 0664);if (n == -1){perror("mkfifo");exit(1);}}~Init(){int m = unlink(FIFO_FILE);if (m == -1){perror("unlink");exit(2);}}
};管理管道文件server.cc:
#include "comm.hpp"using namespace std;// 管理管道文件
int main()
{Init init;// 打开管道int fd = open(FIFO_FILE, O_RDONLY); // 等待写入方打开之后,自己才会打开文件,向后执行, open 阻塞了!if (fd < 0){exit(3);}// 开始通信while (true){char buffer[1024] = {0};int x = read(fd, buffer, sizeof(buffer));if (x > 0){buffer[x] = 0;cout << "client say# " << buffer << endl;}elsebreak; }close(fd);return 0;
}
通信进程client.cc:
#include <iostream>
#include "comm.hpp"using namespace std;int main()
{int fd = open(FIFO_FILE, O_WRONLY);if(fd < 0){perror("open");exit(FIFO_OPEN_ERR);}cout << "client open file done" << endl;string line;while(true){cout << "Please Enter@ ";getline(cin, line);write(fd, line.c_str(), line.size());}close(fd);return 0;
}当进程跑起来后,就能在自己指定的路径下看到p开头的命名管道文件:

两个进程都跑起来后,在client输入,就能在server上看到读取到信息了:

3.日志
在Linux下开发应用程序时,加入日志记录是一种非常好的编程习惯。日志记录不仅有助于调试和维护,还能提供运行时的监控和错误追踪。其中日志主要包括日志等级,内容,文件的名称等。我们可以在上述命名管道的文件下加上一个日志的小模组:
#pragma once#include <iostream>
#include <time.h>
#include <stdarg.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>#define SIZE 1024// 日志级别定义
#define Info 0
#define Debug 1
#define Warning 2
#define Error 3
#define Fatal 4// 日志输出方式定义
#define Screen 1
#define Onefile 2
#define Classfile 3#define LogFile "log.txt" // 日志文件默认名称// 日志类定义
class Log
{
public:Log(){printMethod = Screen; // 默认输出方式为屏幕输出path = "./log/"; // 日志文件默认路径}// 设置日志输出方式void Enable(int method){printMethod = method;}// 将日志级别转换为字符串std::string levelToString(int level){switch (level){case Info:return "Info";case Debug:return "Debug";case Warning:return "Warning";case Error:return "Error";case Fatal:return "Fatal";default:return "None";}}// 打印日志函数,根据打印方式调用相应的打印方法void printLog(int level, const std::string &logtxt){switch (printMethod){case Screen:std::cout << logtxt << std::endl; // 屏幕输出break;case Onefile:printOneFile(LogFile, logtxt); // 输出到一个文件break;case Classfile:printClassFile(level, logtxt); // 输出到不同级别的文件break;default:break;}}// 输出日志到单一文件void printOneFile(const std::string &logname, const std::string &logtxt){std::string _logname = path + logname; // 完整日志文件路径int fd = open(_logname.c_str(), O_WRONLY | O_CREAT | O_APPEND, 0666); // 打开日志文件if (fd < 0)return;write(fd, logtxt.c_str(), logtxt.size()); // 写入日志close(fd); // 关闭文件}// 输出日志到不同级别的文件void printClassFile(int level, const std::string &logtxt){std::string filename = LogFile;filename += ".";filename += levelToString(level); // 构建不同级别的文件名printOneFile(filename, logtxt); // 输出到不同级别的文件}~Log(){}// 重载()操作符,方便日志记录void operator()(int level, const char *format接着就可以打印出日志信息了:

三.共享内存
在 Linux 系统中,共享内存是实现进程间通信最高效机制。通过共享内存,不同进程可以直接访问同一块内存区域,从而实现数据的快速交换。介绍共享内存的基本概念、优点、以及在 C++ 程序中的实现方法。

共享内存的原理就是在物理内存中申请一块空间,接着进程将其挂接到自己的进程地址空间内,然后多个进程挂接到自己的进程地址空间内,进程间就能进行通信了
我们先来了解
创建共享内存的函数:

- key是一个数字,可以在内核中唯一标识,能够让不同进程进行唯一性标识
- size代表创建共享内存的字节
- shmflg标识创建的权限:常用的有两种IPC_CREAT(单独)如果申请的共享内存不存在就创建,存在就获取并返回。 IPC_CREAT|IPC_EXCL,如果申请的内存不存在就创建,存在就出错返回(能确保我们申请一块新的共享内存)

函数ftok用来生成一个唯一的key值,接着用来创建共享内存;
- pathname: 一个指向现有文件的路径名。这个文件必须存在,并且调用进程必须对它有读取权限。这个参数用于生成键值的一部分.
- proj_id: 一个项目标识符,通常是一个字符类型的整数(例如,‘A’ 或 65),用于生成键值的另一部分。proj_id 是一个 8 位的值,所以它的有效范围是 0 到 255
ipcs -m 查看共享内存,ipcrm -m shmid 删除共享内存
共享内存的生命周期是随内核的,用户不主动关闭,他就会一直存在

shmat可将共享内存挂接到进程的地址空间内。

shmat去掉挂接。

参数说明:
- shmid: 共享内存段的标识符,这是由 shmget 函数返回的共享内存段 ID
- cmd: 控制命令,指定对共享内存段执行的操作。
- buf: 指向 shmid_ds 结构的指针,用于存储或设置共享内存段的属性。如果不需要,可以传递 nullptr
控制命令说明:
- IPC_STAT: 获取共享内存段的当前状态信息,并将其存储在 buf 指向的 shmid_ds 结构中。
- IPC_SET: 设置共享内存段的属性,使用 buf 指向的 shmid_ds 结构中的值。
- IPC_RMID: 标记共享内存段以便将其删除。共享内存段在没有进程附加时会被实际删除
- IPC_INFO: 获取系统范围内的共享内存信息(仅 Linux 提供)。
- SHM_INFO: 获取系统范围内的共享内存信息(仅 Linux 提供)。
- SHM_STAT: 获取共享内存段的状态信息(仅 Linux 提供)。
以下是一个共享内存代码的演示(添加日志模组):
comm.hpp
#ifndef __COMM_HPP__
#define __COMM_HPP__#include <iostream>
#include <string>
#include <cstdlib>
#include <cstring>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/types.h>
#include <sys/types.h>
#include <sys/stat.h>#include "log.hpp"using namespace std;Log log;const int size = 4096;
const string pathname="./";
const int proj_id = 1;key_t GetKey()
{key_t k = ftok(pathname.c_str(), proj_id);if(k < 0){log(Fatal, "ftok error: %s", strerror(errno));exit(1);}log(Info, "ftok success, key is : 0x%x", k);return k;
}int GetShareMemHelper(int flag)
{key_t k = GetKey();int shmid = shmget(k, size, flag);if(shmid < 0){log(Fatal, "create share memory error: %s", strerror(errno));exit(2);}log(Info, "create share memory success, shmid: %d", shmid);return shmid;
}int CreateShm()
{return GetShareMemHelper(IPC_CREAT | IPC_EXCL | 0666);
}int GetShm()
{return GetShareMemHelper(IPC_CREAT);
}#define FIFO_FILE "./myfifo"
#define MODE 0664enum
{FIFO_CREATE_ERR = 1,FIFO_DELETE_ERR,FIFO_OPEN_ERR
};class Init
{
public:Init(){// 创建管道int n = mkfifo(FIFO_FILE, MODE);if (n == -1){perror("mkfifo");exit(FIFO_CREATE_ERR);}}~Init(){int m = unlink(FIFO_FILE);if (m == -1){perror("unlink");exit(FIFO_DELETE_ERR);}}
};#endifprocessa/processb.cc:
#include "comm.hpp" // 包含自定义的头文件,通常包含共享内存和日志相关的声明extern Log log; // 声明一个外部的日志对象int main()
{Init init; // 初始化对象,用于初始化环境(具体实现细节在comm.hpp中)int shmid = CreateShm(); // 创建共享内存,并返回共享内存段标识符char *shmaddr = (char*)shmat(shmid, nullptr, 0); // 将共享内存段附加到进程的地址空间,并返回指向共享内存的指针// IPC(进程间通信)代码在这里// 一旦有人把数据写入到共享内存中,我们能立刻看到数据,不需要经过系统调用,直接访问共享内存int fd = open(FIFO_FILE, O_RDONLY); // 以只读方式打开命名管道// 等待写入方打开管道后,当前进程才会继续执行,open函数会阻塞直到管道另一端被打开if (fd < 0){log(Fatal, "error string: %s, error code: %d", strerror(errno), errno); // 记录打开管道失败的日志exit(FIFO_OPEN_ERR); // 退出程序,返回管道打开错误码}struct shmid_ds shmds; // 定义共享内存数据结构,用于存储共享内存段的信息while(true){char c; // 用于读取管道中的数据ssize_t s = read(fd, &c, 1); // 从管道中读取一个字节的数据if(s == 0) break; // 读取到文件末尾,退出循环else if(s < 0) break; // 读取出错,退出循环cout << "client say@ " << shmaddr << endl; // 直接从共享内存中读取数据并输出sleep(1); // 睡眠1秒shmctl(shmid, IPC_STAT, &shmds); // 获取共享内存段的状态,并存储在shmds结构中cout << "shm size: " << shmds.shm_segsz << endl; // 输出共享内存段的大小cout << "shm nattch: " << shmds.shm_nattch << endl; // 输出当前附加到共享内存段的进程数printf("shm key: 0x%x\n", shmds.shm_perm.__key); // 输出共享内存段的键值cout << "shm mode: " << shmds.shm_perm.mode << endl; // 输出共享内存段的访问模式}shmdt(shmaddr); // 将共享内存段从当前进程分离shmctl(shmid, IPC_RMID, nullptr); // 标记共享内存段为删除close(fd); // 关闭管道文件描述符return 0; // 正常退出程序
}#include "comm.hpp"int main()
{int shmid = GetShm();char *shmaddr = (char*)shmat(shmid, nullptr, 0);int fd = open(FIFO_FILE, O_WRONLY); // 等待写入方打开之后,自己才会打开文件,向后执行, open 阻塞了!if (fd < 0){log(Fatal, "error string: %s, error code: %d", strerror(errno), errno);exit(FIFO_OPEN_ERR);}// 一旦有了共享内存,挂接到自己的地址空间中,你直接把他当成你的内存空间来用即可!// 不需要调用系统调用// ipc codewhile(true){cout << "Please Enter@ ";fgets(shmaddr, 4096, stdin);write(fd, "c", 1); // 通知对方}shmdt(shmaddr);close(fd);return 0;
}
log.hpp(日志模组):
#pragma once#include <iostream>
#include <time.h>
#include <stdarg.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>#define SIZE 1024#define Info 0
#define Debug 1
#define Warning 2
#define Error 3
#define Fatal 4#define Screen 1
#define Onefile 2
#define Classfile 3#define LogFile "log.txt"class Log
{
public:Log(){printMethod = Screen;path = "./";}void Enable(int method){printMethod = method;}std::string levelToString(int level){switch (level){case Info:return "Info";case Debug:return "Debug";case Warning:return "Warning";case Error:return "Error";case Fatal:return "Fatal";default:return "None";}}void printLog(int level, const std::string &logtxt){switch (printMethod){case Screen:std::cout << logtxt << std::endl;break;case Onefile:printOneFile(LogFile, logtxt);break;case Classfile:printClassFile(level, logtxt);break;default:break;}}void printOneFile(const std::string &logname, const std::string &logtxt){std::string _logname = path + logname;int fd = open(_logname.c_str(), O_WRONLY | O_CREAT | O_APPEND, 0666); // "log.txt"if (fd < 0)return;write(fd, logtxt.c_str(), logtxt.size());close(fd);}void printClassFile(int level, const std::string &logtxt){std::string filename = LogFile;filename += ".";filename += levelToString(level); // "log.txt.Debug/Warning/Fatal"printOneFile(filename, logtxt);}~Log(){}void operator()(int level, const char *format, ...){time_t t = time(nullptr);struct tm *ctime = localtime(&t);char leftbuffer[SIZE];snprintf(leftbuffer, sizeof(leftbuffer), "[%s][%d-%d-%d %d:%d:%d]", levelToString(level).c_str(),ctime->tm_year + 1900, ctime->tm_mon + 1, ctime->tm_mday,ctime->tm_hour, ctime->tm_min, ctime->tm_sec);va_list s;va_start(s, format);char rightbuffer[SIZE];vsnprintf(rightbuffer, sizeof(rightbuffer), format, s);va_end(s);// 格式:默认部分+自定义部分char logtxt[SIZE * 2];snprintf(logtxt, sizeof(logtxt), "%s %s\n", leftbuffer, rightbuffer);// printf("%s", logtxt); // 暂时打印printLog(level, logtxt);}private:int printMethod;std::string path;
};补充知识:
- 共享内存没有同步机制,导致多个进程对共享内存进行读写操作,可能导致数据的不一致性。例如,进程 A 写入数据 “Hello”,进程 B 同时写入数据 “World”,最终共享内存中的内容可能是 “Horld” 或 “Wello”。竞态条件是指多个进程同时访问共享资源,而最终结果依赖于访问的顺序和时机。共享内存没有同步机制时,进程的执行顺序和速度无法预测,可能导致竞态条件。例如,两个进程分别增加和减少共享内存中的计数器,如果没有同步机制,计数器的最终值可能不正确
- 共享内存的大小建议时4kb(常见块大小是4kb)的整数倍,如若不是实际底层会向上取整整数倍,但是实际你申请多少给多少
- 共享内存和其他的通信机制相比拷贝比较少,所以他是最快的进程间通信的方式
三.System V 标准
1.System V简介
System V 标准是 Unix 系统中的一个重要规范,提供了一系列用于进程间通信(IPC)和同步的机制。这些机制包括消息队列、信号量、共享内存和文件锁。
2.IPC在内核的数据结构设计
首先IPC在内核的数据结构设计和多态相似,在操作系统中,所有的IPC资源都是整合进操作系统的IPC模块中的!
每个通信机制结构体都有struct ipc_pem:

类似与上图的结构体,每个通信机制的struct ipc_prem存在OS中的数组struct ipc_perm *array[];中,此数组下标就是XXXid,eg:shmid、msqid,而且struct ipc_prem和通信机制结构体的关系是基类与子类的关系。
3.信号量
信号量是操作系统中一种重要的同步工具,用于控制多个进程或线程对共享资源的访问。在 Linux 系统中,信号量不仅用于进程间的同步和互斥,还能有效地协调并发操作。我们了解下其原理即可:信号量的本质是进程间通信的一种,是一个计数器,用来描述临界资源的数量多少:
如果A、B进程能同时看到一份资源,如果不加保护,会导致数据不一致的问题。我们将共享的资源并且任何时刻只允许一个执行流访问的资源叫做临界资源:我们把访问临界资源的部分代码叫做临界区。
所以我们要访问临界资源,就先要申请信号量计数器资源(计数器信号量是共享资源),PV操作即对信号量的申请释放操作时原子的。执行流申请资源,必须先申请信号资源,得到信号量之后,才能访问临界资源!!信号量值1,0两态的,二元信号量,就是互斥功能申请信号量的本质:是对临界资源的预订机制!!!
相关文章:
Linux IPC解析:匿名命名管道与共享内存
目录 一.IPC机制介绍二.匿名与命名管道1.匿名管道2.命名管道3.日志 三.共享内存三.System V 标准1.System V简介2.IPC在内核的数据结构设计3.信号量 一.IPC机制介绍 IPC(Inter-Process Communication,进程间通信)是计算机系统中不同进程之间交…...

Codeforces Round 964 (Div. 4) A~G
封面原图 画师ideolo A - AB Again? 题意 给你一个两位数,把他的个位和十位加起来 代码 #include <bits/stdc.h> using namespace std; typedef long long ll; typedef double db; typedef pair<int,int> pii; typedef pair<ll,ll> pll;voi…...

单体应用提高性能和处理高并发-使用缓存
要在单体应用中实现高并发,并利用缓存技术来提高性能,需要深入了解缓存的应用场景、选择合适的缓存工具,以及在具体代码中实现缓存策略。以下是详细说明如何在单体应用中使用缓存来处理高并发的内容,包括常见的缓存框架和实际的代…...

ollama教程——使用LangChain调用Ollama接口实现ReAct
ollama入门系列教程简介与目录 相关文章: Ollama教程——入门:开启本地大型语言模型开发之旅Ollama教程——模型:如何将模型高效导入到Ollama框架Ollama教程——兼容OpenAI API:高效利用兼容OpenAI的API进行AI项目开发Ollama教程——使用LangChain:Ollama与LangChain的强强…...

【Bug分析】Keil报错:error: #18:expected a “)“问题解决
【Bug分析】Keil报错:error: #18:expected a “)”问题解决 前言bug查找bug解决方法小结 前言 keil编译时出现一个问题,缺少一个右括号。然后仔细查看代码,并没有括号缺失。 如下,代码括号正常。 bug查找 站内文章…...

MAC上设置快捷打开终端以及如何运用剪切快捷键
在Mac上设置一个快捷键,在当前文件夹中打开终端,你可以使用Automator创建一个服务,然后将其分配给一个快捷键。以下是步骤: 1. 创建Automator服务 打开 Automator(你可以在应用程序文件夹中找到它,或使用…...

linux docker安装 gitlab后忘记root密码如何找回
1. docker ps - a 查看当前gitlab 当前的id2. docker exec -it gitlab /bin/bash 进入docker git 容器中【gitlab 注意可以上图中的name,也可以是id都可以的】,如下图3.gitlab-rails console -e production 输入该指令,启动Ruby on Rails控制台&…...

C语言典型例题27
《C程序设计教程(第四版)——谭浩强》 习题2.4 用下面的scanf函数输入数据 使a3,b7,x8.5,y71.8,c1A,c2a。问在键盘上怎么输入 代码 //《C程序设计教程(第四版)——谭浩强》 //习题2.4 用下面的scanf函数输入数据,使…...

clion开发stm32f4系列(一)————移植rt-thread os系统
前言 本次使用的rt-thread的版本为5.0.2基于rt-thread sudio生成的源码进行拷贝和修改工程基于上次创建工程的项目进行修改。本次工程只是用了serial和pin组件,其他后面用到再进行添加 拷贝rt-thread源码库 通过CMakeLists来进行管理 顶级(rt-thread目录) cmake_minimum_req…...

计算机网络(网络层)
网络层概述 网络层是干什么的? 网络层的主要任务是实现不同异构网络互连,进而实现数据包在各网络之间的传输相比于数据链路层的以太网通信,网络层则是将一个个数据链路层连接的以太网通过路由器连接起来。从而实现不同数据链路层的互联。 这…...

Python3 第六十六课 -- CGI编程
目录 一. 什么是 CGI 二. 网页浏览 三. CGI 架构图 四. Web服务器支持及配置 五. 第一个CGI程序 5.1. HTTP 头部 5.2. CGI 环境变量 六. GET和POST方法 6.1. 使用GET方法传输数据 6.1.1. 简单的url实例:GET方法 6.1.2. 简单的表单实例:GET方法…...

【Unity23种设计模式】之状态模式
首先创建一个项目 打开项目后复制至3个场景 命名为 创建一个空物体 命名为GameLoop 创建一个脚本GameLoop.cs 编写代码如下 将代码挂载至空物体GameLoop 将三个场景拖拽至Scenes In Build 分析下状态模式的类图 我们创新类图中的代码 编写ISceneState.cs 编写三个状态子类继承构…...

二叉树刷题,bfs刷题
有些题目,你按照拍脑袋的方式去做,可能发现需要在递归代码中调用其他递归函数计算字数的信息。一般来说,出现这种情况时你可以考虑用后序遍历的思维方式来优化算法,利用后序遍历传递子树的信息,避免过高的时间复杂度。…...

为什么要用分布式锁
单应用中,如果要确保多线程修改同一个资源的安全性 加synchronized就可以了 但是性能不高 而mybatis-plus的乐观锁就可以很好的解决这类问题 但是这样的锁机制,只在单应用中有效 试想,在分布式下,有没有可能出现多个应用中的线程同时去修改同一个数据资源的并发问题 例如A …...
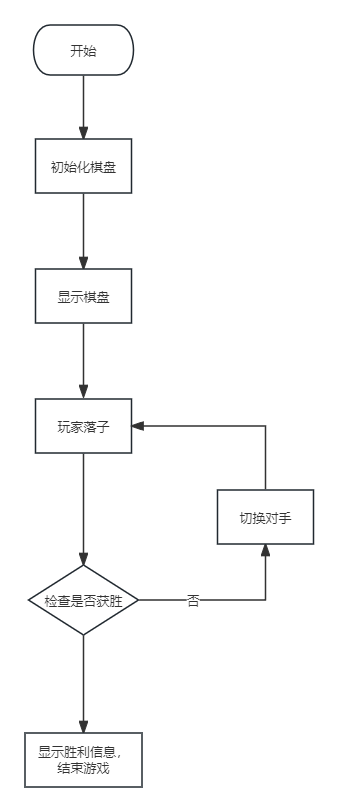
python游戏开发之五子棋游戏制作
五子棋是一种源自中国的传统棋类游戏,起源可以追溯到古代。它是一种两人对弈的游戏,使用棋盘和棋子进行。棋盘通常是一个 1515 的网格,棋子分为黑白两色,双方轮流在棋盘上落子。游戏的目标是通过在棋盘上落子,使自己的…...

文件上传绕过最新版安全狗
本文来源无问社区,更多实战内容,渗透思路可前往查看http://www.wwlib.cn/index.php/artread/artid/9960.html http分块传输绕过 http分块传输⼀直是⼀个很经典的绕过⽅式,只是在近⼏年分块传输⼀直被卡的很死,很多waf都开始加 …...

常用API_2:应用程序编程接口:ArrayList
文章目录 ArrayList常用方法 案例 :上菜 ArrayList 常用方法 来自黑马程序员学习视频 案例 :上菜 待完善...

【Linux操作系统】进程的基本概念(PCB对象)详解
目录 一、进程的基本概念二、进程的描述组织(PCB对象)1.PCB的基本概念2.为什么要有PCB对象(操作系统对进程的组织管理)3.PCB对象的内部属性(tast_struct结构体) 三、查看进程1.ps指令2.top指令3.通过 /proc…...

曙光宁畅中科可控所有服务器机型出厂默认IPMI用户密码
机型 默认IP 用户名/密码 通用 SG机型 DHCP admin/admin 通用 KK机型 DHCP admin/admin 通用 NC 机型 DHCP Admin/Admin5000 I420-G10、I620-G15、I650-G15、I840-GS、I840-G10、I840-G25、I980-G10、A420r-G、A620r-G、A840-G10、TC4600刀片、TC46…...

mysql查线上数据注意数据库的隔离级别
数据库的隔离级别定义了一个事务可能对其他并发事务的可见性,以及它们可能对数据库的影响。隔离级别的选择影响着并发性能和数据的一致性,不同的隔离级别能够防止不同程度的并发问题,如脏读(Dirty Reads)、不可重复读&…...

突破学术资源壁垒:Unpaywall扩展全方位应用指南
突破学术资源壁垒:Unpaywall扩展全方位应用指南 【免费下载链接】unpaywall-extension Firefox/Chrome extension that gives you a link to a free PDF when you view scholarly articles 项目地址: https://gitcode.com/gh_mirrors/un/unpaywall-extension …...

终极指南:如何用Dism++轻松优化Windows系统并释放30GB空间
终极指南:如何用Dism轻松优化Windows系统并释放30GB空间 【免费下载链接】Dism-Multi-language Dism Multi-language Support & BUG Report 项目地址: https://gitcode.com/gh_mirrors/di/Dism-Multi-language Windows系统用久了总是卡顿?磁盘…...

MBR扩展分区的结构分析
由于MBR仅仅为分区表保留了64字节的存储空间,而每个分区的参数占据16字节,所以MBR扇区中总计可以存储4个分区表表项的数据。对于实际情况,4个分区不能满足需求,当超过四个分区时,系统会自动将第四个分区变成扩展分区&a…...

SDMatte多GPU并行推理配置:提升企业级批量处理吞吐量
SDMatte多GPU并行推理配置:提升企业级批量处理吞吐量 1. 为什么需要多GPU并行推理 当企业需要处理大批量图片时,单张GPU往往难以满足需求。想象一下,你有一家电商公司,每天需要处理上万张商品图片的背景替换。如果只用一张GPU&a…...

如何用OpCore-Simplify实现OpenCore EFI自动化配置:黑苹果配置终极指南
如何用OpCore-Simplify实现OpenCore EFI自动化配置:黑苹果配置终极指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的黑苹果…...

Ryujinx终极指南:免费开源Switch模拟器从零到精通的完整教程
Ryujinx终极指南:免费开源Switch模拟器从零到精通的完整教程 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 想在电脑上畅玩《塞尔达传说:王国之泪》《集合啦&a…...

黑苹果EFI配置革命:3大痛点与OpCore Simplify的智能解决方案
黑苹果EFI配置革命:3大痛点与OpCore Simplify的智能解决方案 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 开篇直击:黑苹果配…...

二次型标准化实战:五种方法在机器学习特征降维中的应用
1. 二次型标准化与特征降维的奇妙关联 第一次听说要把二次型标准化方法用在机器学习特征降维时,我的反应和大多数工程师一样:"这俩八竿子打不着的概念能扯上关系?"直到在电商用户行为分析项目中遇到高维数据灾难,才真正…...

批量设计元素替换:提升设计师效率的智能工作流解决方案
批量设计元素替换:提升设计师效率的智能工作流解决方案 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 在现代UI设计和品牌视觉开发流程中,设计师经常面临需…...

贵州公共活动策划公司名录
2026年想在贵州办一场出圈的公共活动?从企业年会到文化展览,从体育赛事到艺术节庆,选对策划公司是关键!但贵州公共活动策划公司鱼龙混杂,如何避开“低价陷阱”“执行脱节”等坑?本文结合本地市场真实案例&a…...