机器学习练手(四):基于SVM 的肥胖风险分类
总结:本文为和鲸python 机器学习原理与实践·闯关训练营资料整理而来,加入了自己的理解(by GPT4o)
原活动链接
原作者:vgbhfive,多年风控引擎研发及金融模型开发经验,现任某公司风控研发工程师,对数据分析、金融模型开发、风控引擎研发具有丰富经验。
在上一关中学习了如何训练决策树模型、可视化决策树、计算特征重要性、计算 r2 分数指标等内容,下面我们将学习今天的内容 SVM 支持向量机。
目录
- SVM
- 肥胖风险数据集之二分类问题
- 引入依赖
- 加载数据
- 数据基础分析
- 特征预处理
- 训练模型
- 如何确定核函数?
- 重新建立模型预测测试集并计算指标
- 总结
- 课后思考题
- 闯关题
vgbhfive,多年风控引擎研发及金融模型开发经验,现任某公司风控研发工程师,对数据分析、金融模型开发、风控引擎研发具有丰富经验。
总结:依然重点关注对于数据的处理及模型核函数的选取,包括:
删除空值(删除前观察空值分布)
查看非数值型数据的分布,使用LabelEncoder()处理数据
查看各维度与预测值的相关性,并删除相关性较小的维度
在SVM模型构建中通过定义不同的核函数并进行交叉验证来评估每种核函数的性能,注意需要对数据集进行标准化,否则定义不同核函数的SVM并进行交叉验证时会很慢,尤其是sigmoid核函数,一晚上都跑不完。进行标准化转换后,几分钟出结果。
SVM
SVM 支持向量机,指定义在特征空间上的间隔最大的线性分类器。单从名字来看该算法是最摸不着头脑的算法,不过在了解其定义之后可以明白其是对逻辑回归的演进,其重点在于扩展特征维度空间。
在之前在逻辑回归问题中,会将日常问题抽象为二维特征空间内的问题,那如果将日常问题映射到三维特征空间,或者多维特征空间,会不会更好区分呢?
而 SVM 的重点就是求解该映射关系的参数,映射关系在 SVM 中被称为核函数。
目前可用的核函数有以下:
- 线性核(
Linear Kernel):适用于线性可分的数据。如果你的数据在特征空间中可以通过一条直线分割,线性核可能是一个好选择。它计算速度快,参数少,对于一般数据,分类效果已经很理想。 - 多项式核函数:适用于非线性问题,可以将特征映射到更高次幂的多项式空间。核函数的阶数由参数
degree决定,决策边界为多项式的曲面。 - 径向基函数(
RBF)核:又称高斯核,适用于线性不可分的数据。RBF核可以将数据映射到一个高维空间,使得数据在新的空间中更容易分割。其具有更多的参数,并且分类结果非常依赖于参数的选择,通过训练数据的交叉验证来寻找合适的参数是常见的做法,但这个过程可能比较耗时。 Sigmoid核函数:类似于神经网络的激活函数,适用于需要逻辑回归模型的决策边界,即收拢最终的结果只在一定边界内。
肥胖风险数据集之二分类问题
随着现在生活水平的提高,现在已经不必为了吃饱肚子而是为了更好吃的食物,因此导致的肥胖问题也更加严重。为了更好地理解肥胖的成因,预测个体的肥胖风险,并为预防和治疗提供支持,现计划开发一个基于机器学习的肥胖风险评估模型。该数据集收集了大量人群的健康数据,共有20758 例记录,其中包括年龄、性别、体重、身高、家族肥胖史、身体活动量、饮食习惯、运动方式等特征信息。
肥胖风险数据集数据含义如下:
| 特征列名称 | 特征含义 |
|---|---|
| Gender | 性别 |
| Age | 年龄 |
| Height | 身高 |
| Weight | 体重 |
| family_history_with_overweight | 家族肥胖史 |
| FAVC | 是否频繁食用高热量食物 |
| FCVC | 食用蔬菜的频次 |
| NCP | 食用主餐的次数 |
| CAEC | 两餐之间的食品消费:always(总是);frequently(经常);sometimes(有时候) |
| SMOKE | 是否吸烟 |
| CH2O | 每日耗水量 |
| SCC | 高热量饮料消耗量 |
| FAF | 运动频率 |
| TUE | 使用电子设备的时间 |
| CALC | 酒精消耗量:0(无); frequently(经常);sometimes(有时候) |
| MTRANS | 日常交通方式:Automobile(汽车);Bike(自行车);Motorbike(摩托车);Public Transportation(公共交通);Walking(步行) |
| 0be1dad | 肥胖水平 |
引入依赖
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltfrom sklearn import svm
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
加载数据
# 1. 加载数据obesity = pd.read_csv('./data/obesity_level-4.csv', index_col='id')
obesity.head()
| Gender | Age | Height | Weight | family_history_with_overweight | FAVC | FCVC | NCP | CAEC | SMOKE | CH2O | SCC | FAF | TUE | CALC | MTRANS | 0be1dad | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||
| 0 | Male | 24.443011 | 1.699998 | 81.669950 | 1 | 1 | 2.000000 | 2.983297 | Sometimes | 0 | 2.763573 | 0 | 0.000000 | 0.976473 | Sometimes | Public_Transportation | Overweight_Level_II |
| 1 | Female | 18.000000 | 1.560000 | 57.000000 | 1 | 1 | 2.000000 | 3.000000 | Frequently | 0 | 2.000000 | 0 | 1.000000 | 1.000000 | 0 | Automobile | 0rmal_Weight |
| 2 | Female | 18.000000 | 1.711460 | 50.165754 | 1 | 1 | 1.880534 | 1.411685 | Sometimes | 0 | 1.910378 | 0 | 0.866045 | 1.673584 | 0 | Public_Transportation | Insufficient_Weight |
| 3 | Female | 20.952737 | 1.710730 | 131.274851 | 1 | 1 | 3.000000 | 3.000000 | Sometimes | 0 | 1.674061 | 0 | 1.467863 | 0.780199 | Sometimes | Public_Transportation | Obesity_Type_III |
| 4 | Male | 31.641081 | 1.914186 | 93.798055 | 1 | 1 | 2.679664 | 1.971472 | Sometimes | 0 | 1.979848 | 0 | 1.967973 | 0.931721 | Sometimes | Public_Transportation | Overweight_Level_II |
数据基础分析
# 2. 数据基础分析obesity.info()
# 数据项各列不存在空值
<class 'pandas.core.frame.DataFrame'>
Index: 20758 entries, 0 to 20757
Data columns (total 17 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 Gender 20758 non-null object 1 Age 20758 non-null float642 Height 20758 non-null float643 Weight 20758 non-null float644 family_history_with_overweight 20758 non-null int64 5 FAVC 20758 non-null int64 6 FCVC 20758 non-null float647 NCP 20758 non-null float648 CAEC 20758 non-null object 9 SMOKE 20758 non-null int64 10 CH2O 20758 non-null float6411 SCC 20758 non-null int64 12 FAF 20758 non-null float6413 TUE 20758 non-null float6414 CALC 20758 non-null object 15 MTRANS 20758 non-null object 16 0be1dad 20758 non-null object
dtypes: float64(8), int64(4), object(5)
memory usage: 2.9+ MB
# 3. 结果列的分布情况obesity['0be1dad'].value_counts()
0be1dad
Obesity_Type_III 4046
Obesity_Type_II 3248
0rmal_Weight 3082
Obesity_Type_I 2910
Insufficient_Weight 2523
Overweight_Level_II 2522
Overweight_Level_I 2427
Name: count, dtype: int64
特征预处理
# 4. 对分类型特征值进行编码lb = LabelEncoder()
columns = ['Gender', 'CAEC', 'CALC', 'MTRANS', '0be1dad']
for col in columns:obesity[col] = lb.fit_transform(obesity[col])
# 5. 查看各个特征与结果列的相关性# 选择数值型列
numeric_cols = obesity.select_dtypes(include=[float, int]).columns# 计算相关性矩阵
correlation_matrix = obesity[numeric_cols].corr()
# 提取与 'Price' 列相关的相关性值
price_correlation = correlation_matrix['0be1dad']# 打印结果
print(price_correlation)
# print(cars.corr()['Price'])
Gender 0.033655
Age 0.269122
Height 0.073753
Weight 0.410058
family_history_with_overweight 0.298750
FAVC 0.016886
FCVC 0.054972
NCP -0.089360
CAEC 0.175111
SMOKE -0.008864
CH2O 0.182406
SCC -0.051350
FAF -0.097437
TUE -0.056894
CALC 0.124926
MTRANS -0.081371
0be1dad 1.000000
Name: 0be1dad, dtype: float64
from sklearn.preprocessing import StandardScaler
# 初始化特征缩放器
scaler = StandardScaler()
# 缩放特征
x_scaled = scaler.fit_transform(obesity[numeric_cols])
# 将缩放后的特征转换为 DataFrame
x_scaled = pd.DataFrame(x_scaled, columns=numeric_cols)
# 6. 拆分特征列和结果列y = obesity['0be1dad']
x = x_scaled
# x = obesity.drop('0be1dad', axis=1)
x.head(), y.head()
( Gender Age Height Weight family_history_with_overweight \0 1.004152 0.105699 -0.002828 -0.235713 0.469099 1 -0.995866 -1.027052 -1.606291 -1.170931 0.469099 2 -0.995866 -1.027052 0.128451 -1.430012 0.469099 3 -0.995866 -0.507929 0.120090 1.644770 0.469099 4 1.004152 1.371197 2.450367 0.224054 0.469099 FAVC FCVC NCP CAEC SMOKE CH2O SCC \0 0.30588 -0.836279 0.314684 0.381571 -0.109287 1.206594 -0.185009 1 0.30588 -0.836279 0.338364 -1.475555 -0.109287 -0.048349 -0.185009 2 0.30588 -1.060332 -1.913423 0.381571 -0.109287 -0.195644 -0.185009 3 0.30588 1.039171 0.338364 0.381571 -0.109287 -0.584035 -0.185009 4 0.30588 0.438397 -1.119801 0.381571 -0.109287 -0.081469 -0.185009 FAF TUE CALC MTRANS 0be1dad 0 -1.171141 0.597438 0.605072 0.429319 1.574360 1 0.021775 0.636513 -1.709084 -2.182324 -1.537581 2 -0.138022 1.755239 -1.709084 0.429319 -1.018924 3 0.579896 0.271455 0.605072 0.429319 0.537046 4 1.176486 0.523111 0.605072 0.429319 1.574360 ,id0 61 02 13 44 6Name: 0be1dad, dtype: int32)
训练模型
# 7. 划分训练集和测试集 7:3x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42)
x_train.head(), x_test.head(), y_train.head(), y_test.head()
( Gender Age Height Weight family_history_with_overweight \1846 1.004152 1.434298 0.569868 1.217350 0.469099 14225 -0.995866 -0.713540 1.401081 1.746285 0.469099 9438 1.004152 -0.360075 0.878986 0.079838 0.469099 12459 -0.995866 -0.499620 -0.346409 -0.829748 0.469099 12189 -0.995866 0.286369 -0.825107 0.738886 0.469099 FAVC FCVC NCP CAEC SMOKE CH2O SCC \1846 -3.26926 -0.836279 0.338364 0.381571 -0.109287 -1.691863 -0.185009 14225 0.30588 1.039171 0.338364 0.381571 -0.109287 1.325007 -0.185009 9438 0.30588 0.891433 0.314548 0.381571 -0.109287 0.255443 -0.185009 12459 0.30588 -0.836279 0.338364 0.381571 -0.109287 -0.048349 -0.185009 12189 0.30588 1.039171 0.338364 0.381571 -0.109287 0.862169 -0.185009 FAF TUE CALC MTRANS 0be1dad 1846 -1.171141 2.297369 0.605072 -2.182324 0.018390 14225 0.803717 0.332553 0.605072 0.429319 0.537046 9438 1.410892 -1.024344 0.605072 0.429319 1.055703 12459 0.021775 2.297369 0.605072 0.429319 -1.537581 12189 -1.140380 -0.220215 0.605072 0.429319 0.537046 ,Gender Age Height Weight family_history_with_overweight \10317 -0.995866 0.379434 -0.584893 0.911536 0.469099 4074 1.004152 -1.027052 0.569868 -0.299019 -2.131745 9060 -0.995866 -0.084652 0.150442 -0.120003 0.469099 11286 1.004152 1.083034 -0.338770 0.914090 0.469099 8254 1.004152 -1.202863 -1.033617 -1.436296 -2.131745 FAVC FCVC NCP CAEC SMOKE CH2O SCC \10317 0.30588 1.039171 0.338364 0.381571 -0.109287 -1.211170 -0.185009 4074 0.30588 -0.836279 0.338364 0.381571 -0.109287 -0.048349 -0.185009 9060 0.30588 0.814419 0.338364 0.381571 -0.109287 1.344141 -0.185009 11286 0.30588 -1.638904 0.338364 0.381571 -0.109287 -0.042493 -0.185009 8254 0.30588 -0.836279 0.338364 0.381571 -0.109287 -0.048349 -0.185009 FAF TUE CALC MTRANS 0be1dad 10317 -1.093287 0.157075 0.605072 0.429319 0.537046 4074 0.021775 0.636513 0.605072 0.429319 1.055703 9060 1.214691 -1.020025 -1.709084 0.429319 -0.500267 11286 -1.171141 -0.834247 0.605072 0.429319 0.018390 8254 -1.171141 2.297369 -1.709084 0.429319 -1.018924 ,id1846 314225 49438 512459 012189 4Name: 0be1dad, dtype: int32,id10317 44074 59060 211286 38254 1Name: 0be1dad, dtype: int32)
# 8. 构建SVM 模型svc = svm.SVC(kernel='linear', C=1, gamma='auto')
svc.fit(x_train, y_train)
SVC(C=1, gamma='auto', kernel='linear')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SVC(C=1, gamma='auto', kernel='linear')
如何确定核函数?
# 8.1 在遇到完全陌生的数据集,如何选择 SVM 模型最优核函数?当然是最简单的方法,对不同的核函数进行尝试,根据最后计算得分最高的就是最优核函数# 定义不同的核函数和参数进行尝试
kernels = ['linear', 'rbf', 'poly', 'sigmoid'] # sigmoid运行的很慢,需要将数据进行标准化
# kernels = ['linear', 'rbf', 'poly']# 存储每个参数组合的交叉验证分数
scores = []for kernel in kernels:print(kernel)svc = svm.SVC(kernel=kernel, C=1, gamma='auto')scores.append(cross_val_score(svc, x_train, y_train, cv=5).mean())scores
linear
rbf
poly
sigmoid[0.999587061252581, 0.9905024088093599, 0.9889194769442533, 0.7741913282863042]
综上:模型使用rbf核函数效果最好
sklearn.svm.SVC() 支持向量机参数详解,用法如下:
class sklearn.svm.SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None)
挑选重要性较大的几个参数说明:
C:浮点数,可不填,默认1.0,必须大于等于0,为松弛系数的惩罚项系数。
如果C值设定比较大,那SVC可能会选择边际较小的,能够更好地分类所有训练点的决策边界。如果C的设定值较小,那SVC会尽量最大化边界,决策功能会更简单, 但代价是训练的准确度。 总而言之,C在SVM中的影响就像正则化参数对逻辑回归的影响。kernel:字符,可不填,默认rbf。指定要在算法中使用的核函数类型,可以输入linear,poly,rbf,sigmoid。degree:整数,可不填,默认3。多项式核函数的次数(poly) ,如果核函数没有选择poly,这个参数会被忽略。gamma:浮点数,可不填,默认auto。核函数的系数,仅在参数Kernel的选项为rbf、poly和sigmoid的时候有效。当输入auto, 自动使用1/(n_features)作为gamma的取值。coefo:浮点数,可不填,默认0.0。核函数中的独立项,它只在参数kernel为poly和sigmoid的时候有效。
这段代码尝试使用不同的核函数和参数配置来训练支持向量机(SVM)模型,并使用交叉验证评估每个配置的性能。具体步骤如下:
代码解析
# 导入所需的库
from sklearn import svm
from sklearn.model_selection import cross_val_score
定义核函数和初始化参数
# 定义要尝试的不同核函数
kernels = ['linear', 'rbf', 'poly', 'sigmoid']# 用于存储每个参数组合的交叉验证分数
scores = []
kernels列表定义了四种不同的核函数:线性核(linear)、径向基核(rbf)、多项式核(poly)和 Sigmoid 核(sigmoid)。scores列表用于存储每种核函数对应的交叉验证分数的平均值。
迭代不同核函数,训练模型并评估
for kernel in kernels:# 使用当前核函数定义 SVM 分类器svc = svm.SVC(kernel=kernel, C=1, gamma='auto')# 对当前分类器进行交叉验证,cv=5 表示使用 5 折交叉验证cv_scores = cross_val_score(svc, x_train, y_train, cv=5)# 计算交叉验证分数的平均值并存储在 scores 列表中scores.append(cv_scores.mean())
for kernel in kernels::遍历每种核函数。svc = svm.SVC(kernel=kernel, C=1, gamma='auto'):定义 SVM 分类器,设置当前核函数、惩罚参数C=1,以及核系数gamma='auto'。kernel=kernel:设置当前的核函数。C=1:惩罚参数,较小的 C 值会使模型更宽松,较大的 C 值会使模型对错误分类更敏感。gamma='auto':核系数,对于 RBF、多项式和 Sigmoid 核函数有影响。设置为 ‘auto’ 时,gamma值为1 / n_features。
cv_scores = cross_val_score(svc, x_train, y_train, cv=5):对当前分类器进行 5 折交叉验证,返回每次验证的分数。scores.append(cv_scores.mean()):计算交叉验证分数的平均值,并存储在scores列表中。
输出交叉验证分数
scores
- 最终,
scores列表包含了每种核函数对应的交叉验证分数的平均值。这些分数可以用于比较不同核函数在该数据集上的表现。
总结
这段代码通过定义不同的核函数并进行交叉验证来评估每种核函数的性能。最终,scores 列表包含了每种核函数在 5 折交叉验证中的平均得分,便于比较和选择最佳的核函数。
重新建立模型预测测试集并计算指标
# 9. 预测测试集
svc = svm.SVC(kernel='rbf', C=1, gamma='auto')
svc.fit(x_train, y_train)y_pred = svc.predict(x_test)
y_pred
array([4, 5, 2, ..., 1, 2, 1])
# 10. 计算测试集的平均准确率和预测测试集准确率acc = accuracy_score(y_test, y_pred)svc.score(x_test, y_test), acc
(0.9932562620423893, 0.9932562620423893)
总结
SVM 支持向量机采用扩展维度空间的方式进行分类,从而避免了之前逻辑回归的二维空间内的问题(线性不可分)。SVM 在扩展维度空间后,即当前数据线性可分,通过计算间隔最大化的分离超平面将数据分开,其对未知数据的预测性是最强的。
课后思考题
- 当训练数据线性不可分时,为何引入核函数就可以可分?(对偶问题)
闯关题
Q1. svm中的核函数下面解释正确的是?(多选题)
A. linear 线性分类核函数,适用于线性可分的数据。
B. poly 适用于非线性的问题。
C. rbf 适用于线性不可分的数据。
D. sigmoid 适用于需要逻辑回归模型的决策边界。
关于支持向量机(SVM)中的核函数,下面的解释中哪些是正确的?(多选题)
A. linear 线性分类核函数,适用于线性可分的数据。
B. poly 适用于非线性的问题。
C. rbf 适用于线性不可分的数据。
D. sigmoid 适用于需要逻辑回归模型的决策边界。
下面是对每个选项的解释:
A. linear 线性分类核函数,适用于线性可分的数据。
- 正确。线性核函数适用于线性可分的数据集,即数据可以通过一个线性决策边界分开。
B. poly 适用于非线性的问题。
- 正确。多项式核函数(poly)适用于非线性的问题,通过增加特征空间的维度使得线性不可分的数据在高维空间中变得可分。
C. rbf 适用于线性不可分的数据。
- 正确。径向基函数核(rbf)适用于线性不可分的数据,通过映射到高维空间,可以使得原本线性不可分的数据在高维空间中变得可分。
D. sigmoid 适用于需要逻辑回归模型的决策边界。
- 正确。Sigmoid 核函数与神经网络中的激活函数类似,适用于某些类型的二分类问题,并可以产生类似于逻辑回归的决策边界。
综上所述,正确的答案是:
A, B, C, D
Q2. SVM出现欠拟合时,下面哪些可以解决?(欠拟合是指模型不能在训练集上获得足够低的误差,即模型训练较少,没有充分从训练集中学习到规律。)
A. 增大惩罚参数 C 的值
B. 减小惩罚参数 C 的值
C. 减小核系数(gamma参数)
SVM 出现欠拟合时,以下哪些可以解决问题?(欠拟合是指模型不能在训练集上获得足够低的误差,即模型训练较少,没有充分从训练集中学习到规律。)
A. 增大惩罚参数 C 的值
B. 减小惩罚参数 C 的值
C. 减小核系数(gamma 参数)
解释
-
A. 增大惩罚参数 C 的值:
- 正确。惩罚参数 C 控制的是对误分类的惩罚程度。增大 C 的值会使模型对训练集中的误分类样本惩罚更大,从而使模型更关注训练数据,减少欠拟合的可能性。
-
B. 减小惩罚参数 C 的值:
- 不正确。减小 C 的值会使模型对误分类样本的惩罚变小,导致模型更加宽容,从而可能增加欠拟合的风险。
-
C. 减小核系数(gamma 参数):
- 不正确。减小 gamma 的值会使得 RBF 核函数的作用范围变大,从而可能导致模型变得更简单,更容易出现欠拟合。相反,增大 gamma 的值可以使模型变得更加复杂,减少欠拟合。
综上所述,正确的解决方案是:
A. 增大惩罚参数 C 的值
Q3. 使用iris 数据集基于SVM 训练模型计算其准确率是多少?
A. 1
B. 0.99
C. 0.98
D. 0.97
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn import svmiris = load_iris()
x, y = iris.data, iris.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42)svc = svm.SVC(kernel='linear', C=1, gamma='auto')
svc.fit(x_train, y_train)
y_pred = svc.predict(x_test)acc = accuracy_score(y_test, y_pred)
acc
1.0
#填入你的答案并运行,注意大小写
a1 = 'ABCD' # 如 a1= 'A'
a2 = 'A' # 如 a2= 'A'
a3 = 'A' # 如 a3= 'A'
相关文章:
:基于SVM 的肥胖风险分类)
机器学习练手(四):基于SVM 的肥胖风险分类
总结:本文为和鲸python 机器学习原理与实践闯关训练营资料整理而来,加入了自己的理解(by GPT4o) 原活动链接 原作者:vgbhfive,多年风控引擎研发及金融模型开发经验,现任某公司风控研发工程师&…...

AutoGPT项目实操总结
AutoGPT项目介绍 AutoGPT是一个基于GPT-4的开源项目,旨在简化用户与语言模型的交互过程,使文本生成和信息收集更轻松、更高效。它具备互联网搜索、长短期记忆管理、调用大模型进行文本生成、存储和总结文件等能力,并且可以通过插件扩展功能与…...

uniapp 荣耀手机 没有检测到设备 运行到Android手机 真机运行
背景: 使用uniapp框架搭建的项目,开发的时候在浏览器运行,因为项目要打包成App,所以需要真机联调,需要运行到Android手机,在手机上查看/运行项目。通过真机调试才能确保软件开发的准确性和页面显示的完整性…...
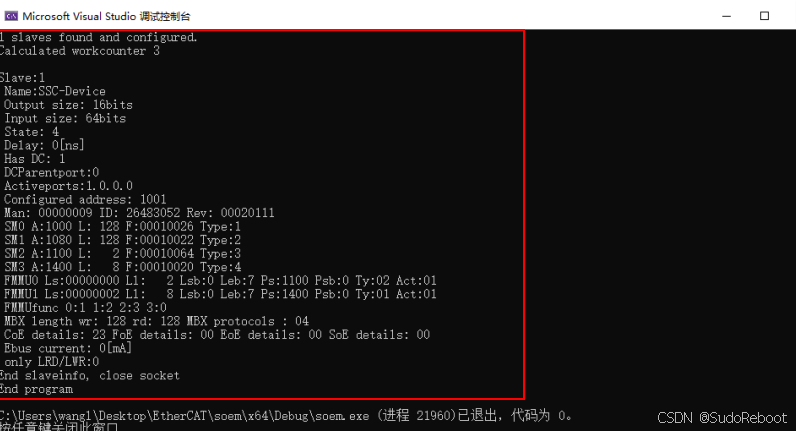
【EtherCAT】Windows+Visual Studio配置SOEM主站——静态库配置+部署
目录 一、准备工作 1. Visual Studio 2022 2. Npcap 1.79 3. SOEM源码 二、静态库配置 1. 修改SOEM源码配置 2. 编译SOEM源码 3. 测试 三、静态库部署 1. 新建Visual Studio工程 2. 创建文件夹 3. 创建主函数 4. 复制静态库 5. 复制头文件 6. 配置头文件…...

【Python小游戏示例:猜拳游戏】
当然可以!以下是一个简单的Python小游戏示例:猜拳游戏。在这个游戏中,玩家将与计算机进行猜拳(石头、剪刀、布)。 import randomdef get_computer_choice():choices [石头, 剪刀, 布]return random.choice(choices)d…...

多态实现的必要条件,实现多态的三个方法,输入一个URL的过程,死锁产生的原理和条件,进程和线程的定义及区别,进程通信的几种方式
继承:面相对象编程中的核心概念,子类可以使用父类的属性和方法,无需重新编写,子类还可以添加新的属性和方法来提供特定的实现多态:同一件事,发生在不同的对象上,会产生不同的结果,传递不同的对象会调用对应类中的方法重载(Overload),同一个类中多个同名的方法,参数列表不同,提高…...

Springboot+MybatisPlus项目中,数据库表中存放Date,查出后转为String
新增一条记录时,数据库表中会有一个gmt_created 的字段,存放创建时间。 该值在数据库中的默认值为:CURRENT_TIMESTAMP 在对应的JavaBean中,该值为 gmtCreated, 那么问题来了: 如何让在表中的Date类型&…...

JavaDS —— AVL树
前言 本文章将介绍 AVL 树的概念,重点介绍AVL 树的插入代码是如何实现的,如果大家对 AVL 树的删除(还是和二叉搜索树一样使用的是替换删除法,然后需要判断是否进行旋转调整)感兴趣的话,可以自行去翻阅其他…...

NSSCTF练习记录:[SWPUCTF 2021 新生赛]jicao
题目: 这段PHP代码的意思是: 对index.php文件进行语法高亮显示,插入flag.php文件,变量id的值为POST传递的值,变量json的值为GET传递的json类型的值。当id值为wllmNB且json中含有键为“x”,值为“wllm”的时…...
LabVIEW位移检测系统
工业控制器的位移检测在保证机械设备精确运行中发挥着重要的作用。开发了一种基于LabVIEW的高精度位移检测系统,该系统通过集成硬件与软件的优化配置,实现了对工业控制器位移的精确测量和分析。 项目背景 在传统工业生产中,位移检测系统往往…...
)
02、MySQL-DML(数据操作语言)
目录 1、添加数据(INSERT) 2、修改数据(UPDATE) 3、删除数据(DELETE) 1、添加数据(INSERT) 注意: 插入数据时,指定的字段顺序需要与值的顺序是一一对应的字符串和日期型数据应该包含在引号中插入的数据大小,应该在字段的规定范围内 给指定…...

vue3 项目部署到线上环境,初始进入系统,页面卡顿大概一分钟左右,本地正常无卡顿。localStorage缓存1MB数据导致页面卡顿。
使用vue3进行项目开发,前端框架使用jeecg-boot进行开发,项目初期,打包部署到生产环境,无异常。某天,进行前端项目打包部署到生产环境,突然出现异常情况,部署到线上环境,初始进入系统…...

软件更新中的风险识别与质量保证机制分析
您好,我是程序员小羊! “微软蓝屏”事件暴露了网络安全哪些问题? 近日,一次由微软视窗系统软件更新引发的全球性“微软蓝屏”事件,不仅成为科技领域的热点新闻,更是一次对全球IT基础设施韧性与安全性…...

QT下载与安装
我们要下载开源的QT,方式下载方式: 官网 登录地址:http://www.qt.io.com 点击右上角的Download. Try.按钮;进入一下画面: 如果进入的是以下画面: 直接修改网址:www.qt.io/download-dev; 改为w…...

Java 2.2 - Java 集合
Java 集合,也叫做容器,主要是由两大接口派生而来:一个是 Collection 接口,主要用于存放单一元素;另一个是 Map 接口,主要用于存放键值对。对于 Collection 接口,其下又有三个主要的子接口&#…...

Linux驱动.之I2C,iic驱动层(二)
一、 Linux下IIC驱动架构 本篇只分析,一个整体框架。 1、首先说说,单片机,的i2c硬件接口图,一个i2c接口,通过sda和scl总线,外接了多个设备device,通过单片机,来控制i2c的信号发生&…...

【STM32】USART串口和I2C通信
个人主页~ USART串口和I2C通信 USART串口一、串口1、简介2、电路要求3、参数及时序 二、USART外设1、USART结构2、波特率发生器 三、数据包1、HEX数据包HEX数据包接收 2、文本数据包文本数据包接收 I2C通信一、简介二、通信协议1、硬件电路2、I2C时序基本单元 三、I2C外设1、简…...

【Material-UI】按钮组:垂直按钮组详解
文章目录 一、按钮组概述1. 组件介绍2. 基本用法 二、垂直按钮组的应用场景1. 导航菜单2. 表单操作3. 选项切换 三、按钮组的样式定制1. 变体(Variants)2. 颜色(Colors) 四、垂直按钮组的优势1. 空间利用2. 可读性与易用性3. 视觉…...

DDR5 的优势与应用
DDR5 是新一代 DRAM 内存,具有一系列强大的功能,可提升可靠性、可用性和可维护性 (RAS),降低能耗并显著提高性能。请查看下方表格,了解 DDR4 和 DDR5 之间的一些主要特性差异。 DDR5 的优势 特性/选项 DDR4DDR5DDR5 优势数据速率…...

STM32 - 笔记
1 STM32的串口通信 【keysking的STM32教程】 第8集 STM32的串口通信_哔哩哔哩_bilibili 波特律动 串口助手...

告别第三方软件!用Win10远程桌面高效管理家里和公司的电脑,完整设置流程分享
高效混合办公指南:用Win10远程桌面无缝连接家庭与工作电脑 混合办公模式已成为现代职场的新常态,无论是居家办公时访问公司电脑处理紧急文件,还是出差途中远程连接家中设备获取资料,Win10内置的远程桌面功能都能提供稳定高效的解决…...
)
解决vue-quill-editor保存后莫名多空行问题(附实测有效CSS方案)
彻底解决vue-quill-editor保存后空行异常问题:从原理到实战 最近在Vue项目中使用vue-quill-editor时,发现一个令人头疼的问题:每次保存后重新打开编辑器,内容之间总会莫名其妙地多出空行。特别是当使用标题样式(h1-h6…...

C++技术岗面试经验总结
🎬 胖咕噜的稞达鸭:个人主页🔥 个人专栏: 《数据结构》《C初阶高阶》 《Linux系统学习》 《算法日记》⛺️技术的杠杆,撬动整个世界! 1. 右值引用和左值引用的区别 左值是我们平常使用的函数对象,表达式结束后依旧存在…...

手柄适配终极方案:DS4Windows实现跨平台控制器无缝体验
手柄适配终极方案:DS4Windows实现跨平台控制器无缝体验 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 当你兴冲冲地将PlayStation手柄连接到PC,却发现游戏完全没有…...

wan2.1-vae开源模型价值:免授权商用+自主可控+私有化部署保障
wan2.1-vae开源模型价值:免授权商用自主可控私有化部署保障 1. 为什么选择wan2.1-vae开源模型 在当今AI图像生成领域,商业使用往往面临授权费用高、数据隐私风险等问题。wan2.1-vae作为基于Qwen-Image-2512模型的开源解决方案,提供了三大核…...

深入解析Xilinx PCIe IP核示例工程的仿真与调试技巧
1. Xilinx PCIe IP核示例工程快速入门 第一次接触Xilinx PCIe IP核时,我完全被复杂的文件结构和专业术语搞懵了。后来发现,只要掌握几个关键点,就能快速上手这个强大的高速串行通信接口。PCIe(Peripheral Component Interconnect …...

Claude Code智能体与CasRel模型协作:自动化数据标注流水线
Claude Code智能体与CasRel模型协作:自动化数据标注流水线 1. 引言 做关系抽取项目,最头疼的是什么?十有八九的工程师会告诉你:是数据标注。传统的人工标注,不仅耗时费力,成本高昂,而且面对复…...

Appium自动化测试卡在iOS签名?手把手教你搞定Provisioning Profile与entitlements不匹配的坑
Appium自动化测试卡在iOS签名?手把手教你搞定Provisioning Profile与entitlements不匹配的坑 当你兴致勃勃地准备开始iOS自动化测试时,突然遇到"Provisioning profile doesnt match the entitlements files value for the get-task-allow entitleme…...

pandas高效筛选技巧:如何精准匹配与排除DataFrame中的特定字符串列
1. 字符串筛选的常见场景与痛点 做数据分析的朋友们应该都遇到过这样的需求:从海量数据中快速找出包含特定关键词的记录。比如电商平台要筛选出所有包含"促销"字样的商品标题,或者客服系统需要过滤掉所有包含"投诉"关键词的工单。这…...

OpenClaw技能市场挖掘:Phi-3-mini-128k-instruct适配插件精选
OpenClaw技能市场挖掘:Phi-3-mini-128k-instruct适配插件精选 1. 为什么需要为Phi-3-mini定制技能? 当我第一次在本地部署Phi-3-mini-128k-instruct模型时,发现这个128k超长上下文的小模型特别适合处理办公场景的文档流。但直接通过OpenCla…...