【多线程-从零开始-捌】阻塞队列,消费者生产者模型
什么是阻塞队列
阻塞队里是在普通的队列(先进先出队列)基础上,做出了扩充
- 线程安全
- 标准库中原有的队列 Queue 和其子类,默认都是线程不安全的
- 具有阻塞特性
- 如果队列为空,进行出队列操作,此时就会出现阻塞。一直阻塞到其他线程往队列里添加元素为止
- 如果队列满了,进行入队列操作,此时就会出现阻塞。一直阻塞到其他线程从队列里取走元素为止
基于阻塞队列,最大的应用场景,就是实现“生产者消费者模型”(日常开发中,常见的编程手法)
生产者消费者模型
比如:
小猪佩奇一家准备包饺子,成员有佩奇,猪爸爸和猪妈妈,外加一个桌子
- 佩奇负责擀面皮
- 猪爸爸和猪妈妈负责包饺子
- 桌子用来放你擀好的面皮
每次佩奇擀好一个面皮后,就放在桌子上,猪爸爸和猪妈妈就用这个面皮包出一个饺子
此时:
- 佩奇就是面皮的生产者——生产者
- 猪爸爸和猪妈妈就是面皮的消费者——消费者
- 桌子就是阻塞队列——阻塞队列
为什么是是阻塞队列而不是普通队列?
因为阻塞队列可以很好的协调生产者和消费者
- 若佩奇擀面皮很快,不一会桌子上就满了
- 阻塞队列:佩奇就休息一下,等面皮被消耗一些之后继续再擀
- 普通队列:不会停,放不下了也一直擀
- 若猪爸爸和猪妈妈包的很快,不一会桌子上就空了
- 阻塞队列:猪爸爸和猪妈妈休息一下,等到面皮擀出来之后再包
- 普通队列:不会停,没面皮了也一直包
好处
上述生产者消费者模型在后端开发中,经常会涉及到
当下后端开发,常见的结构——“分布式系统”,不是一台服务器解决所有问题,而是分成了多个服务器,服务器之间相互调用
主要有两方面的好处
1. 服务器之间解耦合
我们希望见到“低耦合”
- 模块之间的关联程度/影响程度
通常谈到的“阻塞队列”是代码中的一个数据结构
但是由于这个东西太好用了,以至于会把这样的数据结构单独封装成一个服务器程序,并且在单独的服务器机器上进行部署
此时,这样的饿阻塞队列有了一个新的名字,“消息队列”(Message Queue,MQ)
如果是直接调用: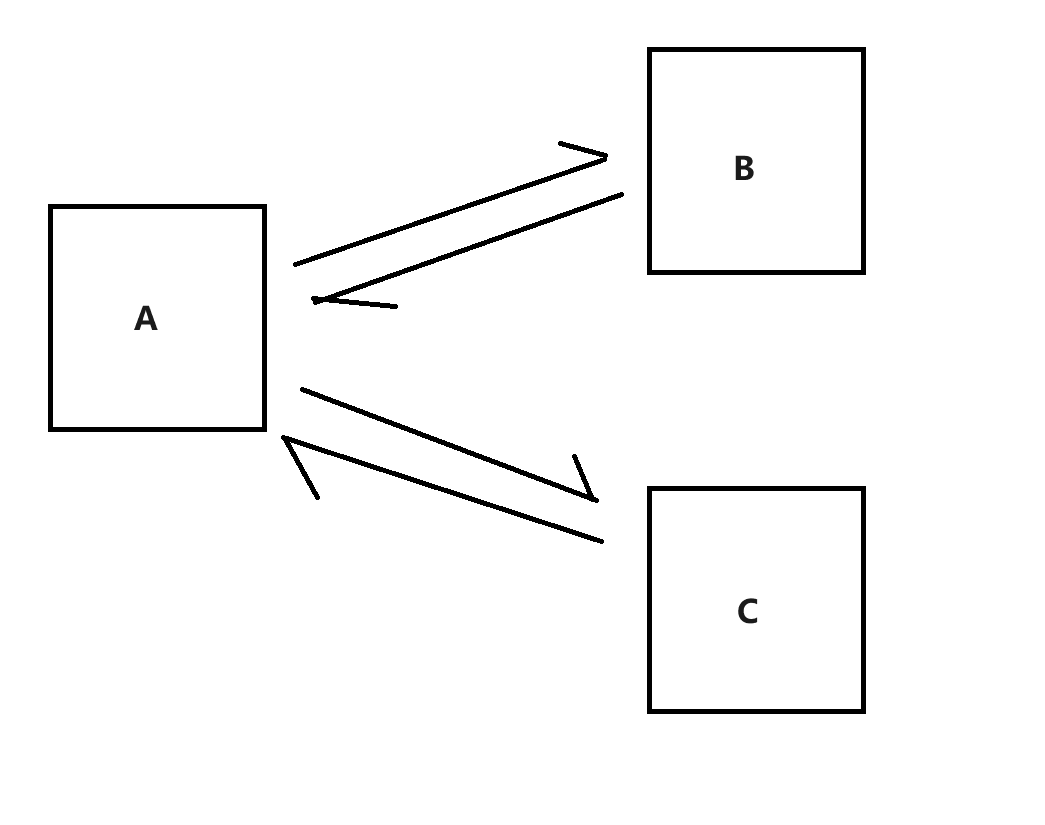
- 编写 A 和 B 代码中,会出现很多对方服务器相关的代码
- 并且,此时如果 B 服务器挂了,A 可能也会直接受到影响
- 再并且,如果后续想加入一个 C 服务器,此时对 A 的改动就很大
如果是通过阻塞队列:
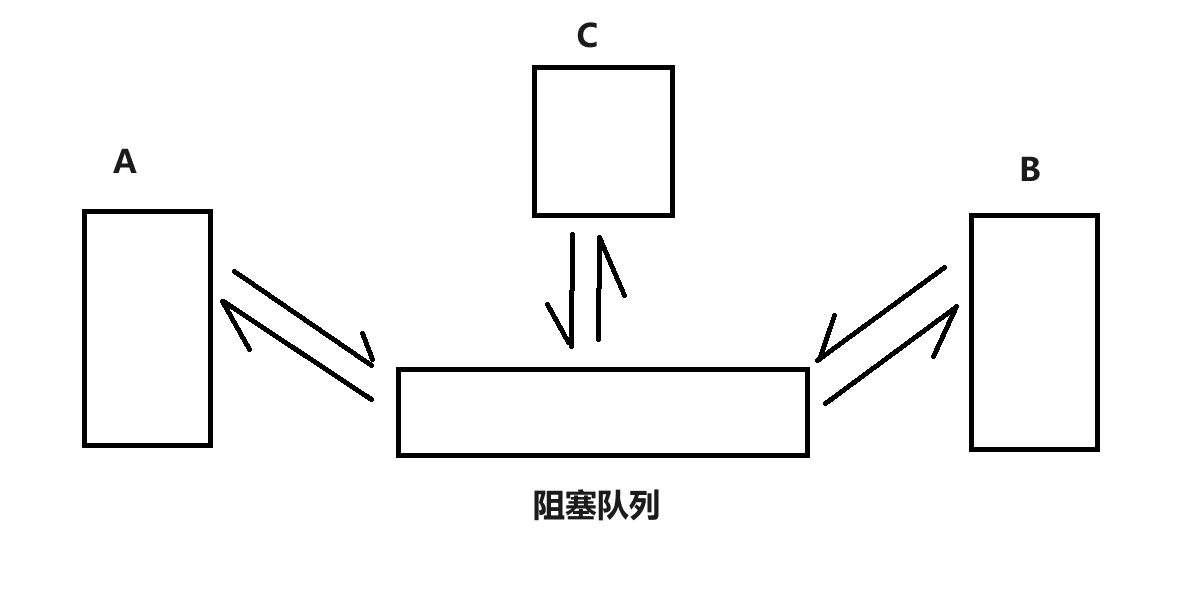
- A 之和队列通信
- B 也只和队列通信
- A 和 B 互相不知道对方的存在,代码中就更没有对方的影子
看起来,A 和 B 之间是解耦合了,但是 A 和队列,B 和队列之间,不是引入了新的耦合吗?- 耦合的代码,在后续的变更工程中,比较复杂,容易产生 bug
- 但消息队列是成熟稳定的产品,代码是稳定的,不会频繁更改。A、B 和队列之间的耦合,对我们的影响微乎其微
- 再增加 C 服务器也很方便,也不会影响到原有的 A 和 B 服务器
2. “削峰填谷”的效果
通过中间的阻塞队列,可以起到削峰填谷的效果,在遇到请求量激增突发的情况下,可以有效保护下游服务器,不会被请求冲垮
阻塞队列的作用就相当与三峡大坝在三峡的防汛作用
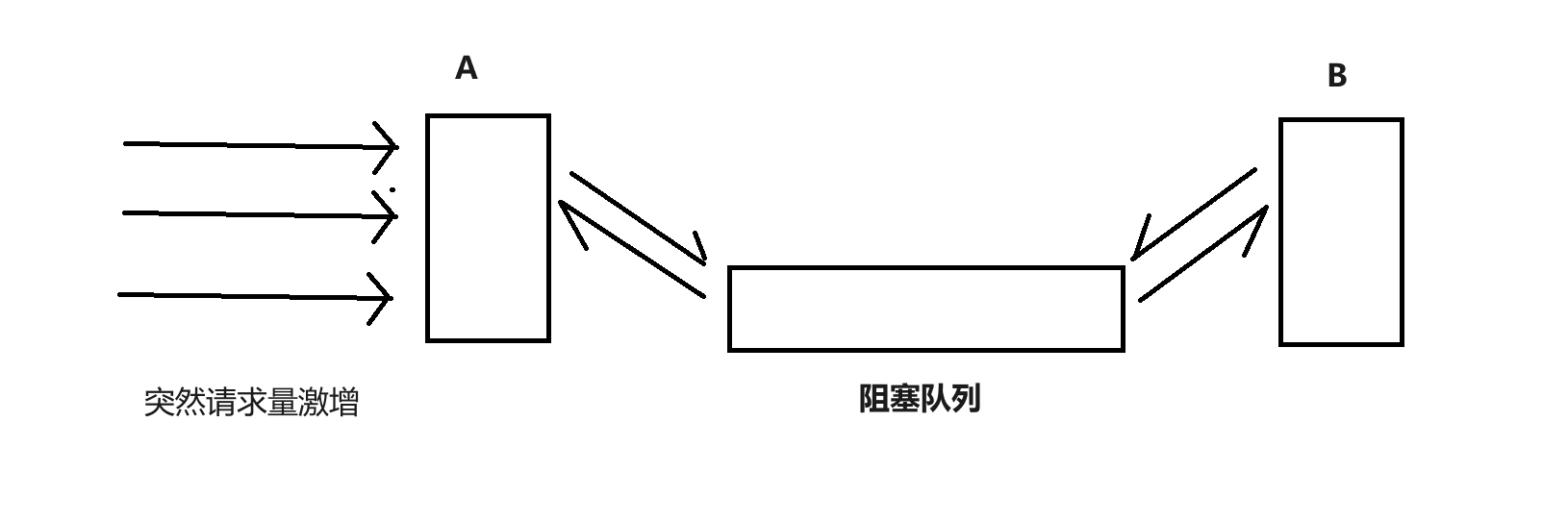
- A 向队列中写入数据变快了,但是 B 仍然可以按照原有的速度来消费数据
- 阻塞队列扛下了这样的压力,就像三峡大坝抗住上游的大量水量的压力
- 如果是直接调用,A 收到多少请求,B 也收到多少,那很可能直接就把 B 给搞挂了
- 当 A 不再写入数据的时候,但队列中还存有数据,可以继续工给 B
问题
- 为啥一个服务器,收到的请求变多,就容易挂?
- 一台服务器,就是一台“电脑”,上面就提供了一些硬件资源(包括但不限于 CPU,内存,硬盘,网络带宽…)
- 就算你这个及其配置再好,硬件资源也是有限的
- 服务器每次收到一个请求,处理这个请求的过程,就都需要执行一系列的代码,在执行这些代码的过程中,就需要消耗一定的硬件资源(CPU,内存,硬盘,网络带宽…)
- 这些请求小号的总的硬件资源的量,超过了及其能提供的上限,那么此时机器就会出现(卡死,程序直接崩溃等…)
- 在请求激增的时候,A 为啥不会挂?队列为啥不会挂?反而是 B 更容易挂呢?
- A 的角色是一个“网关服务器”,收到客户端的请求,再把请求转发给其他的服务器
- 这样的服务器里的代码,做的工作比较简单(单纯的数据转发),消耗的硬件资源通常更少
- 处理一个请求,消耗的资源更少,同样的配置下,就能支持更多的请求处理
- 同理,队列其实也是比较简单的程序,单位请求消耗的硬件资源,也是比较少见的
- B 这个服务器,是真正干活的服务器,要真正完成一系列的业务逻辑
- 这一系列的工作,代码量非常庞大,消耗的时间很多,消耗的系统硬件资源,也是更多的
类似的,像 MySQL 这样的数据库,处理每个请求的时候,做的工作就是比较多的,消耗的硬件资源也是比较多的,因此 MySQL 也是后端系统中,容易挂的部分
对应的,像 Redis 这种内存数据库,处理请求,做的工作远远少于 MySQL,消耗的资源更少,Redis 就比 MySQL 硬朗很多,不容易挂
代价
- 需要更多的机器来部署这样的消息队列(小代价)
- A 和 B 之间的通信延迟会变长
- 对于 A 和 B 之间的调用,要求响应时间比较短就不太适合了
每个技术都有优缺点,不能无脑吹,也不能无脑黑
比如:微服务
- 本质上就是把分布式系统服务拆的更细了,每个服务都很小,只做一项功能
- 非常适合大公司,部门分的很细
- 但需要更多的机器,处理请求需要更多的响应时间,更复杂的后端结构,运维成本水涨船高
Java 自带的阻塞队列
阻塞队列在 Java 标准库中也提供了现成的封装——BlockingQueue
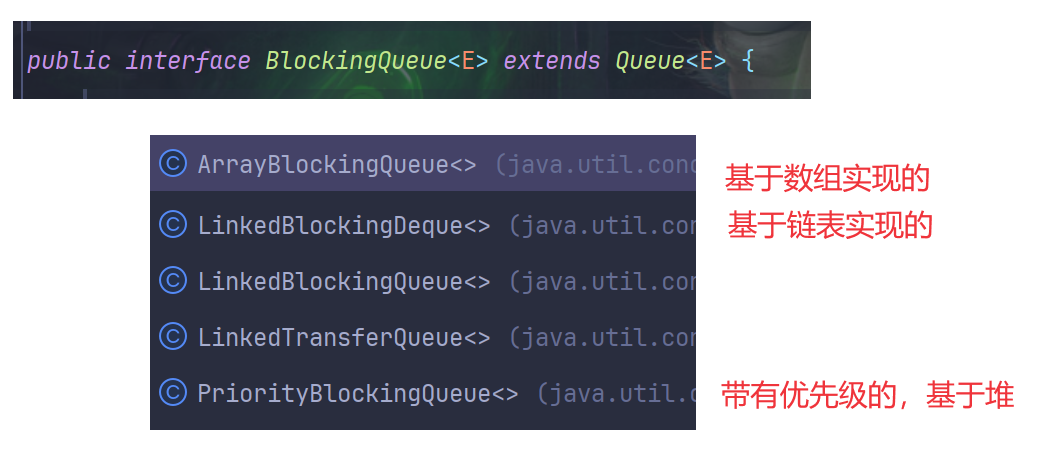
BlockingQueue本质上是一个接口,不能直接new,只能new一个类- 因为是继承与
Queue,所以Queue的一些操作,offer、poll这些,在BlockingQueue中同样可以使用(不过不建议使用,因为都不能阻塞)BlockingQueue提供了另外两个专属方法,都能阻塞
put——入列take——出队列
BlockingQueue<String> queue = new ArrayBlockingQueue<>(1000);
capacity 指的是容量,是一个需要加上的参数
public class Demo10 { public static void main(String[] args) throws InterruptedException { BlockingQueue<String> queue = new ArrayBlockingQueue<>(3); queue.put("111"); System.out.println("put成功"); queue.put("111"); System.out.println("put成功"); }
}
//运行结果
put成功
put成功
put成功
- 只打印了三个,说明第四次 put 的时候容量不够,阻塞了
public class Demo10 { public static void main(String[] args) throws InterruptedException { BlockingQueue<String> queue = new ArrayBlockingQueue<>(3); queue.put("111"); System.out.println("put 成功"); queue.put("111"); System.out.println("put 成功"); queue.take(); System.out.println("take 成功"); queue.take(); System.out.println("take 成功"); queue.take(); System.out.println("take 成功"); }
}
//运行结果
put 成功
put 成功
take 成功
take 成功
- 由于只有
put了两次,所以也只有两次take,随后阻塞住了
public class Demo11 { public static void main(String[] args) { BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(1000); Thread t1 = new Thread(() -> { int i = 1; while(true){ try { queue.put(i); System.out.println("生产者元素"+i); i++; Thread.sleep(1000); } catch (InterruptedException e) { throw new RuntimeException(e); } } }); Thread t2 = new Thread(() -> { while(true) { try { Integer i = queue.take(); System.out.println("消费者元素"+i); } catch (InterruptedException e) { throw new RuntimeException(e); } } }); t1.start(); t2.start(); }
}
- 上述程序中,一个线程生产,一个线程消费
- 实际开发中,通常可能是多个线程生产,多个线程消费
自己实现一个阻塞队列
普通队列
基于数组的队列
实现一个基础的队列
//此处不考虑泛型参数,只是基于 String 进行存储
class MyBlockingQueue { private String[] data = null; private int head = 0; private int tail = 0; private int size = 0; public MyBlockingQueue(int capacity) { data = new String[capacity]; } public void put(String s) { if(size == data.length) { //队列满了 return; } data[tail] = s; tail++; if(tail >= data.length){ tail = 0; } size++; } public String take() { if(size == 0) { //队列为空 return null; } String ret = data[head]; head++; if(head >= data.length){ head = 0; } size--; return ret; }
}
阻塞队列
- 队列为空,
take就要阻塞,在其他线程put的时候唤醒 - 队列未满,
put就要阻塞,在其他线程take的时候唤醒
//此处不考虑泛型参数,只是基于 String 进行存储
class MyBlockingQueue { private String[] data = null; private int head = 0; private int tail = 0; private int size = 0; private Object locker = new Object(); public MyBlockingQueue(int capacity) { data = new String[capacity]; } public void put(String s) throws InterruptedException { //加锁的对象,可以单独定义一个,也可以直接就地使用this synchronized (locker) { if (size == data.length) { //队列满了,需要阻塞 //return; locker.wait(); } data[tail] = s; tail++; if (tail >= data.length) { tail = 0; } size++; //唤醒 take 的阻塞 locker.notify(); } } public String take() throws InterruptedException { String ret = ""; synchronized (locker) { if (size == 0) { //队列为空,需要阻塞 //return null; locker.wait(); } ret = data[head]; head++; if (head >= data.length) { head = 0; } size--; //唤醒 put 的阻塞 locker.notify(); } return ret; }
}
相关文章:
【多线程-从零开始-捌】阻塞队列,消费者生产者模型
什么是阻塞队列 阻塞队里是在普通的队列(先进先出队列)基础上,做出了扩充 线程安全 标准库中原有的队列 Queue 和其子类,默认都是线程不安全的 具有阻塞特性 如果队列为空,进行出队列操作,此时就会出现阻…...

数据结构——栈(Stack)
目录 前言 一、栈的概念 1、栈的基本定义 2、栈的特性 二、栈的基本操作 1.相关操作概念 2.实现方式 (1)顺序栈 (2)链式栈 三、栈的应用 总结 前言 栈(Stack)是一种常见且重要的数据结构,它遵循…...

修改pom.xml为阿里云仓库并且让他生效
一、项目pom.xml添加 <repositories><repository><id>aliyun-central</id><name>Aliyun Maven Central</name><url>https://maven.aliyun.com/repository/central</url></repository><repository><id>aliyu…...

step13:qml/qt程序打包
文章目录 0.文章介绍1.软件发布2.准备打包软件3.双击开始运行打包软件4.点击安装5.参考连接 0.文章介绍 1.软件发布 打包之前需要先发布,参考教程连接 2.准备打包软件 官方下载地址:http://www.jrsoftware.org/isdl.php#stable 下载之后一路点击下一…...
招聘求职小程序
本文来自:ThinkPHPFastAdmin招聘求职小程序 - 源码1688 应用介绍 一款基于ThinkPHPFastAdmin开发的原生微信小程序招聘管理系统。 前端小程序演示: 后台管理网址: https://fastadmin.site100.cn/PbfhegDBAJ.php/index/login 网盘链接&#x…...

10分钟学会docker安装与使用
文章目录 1、docker简介2、docker的基本组成3、docker的安装与配置4、docker的常用命令 1、docker简介 什么是容器? 它是一种虚拟化的方案,是操作系统级别的虚拟化,只能运行相同或相似内核的操作系统,依赖于Linux内核特性&#x…...

vue3、uniapp-vue3模块自动导入
没有使用插件 使用插件,模块自动导入 安装: npm i -D unplugin-auto-importvite.config.js (uniapp没有此文件,在项目根目录下创建) import { defineConfig } from "vite"; import uni from "dcloudio/vite-plugin-uni"; import AutoImport from &qu…...
)
Ubantu设置国内镜像(阿里云、华为云)
1. 确定系统版本 国内有很多 Ubuntu 的镜像源,包括阿里的、网易的,还有很多教育网的源,比如:清华源、中科大源等。 不同的 ubantu 版本对应的镜像源有所不同,所以需要先查看系统的版本号: lsb_release -a…...

Redis远程字典服务器(3)——常用数据结构和单线程模型
目录 一,常用数据结构 1.0 前言 1.1 string 1.2 hash 1.3 list 1.4 set 1.5 zset 1.6 演示 二,关于单线程模型 2.1 关于Redis的单线程 2.2 Redis为什么快 一,常用数据结构 1.0 前言 Redis是采用键值对的方式来存储数据的&#…...

[Qt][按钮类控件]详细讲解
目录 0.按钮状态说明1.Push Button2.Radio Button3.Check Box4.Tool Button 0.按钮状态说明 clicked:⼀次 ⿏标按下⿏标释放 触发pressed:鼠标按下时触发released:鼠标释放时触发toggled:checked属性改变时触发 1.Push Button QP…...

数据结构(5.5_2)——并查集
逻辑结构——数据元素之间的逻辑关系 并查集: 并查集(Union-Find)是一种树型的数据结构,用于处理一些不交集的合并及查询问题。它支持两种操作: 用双亲表示存储并查集 首先将所有根节点数组值设为-1,其…...

Java Web —— 第四天(Maven)
Maven是什么 Maven 的本质是一个项目管理工具,将项目开发和管理过程抽象成一个项目对象模型(POM) POM (ProjectObject Model): 项目对象模型 Maven的作用 项目构建:提供标准的、跨平台的自动化项目构建方式 依赖管理:方便快捷的管理项目依赖的资源 (ar包)&…...

2024年电脑录屏软件推荐:捕捉屏幕,记录生活,分享精彩
在众多电脑录屏软件中,如何挑选出一款适合自己的工具呢?今天,我们就来为大家对比评测四款热门电脑录屏软件:福昕REC、转转大师录屏、爱拍录屏和轻映录屏。通过对它们的功能、性能、操作便捷性等方面进行对比,帮助你找到…...

oracle 增删改查字段
在Oracle数据库中,对表字段的增删改查是数据库操作的基础。以下是关于Oracle中如何增加、删除、修改和查询字段的详细解释: 1. 增加字段(Add) 增加字段的语法为: ALTER TABLE 表名 ADD (字段名 数据类型 [DEFAULT 默…...

给不规则的shapeGeometry贴图
首先看一下贴图效果,我们要做的是将一个长方形的贴图在不规则的多边形中贴图 实现思路 1. 取不规则多边形的box2,这个box2就是整个贴图的UV坐标 2. 计算每个不规则的多边形顶点的在该box2上的对应映射 3. 更新整个geometry的uvs数据 怎么计算映射&…...

网络层IP协议报头字段的认识
认识IP协议 IP协议(Internet Protocol),又称网际协议,是整个TCP/IP协议栈中的核心协议之一,位于网络层。IP协议是互联网中最基础的网络协议之一,负责在网络中传输数据包。它定义了数据包的格式、地址分配和…...

Linux部署MySQL8.0
目录 一、部署前准备1.1、查看系统版本和位数(32位或64位)1.2、下载对应安装包 二、开始部署1、将安装包解压并且移动到目标安装目录2、准备MySQL数据和日志等存储文件夹3、准备MySQL配置文件 my.cnf4、创建mysql单独用户组和用户,将安装目录…...

二叉树中的深搜
🎥 个人主页:Dikz12🔥个人专栏:算法(Java)📕格言:吾愚多不敏,而愿加学欢迎大家👍点赞✍评论⭐收藏 目录 1. 计算布尔二叉树的值 1.1 题目描述 1.2 题解 1.3 代码实现 2. 求根节…...

固态继电器行业知识详解
固态继电器(SSR)是一种通过电子元件来实现开关功能的器件,与传统的电磁继电器相比,它具有更高的可靠性、耐用性和响应速度,广泛应用于工业自动化、家用电器和各种电子控制系统中。本文将详细探讨固态继电器的工作原理、…...

【practise】数组中出现次数超过一半的数字
关于我: 睡觉待开机:个人主页 个人专栏: 《优选算法》《C语言》《CPP》 生活的理想,就是为了理想的生活! 作者留言 PDF版免费提供:倘若有需要,想拿我写的博客进行学习和交流,可以私信我将免费提供PDF版。…...

YOLO26涨点改进| TPAMI 2026 |独家创新首发、Conv改进篇| 引入LPM 局部先验特征增强模块,更加聚焦于目标区域并抑制背景干扰,助力目标检测、图像分割、图像恢复、图像增强有效涨点
一、本文介绍 🔥本文给大家介绍使用 LPM 局部先验特征增强模块 改进YOLO26网络模型,通过构建重要性图对特征提取过程进行引导,使模型能够更加聚焦于目标区域并抑制背景干扰,从而提升特征表达质量和目标区分能力。其优势体现在能够有效增强关键区域信息、提升小目标和复杂…...

OpenClaw安装部署Mac操作系统版 - 打造你的专属AI助理
【第二篇】OpenClaw安装部署Mac操作系统版 - 打造你的专属AI助理摘要:Mac系统是OpenClaw的最佳部署平台之一。本文详细介绍在macOS上安装部署OpenClaw的完整流程,包括环境准备、多种安装方式、权限配置等内容,让Mac用户轻松搭建AI智能体平台。…...

2026跨境电商数据采集避坑指南:实测实在Agent如何终结“数字员工”的幻觉时代
【摘要】 2026年3月,跨境电商行业正式迈入“Agent驱动”的生产力新纪元。随着阿里巴巴Accio Work、腾讯云MAGIC Agent 2.0等工具的密集发布,传统基于脚本的爬虫正被具备自主决策能力的“数字员工”取代。然而,在实际业务落地中,通…...

C++ 模板元编程工程应用
C模板元编程:工程实践中的编译期魔法 在现代C开发中,模板元编程(TMP)通过编译期计算将复杂逻辑转移到代码生成阶段,显著提升了运行时效率与代码可维护性。从类型安全的容器到高性能数学库,TMP已成为工程领…...

如何利用 SEO 工具提取网站的外部链接
如何利用 SEO 工具提取网站的外部链接 在当今竞争激烈的网络环境中,外部链接(即指向你网站的其他网站的链接)已经成为提升网站搜索引擎排名的重要因素。利用 SEO 工具提取网站的外部链接,不仅能帮助你更好地了解你的网站链接情况…...
proteus、原理图、流程图 1185-基于51单片机的电子秤...)
基于51单片机的电子秤(4挡)proteus、原理图、流程图 1185-基于51单片机的电子秤...
基于51单片机的电子秤(4挡)proteus、原理图、流程图 1185-基于51单片机的电子秤(4挡)proteus、原理图、流程图、物料清单、仿真图、源代码 功能介绍: 1、基本部分 (1)称重范围用开关分为三挡&am…...

利用快马平台与openclaw快速构建电商数据抓取原型
最近在做一个电商数据分析的小项目,需要快速验证数据抓取的可行性。传统方式从零搭建爬虫环境太费时间,正好发现了InsCode(快马)平台这个神器,配合openclaw库可以快速完成原型开发。这里记录下我的实践过程,特别适合需要快速验证想…...

建议收藏!我开发了一个免费无限制的AI绘画公益站!
大家好,最近我做了一个小网站,叫 Dreamify ,一个可以让你随便玩AI画画的小工具。不收费、不限次数、不用登录,想画就画,全凭兴趣。 今天就想简单分享一下它,顺便邀请你也来玩玩看。 🎨 为什么…...

Java 基础核心知识
文章目录1. 谈谈对AQS的理解2. fail-safe机制与fail-fast机制分别有什么作用3. new String("abc")到底创建了几个对象4. 对序列化和反序列化的理解5. 谈谈对Java中SPI的理解6. String、StringBuffer、StringBuilder区别7. Integer 的判断8. 深拷贝和浅拷贝9. 强引用、…...

mysql备份工具选择_mysqldump对InnoDB与MyISAM支持
mysqldump默认对MyISAM用表级锁、InnoDB不启用事务快照,混合引擎必须用--lock-all-tables保证一致性,且需确保REPEATABLE READ隔离级别和ROW/MIXED binlog格式。mysqldump 默认行为对 InnoDB 和 MyISAM 完全不同默认不加任何参数时,mysqldump…...