Spark - 继承 FileOutputFormat 实现向 HDFS 地址追加文件
目录
一.引言
二.源码浅析
1.RDD.saveAsTextFile
2.TextOutputFormat
3.FileOutputFormat
三.源码修改
1.修改文件生成逻辑 - getRecordWriter
2.允许目录存在 - checkoutputSpecs
3.全部代码 - TextOutputFormatV2
四.追加存储代码实战
五.总结
一.引言
Output directory file XXX already exists 目标目录已经存在,这个报错写 Spark 的同学都不会陌生,它不允许我们在同一个目录持续增加文件存储。在使用 Flink 文件流场景中,我们有向 HDFS 目录追加文件的需求,所以下面我们尝试继承 FileOutputFormat 实现自定义文件追加。

二.源码浅析
自定义实现之前,我们需要明确一下追加文件的两个主要问题:
- 允许目录存在
即避免 Output directory file XXX already exists 的报错
- 避免 File 重复
由于是追加文件,这里我们要避免文件名相同导致追加失败
1.RDD.saveAsTextFile
这个是我们日常使用的文本落地 API:
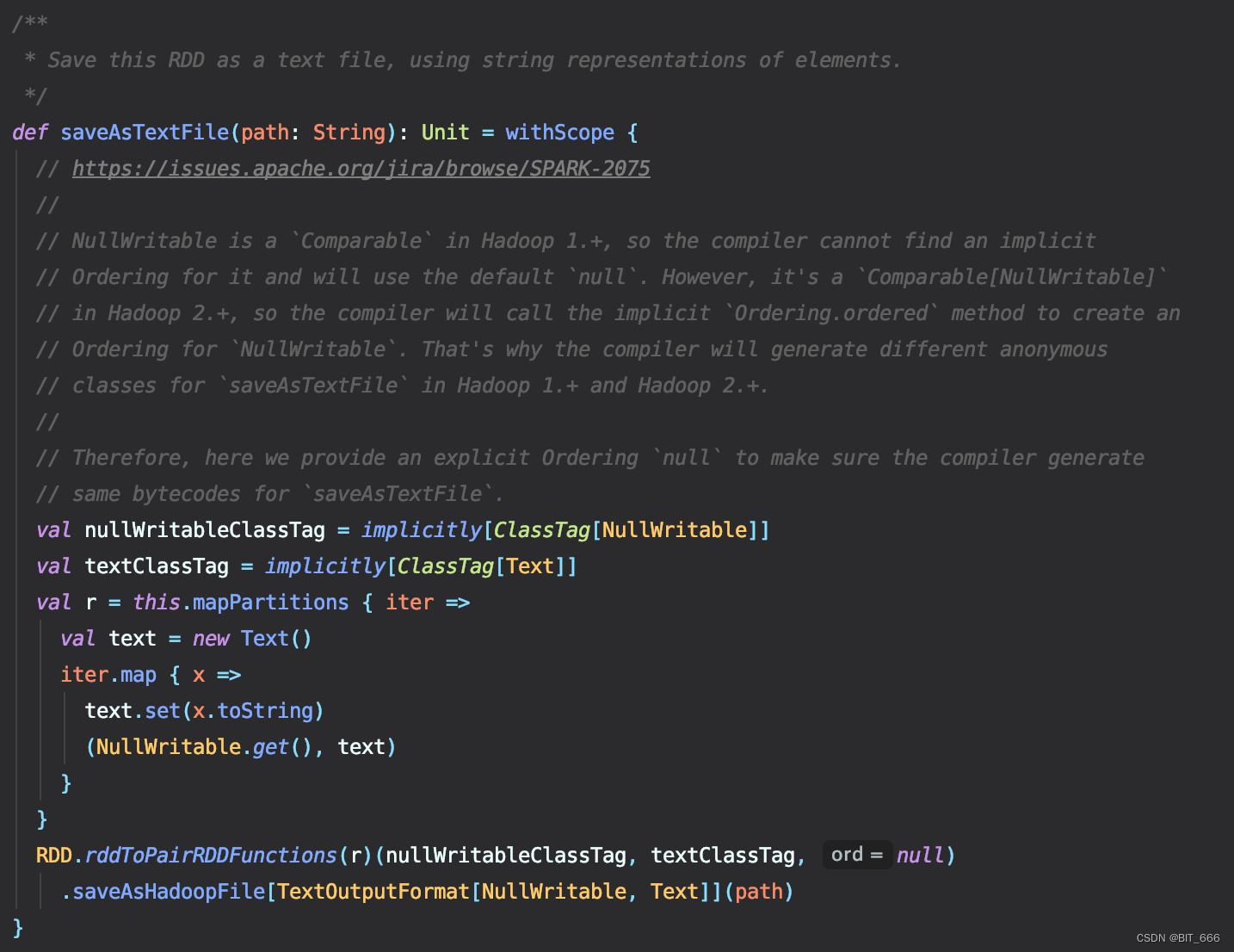
这里将原始的 RDD[String] 转化为 (NullWritable.get(), text) 的 pairRDD 并调用后续的 saveAsHadoopFile 并传入 TextOutputFormat:
- NullWritable
在Hadoop1.+中是 "Comparable",因此编译器无法找到隐式为其排序,并将使用默认的 "null"。然而,它是一个 `Comparable[NullWritable]` 在 Hadoop2.+ 中,编译器将调用隐式 "Ordering.ordered” 方法来创建为 "NullWritable" 排序。这就是为什么编译器会生成不同的匿名Hadoop1.+和Hadoop2.+中“saveAsTextFile”的类。因此,在这里我们提供了一个显式排序“null”,以确保编译器生成 "saveAsTextFile" 的字节码相同。
这里翻译自官方 API,简言之,我们后续自定义 OutputFormat 时需要将 RDD[String] 转换为 PairRDD 并将 key 置为 NullWritable,否则这里无法调用 saveAsHadoopFile:
2.TextOutputFormat
前者继承了后者,我们先看下前者复写了哪些函数:
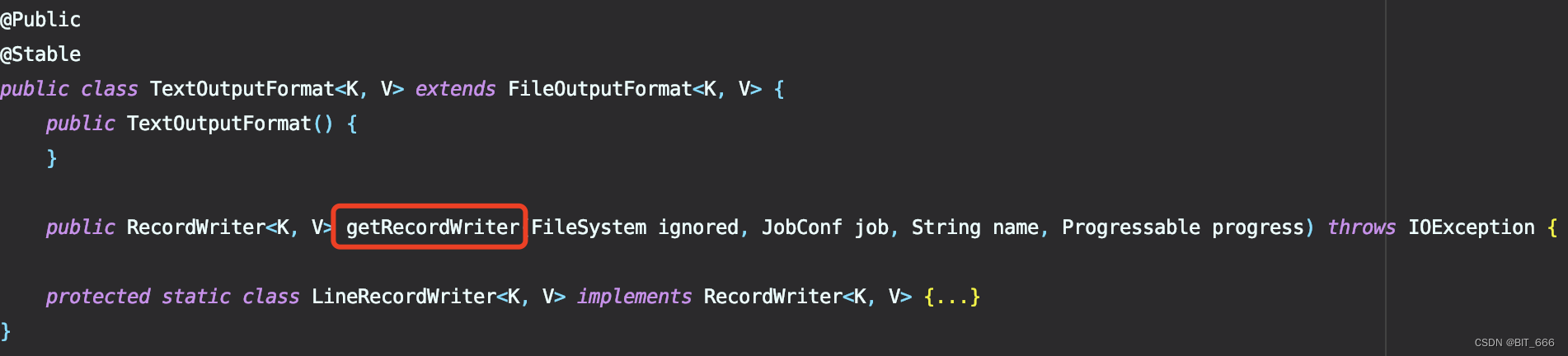
非常简洁,大部分方法都使用父类的实现,这里 getRecordWriter 的具体实现对应我们上面提到的第二个问题即避免文件重复,因为其负责根据 name 轮训生成落地的 Path 地址,我们修改这个函数即可避免追加时文件重复。
3.FileOutputFormat
TextOutputFormat Extends FileOutputFormat,上面 TextOutputFormat 只实现了 Path 相关的工作,所以需要继续到父类 FileOutputFormat 寻找抛出异常的语句:
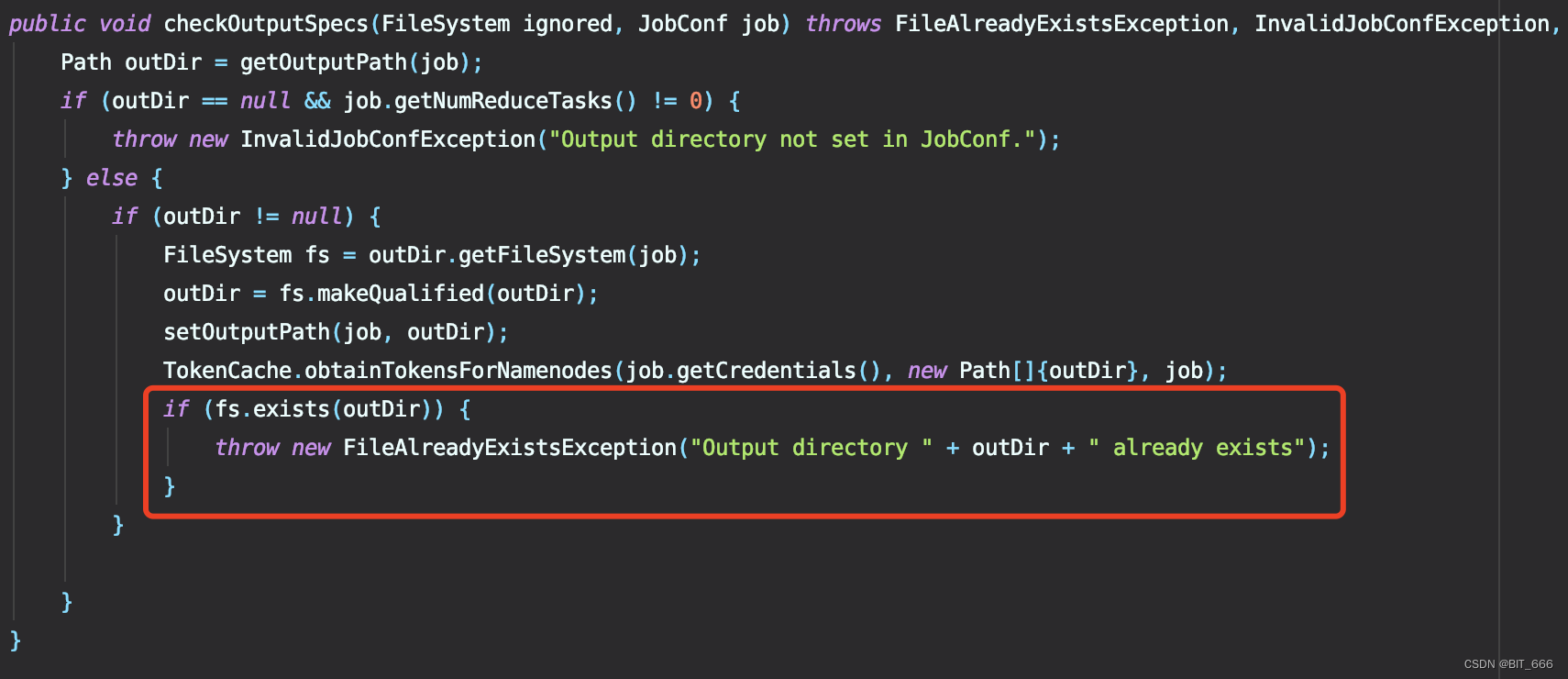
在文件中搜索 already exists 即可定位到当前函数,是不是很熟悉,因此针对第一个问题避免文件的报错就要修改这里了,最简单的我们把这三行注释掉即可。
三.源码修改
经过上面的源码三部曲,我们如何修改 TextOutputFormat 思路也很清晰了,修改文件生成逻辑、取消抛出异常即可,下面看一下代码实现:
1.修改文件生成逻辑 - getRecordWriter
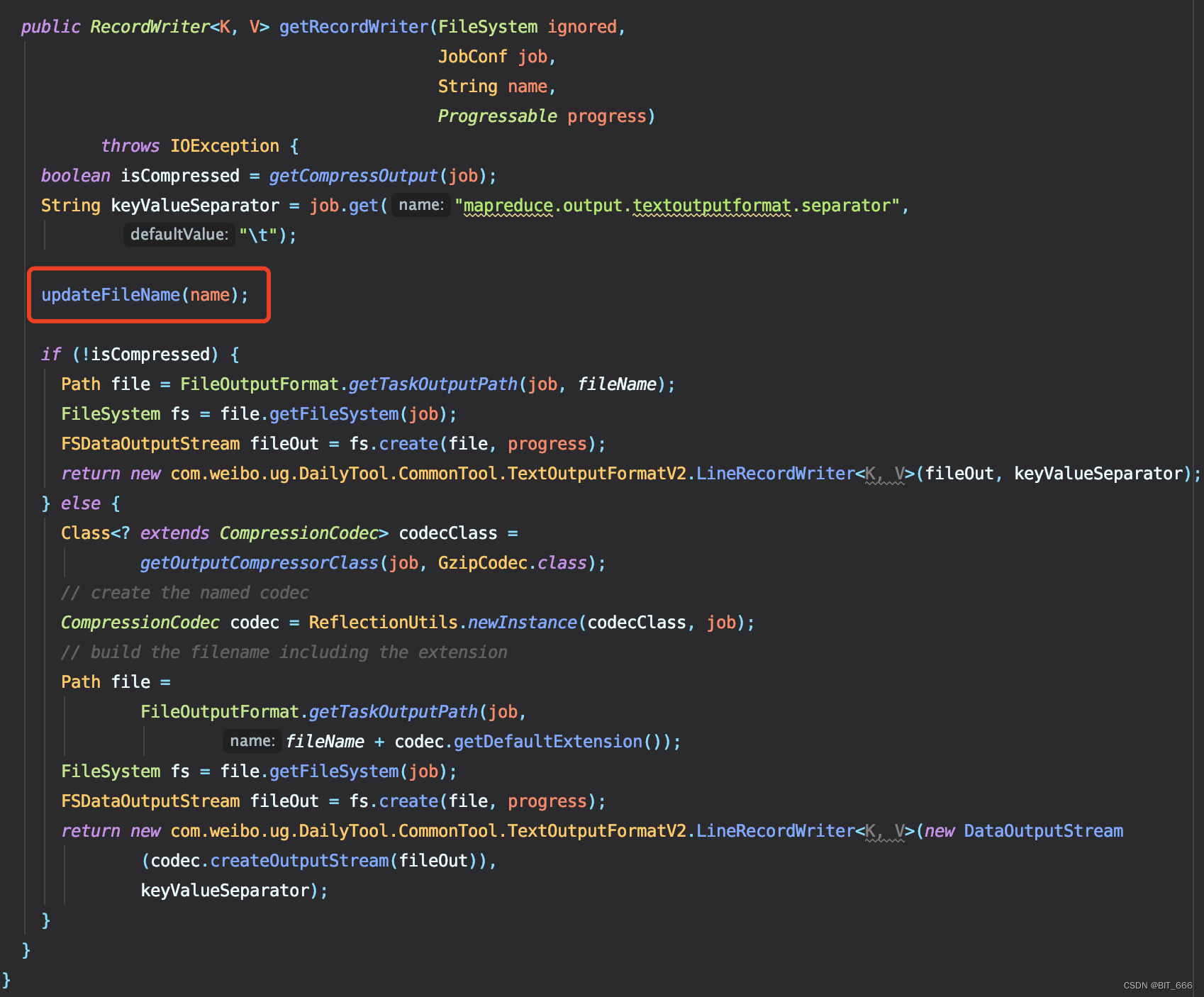
这里我们在源码中增加了 updateFileName 函数,该函数由用户自己定义输出文件名,常规的我们可以按照 part-00000、part-00001 的顺序继续存储下去,当然如果为了区分追加文件的添加时间与类型,我们也可以给其打上时间戳和自定义标记,都不想用的话也可以直接用 UUID 代替:
import java.util.UUIDUUID.randomUUID().toString
下面看一下 updateFileName 的实现:
这里初始化变量 fileName 为 "",更新时对其加锁并基于当前 name 进行判断,如果当前 fileName 为 "",则代表是第一次保存,因此默认使用 name 的 part-00000,后续再多次存储是,我们就可以获取 fileName 的后缀进行累加输出了,这里使用 DecimalFormat 实现了自动补 0 的操作。
static String fileName = "";DecimalFormat decimalFormat = new DecimalFormat("00000");public void updateFileName(String name) {synchronized (fileName) {if (fileName.equals("")) {fileName = name;} else {fileName = "part-" + decimalFormat.format(Integer.parseInt(fileName.split("-")[1]) + 1);}}}2.允许目录存在 - checkoutputSpecs
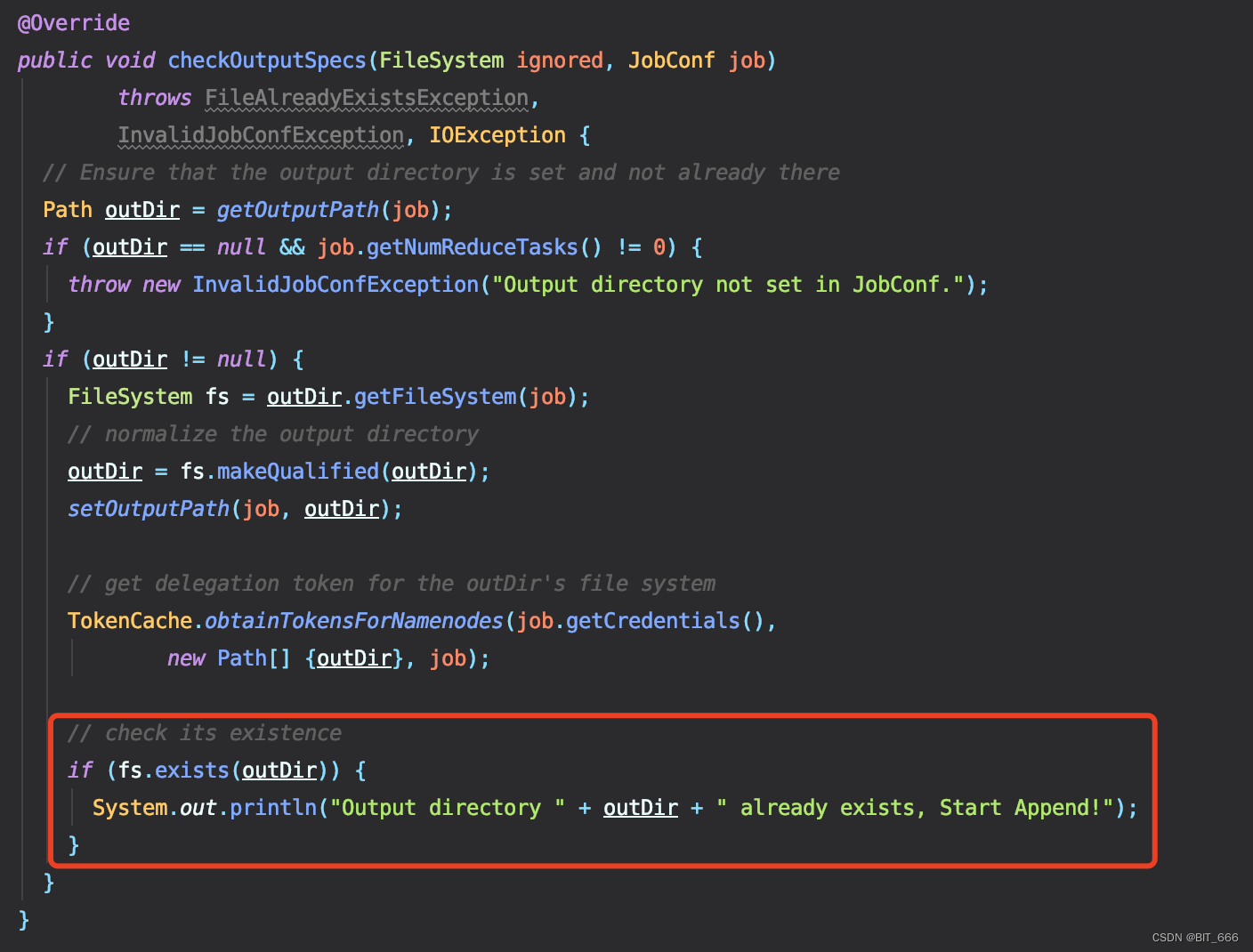
把 throw Exception 的异常去掉就好了,这里保留了 Println 提示目录已经存在并开始追加。
3.全部代码 - TextOutputFormatV2
换个 TextOutputFormatV2 实现我们追加文件存储的目的。
import java.io.DataOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.text.DecimalFormat;import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataOutputStream;import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.mapreduce.security.TokenCache;
import org.apache.hadoop.util.*;/*** An {@link OutputFormat} that writes plain text files.*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public class TextOutputFormatV2<K, V> extends FileOutputFormat<K, V> {static String fileName = "";DecimalFormat decimalFormat = new DecimalFormat("00000");public void updateFileName(String name) {synchronized (fileName) {if (fileName.equals("")) {fileName = name;} else {fileName = "part-" + decimalFormat.format(Integer.parseInt(fileName.split("-")[1]) + 1);}}}protected static class LineRecordWriter<K, V>implements RecordWriter<K, V> {private static final String utf8 = "UTF-8";private static final byte[] newline;static {try {newline = "\n".getBytes(utf8);} catch (UnsupportedEncodingException uee) {throw new IllegalArgumentException("can't find " + utf8 + " encoding");}}protected DataOutputStream out;private final byte[] keyValueSeparator;public LineRecordWriter(DataOutputStream out, String keyValueSeparator) {this.out = out;try {this.keyValueSeparator = keyValueSeparator.getBytes(utf8);} catch (UnsupportedEncodingException uee) {throw new IllegalArgumentException("can't find " + utf8 + " encoding");}}public LineRecordWriter(DataOutputStream out) {this(out, "\t");}/*** Write the object to the byte stream, handling Text as a special* case.* @param o the object to print* @throws IOException if the write throws, we pass it on*/private void writeObject(Object o) throws IOException {if (o instanceof Text) {Text to = (Text) o;out.write(to.getBytes(), 0, to.getLength());} else {out.write(o.toString().getBytes(utf8));}}public synchronized void write(K key, V value)throws IOException {boolean nullKey = key == null || key instanceof NullWritable;boolean nullValue = value == null || value instanceof NullWritable;if (nullKey && nullValue) {return;}if (!nullKey) {writeObject(key);}if (!(nullKey || nullValue)) {out.write(keyValueSeparator);}if (!nullValue) {writeObject(value);}out.write(newline);}public synchronized void close(Reporter reporter) throws IOException {out.close();}}@Overridepublic void checkOutputSpecs(FileSystem ignored, JobConf job)throws FileAlreadyExistsException,InvalidJobConfException, IOException {// Ensure that the output directory is set and not already therePath outDir = getOutputPath(job);if (outDir == null && job.getNumReduceTasks() != 0) {throw new InvalidJobConfException("Output directory not set in JobConf.");}if (outDir != null) {FileSystem fs = outDir.getFileSystem(job);// normalize the output directoryoutDir = fs.makeQualified(outDir);setOutputPath(job, outDir);// get delegation token for the outDir's file systemTokenCache.obtainTokensForNamenodes(job.getCredentials(),new Path[] {outDir}, job);// check its existenceif (fs.exists(outDir)) {System.out.println("Output directory " + outDir + " already exists, Start Append!");}}}public RecordWriter<K, V> getRecordWriter(FileSystem ignored,JobConf job,String name,Progressable progress)throws IOException {boolean isCompressed = getCompressOutput(job);String keyValueSeparator = job.get("mapreduce.output.textoutputformat.separator","\t");updateFileName(name);if (!isCompressed) {Path file = FileOutputFormat.getTaskOutputPath(job, fileName);FileSystem fs = file.getFileSystem(job);FSDataOutputStream fileOut = fs.create(file, progress);return new com.CommonTool.TextOutputFormatV2.LineRecordWriter<K, V>(fileOut, keyValueSeparator);} else {Class<? extends CompressionCodec> codecClass =getOutputCompressorClass(job, GzipCodec.class);// create the named codecCompressionCodec codec = ReflectionUtils.newInstance(codecClass, job);// build the filename including the extensionPath file =FileOutputFormat.getTaskOutputPath(job,fileName + codec.getDefaultExtension());FileSystem fs = file.getFileSystem(job);FSDataOutputStream fileOut = fs.create(file, progress);return new com.CommonTool.TextOutputFormatV2.LineRecordWriter<K, V>(new DataOutputStream(codec.createOutputStream(fileOut)),keyValueSeparator);}}
}四.追加存储代码实战
def main(args: Array[String]): Unit = {val (argsList, argsMap) = ArgsParseUtil.parseArgs(args)val conf = (new SparkConf).setAppName("AppendFileToHdfs").setMaster("local[*]")val spark = SparkSession.builder.config(conf).getOrCreate()val sc = spark.sparkContextval output = argsMap.getOrElse("output", "./append_output")val data = sc.parallelize(0 to 1000).mapPartitions { iter =>val text = new Text()iter.map { x =>text.set(x.toString)(NullWritable.get(), text)}}(0 until 10).foreach(epoch => {// 存储一次无法继续存储// data.saveAsTextFile(output)data.saveAsHadoopFile(output, classOf[NullWritable], classOf[Text], classOf[TextOutputFormatV2[NullWritable, String]])})}首先转化为 (NullWritable.get(), text) 的 pairRDD,随后调用 saveAsHadoopFile 方法并传入我们自定义的 TextOutputFormatV2 即可,由于我们 for 循环了 10 次,所以打印了 10 个相关日志。

下面再看下生成的文件:
![]()
每个文件存 250 个数字,每次存储 4 个 part,10 次 40 个且保持递增顺序。
五.总结
想要结合源码进行修改时,结合自己的需求,带着问题去找对应的函数再复写就 OK 了,由于这里逻辑比较简单所以我们也没踩太多坑。上面采用的是单次 Job 连续存储,所以 Format 里 FileName 能够达到累加的情况,如果是多个 Job 重复启动,则每次获取的都是 part-00000,这时如果还想要保持文件名递增的话可以使用 FileSystem.listStatus 遍历文件夹获取 modifyTime 最新的文件并取其 name 即可拿到最新的文件名 part,此时将参数传入 TextFormat 并修改 update 逻辑即可实现多 Job 重复启动且文件名递增的需求了。当然了,使用 UUID + Date 是最省事滴。
相关文章:

Spark - 继承 FileOutputFormat 实现向 HDFS 地址追加文件
目录 一.引言 二.源码浅析 1.RDD.saveAsTextFile 2.TextOutputFormat 3.FileOutputFormat 三.源码修改 1.修改文件生成逻辑 - getRecordWriter 2.允许目录存在 - checkoutputSpecs 3.全部代码 - TextOutputFormatV2 四.追加存储代码实战 五.总结 一.引言 Output d…...

树莓派编程控制继电器及继电器组
目录 一,继电器说明 ● 继电器接口说明 ① 继电器输入端: ② 继电器输出端: 二,树莓派控制继电器 三,树莓派控制继电器组 一,继电器说明 通俗点讲,可以把继电器理解成是一些功能设备的控制开关。 ● LOW&#…...

oracle和mysql的区别
Oracle与MySQL的区别以及优缺点 MySQL的特点 1、性能卓越,服务稳定,很少出现异常宕机; 2、开放源代码无版本制约,自主性及使用成本低; 3、历史悠久,社区和用户非常活跃,遇到问题及时寻求帮助…...
<Linux开发> linux应用开发-之-uart通信开发例程
一、简介 串口全称叫做串行接口,串行接口指的是数据一个一个的按顺序传输,通信线路简单。使用两条线即可. 实现双向通信,一条用于发送,一条用于接收。串口通信距离远,但是速度相对会低,串口是一种很常用的工…...

基于深度学习的安全帽检测系统(YOLOv5清新界面版,Python代码)
摘要:安全帽检测系统用于自动化监测安全帽佩戴情况,在需要佩戴安全帽的场合自动安全提醒,实现图片、视频和摄像头等多种形式监测。在介绍算法原理的同时,给出Python的实现代码、训练数据集,以及PyQt的UI界面。安全帽检…...
Linux - 进程控制(进程替换)
0.引入创建子进程的目的是什么?就是为了让子进程帮我执行特定的任务让子进程执行父进程的一部分代码如果子进程想执行一个全新的程序代码呢? 那么就要使用进程的程序替换为什么要有程序替换?也就是说子进程想执行一个全新的程序代码ÿ…...

Java中 ==和equals的区别是什么?
作用: 基本类型,比较值是否相等引用类型,比较内存地址值是否相等不能比较没有父子关系的两个对象equals()方法的作用: JDK 中的类一般已经重写了 equals(),比较的是内容自定义类如果没有重写 equals(),将…...
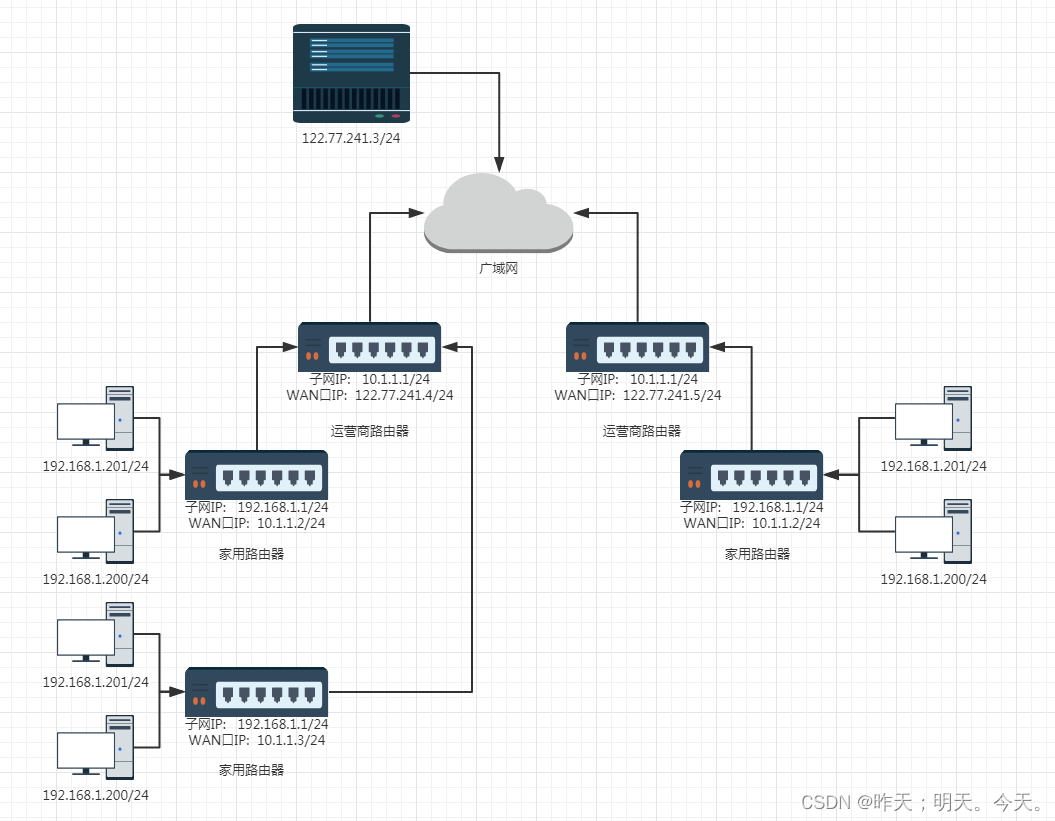
Linux(网络基础---网络层)
文章目录0. 前言1. IP协议1-1 基本概念1-2 协议头格式2. 网段划分2-1 基本概念2.2 IP地址分五大类2-3 特殊的IP地址2-4 IP地址的数量限制2-5 私有IP地址和公网IP地址2-6 路由0. 前言 前面我们讲了,应用层、传输层;本章讲网络层。 应用层:我…...
空间信息智能应用团队研究成果介绍及人才引进
目录1、多平台移动测量技术1.1 车载移动测量系统1.2 机载移动测量系统2、数据处理与应用技术研究2.1 点云与影像融合2.2 点云配准与拼接2.3 点云滤波与分类2.4 道路矢量地图提取2.5 道路三维自动建模2.6 道路路面三维病害分析2.7 多期点云三维变形分析2.8 地表覆盖遥感监测分析…...

ChatGPT应用场景与工具推荐
目录 写在前面 一、关于ChatGPT 二、应用实例 1.写文章 2.入门新的知识 3.解决疑难问题 4.生成预演问题 5.文本改写 6.语言翻译 7.思维导图 8.PDF阅读理解 9.操作格式化的数据 10.模拟场景 11.写代码 三、现存局限 写在前面 本文会简单介绍ChatGPT的特点、局限以…...
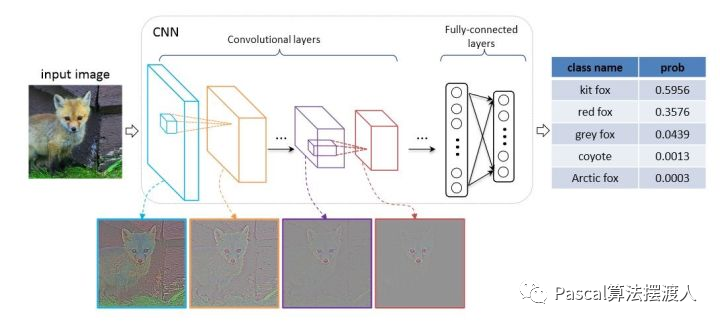
图像分类卷积神经网络模型综述
图像分类卷积神经网络模型综述遇到问题 图像分类:核心任务是从给定的分类集合中给图像分配一个标签任务。 输入:图片 输出:类别。 数据集MNIST数据集 MNIST数据集是用来识别手写数字,由0~9共10类别组成。 从MNIST数据集的SD-1和…...

艹,终于在8226上把灯点亮了
接上次点文章ESP8266还可以这样玩这次,我终于学会了在ESP8266上面点亮LED灯了现在一个单片机的价格是几块,加上一个晶振,再来一个快递费,十几块钱还是需要的。所以能用这个ESP8266来当单片机玩,还是比较不错的可以在ub…...
脱不下孔乙己的长衫,现代的年轻人该怎么办?
“如果我没读过书,我还可以做别的工作,可我偏偏读过书” “学历本该是我的敲门砖,却成了我脱不下的长衫。” 最近,“脱下孔乙己的长衫”在网上火了。在鲁迅的原著小说中,孔乙己属于知识阶级(长衫客…...

Matlab实现遗传算法
遗传算法(Genetic Algorithm,GA)是一种基于生物进化理论的优化算法,通过模拟自然界中的遗传过程,来寻找最优解。 在遗传算法中,每个解被称为个体,每个个体由一组基因表示,每个基因是…...

评价公式-均方误差
均方误差的公式可以通过以下步骤推导得出: 假设有n个样本,真实值分别为y₁, y₂, ……, yₙ,预测值分别为ŷ₁, ŷ₂, ……, ŷₙ。 首先,我们可以定义误差(error)为预测值与真实值之间的差: …...

冲击蓝桥杯-时间问题(必考)
目录 前言: 一、时间问题 二、使用步骤 1、考察小时,分以及秒的使用、 2、判断日期是否合法 3、遍历日期 4、推算星期几 总结 前言: 时间问题可以说是蓝桥杯,最喜欢考的问题了,因为时间问题不涉及到算法和一些复杂的知识…...

10个杀手级应用的Python自动化脚本
10个杀手级应用的Python自动化脚本 重复的任务总是耗费时间和枯燥的。想象一下,逐一裁剪100张照片,或者做诸如Fetching APIs、纠正拼写和语法等任务,所有这些都需要大量的时间。为什么不把它们自动化呢?在今天的文章中,…...

2023史上最全软件测试工程师常见的面试题总结 备战金三银四
在这里我给大家推荐一套专门讲解软件测试简历,和面试题的视频,实测有效,建议大家可以看看! 春招必看已上岸,软件测试常问面试题【全网最详细,让你不再踩坑】_哔哩哔哩_bilibili春招必看已上岸,…...

2023年全国最新安全员精选真题及答案29
百分百题库提供安全员考试试题、建筑安全员考试预测题、建筑安全员ABC考试真题、安全员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 81.(单选题)同一建筑施工企业在12个月内连续发生(&…...

关系数据库的7个基本特征
文章目录关系数据库中的二维表─般满足7个基本特征:①元组(行)个数是有限的——元组个数有限性。 ②元组(行)均不相同——元组的唯—性。 ③元组(行)的次序可以任意交换——元组的次序无关性。 ④元组(行)的分量是不可分割的基本特征——元组分量的原子性。 ⑤属性(列)名各不相…...

NCCL中RoCE与RDMA的深度解析:如何优化分布式训练网络性能
1. 为什么RoCE和RDMA对分布式训练如此重要? 第一次接触分布式训练时,我盯着日志里不断跳动的通信耗时直发愁。8块GPU明明都在满负荷运转,但总训练时间就是比单卡8要长不少。后来用NVIDIA的Nsight工具一分析,发现超过30%的时间都花…...

FlexRay帧格式拆解:从Header到Trailer,手把手教你读懂汽车总线的‘数据包’
FlexRay帧格式实战解析:像拆解网络包一样掌握汽车总线通信 在汽车电子系统开发中,理解总线协议就像网络工程师需要精通TCP/IP一样重要。FlexRay作为高性能车载网络的核心协议,其帧格式设计既体现了汽车电子对确定性的严苛要求,又融…...

探索开源软件 FireGeo:地理空间数据处理的新选择
探索开源软件 FireGeo:地理空间数据处理的新选择 在地理空间数据处理的领域中,开源软件正以其独特的优势逐渐崭露头角,为众多专业人士和爱好者提供了丰富多样的工具。FireGeo 作为其中一款开源软件,正吸引着越来越多人的关注&…...

太原烘焙培训排名
在太原选择烘焙培训机构时,许多朋友会关注不同机构的教学质量与特色。以下整理了一些选择时可以考虑的方面,供您参考。教学方式与内容部分机构采用以实操为主的教学模式,例如山西旭梦圆食品有限公司的课程安排中,实践操作占较大比…...

零基础实战:揭秘Python漫画下载器高效收藏完整指南
零基础实战:揭秘Python漫画下载器高效收藏完整指南 【免费下载链接】copymanga-downloader 使用python编译exe/bash/命令行参数来下载copymanga(拷贝漫画)中的漫画,支持批量选话下载和获取您收藏的漫画并下载!(windows&linux支持…...

Copilot 插入广告引担忧,AI 工具商业化边界受考
Copilot 拉取请求中惊现广告插入团队成员使用 Copilot 纠正拉取请求(PR)中的拼写错误时,出现了令人意想不到的情况。Copilot 不仅修改了 PR 描述,还插入了它自身以及 Raycast 的广告。这一行为引发了用户的强烈反应,有…...

【Java边缘运行时部署终极指南】:20年专家亲授5大避坑法则与3步极速上线实战
第一章:Java边缘运行时部署全景认知与演进脉络Java在边缘计算场景中的运行时部署正经历从传统云中心化架构向轻量、自治、低延迟方向的深刻演进。早期Java应用依赖完整JDK和重量级容器(如Tomcat)部署于虚拟机或Kubernetes集群,难以…...

ESP32/ESP8266嵌入式IoT工具库:轻量、可靠、生产就绪
1. 项目概述esp-iot-utils是面向 ESP32 和 ESP8266 平台的轻量级、生产就绪型嵌入式 IoT 工具集。它并非功能堆砌的“大而全”框架,而是以工程师视角提炼出高频、重复、易出错的底层任务——网络通信、结构化数据解析、时间同步、配置持久化与系统状态管理——并封装…...

XUnity.AutoTranslator:如何为Unity游戏构建高效的多语言本地化系统
XUnity.AutoTranslator:如何为Unity游戏构建高效的多语言本地化系统 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator XUnity.AutoTranslator是一个专为Unity游戏设计的自动翻译插件,…...

ngx_http_join_exact_locations
1 定义 ngx_http_join_exact_locations 函数 定义在 ./nginx-1.24.0/src/http/ngx_http.cstatic ngx_int_t ngx_http_join_exact_locations(ngx_conf_t *cf, ngx_queue_t *locations) {ngx_queue_t *q, *x;ngx_http_location_queue_t *lq, *lx;q ngx_queue_he…...