RAGFlow v0.9 重磅升级,支持 GraphRAG,开启下一代 RAG 之旅!

一、引言
前面我们介绍过很多的关于大模型和RAG相关的技术,通过其关注程度足以看到市场上对RAG框架和成熟产品的迫切需求,因为想要个人独立从0开始实现一个RAG产品并非易事,虽然有相当多的RAG或者知识库开源产品,大部分其实很难应用于实际生产环境,很多都只能算是一个简单的演示 demo 的基本实现,并没有针对不同行业不同场景实际的需求进行覆盖和完善,光一个文档深度学习和内容解析,在面对各种复杂的文档格式,有些不规则的文档内容、以及一些包括复杂表格和图片的文档,如何有效的将其内容完整的提取出来输入给大模型本身就存在非常多的困难和挑战需要突破,就算使用目前通用的 GPT-4o 和 Gemini Pro 等超大模型,其效果和准确率也是有限的。
然而,现有的 RAG 系统,即 RAG 1.0,大多依赖简单的语义相似度搜索,在处理海量、复杂的企业级数据时,面临着效率和准确性的双重挑战,同时还存在检索召回率低、缺乏精确检索能力。这导致了所谓的“垃圾输入,垃圾输出”(GIGO)问题:如果输入数据质量不高,即使 LLM 能力再强,生成的答案也难以令人满意,也就是我们上面讲到的高质量文档数据输入问题。
正是在这种完全依赖大模型解决GPU算力成本还太高且又有很多迫切需求的背景下,开源界传来了好消息,RAGFlow 应运而生,它致力于打造一个以搜索为中心的端到端优化系统,从根本上解决 RAG 1.0 的局限性。RAGFlow 的设计理念是“高质量输入,高质量输出”,它通过深度文档理解技术,智能识别文档结构和内容,确保数据的高质量输入,为 LLM 提供更精准、更可靠的答案。

2024 年 4 月 1 日,RAGFlow 正式开源,这一消息在技术界引起轰动。开源不到一周时间,RAGFlow 在 GitHub 上就已收获 2900 颗星,而不到 4 个月的时间,这一数字已飙升至 13600,足以说明其受欢迎程度。虽然很多小伙伴在实际体验了 RAGFlow 产品之后反馈目前的版本还是存在非常多的 bug 未修复,相信按 RAGFlow 现在的发展和迭代速度,估计迭代俩版本就能稳定下来了,让我们拭目以待。

RAGFlow v0.9 版本于两天前正式发布,从发布日志中可以看到令人期待的新功能和体验升级。该版本不仅标志着 RAG 系统迈向知识图谱增强的RAG 2.0 时代,还针对之前版本用户的反馈,修复了大量bug,进一步提升了稳定性和易用性。
此次更新的一大亮点是对 GraphRAG 的正式支持,为 RAG 系统注入知识图谱的强大能力,显著提升了答案的精准度和可解释性。此外,v0.9 版本还新增了关键词提取、百度/DuckDuckGo/PubMed/Wikipedia/Bing/Google 搜索等 Agent 运算符,扩展了信息检索渠道。用户现在还可以使用 ASR 语音转文本功能,方便地输入音频文件。
为了满足用户多样化的需求,RAGFlow v0.9 兼容了 Gemini、Groq 等更多 LLMs,并集成了 xinference reranker,进一步提升答案质量。同时,该版本还增加了对 LM Studio/OpenRouter/LocalAI/Nvidia API 等推理框架/引擎/服务的支持,为用户构建和部署 RAG 系统提供更多便利。
二、RAG 1.0 :语义相似度搜索的瓶颈
早期的 RAG 系统,即 RAG 1.0,主要依赖于语义相似度搜索技术。其工作原理是将文档分割成数据块,并利用嵌入模型将其转换为向量表示,存储在向量数据库中。当用户提出问题时,系统会将问题转换为向量,并在数据库中搜索语义最相似的文档块,将其作为 LLM 的参考信息。

然而,随着 LLM 应用场景的不断拓展,这种看似直观的传统方法逐渐暴露出其局限性:
- 召回率低: RAG 1.0 通常采用简单的文档分块策略,忽略了文档内部细粒度的语义结构,导致许多包含关键信息的文档块无法被检索到,从而降低了答案的召回率,很多开源知识库项目基本上就是采用的这种方案。
- 缺乏精确检索能力: 语义相似度搜索只能找到与查询内容“大致相关”的信息,而无法满足用户对时间、主题、实体等方面的精确检索需求,尤其是在处理一些需要精确匹配的专业问题时,RAG 1.0 往往难以胜任。
- 过度依赖嵌入模型: RAG 1.0 的检索效果与嵌入模型的选择密切相关,而通用嵌入模型在特定领域的性能往往难以令人满意,这限制了 RAG 系统在专业领域的应用。
- 忽略文档结构: RAG 1.0 简单的文档分块方法忽略了文档本身的结构信息,例如章节标题、表格数据、图片注释等,这些信息对于理解文档内容、提取关键信息至关重要,而 RAG 1.0 的处理方式无疑会导致信息丢失,影响答案质量。
- 缺乏用户意图识别: 用户的问题表述往往与其真实意图存在差异,而 RAG 1.0 缺乏对用户意图的深度理解,只能进行简单的关键词匹配,导致检索结果与用户预期存在偏差。
- 无法处理复杂查询: 现实场景中的许多问题都需要进行多轮推理才能得到答案,而 RAG 1.0 仅限于处理简单的单轮问答,无法满足复杂查询的需求。
总而言之,RAG 1.0 虽然为 LLM 的应用打开了新的局面,但其简单的架构和对语义相似度搜索的依赖,使其在面对海量、复杂的企业级数据时,显得力不从心。为了突破 RAG 1.0 的瓶颈,我们需要一种更加智能、高效、精准的 RAG 解决方案,而 RAGFlow v0.9 版本带来的 GraphRAG 正是为此而生。
三、RAG 2.0:以搜索为中心的端到端优化
为了解决 RAG 1.0 的局限性,新一代 RAG 架构,即 RAG 2.0,应运而生。 RAG 2.0 将 RAG 系统视为一个以搜索为中心的端到端流程,并将其细化为四个关键阶段:信息提取、文档预处理、索引构建和检索。

与 RAG 1.0 不同的是,RAG 2.0 强调对数据处理流程的精细化控制,每个阶段都围绕模型和算法进行优化,以确保最终答案的质量。例如,
- 在信息提取阶段:RAG 2.0 采用更精细的文档解析和信息抽取技术,保留更多关键信息
- 在文档预处理阶段:RAG 2.0 引入了知识图谱构建、文档聚类等技术,为检索提供更丰富的上下文信息
- 在索引构建阶段:RAG 2.0 支持向量搜索、全文搜索、张量搜索等多种混合搜索方式,提升检索效率和精度
- 在检索阶段:RAG 2.0 引入了查询重写、意图识别等技术,优化检索策略
为了更好地支持 RAG 2.0 架构, RAGFlow 不是简单地将 RAG 1.0 的组件拼凑起来,而是从底层架构上进行了重新设计,以模型和算法为核心,为用户提供更灵活、更高效、更精准的 RAG 解决方案。
具体来说,RAGFlow 在以下几个方面体现了对 RAG 2.0 的支持:
- 深度文档理解: RAGFlow 采用先进的文档解析和信息抽取技术,能够处理各种复杂的文档格式,并提取关键信息,为后续的知识图谱构建、索引构建等环节提供高质量的数据基础。
- 混合搜索: RAGFlow 集成了多种搜索技术,包括向量搜索、全文搜索和张量搜索,能够根据不同的数据类型和查询需求,灵活选择最优的搜索策略,提升检索效率和精度。
- 知识图谱增强: RAGFlow 支持 GraphRAG 等知识图谱构建技术,能够自动从文本数据中抽取实体和关系,构建知识图谱,为 LLM 提供更丰富的上下文信息,提升答案的精准性和可解释性。
- 查询优化: RAGFlow 引入了查询重写、意图识别等技术,能够根据用户的查询意图,动态调整检索策略,提高答案的精准度和相关性。
RAG 2.0 中的每个阶段本质上都以模型为中心。他们与数据库结合工作,以确保最终答案的有效性。
因此,RAG 2.0 相比 RAG 1.0 会复杂很多,其核心是数据库和各种模型,需要依托一个平台来不断迭代和优化,这就是我们开发并开源 RAGFlow 的原因。它没有采用已有的 RAG 1.0 组件,而是从整个链路出发来根本性地解决 LLM 搜索系统的问题。当前,RAGFlow 仍处于初级阶段,系统的每个环节,都还在不断地进化中。由于使用了正确的方式解决正确的问题,因此自开源以来 RAGFlow 只用了不到 3 个月就获得了 Github 万星。当然,这只是新的起点。
四、RAGFlow v0.9:深度融合 GraphRAG
在 RAGFlow 体系中,我们对下一代 RAG (RAG 2.0) 的定义更加完整:它是一个以搜索为中心的端到端优化系统。RAG 2.0 共分为四个阶段,其中索引与检索阶段通常需要专用数据库提供支持,而前两个阶段,即数据抽取和预处理,则扮演着至关重要的角色。
数据抽取阶段,我们利用各类文档模型,例如强大的大型语言模型 (LLM),来确保被索引数据的质量,避免出现“垃圾输入,垃圾输出”(Garbage In, Garbage Out) 的情况。
在数据进入数据库之前,我们还可以选择性地进行一些预处理,包括文档预聚类和知识图谱构建等。这些预处理步骤主要用于解决多跳问答和跨文档提问等复杂场景。
GraphRAG 作为一种面向下一代 RAG 的解决方案应运而生。在 RAG 2.0 的体系中,它可以被视为整个流程中的一个重要单元。从 RAGFlow 的 0.9 版本开始,我们已经将 GraphRAG 集成到系统当中。
那么,为什么选择引入 GraphRAG? 它与微软提出的 GraphRAG 又有哪些区别和联系?
知识图谱对提升 RAG 的效果至关重要。传统的 RAG 系统只能根据提问检索答案,找到的往往是与提问相似的结果,而非精准答案。例如,对于一些需要总结归纳的问题,简单的关键词匹配显然无法满足需求。
这类问题本质上是一种聚焦于查询的总结 (Query Focused Summarization, QFS)。利用知识图谱可以很好地解决这类问题。知识图谱能够根据文本相关性将内容聚合,在对话过程中根据这些聚合信息生成总结,从而精准地回答用户问题。目前,很多专用 AI 搜索引擎都在采用这种方法。
之前的 RAGFlow 版本提供的 RAPTOR 功能也是对文本进行聚类,与上述原理类似。但相比之下,以知识图谱为中心的方法可以构建以命名体实体节点为中心的层次化结果,在处理 QFS 查询时,能够提供更准确、更系统的答案。
不仅如此,在其他一些场景中,知识图谱也能改善 RAG 的返回结果。它能够为返回结果添加更丰富的上下文信息,使 LLM 可以生成更具解释性的答案。
大量研究工作已经证明了知识图谱在 RAG 中的有效性。因此,GraphRAG 一经推出就迅速获得了社区的广泛关注。
当然,利用知识图谱进行问答并非新鲜事。早在 RAG 出现之前,KGQA 就已经存在多年。但这些工作一直面临着一个瓶颈:如何实现知识图谱构建的自动化和标准化。这也阻碍了基于知识图谱的问答系统在企业级场景中的大规模应用。
随着 LLM 和 RAG 的出现和普及,使用 LLM 自动构建知识图谱成为了一种可行的方案,GraphRAG 就是其中的佼佼者。
然而,GraphRAG 在实际应用中也面临一些挑战。例如,在实体抽取过程中,可能会出现多个同义词对应同一个实体的情况,影响知识图谱的准确性。此外,GraphRAG 需要多次调用 LLM, 尤其是在处理大规模数据集时,会不可避免地消耗大量的 Token,增加使用成本。
为了解决这些问题,RAGFlow 在 GraphRAG 的基础上进行了一系列优化和改进,使其更适用于实际应用场景:
- 实体去重: 为了解决 GraphRAG 在实体抽取过程中可能出现的同义词问题,RAGFlow 引入了实体去重机制。它利用 LLM 的语义理解能力,自动识别和合并表示相同实体的不同名称,例如将 “2024” 和 “2024 年” 合并为同一个实体,从而提高知识图谱的准确性。
- 降低 Token 消耗: GraphRAG 在构建知识图谱的过程中,需要多次调用 LLM,这在处理大规模数据集时会消耗大量的 Token。为了降低使用成本,RAGFlow 对 GraphRAG 的流程进行了优化,尽可能减少 LLM 的调用次数,并通过缓存机制避免重复计算,从而有效降低 Token 的消耗量。
简而言之,GraphRAG 对知识图谱的抽象和构建进行了简化,使其更易于工程化和标准化,推动了基于知识图谱的问答系统在实际应用中的落地。RAGFlow 借鉴了 GraphRAG 的实现,并在其基础上进行了一系列改进,例如引入去重步骤、降低 Token 消耗等,使其更加高效和实用。
五、总结与展望:知识图谱赋能 RAG 的未来
RAGFlow v0.9 的发布,标志着知识图谱增强型 RAG 系统 (RAG 2.0) 的全新时代正式开启。 GraphRAG 作为其中的先行者,展现了 LLM 驱动下的知识图谱构建技术所蕴含的巨大潜力。 它不仅为 RAG 系统注入了更强大的语义理解和知识推理能力,也为智能问答、语义搜索、知识发现等领域的应用打开了新的大门。
GraphRAG 之所以能够取得成功,很大程度上得益于它对传统知识图谱构建流程的简化,使其更容易在实际工程中落地。 然而,我们必须认识到,这仅仅是知识图谱与 RAG 结合的开始,未来还有广阔的探索空间。
现有的 GraphRAG 主要面向能够构建知识图谱的结构化和半结构化数据, 但在实际的企业级应用中,还有大量数据并不适合构建知识图谱, 也有一些场景需要考虑成本因素,无法对所有数据进行知识图谱构建。
因此,如何将知识图谱的优势应用到更广泛的数据类型上,如何在成本可控的情况下构建和利用知识图谱,将是未来 RAGFlow 需要着重解决的问题。
为了进一步释放知识图谱的潜力, RAGFlow 未来的发展方向将包含以下几个方面:
- 突破数据限制,构建跨文档知识图谱: 未来的 RAG 系统需要具备处理更复杂数据的能力。RAGFlow 将探索构建跨越多个文档的知识图谱, 以捕捉更复杂的语义关系, 提升系统对复杂问题的理解和推理能力,打破数据之间的壁垒。
- 深入挖掘语义信息,实现知识图谱驱动的查询改写: 为了进一步提升检索的精准度, RAGFlow 将探索利用知识图谱中的语义信息,对用户查询进行改写和扩展, 帮助系统更准确地理解用户意图, 返回更符合用户需求的结果。
- 拓展知识维度,实现多模态知识融合: 未来的 RAG 系统需要能够理解和处理更加多元的信息。RAGFlow 将探索将文本、图像、视频等多模态信息融入知识图谱,构建更全面的知识表示,支持更丰富的问答场景,例如结合图片和文字进行问答等。
除了对知识图谱应用的探索, RAGFlow 还将持续进行功能开发和完善,打造更加强大和易用的 RAG 系统,例如:
- Text2SQL: 支持用户使用自然语言进行数据库查询,方便用户从结构化数据中获取信息,降低使用门槛。
- 多模态代理: 支持 TTS (语音合成) 和类似 Perplexity 的搜索代理, 为用户提供更便捷、更自然的交互体验。
- OpenAI 兼容 API: 提供与 OpenAI 兼容的 API,方便开发者将 RAGFlow 集成到现有应用中, 降低开发成本。
- 更丰富的文件格式支持: 支持解析 eml 等更多类型的文件, 扩展系统的应用场景, 满足更多用户的需求。
我们相信, 随着 RAGFlow 等开源项目的不断发展,知识图谱将与 RAG 技术更加紧密地结合,共同推动智能问答系统朝着更智能、更可靠、更易用的方向发展,为用户带来更优质的智能体验。
🚀🎁 为了方便大家快速学习和掌握大模型在实际业务场景中的实践应用,我整理了一份大模型精选资源包,包含我在探索和实践大模型过程中积累的各种资料,主要包括如下内容:
🔥 大模型文档 & 教程
🔥 大模型前沿趋势解读
🔥 最新研究报告 & 企业落地案例
关注公众号「技术狂潮AI」回复以下关键词即可快速获取:
01「大模型专栏|AI Agent」👉 回复关键词 「AI Agent」 获取
02「大模型专栏|企业落地」👉 回复关键词 「企业落地」 获取
03「大模型专栏|学习资源」👉 回复关键词 「学习资源」 获取
04「大模型专栏|行业趋势」👉 回复关键词 「行业趋势」 获取
05「大模型专栏|研究报告」👉 回复关键词 「研究报告」 获取
06「大模型专栏|技术大会」👉 回复关键词 「技术大会」 获取
07「企业数字化|转型合集」👉 回复关键词 「企业转型」 获取
所有资料都会持续更新,敬请期待!
六、参考资料
[1]. RAGFlow GitHub: https://github.com/infiniflow/ragflow
[2]. RAGFlow Demo: https://demo.ragflow.io/
[3]. GraphRAG, https://github.com/microsoft/graphrag
[4]. From Local to Global: A Graph RAG Approach to Query-Focused Summarization, https://arxiv.org/abs/2404.16130
[5]. HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models , https://arxiv.org/abs/2405.14831
相关文章:
RAGFlow v0.9 重磅升级,支持 GraphRAG,开启下一代 RAG 之旅!
一、引言 前面我们介绍过很多的关于大模型和RAG相关的技术,通过其关注程度足以看到市场上对RAG框架和成熟产品的迫切需求,因为想要个人独立从0开始实现一个RAG产品并非易事,虽然有相当多的RAG或者知识库开源产品,大部分其实很难应…...

MySQL的InnoDB的页里面存了些什么
文章目录 创建新表页的信息新增一条数据根据页号找数据信息脚本代码py_innodb_page_info根据地址计算页号根据页号计算起始地址 主要介绍数据页里面有哪些内容,一行数据在文件里面是怎么组织的 创建新表页的信息 CREATE TABLE test8 (id bigint(20) NOT NULL AUTO…...

SQL Server 事务
1. 什么是事务 SQL Server 事务是数据库操作的一个基本特性,它允许你将一系列数据库操作组合成一个原子单元,这个单元中的所有操作要么全部成功,要么全部失败。事务具有以下四个重要的属性,通常被称为ACID属性。 2、事务的特性 原…...

qt quick实现的水波纹特效:横向波纹、纵向波纹效果
qml实现的水波纹特效 1.横向波纹效果2.另一种效果(纵向波纹) 一直以来使用c qt如果要实现一些高级特效比如水波纹效果都难度比较大,但是使用qt quick难度就会小很多。这里借鉴一些网友的思路简单实现一下水波纹效果。主要思路就是波浪的形成是…...

释放数据要素价值,FISCO BCOS 2024 应用案例征集
2024年,国家数据局等17部门联合印发《“数据要素”三年行动计划(2024—2026年)》,《行动计划》指出,发挥数据要素的放大、叠加、倍增作用,构建以数据为关键要素的数字经济,是推动高质量发展的必…...
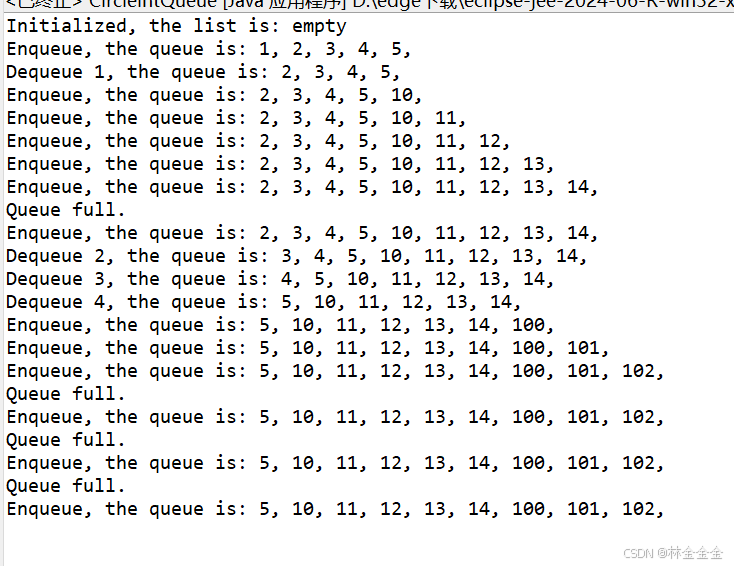
日撸Java三百行(day18:循环队列)
目录 一、顺序队列与循环队列 二、代码实现 1.循环队列创建 2.循环队列遍历 3.循环队列入队 4.循环队列出队 5.数据测试 6.完整的程序代码 总结 一、顺序队列与循环队列 在昨天,我们提到队列实现除了采用链式存储结构,还可以采用顺序存储结构&…...

论文精读1
Equivariant Pretrained Transformer for Unified Geometric Learning on Multi-Domain 3D Molecules 核心公式: 论文导图 创新在统一分子建模和块级去噪预训练。...

uniapp免费申请苹果证书教程每次7天可用于测试
准备一个苹果账号没有加入过任何组织的 然后下载appuploader下载链接 登录上去切记勾选上未付苹果688 然后点击苹果证书创建p12证书 创建描述文件 uniapp打包自定义基座 这就打包好了可以愉快地开发了,但每次生成只有7天,设备限制3个,…...

【优秀python大屏】基于python flask的广州历史天气数据应用与可视化大屏
摘要 气象数据分析在各行各业中扮演着重要的角色,尤其对于农业、航空、海洋、军事、资源环境等领域。在这些领域中,准确的气象数据可以对预测未来的自然环境变化和采取行动来减轻负面影响的决策起到至关重要的作用。 本系统基于Python Flask框架&#…...
:eBPF初体验)
eBPF编程指南(一):eBPF初体验
1 什么是EBPF? EBPF是一种可以让程序员在内核态执行自己的程序的机制,但是,为了安全起见,无法像内核模块一样随意调用内核的函数,只能调用一些bpf提前定义好的函数。为了让内核执行程序员自己的代码,需要指…...

pip笔记
pip介绍 pip的全称:package installer for python,也就是Python包管理工具。 配置镜像源 镜像列表 阿里云 http://mirrors.aliyun.com/pypi/simple/中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/豆瓣 http://pypi.douban.com/simple/清华大…...

centos安装postgresql-12
安装pg文件 sudo curl -o /etc/yum.repos.d/pgdg-redhat-all.repo https://mirrors.aliyun.com/postgresql/repos/yum/12/redhat/rhel-7-x86_64/pgdg-redhat-all.repo 清楚缓存重新安装 sudo yum clean all sudo yum makecache 如果报错 删除现有的文件 sudo rm /etc/yum.r…...

Npm使用教程
Npm使用教程 Npm(Node Package Manager)是Node.js的包管理工具和软件包管理系统,广泛用于JavaScript项目的依赖管理和包发布。本文将为你提供一份详细的Npm使用教程,从安装、基本命令、包管理到高级用法,帮助你全面掌…...

【Android Studio】修改项目名称can‘t rename root module解决办法
文章目录 问题现象解决办法 问题现象 修改项目名称 但是直接rename 又会出现 can‘t rename root module 的警告 下图方式只适合修改除项目级别以外的,直接修改项目名称则会报错 解决办法 此时我们只要两步就可以成功修改项目名称了 关闭项目修改其文件夹名称…...

豆瓣Top250电影数据分析可视化系统(Flask+Mysql+Pyecharts)
爬取目标网址:豆瓣Top250 可以看到进入每条电影的详细链接后,显示的内容会更加详细一点 因此我们需要先利用爬虫技术从主页爬取到每条电影的链接,再分别遍历每条电影的链接,获取它的详细内容,这里仅展示一部分代码 利…...

软件质量保证计划书(2024Word完整版)
软件质量保证计划书要点:确立质量目标,组建质保团队,规划全程质控活动,设定质量标准,明确各阶段检查与评审流程,确保各角色职责清晰。强化过程监控,注重数据度量,旨在通过持续改进&a…...

【学习笔记】Matlab和python双语言的学习(动态规划)
文章目录 前言一、动态规划动态规划的基本步骤示例1示例2 三、代码实现----Matlab1.示例12.示例2 四、代码实现----python1.示例12.示例2 总结 前言 通过模型算法,熟练对Matlab和python的应用。 学习视频链接: https://www.bilibili.com/video/BV1EK411…...

低代码开发:机遇与挑战的双重探索
随着科技的迅速发展,“低代码”开发平台悄然兴起,为非专业程序员提供了构建应用程序的快捷途径。无疑,这一创新技术正在颠覆传统的软件开发模式,并激发了IT行业的热烈讨论。但究竟低代码平台是提高开发效率的有利工具,…...

Docker最佳实践(三):安装mysql
大家好,欢迎各位工友。 本篇呢我们就来演示一下如何在Docker中部署MySQL容器,可以按照以下步骤进行: 1. 搜索镜像 首先搜索MySQL镜像,可以使用以下命令: docker search mysql2. 拉取镜像 根据需求选择MySQL或Maria…...

进阶SpringBoot之 Web 静态资源导入
idea 创建一个 web 项目 新建 controller 包下 Java 类,用来查验地址是否能成功运行 package com.demo.web.controller;import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController;RestControl…...

实战指南:用Python的pyttsx3库打造你的专属语音助手
1. 从零认识pyttsx3:你的代码会说话 第一次听到电脑用标准播音腔朗读出我写的文字时,那种感觉就像小时候收到会说话的生日贺卡。pyttsx3这个神奇的Python库,能让任何文本通过声卡变成人声。不同于需要联网的语音合成服务,它完全离…...

游戏盾导致 Unity/UE 引擎崩溃的主要原因排查?
做游戏上线的都知道,游戏盾是必装的——毕竟要防外挂、防攻击,不然刚上线就被搞崩,损失太大。但最近帮几个同行排查问题,发现好多项目接入游戏盾后,Unity和UE引擎动不动就崩,要么内存飙到爆,安卓…...

2026届学术党必备的六大AI学术神器推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 基于自然语言处理以及深度学习算法的AI论文查重技术,经过对文本的语义结构、句式…...

SEO_中小企业如何低成本做好SEO?实用方案分享
为什么中小企业需要关注SEO 在当今数字化经济时代,中小企业如果想要在竞争激烈的市场中脱颖而出,关注SEO(搜索引擎优化)是必不可少的。SEO不仅能够提升网站的搜索引擎排名,还能有效带来更多的潜在客户。许多中小企业在…...

高效部署Kafka Connect集群:AKHQ的5个进阶实战策略
高效部署Kafka Connect集群:AKHQ的5个进阶实战策略 【免费下载链接】akhq Kafka GUI for Apache Kafka to manage topics, topics data, consumers group, schema registry, connect and more... 项目地址: https://gitcode.com/gh_mirrors/ak/akhq Apache K…...

FlutterFire云函数终极部署指南:Firebase函数一键部署前必做的10个检查
FlutterFire云函数终极部署指南:Firebase函数一键部署前必做的10个检查 【免费下载链接】flutterfire 🔥 A collection of Firebase plugins for Flutter apps. 项目地址: https://gitcode.com/gh_mirrors/fl/flutterfire FlutterFire是Firebase官…...

3步构建数字记忆堡垒:开源工具GetQzonehistory数据留存全攻略
3步构建数字记忆堡垒:开源工具GetQzonehistory数据留存全攻略 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字时代,我们的生活轨迹日益依赖在线平台&#…...

kprobe函数入口时的汇编跳板执行流程与栈帧机制
kprobe函数入口汇编跳板执行流程与栈帧机制 文章目录kprobe函数入口汇编跳板执行流程与栈帧机制前言环境准备ftrace跳板创建跳板执行流程与栈帧逐行拆解初始状态与安全校验双层栈帧构建(CONFIG_FRAME_POINTER)通用寄存器保存与C函数参数准备剩余寄存器保…...

实战指南:基于业务数据,用快马平台AI模型快速生成定制化图表代码
今天想和大家分享一个实战经验:如何用InsCode(快马)平台的AI模型,快速生成符合业务需求的数据可视化图表代码。这个需求源于我们团队最近接到的紧急项目——需要在三天内为客户的销售系统集成十几张动态报表。 需求痛点与解决方案选择 传统开发方式需要手…...

【typst-rs】Typst CLI 入口代码解析
这段代码是 Typst CLI 工具的入口点(main.rs),Typst 是一个基于 Rust 的排版系统。让我详细解析这段代码的结构和功能。 模块声明 (1-18行) mod args; mod compile; mod completions; mod deps; mod download; mod eval; mod fonts; mod gree…...