C语言 | Leetcode C语言题解之第327题区间和的个数
题目:

题解:
#define FATHER_NODE(i) (0 == (i) ? -1 : ((i) - 1 >> 1))
#define LEFT_NODE(i) (((i) << 1) + 1)
#define RIGHT_NODE(i) (((i) << 1) + 2)/* 优先队列(小根堆)。 */
typedef struct
{int *arr;int arrSize;
}
PriorityQueue;/* 二进制树(01字典树)。 */
typedef struct
{int *arr;int highestBit;
}
BinaryTree;/* 几个自定义函数的声明,具体实现见下。 */
static void queuePush(PriorityQueue *queue, long long *prefix, int x);
static void queuePop(PriorityQueue *queue, long long *prefix);
static int treeHighestBit(int mostVal);
static void treePush(BinaryTree *tree, int x);
static void treePop(BinaryTree *tree, int x);
static int treeSmaller(BinaryTree *tree, int x);/* 主函数:treeSize: 二进制树的数组空间大小,等于里面最大值的3倍,具体证明略,大致就是等比数列求和的结果。prefix[]: 其中prefix[x]表示[0, x]范围内子数组的前缀和。这里必须以long long类型存储。window[]: 里面存储prefix[]数组的下标,即prefix[window[x]]才真正表示一个前缀和。buff1[],buff2[]: 优先队列与二进制树各自使用的数组空间。其中buff2[]必须初始化为全0。queue: 优先队列(小根堆),为了不打乱prefix[]数组中的数值顺序,而且window[]数组中实际存放的是下标,所以借用堆排序。tree: 二进制树(01字典树)。 */
int countRangeSum(int *nums, int numsSize, int lower, int upper)
{const int treeSize = numsSize * 3;int x = 0, y = 0, z = 0, t = 0, result = 0;long long sum = 0;long long prefix[numsSize];int window[numsSize], buff1[numsSize], buff2[treeSize];PriorityQueue queue;BinaryTree tree;/* 初始化。 */queue.arr = buff1;queue.arrSize = 0;memset(buff2, 0, sizeof(buff2));tree.arr = buff2;tree.highestBit = treeHighestBit(numsSize - 1);/* 计算前缀和,并将前缀和的下标放到一个小根堆里面,小根堆里面以对应的前缀和为优先级。 */for(x = 0; numsSize > x; x++){sum += nums[x];prefix[x] = sum;queuePush(&queue, prefix, x);/* 如果[0, x]的子数组和本来就在[lower, upper]之间,计数累计。 */if((long long)lower <= sum && (long long)upper >= sum){result++;}}/* 将前缀和数组的下标,以对应的prefix值从小到大的顺序,放到window数组中。 */while(0 < queue.arrSize){window[t] = queue.arr[0];t++;queuePop(&queue, prefix);}/* 开始以滑动窗口的形式移动窗口的左右指针。 */for(x = 0; numsSize > x; x++){/* 将所有prefix[window[x]] - prefix[window[y]] >= lower的下标y都加入。 */while(numsSize > y && prefix[window[x]] - lower >= prefix[window[y]]){treePush(&tree, window[y]);y++;}/* 将所有prefix[window[x]] - prefix[window[z]] > upper的下标z都移除。 */while(numsSize > z && prefix[window[x]] - upper > prefix[window[z]]){treePop(&tree, window[z]);z++;}/* 将窗口内(树内)剩余的下标值中,小于window[x]的数量加到结果中。 */t = treeSmaller(&tree, window[x]);result += t;}return result;
}/* 小根堆的push操作。由于堆中存储的是prefix[]数组的下标,所以入参需带上prefix。 */
static void queuePush(PriorityQueue *queue, long long *prefix, int x)
{int son = queue->arrSize, father = FATHER_NODE(son);/* 新加入数值之后,数量加一。 */queue->arrSize++;/* 根据对应prefix[]值的大小关系,调整父子节点的位置。 */while(-1 != father && prefix[x] < prefix[queue->arr[father]]){queue->arr[son] = queue->arr[father];son = father;father = FATHER_NODE(son);}/* 放到实际满足父子节点大小关系的位置。 */queue->arr[son] = x;return;
}/* 小根堆的pop操作。由于堆中存储的是prefix[]数组的下标,所以入参需带上prefix。 */
static void queuePop(PriorityQueue *queue, long long *prefix)
{int father = 0, left = LEFT_NODE(father), right = RIGHT_NODE(father), son = 0;/* 堆顶pop之后,数量减一。默认将堆尾的数值补充上来填补空位。 */queue->arrSize--;/* 根据对应prefix[]值的大小关系,调整父子节点的位置。 */while((queue->arrSize > left && prefix[queue->arr[queue->arrSize]] > prefix[queue->arr[left]])|| (queue->arrSize > right && prefix[queue->arr[queue->arrSize]] > prefix[queue->arr[right]])){son = (queue->arrSize > right && prefix[queue->arr[left]] > prefix[queue->arr[right]]) ? right : left;queue->arr[father] = queue->arr[son];father = son;left = LEFT_NODE(father);right = RIGHT_NODE(father);}/* 放到实际满足父子节点大小关系的位置。 */queue->arr[father] = queue->arr[queue->arrSize];return;
}/* 计算二进制树中,可能出现的最大的数值,所占据的最高二进制比特。比如,最大值的二进制是101100(b),那么返回的最高比特是100000(b)。特殊的,最大是0的时候返回1(b)。 */
static int treeHighestBit(int mostVal)
{int x = 1;if(0 < mostVal){while(0 < mostVal){x++;mostVal = mostVal >> 1;}x = 1 << x - 2;}return x;
}/* 往二进制树中push一个数值。 */
static void treePush(BinaryTree *tree, int x)
{int i = 0, bit = tree->highestBit;/* 从最高位到最低位的顺序,该位为1就给右分支加1,为0就给左分支加1。 */while(0 < bit){i = (bit & x) ? RIGHT_NODE(i) : LEFT_NODE(i);tree->arr[i]++;bit = bit >> 1;}return;
}/* 从二进制树中pop一个数值。 */
static void treePop(BinaryTree *tree, int x)
{int i = 0, bit = tree->highestBit;/* 从最高位到最低位的顺序,该位为1就给右分支减1,为0就给左分支减1。 */while(0 < bit){i = (bit & x) ? RIGHT_NODE(i) : LEFT_NODE(i);tree->arr[i]--;bit = bit >> 1;}return;
}/* 在二进制树中查找比输入数值小的数值数量。 */
static int treeSmaller(BinaryTree *tree, int x)
{int i = 0, bit = tree->highestBit, result = 0;/* 从高位到低位的顺序查看。 */while(0 < bit){/* 该位为1,则肯定比高位相同,该位为0的数值更大,即把左分支的数量加到结果中。 */if(bit & x){result += tree->arr[LEFT_NODE(i)];i = RIGHT_NODE(i);}/* 该位为0,就往左分支走,不做任何其它处理。 */else{i = LEFT_NODE(i);}bit = bit >> 1;}return result;
}相关文章:
C语言 | Leetcode C语言题解之第327题区间和的个数
题目: 题解: #define FATHER_NODE(i) (0 (i) ? -1 : ((i) - 1 >> 1)) #define LEFT_NODE(i) (((i) << 1) 1) #define RIGHT_NODE(i) (((i) << 1) 2)/* 优先队列(小根堆)。 */ typedef s…...

统计学:条件概率模型
照片由Edge2Edge Media在Unsplash上拍摄 一、介绍 在概率的许多应用中,不可能直接观察实验的结果;而是观察与结果相关的事件。因此,条件概率模型对于考虑和利用从观察到的事件中获得的信息至关重要。此外,条件概率模型与贝叶斯定理…...

前端工程师学习springboot2.x之配置idea热更新实现高效率开发节奏
目前已经学习springboot实现了增删改查分页查询,每次修改业财或者是代码重启项目都让我觉得很闹心,现在给出idea2021版本自带热更新操作设置,设置过程分享给大家 总结:以上就是配置的全部过程,祝大家写代码快乐…...

文本rerank与图像rerank
1、文本rerank: 这里介绍的是目前比较流行和通用一套方案:先利用特征检索(这里是特征空间上的相似度),召回相关信息,然后对query与召回的相关信息进行rerank(这里是利用cross-encoder网络做一个…...

Docker 在 Windows 系统下的使用指南:数据卷和数据库
Docker 在 Windows 系统下的使用指南:数据卷和数据库 Docker 提供了强大的功能来创建、管理和持久化数据。数据卷是 Docker 中用于存储和管理数据的机制,使得数据能够在容器的生命周期之外持久化。数据库容器可以利用数据卷来持久化数据库文件ÿ…...

[数据集][目标检测]轴承缺陷划痕检测数据集VOC+YOLO格式1166张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1166 标注数量(xml文件个数):1166 标注数量(txt文件个数):1166 标注…...

将本地微服务发布到docker镜像二:
上一篇文章我们介绍了如何将一个简单的springboot服务发布到docker镜像中,这一篇我们将介绍如何将一个复杂的微服务(关联mysql、redis)发布到docker镜像。 我们将使用以下两种不同的方式来实现此功能。 redis、mysql、springboot微服务分开…...

前端构建工具|vite快速入门
认识vite vite组成部分 Vite是一种新型前端构建工具,能够显著提升前端开发体验。它主要由两部分组成: 一个开发服务器,它基于 原生 ES 模块 提供了 丰富的内建功能,如速度快到惊人的 模块热更新(HMR)。一…...

拯救PyCharm:击退IDE内存泄漏的策略
拯救PyCharm:击退IDE内存泄漏的策略 PyCharm,作为一款功能强大的集成开发环境(IDE),在处理大型项目或长时间开发过程中,可能会遇到内存泄漏的问题,导致IDE运行缓慢甚至崩溃。本文将提供一系列解…...

在vue3的开发环境中为什么使用vite而不是用webpack
1、vite在开发阶段没有打包过程,直接启动一个服务器 2、请求一个模块到开发服务器 3、开发服务器编译模块,根据页面用所需要的依赖去加载文件 4、加载完成后,开发服务器把编译的结果返回给页面 这使得提高了我们在开发阶段运行的效率 vite是…...

mybatis结合generator进行分页插件PluginAdapter开发
mybatis结合generator生成的代码没有分页的功能,可以尝试自己继承分页插件PluginAdapter,进行开发,实现自己的分页插件这样generator生产的代码 带分页功能了。 MyBatis MySQL自动生成带分页插件 继承PluginAdapter类,实现相关方…...

面试:ArrayList和LinkedList
ArrayList和LinkedList是什么? ArrayList: ArrayList是Java集合框架中的一个类,它实现了List接口,底层基于数组实现。ArrayList的特点是支持动态数组,可以自动扩容,适合顺序访问和随机访问。LinkedList&am…...

【uniapp】uniapp+vue2微信小程序实现分享功能
uniappvue2做的微信小程序实现分享功能 问题描述 uniappvue2做的微信小程序,发布以后点击右上角三个点,分享小程序的时候,转发和分享按钮都是灰色 解决方案 转发、分享、复制链接这几个功能需要自己来手动写方法,考虑到每个页…...

WEB渗透Web突破篇-目录爆破
开源 工具名称下载地址工具描述cansinahttps://github.com/deibit/cansina网站的敏感目录发掘工具Cewlcewl | Kali Linux Tools你可以给它的爬虫指定URL地址和爬取深度,接下来Cewl会给你返回一个字典文件dirsearchhttps://github.com/maurosoria/dirsearch目录扫描…...
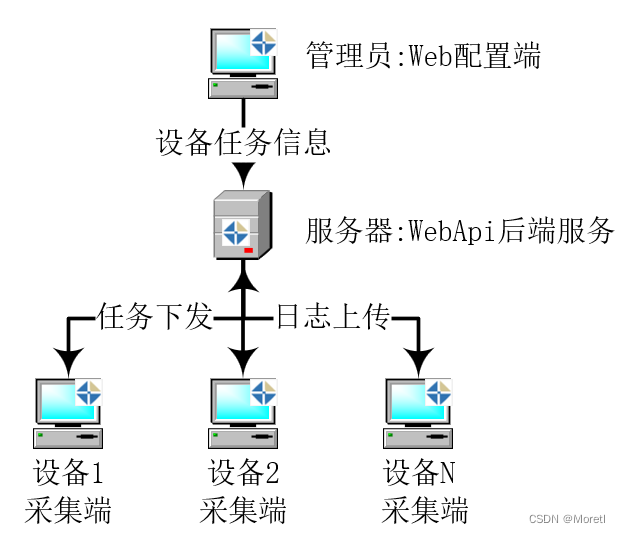
Windows设备文件同步平台
使用咨询: 扫码添加QQ 永久免费: Gitee下载最新版本 使用说明: CSDN查看使用说明 功能: 定时(全量采集or增量采集) SCADA,MES等系统采集工控机,办公电脑文件. 优势1: 开箱即用. 解压直接运行.插件集成下载. 优势2: 批管理设备. 配置均在后台配置管理. 优势3: 无人值守 采集端…...

用九方智投学习机,学会应对回撤风险
(九方智投属于九方智投控股有限公司(9636.HK)旗下品牌) 近期国内海风项目密集落地,行业景气度提升。2023年下半年以来,各省加快建设“十四五”规划,我国海风建设重新迈入快车道&#x…...

maven打包加入本地jar包
在使用maven打包的过程中,有时候我们需要添加一些本地的jar包,并将其打到jar包的lib中。 首先将需要本地的jar包,放到项目的的src/resources/lib下面。 然后在对应的项目的pom中加入一下依赖: <dependency><groupId>…...
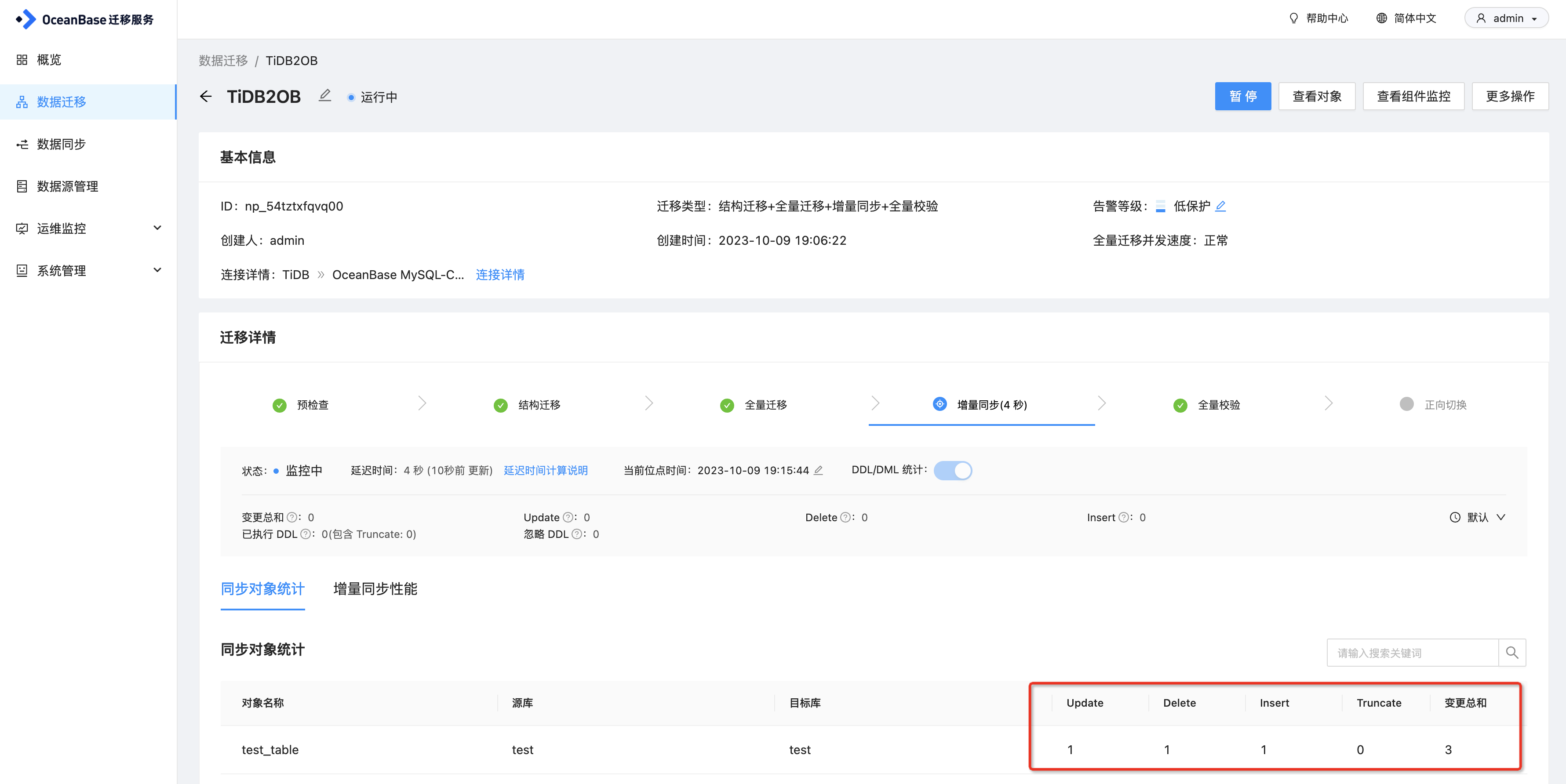
从TiDB迁移到OceanBase的实践分享
本文来自OceanBase热心用户的分享 近期,我们计划将业务数据库从TiDB迁移到OceanBase,但面临的一个主要挑战是如何更平滑的完成这一迁移过程。经过研究,了解到OceanBase提供的OMS数据迁移工具能够支持从TiDB到OceanBase的迁移,并且…...

DL00765-光伏故障检测高分辨率无人机热红外图像细粒度含数据集4000+张
光伏发电作为清洁能源的重要组成部分,近年来得到了广泛应用。然而,随着光伏电站规模的扩大,光伏组件在运行过程中可能会出现各种故障,如热斑、遮挡、接线盒故障等。这些故障不仅会影响光伏电站的发电效率,还可能导致更…...

CICD流水线
一、CICD流水线简介 CICD概念 CI/CD流水线是现代软件开发的一个核心概念,它涉及自动化和管理软件从开发到部署的整个生命周期 概念定义 具体有三点:持续集成、持续交付、持续部署 流水线组成为:代码提交、测试、构建、部署、结果通知 二…...

STM32语音智能垃圾桶开发实战
1. 项目概述 这个基于STM32的语音智能垃圾桶项目,本质上是一个融合了嵌入式开发、语音识别和物联网技术的综合性解决方案。我在去年为一个社区环保项目开发过类似系统,实测下来发现这种智能垃圾桶不仅能提升垃圾分类效率,还能显著降低公共区域…...
)
【国家级数字农场认证标准】:PHP可视化配置合规性检查清单(含GDPR+农业农村部2024新规适配)
第一章:国家级数字农场认证标准的农业数字化背景与合规性演进农业正经历从机械化、自动化向数字化、智能化的历史性跃迁。国家层面推动“数字乡村”战略与“智慧农业三年行动计划”,将数据要素深度融入耕、种、管、收全链条,催生对可验证、可…...
了!PHP 8.9智能GC自适应算法上线,3类高并发场景下的自动回收策略配置清单)
别再手动gc_collect_cycles()了!PHP 8.9智能GC自适应算法上线,3类高并发场景下的自动回收策略配置清单
第一章:PHP 8.9智能垃圾回收机制演进全景PHP 8.9并未实际发布——截至2024年,PHP官方最新稳定版本为PHP 8.3,PHP 8.4处于RC阶段,而PHP 8.9尚不存在。该标题属于前瞻性技术构想与行业演进推演场景下的概念性章节,旨在基…...

如何用G-Helper解决华硕笔记本性能控制臃肿问题
如何用G-Helper解决华硕笔记本性能控制臃肿问题 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar, and other mod…...

EPLAN笔记
一般使用:1.端子排报表:每个端子前后要放置线线号,原则上端子前后都要放置设备(如:电机、按钮、开关、端子),端子前后中断点、描述点、节点等端子EPLAN端子数据里是识别不了线号的。在自建端子排中,端子前或后最少有一边放置了设备࿰…...

告别暴力穷举!用ip33在线工具手工反算1~4字节CRC32校验码的原始数据
告别暴力穷举!手工反算1~4字节CRC32校验码的数学艺术 在数据校验的世界里,CRC32就像一位沉默的守门人,它用32位的校验码守护着数据的完整性。但鲜为人知的是,当面对1-4字节的短数据时,这位守门人的规则可以被优雅地逆…...

2026年智能巡检管理系统如何让设备隐患无处遁形?
传统的设备巡检,本质上是一场“信任游戏”。我信任员工去看了,员工信任自己画了钩,结果往往是——等到设备真的坏了、管道真的漏了,翻开那本厚厚的巡检记录,上面依然写满了“正常”。直到我们引入了智能巡检管理系统&a…...

realme Q3 5G刷机全攻略:从TWRP到Magisk Root权限获取
1. realme Q3 5G刷机前的准备工作 在开始刷机之前,我们需要做好充分的准备工作。realme Q3 5G(型号RMX3161)作为一款性价比极高的5G手机,搭载高通骁龙750G处理器,确实是个不错的刷机选择。不过刷机有风险,操…...

相同文件按优先级取唯一值
问题:我有三个文件,字段名都一样,如果不重复就union到一起,如果有重复,按类型优先级取唯一值,用python实现import pandas as pd from datetime import date import time todaystr(date.today())filepath/Us…...

OpenTAP硬件集成测试优势解析
OpenTAP 之所以在硬件和系统集成测试领域表现出色,主要得益于其独特的设计理念、灵活的架构以及强大的社区生态支持。以下将从核心架构、技术优势、应用场景和具体实施案例等多个维度进行详细阐述。 一、 核心架构与设计理念 OpenTAP 基于 .NET 平台构建ÿ…...