linux文件——深度学习文件fd、文件系统调用
前言:从本片开始正式进入linux文件的学习,本片内容主要是文件的fd。 本篇内容博主将要先带友友回忆C语言中的文件操作接口,然后再过渡到操作系统中的系统调用的学习,最后理解操作系统中的文件操作。
ps:本节内容设计一点linux下的task_struct的知识,友友们最好了解一点进程PCB相关知识后再进行观看
目录
C语言下的各种文件操作接口
fopen
chdir
fwrite
>
strlen是否加一的问题
认识文件系统
open
O_WRONLY
O_CREAT
mode
write
O_TRUNC清空写
O_APPEND追加写
访问文件的本质
文件fd——系统级别
FILE——语言级别
C语言下的各种文件操作接口
fopen
我们先使用man fopen, 查看一下c里面的打开文件操作:

然后我们从图中就可以看到fopen的返回值是一个FILE的类型, 而这个东西以前我们不知道是什么。 但是现在我们可以知道了, 这个东西其实就是一种叫做文件句柄的东西。
我们以前说过, 如果fopen打开一个文件, 这个文件在当前目录下不存在, 又是以写的方式方式打开。 那么这个文件就会自动在当前程序的目录下创建一个文件。
这个规则在man手册中也有提到:
就是如上图的红框框, 如上图就是说将文件清空, 或者创建一个新的文件。

现在我们写下面这个程序:
运行后,就会发现, 创建了一个新的文件。

chdir
现在, 我们回到代码当中, 看我们给fopen传的第一个参数。(如下图)

这个参数是我们打开文件的路径和文件名。 但是如果只有文件名, 那么就默认在当前路径下创建一个文件。 但是问题来了, 当前路径是什么呢?——我们在讲进程的时候, 程序打开, 就会形成进程, 进程有一个当前工作路径, 这个当前工作路径cwd, 就是我们所说的当前路径。 ——如果我更改了当前进程cwd, 就可以把文件新建到其他目录。 而更改工作路径的系统调用就是chdir。
现在我们来试验一下:
我们先在当前路径下创建一个cydir目录, 一会我们就要将newfile.exe的工作路径改到cydir里面去。
这个时候里面还没有什么东西:
修改一下我们的程序, 让这个程序睡眠上100秒, 方便我们观察proc命令, 查看当前进程的工作路径。
输入ls/proc/9238 -l指令
就可以查到当前进程的工作路径cwd:
然后我们修改我们的程序——使用chdir修改工作路径:
然后我们就会发现我们的工作路径确实发生了改变。







fwrite
先使用man手册查看一下fwrite

fwrite有四个参数, 第一个参数是ptr, 代表需要拷贝的数据的起始地址; 第二个参数是要拷贝的大小; 第三个参数是要拷贝的个数;第四个参数是要拷贝到哪里去。
下面是我们的程序以及运行结果:


现在, 我们再写入其他的字符串, 就会发现原本的数据都被清空了, 只剩下新写入的数据:
下面是代码以及运行结果:


这是为什么呢? 我们重新看一下man手册中对w方法的论述, 就如同下图的红框框——对于w方法, 如果没有该文件, 那么就创建一个文件。如果有这个文件, 就让这个文件清空再写入。

>
>和w类似, 重定向到文件中的时候, 我们的文件会先被清空,再写入。

如果什么都没写, 只是 > 文件名, 那么文件会被清空, 里面没有任何数据。

由此, 我们可以发现, 其实>的底层就是"w"方法!!!两者都是打开文件即是空文件!!
strlen是否加一的问题
我们这里思考一个问题, 我们在c语言中, 每一个字符串都有一个\0, 这个\0在strlen的时候不会计算, 并且不会显示。 那么, 我们看下面这个代码:
这个strlen(src)处要不要加1? 我们目前虽然不知道要不要加一, 但是我们可以试验一下, 如果加1会打印什么, 这里我们实验, 下面是运行结果:

我们可以发现, 在换行符后面又多打印了一串乱码。 ——而博主可以告诉友友们, 这个乱码其实就是\0。 strlen + 1就是将最后一个\0也包括进来了, 所以会打印\0。
那么问题来了, 我们平时打印的时候, 要不要加这个1呢? ——答案是不加, 因为我们的字符串后面默认补\0是c语言中的规则, c语言规定字符串的长度默认加1, 但是这是c语言规定, 而不是操作系统规定。 所以, 对于操作系统来说, 我们不加1。
认识文件系统
认识文件系统之前,我们需要理解几个知识点:
- 首先, 文件是不是在磁盘上的?——是的。 那么磁盘是不是硬件设备呢?——是的。 那么访问文件的本质上其实就是访问硬件。 ——无论是什么文件, 比如显示器, 向显示器上面打印数据的本质上就是在访问显示器文件。 又比如键盘, 我们从键盘输入本质上就是在访问键盘文件。 而且, 要知道, 磁盘文件就是硬件, 而文件保存在磁盘里。 我们平时在IO的时候访问文件, 那么是不是就是在访问磁盘?——结论就是, 访问文件, 本质上就是访问硬件。
- 我们知道, 整个计算机结构的最上层是用户, 下面是程序, 再下面是操作系统, 然后是驱动器, 最后是硬件。 如下图:
并且, 对于用户来说, 不存在用户越过中间的程序、操作系统、驱动器而直接去访问硬件。用户做不到, 因为操作系统不相信任何人。 用户要访问硬件必须从上向下贯穿整个操作系统。 又因为操作系统不相信任何人, 所以操作系统和程序又有一层系统调用。——几乎所有的库只要是访问硬件,必定要封装系统调用!!!比如fprintf/printf/fscanf/fread/gets/fgetss………都是库函数!!!都能访问硬件, 所以一定封装系统调用!!!

open
现在我们来看一个系统调用——open, 下面是man手册:
使用man 2 open


这里有两个函数, 两个的区别就是第三个参数:mode_t mode。
这两个参数, 第一个参数是我们要打开的文件名——即路径。 第二个是我们要打开的文件的模式——即权限。
然后第二个open里面的特殊的第三个参数, 这个参数就是指定我们创建一个新文件的时候创建这个文件的默认权限。
那么就是说, 第一个open一般用于我们已经存在这个文件时候的打开。 第二个open一般用于这个文件不存在的时候再打开。
那么第一个参数就是要开的文件的所在路径, 这个路径相对和绝对可以, 但是如果不带路径, 只有文件名那么就以进程的当前工作目录来决定了。
第二个参数叫做flags, 这个flags有几个常见的选项O_RDONLY、O_WRONLY、O_RDWR、O_ERCAT、O_APPEND——这些选项是宏定义。
我们如果学过位图, 我们就知道, 对于一个整形来说, 有32个比特位, 那么就是有32个标志位。 而这种标志位就是flags, flags利用了这种比特位级别的标志方式。
接下来我们做一些实验。
我们想要看ONE处的标志位, 那么我们就可以show(ONE), 想看TWO处的标志位, 那么就show(TWO)。 如果想要看一下ONE以及TWO处的标记位, 我们就show(ONE|TWO)。
然后结果就是如下:


接下来我们测试一下具有两个参数的open函数:
O_WRONLY
我们使用下面的代码测试, 注意, 这个时候我们只以写的方式打开:
我们会发现, 没有文件被创建出来, 就如同下图:


O_CREAT
而我们想要创建出这个文件, 就需要使用O_WRONLY和O_CREAT两种方式组合。
这个时候再运行就能看到新创建出来的文件里。 但是这个时候新创建出来的文件权限是---s-wx---, 这个很显然不是文件被创建出来的时候的默认权限。

mode
想要获得默认权限, 两个参数的open不能解决这个问题。 必须使用三个参数的open。 第三个参数就是规定新创建的文件的默认权限。——第三个参数是默认权限, 我们在传参的时候必须传八进制。


创建出来后, 我们就会发现我们创建出来的是664权限而不是666权限。 这是为什么呢? ——因为我们传的是默认权限, 而真正的权限等于默认权限 & (~umask)博主此时的umask是002, 所以最终权限是664.
而如果想要不考虑umask, 就在对应的进程中运行函数umask(0)。
这个时候, 我们创建的文件权限就是666了!!!


write
write函数是写函数, 下面是man手册:

- 第一个参数是打开文件的时候的返回值。——open的返回值。
- 第二个参数是要拷贝的数据来源的地址。
- 第三个参数是要拷贝的字节数。
如下图, write的实际应用:
运行后, 运行的结果如下图:


但是我们修改写入的内容, 会发现文件的内容没有被清空。 下面是实验过程:
先写入一行bbbbbbbb后又写入了一行aaaa
下面是运行结果:



O_TRUNC清空写
想要能够清空文件, 就要另外加一个选项:O_TRUNC, 这个选项就是先清空文件。
加了选项之后我们再运行程序:

首先打印一行bbbbbbbbbbbbbb

然后再写入一行aaaa, 下面是代码和运行结果:


我们可以发现, 已经清空了文件!!!
O_APPEND追加写
追加写需要用到O_APPEND选项:

现在我们回头看一线fopen、fpeintf这些函数的底层一定是封装了open, write这些函数。 另外, 像python, java这类语言, 他们也一定有类似于fprintf, fopen类似的函数。 这些函数的底层一定会封装open, write, read这些系统调用。
访问文件的本质
文件fd——系统级别
首先, 我们知道, 文件一定是保存在磁盘中, 我们的一个进程启动时, 会加载一个PCB。 而当进程访问一个文件的时候, 首先会打开这个文件。 然后就会内存中加载一个叫做struct_file的结构体。 这个结构体里面描述了一个被打开的文件的信息。

对于每一个进程, 都可能打开多个文件, 这些文件都会有对应的struct file结构体, 也就是上图的连成串的链表的一个节点。 那么进程如何找到这些struct file结构体呢?
其实, 每一个进程里面都有一个struct file_struct* files, 指向一个名叫struct file_struct的结构体, 这个结构体里面保存了一个指针数组。 这个数组的名字叫做struct file* fd_array[]。 这些文件指针数组指向一个个描述文件的结构体。
当我们打开一个文件的时候, 就会生成一个描述文件的结构体。 同时进程会在文件指针数组里面找一个空位置保存刚刚创建的描述文件的结构体的地址。 然后再讲这个数组的下标返回给用户。 这个返回值就是open的返回值!!!最终, 进程就可以根据这一张文件描述符表, 就可以把我们打开的文件找到了。
那么open的返回值具体是如何返回的呢? ——当我们使用open打开一个文件, 操作系统就会创建一个文件描述对象。 然后文件描述符表就会在指针数组中找空位置指向这个文件描述对象。 然后将这个位置的下标返回给用户, 返回值就是一个整型类型的, 我们称为fd。
在上面那张图中, 我们如果划分区域, 可以划分如下:

那么左侧的就是进程管理, 右边的就是文件管理。 而两者的联系点就是struct file_struct。
多个文件创建的时候, 因为进程练习文件的本质就是使用指针数组。——是一个数组, 所以返回值fd是按照从小到大的顺序返回的。 如下图实验:

运行结果3, 4, 5按照顺序创建的fd。

那么我们知道了, 文件的返回值fd时按照文件的打开顺序返回, 那么请问, 文件的返回值, 上图中是从3开始的。 那么0, 1, 2去哪里了呢? 或者说有0号下标吗?
我们需要知道, c程序在启动的时候, 会默认打开三个文件——stdin、stdout、stderr。 这三个文件会默认占用0, 1, 2三个fd。 所以我们在新建文件的时候, 是从3开始的。
//现在我们使用fd == 1, 也就是显示器文件。 在这个文件里打印数据, 就能将数据在终端中打印出来:

//接下来测试fd == 0, 事实stdin——我们要使用read函数读取数据:

由上面两个测试我们可以发现, 当进程打开的时候, 就会默认将0, 1, 2打开!!!
那么我们再思考一下, 请问我们默认打开的三个标准输入输出, 是c语言的特性吗???不是, 是操作系统的特性!操作系统会默认打开进程的三个标准输入输出!!!
那么, 操作系统为什么要默认打开呢?
因为计算机开机的时候, 我们是不是就能看到显示器画面里, 而且键盘也已经被识别了? 所以, 我们计算机开机的时候, 操作系统已经将我们的显示器和键盘打开了。 而且我们在进行编程的时候, 是必须要用显示器和键盘的。 所以, 当我们打开一个进程, 那么只需要将已经打开的显示器, 键盘文件的地址填到自己进程PCB里。——而之所以要这样, 是因为程序员天然就需要用键盘输入, 用显示器看结果。
FILE——语言级别
FILE是什么东西? ——对于FILE* fopen来说, 这个是c库自己封装的一个结构体。 而因为linux访问文件的时候只认文件描述符, 所以我们就可以确定, 这个FILE结构体里面必须封装文件描述符!!!
就比如我们看一下C语言中的stdin, stdout, stderr:

三个默认文件流底层一定封装了:stdin, 对应fd == 0; stdout, 对应fd == 1; stderr, 对应fd == 2;——也就是说, FILE类型里面一定给封装有fd这样的文件描述符字段。
而且, 我们也知道, 我们的C库里面有各种接口, 这里我们用fwrite举例:

fwrite一定要拿到FILE类型的结构体才能执行写入操作。 而fwrite底层的系统调用是write, write写入需要fd。 那么换句话说, FILE里面一定有fd字段。 也就是文件描述符!!!那么我们现在测试一下到底是不是这样的呢? 下面是代码和测试结果:

现在我们关闭1号文件, 看看是否能够关闭:


很显然, 不能打印了, 说明1号文件, 也就是显示器文件被关闭了。
但是这里有一个问题, 就是我们在stderr文件中打印, 我们仍旧可以看到打印结果:


这是为什么呢? ——这是因为虽然1号和二号都是指向显示器文件。 但是显示器文件有引用计数(并不仅仅只有显示器文件有引用计数, struct file结构体里面都有引用计数), 关闭1号文件不会彻底关闭显示器文件!!! 也就是说, 1号和2号是根据文件描述符分开打印的!!! 关闭文件的本质就是让struct file里面的引用计数减减和自己这个进程里面指向这个struct file的下标置为空就可以了。
那么我们重新捋一下这个过程——也就是说一开始1, 2号fd都是指向显示器文件, 此时显示器文件的引用计数是2. 当1关闭, 显示器文件的引用计数减减, 变成1, 1号fd指向空, 但是2号fd不变。 所以2号fd依旧可以向显示器打印。
那么我们就可以确定, 我们C++里面使用的iostream, 虽然可能包含了继承体系或者各种基类, 但是最底层, 一定包含了fd!——因为什么都可以改变, 但是操作系统的系统调用不会变, 变的只是上面语言级别的各种外壳!
----------------------------------------------以上, 就是本节全部内容, 下面是本节笔记:



相关文章:
linux文件——深度学习文件fd、文件系统调用
前言:从本片开始正式进入linux文件的学习,本片内容主要是文件的fd。 本篇内容博主将要先带友友回忆C语言中的文件操作接口,然后再过渡到操作系统中的系统调用的学习,最后理解操作系统中的文件操作。 ps:本节内容设计一…...

003集——C#数据类型 及大小端序转换——C#学习笔记
如需得到一个类型或一个变量在特定平台上的准确尺寸,可以使用 sizeof 方法。表达式 sizeof(type) 产生以字节为单位存储对象或类型的存储尺寸。下面举例获取任何机器上 int 类型的存储尺寸: using System;namespace DataTypeApplication {class Program{…...
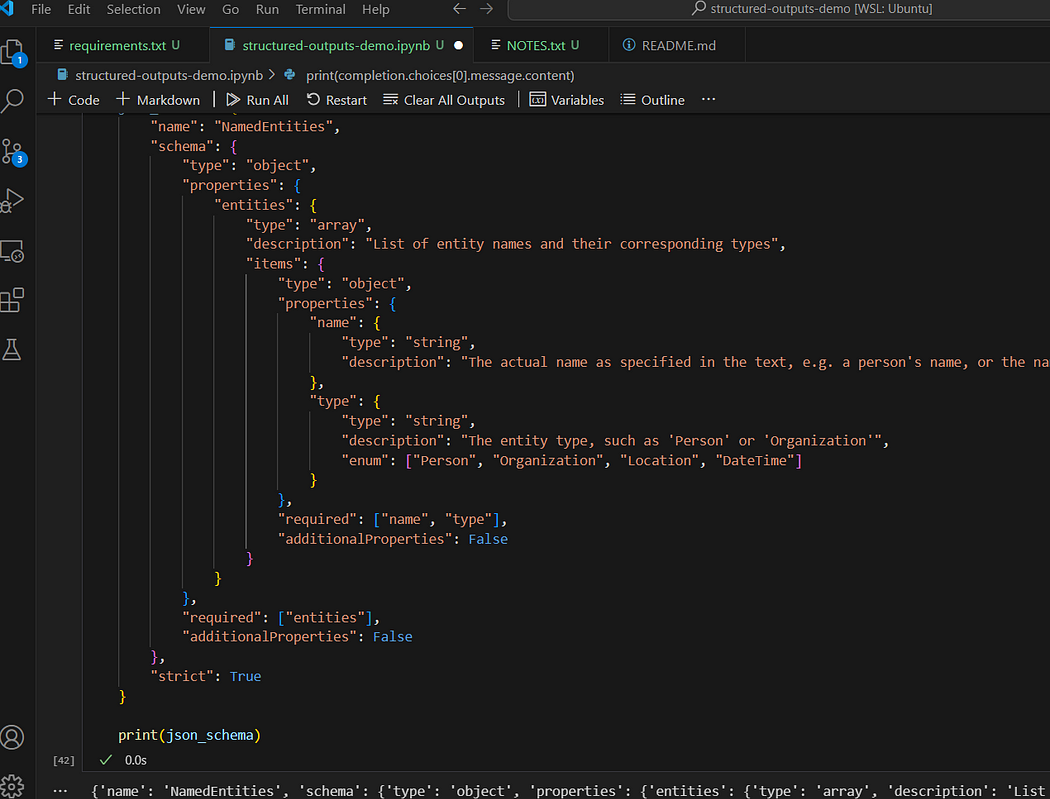
结构化输出及其使用方法
在 LLM 应用程序中构建稳健性和确定性 图片来自作者 欢迎来到雲闪世界。OpenAI最近宣布其最新的gpt-4o-2024–08–06模型支持结构化输出。与大型语言模型 (LLM) 相关的结构化输出并不是什么新鲜事——开发人员要么使用各种快速工程技术,要么使用第三方工具。 在本文…...

yolov8人脸识别案例
GitHub - wangWEI201901/YOLOv8-Detection-Project: 🛣️基于YOLOv8的智慧校园人脸识别和公路汽车检测...

成员变量在Java中的定义与使用
成员变量在Java中的定义与使用 大家好,我是微赚淘客系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿!在本文中,我们将详细探讨Java中的成员变量,包括其定义、使用以及各种类型的成员变量示例。 成员…...
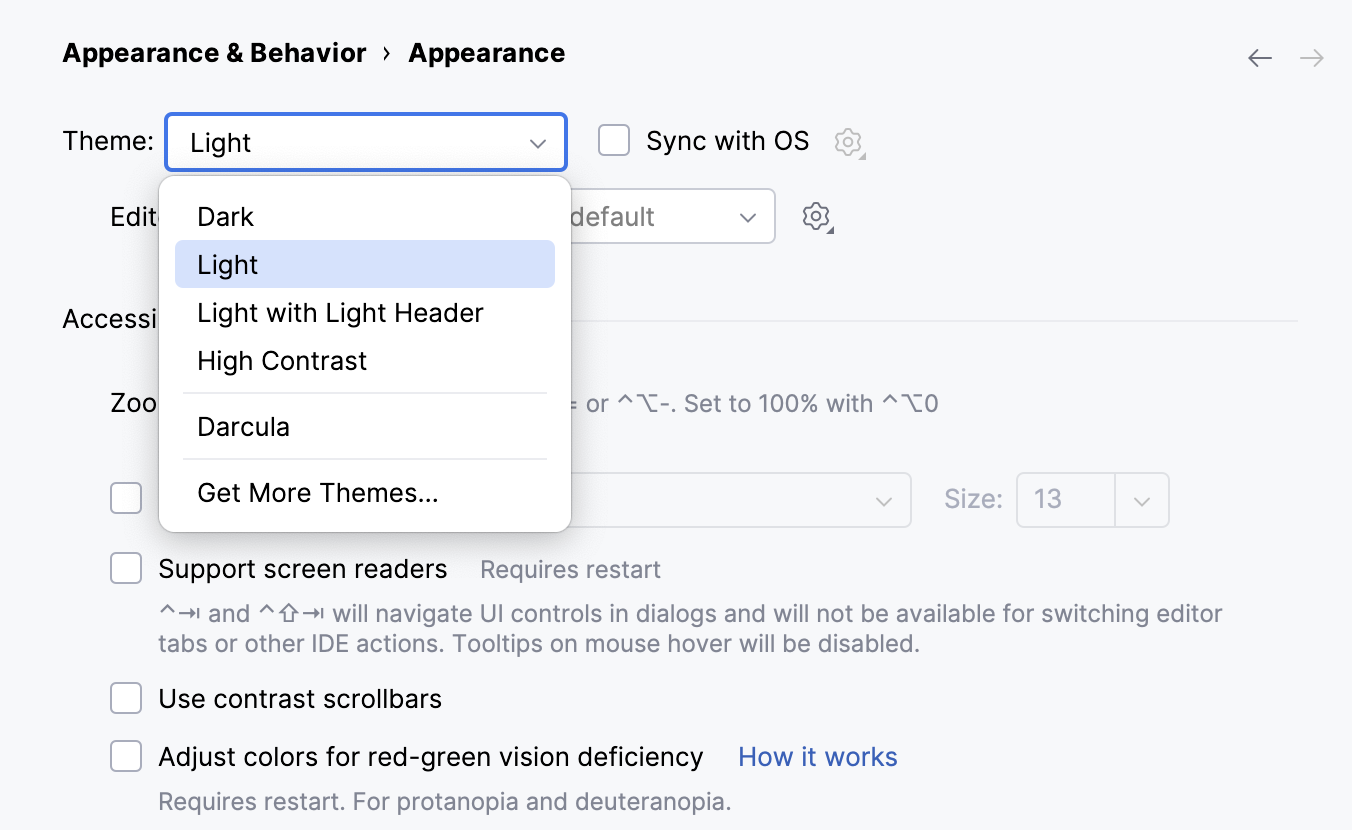
Python开发工具PyCharm入门指南 - 用户界面主题更改
JetBrains PyCharm是一种Python IDE,其带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具。此外,该IDE提供了一些高级功能,以用于Django框架下的专业Web开发。 界面主题定义了窗口、对话框、按钮和用户界面的所有可视元素的外观…...

TCP网络套接字
一、创建套接字 #include <sys/types.h> #include <sys/socket.h> int socket(int domain, int type, int protocol); 参数: domain:指定使用的协议族。常见的取值有AF_INET(IPv4)和AF_INET6(IPv6&a…...

Element学习(axios异步加载数据、案例操作)(5)
1、这次学习的是上次还未完成好的恶element案例,对列表数据的异步加载,并渲染展示。 ——>axios来发送异步请求 (1) (2)在vue当中安装axios (注意在当前的项目目录,并且安装完之后…...

大数据-65 Kafka 高级特性 分区 Broker自动再平衡 ISR 副本 宕机恢复再重平衡 实测
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

html+css+js网页设计 软通动力网站2个页面(带js)首页轮播图+置顶导航
htmlcssjs网页设计 软通动力网站2个页面(带js)首页轮播图置顶导航 网页作品代码简单,可使用任意HTML编辑软件(如:Dreamweaver、HBuilder、Vscode 、Sublime 、Webstorm、Text 、Notepad 等任意html编辑软件进行运行及…...
【经验分享】ShardingSphere+Springboot-04:自定义分片算法(COMPLEX/STANDARD)
文章目录 3.4 CLASS_BASED 自定义类分片算法3.4.1 复杂分片自定义算法(strategyCOMPLEX )3.4.2 STANDARD 标准分片自定义算法## 进阶:star: 自定义算法范围查询优化 3.4 CLASS_BASED 自定义类分片算法 3.4.1 复杂分片自定义算法(strategyCOM…...

如何设置RabbitMQ和Redis消息队列系统
设置RabbitMQ和Redis作为消息队列系统时,需要分别进行安装、配置和测试,以确保它们能够正常工作并满足你的应用需求。以下是一个基于这两个系统的设置指南: RabbitMQ的设置 1. 安装Erlang 由于RabbitMQ是用Erlang语言编写的,因…...

白骑士的Matlab教学高级篇 3.3 工具箱与扩展
MATLAB 提供了丰富的工具箱(Toolbox)和扩展功能,这些工具箱涵盖了各个领域的专业计算需求,如信号处理、图像处理、统计与机器学习等。利用工具箱,用户可以快速实现复杂的计算和分析任务。本文将介绍常用的工具箱及其使…...

bug: 配置flyway.locations多个脚本位置不生效
文章目录 业务场景场景一场景二 业务场景 随着项目版本迭代,数据库结构也会变动。如果一个项目引用其他项目的jar包,并且需要执行对应jar包的flyway脚本,就需要配置flyway.locations 场景一 正常情况下,在一个项目中可以在yml文件…...

8月5日SpringBoot学习笔记
今日内容:搭建mybatis ORM 配置数据源 $#的区别 增删改查 搭建mybatis 在原有maven项目基础配置上进行: pom文件添加依赖 <!-- Mybatis --><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-…...

Java学习笔记(二十):反射、动态代理、日志、类加载器、xml、单元测试Junit、注解
目录 一、反射 1.1 反射的概述: 1.2 学习反射到底学什么? 1.3 获取字节码文件对象的三种方式 1.4 字节码文件和字节码文件对象 1.5 获取构造方法 1.6 获取构造方法并创建对象 1.7 获取成员变量 1.8 获取成员变量并获取值和修改值 1.9 获取成员…...

如何快速从文本中找到需要的信息,字典和正则灵活运用
import re #打开文本文件 f open("stock_data.txt",encoding"utf-8") #单独读取第一行数据处理进行分割,末尾换行符去掉 headers f.readline().strip().split(,) print(headers) #定义一个字典,以股标代码做为KEY,每个行做为值 st…...

springboot3整合redis
来源于https://www.bilibili.com/video/BV1UC41187PR/?spm_id_from333.1007.top_right_bar_window_history.content.click&vd_source865f32e12aef524afb83863069b036aa 一、整合redis 1.创建项目文件 2.添加依赖 <dependencies><dependency><groupId>…...

VUE基础快速入门
VUE 和 VUE-Cli VUE 是一种流行的渐进式JavaScript框架,用于构建Web用户界面它具有易学、轻量级、灵活性强、高效率等特点,并且可以与其他库和项目集成是目前最流行的前端框架之一VUE-Cli 称为“VUE脚手架”,它是由VUE官方提供的客户端,专门为…...

用Python实现特征工程之特征提取——数值特征提取、类别特征提取、文本特征提取、时间特征提取
特征提取是特征工程中的关键步骤,它从原始数据中提取有意义的特征,以便机器学习模型能够更好地理解和学习数据。根据数据类型,特征提取可以分为数值特征提取、类别特征提取、文本特征提取和时间特征提取。下面详细讲解每种特征提取方法&#…...

收藏!新手程序员必看:大模型入门指南,告别“没基础”焦虑
准备入门大模型?请立刻丢掉“我没基础”“这技术太难”的顾虑!作为常年深耕技术领域的博主,我始终坚信:只要你有主动学习的意愿,再加上持续的付出,不仅能轻松攻克大模型入门难关,更能熟练运用它…...

终极指南:如何无需Steam客户端轻松下载创意工坊模组
终极指南:如何无需Steam客户端轻松下载创意工坊模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 你是否曾因Steam客户端无法访问创意工坊而烦恼?或者…...

如何通过抖音批量下载工具实现高效内容管理与分析
如何通过抖音批量下载工具实现高效内容管理与分析 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批量下载…...

ChatGLM3-6B Streamlit应用案例:代码辅助、长文档摘要、闲聊三合一
ChatGLM3-6B Streamlit应用案例:代码辅助、长文档摘要、闲聊三合一 1. 项目简介:你的本地全能AI助手 想象一下,你正在写一段复杂的代码,卡在某个逻辑上;或者面对一份几十页的技术文档,需要快速提炼核心&a…...

ViGEmBus完全指南:解决游戏控制器兼容性问题的4个关键步骤
ViGEmBus完全指南:解决游戏控制器兼容性问题的4个关键步骤 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 在游戏世界中,硬件兼容性问…...

qmcdump:QQ音乐加密文件解码的跨平台解决方案指南
qmcdump:QQ音乐加密文件解码的跨平台解决方案指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 问题引入&…...

GLM-4.1V-9B-Base实际作品集:10张典型图片的多角度中文理解结果
GLM-4.1V-9B-Base实际作品集:10张典型图片的多角度中文理解结果 1. 模型能力概览 GLM-4.1V-9B-Base是智谱开源的视觉多模态理解模型,专为中文视觉理解任务设计。这个模型最令人印象深刻的地方在于,它能像人类一样"看"图片并回答各…...

OpenClaw+Phi-3-vision智能相册:私人照片自动分类与摘要
OpenClawPhi-3-vision智能相册:私人照片自动分类与摘要 1. 为什么需要本地化的智能相册管理 去年夏天,我带着家人去海边度假,用手机拍了近千张照片。回来后面对杂乱的相册,花了整整两个周末才完成分类整理——这种痛苦经历让我开…...

Ivanti EPMM RCE CVE-2026-1340/1281完整分析
介绍:近日,Ivanti公司披露了Ivanti Endpoint Manager Mobile (EPMM)中存在的代码注入漏洞(CVE-2026-1281和CVE-2026-1340),并确认已存在在野利用。该漏洞源于 Apache HTTPd 调用的 Bash 脚本在处理时间戳比较时,未能有效过滤恶意参数…...

OpenClaw技能组合:用Qwen2.5-VL-7B+OCR实现全自动发票报销
OpenClaw技能组合:用Qwen2.5-VL-7BOCR实现全自动发票报销 1. 为什么需要自动化发票报销 每次月底整理发票都让我头疼——需要手动截图、识别金额、填写报销单、发送邮件。直到我发现OpenClaw可以通过组合多个技能模块,实现从截图识别到财务审核的全流程…...