Java 2.2 - Java 集合
Java 集合,也叫做容器,主要是由两大接口派生而来:一个是 Collection 接口,主要用于存放单一元素;另一个是 Map 接口,主要用于存放键值对。对于 Collection 接口,其下又有三个主要的子接口:List、Set、Queue。
目录
Java 集合框架
(1)List、Set、Queue、Map的区别是什么?
List
Set
Queue
Map
(2)集合的底层数据结构都是什么?
List
Set
Queue
Map
* 拓展:为什么将插入链表的方式进行更改?
(3)如何选用集合?
(4)为什么要使用集合?
(5)ArrayList 和 Vector 的区别?
(6)ArrayList 和 LinkedList
(7)双向链表和双向循环链表(1.6 1.7 LinkedList)
(8)RandomAccess 接口
(9)ArrayList 的扩容机制是怎么样的?
(10)comparable 和 Comparator 的区别
(11)无序性和不可重复性的含义是什么?
无序性
不可重复性
(12)HashSet、LinkedHashSet、TreeSet三者有何异同?
(13)Queue 和 Deque 有什么区别?
(14)ArrayDeque 和 LinkedList 的区别是什么?
(15)你知道 PriorityQueue 吗?
(16)HashMap 和 Hashtable 的区别是什么?
为什么 HashMap 的长度为什么需要是2的幂次方?
(17)HashMap 和 HashSet 有什么区别?
(18)HashMap 和 TreeMap 有什么区别?
(19)HashSet 如何检查重复?
(20)HashMap 的底层实现
1.8之前
1.8之后
(21)HashMap 多线程操作导致死循环问题
(22)HashMap 有哪几种常见的遍历方式?
(23)ConcurrentHashMap 和 Hashtable 的区别是什么?
ConcurrentHashMap
Hashtable
(24)ConcurrentHashMap 线程安全的具体实现方法 / 底层具体实现?
1.8 之前
1.8 之后
Java 集合框架
(列举主要继承和派生关系,并未全部列出)

(1)List、Set、Queue、Map的区别是什么?
List
有序的,可重复的。类似于数组
Set
无序的、不可重复的。类似于集合(数学上)
Queue
队列,一般是FIFO。
Map
key-value 键值对存储。key 无序的,不可重复的;value 无序的,可重复的。每个 key 最多映射到一个 value 上。
(2)集合的底层数据结构都是什么?
List
1、ArrayList:底层是数组 Object[]
2、LinkedList:底层是双向链表(1.6之前是循环链表,1.7之后取消循环)
3、Vector:底层是数组 Object[]
Set
1、HashSet(无序、唯一):基于 HashMap 实现,底层通过 HashMap 保存数据
2、LinkedHashSet:HashSet 的子类,内部通过 LinkedHashMap 实现。
3、TreeSet(有序、唯一):红黑树(自平衡的二叉排序树)
Queue
1、ArrayQueue:底层是数组 Object[] + 双指针
2、PriorityQueue(优先队列):底层是数组 Object[] 来实现二叉堆
Map
1、HashMap:
1.8 之前是数组 + 链表,通过“拉链法”解决哈希冲突(拉链法即创建一个链表数组,当发生哈希冲突的时候直接将其加入链表即可)。在1.8之前,将元素插入链表使用的是头插法。
1.8之后使用数组 + 链表 + 红黑树,当链表长度大于一个阈值(默认为8)(将链表转换为红黑树之前会进行判断,如果数组长度小于64,会优先对数组进行扩容,如果长度大于64则进行转换)时,将链表转换为红黑树,以减小搜索时间。在1.8之后,将元素插入链表使用的是尾插法。
2、Hashtable:数组 + 链表
3、LinkedHashMap:
LinkedHashMap 继承 HashMap,它的底层仍然是基于拉链式散列结构即由数组和链表或红⿊树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对插入的顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。

每当有新键值对节点插入,新节点最终会接在 tail 引用指向的节点后面。而 tail 引用则会移动到新的节点上,这样一个双向链表就建立起来了。
* 拓展:为什么将插入链表的方式进行更改?
答:1、扩容会导致链表的顺序被反转
2、头插法可能导致链表环形问题,这个问题会导致 CPU 使用率 100% 或者死循环问题。(多线程情况下)
(3)如何选用集合?
我们主要根据集合的特点进行选择,
比如我们需要键值对进行存储,选用的肯定是 Map 接口下的集合。需要排序的时候选用 TreeMap,不需要排序的时候选 HashMap,保证线程安全使用 ConcurrentHashMap。
比如我们只需要存放值的之后,选择 Collection 接口下的集合,需要保证元素唯一的时候选择 Set下的 TreeSet 或 HashSet,不要则选择 List 下的 ArrayList 或者 LinkedList。
(4)为什么要使用集合?
当我们需要保存一组类型相同的数据的时候,我们选用数组进行存储;
而在实际开发过程中,我们需要存储的数据类型往往是多样的,所以就出现了“集合”,它可以存储不同类型的数据。
而且数组在声明之后,长度不可变,这在开发中非常不方便,因为有些时候你不知道你需要存储多少数据;而使用集合基本不存在这样的问题,它的存储非常灵活,它可以存储不同类型不同数量的对象,并且可以保存 key - value 关系的数据。
(5)ArrayList 和 Vector 的区别?
ArrayList 是 List 的主要实现类,它的底层是数组 Object[],适合于频繁的查找工作,但是线程不安全,性能更好。在扩容的时候容量变为原来的1.5倍。
Vector 是 List 的古老实现类,它的底层是数组 Object[],线程安全,性能较低。在扩容时容量变为原来的2倍。
更现代的线程安全 List 实现类:CopyOnWriteArrayList(需要线程安全的时候用这个)
(6)ArrayList 和 LinkedList
1、线程安全:它们都是不同步的,也就是都不是线程安全的。
2、底层数据结构:ArrayList 底层是数组,LinkedList 底层是双向链表。(1.6之前是循环链表)
3、插入和删除:
ArrayList 默认插入到尾部,时间复杂度是O(1),如果插入到位置 i ,时间复杂度是O(n-i),因为需要移动位置;
LinkedList 可以在头尾进行插入和删除,此时时间复杂度是O(1),如果需要在指定位置 i 进行插入和删除,时间复杂度为O(n),因为要先遍历寻找到位置 i 再进行操作。
4、快速随机访问:ArrayList 支持,LinkedList 不支持。
5、内存空间占用:ArrayList 空间浪费在尾部预留的空间;LinkedList 空间浪费在每个元素耗费更多空间。
项目中一般不会用到 LinkedList,它的作者 Joshua Bloch 自己说从来不会使用 LinkedList。 - -
(7)双向链表和双向循环链表(1.6 1.7 LinkedList)


它们的区别就在于:双向循环链表的头节点的 prev 指向尾节点;而其尾节点的 next 指向头节点。双向链表头节点的 prev 指向 null;尾结点的 next 指向 null。
(8)RandomAccess 接口
该接口为空,它存在的意义就是标识实现这个接口的类有快速随机访问的能力。
例如:ArrayList 底层实现了 RandomAccess 接口,而 LinkedList 没有实现,关键在于它们的底层数据结构不同。ArrayList 本身就可以实现快速随机访问,因为其底层是一个 Object 数组。而不是因为其实现了 RandomAccess 。
(9)ArrayList 的扩容机制是怎么样的?
ArrayList 的无参构造方法创建 ArrayList的时候,实际上初始化赋值了一个空数组,只有当向其中添加元素的时候才会分配空间。
ArrayList 每次扩容后容量会变为原来的1.5倍左右 int new = old + (old >> 1);
详见 黑马程序员
(10)comparable 和 Comparator 的区别
comparable 接口出自 java.lang 包,它有一个 compareTo(Object obj) 方法用来排序。
Comparator 接口出自 java.util 包,它有一个 compare(Object obj1, Object obj2) 方法用来排序。
当需要对集合进行自定义排序的时候,例如对 song 对象 歌名 / 歌手 顺序进行排序的时候,我们可以通过重写 comparable 的 compareTo 方法和 使用自制的 Comparator 方法;或者以两个 Comparator 来实现排序,这种方法代表我们只能使用两个参数版的 Collection.sort()。
定制排序的编写方法:
1、comparable(对于没有实现 Comparable 接口的类,必须实现其才能通过重写 compareTo 方法进行排序)
![]()
重写方法

2、 Comparator 定制排序

(11)无序性和不可重复性的含义是什么?
无序性
无序性不等于随机性,无序性是指存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值进行添加的。
不可重复性
是指添加的元素按照 equals() 进行判断的时候,返回值为false。
(12)HashSet、LinkedHashSet、TreeSet三者有何异同?
它们是 Set 接口的三个实现类,它们都能保证元素唯一且都不是线程安全的。
它们的区别在于底层的数据结构不同。HashSet 的底层数据结构为 HashMap;LinkedHashSet 的底层是 HashMap 和 链表,取出元素的顺序满足 FIFO;TreeSet 的底层数据结构为红黑树,排序的方法有自然排序和定制排序。
(13)Queue 和 Deque 有什么区别?
Queue 是单端队列,只能从队尾进行数据的添加,队首进行数据的删除。一般满足 FIFO。
Queue 拓展了 Collection 接口,根据 因为容量不足而导致的数据操作失败,一类方法在失败后会抛出异常,一类方法在失败后会返回特殊值。

Deque 拓展了 Queue,它是一个双端队列,可以从队尾队首任意一端进行数据的添加和删除,同样根据数据操作失败后的处理分为两类方法。

Deque 还有 push() 和 pop() 方法可以用来模拟栈。
(14)ArrayDeque 和 LinkedList 的区别是什么?
ArrayDeque 和 LinkedList 都实现了 Deque 接口,它们都具有队列的功能。

(15)你知道 PriorityQueue 吗?
PriorityQueue 在 JDK1.5 中被引入,它与 Queue 的区别在于:队列是 FIFO 的;而优先队列先出队的元素是优先级最高的元素。
要点:
1、PriorityQueue 利用二叉堆的数据结构进行实现,底层使用可变长的数据来存储数据。
2、PriorityQueue 的时间复杂度为 O(logn),即堆排序的时间复杂度。
3、PriorityQueue 不是线程安全的,且不能存储 null 和 non-comparable 对象。
4、PriorityQueue 默认是最小堆,但可以接收一个 Comparator 参数来自定义排序方法(优先级大小)。
PriorityQueue 在面试中经常出现于手撕算法中,尤其是堆排序、求第K大数等等,需要熟练掌握。
(16)HashMap 和 Hashtable 的区别是什么?
1、HashMap 不是线程安全的,Hashtable 是线程安全的。
2、HashMap 效率高于 Hashtable(因为线程安全问题)。
3、HashMap 可以存储 null key 和 null value;Hashtable 不支持存储 null key 和 null value。
4、HashMap 默认容量为11,每次扩充变成 2n+1; Hashtable 默认大小为 16,每次扩充变成 2n。
HashMap 如果给定容量,它会初始化为 2 的幂次大小;Hashtable 会直接使用你给定的大小。
5、HashMap 底层数据结构使用的是数组、链表和红黑树;Hashtable 未使用红黑树。
* HashMap 中使用 2 的幂作为哈希表的大小代码。

这里做一下讲解:
我们希望使用 2 的幂大小,在二进制看来,实际上就是使得其最高位的下一位变为1,其余都为0(除了本身就是 2 的幂大小的数,这就是为什么 n 需要先减1)
那么我们的做法是这样的:
1、第1次将该数右移1位,与原数做或运算,这样就会有2位变成1;
2、第2次将该数右移2位,与原数做或运算,这样就会有4位变成1;
3、第3次将该数右移4位,与原数做或运算,这样就会有8位变成1;
4、第4次将该数右移8位,与原数做或运算,这样就会有16位变成1;
2、第5次将该数右移16位,与原数做或运算,这样就会有32位变成1;
这样就可以保证一个 int 类型的数在 + 1 之后一定是 2 的幂次大小,因为二进制数字如果都是1的话,那么他加一后就是首位为1其他位都是0,这个数字肯定是 2 的幂次方。
某次过程:

当某个数较小的时候,后面会有一些多余的运算但效率影响很小。
为什么 HashMap 的长度为什么需要是2的幂次方?
为了能让hashMap存取高效,尽量减少碰撞,也就是要尽量把数据分配均匀。在插入数据之前做取模运算,得到的余数就是将要存放的数据在哈希表中对应的下标。在HashMap中这个下标的取值算法是:(n - 1) & hash n是哈希表的长度。

(17)HashMap 和 HashSet 有什么区别?

(18)HashMap 和 TreeMap 有什么区别?
HashMap 和 TreeMap 都继承自 AbstractMap,但是 TreeMap 还实现了 NavigableMap 和 SortedMap 接口。
Navigable 接口让 TreeMap 有了对集合内元素进行搜索的能力;
SortedMap 接口让 TreeMap 有了对 key 进行排序的能力(默认升序)。
Lambda 表达式实现自定义排序:

综上,TreeMap 相比 HashMap 有了对集合内元素搜索的能力和按照 key 进行排序的能力。
(19)HashSet 如何检查重复?
当把对象加入到 HashSet 中时,首先会计算对象的 hashcode 是否存在相同值;如果不存在则加入,如果存在相同的 hashcode,则使用 equals 方法判断它们是否真的一致;如果相同,HashSet就不会让加入操作成功。
(20)HashMap 的底层实现
1.8之前
HashMap 底层是 数组和链表 结合在一起实现。
HashMap 通过 key 的 hashcode 经过扰动函数后得到 hash 值,再通过 (n - 1) & hash 得到 value 需要插入的位置。如果当前位置存在元素的话,则比较它们是否相同。如果不同则使用拉链法解决冲突,如果相同的话直接进行覆盖。
* 扰动函数
扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法的原因是防止一些实现比较差的 hashcode() 方法产生影响,减小碰撞概率。

1.8之后
当链表长度大于阈值(默认为8)(将链表转换为红黑树之前对数组的长度进行判断,如果数组长度小于 64 先进行扩容,大于 64 才进行红黑树转换)时,将链表转换为红黑树,减少搜索时间。
为什么不使用二叉搜索树?
原因:二叉搜索树在某种情况下会退化成线性结构,而红黑树是一个平衡的二叉搜索树,可以避免这种情况。
(21)HashMap 多线程操作导致死循环问题
这个问题就是前面说的那个 头插法 导致的死循环问题。
在 1.8 之后得到了解决
(22)HashMap 有哪几种常见的遍历方式?
HashMap 有七种遍历方式

1、使用迭代器(Iterator)EntrySet 的方式进行遍历;
public class EntrySet {public static void main(String[] args) {Map<Integer, String> map = new HashMap<>();map.put(1, "Java");map.put(2, "JDK");map.put(3, "Spring Framework");map.put(4, "MyBatis framework");Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();while(iterator.hasNext()){Map.Entry<Integer, String> entry = iterator.next();System.out.println(entry.getKey());System.out.println(entry.getValue());}}
}2、使用迭代器(Iterator)KeySet 的方式进行遍历;
public class KeySet {public static void main(String[] args) {Map<Integer, String> map = new HashMap<>();map.put(1, "Java");map.put(2, "JDK");map.put(3, "Spring Framework");map.put(4, "MyBatis framework");Iterator<Integer> iterator = map.keySet().iterator();while(iterator.hasNext()){Integer key = iterator.next();System.out.println(key);System.out.println(map.get(key));}}
}3、使用 For Each EntrySet 的方式进行遍历;
public class foreachEntrySet {public static void main(String[] args) {Map<Integer, String> map = new HashMap<>();map.put(1, "Java");map.put(2, "JDK");map.put(3, "Spring Framework");map.put(4, "MyBatis framework");for(Map.Entry<Integer,String> entry : map.entrySet()){System.out.println(entry.getKey());System.out.println(entry.getValue());}}
}4、使用 For Each KeySet 的方式进行遍历;
public class foreachKeySet {public static void main(String[] args) {Map<Integer, String> map = new HashMap<>();map.put(1, "Java");map.put(2, "JDK");map.put(3, "Spring Framework");map.put(4, "MyBatis framework");for(Integer key : map.keySet()){System.out.println(key);System.out.println(map.get(key));}}
}5、使用 Lambda 表达式的方式进行遍历;
public class lambda {public static void main(String[] args) {Map<Integer, String> map = new HashMap<>();map.put(1, "Java");map.put(2, "JDK");map.put(3, "Spring Framework");map.put(4, "MyBatis framework");map.forEach((key, value) ->{System.out.println(key);System.out.println(value);});}
}6、使用 Streams API 单线程的方式进行遍历;
public class streams1 {public static void main(String[] args) {Map<Integer, String> map = new HashMap<>();map.put(1, "Java");map.put(2, "JDK");map.put(3, "Spring Framework");map.put(4, "MyBatis framework");map.entrySet().stream().forEach((entry) -> {System.out.println(entry.getKey());System.out.println(entry.getValue());});}
}7、使用 Streams API 多线程的方式进行遍历。
public class streams {public static void main(String[] args) {Map<Integer, String> map = new HashMap<>();map.put(1, "Java");map.put(2, "JDK");map.put(3, "Spring Framework");map.put(4, "MyBatis framework");map.entrySet().parallelStream().forEach((entry) -> {System.out.println(entry.getKey());System.out.println(entry.getValue());});}
}性能:
 可以看出 EntrySet 的执行完成时间最短,性能最好;然后是 stream 和 keySet,性能最差的是 lambda表达式。
可以看出 EntrySet 的执行完成时间最短,性能最好;然后是 stream 和 keySet,性能最差的是 lambda表达式。
结论:entrySet 的性能比 keySet 的性能要高出一倍之多,所以我们应该尽量使用 entrySet 来进行Map 集合的遍历。
(23)ConcurrentHashMap 和 Hashtable 的区别是什么?
它们都是线程安全的,但是在实现线程安全的方式不同。
实现线程安全的方式
ConcurrentHashMap
1.7 的时候,ConcurrentHashMap 对整个桶数组进行了分割分段(Segment,分段锁),每一把锁只锁容器内其中一部分数据,多线程访问不同数据段内的数据的时候不存在冲突,可以提高并发访问率。

1.8 的时候,ConcurrentHashMap 摒弃了 Segment,转而使用 Node数组 + 链表 + 红黑树的数据结构进行实现,并发控制使用 synchronized 和 CAS 进行操作。整个就是 HashMap 进行优化且线程安全的升级版本。

Hashtable
也是使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法是,另一个线程也访问该方法,另一个线程可能进入阻塞或者轮询,这会导致竞争越来越激烈,效率越来越低。
(24)ConcurrentHashMap 线程安全的具体实现方法 / 底层具体实现?
1.8 之前
首先将数据分为 segment 的段进行存储,给每一段数据都配一把锁,当其中一个线程占用锁访问一段数据的时候,其他段的数据可以被访问。
数据结构:Segment 数组 和 HashEntry 数组
Segment 集成了 ReentrantLock,所以 Segment 是一种可重入锁。HashEntry 用于存储键值对数据。

一个 ConcurrentHashMap 包含一个 Segment 数组,该数组默认大小为 16,也就是默认最高可并发线程数为 16(并发写)。
Segment 的结构和 HashMap 类似,是一种由数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 数组保存链表元素。每个 Segment 守护对应的 HashEntry 数组。这也就是说对 HashEntry 数组内的元素进行修改的时候,首先获得对应的 Segment 的锁。
1.8 之后
ConcurrentHashMap 取消了 Segment 分段锁,采用 Node + CAS + synchronized 来保证并发安全,数据结构和 HashMap 1.8 的结构类似。Java 8 中,锁的粒度更细,synchronized 只锁定当前链表或红黑树的首节点,这样只要 hash 不冲突,就不会发生并发,就不会影响其他 Node 的读写,效率大幅提升。

相关文章:
Java 2.2 - Java 集合
Java 集合,也叫做容器,主要是由两大接口派生而来:一个是 Collection 接口,主要用于存放单一元素;另一个是 Map 接口,主要用于存放键值对。对于 Collection 接口,其下又有三个主要的子接口&#…...

Linux驱动.之I2C,iic驱动层(二)
一、 Linux下IIC驱动架构 本篇只分析,一个整体框架。 1、首先说说,单片机,的i2c硬件接口图,一个i2c接口,通过sda和scl总线,外接了多个设备device,通过单片机,来控制i2c的信号发生&…...

【STM32】USART串口和I2C通信
个人主页~ USART串口和I2C通信 USART串口一、串口1、简介2、电路要求3、参数及时序 二、USART外设1、USART结构2、波特率发生器 三、数据包1、HEX数据包HEX数据包接收 2、文本数据包文本数据包接收 I2C通信一、简介二、通信协议1、硬件电路2、I2C时序基本单元 三、I2C外设1、简…...

【Material-UI】按钮组:垂直按钮组详解
文章目录 一、按钮组概述1. 组件介绍2. 基本用法 二、垂直按钮组的应用场景1. 导航菜单2. 表单操作3. 选项切换 三、按钮组的样式定制1. 变体(Variants)2. 颜色(Colors) 四、垂直按钮组的优势1. 空间利用2. 可读性与易用性3. 视觉…...

DDR5 的优势与应用
DDR5 是新一代 DRAM 内存,具有一系列强大的功能,可提升可靠性、可用性和可维护性 (RAS),降低能耗并显著提高性能。请查看下方表格,了解 DDR4 和 DDR5 之间的一些主要特性差异。 DDR5 的优势 特性/选项 DDR4DDR5DDR5 优势数据速率…...

STM32 - 笔记
1 STM32的串口通信 【keysking的STM32教程】 第8集 STM32的串口通信_哔哩哔哩_bilibili 波特律动 串口助手...

基于QT实现的简易WPS(已开源)
一、开发工具及开源地址: 开发工具:QTCreator ,QT 5 开源地址: GitHub - Whale-xh/WPS_official: Simple WPS based on QTSimple WPS based on QT. Contribute to Whale-xh/WPS_official development by creating an acc…...
)
Flask-WTF 表单处理详细教程(第六阶段)
目录 Flask-WTF 表单处理详细教程1. 安装 Flask-WTF2. 创建 Flask 应用3. 创建表单类表单字段解释: 4. 渲染表单渲染模板CSRF 保护 5. 表单验证6. 处理错误7. 完整示例8. 结论 Flask-WTF 表单处理详细教程 Flask-WTF 是 Flask 框架的一个扩展,简化了 We…...

C语言 | Leetcode C语言题解之第330题按要求补齐数组
题目: 题解: int minPatches(int* nums, int numsSize, int n) {int patches 0;long long x 1;int index 0;while (x < n) {if (index < numsSize && nums[index] < x) {x nums[index];index;} else {x << 1;patches;}}retu…...

无人机之测绘行业篇
无人机倾斜摄影技术凭借快速高效、机动灵活、成本低等优势,正慢慢颠覆传统测绘的作业方式,已成为测绘行业的“新宠”,将倾斜摄影技术应用到无人机上,实际上就是在做一个三维模型,而建立起来的这个模型更加真实…...

Java编程:每日挑战
目录 题目1.一个抽象类并不需要其中所有的方法都是抽象的。( )2.下面有关java hashmap的说法错误的是?A. HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。B. HashMap 的实现不是同步的,意味着它不…...

【自动驾驶】ubuntu server安装桌面版
目录 安装桌面版当锁屏界面使用root用户登录错误时 这里环境一开始是ubuntu20.04服务器版本 安装桌面版 sudo apt-get update sudo apt-get upgrade apt-get install -y ubuntu-desktop # 如果你不想安装一些附加的程序,可用以下命令 sudo apt install --no-instal…...
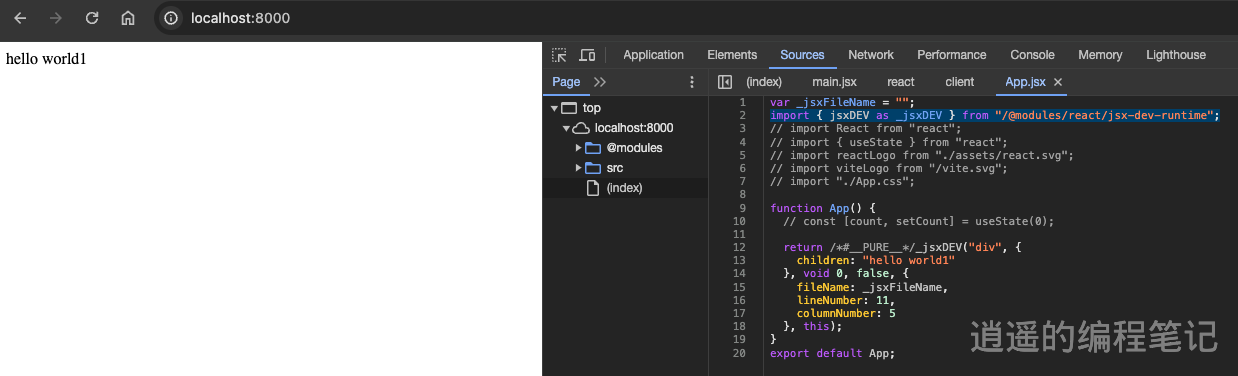
前端模块化-手写mini-vite
前言 本文总结了一些关于 Vite 的工作原理,以及一些实现细节。 本节对应的 demo 可以在这里找到。 什么是 Vite Vite 是一个基于浏览器原生 ES imports 的开发服务器。利用浏览器去解析 imports,在服务器端按需编译返回,完全跳过了打包这个…...

SpringBoot中fastjson扩展: 自定义序列化和反序列化方法实战
❃博主首页 : 「码到三十五」 ,同名公众号 :「码到三十五」,wx号 : 「liwu0213」 ☠博主专栏 : <mysql高手> <elasticsearch高手> <源码解读> <java核心> <面试攻关> ♝博主的话 :…...

【QT】鼠标按键事件 - QMouseEvent QKeyEvent
qt 事件 事件1. 事件概念2. 事件的处理3. 按键事件(1)单个按键(2)组合按键 4. 鼠标事件(1)鼠标单击事件(2)鼠标释放事件(3)鼠标双击事件(4&#x…...

纯手工在内网部署一个Docker私有仓库
纯手工在内网部署一个Docker私有仓库 下载Docker仓库的镜像上传仓库的镜像导入仓库的镜像启动仓库镜像配置客户端的Docker上传镜像到本地仓库从本地仓库拉取镜像 下载Docker仓库的镜像 这个镜像不太好找,有需要的可以从下面的地址中下载。 通过百度网盘分享的文件…...

农林经济管理学报
《农林经济管理学报》是由江西省教育厅主管、江西农业大学主办、北京大学中国农业政策研究中心和中国人民大学农业与农村发展学院学术支持的农林经管类学术双月刊,以主要刊载农林经济政策与理论,反映农林经济管理前沿动态和研究成果,开展学术…...

【初阶数据结构题目】16.用队列实现栈
用队列实现栈 点击链接答题 思路: 出栈:找不为空的队列,将size-1个数据导入到另一个队列中。 入栈:往不为空队列里面插入数据 取栈顶元素: 例如: 两个队列: Q1:1 2 3Q2:…...

使用 OpenAI Whisper v2 模型进行中英文混合语音识别
https://huggingface.co/openai/whisper-large-v2 使用 OpenAI Whisper 模型进行中英文混合语音识别 在本篇博客中,我们将详细介绍如何使用 OpenAI 的 Whisper 模型进行中英文混合语音识别,并设置 Hugging Face 的缓存路径。 简介 Whisper 是 OpenAI 提供的一个强大的自动…...

代码随想录算法训练营day37|动态规划part05
完全背包问题; 第一题:518. Coin Change II class Solution {public int change(int amount, int[] coins) {//递推表达式int[] dp new int[amount 1];//初始化dp数组,表示金额为0时只有一种情况,也就是什么都不装dp[0] 1;fo…...

PP-DocLayoutV3部署实操:Linux环境权限配置+start.sh执行问题解决
PP-DocLayoutV3部署实操:Linux环境权限配置start.sh执行问题解决 1. 项目概述与核心价值 PP-DocLayoutV3是一个专门用于处理非平面文档图像的布局分析模型,能够智能识别文档中的各种元素布局。与传统的矩形框检测不同,它支持多点边界框预测…...

DJI Payload-SDK实战指南:构建工业级无人机智能载荷的完整方案
DJI Payload-SDK实战指南:构建工业级无人机智能载荷的完整方案 【免费下载链接】Payload-SDK DJI Payload SDK Official Repository 项目地址: https://gitcode.com/gh_mirrors/pa/Payload-SDK 作为系统集成商和解决方案提供商,您是否正在寻找一种…...

PyTorch模型保存超简单
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 PyTorch模型保存的深度实践:超越简单save()的可复现性革命目录PyTorch模型保存的深度实践:超越简单save(…...

Qwen-Image-Edit-F2P实战:QT图形界面开发指南
Qwen-Image-Edit-F2P实战:QT图形界面开发指南 1. 学习目标与前置准备 今天咱们来聊聊怎么用QT给Qwen-Image-Edit-F2P模型做个图形界面。这个模型挺有意思的,它能根据一张人脸照片生成全身像,比如你把自拍照传进去,它能给你生成在…...

如何构建 Flink SQL 任务的血缘分析
版本一:干燥苦涩、缺乏深度(反面回答素材)面试者语气:(机械地背诵,没有眼神交流,缺乏实践细节)“关于 Flink SQL 的血缘分析,我认为主要分为以下几个步骤:首先…...
实时互动艺术装置:LumiPixel Canvas Quest结合摄像头生成动态肖像
实时互动艺术装置:LumiPixel Canvas Quest结合摄像头生成动态肖像 1. 项目背景与核心价值 在当代艺术展览中,观众往往只是被动的观赏者。LumiPixel Canvas Quest项目打破了这种单向关系,通过实时图像处理和生成技术,让每位参观者…...

granite-4.0-h-350m效果展示:中英双语问答、代码补全、文本摘要三连击
granite-4.0-h-350m效果展示:中英双语问答、代码补全、文本摘要三连击 今天带大家看看一个轻量级但能力不俗的AI模型——granite-4.0-h-350m。这个模型虽然只有3.5亿参数,但在多个任务上的表现却让人眼前一亮。我用Ollama部署了它的文本生成服务&#x…...

5分钟掌握BepInEx:Unity游戏插件开发的终极框架指南
5分钟掌握BepInEx:Unity游戏插件开发的终极框架指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 如果你正在寻找一个强大、稳定且易于使用的Unity游戏插件开发框架&…...

OpenClaw+千问3.5-9B:自动化学习笔记整理系统
OpenClaw千问3.5-9B:自动化学习笔记整理系统 1. 为什么需要自动化笔记整理 作为一个长期与技术文档打交道的开发者,我发现自己陷入了一个困境:每天阅读大量技术文章、论文和在线课程,但收集的笔记却散落在不同平台——有些在One…...

如何在 React 中正确绑定 onClick 事件以避免类型错误
React 中 onClick 期望接收一个函数,若传入字符串或直接执行表达式(如 window.href...)会导致“Expected onclick listener to be a function”报错;正确做法是使用箭头函数包裹逻辑。 react 中 onclick 期望接收一个函数&am…...