知识图谱学习总结
1 知识图谱的介绍
知识图谱,是结构化的语义知识库,用于迅速描述物理世界中的概念及其相互关系,通过知识图谱能够将Web上的信息、数据以及链接关系聚集为知识,使信息资源更易于计算、理解以及评价,并能实现知识的快速响应和推理。
1.1知识图谱的应用
当下知识图谱已在工业领域得到了广泛应用,如搜索领域的Google搜索、百度搜索,社交领域的领英经济图谱,企业信息领域的天眼查企业图谱,电商领域的淘宝商品图谱,O2O领域的美团知识大脑,医疗领域的丁香园知识图谱,以及工业制造业知识图谱等。
 1.2知识图谱构建分类
1.2知识图谱构建分类
识图谱的构建技术主要有自顶向下和自底向上两种。
- 自顶向下构建:借助百科类网站等结构化数据源,从高质量数据中提取本体和模式信息,加入到知识库里。
- 自底向上构建:借助一定的技术手段,从公开采集的数据中提取出资源模式,选择其中置信度较高的信息,加入到知识库中。

1.3 “实体-关系-实体”三元组
下图是典型的知识图谱样例示意图。可以看到,“图谱”中有很多节点,如果两个节点之间存在关系,他们就会被一条无向边连接在一起,这个节点我们称为实体(Entity),节点之间的这条边,我们称为关系(Relationship)。
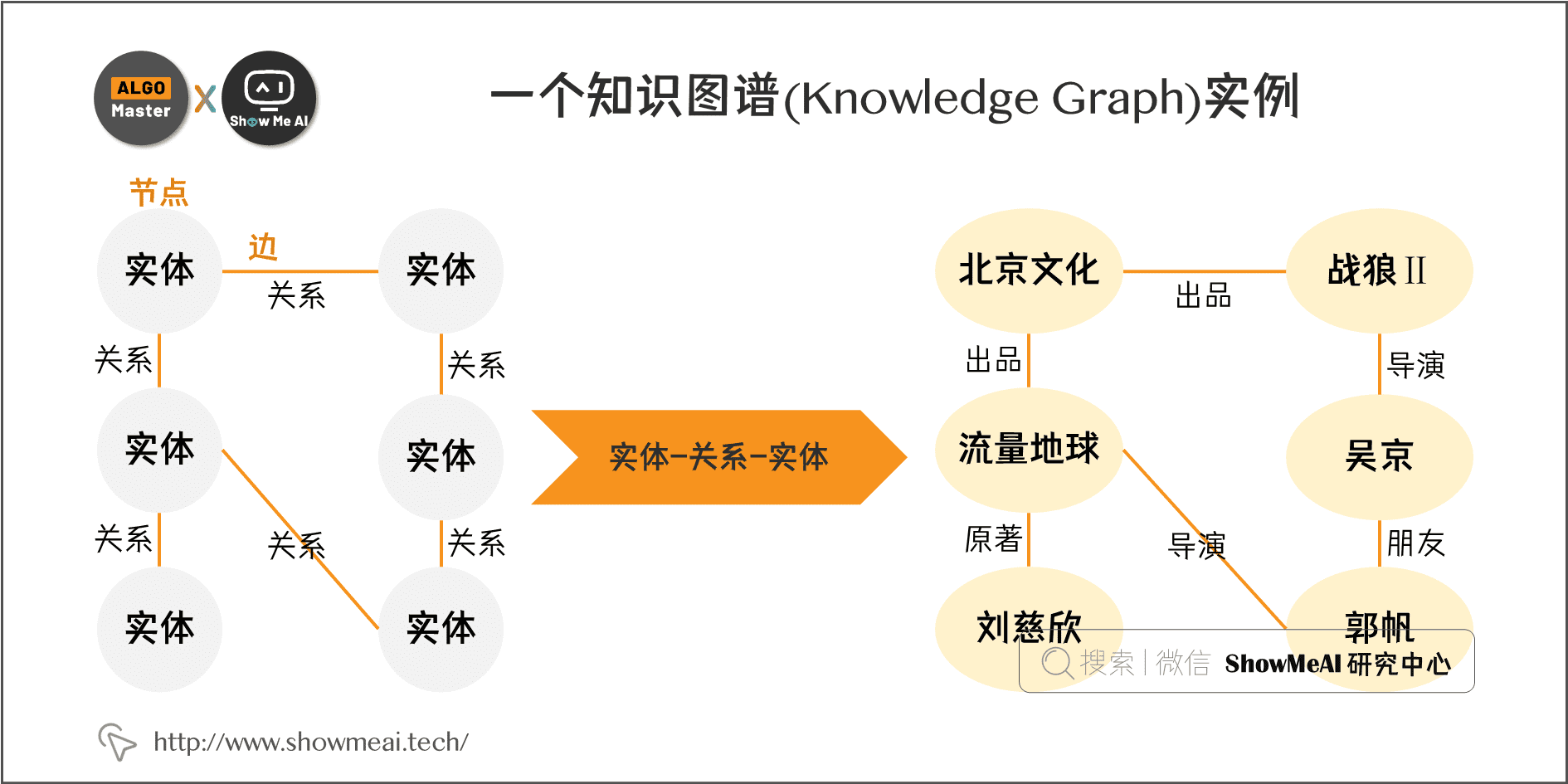
知识图谱的基本单位,就是“实体(Entity)-关系(Relationship)-实体(Entity)” 构成的三元组,这也是知识图谱的核心。
二、数据类型和存储方式
知识图谱的原始数据类型一般来说有三类(也是互联网上的三类原始数据):
- 结构化数据(Structed Data),如:关系数据库、链接数据
- 半结构化数据(Semi-Structured Data),如:XML、JSON、百科
- 非结构化数据(Unstructured Data),如:图片、音频、视频
 典型的半结构化数据样例如下:
典型的半结构化数据样例如下:

如何存储上面这三类数据类型呢?
两种选择:
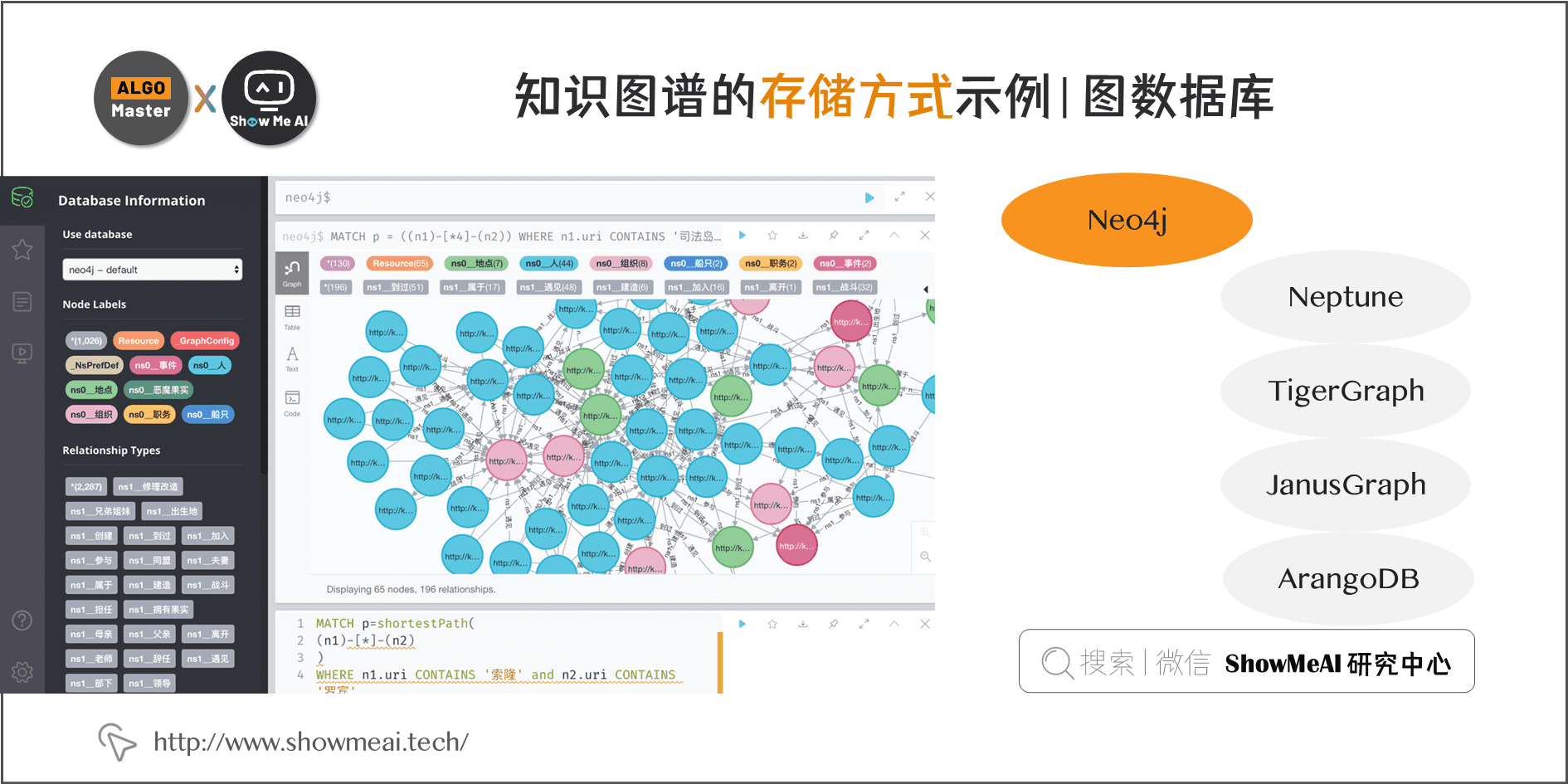
可以通过 RDF(资源描述框架)这样的规范存储格式来进行存储,比较常用的有 Jena等。
另一种方法是使用 图数据库来进行存储,常用的有 Neo4j等。
注意:
截止目前为止,看起来知识图谱主要是一堆三元组,那用关系数据库来存储可以吗?
对,从技术上来说,用关系数据库来存储知识图谱(尤其是简单结构的知识图谱),是完全没问题的。但一旦知识图谱变复杂,用传统的「关系数据存储」,查询效率会显著低于「图数据库」。在一些涉及到2,3度的关联查询场景,图数据库能把查询效率提升几千倍甚至几百万倍。
而且基于图的存储在设计上会非常灵活,一般只需要局部的改动即可。当你的场景数据规模较大的时候,建议直接用图数据库来进行存储。
三、知识图谱的架构
知识图谱的架构主要可以被分为:
- 逻辑架构
- 技术架构
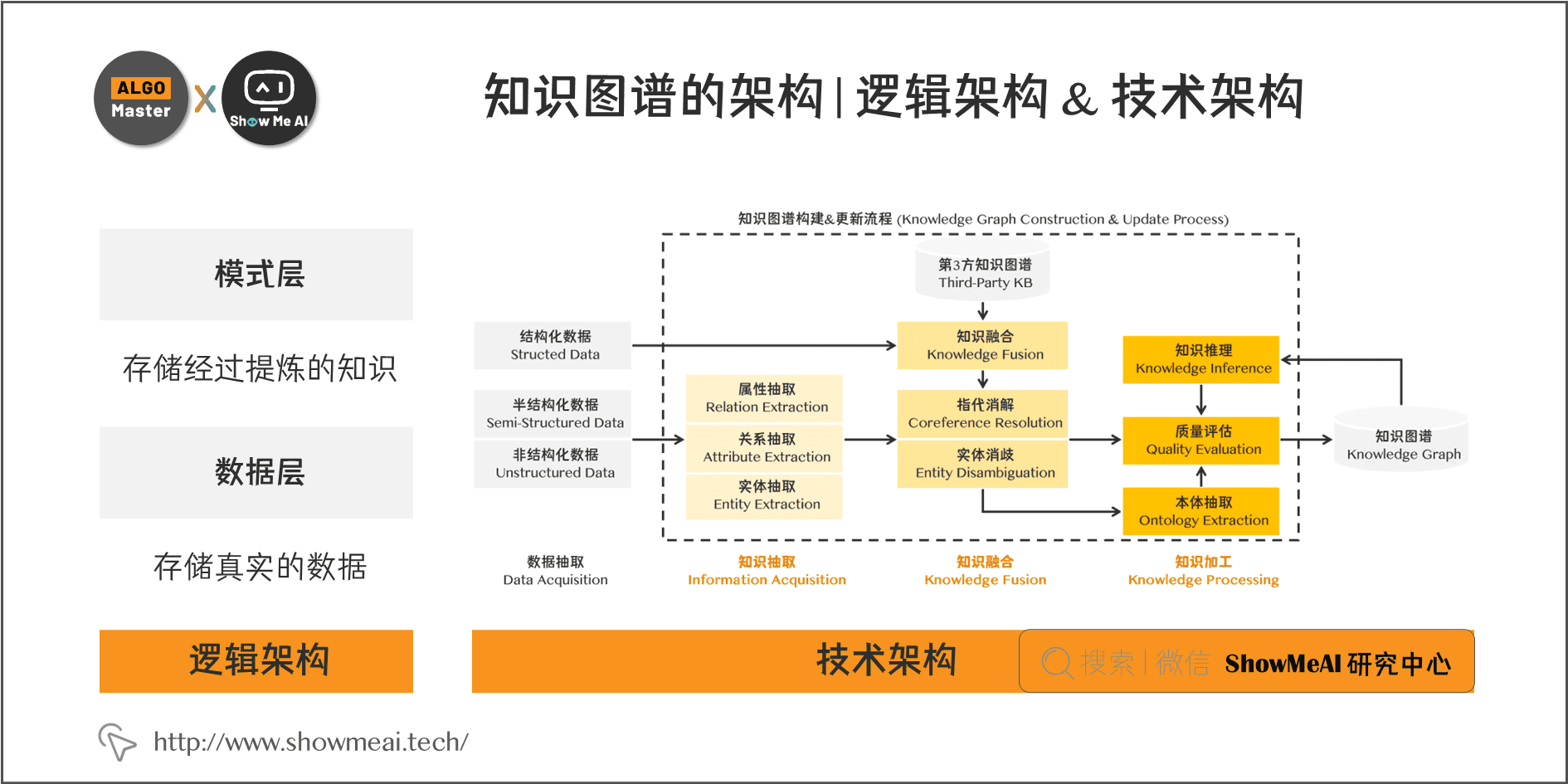
3.1 逻辑架构
在逻辑上,我们通常将知识图谱划分为两个层次:数据层和模式层。
- 模式层:在数据层之上,是知识图谱的核心,存储经过提炼的知识,通常通过本体库来管理这一层(本体库可以理解为面向对象里的“类”这样一个概念,本体库就储存着知识图谱的类)。
- 数据层:存储真实的数据。
可以看看这个例子:
- 模式层: 实体-关系-实体,实体-属性-性值
- 数据层:吴京-妻子-谢楠,吴京-导演-战狼Ⅱ
3.2 技术架构
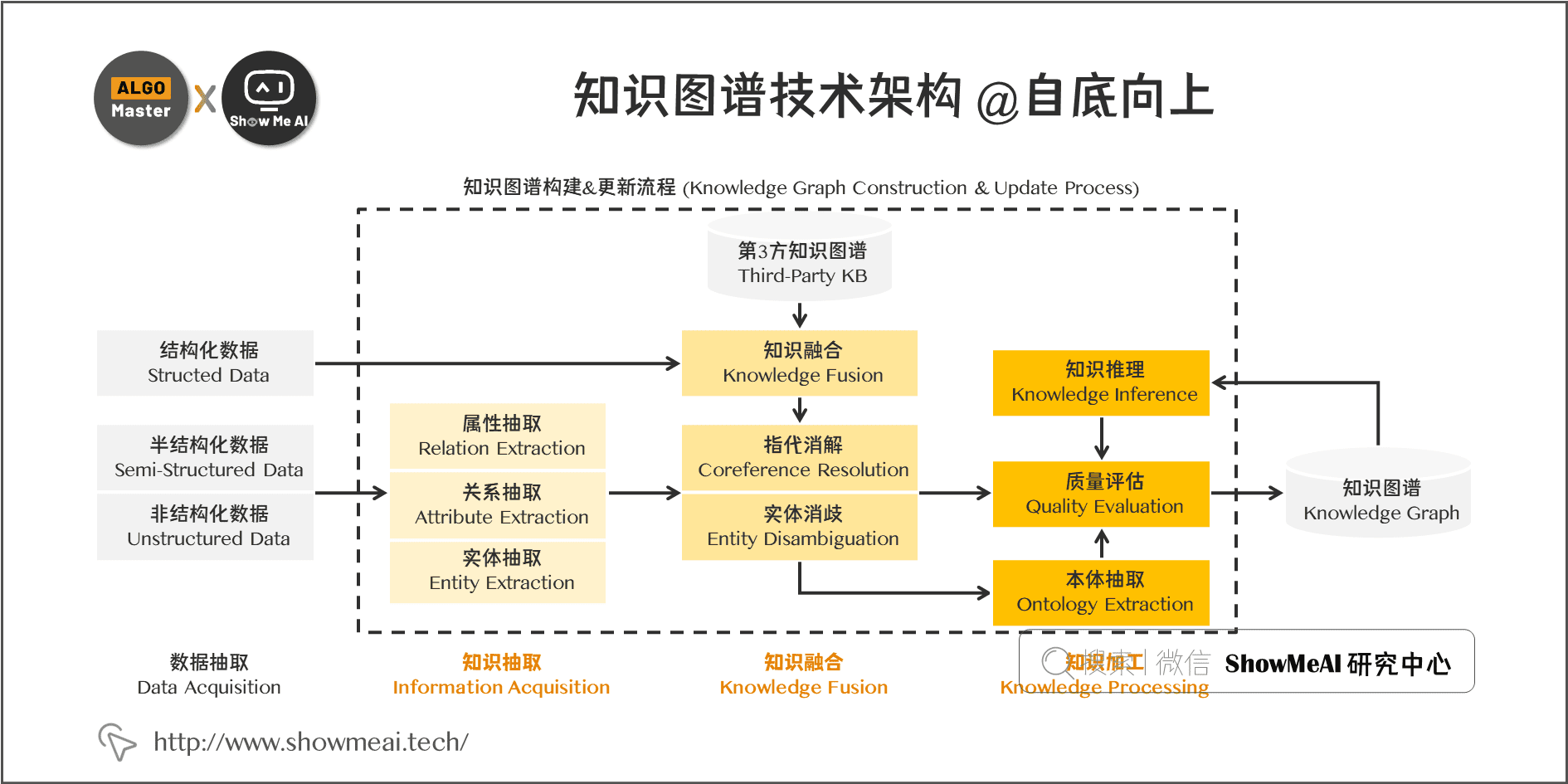
知识图谱的整体架构如图所示,其中虚线框内的部分为知识图谱的构建过程,同时也是知识图谱更新的过程。别紧张,让我们顺着这张图来理一下思路。
- 首先,我们有一大堆的数据,这些数据可能是结构化的、非结构化的以及半结构化的;
- 然后,我们基于这些数据来构建知识图谱,这一步主要是通过一系列自动化或半自动化的技术手段,来从原始数据中提取出知识要素,即一堆实体关系,并将其存入我们的知识库的模式层和数据层。
四、构建技术
前面的内容说到了,知识图谱有自顶向下和自底向上两种构建方式,这里提到的构建技术主要是自底向上的构建技术。
如前所述,构建知识图谱是一个迭代更新的过程,根据知识获取的逻辑,每一轮迭代包含三个阶段:
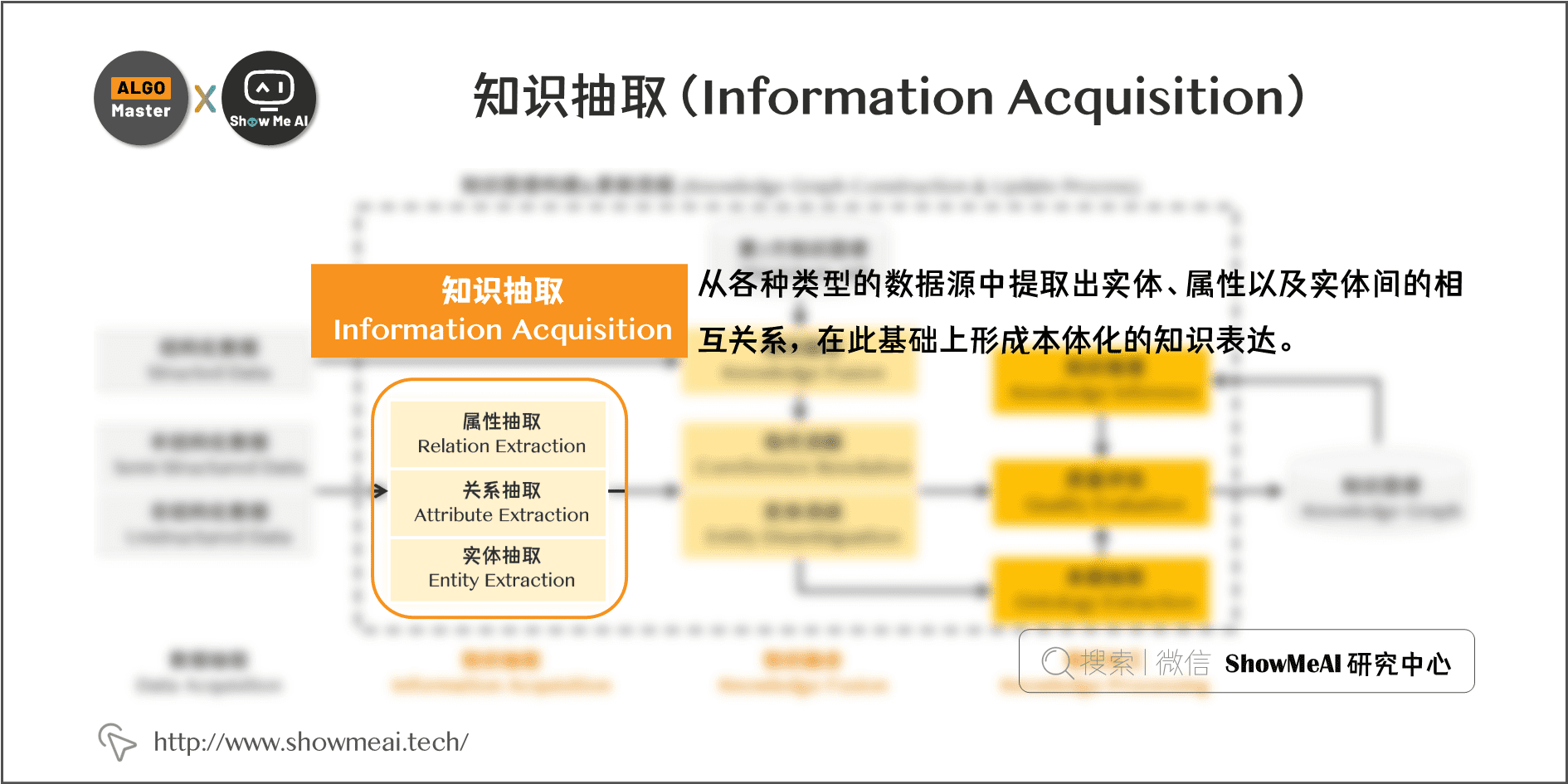
- 信息抽取:从各种类型的数据源中提取出实体、属性以及实体间的相互关系,在此基础上形成本体化的知识表达。
- 知识融合:在获得新知识之后,需要对其进行整合,以消除矛盾和歧义,比如某些实体可能有多种表达,某个特定称谓也许对应于多个不同的实体等。
- 知识加工:对于经过融合的新知识,需要经过质量评估之后(部分需要人工参与甄别),才能将合格的部分加入到知识库中,以确保知识库的质量。
4.1 知识抽取
知识抽取(infromation extraction)是知识图谱构建的第1步,其中的关键问题是:如何从异构数据源中自动抽取信息得到候选指示单元?
信息抽取是一种自动化地从半结构化和无结构数据中抽取实体、关系以及实体属性等结构化信息的技术。涉及的关键技术包括:实体抽取、关系抽取和属性抽取。
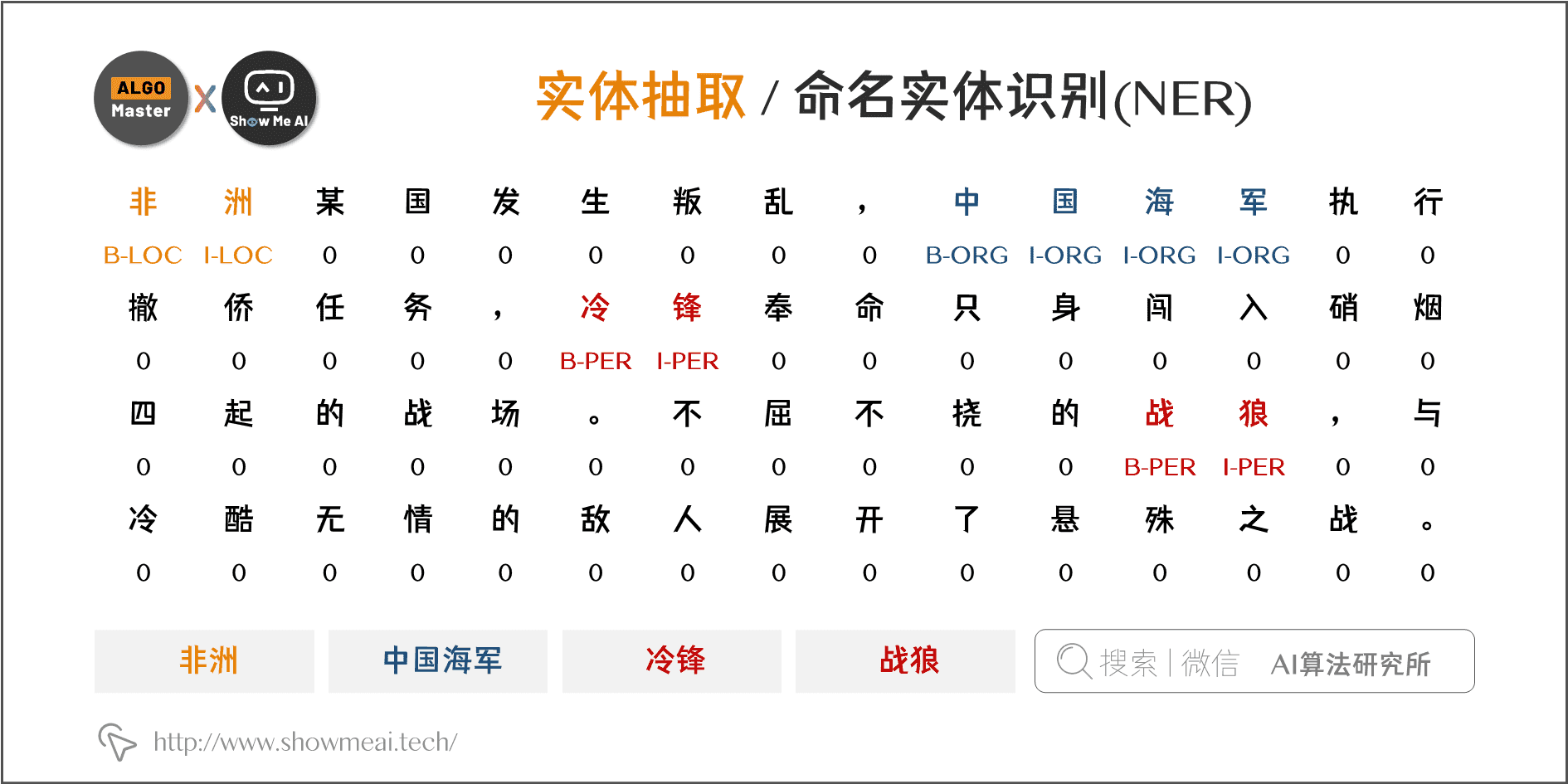
(1)实体抽取
实体抽取,也称为命名实体识别(named entity recognition,NER),是指从文本数据集中自动识别出命名实体。
图中,通过实体抽取我们可以从其中抽取出四个实体:“非洲”、“中国海军”、“冷锋”、“战狼”。
(2)关系抽取
文本语料经过实体抽取之后,得到的是一系列离散的命名实体。为了得到语义信息,还需要从相关语料中提取出实体之间的关联关系,通过关系将实体联系起来,才能够形成网状的知识结构。这就是关系抽取需要做的事,如下图所示。

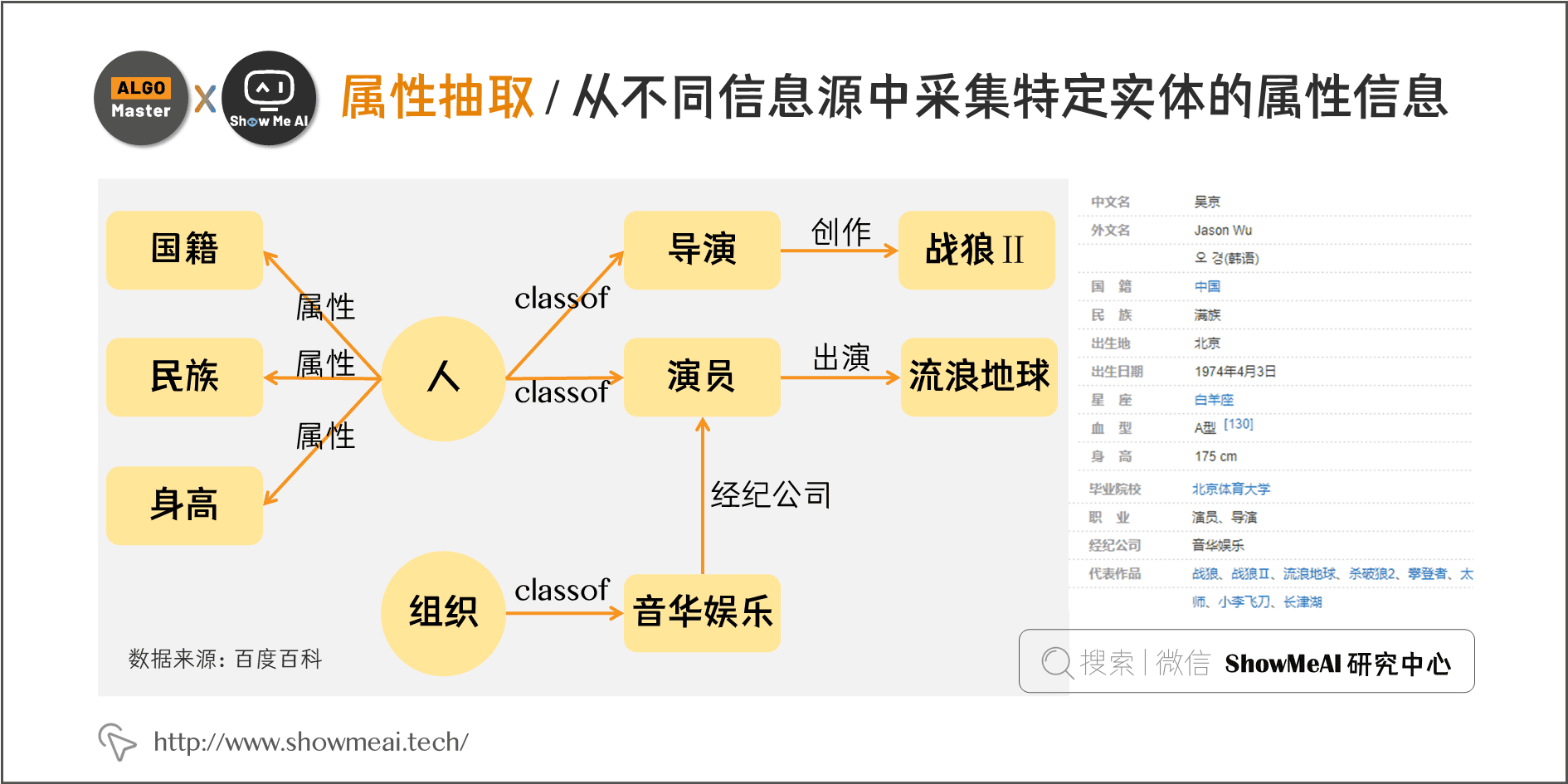
(3)属性抽取
属性抽取的目标是从不同信息源中采集特定实体的属性信息,如针对某个公众人物,可以从网络公开信息中得到其昵称、生日、国籍、教育背景等信息。
相关文章:
知识图谱学习总结
1 知识图谱的介绍 知识图谱,是结构化的语义知识库,用于迅速描述物理世界中的概念及其相互关系,通过知识图谱能够将Web上的信息、数据以及链接关系聚集为知识,使信息资源更易于计算、理解以及评价,并能实现知识的快速响…...

2021-10-23 51单片机LED1-8按秒递增闪烁
缘由51单片机,八个LED灯按LED1亮1s灭1s,LED1亮2s 灭2s以此类推的方式亮灭-编程语言-CSDN问答 #include "REG52.h" sbit K1 P1^0; sbit K2 P1^1; sbit K3 P1^2; sbit K4 P1^3; sbit P1_0P2^0; sbit P1_1P2^1; sbit P1_2P2^2; sbit P1_3P2^3; sbit P1_…...

在Linux中宏观的看待线程
线程一旦被创建,几乎所有的资源都是被所有的线程共享的。线程也一定要有自己私有的资源,什么样的资源应该是线程私有的? 1.PCB属性私有 2.要有一定的私有上下文结构 3.每个线程都要有独立的栈结构 ps -aL ##1. Linux线程概念 ###什么是线程…...

提示libfakeroot.so或libfakeroot-sysv.so出错处理方法
在RK3588 Buildroot SDK里面,uboot和kernel使用的是prebuild目录下的交叉编译链,而buildroot和APP编译则使用Buildroot生成的交叉编译链来编译(如:位于buildroot/output/rockchip_rk3588/host目录为交叉编译工具链目录)…...

【计算机网络】什么是socket编程?以及相关接口详解
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...

LeetCode.19.删除链表的倒数第n个节点
题目描述: 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点 输入输出实例: 思路:这道题目我们可以用双指针来做,让first和second指针之间的距离为n1,然后我们first和second指针…...

vue-cesium
vue-cesium: Vue 3.x components for CesiumJS. cesium 文档中文版 ArcGisMapServerImageryProvider - Cesium Documentation all参考 https://juejin.cn/post/7258119652726341669 cesium官网 Cesium Sandcastle...

《npm 学习过程中遇到的诸多问题》
npm 开发 1.开发过程中难免会使用到npm ,进行安装第三方包 遇到的问题 match 报错:npm i报错npm ERR! Cannot read property match of undefined 可以尝试清除本地的package-log.json 文件,再试试...

CentOS 介绍
引出 Linux 系统内核与 Linux 发行套件系统的区别? Linux 系统内核指的是一个由 Linus Torvalds(Linux之父,内核主要开发者)负责维护,提供硬件抽象层、磁盘、文件系统控制及多任务功能的系统核心程序。 Linux 发行套…...

模拟面试题1
目录 一、JVM的内存结构? 二、类加载器分为哪几类? 三、讲一下双亲委派机制 为什么要有双亲委派机制? 那你知道有违反双亲委派的例子吗? 四、IO 有哪些类型? 五、Spring Boot启动机制 六、Spring Boot的可执行…...

CTFHUB-web-RCE-综合过滤练习
开启题目 查看网页源代码发现这次网页对 | 、 && 、 || 、 \ 、 / 、; ,都进行了过滤处理 发现换行符 %0a 和回车符 %0d 可以进行测试,在 URL 后面拼接访问 127.0.0.1%0als 用 ls flag_is_here 查看 flag 文件中的内容,发现回显为空…...

Leetcode75-7 除自身以外数组的乘积
没做出来 本来的思路是遍历一遍得到所有乘积和然后除就行 但是题目不能用除法 答案的思路 for(int i0;i<n;i) //最终每个元素其左右乘积进行相乘得出结果{res[i]*left; //乘以其左边的乘积left*nums[i];res[n-1-i]*right; //乘以其右边的乘积right*nums[n-1-i]…...

AI绘画工具介绍:以新奇角度分析与探索AI绘画艺术与技术的交汇点
目录 前言 一、AI绘画工具的前沿技术 1.1 深度学习的进化 1.2 GANs的创新应用 1.3 风格迁移的多样化 1.4 交互式AI绘画的智能化 二、艺术与技术的交汇点 2.1 艺术创作的普及化 2.2 艺术风格的创新 2.3 艺术与科技的深度融合 三、新颖的思考角度 3.1 AI作为艺术创作…...

基于Springboot + Vue的宿舍管理系统
前言 文末获取源码数据库 感兴趣的可以先收藏起来,需要学编程的可以给我留言咨询,希望帮助更多的人 精彩专栏推荐订阅 不然下次找不到哟 Java精品毕设原创实战项目 作者的B站地址:程序员云翼的个人空间-程序员云翼个人主页-哔哩哔哩视频 csd…...

CTFHUB-web-RCE-eval执行
开启题目 查看源码发现直接用蚁剑连接就可以,连接之后发现成功了...

Oracle DBA常用 sql
文章目录 一、基础环境二、常用 sql三、参考资料 版权声明:本文为CSDN博主「杨群」的原创文章,遵循 CC 4.0 BY-SA版权协议,于2023年7月6日首发于CSDN,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.n…...

MindSearch:AI 时代的“思考型”搜索引擎
随着AI技术的飞速发展,搜索引擎领域也迎来了新的变革。继 OpenAI 发布 SearchGPT 之后,国内也涌现出一批优秀的AI搜索引擎,其中,由中科大和上海人工智能实验室联合研发的 MindSearch(思索)尤为引人注目。这…...
:基于SVM 的肥胖风险分类)
机器学习练手(四):基于SVM 的肥胖风险分类
总结:本文为和鲸python 机器学习原理与实践闯关训练营资料整理而来,加入了自己的理解(by GPT4o) 原活动链接 原作者:vgbhfive,多年风控引擎研发及金融模型开发经验,现任某公司风控研发工程师&…...

AutoGPT项目实操总结
AutoGPT项目介绍 AutoGPT是一个基于GPT-4的开源项目,旨在简化用户与语言模型的交互过程,使文本生成和信息收集更轻松、更高效。它具备互联网搜索、长短期记忆管理、调用大模型进行文本生成、存储和总结文件等能力,并且可以通过插件扩展功能与…...

uniapp 荣耀手机 没有检测到设备 运行到Android手机 真机运行
背景: 使用uniapp框架搭建的项目,开发的时候在浏览器运行,因为项目要打包成App,所以需要真机联调,需要运行到Android手机,在手机上查看/运行项目。通过真机调试才能确保软件开发的准确性和页面显示的完整性…...

如何让老照片焕发新生?图像超分技术的4大突破与分辨率增强实践
如何让老照片焕发新生?图像超分技术的4大突破与分辨率增强实践 【免费下载链接】SwinIR SwinIR: Image Restoration Using Swin Transformer (official repository) 项目地址: https://gitcode.com/gh_mirrors/sw/SwinIR 在数字时代,我们常常遇到…...
)
别再死磕localhost了!Dify连接MySQL报错1130?手把手教你搞定IP授权(附MySQL 8.0+命令)
别再死磕localhost了!Dify连接MySQL报错1130?手把手教你搞定IP授权(附MySQL 8.0命令) 当你在Dify中尝试将LLM生成的数据导入本地MySQL数据库时,可能会遇到一个令人头疼的错误:pymysql.err.OperationalError…...

基于条件风险价值CVaR的微网/虚拟电厂多场景随机规划 摘要:构建了含风、光、燃、储的微网/虚...
基于条件风险价值CVaR的微网/虚拟电厂多场景随机规划 摘要:构建了含风、光、燃、储的微网/虚拟电厂优化调度模型,在此基础上,考虑多个风光出力场景,构建了微网随机优化调度模型,并在此基础上,基于条件风险价…...

从“画个女孩”到“绝世圣女”:圣女司幼幽-造相Z-Turbo提示词进阶指南
从“画个女孩”到“绝世圣女”:圣女司幼幽-造相Z-Turbo提示词进阶指南 1. 理解圣女司幼幽-造相Z-Turbo模型特性 1.1 模型定位与核心优势 圣女司幼幽-造相Z-Turbo是基于Z-Image-Turbo的LoRA微调版本,专门针对"牧神记"中的圣女司幼幽角色进行…...

AI模型推理服务化:基于StructBERT构建高并发微服务架构
AI模型推理服务化:基于StructBERT构建高并发微服务架构 最近几年,AI模型从实验室走向生产环境的速度越来越快。很多团队都遇到过这样的场景:好不容易训练出一个效果不错的模型,比如一个文本分类或情感分析的模型,但当…...

快速生成eNSP自动化安装脚本原型,用快马AI告别繁琐配置
作为一名经常需要搭建网络实验环境的工程师,我深知华为eNSP安装过程的繁琐。每次在新设备上配置时,手动安装依赖、处理环境变量的过程都让人头疼。最近尝试用InsCode(快马)平台的AI辅助功能后,发现可以快速生成自动化安装脚本原型,…...

极简配置:OpenClaw快速接入Phi-3-mini-128k-instruct的HTTP接口
极简配置:OpenClaw快速接入Phi-3-mini-128k-instruct的HTTP接口 1. 为什么选择Phi-3-mini-128k-instruct 上周我在调试一个自动化文档处理流程时,发现现有的大模型响应速度跟不上我的实时需求。经过几轮测试,最终选择了微软开源的Phi-3-min…...

OpenClaw自动化测试:百川2-13B-4bits量化版验证Python脚本正确性
OpenClaw自动化测试:百川2-13B-4bits量化版验证Python脚本正确性 1. 为什么需要AI辅助代码测试? 作为长期与Python打交道的开发者,我经常面临一个经典困境:在快速迭代功能时,测试用例的编写往往成为瓶颈。传统方案要…...

OpenClaw+Phi-3-vision-128k-instruct:个人知识库自动化建设方案
OpenClawPhi-3-vision-128k-instruct:个人知识库自动化建设方案 1. 为什么需要自动化知识管理 作为一个长期与技术文档打交道的开发者,我发现自己陷入了一个典型的知识管理困境:每天接触大量优质内容——技术博客、论文PDF、会议视频、截图…...

ai域名后缀注册对SEO有影响吗
ai域名后缀注册对SEO有影响吗 在当今互联网时代,域名选择对于一个网站的成功至关重要。尤其是对于那些在科技、人工智能(AI)等前沿领域的企业和个人来说,ai域名后缀注册的问题更是备受关注。本文将从多个角度探讨ai域名后缀注册对…...