CUDA编程从零到壹
如今,当我们谈论深度学习时,为了提高性能,我们通常会将其实现与使用 GPU 联系起来。
GPU(图形处理单元)最初设计用于加速图像、2D 和 3D 图形的渲染。然而,由于它们能够执行许多并行操作,它们的实用性不仅限于此,还扩展到深度学习等应用。
GPU 用于深度学习模型始于 2000 年代中后期,随着 AlexNet 的出现,它在 2012 年左右变得非常流行。 AlexNet 是由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 设计的卷积神经网络,于 2012 年赢得了 ImageNet 大规模视觉识别挑战赛 (ILSVRC)。这次胜利标志着一个里程碑,因为它证明了深度神经网络在图像分类方面的有效性以及使用 GPU 训练大型模型的有效性。
在这一突破之后,使用 GPU 进行深度学习模型变得越来越流行,这促成了 PyTorch 和 TensorFlow 等框架的创建。
如今,我们只需在 PyTorch 中写入 .to("cuda") 即可将数据发送到 GPU,并期望训练得到加速。但深度学习算法在实践中如何利用 GPU 的计算性能?让我们来一探究竟!

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、计算优化问题
深度学习架构(如神经网络、CNN、RNN 和 Transformer)基本上是使用数学运算(例如矩阵加法、矩阵乘法和对矩阵应用函数)构建的。因此,如果我们找到优化这些操作的方法,我们就可以提高深度学习模型的性能。
那么,让我们从简单的开始。假设你要添加两个向量 C = A + B。

在 C 语言中,一个简单的实现如下:
void AddTwoVectors(flaot A[], float B[], float C[]) {for (int i = 0; i < N; i++) {C[i] = A[i] + B[i];}
}正如你所注意到的,计算机必须对向量进行迭代,在每次迭代中按顺序添加每对元素。但这些操作彼此独立。第 i 对元素的添加不依赖于任何其他对。那么,如果我们可以同时执行这些操作,并行添加所有元素对,会怎么样?
一种简单的方法是使用 CPU 多线程来并行运行所有计算。但是,当涉及到深度学习模型时,我们要处理的是包含数百万个元素的海量向量。普通 CPU 只能同时处理大约十几个线程。这就是 GPU 发挥作用的时候了!现代 GPU 可以同时运行数百万个线程,从而提高这些数学运算对海量向量的性能。
2、GPU 与 CPU 比较
虽然 CPU 计算在单个操作上可以比 GPU 更快,但 GPU 的优势在于其并行化能力。原因是它们的设计目标不同。 CPU 的设计目标是尽可能快地执行一系列操作(线程)(并且只能同时执行数十个操作),而 GPU 的设计目标是并行执行数百万个操作(同时牺牲单个线程的速度)。
为了说明这一点,我们可以将 CPU 想象为一辆法拉利,将 GPU 想象为一辆公交车。如果你的任务是运送一个人,那么法拉利 (CPU) 是更好的选择。但是,如果你要运送几个人,即使法拉利 (CPU) 每次行程速度更快,公交车 (GPU) 也可以一次性运送所有人,一次性运送所有人的速度比法拉利多次行驶路线的速度更快。因此,CPU 更适合处理顺序操作,而 GPU 更适合处理并行操作。

为了提供更高的并行能力,GPU 设计为数据处理分配了更多的晶体管,而不是数据缓存和流控制,而 CPU 则为此分配了相当一部分晶体管,以优化单线程性能和复杂指令执行。
下图说明了 CPU 与 GPU 的芯片资源分布。
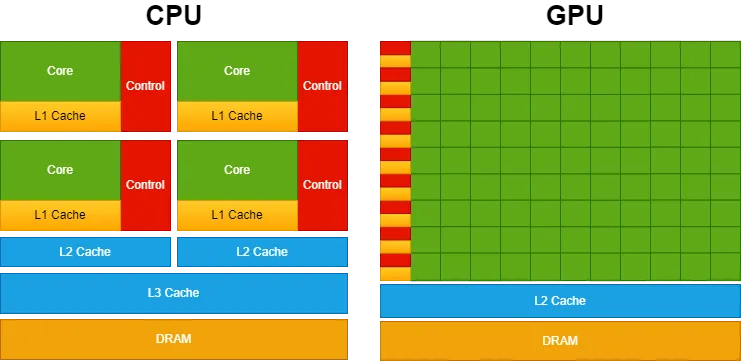
CPU 具有强大的内核和更复杂的缓存架构(为此分配了大量晶体管)。这种设计可以更快地处理顺序操作。另一方面,GPU 优先考虑拥有大量内核以实现更高级别的并行性。
现在我们理解了这些基本概念,我们如何在实践中利用这种并行计算能力?
3、CUDA 简介
当运行某些深度学习模型时,你的选择可能是使用一些流行的 Python 库,例如 PyTorch 或 TensorFlow。然而,众所周知,这些库的核心在底层运行 C/C++ 代码。此外,正如我们之前提到的,你可以使用 GPU 来加速处理。这就是 CUDA 的作用所在!
CUDA 代表计算统一架构,它是由 NVIDIA 开发的用于在其 GPU 上进行通用处理的平台。因此,虽然游戏引擎使用 DirectX 来处理图形计算,但 CUDA 使开发人员能够将 NVIDIA 的 GPU 计算能力集成到他们的通用软件应用程序中,而不仅仅是图形渲染。
为了实现这一点,CUDA 提供了一个简单的基于 C/C++ 的接口 (CUDA C/C++),该接口授予对 GPU 虚拟指令集和特定操作(例如在 CPU 和 GPU 之间移动数据)的访问权限。
在进一步讨论之前,让我们先了解一些基本的 CUDA 编程概念和术语:
- 主机:指 CPU 及其内存;
- 设备:指 GPU 及其内存;
- 核:指在设备 (GPU) 上执行的函数;
因此,在使用 CUDA 编写的基本代码中,程序在主机 (CPU) 上运行,将数据发送到设备 (GPU) 并启动要在设备 (GPU) 上执行的核 (函数)。 这些核由多个线程并行执行。 执行后,结果从设备 (GPU) 传输回主机 (CPU)。
让我们回到两个向量相加的问题:
#include <stdio.h>void AddTwoVectors(flaot A[], float B[], float C[]) {for (int i = 0; i < N; i++) {C[i] = A[i] + B[i];}
}int main() {...AddTwoVectors(A, B, C);...
}在 CUDA C/C++ 中,程序员可以定义 C/C++ 函数(称为内核),当调用这些函数时,它们会由 N 个不同的 CUDA 线程并行执行 N 次。
要定义内核,可以使用 __global __声明说明符,并且可以使用 <<<...>>> 符号指定执行此内核的 CUDA 线程数:
#include <stdio.h>// Kernel definition
__global__ void AddTwoVectors(float A[], float B[], float C[]) {int i = threadIdx.x;C[i] = A[i] + B[i];
}int main() {...// Kernel invocation with N threadsAddTwoVectors<<<1, N>>>(A, B, C);...
}每个线程执行内核,并被赋予一个唯一的线程 ID threadIdx,可通过内置变量在内核中访问。上面的代码将两个大小为 N 的向量 A 和 B 相加,并将结果存储到向量 C 中。您可以注意到,CUDA 允许我们同时执行所有这些操作,使用 N 个并行线程,而不是循环按顺序执行每个成对的加法。
但在运行此代码之前,我们需要进行另一项修改。重要的是要记住内核函数在设备(GPU)内运行。因此,它的所有数据都需要存储在设备内存中。你可以使用以下 CUDA 内置函数来执行此操作:
#include <stdio.h>// Kernel definition
__global__ void AddTwoVectors(float A[], float B[], float C[]) {int i = threadIdx.x;C[i] = A[i] + B[i];
}int main() {int N = 1000; // Size of the vectorsfloat A[N], B[N], C[N]; // Arrays for vectors A, B, and C...float *d_A, *d_B, *d_C; // Device pointers for vectors A, B, and C// Allocate memory on the device for vectors A, B, and CcudaMalloc((void **)&d_A, N * sizeof(float));cudaMalloc((void **)&d_B, N * sizeof(float));cudaMalloc((void **)&d_C, N * sizeof(float));// Copy vectors A and B from host to devicecudaMemcpy(d_A, A, N * sizeof(float), cudaMemcpyHostToDevice);cudaMemcpy(d_B, B, N * sizeof(float), cudaMemcpyHostToDevice);// Kernel invocation with N threadsAddTwoVectors<<<1, N>>>(d_A, d_B, d_C);// Copy vector C from device to hostcudaMemcpy(C, d_C, N * sizeof(float), cudaMemcpyDeviceToHost);}我们需要使用指针,而不是直接将变量 A、B 和 C 传递给内核。在 CUDA 编程中,您不能在内核启动(<<<...>>>)中直接使用主机数组(如示例中的 A、B 和 C)。CUDA 内核在设备内存上运行,因此您需要将设备指针(d_A、d_B 和 d_C)传递给内核以供其运行。
除此之外,我们还需要使用 cudaMalloc 在设备上分配内存,并使用 cudaMemcpy 在主机和设备之间复制数据。
现在我们可以在代码末尾添加向量 A 和 B 的初始化,并刷新 cuda 内存。
#include <stdio.h>// Kernel definition
__global__ void AddTwoVectors(float A[], float B[], float C[]) {int i = threadIdx.x;C[i] = A[i] + B[i];
}int main() {int N = 1000; // Size of the vectorsfloat A[N], B[N], C[N]; // Arrays for vectors A, B, and C// Initialize vectors A and Bfor (int i = 0; i < N; ++i) {A[i] = 1;B[i] = 3;}float *d_A, *d_B, *d_C; // Device pointers for vectors A, B, and C// Allocate memory on the device for vectors A, B, and CcudaMalloc((void **)&d_A, N * sizeof(float));cudaMalloc((void **)&d_B, N * sizeof(float));cudaMalloc((void **)&d_C, N * sizeof(float));// Copy vectors A and B from host to devicecudaMemcpy(d_A, A, N * sizeof(float), cudaMemcpyHostToDevice);cudaMemcpy(d_B, B, N * sizeof(float), cudaMemcpyHostToDevice);// Kernel invocation with N threadsAddTwoVectors<<<1, N>>>(d_A, d_B, d_C);// Copy vector C from device to hostcudaMemcpy(C, d_C, N * sizeof(float), cudaMemcpyDeviceToHost);// Free device memorycudaFree(d_A);cudaFree(d_B);cudaFree(d_C);
}此外,我们需要在调用内核后添加 cudaDeviceSynchronize();。这是一个用于将主机线程与设备同步的函数。调用此函数时,主机线程将等待设备上所有先前发出的 CUDA 命令完成后再继续执行。
除此之外,添加一些 CUDA 错误检查也很重要,这样我们就可以识别 GPU 上的错误。如果我们不添加此检查,代码将继续执行主机线程(CPU),并且很难识别与 CUDA 相关的错误。
以下是两种技术的实现:
#include <stdio.h>// Kernel definition
__global__ void AddTwoVectors(float A[], float B[], float C[]) {int i = threadIdx.x;C[i] = A[i] + B[i];
}int main() {int N = 1000; // Size of the vectorsfloat A[N], B[N], C[N]; // Arrays for vectors A, B, and C// Initialize vectors A and Bfor (int i = 0; i < N; ++i) {A[i] = 1;B[i] = 3;}float *d_A, *d_B, *d_C; // Device pointers for vectors A, B, and C// Allocate memory on the device for vectors A, B, and CcudaMalloc((void **)&d_A, N * sizeof(float));cudaMalloc((void **)&d_B, N * sizeof(float));cudaMalloc((void **)&d_C, N * sizeof(float));// Copy vectors A and B from host to devicecudaMemcpy(d_A, A, N * sizeof(float), cudaMemcpyHostToDevice);cudaMemcpy(d_B, B, N * sizeof(float), cudaMemcpyHostToDevice);// Kernel invocation with N threadsAddTwoVectors<<<1, N>>>(d_A, d_B, d_C);// Check for errorcudaError_t error = cudaGetLastError();if(error != cudaSuccess) {printf("CUDA error: %s\n", cudaGetErrorString(error));exit(-1);}// Waits untill all CUDA threads are executedcudaDeviceSynchronize();// Copy vector C from device to hostcudaMemcpy(C, d_C, N * sizeof(float), cudaMemcpyDeviceToHost);// Free device memorycudaFree(d_A);cudaFree(d_B);cudaFree(d_C);
}要编译和运行 CUDA 代码,你需要确保系统上安装了 CUDA 工具包。然后,你可以使用 NVIDIA CUDA 编译器 nvcc 编译代码。如果你的机器上没有 GPU,则可以使用 Google Colab。你只需在运行时 → 笔记本设置中选择一个 GPU,然后将代码保存在 example.cu 文件中并运行:
%%shell
nvcc example.cu -o compiled_example # compile
./compiled_example # run# you can also run the code with bug detection sanitizer
compute-sanitizer --tool memcheck ./compiled_example 但是,我们的代码仍未完全优化。上面的示例使用大小为 N = 1000 的向量。但是,这个数字很小,无法完全展示 GPU 的并行化能力。此外,在处理深度学习问题时,我们经常处理具有数百万个参数的大量向量。
但是,如果我们尝试设置,例如 N = 500000,并使用上面的示例以 <<<1, 500000>>> 运行内核,它将抛出错误。因此,为了改进代码并执行此类操作,我们首先需要了解 CUDA 编程的一个重要概念:线程层次结构。
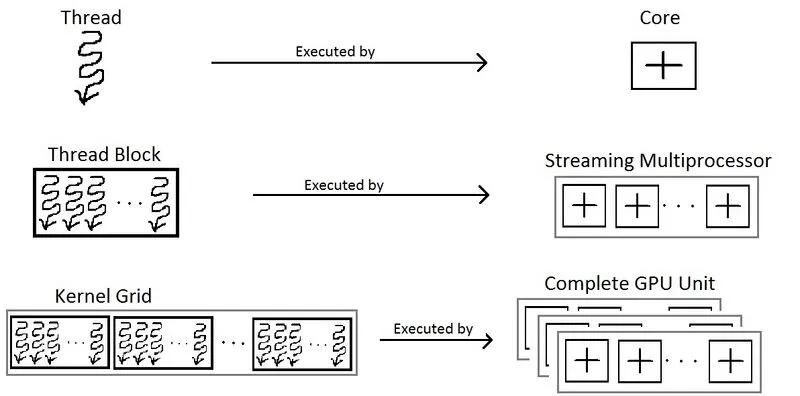
4、线程层次结构
内核函数的调用使用符号 <<<number_of_blocks,threads_per_block>>>完成。因此,在上面的例子中,我们运行具有 N 个 CUDA 线程的 1 个块。但是,每个块对其可以支持的线程数都有限制。发生这种情况的原因是,块内的每个线程都必须位于同一个流式多处理器核心上,并且必须共享该核心的内存资源。
可以使用以下代码片段获取此限制:
int device;
cudaDeviceProp props;
cudaGetDevice(&device);
cudaGetDeviceProperties(&props, device);
printf("Maximum threads per block: %d\n", props.maxThreadsPerBlock);在当前的 Colab GPU 上,一个线程块最多可以包含 1024 个线程。因此,我们需要更多块来执行更多线程,以便处理示例中的大量向量。此外,块被组织成网格,如下所示:
现在,可以使用以下方式访问线程 ID:
int i = blockIdx.x * blockDim.x + threadIdx.x;因此,我们的脚本变成:
#include <stdio.h>// Kernel definition
__global__ void AddTwoVectors(float A[], float B[], float C[], int N) {int i = blockIdx.x * blockDim.x + threadIdx.x;if (i < N) // To avoid exceeding array limitC[i] = A[i] + B[i];
}int main() {int N = 500000; // Size of the vectorsint threads_per_block;int device;cudaDeviceProp props;cudaGetDevice(&device);cudaGetDeviceProperties(&props, device);threads_per_block = props.maxThreadsPerBlock;printf("Maximum threads per block: %d\n", threads_per_block); // 1024float A[N], B[N], C[N]; // Arrays for vectors A, B, and C// Initialize vectors A and Bfor (int i = 0; i < N; ++i) {A[i] = 1;B[i] = 3;}float *d_A, *d_B, *d_C; // Device pointers for vectors A, B, and C// Allocate memory on the device for vectors A, B, and CcudaMalloc((void **)&d_A, N * sizeof(float));cudaMalloc((void **)&d_B, N * sizeof(float));cudaMalloc((void **)&d_C, N * sizeof(float));// Copy vectors A and B from host to devicecudaMemcpy(d_A, A, N * sizeof(float), cudaMemcpyHostToDevice);cudaMemcpy(d_B, B, N * sizeof(float), cudaMemcpyHostToDevice);// Kernel invocation with multiple blocks and threads_per_block threads per blockint number_of_blocks = (N + threads_per_block - 1) / threads_per_block;AddTwoVectors<<<number_of_blocks, threads_per_block>>>(d_A, d_B, d_C, N);// Check for errorcudaError_t error = cudaGetLastError();if (error != cudaSuccess) {printf("CUDA error: %s\n", cudaGetErrorString(error));exit(-1);}// Wait until all CUDA threads are executedcudaDeviceSynchronize();// Copy vector C from device to hostcudaMemcpy(C, d_C, N * sizeof(float), cudaMemcpyDeviceToHost);// Free device memorycudaFree(d_A);cudaFree(d_B);cudaFree(d_C);}5、性能比较
下面是针对不同向量大小的两个向量相加运算的 CPU 和 GPU 计算比较。
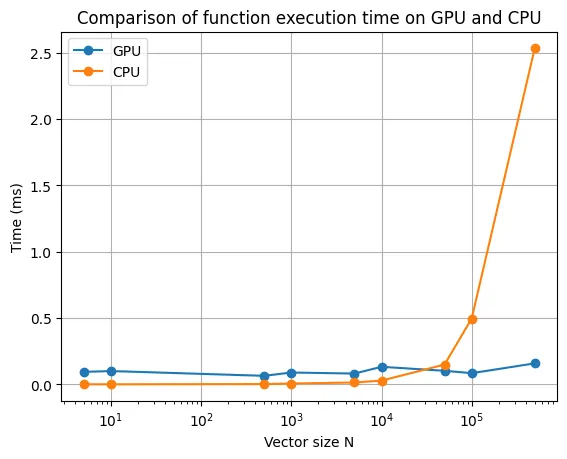
可以看出,GPU 处理的优势只有在向量大小为 N 时才明显。另外,请记住,这次时间比较仅考虑了内核/函数的执行。它没有考虑在主机和设备之间复制数据的时间,虽然在大多数情况下这可能并不重要,但在我们的例子中,由于我们只执行简单的加法运算,因此它相对重要。因此,重要的是要记住,GPU 计算仅在处理高度计算密集且高度并行化的计算时才显示其优势。
6、多维线程
好的,现在我们知道如何提高简单数组操作的性能。但是在处理深度学习模型时,我们需要处理矩阵和张量运算。
在我们之前的示例中,我们仅使用了具有 N 个线程的一维块。但是,也可以执行多维线程块(最多 3 个维度)。因此,为了方便起见,如果你需要运行矩阵操作,则可以运行 NxM 个线程的线程块。
在这种情况下,你可以获得矩阵行列索引,即 row = threadIdx.x, col = threadIdx.y。另外,为了方便起见,你可以使用 dim3 变量类型来定义 number_of_blocks 和 threads_per_block。
下面的示例说明了如何添加两个矩阵。
#include <stdio.h>// Kernel definition
__global__ void AddTwoMatrices(float A[N][N], float B[N][N], float C[N][N]) {int i = threadIdx.x;int j = threadIdx.y;C[i][j] = A[i][j] + B[i][j];
}int main() {...// Kernel invocation with 1 block of NxN threadsdim3 threads_per_block(N, N);AddTwoMatrices<<<1, threads_per_block>>>(A, B, C);...
}你还可以扩展此示例来处理多个块:
#include <stdio.h>// Kernel definition
__global__ void AddTwoMatrices(float A[N][N], float B[N][N], float C[N][N]) {int i = blockIdx.x * blockDim.x + threadIdx.x;int j = blockIdx.y * blockDim.y + threadIdx.y;if (i < N && j < N) {C[i][j] = A[i][j] + B[i][j];}
}int main() {...// Kernel invocation with 1 block of NxN threadsdim3 threads_per_block(32, 32);dim3 number_of_blocks((N + threads_per_block.x - 1) ∕ threads_per_block.x, (N + threads_per_block.y - 1) ∕ threads_per_block.y);AddTwoMatrices<<<number_of_blocks, threads_per_block>>>(A, B, C);...
}你还可以使用相同的想法扩展此示例以处理三维操作。
现在你已经知道如何操作多维数据,还有另一个重要而简单的概念需要学习:如何在内核中调用函数。基本上,这只需使用 __device__ 声明说明符即可完成。这定义了可以由设备(GPU)直接调用的函数。因此,它们只能从 __global__ 或另一个 __device__ 函数调用。下面的示例将 S 形运算应用于向量(深度学习模型上非常常见的操作)。
#include <math.h>// Sigmoid function
__device__ float sigmoid(float x) {return 1 / (1 + expf(-x));
}// Kernel definition for applying sigmoid function to a vector
__global__ void sigmoidActivation(float input[], float output[]) {int i = threadIdx.x;output[i] = sigmoid(input[i]);}因此,既然你已经了解了 CUDA 编程的基本重要概念,就可以开始创建 CUDA 内核了。在深度学习模型的情况下,它们基本上是一堆矩阵和张量运算,例如求和、乘法、卷积、归一化等。例如,一个简单的矩阵乘法算法可以按如下方式并行化:
![]()
// GPU version__global__ void matMul(float A[M][N], float B[N][P], float C[M][P]) {int row = blockIdx.x * blockDim.x + threadIdx.x;int col = blockIdx.y * blockDim.y + threadIdx.y;if (row < M && col < P) {float C_value = 0;for (int i = 0; i < N; i++) {C_value += A[row][i] * B[i][col];}C[row][col] = C_value;}
}现在将其与下面两个矩阵乘法的正常 CPU 实现进行比较:
// CPU versionvoid matMul(float A[M][N], float B[N][P], float C[M][P]) {for (int row = 0; row < M; row++) {for (int col = 0; col < P; col++) {float C_value = 0;for (int i = 0; i < N; i++) {C_value += A[row][i] * B[i][col];}C[row][col] = C_value;}}
}你可以注意到,在 GPU 版本中,我们的循环更少,从而可以更快地处理操作。以下是 CPU 和 GPU 之间 NxN 矩阵乘法的性能比较:
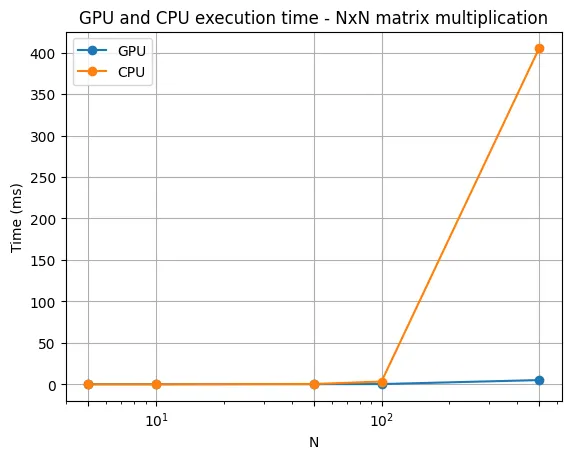
你可能会发现,随着矩阵大小的增加,GPU 处理矩阵乘法运算的性能提升甚至更高。
现在,考虑一个基本的神经网络,它主要涉及 y = σ(Wx + b) 运算,如下所示:
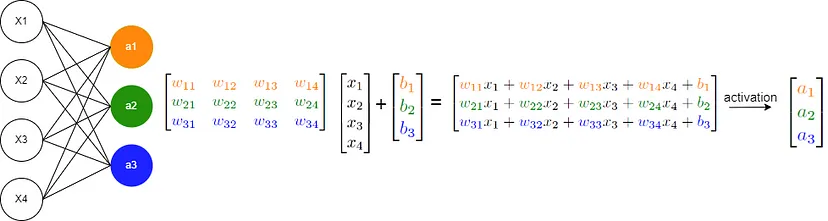
这些操作主要包括矩阵乘法、矩阵加法和将函数应用于数组,所有这些您都已经熟悉了并行化技术。因此,您现在可以从头开始实现在 GPU 上运行的自己的神经网络!
7、结束语
在这篇文章中,我们介绍了有关 GPU 处理的入门概念,以增强深度学习模型的性能。但是,同样重要的是,你看到的概念只是基础知识,还有很多东西需要学习。
像 PyTorch 和 Tensorflow 这样的库实现了优化技术,涉及其他更复杂的概念,例如优化的内存访问、批处理操作等(它们利用在 CUDA 之上构建的库,例如 cuBLAS 和 cuDNN)。但是,我希望这篇文章有助于澄清当你编写 .to("cuda") 并在 GPU 上执行深度学习模型时幕后发生的事情。
原文链接:CUDA编程从零到壹 - BimAnt
相关文章:
CUDA编程从零到壹
如今,当我们谈论深度学习时,为了提高性能,我们通常会将其实现与使用 GPU 联系起来。 GPU(图形处理单元)最初设计用于加速图像、2D 和 3D 图形的渲染。然而,由于它们能够执行许多并行操作,它们的…...

【国产开源可视化引擎】Meta2d.js API-Utils
Utils 常用功能函数 函数 formatPadding 将 padding 转换成数组格式 [top, right, bottom, left] padding 规则与 css padding 相同 参数: padding: Padding type Padding number | string | number[]; 返回: number[] 示例: formatP…...

大模型与数据分析的融合:创新与发展的新机遇
大模型与数据分析的融合:创新与发展的新机遇 前言大模型与数据分析的融合 前言 大模型与数据分析的融合正成为推动企业发展的关键力量。大模型在数据分析领域展现出了强大的能力。它能够以接近人类的水平理解和处理自然语言,快速、准确地解析大量非结构…...
基于融合正余弦和柯西变异的麻雀搜索算法SCSSA优化CNN-BiLSTM的多变量时间序列预测
matlab R2024a以上 一、数据集 二、融合正余弦和柯西变异的麻雀搜索算法 麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种新型的群体智能优化算法,其灵感来源于麻雀觅食行为。为了提高算法的性能,可以融合正余弦函数和柯西变…...

c++基本数据类型变量的最大值,最小值和内存空间
基本数据类型有哪些? 在C中,基本数据类型主要包括以下几种: 整型 (Integral Types): int:通常为32位,有 signed 和 unsigned 两种版本,如 int, unsigned int.short 或 signed short / unsigned …...

005集——运算符和循环——C#学习笔记
C# 提供了许多运算符。 其中许多都受到内置类型的支持,可用于对这些类型的值执行基本操作。 这些运算符包括以下组: 算术运算符,将对数值操作数执行算术运算比较运算符,将比较数值操作数布尔逻辑运算符,将对 bool 操作…...

【Tessent IJATG Users Manual】【Ch5】IJTAG Network Insertion
The IJTAG Network Insertion FlowIJTAG Network Insertion ExampleModification of the IJTAG Network Insertion Flow How to Edit or Modify a DftSpecificationEdit or Modify MethodDftSpecification Examples IJTAG Network Insertion 可以将已有的 instrument 连接起来&…...

我在高职教STM32——I2C通信入门(2)
大家好,我是老耿,高职青椒一枚,一直从事单片机、嵌入式、物联网等课程的教学。对于高职的学生层次,同行应该都懂的,老师在课堂上教学几乎是没什么成就感的。正是如此,才有了借助CSDN平台寻求认同感和成就感的想法。在这里,我准备陆续把自己花了很多心思设计的教学课件分…...

GPT解逻辑数学题之8个8变1000的故事
目录 初试正解 我: GPT4: 再问思索 我: GPT4: 提醒错误 我: GPT4: 给出正解提示 我: GPT4: 不愿放弃 我: GPT4: 再次尝试 我: …...

10、MySQL-索引
目录 1、索引概述 2、索引结构 2.1 BTree 2.2 BTree 2.3 Hash 3、索引分类 4、索引语法 4.1 创建索引 4.2 查看索引 4.3 删除索引 5、SQL性能分析 5.1 SQL执行频率 5.2 慢查询日志 5.3 profile详情 5.4 explain执行计划 6、索引使用 6.1 验证索引效率 6.2 最左…...

【python】Python操作Redis数据库的详细教程与应用实战
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

【数据结构的——红黑树】
目录 一、红黑树简介二、红黑树的特性三、2-3-4树与红黑树的等价关系四、红黑树的操作4.1、旋转操作4.2、红黑树的插入4.2.1、情形一4.2.2、情形二4.2.3、情形三4.2.4、情形四4.2.5、情形五4.2.6、情形六4.2.7、对插入进行小结4.3、红黑树的删除4.3.1、情形一4.3.2、情形二4.3.…...

第十二章:设置pod和容器权限-保障集群内节点和⽹络安全
本章内容包括: 在pod中使用宿主机节点的默认Linux命名空间以不同用户身份运行容器运行特权容器添加或禁用容器内核功能定义限制pod行为的安全策略保障pod的网络安全 谈到了如何保障API服务器的安全。如果攻击者获得了访问API服务器的权限,他们可以通过在…...

灵途科技再度入选2024年度“光谷瞪羚”企业名单!
今年5月,东湖高新区启动了2024年度“光谷瞪羚”企业认定工作,共有549家企业拟被认定为“光谷瞪羚”企业。作为泛自动驾驶领域光电感知专家,灵途科技凭借其快速成长、强大创新能力和巨大发展潜力,再次获得“光谷瞪羚”企业的荣誉。…...

Centos7.6配置阿里云镜像源
1、备份本地镜像源,将/etc/yum.repos.d/下所有文件备份到/etc/yum.repos.d/bak/下 2、下载阿里云镜像 wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo 3、清除yum缓存-yum clean all 4、验证镜像源仓库 yum repolist...

梨子的功效与作用 梨子生吃熟吃功效竟大不同
梨,这一寻常的水果,因其独特的口感和丰富的营养价值,深受人们的喜爱。梨子不仅味道甜美,而且具有多种功效与作用,无论是生吃还是熟吃,都能给人体带来诸多益处。然而,你是否知道,生吃…...

北斗三号5G遥测终端机系统在水库大坝安全监测应用
一、概述 我国现有水库大坝9.8万余座,是世界上拥有水库大坝最多的国家。这些水库大坝在防洪、发电、供水、灌溉等方面发挥巨大效益的同时,所存在的安全风险不容忽视。大坝安全监测是大坝安全管理的重要内容,是控制大坝风险的重要措施。大坝安…...

代码随想录算法训练营第五十一天|99.岛屿数量 深搜 、99.岛屿数量 广搜、岛屿的最大面积
#99. 岛屿数量 深度优先搜索: 每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。 本题思路:用遇到一个没有遍历过的节点陆地,计数器就加一,然后把该节点陆地所能遍历到的陆地都标记上。在遇到标记过的陆地节点和海洋…...

【c++刷题笔记-图论】day62:Floyd 算法、A * 算法精讲
Floyd 算法 重点:多源最短路径算法,前的最短路径算法是单源的也就是只有一个起点。递推每个节点之间最短的路径 时间复杂度: O(n^3)空间复杂度:O(n^2) #include <iostream> #include <vector> using namespace std…...

FPGA知识基础之--clocking wizard ip核的使用以及modelsim与vivado联合仿真
目录 前言一、ip核是什么?1.1 定义1.2 分类 二、为什么使用ip核2.1 ip核的优点2.2 ip核的缺点 三、如何使用ip核(vivado)四、举例(clocking wizard ip核)4.1 简介4.2 实验任务4.3 程序设计4.3.1 系统模块4.3.2 波形绘制…...

OpenClaw+千问3.5-35B-A3B-FP8:自动化技术文档翻译系统
OpenClaw千问3.5-35B-A3B-FP8:自动化技术文档翻译系统 1. 为什么需要自动化文档翻译 去年参与一个开源项目时,我遇到了多语言文档维护的困境。项目文档需要同步维护中英文版本,每次更新都要经历"写中文→翻译→调整格式→校对"的…...
)
告别景深烦恼:用PyTorch+PyQt5打造你的专属多焦点图像融合桌面工具(附完整源码)
告别景深烦恼:用PyTorchPyQt5打造你的专属多焦点图像融合桌面工具 每次拍摄微距或静物时,是否总在景深和清晰度之间纠结?按下快门后才发现前景清晰时背景模糊,背景聚焦时前景又失焦。专业摄影师会告诉你:这是光学镜头的…...

从零到一:基于MMPretrain框架定制化训练专属图像分类模型
1. 环境准备与框架安装 第一次接触MMPretrain时,我对着官方文档折腾了半天环境配置。后来发现用mim这个包管理工具能省去80%的依赖问题。先确保你的Python环境是3.7版本,然后执行下面这组命令: pip install openmim mim install mmengine mim…...

正则表达式元字符详解:learn-regex-zh 进阶教程
正则表达式元字符详解:learn-regex-zh 进阶教程 【免费下载链接】learn-regex-zh :cn: 翻译: 学习正则表达式的简单方法 项目地址: https://gitcode.com/gh_mirrors/le/learn-regex-zh 正则表达式是一种强大的文本处理工具,而元字符是构建正则表达…...

课堂学习1
Miniconda 安装教程 (2026版) Anaconda 是最流行的 Python 和 R 语言数据科学平台,它包含了康达包管理器(Conda)、Python 以及 1500 个科学包及其依赖项。Miniconda 可以看作是 Anaconda 的“轻装版”,只自带 conda …...
)
新手必看:用Wireshark分析CTF流量包的5个实战技巧(附BUUCTF真题解析)
新手必看:用Wireshark分析CTF流量包的5个实战技巧(附BUUCTF真题解析) 当你第一次打开一个陌生的pcap文件时,面对密密麻麻的数据包列表,是不是感觉无从下手?作为CTF比赛中最常见的题型之一,流量分…...

别再硬记索引了!Mujoco Python API实战:用`name`属性优雅读写机器人关节状态
别再硬记索引了!Mujoco Python API实战:用name属性优雅读写机器人关节状态 在机器人仿真开发中,我们常常陷入这样的困境:面对一个20自由度的机械臂,需要反复查阅文档确认data.qpos[12]对应的是哪个关节;当X…...

嵌入式系统错误处理策略与实现技术
1. 嵌入式系统中的错误处理概述在嵌入式软件开发中,错误处理是确保系统稳定性和可靠性的关键环节。与通用计算机系统不同,嵌入式系统往往运行在资源受限的环境中,且需要长时间不间断工作,这使得错误处理策略的选择尤为重要。嵌入式…...

YOLOv11涨点改进| TPAMI 2025顶刊 |独家创新首发、Conv改进篇| 引入LPRM局部像素关系卷积模块,提升细节表达和边界定位能力,助力小目标检测、语义分割、图像分割、图像增强有效涨点
一、本文介绍 🔥本文给大家介绍使用 LPRM局部像素关系卷积模块 改进YOLOv11网络模型,通过建模局部像素之间的关系对特征进行细化优化,使模型在特征融合或上采样阶段能够更好地恢复空间结构信息并增强区域间的上下文联系。其优势体现在能够提升细节表达和边界定位能力,增强…...

智慧校园系统怎么选?看懂这 5 个核心功能再决定不迟
✅作者简介:合肥自友科技 📌核心产品:智慧校园系统(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...