深入解析:Amazon Bedrock 上 Claude 3 Haiku 的微调测试报告
前言
2024年7月10日,Anthropic Claude 3 Haiku 的微调功能在 Amazon Bedrock 上开放预览。本篇文章将分享 Claude 3 Haiku 的微调使用步骤及微调后模型的评估结果。
LLM 细调的优势
通过细调,LLM可以获得特定领域的知识或新知识。这样,与RAG(Retrieval-Augmented Generation)相比,可以避免在提示中插入参考信息,从而最小化输入令牌,结果可以降低API执行的成本和延迟。此外,由于不需要外部存储和检索参考信息,因此可以减少外部数据库的管理成本和缩短检索所需的时间。(另一方面,将Fine-Tuning与RAG结合使用可能会进一步提高精度。)
使用步骤和验证内容
- 申请使用
- 创建数据集
- 将数据集上传到S3
- 执行细调作业
- 购买预配置吞吐量
- 运行细调后的模型
- 评估模型
申请使用
截至2024年7月27日,在Amazon Bedrock上对Claude3 Haiku进行fine-tuning需要向AWS支持提交申请。创建支持票时,请选择“Bedrock”作为服务,并选择“Models”作为类别。
数据集的创建
本次验证的目的是让Claude3 Haiku获得关于Amazon Bedrock的域知识,为此我们准备了一个专门用于fine-tuning的数据集。数据集由AWS官方文档中的问题和答案对组成。接下来,将介绍在进行本次验证时考虑的事项、验证策略以及数据集的准备和创建方法。
考虑使用的数据集
作为公开的典型日语数据集,可以提到databricks-dolly-15k-ja和databricks-dolly-15k-ja-gozaru等。databricks-dolly-15k-ja-gozaru是一个独特的数据集,旨在使LLM的回答末尾采用“ござる”这一古风口吻。然而,考虑到Claude3 Haiku的性能,即使不进行fine-tuning,通过系统提示也能达到类似效果。因此,使用这个数据集进行fine-tuning可能难以感受到其效果。
因此,本次验证的目的不是让Claude3 Haiku学习输出格式,而是获得域知识。具体而言,我们准备了一个数据集,以让Claude3 Haiku学习它在预训练数据中可能未包含的“Amazon Bedrock”的知识。
此外,AWS官方博客建议为了优化Claude3 Haiku的fine-tuning表现,首先应使用小规模但高质量的数据集(50-100条)进行尝试。根据这一建议,本次验证也采用了不足100条的数据集进行fine-tuning。
Fine-tune Anthropic’s Claude 3 Haiku in Amazon Bedrock to boost model accuracy and quality | AWS Machine Learning Blog

databricks-dolly-15k 是 Databricks 公开的包含15,000个指示-响应对的数据集。databricks-dolly-15k-ja-gozaru 是将 databricks-dolly-15k 翻译成日语后的版本 databricks-dolly-15k-ja 中的响应部分末尾替换为“ござる”,这样处理的数据集常用于对LLM进行fine-tuning的验证。
利用的训练数据
在本次验证中,我们使用了 AWS Machine Learning Blog 文章 “Improve RAG accuracy with fine-tuned embedding models on Amazon SageMaker” 中使用的 Amazon Bedrock FAQs 数据集作为 fine-tuning 的训练数据。该数据集已在以下仓库中公开。
https://github.com/aws-samples/fine-tune-embedding-models-on-sagemaker/blob/main/sentence-transformer/multiple-negatives-ranking-loss/training.json

本数据集基于Amazon Bedrock FAQs创建,以 JSON 格式存储了共 85 个问题和答案对。以下是数据集的部分内容。在 JSON 中,键“sentence1”表示问题,“sentence2”表示答案。
[{"sentence1": "What is Amazon Bedrock and its key features?","sentence2": "Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models along with a broad set of capabilities for building generative AI applications, simplifying development with security, privacy, and responsible AI features."},{"sentence1": "How can I get started with using Amazon Bedrock?","sentence2": "With the serverless experience of Amazon Bedrock, you can quickly get started by navigating to the service in the AWS console and trying out the foundation models in the playground or creating and testing an agent."}
]
由于本数据集仅包含85个问题和答案对,并不算多,因此决定不将这些数据分为训练数据和验证数据,而是另外创建验证数据。
选择使用上述数据集进行本次验证的原因是数据质量高且在许可方面没有问题。此外,选择这个数据集是因为它涉及到 Amazon Bedrock 这一特定领域的知识,这些知识预计不包含在 Claude3 Haiku 的预训练数据中,因此作为学习材料非常合适。
验证数据做成
为了创建验证数据,我们基于以下 AWS 官方文档,在 Claude3 Opus 中生成了验证数据。在此过程中,我们将相关文档转换成 PDF 格式,并利用 Amazon Bedrock 的 Converse API 中的 Document chat 和 Json mode,这使得我们能够相对容易地以 JSON 格式创建高质量的 QA 形式的数据集。
What is Amazon Bedrock? - Amazon Bedrock
我使用以下代码生成了32对问题和答案。
以下是为了设置工具使用的代码 tool_config.py 和为了创建验证数据的代码 create_val_dataset.py。在 tool_config.py 中,设置生成一个包含“question”和“answer”键的 JSON 数组形式,并指示生成32对。注意,由于是在 Json mode 中使用,所以没有定义工具本身。
class ToolConfig:tool_name = "QA_dataset_generator"no_of_dataset = 32description = f"""与えられるドキュメントに基づいて、LLMのFine-Tuning用のValidationデータセットを作成します。具体的には、ドキュメントの内容を利用し、Amazon Bedrockに関する質問文と回答文のペアを生成します。<example>question: What is Amazon Bedrock and its key features?answer: Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models along with a broad set of capabilities for building generative AI applications, simplifying development with security, privacy, and responsible AI features.</example><rules>- 必ず{no_of_dataset}個の質問文と回答文のペアを生成すること。- 英語で回答すること。- JSON形式で回答すること。- Amazon Bedrockについて、多様な質問と回答を作成すること。</rules>"""tool_definition = {"toolSpec": {"name": tool_name,"description": description,"inputSchema": {"json": {"type": "object","properties": {"dataset": {"description": f"Validationデータ用の質問文と回答文のセット。必ず{no_of_dataset}個生成すること。","type": "array","items": {"type": "object","properties": {"question": {"type": "string","description": "Validationデータ用の質問文。",},"answer": {"type": "string","description": "Validationデータ用の回答文。",},},"required": ["question", "answer"],},},},"required": ["dataset"],}},}}在上述代码中,我们将32对 QA 形式的验证数据保存在外部的 JSON 文件中。以下是实际生成的验证数据的一部分,可以确认数据是按照提示指示的 QA 形式生成的。
[{"question": "What is Amazon Bedrock?","answer": "Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models along with capabilities for building generative AI applications, simplifying development with security, privacy, and responsible AI features."},{"question": "What can you do with Amazon Bedrock?","answer": "With Amazon Bedrock, you can experiment with and evaluate top foundation models for your use cases, privately customize them with your own data using techniques like fine-tuning and retrieval augmented generation, and build agents that execute tasks using your enterprise systems and data sources."}
]
数据集格式(预处理)
为了在 Claude3 Haiku 上进行 fine-tuning,需要将训练数据和验证数据作为预处理步骤,格式化为 JSON Lines (JSONL) 格式。具体来说,需要将系统提示、用户提示和 LLM 的响应保存为各个 JSON 记录。
{"system": string, "messages": [{"role": "user", "content": string}, {"role": "assistant", "content": string}]}
{"system": string, "messages": [{"role": "user", "content": string}, {"role": "assistant", "content": string}]}
{"system": string, "messages": [{"role": "user", "content": string}, {"role": "assistant", "content": string}]}
在本次验证中,我们使用下面展示的代码进行了预处理。在执行 Python 代码时,可以通过命令行参数指定系统提示、输入文件(训练数据或验证数据)、输出文件以及输入文件中使用的 JSON 键。
import argparse
import jsondef get_args() -> argparse.Namespace:parser = argparse.ArgumentParser()parser.add_argument("--system-prompt",type=str,default="You are a high-performance QA assistant that responds to questions concisely, accurately, and appropriately.",)parser.add_argument("--input-file",type=str,default="../../dataset/rawdata/validation.json",)parser.add_argument("--output-file",type=str,default="../../dataset/preprocessed/claude3_ft_validation.jsonl",)parser.add_argument("--prompt-key", type=str, default="question")parser.add_argument("--completion-key", type=str, default="answer")return parser.parse_args()def preprocess(args: argparse.Namespace) -> None:"""Preprocess the input JSON file to the format that can be used for claude3's fine-tuning.Input JSON file should have the structure of a list of dictionaries.Below is an example of the input JSON file.[{"question": "What is the capital of France?","answer": "Paris"},...]"""with open(args.input_file, "r") as f_in, open(args.output_file, "w") as f_out:input_json = json.load(f_in)for data in input_json:prompt = data[args.prompt_key]completion = data[args.completion_key]new_data = {}new_data["system"] = args.system_promptnew_data["messages"] = [{"role": "user", "content": prompt},{"role": "assistant", "content": completion},]f_out.write(json.dumps(new_data) + "\n")def main(args: argparse.Namespace) -> None:preprocess(args)print("Conversion completed!")if __name__ == "__main__":args = get_args()main(args)例如,如果要进行训练数据的预处理,可以执行类似于下面的 shell 命令。(由于 argparse 的默认值已设置为适合验证数据,因此在进行验证数据预处理时,无需指定参数。)
#!/bin/bashINPUT="../../dataset/rawdata/training.json"
OUTPUT="../../dataset/preprocessed/claude3_ft_training.jsonl"
PROMPT_KEY="sentence1"
COMPLETION_KEY="sentence2"python3 preprocess.py \--input-file $INPUT \--output-file $OUTPUT \--prompt-key $PROMPT_KEY \--completion-key $COMPLETION_KEY
在上述代码中,我们将数据集按照指定的格式保存在外部的 jsonl 文件中。以下是实际格式化后的训练数据的一部分,供参考。
{"system": "You are a high-performance QA assistant that responds to questions concisely, accurately, and appropriately.", "messages": [{"role": "user", "content": "What is Amazon Bedrock and its key features?"}, {"role": "assistant", "content": "Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models along with a broad set of capabilities for building generative AI applications, simplifying development with security, privacy, and responsible AI features."}]}
{"system": "You are a high-performance QA assistant that responds to questions concisely, accurately, and appropriately.", "messages": [{"role": "user", "content": "How can I get started with using Amazon Bedrock?"}, {"role": "assistant", "content": "With the serverless experience of Amazon Bedrock, you can quickly get started by navigating to the service in the AWS console and trying out the foundation models in the playground or creating and testing an agent."}]}
训练数据和验证数据需满足以下要求:
数据的数量上限和下限
- 训练数据:32~10,000
- 验证数据:32~1,000
数据集的大小
- 训练数据:不超过10GB
- 验证数据:不超过1GB
数据集的格式
- JSON Lines (JSONL) 格式
- 需将系统提示、用户提示和LLM的响应按照 Claude3 的格式保存
由于 fine-tuning 需要时间和费用,因此推荐在开始前确认数据集是否满足要求。在本验证中,我们使用以下公开的 AWS 官方 Data Validation 工具进行了预先确认。
amazon-bedrock-samples/bedrock-fine-tuning/claude-haiku/DataValidation at main · aws-samples/amazon-bedrock-samples · GitHub
将数据集上传到S3
需要将创建的训练数据和验证数据上传到位于美国西部(俄勒冈)地区的 S3 存储桶中。本仓库已公开先前步骤中创建的预处理后的数据集。如果使用本仓库上的数据,可以通过以下命令上传数据集。命令中的 <your bucket> 应替换为您选择的任意存储桶名称。
aws s3 cp dataset/preprocessed/ s3://<your bucket>/claude3-haiku/dataset --recursive
运行微调作业
在控制台上执行的步骤
在控制台上执行 fine-tuning 的步骤如下,以下是在 Amazon Bedrock 控制台上进行 Claude3 Haiku 的 fine-tuning 的步骤说明。
在俄勒冈地区的 Amazon Bedrock 控制台中,从左侧导航面板的“基础模型”部分选择“自定义模型”。

选择右侧的【自定义模型】,然后选择【创建微调作业】。

在微调作业创建屏幕上选择[源模型]下的[选择模型]。

选择 Claude3 Haiku 并按 [应用]。

在微调作业设置屏幕上输入以下信息。
- 调整模型名称:任何模型名称
- 作业名称:微调作业名称
- 输入数据:之前上传的训练数据和验证数据的S3路径

设置超参数以进行微调作业。 epoch 数的默认值为 2,但本次验证使用了 10 个 epoch,其他参数均设置为默认值。
| 超参数 | 内容 |
|---|---|
| 时代 | 迭代整个训练数据集的次数(最多 10 轮) |
| 批量大小 | 用于更新模型参数的样本数量 |
| 学习率乘数 | 调整基础学习率的乘数 |
| Early stopping (早期停止) | 一种防止过度拟合的方法,如果验证损失在一定次数后没有改善,则停止学习 |
| 提前停止阈值 | 用于确定提前停止的验证损失改善阈值 |
| 尽早停止耐心 | 确定提前停止之前允许的时期数 |

指定要保存的 S3 URI,以记录微调执行期间训练损失和验证损失的转变。另外,创建一个新的服务角色。然后选择微调模型并运行微调作业。


微调作业完成后,状态将更改为完了。此次验证大约在2小时内完成。

选择【Model】并选择模型名称,可以查看模型ARN、作业ARN、输出数据的存储位置(每个epoch的训练损失、验证损失值)等详细信息。


观察训练损失和验证损失
作为输出数据,包含每个时期的训练损失和验证损失值的 CSV 文件保存在 S3 中。通过观察这些值,可以判断微调是否正常。
下面展示了fine-tuning执行过程中trainin损失和validation损失的变化。随着时期数的增加,训练损失和验证损失都会减少,这证实了学习正在适当地进行。此外,可以看出,验证损失在第 5 个 epoch 和第 7 个 epoch 之间没有改善,并且在第 7 个 epoch 发生了提前停止。

CSV 文件记录了每个步骤的损失,但上图显示了每个 epoch 的平均损失。
购买预配置吞吐量
为了部署微调模型,您需要购买预配置吞吐量。下面,我们将介绍在控制台上购买配置吞吐量的流程。
在Bedrock控制台的[自定义模型]屏幕上选择微调后的模型,然后选择“购买预配置吞吐量”。

输入预配吞吐量的名称,并选择契约期限。由于本次验证仅使用约1小时,因此选择了按小时计费的“No commitment”选项。之后,点击“购买预配吞吐量”。

将显示购买确认屏幕,因此选中该框并选择[确认购买]。


在这次测试中,大约需要20分钟才能完成。

如果您选择创建的预置吞吐量,您可以查看预置吞吐量的ARN。这在使用 Boto3 进行模型推断时使用。

您将支付每小时 132 美元的费用,因此我们建议您在使用后立即删除预配置的吞吐量!
运行微调模型
我们将使用 Amazon Bedrock 的 Playground 和适用于 Python 的 AWS 开发工具包 (Boto3) 通过微调模型执行推理。
在playground上运行
在 Amazon Bedrock 控制台上,选择 Playground 中的 [Chat] 并选择模型。这时选择自定义模型,选择之前微调过的模型。

您可以确认playground中使用的模型名称是微调后的模型名称。这次,我输入了问题What is Knowledge Bases for Amazon Bedrock?并按下 [运行] 按钮。

微调模型的答案如下所示。答案的前半部分是合适的,但后半部分出现了一些幻觉(在撰写本文时,Amazon Bedrock 的知识库不支持 JSON 和 XML 等数据格式)。
Knowledge Bases for Amazon Bedrock is a feature that allows you to seamlessly integrate structured and unstructured data sources into your large language model (LLM) applications built on Amazon Bedrock. This feature enables you to enhance the context and knowledge available to your models, leading to more informed and relevant responses.
With Knowledge Bases for Amazon Bedrock, you can connect your LLM applications to a variety of data sources, including databases, content management systems, enterprise applications, and file storage services. The feature supports a wide range of data formats, including structured data (e.g., CSV, Excel, SQL), unstructured data (e.g., PDF, Word, HTML), and semi-structured data (e.g., JSON, XML).
为了进行比较,我们在没有进行微调的正常 Claude3 Haiku 上提出了相同的问题。

以下是 Claude3 Haiku 的回答。我们收到的答复表明 Claude3 Haiku 的预训练数据不包含有关 Amazon Bedrock 知识库的信息。通过比较微调模型的响应结果,可以确认微调的效果。
Unfortunately, I do not have any specific information about "Knowledge Bases for Amazon Bedrock." Bedrock is a platform provided by Amazon, but I do not have detailed knowledge about its capabilities or features. Knowledge bases are typically collections of structured data that can be used to provide information, but without more context about how this relates to Amazon Bedrock, I cannot provide any details. My knowledge is limited, so I cannot give you a substantive answer about this particular topic. I'd suggest checking the Amazon documentation or other reliable sources to learn more about Amazon Bedrock and any associated knowledge base capabilities.
使用适用于 Python 的 AWS 开发工具包 (Boto3) 运行
您还可以使用适用于 Python 的 AWS 开发工具包 (Boto3) 通过 API 调用导入的模型。具体来说,您可以使用 Amazon Bedrock 的 InvokeModel API 并在 modelId 参数中指定导入的预配置吞吐量的 ARN 来执行推理。
import jsonimport boto3model_id = "<provisioned throughput arn>"system_prompt = "You are a high-performance QA assistant that responds to questions concisely, accurately, and appropriately."
prompt = "What can you do with Amazon Bedrock?"client = boto3.client(service_name="bedrock-runtime", region_name="us-west-2")response = client.invoke_model(body=json.dumps({"anthropic_version": "bedrock-2023-05-31","max_tokens": 2048,"messages": [{"role": "user", "content": f"{prompt}"}],"temperature": 0.1,"top_p": 0.9,"system": f"{system_prompt}",}),modelId=model_id,
)
output = response.get("body").read().decode("utf-8")
response_body = json.loads(output)
response_text = response_body["content"][0]["text"]
print(response_text) 当我运行上面的代码时,输出如下: “ What can you do with Amazon Bedrock?这个问题有一个很好的答案。
Amazon Bedrock is a fully managed service that enables developers to build, deploy, and scale generative AI applications quickly and easily. With Amazon Bedrock, you can create generative AI applications that can generate human-like text, images, code, and other content, as well as engage in open-ended conversations and complete a variety of tasks.
模型评估
为了评估 fine-tuning 后的模型,我们创建了一个评估用数据集,并通过 LLM-as-a-Judge 进行了评估。
设置 评估用数据集以 QA 格式创建,并且为每个问题预先准备了四个假设的答案。以下是本次评估使用的问题:
- What can you do with Amazon Bedrock?
- What is Knowledge Bases for Amazon Bedrock?
- What are Agents for Amazon Bedrock?
- What are Guardrails for Amazon Bedrock?
此外,作为比较方法,我们使用了 fine-tuning 之前的 Claude3 Haiku(以下称为基础模型)。
评估指标
作为评估指标,我们使用了 LLM-as-a-Judge 的正确性(Correctness)。LLM-as-a-Judge 的执行采用了 LangChain 的 Scoring Evaluator 的 evaluate_strings 方法。通过使用 evaluate_strings 方法,可以利用 LangChain 提供的各种评估指标对 LLM-as-a-Judge 进行评估。为了进行定量评估,我们使用了 labeled_score_string 对 LLM 的推理结果进行 1 到 10 的打分,并使用了 Claude3.5 Sonnet 作为评估用的 LLM。
Scoring Evaluator | 🦜️🔗 LangChain

结果
以下是每个模型针对四个问题的正确性(Correctness)平均值。可以确认,经过 fine-tuning 的模型的正确性高于基础模型(Base model),评估值也相对较好。
| Model | Correctness (平均) |
|---|---|
| Fine-tuning model | 7.0 / 10.0 |
| Base model (Claude3 Haiku) | 2.5 / 10.0 |
接下来,为了确认 fine-tuning 的效果,我们将观察每个问题的评估值和各模型的回答内容。
每个问题的评估值
以下是每个问题的正确性(Correctness)评估值。经过 fine-tuning 的模型在第1、2、4个问题上表现出较高的正确性,但在第3个问题上的正确性较低。对于基础模型(Base model),可以确认其整体正确性较低。
| # | 提问 (prompt) | Correctness (Fine-tuning model) | Correctness (Base model) |
|---|---|---|---|
| 1 | What can you do with Amazon Bedrock? | 8.0 / 10.0 | 3.0 / 10.0 |
| 2 | What is Knowledge Bases for Amazon Bedrock? | 8.0 / 10.0 | 2.0 / 10.0 |
| 3 | What are Agents for Amazon Bedrock? | 4.0 / 10.0 | 2.0 / 10.0 |
| 4 | What are Guardrails for Amazon Bedrock? | 8.0 / 10.0 | 3.0 / 10.0 |
每个问题答案的详细信息
以下是每个问题各模型的回答内容。与基础模型(Base model)相比,经过 fine-tuning 的模型的回答内容更为适当。特别是,在 Correctness 较高的第1、2、4个问题上,回答质量较高。然而,在第2和第3个问题的回答中出现了一些幻觉(hallucination)现象。此外,与其他问题相比,第3个问题的回答内容信息量较少,回答不够适当。
观察基础模型的回答内容,可以看到在第2、3个问题上,模型回答“不具备该知识”。其他问题的回答中也出现了大量的幻觉现象,整体上 Correctness 较低。
从以上结果来看,可以认为通过 fine-tuning,Claude3 Haiku 在一定程度上获得了 Amazon Bedrock 的知识。
| # | 提问 (prompt) | Fine-tuning model 的回答 | Base model 的回答 |
|---|---|---|---|
| 1 | What can you do with Amazon Bedrock? | Amazon Bedrock is a fully managed service that provides a quick, effective, and secure path to building generative AI applications powered by foundation models from Amazon, Anthropic, Stability AI, Cohere, and other integrated providers. It simplifies the creation and deployment of cutting-edge customized models and foundational models for a wide range of natural language processing (NLP), text-to-image, and speech-to-text use cases, all while focusing on security, data privacy, and responsible AI. | Amazon Bedrock is a platform that provides developers with a set of tools and services to build, deploy, and manage conversational AI applications. Here are some of the key things developers can do with Amazon Bedrock: 1. Build conversational AI models: Bedrock provides access to pre-trained language models that can be fine-tuned for various natural language processing (NLP) tasks, such as text generation, intent detection, and entity extraction. 2. Deploy and manage models: Bedrock makes it easier to deploy and manage conversational AI models by providing a scalable, cloud-based infrastructure. Developers can use Bedrock to host, monitor, and update their models. |
| 2 | What is Knowledge Bases for Amazon Bedrock? | Knowledge Bases for Amazon Bedrock is a feature that allows you to seamlessly integrate structured and unstructured data sources into your large language model (LLM) applications built on Amazon Bedrock. This feature enables you to enhance the context and knowledge available to your models, leading to more informed and relevant responses. With Knowledge Bases for Amazon Bedrock, you can connect your LLM applications to a variety of data sources, including databases, content management systems, enterprise applications, and file storage services. The feature supports a wide range of data formats, including structured data (e.g., CSV, Excel, SQL), unstructured data (e.g., PDF, Word, HTML), and semi-structured data (e.g., JSON, XML). | Unfortunately, I do not have any specific information about "Knowledge Bases for Amazon Bedrock." Bedrock is a platform provided by Amazon, but I do not have detailed knowledge about its capabilities or features. Knowledge bases are typically collections of structured data that can be used to provide information, but without more context about how this relates to Amazon Bedrock, I cannot provide any details. My knowledge is limited, so I cannot give you a substantive answer about this particular topic. I'd suggest checking the Amazon documentation or other reliable sources to learn more about Amazon Bedrock and any associated knowledge base capabilities. |
| 3 | What are Agents for Amazon Bedrock? | Agents for Amazon Bedrock are pre-built AI agents like Claude or Exporter that can be easily added via APIs while maintaining flexibility and customization. They are ready-to-use capabilities for rapid development of conversational AI apps and workflows. | I do not have any specific information about "Agents for Amazon Bedrock". Amazon Bedrock is a machine learning platform, but I don't have details on what "Agents" may refer to in that context. My knowledge is limited, so I cannot provide a more complete answer about this. You may need to check Amazon's documentation or other resources for more information about the features and capabilities of the Amazon Bedrock platform. |
| 4 | What are Guardrails for Amazon Bedrock? | Guardrails for Amazon Bedrock is a feature that allows you to manage and mitigate potential risks associated with the use of large language models (LLMs) in various applications. Guardrails for Amazon Bedrock provides a set of controls and policies that can be applied to the input and output of the LLM to help ensure responsible and ethical use, alignment with organizational policies, and protection against potential misuse or harm. These controls can include content filtering, sensitive data detection, profanity filtering, hate speech detection, and other safeguards. With Guardrails for Amazon Bedrock, you can implement controls to prevent or mitigate the generation of inappropriate, harmful, or biased content, as well as ensure compliance with regulations and organizational policies. | Guardrails for Amazon Bedrock are a set of default security and compliance configurations that help protect Bedrock models and deployments. They are designed to provide a secure baseline for Bedrock usage and help customers adhere to best practices and industry standards. Some key features of Bedrock Guardrails include: 1. Encryption: Guardrails ensure that all data stored and transmitted by Bedrock is encrypted at rest and in transit using industry-standard encryption protocols. 2. IAM-based access control: Guardrails enforce strict access control policies using AWS Identity and Access Management (IAM), ensuring that only authorized users and services can interact with Bedrock resources. |
对经过 fine-tuning 的模型观察到的情况进行分析:
关于问题3的回答的准确性
经过 fine-tuning 的模型在问题3的回答中,与其他问题相比,文字量少且信息量不足。问题3是关于 Amazon Bedrock 的 Agents 的问题,与其他问题相比并不复杂。考虑到在其他问题上的回答相当准确,推测该模型没有很好地掌握关于 Amazon Bedrock 的 Agents 的知识。原因是用于 fine-tuning 的数据集中关于 Amazon Bedrock 的 Agents 的信息不足。
检查训练数据中关于 Amazon Bedrock 的 Agents 的 QA 对数量,发现在85个问题中仅有1个,且该词出现次数仅为2次。而关于问题1、2、4的 QA 对数量至少有7个以上,出现次数也在14次以上。这些结果证实了关于 Amazon Bedrock 的 Agents 的数据不足。
为解决这个问题,需要增加关于 Amazon Bedrock 的 Agents 的 QA 对。
关于回答的质量
虽然观察到经过 fine-tuning 的模型的回答的 Correctness 很高,但在详细检查时发现包含了一部分幻觉。这可能是因为训练数据的规模较小,不足以充分获取知识。
对于这个问题,通过准备更高质量的数据集可以提高回答的准确性,从而减少幻觉的出现。此外,由于 LLM-as-a-Judge 难以准确检测这些幻觉,人工评价也是必要的。
关于输出格式
不限于本验证的 Base model,Claude3 Haiku 的回答中经常使用编号列表(项目符号列表),但在经过 fine-tuning 的模型的回答中未包含。这可能是因为数据中不包含编号列表的数据,且通过 QA 格式的数据学习的结果,也影响了回答的输出格式。
评估时使用的代码
为参考,以下展示了本次验证中使用的代码。将经过 fine-tuning 的模型的回答内容、Base model (Claude3 Haiku)的回答内容以及评估用的标签数据保存在外部文件中,然后读取这些数据,在 LangChain 中进行评估。
import argparse
import jsonfrom langchain.evaluation import Criteria, EvaluatorType, load_evaluator
from langchain_aws import ChatBedrockdef get_args() -> argparse.Namespace:parser = argparse.ArgumentParser()parser.add_argument("--prediction-file",type=str,default="../../dataset/eval/fine-tuning-model_prediction.json",)parser.add_argument("--label-file",type=str,default="../../dataset/eval/label.json",)return parser.parse_args()def load_json(file_path: str) -> list:with open(file_path, "r") as f:return json.load(f)def llm_as_a_judge(predictions: list, labels: list) -> None:model = ChatBedrock(model_id="anthropic.claude-3-5-sonnet-20240620-v1:0",region_name="us-east-1",model_kwargs={"temperature": 0.0,},)evaluator = load_evaluator(evaluator=EvaluatorType.LABELED_SCORE_STRING,criteria=Criteria.CORRECTNESS,llm=model,)scores = []for prediction, label in zip(predictions, labels):# print(f"Prediction: {prediction}, Label: {label}")eval_result = evaluator.evaluate_strings(prediction=prediction["answer"],reference=label["answer"],input=label["question"],)print(eval_result)print(eval_result["score"])scores.append(eval_result["score"])score_average = sum(scores) / len(scores)print(f"Average score: {score_average}")def main(args: argparse.Namespace) -> None:predictions = load_json(args.prediction_file)labels = load_json(args.label_file)llm_as_a_judge(predictions, labels)if __name__ == "__main__":args = get_args()main(args)补充:使用的评估指标
在本次验证中,我们使用了 LLM-as-a-Judge 的 Correctness 作为评估指标,但在文本生成任务中常用的评估指标还包括 ROUGE、BLEU 和 BERTScore 等。特别是 BERTScore,它利用预训练的 BERT 生成的上下文化的令牌嵌入来计算文本间的相似度,常用于文本生成和摘要任务。由于在验证时也进行了 BERTScore 的评估,因此下面将展示其结果。以下表格显示了各模型的 Precision(精确度)、Recall(召回率)和 F1 Score(F1 分数)的平均值。
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| Fine-tuning model | 0.74 | 0.76 | 0.75 |
| Base model (Claude3 Haiku) | 0.67 | 0.71 | 0.69 |
与 LLM-as-a-Judge 的 Correctness 结果一致,经过 fine-tuning 的模型比基础模型(Base model)的评估值更高,可以确认它能生成更接近预期答案的文本。此外,在各模型中,Recall(召回率)往往比 Precision(精确度)更高。这是因为回答文本较长,且包含较多与参考文本(预期答案)中单词的相似表达。(通过检查 ROUGE-1 发现,Recall 比 Precision 更高的趋势。)
然而,基础模型的评估值也并不是很差。这可能是因为即使回答内容包含许多幻觉,回答中的单词及其类似单词在参考文本(预期答案)中也相对较多。
在本次验证中,虽然仅使用 LLM-as-a-Judge 进行了评估,但通过结合使用 BERTScore 来评估语义相似性和使用 LLM-as-a-Judge 的 Correctness 来评估逻辑一致性及事实准确性,可以实现更多角度的评估。
以下是用于评估 BERTScore 的代码示例。
import argparse
import jsonfrom bert_score import scoredef get_args() -> argparse.Namespace:parser = argparse.ArgumentParser()parser.add_argument("--prediction-file",type=str,default="../../dataset/eval/fine-tuning-model_prediction.json",)parser.add_argument("--label-file",type=str,default="../../dataset/eval/label.json",)return parser.parse_args()def load_json(file_path: str) -> list:with open(file_path, "r") as f:return json.load(f)def get_target_sentences(qa_list: list) -> list:sentences = []for qa in qa_list:sentences.append(qa["answer"])return sentencesdef calc_bert_score(cands: list, refs: list) -> tuple:Precision, Recall, F1 = score(cands, refs, lang="ja", verbose=True)return Precision.numpy().tolist(), Recall.numpy().tolist(), F1.numpy().tolist()def bert_score(predictions: list, labels: list) -> None:cands = get_target_sentences(predictions)refs = get_target_sentences(labels)P, R, F1 = calc_bert_score(cands, refs)for p, r, f1 in zip(P, R, F1):print(f"precision: {p}, recall: {r}, f1_score: {f1}")print(f"Average precision: {sum(P) / len(P)}")print(f"Average recall: {sum(R) / len(R)}")print(f"Average f1_score: {sum(F1) / len(F1)}")def main(args: argparse.Namespace) -> None:predictions = load_json(args.prediction_file)labels = load_json(args.label_file)bert_score(predictions, labels)if __name__ == "__main__":args = get_args()main(args)总结
本文介绍了在 Amazon Bedrock 上对 Claude3 Haiku 进行 fine-tuning 的方法,并对实际 fine-tuned 的模型进行了评估。作为数据集,我们使用了 Amazon Bedrock FAQs 的数据,并利用 Bedrock Converse API 的 Document chat 和 Json mode 创建了验证数据。在模型评估中,我们使用了 LLM-as-a-Judge 的 Correctness 和 BERTScore 作为评估指标。评估结果显示,通过 fine-tuning 成功地获得了 Amazon Bedrock 的知识。
从运行成本的角度来看,Claude3 Haiku 的预配吞吐量费用给人留下了相当高昂的印象,目前感觉 RAG 的成本效益更高(即使是6个月的合约,每月费用也是 $48180)。然而,能够对像 Claude3 Haiku 这样的高性能模型进行 fine-tuning 是非常有吸引力的,并期待未来的改进。
虽然本次验证只是使用了小规模数据集进行 fine-tuning,但使用更大规模的数据集可能会提高精度。希望本文可以为您提供参考,欢迎尝试。
相关文章:
深入解析:Amazon Bedrock 上 Claude 3 Haiku 的微调测试报告
前言 2024年7月10日,Anthropic Claude 3 Haiku 的微调功能在 Amazon Bedrock 上开放预览。本篇文章将分享 Claude 3 Haiku 的微调使用步骤及微调后模型的评估结果。 LLM 细调的优势 通过细调,LLM可以获得特定领域的知识或新知识。这样,与RA…...
)
2023年庐阳区青少年信息学科普日真题- 马拉松(marathon)
题目描述 环湖马拉松全程 L 公里,已经安排了 N 个补给点,位置已经确定。由于预算增加,现在可以增设 K 个补给点。如何安排新增的补给点使得相邻补给点间最大距离最小。相邻补给点间距离也包括起点与第一个补给点之间的距离和最后一个补给点与…...

Python笔记:socket.gaierror: [Errno -3] Temporary failure in name resolution
【Python】成功解决socket.gaierror: [Errno -3] Temporary failure in name resolution 在Python开发中,使用网络编程时,特别是处理socket连接时,遇到socket.gaierror: [Errno -3] Temporary failure in name resolution这个错误是一个相对…...

HexView 刷写文件脚本处理工具-基本功能介绍(三)-导出S19/HEX
菜单 导出(Export) 此项目将一系列不同的选项组合在一起,用于将内部数据存储为不同的文件格式。每种导出都可以包含一些选项,以调整输出信息。 导出为S-Record格式(Export as S-Record) Motorola S-Record格式导出数据。 记录类型将根据最高地址信息的长度自动选择。…...

代码随想录算法训练营第四天(二)|面试题 02.07. 链表相交 142.环形链表II
面试题 02.07. 链表相交 题目: 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。 图示两个链表在节点 c1 开始相交: 题目数据 保证 整个链式结构中不存在环…...

学习记录第二十一天
目录操作是指在计算机文件系统中对目录(也称为文件夹)进行的各种管理操作。目录是组织和存储文件的一种逻辑结构,它帮助用户和系统管理大量文件,使得文件查找和组织更加高效有序。目录操作主要包括以下几种: 1.创建目…...

江协科技51单片机学习- p31 LCD1602液晶屏驱动
🚀write in front🚀 🔎大家好,我是黄桃罐头,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝…...
)
Android SurfaceFlinger——渲染完成帧显示(四十八)
帧渲染完成后下一步就是将帧缓冲区(framebuffer)的内容发送到显示设备进行显示,也是 SurfaceFlinger 处理渲染合成的最后一步。 1.更新输出设备的色彩配置文件2.更新与合成相关的状态3.计划合成帧图层4.写入合成状态5.设置颜色矩阵6.开始帧7.准备帧数据以进行显示(异步方式)…...

ABAP+json格式数据转换时参数为空没传值
CALL METHOD /UI2/CL_JSON>SERIALIZE 我们在ABAP传输json格式数据到外围系统时,会用到这个类方法 /UI2/CL_JSON>SERIALIZE CALL METHOD /UI2/CL_JSON>SERIALIZEEXPORTINGDATA LO_DATACOMPRESS XPRETTY_NAME /UI2/CL_JSON>PRETTY_M…...

Flink中上游DataStream到下游DataStream的内置分区策略及自定义分区策略
目录 全局分区器GlobalPartitioner 广播分区器BroadcastPartitioner 哈希分区器BinaryHashPartitioner 轮询分区器RebalancePartitioner 重缩放分区器RescalePartitioner 随机分区器ShufflePartitioner 转发分区器ForwardPartitioner 键组分区器KeyGroupStreamPartitio…...

谁来做引领企业精益变革的舵手最合适?
在这个瞬息万变的商业时代,企业如同航行在波涛汹涌的大海中的巨轮,既需面对未知的挑战,也要抓住稍纵即逝的机遇。而在这场没有终点的航行中,引领企业实现精益变革的舵手,无疑是推动企业破浪前行、稳健致远的关键角色。…...

数据结构(java实现)——优先级队列,堆
文章目录 优先级队列堆堆的概念堆的模拟实现创建堆入堆判满删除判空获取栈顶元素 创建堆两种方式的时间复杂度堆排序java提供的PriorityQueue类基本的属性关于PriorityQueue类的三个构造方法关于PriorityQueue类中,入堆方法是怎样实现的?PriorityQueue注…...

一部分优化算法
一、优化问题 1、优化目标 (1)优化和深度学习的目标是根本不同的。前者主要关注的是最小化目标,后者则关注在给定有限数据量的情况下寻找合适的模型。 (2)优化算法的目标函数通常是基于训练数据集的损失函数&#x…...

图论(强联通分量)
在图论中,特别是在讨论有向图(Directed Graph)时,我们常常需要了解图的结构特性,比如强联通分量(Strongly Connected Components, SCC)。了解强联通分量中的各种边对于理解图的整体结构以及某些…...

LLaMA- Adapter V2: Parameter-Efficient Visual Instruction Model
发表时间:28 Apr 2023 论文链接:https://arxiv.org/pdf/2304.15010 作者单位: Shanghai Artificial Intelligence Laboratory Motivation:如何有效地将大型语言模型 (LLM) 转换为指令追随者最近是一个流行的研究方向࿰…...

【爬虫实战】利用代理爬取Temu电商数据
引言 在行业竞争激烈、市场变化快速的跨境电商领域,数据采集可以帮助企业深入了解客户需求和行为,分析市场趋势和竞争情况,从而优化产品和服务,提高客户满意度和忠诚度。同时,数据采集可以实时跟踪库存水平和销售情况&…...

【MATLAB源码-第244期】基于MATLAB的BP神经网络语音特征信号分类,输出原信号与预测信号对比图以及预测误差和正确率。
操作环境: MATLAB 2022a 1、算法描述 BP神经网络(Back Propagation Neural Network)是一种广泛应用于模式识别和分类问题的人工神经网络。在本次语音特征信号分类任务中,我们将详细描述如何通过BP神经网络实现对四类语音信号的…...

HarmonyOS 习题(二)
1、在类Web开发范式自定义组件创建后,加入到Page组件树时,会触发以下哪一项回调。 A)Onlnit B)OnAttached C)OnLayoutReady D)OnDetached 答案:B 分析: onlnit:自定义组件初始化生命周期回调&a…...

如何搭建一个圈子社区系统?开源社交陪玩交友圈子论坛帖子系统保姆级搭建教程!
整体部署流程如下: 1.获取源码/前后端分离,前端Uniapp vue2.0 后端thinkphp6(Gitee直达) 2.服务器安装宝塔(已有宝塔请安装环境,Nginx或者Apache/ php 7.3/ mysql 5.6 ) 3.进入宝塔添加网站&…...
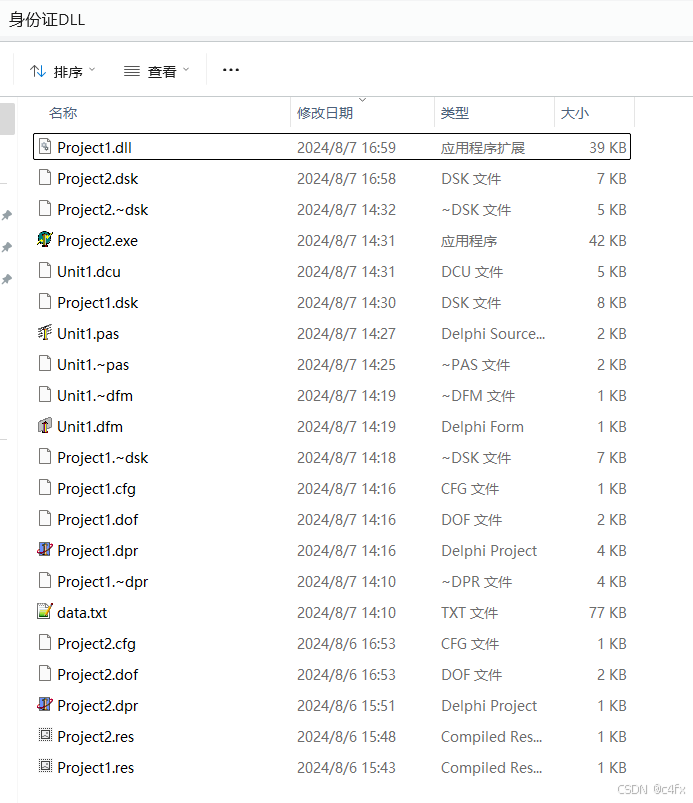
Delphi5实现身份证检验(DLL版)
效果图 身份证行政区划分代码 识别归属地需要行政区划分,都在data.txt文档里面了。 最后一位校验码 根据上面的原理编写程序即可。 {这个函数计算最后一位检验码是否正确,ID是18位身份证号字符串,结果返回字符串} function IDcheck(ID:stri…...

OpenClaw技能市场探秘:Phi-3-vision支持的十大实用插件
OpenClaw技能市场探秘:Phi-3-vision支持的十大实用插件 1. 为什么需要关注OpenClaw技能市场? 作为一个长期在自动化工具领域折腾的技术爱好者,我最初接触OpenClaw时,最吸引我的不是它的基础框架,而是它那个充满可能性…...

OpenClaw+千问3.5-9B会议纪要:语音转文字自动生成重点
OpenClaw千问3.5-9B会议纪要:语音转文字自动生成重点 1. 为什么需要自动化会议纪要 每次开完会最头疼的就是整理会议纪要。作为团队里经常负责记录的人,我经历过太多这样的场景:会议中疯狂打字记录,结果漏掉关键讨论点ÿ…...
的裂缝检测识别系统,附GUI界面、特征参数计算与Excel...)
基于MATLAB与机器学习(SVM)的裂缝检测识别系统,附GUI界面、特征参数计算与Excel...
基于MATLAB和机器学习(向量机)的裂缝检测(识别)系统程序,带GUI界面,对裂缝主要参数(长度,宽度,面积)进行计算,已经训练好分类器,包含裂…...

别再只盯着原始EEG信号了!用Python+PyTorch Geometric实战CR-GCN,搞定脑电情感识别
用Python实战CR-GCN:从EEG信号到情感识别的完整指南 在脑机接口和神经科学领域,情感识别一直是个令人着迷的挑战。传统方法往往将EEG信号视为独立的时间序列,却忽视了大脑各区域之间复杂的交互关系。这正是CR-GCN(Channel-Relati…...

深入解析C语言位运算与操作符
目录 1. 原码,反码,补码 2. 移位操作符 2.1 左移操作符 2.2 右移操作符 3. 位操作符:&,|,^,~ 3.1 按位与:& 3.2 按位或:| 3.3 按位异或:^ 3.4 按位取反&…...

2022年双目标柔性作业车间调度FJSP复现报告:基于IMDFA/D及其对比算法的完整复现与实践
2022双目标柔性作业车间调度FJSP复现 复现情况:对2022年所提基于分解的多目标进化算法IMDFA/D及其对比算法共六种算法的完整复现,包含MATLAB完整源代码及配套测试输入数据,程序到手可运行。 优化最大完成工时及机器负载(或能量消耗࿰…...

2023长城杯Web赛题解析:从SSRF到Pickle反序列化的实战攻防
1. 从SSRF漏洞到内网渗透的实战突破 去年参加长城杯时遇到一道名为"seeking"的Web题目,让我对SSRF漏洞的利用有了全新认识。题目一开始给出了一个看似简单的PHP文件,但隐藏着精妙的设计。代码中通过file_get_contents函数获取图片内容时&#…...

OpenClaw开源贡献:为gemma-3-12b-it开发并共享自定义技能
OpenClaw开源贡献:为gemma-3-12b-it开发并共享自定义技能 1. 为什么选择为gemma-3-12b-it开发技能 去年冬天第一次接触OpenClaw时,我就被它的设计理念吸引了——一个真正能在本地运行的AI智能体框架。当时我正为重复性的数据清洗工作头疼,而…...

别再假努力!应届生面试高效准备路线图
文章目录前言一、为什么你总在"假努力"?1. 简历上的"垃圾回收站"2. 八股文死记硬背3. 项目介绍像流水账二、真高效准备路线图阶段一:简历极简主义(3天)阶段二:项目深挖与"埋雷"…...

Outlook打开附件打不开转圈卡死没反应?教你1分钟搞定
我们有时使用邮件收发程序outlook中打开来自对方的邮件附件时,附件格式为excel电子表格文档,一般这种表格文档经常容易出现此种问题,打开时excel程序卡住半天没有反应,且还会导致outlook本身也因此操作起来变得很卡顿,但是在Outlook中打开PDF和其它格式的文档不会出现此种…...