Hadoop单机及集群部署
目录
- 一、Hadoop 单机模式部署
- 1. 环境准备
- 2. 安装 Java
- 3. 下载并安装 Hadoop
- 4. 配置环境变量
- 5. 配置 Hadoop
- 编辑 core-site.xml
- 编辑 hdfs-site.xml
- 编辑 mapred-site.xml
- 编辑 yarn-site.xml
- 6. 格式化 Namenode
- 7. 启动 Hadoop 服务
- 8. 验证 Hadoop
- 注意事项
- 二、Hadoop 集群模式部署
- 1. 环境准备
- 2. 设置 SSH 免密码登录
- 3. 下载并安装 Hadoop
- 4. 配置 Hadoop
- 编辑 core-site.xml
- 编辑 hdfs-site.xml
- 编辑 mapred-site.xml
- 编辑 yarn-site.xml
- 配置 slaves 文件
- 5. 启动 Hadoop 集群
- 6. 验证集群状态
- 注意事项
- 三、Hadoop 使用案例:Word Count
- 1. 创建输入文件
- 2. 编写 MapReduce 程序
- 3. 编译并运行程序
- 四、使用 Python 实现 Word Count
- 1. 环境准备
- 2. 编写 Mapper 和 Reducer
- Mapper (mapper.py)
- Reducer (reducer.py)
- 3. 设置可执行权限
- 4. 上传输入文件到 HDFS
- 5. 使用 Hadoop Streaming 运行作业
- 6. 查看结果
- 7. Python 实现 Word Count 示例
- 8. 注意事项
- 9. 总结
- 10. 查看结果
- 五、总结与注意事项
- 常见问题
- 优化建议
下面是关于如何在单机和集群环境中部署Hadoop的详细指南,以及部署过程中的注意事项和一个实际使用案例。我们将涵盖从基础安装到配置细节,并讨论一些常见的问题和解决方案。
一、Hadoop 单机模式部署
1. 环境准备
- 操作系统:Linux (推荐使用 Ubuntu 20.04 或 CentOS 7)
- Java:Hadoop 需要 Java 环境,推荐使用 OpenJDK 8。
- SSH:Hadoop 需要 SSH 访问,因此要确保 SSH 服务已安装并运行。
2. 安装 Java
在 Ubuntu 中:
sudo apt update
sudo apt install openjdk-8-jdk
在 CentOS 中:
sudo yum install java-1.8.0-openjdk
验证 Java 安装:
java -version
3. 下载并安装 Hadoop
访问 Hadoop 官网 下载最新版本的 Hadoop。
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
tar -xzvf hadoop-3.3.1.tar.gz
mv hadoop-3.3.1 /usr/local/hadoop
4. 配置环境变量
编辑 ~/.bashrc 文件,添加以下内容:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
应用更改:
source ~/.bashrc
5. 配置 Hadoop
编辑 core-site.xml
路径:$HADOOP_HOME/etc/hadoop/core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
</configuration>
编辑 hdfs-site.xml
路径:$HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:///usr/local/hadoop/hadoop_data/hdfs/namenode</value></property><property><name>dfs.datanode.data.dir</name><value>file:///usr/local/hadoop/hadoop_data/hdfs/datanode</value></property>
</configuration>
编辑 mapred-site.xml
复制模板文件并编辑:
cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml
路径:$HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
编辑 yarn-site.xml
路径:$HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
6. 格式化 Namenode
hdfs namenode -format
7. 启动 Hadoop 服务
start-dfs.sh
start-yarn.sh
8. 验证 Hadoop
访问 Hadoop Web 界面:
- Namenode: http://localhost:9870
- ResourceManager: http://localhost:8088
注意事项
- 确保 Java 环境配置正确。
- 确保 SSH 服务正常运行。
- 检查配置文件路径和参数的正确性。
二、Hadoop 集群模式部署
1. 环境准备
- 多台服务器,至少 3 台(1 个 NameNode,2 个 DataNode)。
- 网络:确保各节点之间可以互相访问。
- 操作系统:Linux (Ubuntu 或 CentOS)。
- Java:在所有节点上安装 Java。
2. 设置 SSH 免密码登录
在主节点上生成 SSH 密钥:
ssh-keygen -t rsa
将公钥复制到所有从节点:
ssh-copy-id user@datanode1
ssh-copy-id user@datanode2
3. 下载并安装 Hadoop
在所有节点上安装 Hadoop,步骤与单机安装相同。
4. 配置 Hadoop
编辑 core-site.xml
在所有节点上配置相同的 core-site.xml:
<configuration><property><name>fs.defaultFS</name><value>hdfs://namenode:9000</value></property>
</configuration>
编辑 hdfs-site.xml
在所有节点上配置相同的 hdfs-site.xml:
<configuration><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.namenode.name.dir</name><value>file:///usr/local/hadoop/hadoop_data/hdfs/namenode</value></property><property><name>dfs.datanode.data.dir</name><value>file:///usr/local/hadoop/hadoop_data/hdfs/datanode</value></property>
</configuration>
编辑 mapred-site.xml
在所有节点上配置相同的 mapred-site.xml:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
编辑 yarn-site.xml
在所有节点上配置相同的 yarn-site.xml:
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
配置 slaves 文件
在 NameNode 上,编辑 $HADOOP_HOME/etc/hadoop/slaves 文件,添加所有 DataNode 的主机名:
datanode1
datanode2
5. 启动 Hadoop 集群
在 NameNode 上执行:
start-dfs.sh
start-yarn.sh
6. 验证集群状态
访问 Namenode 和 ResourceManager 的 Web 界面,确保所有节点正常运行。
注意事项
- 确保所有节点的时钟同步。
- 确保网络配置正确,各节点之间可访问。
- 检查每个节点的配置文件,确保一致性。
三、Hadoop 使用案例:Word Count
1. 创建输入文件
在 HDFS 中创建一个目录,并上传一个文本文件:
hdfs dfs -mkdir -p /user/hadoop/input
hdfs dfs -put localfile.txt /user/hadoop/input
2. 编写 MapReduce 程序
以下是一个简单的 Word Count Java 程序:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCount {public static class TokenizerMapperextends Mapper<Object, Text, Text, IntWritable>{private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {String[] tokens = value.toString().split("\\s+");for (String token : tokens) {word.set(token);context.write(word, one);}}}public static class IntSumReducerextends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
3. 编译并运行程序
编译程序:
javac -classpath `hadoop classpath` -d wordcount_classes WordCount.java
jar -cvf wordcount.jar -C wordcount_classes/ .
运行程序:
hadoop jar wordcount.jar WordCount /user/hadoop/input /user/hadoop/output
当然可以使用 Python 来实现 Word Count 的 Hadoop MapReduce 程序。Python 提供了一个名为 Hadoop Streaming 的工具,可以通过管道方式使得我们可以使用 Python、Perl、Ruby 等语言来编写 Map 和 Reduce 函数。
下面是使用 Python 实现的 Word Count 示例。
四、使用 Python 实现 Word Count
1. 环境准备
确保你的 Hadoop 环境支持 Hadoop Streaming,可以通过以下命令查看:
hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-3.3.1.jar
如果没有报错,那么你的 Hadoop 支持 Streaming。
2. 编写 Mapper 和 Reducer
Mapper (mapper.py)
Mapper 的任务是读取输入文件的每一行,将每个单词输出为一个键值对 (word, 1)。
#!/usr/bin/env pythonimport sys# 读取标准输入
for line in sys.stdin:# 去除前后空格并分割成单词words = line.strip().split()for word in words:# 输出键值对print(f"{word}\t1")
保存为 mapper.py。
Reducer (reducer.py)
Reducer 的任务是汇总 Mapper 的输出,统计每个单词出现的次数。
#!/usr/bin/env pythonimport syscurrent_word = None
current_count = 0
word = None# 从标准输入读取数据
for line in sys.stdin:# 去除前后空格并解析输入line = line.strip()word, count = line.split('\t', 1)# 将 count 转换为 inttry:count = int(count)except ValueError:continue# 检查当前单词是否与之前的单词相同if current_word == word:current_count += countelse:if current_word:# 输出当前单词的计数print(f"{current_word}\t{current_count}")current_word = wordcurrent_count = count# 输出最后一个单词的计数
if current_word == word:print(f"{current_word}\t{current_count}")
保存为 reducer.py。
3. 设置可执行权限
确保这两个 Python 脚本具有可执行权限:
chmod +x mapper.py
chmod +x reducer.py
4. 上传输入文件到 HDFS
确保 HDFS 已经运行,创建输入目录并上传数据文件:
hdfs dfs -mkdir -p /user/hadoop/input
hdfs dfs -put localfile.txt /user/hadoop/input
5. 使用 Hadoop Streaming 运行作业
使用 Hadoop Streaming 工具运行 MapReduce 作业:
hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-3.3.1.jar \-input /user/hadoop/input \-output /user/hadoop/output \-mapper mapper.py \-reducer reducer.py \-file mapper.py \-file reducer.py
参数说明:
-input:指定输入数据所在的 HDFS 目录。-output:指定输出结果存储的 HDFS 目录。-mapper:指定 Mapper 的执行脚本。-reducer:指定 Reducer 的执行脚本。-file:将本地文件发送到 Hadoop 分布式缓存中,以便在集群节点上执行。
6. 查看结果
hdfs dfs -cat /user/hadoop/output/part-00000
7. Python 实现 Word Count 示例
假设 localfile.txt 内容如下:
Hello Hadoop
Hello Python
Hello World
运行以上命令后,输出结果可能如下:
Hadoop 1
Hello 3
Python 1
World 1
8. 注意事项
- 输入输出路径:确保输入路径正确,输出路径不存在(Hadoop 不允许输出路径已存在)。
- 权限问题:检查脚本的执行权限。
- Python 版本:确保 Python 版本与环境兼容。
- 换行符问题:确保输入文件中的换行符格式正确(Linux 使用 LF,而不是 CRLF)。
9. 总结
通过以上步骤,我们成功地使用 Python 实现了一个简单的 Hadoop Word Count 程序。Hadoop Streaming 提供了极大的灵活性,可以使用任意支持标准输入输出的编程语言来实现 MapReduce 作业。这使得开发者能够利用熟悉的编程语言进行大规模数据处理。
如果在开发过程中遇到任何问题,请确保查看 Hadoop 和 Python 的错误日志,以便更快地定位问题并进行调试。
10. 查看结果
hdfs dfs -cat /user/hadoop/output/part-r-00000
五、总结与注意事项
常见问题
- SSH 问题:确保所有节点之间的 SSH 无密码访问正常。
- Java 环境问题:确认所有节点上的 Java 版本一致。
- Hadoop 版本问题:确保所有节点的 Hadoop 版本一致。
- 文件权限问题:确保 HDFS 中的文件权限正确,避免权限问题导致的作业失败。
- 内存和资源配置:合理配置每个节点的内存和资源分配,以提高作业执行效率。
优化建议
- 使用 HDFS 进行大规模数据存储,提高数据的可靠性和可用性。
- 合理设置副本数量,根据集群规模和业务需求进行调整。
- 监控集群状态,使用工具(如 Ambari、Ganglia)对 Hadoop 集群进行实时监控和管理。
通过以上步骤,您可以成功部署 Hadoop 单机和集群环境,并运行简单的 MapReduce程序进行数据处理。在实际生产环境中,还需要根据具体需求进行进一步优化和调整。
相关文章:

Hadoop单机及集群部署
目录 一、Hadoop 单机模式部署1. 环境准备2. 安装 Java3. 下载并安装 Hadoop4. 配置环境变量5. 配置 Hadoop编辑 core-site.xml编辑 hdfs-site.xml编辑 mapred-site.xml编辑 yarn-site.xml 6. 格式化 Namenode7. 启动 Hadoop 服务8. 验证 Hadoop注意事项 二、Hadoop 集群模式部…...

使用es-hadoop同步hive和es之间数据
💻近期在华为云连接es时的时候发现不能输入账号密码,后面联系华为工程师了解到,华为云默认是非安全模式,即不需要输入账号密码。 如果对你有所帮助,欢迎点赞收藏关注不迷路哦💓 目录 使用es-hadoop同步h…...

Java - 泛型 + JUnit
一、泛型(参数化类型,在编译时确定) 泛型是一种可以接收数据类型的数据类型(可以这么理解) 作用: 1.能对加入到集合中的数据类型进行约束 2.遍历的时候,不需要进行类型转换,提高效率(因为遍历时,默认的是Object,需要进行类型转换的…...

vue3实现包含表格的Word文件导出
vue3实现包含表格的Word文件导出 近期遇到一个要求,需要在网页上导出Word文档,文档中有表格,也有普通的数据,查阅了很多资料,总算比较完美的解决了,记录一下 先上一下最终效果 演示视频 vue3项目根据Wor…...

【深度学习】TTS,CosyVoice,推理部署的代码原理讲解分享
文章目录 demo代码加载配置文件speech_tokenizer_v1.onnx(只在zero_shot的时候使用)campplus.onnx(只为了提取说话人音色embedding)`campplus_model` 的作用代码解析具体过程解析总结示意图CosyVoiceFrontEndCosyVoiceModel推理过程总体推理过程推理速度很慢: https://git…...

flask高频面试题
目录 高频面试题及答案1. 如何在Flask中处理数据库迁移?2. Flask如何处理文件上传?3. 如何在Flask中处理跨域请求(CORS)?4. 如何在Flask中实现用户认证?5. Flask如何处理会话?6. Flask如何处理表…...

尚硅谷谷粒商城项目笔记——五、使用docker安装mysql
五、使用docker安装mysql 注意: 因为电脑是AMD芯片,自己知识储备不够,无法保证和课程中用到的环境一样,所以环境都是自己根据适应硬件软件环境重新配置的,这里的虚拟机使用的是VMware。 使用 Docker 安装 MySQL 与安…...

filebeat + logstash使用笔记
背景 本文中有2台主机: (1)1.1.1.1是OpenStack的nova节点,安装filebeat (2)1.1.1.2是logstash节点 在1.1.1.1上通过filebeat读取OpenStack的nova-compute组件日志(/var/log/nova/nova-compute.…...

学校考场电子钟设置自动开关机,节能环保
在标准化考试中,准确的时间显示对于确保考试的公正性和秩序至关重要。然而,传统的电子钟系统往往存在一些问题,影响了考试管理的效率。 一、学校普通电子钟使用问题 二、学校考场电子钟优点 学校同步时钟系统通过自动同步网络或卫星时间的方式…...

短剧APP系统开发带来了哪些发展空间?
在影视行业快速发展的时期,短剧作为一种新兴的影视模式,获得了大众的欢迎。目前,短剧行业巨大的发展空间,再次成为大众关注的焦点。 随着移动互联网的发展,信息技术不断升级进步,短剧APP系统的开发&#x…...

PaddlePaddle / PaddleOCR踩坑记,动手实现一个OCR服务器
文章目录 一、环境搭建1、官网2、准备环境 二、编码实现一个web程序 一、环境搭建 1、官网 https://gitee.com/paddlepaddle/PaddleOCR#/paddlepaddle/PaddleOCR/blob/main/doc/doc_ch/quickstart.md 2、准备环境 本地环境坑太多了,好在官网还有一种基于docker搭…...

JeecgBoot低代码平台简单记录
BasicModal弹窗 Usage 由于弹窗内代码一般作为单文件组件存在,也推荐这样做,所以示例都为单文件组件形式 注意v-bind"$attrs"记得写,用于将弹窗组件的attribute传入BasicModal组件 attribute:是属性的意思,…...

零基础入门转录组数据分析——机器学习算法之xgboost(筛选特征基因)
零基础入门转录组数据分析——机器学习算法之xgboost(筛选特征基因) 目录 零基础入门转录组数据分析——机器学习算法之xgboost(筛选特征基因)1. xgboost基础知识2. xgboost(Rstudio)——代码实操2. 1 数据…...

C#开发常见面试题三(浅复制和深复制的区别)
C#开发常见面试题三(浅复制和深复制的区别) 一.浅复制和深复制定义 (1)浅复制:复制一个对象的时候,仅仅复制原始对象中所有的非静态类型成员和所有的引用类型成员的引用。(新对象和原对象将共享所有引用类型成员的实…...
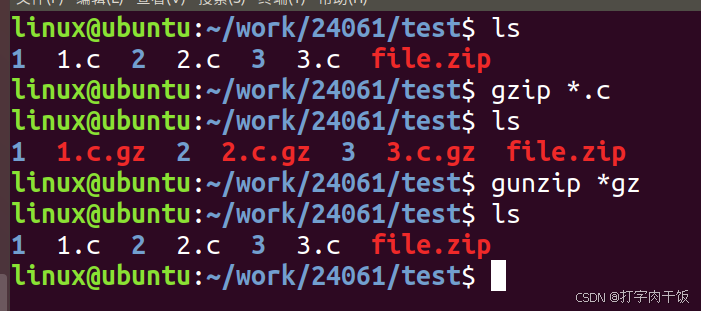
Linux/C 高级——Linux命令
从这里开始,我们展开对Linux/c 高级的学习,首先介绍的是在Linux/c高级中,Linux的部分 目录 1.Linux简介 1.1Linux起源 1.2查看系统版本命令 1.3分层结构 1.4系统关机重启命令 2.Linux安装工具 2.1软件包安装 2.1.1软件包的管理机制 …...

怎么在 tailwindcss 项目中自定义一些可复用的样式
在 Tailwind CSS 项目中自定义可复用的样式有几种常用方法: 使用 apply 指令 你可以在 CSS 文件中使用 apply 指令来创建可复用的样式类: layer components {.btn-primary {apply py-2 px-4 bg-blue-500 text-white font-semibold rounded-lg shadow-md hover:bg-blue-700 f…...

在vue3中 引入echarts
安装:npm install echarts --save 方式一:直接在组件中引用 <template><divref"myChart"id"myChart":style"{ width: 800px, height: 400px }"></div></template><script>import * as echa…...

栈和队列(数据结构)
1. 栈(Stack) 1.1 概念 栈 :一种特殊的线性表,其 只允许在固定的一端进行插入和删除元素操作 。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO ( Last In First Out )的原…...

如何实现ElementUI表单项label的文字提示?
在Vue和ElementUI的丰富组件库中,定制化表单是常见的需求之一。那么如何在表单项label后添加文字提示,以提升用户体验呢? 首先我们来看一下效果图: 这里我们鼠标移动到❓图标上就会出现提示 在 ElementUI 中,el-form-item 组件允许使用 slot 自定义 label。通过在 el-fo…...

c++中的标准库
前言 hello,我是文宇。 正文 C标准库是C编程语言的基本组成部分之一,它为开发人员提供了一套丰富和强大的工具和功能,以便快速开发高效、可靠和可移植的应用程序。C标准库由两个主要部分组成:STL(Standard Template…...

爬虫实践——selenium、bs4
目录 一、浏览器的一般设置 二、打开网页并获取网页源码的方式 1、基于requests库 2、基于urlib库 3、基于selenium 三、HTML解析 1、BeautifulSoup 2、Selenium动态渲染爬虫:模拟动态操作网页,加载JS(webdriver) 1) 8种find_element定位元素的方法: 2)frame、window切换:…...

终极指南:如何快速安装Koikatu HF Patch完整增强补丁
终极指南:如何快速安装Koikatu HF Patch完整增强补丁 【免费下载链接】KK-HF_Patch Automatically translate, uncensor and update Koikatu! and Koikatsu Party! 项目地址: https://gitcode.com/gh_mirrors/kk/KK-HF_Patch 还在为Koikatu和Koikatsu Party游…...

1980-2025年中国各区县逆温数据
1980~2025 年中国各区县逆温数据 该数据包含如下变量,各个变量的含义如下: date:日期 year:年 mnth:月 day:日 省:省份名称 省代码:省份行政区划代码 市…...

MedSAM开源项目:医学图像分割的通用架构创新与实战应用
MedSAM开源项目:医学图像分割的通用架构创新与实战应用 【免费下载链接】MedSAM Segment Anything in Medical Images 项目地址: https://gitcode.com/gh_mirrors/me/MedSAM MedSAM(Segment Anything in Medical Images)是一个针对医学…...

FanControl中文设置高效配置:5分钟完成本地化界面实战指南
FanControl中文设置高效配置:5分钟完成本地化界面实战指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

KKS-HF Patch 完整解决方案:优化《Koikatsu Sunshine》游戏体验指南
KKS-HF Patch 完整解决方案:优化《Koikatsu Sunshine》游戏体验指南 【免费下载链接】KKS-HF_Patch Automatically translate, uncensor and update Koikatsu Sunshine! 项目地址: https://gitcode.com/gh_mirrors/kk/KKS-HF_Patch KKS-HF Patch 是针对《Koi…...

如何在不影响员工效率的前提下,彻底杜绝Web威胁?
在数字化转型的浪潮中,浏览器早已从一个简单的网页浏览工具,演变为企业业务运转的核心枢纽。无论是访问云应用、处理内部系统,还是与客户协作,几乎每项工作都离不开它。然而,正是这种无处不在的依赖,让浏览…...
)
山东大学项目实训-大数据租房推荐智能体(一)
整体任务搭建完整的agent框架,设计项目结构,agent工作流程,编写prompt和重试机制约束LLM输出,实现多轮对话管理,让agent能够理解当下环境和用户意图,编排正确的工具调用顺序。(一)第…...

企业级可视化生态系统|关于Highcharts集成的前端框架、后端编程语言与生态
在 Web 开发和数据分析领域,Highcharts 凭借其强大的交互性和美观的视觉效果,早已成为行业标杆。然而,真正让 Highcharts 脱颖而出的,不仅仅是它那 100 多种图表类型,更是其全方位的集成能力(Integrations&…...

3分钟搞定iPhone USB网络共享:Windows苹果驱动极简安装指南
3分钟搞定iPhone USB网络共享:Windows苹果驱动极简安装指南 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/g…...