【生成式人工智能-四-chatgpt的训练过程-pretrain预训练自督导式学习督导式学习】
大模型是怎么被训练出来的具有人类智慧的
- 阶段一训练-自我学习-具备知识
- 训练资料
- self-supervised learning(自督导式学习)
- 阶段二-怎么让模型具备人的智慧
- supervised learning 督导式学习
- 预训练pretrain
- 为什么要用预训练的模型?
- Adapter
- 逆向工程
- 开源的Pre-train参数
- 参考
一个语言模型是怎么训练出来的呢?它是怎么具备人类智慧的呢? 它被训练的过程中到底有些什么困难?
阶段一训练-自我学习-具备知识
我们之前就已经讲过,实际上我们要做的就是寻找一个函数,来实现一个文字接龙的功能:
它的做法,它会寻找要给函数:
- 输入:中国最高的山是,输出:珠
- 输入:中国最高的山是珠,输出:穆
- …
- 输入:中国最高的山是朗玛峰,输出:结束符
现在我们知道要实现这个功能我们使用的是一个类神经网络,这个网络有上亿个参数,来实现这样的功能。这上亿个参数是怎么得到的呢,就是通过大量的资料学习到的,就像是人的大脑一样,很难解释每个神经元是怎么作用的,但他们确实可以和谐办公。接下来的要给问题就是到底需要多少的资料才能学会人类的语言呢,又是怎么获取这些资料的呢?
训练资料
要让一个语言模型学会对话,必须具备文法知识以及世界知识,学会文法知识才会知道,“这是一个”这样的表达后面跟的是个名词,而仅仅只有文法知识,还是不够的,所以还需要知道一些世界知识,比如体重的衡量是用公斤数,温度使用摄氏度,不同压力下水的沸点不一样等等。

这篇论文里面可以看得出来,知道文法知识1亿个参数足够了,但是了解世界知识至少需要300亿个以上,那这么多的资料是怎么喂给大模型的呢
self-supervised learning(自督导式学习)
实际上资料的获取并不复杂,因为网络上的资料足够了,但是怎么喂给大模型呢。通常情况下,我们需要的资料是这样的:
输入:今天天气很好 输出:情感正面
也就是说这些数据是带有标签的,但是现在这么多数据我们是无法进行人工标注的。所以今天我们用的技术就是self-supervised learning(自督导式学习)。我们使用网络上爬到的资料,不需要人工标注,处理成如下格式:
比如我们搜到的是中国最高的山是珠穆朗玛峰,我们可以简单的写一个函数,把这个句子处理成:
- 输入:中国最高的山是,输出:珠
- 输入:中国最高的山是珠,输出:穆
- …
- 输入:中国最高的山是朗玛峰,输出:结束符
这种不需要人工标注的方式,我们就称为自督导式学习。
阶段二-怎么让模型具备人的智慧
学习了那么多资料,真的就可以有很好的答案了么?
答案是否定的。在GPT-3学习了580G的资料,参数有1750亿,但是答案依然是很难尽如人意,你问它一个问题,它甚至有可能会反问你一个问题,完全没有人类的智慧,跟现在的GPT-4是完全没法比。
其实我们想想也可以知道,从网络上爬来的资料,本身就没有告诉模型,怎么样的回答才是符合人类回复的。
supervised learning 督导式学习
为了让模型具备人类回答的智慧,必须要收集人类对话,进行资料标注,来教会模型该怎么回答。
这种人类标注的训练方法,我们就叫做督导式学习,这个过程就叫做Instructing Fine-tuning
比如从人类收集到的资料:

对于模型来说的输入输出就是:

那你可以说,我们完全使用人力标注的资料那不是更好么?答案确实是,但是人力能够标注的资料有限的,有限的资料训练出来的参数结果可能就会很奇怪。比如你问模型,中国最高的山是什么? 它很有可能告诉你是:姚明。为什么会出现这样奇怪的答案呢?很有可能是因为资料太少,它只看过这样一个资料。篮球队里最高的人是姚明。
预训练pretrain
那我们有没有更好的方式既能有大量的知识,又能够接受人类的智慧呢?
那就是pretrain,我们使用第一阶段自督导式学习得到的参数,在这个基础上再使用人类标注的数据进行督导式学习,对参数进行微调。
为什么要用预训练的模型?
因为经过预训练的模型具备很强的能力,它甚至能够达到举一反三的效果:

BERT模型上,如果它看过104种语言的资料,如果我们只用英文做Fine-tune,模型竟然可以做中文的QA,正确率可以达到78.7!!
但还是有一个问题,参数这么多微调一次也很费时间,另外微调过程种参数不会被修改太多,导致失去这些已经学会的知识了呢?Adapter技术就是来解决这个问题的。
Adapter
Adapter,就是字面的意思,我在原模型的基础上,我还要再加上一个适配器,适配器的参数比原来的参数要少很多,微调的过程就会变的很快,且不会影响原来的参数。整个模型的输出就是在原来模型参数的基础上,又加上了少量Adapter的参数

LoRA就是一种Adapter技术,Adapter其实包括了很多种可以在https://arxiv.org/abs/2210.06175上找到很多种实现
LLAMA在它的论文中,曾指出自己只需要2万多笔资料,就可以训练好一个模型了,但是还有一个问题,有了它就能训练好一个大模型了么?
答案是不能。因为我们依然还是需要优质的微调资料。
逆向工程
显然不是随便标注就可以得到这些微调需要的优质资料,因为我们不知道用户会怎么问问题,那么怎么获取这部分数据呢?现在有种方法就叫做逆向工程,反问GPT,让他帮忙想问题,想答案,用反向生成出来的内容来微调模型。当GPT是不太喜欢这样的。
有了微调的资料,那参数也是很大的训练成本呀,别着急,有开源的参数
开源的Pre-train参数
Meta 23年开源了LLaMA的参数,我们可以用它来初始化自己的模型。由这个开源的参数,迅速衍生出了一系列的模型,可以说事半功倍
参考
李宏毅-生成式人工智能导论
相关文章:
【生成式人工智能-四-chatgpt的训练过程-pretrain预训练自督导式学习督导式学习】
大模型是怎么被训练出来的具有人类智慧的 阶段一训练-自我学习-具备知识训练资料self-supervised learning(自督导式学习) 阶段二-怎么让模型具备人的智慧supervised learning 督导式学习预训练pretrain为什么要用预训练的模型?Adapter逆向工…...

期权价格的奥秘:深入理解影响因素
在金融市场中,期权作为一种衍生工具,为投资者提供了风险管理和资产增值的多种可能性。期权价格的波动往往令人着迷,但其背后的定价机制却充满了复杂性。本文将带您探索期权价格变化的奥秘,并尝试以浅显易懂的方式,解析…...

STM32-USART时序与寄存器状态分析
一、时序分析 在UART(通用异步收发传输)通信中,信号线上的状态分为两种:逻辑1(高电平)和逻辑0(低电平)。在空闲状态下,数据线应保持逻辑高电平。UART协议中的各个信号位具…...

从零安装pytorch并在pycharm中使用
背景介绍 目前主流使用的工具有Facebook搞的pythorch和谷歌开发的tensorflow两种,二者在实现理念上有一定区别,pytorch和人的思维模式与变成习惯更像,而tensorflow则是先构建整体结构,然后整体运行,开发调试过程较为繁…...

开源AI工具FastGPT和RagFlow对比
FastGPT和RagFlow都是基于大型语言模型(LLM)的先进AI系统,它们在多个方面有着各自的特点和优势。 以下是对两者性能的详细对比: 一、系统架构与功能 FastGPT: 数据收集:通过从互联网上收集大量的文本数…...

第N2周:NLP中的数据集构建
对于初学者,NLP中最烦人的问题之一就数据集的构建问题,处理不好就会引起shape问题(各种由于shape错乱导致的问题)。这里给出一个模版,大家可根据这个模版来构建。 torch.utils.data是PyTorch中用于数据加载和预处理的…...

AI助力浮雕创作!万物皆可浮雕?Stable Diffusion AI绘画【浮雕艺术】之文生浮雕!
前言 对于浮雕艺术,其实并不了解。但有幸能和“细辛”前辈结识,对浮雕有了简单的了解,浮雕图案的传统方式是先由画师画出图,然后由雕刻师雕刻。画师画图归为浮雕的设计阶段,画师会绘制出浮雕的设计图,这为…...

你觉得大模型时代该出现什么?
大模型的概念都火了两年了,之前各种媒体吹嘘大模型的出现是类似“蒸汽机时代”、“iPhone时刻”等等。那为什么我们期待的结果都没出现呢?咱们先一起回顾下历史。 1、蒸汽机时代 1.1、蒸汽机历史 许多人都在讨论大模型时代好像只是概念在火࿰…...

JS【详解】事件委托
事件委托的简介 事件委托(Event Delegation)是 JS 处理事件的一种技术:不直接在目标元素上设置事件监听器,而是在其父元素或祖先元素上设置监听器,然后利用事件冒泡机制来捕获和处理事件。 事件委托的好处 减少内存占用…...

谈对象系列:C++类和对象
文章目录 一、类的定义1.1类定义的格式类的两种定义方法结构体: 1.2访问限定符1.3类域 二、实例化2.1变量的声明和定义2.2类的大小计算空类的大小(面试): 三、this指针小考题 一、类的定义 1.1类定义的格式 使用class关键字&…...

设计模式20-备忘录模式
设计模式20-备忘录 动机定义与结构定义结构 C代码推导优缺点应用场景总结备忘录模式和序列化备忘录模式1. **动机**2. **实现方式**3. **应用场景**4. **优点**5. **缺点** 序列化1. **动机**2. **实现方式**3. **应用场景**4. **优点**5. **缺点** 对比总结 动机 在软件构建过…...

绘制echarts-liquidfill水球图
文章目录 一、效果图二、步骤1.安装插件2.引入2.主要代码2.素材图片 总结 一、效果图 二、步骤 1.安装插件 npm install echarts npm install echarts-liquidfillecharts5的版本与echarts-liquidfill3兼容,echarts4的版本与echarts-liquidfill2兼容,安装的时候需要…...

应急响应:D盾的简单使用.
什么是应急响应. 一个组织为了 应对 各种网络安全 意外事件 的发生 所做的准备 以及在 事件发生后 所采取的措施 。说白了就是别人攻击你了,你怎么把这个攻击还原,看看别人是怎么攻击的,然后你如何去处理,这就是应急响应。 D盾功…...

c语言第14天笔记
通过指针引用数组 数组元素的指针 数组指针:数组中的第一个元素的地址,也就是数组的首地址。 指针数组:用来存放数组元素地址的数组,称之为指针数组。 注意:虽然我们定义了一个指针变量接收了数组地址,但…...

服装行业QMS中的来料检验:常见问题解析与解决策略
在服装行业的来料检验过程中,常会遇到一系列问题,这些问题可能影响到原材料的质量,进而影响最终产品的品质。以下将详细介绍来料检验的常见问题及相应的解决方法: 一、常见问题 外观瑕疵 问题描述:原材料表面存在污渍…...

健身动作AI识别,仰卧起坐计数(含UI界面)
用Python和Mediapipe打造,让你的运动效果一目了然! 【技术揭秘】 利用Mediapipe的人体姿态估计,实时捕捉关键点,精确识别动作。 每一帧的关键点坐标和角度都被详细记录,为动作分析提供数据支持。 支持自定义动作训练&a…...
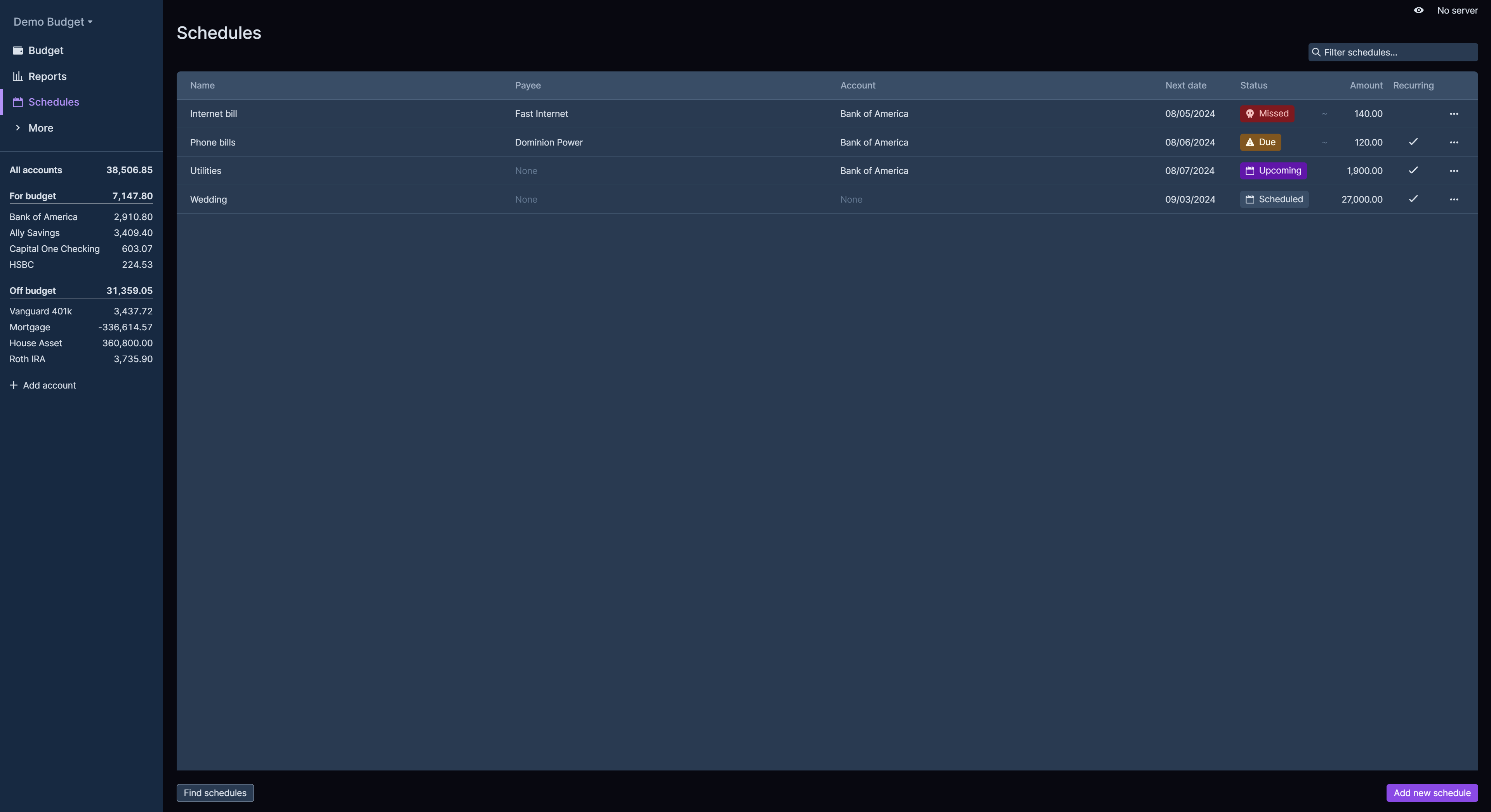
GitHub开源金融系统:Actual
Actual:电子金融,本地优先,自由开源- 精选真开源,释放新价值。 概览 Actual的创新之处在于其对个人财务管理的全面考虑,它不仅仅是一个简单的记账工具,而是一个综合性的理财解决方案。它的本地优先设计意味…...

【学习笔记】Day 7
一、进度概述 1、DL-FWI基础入门培训笔记 2、inversionnet_train 试运行——未成功 二、详情 1、InversionNet: 深度学习实现的反演 InversionNet构建了一个具有编码器-解码器结构的卷积神经网络,以模拟地震数据与地下速度结构的对应关系。 (一…...

网络中特殊的 IP 地址
特殊网络 IP 127.0.0.1 127.0.0.1 是本机回送地址,发送到 127.0.0.1 的数据或者从 127.0.0.1 返回的数据只会在本机进行传输, 而不进行外部网络传输。 主要有以下两个作用: 测试本机网络 当我们可以 ping 通 127.0.0.1 的时候, 则说明本机的网卡以及 tc…...

ASP 表单处理入门指南
ASP 表单处理入门指南 简介 ASP(Active Server Pages)是一种由微软开发的服务器端脚本环境,用于动态生成交互性网页。它允许开发者结合HTML、VBScript或JScript脚本语言来创建和运行动态网页或Web应用程序。本文将重点介绍如何使用ASP来处理表单数据,包括表单的创建、数据…...

从零实现Clock页面置换算法:原理、代码与性能调优实战
1. 为什么需要页面置换算法? 想象你正在玩一个大型开放世界游戏,电脑内存就像你的背包空间。当背包装满时,每次捡新道具都需要先扔掉旧道具——这就是操作系统面临的内存管理问题。Clock算法就是那个帮你智能决定"扔哪件道具"的管家…...

为什么28S与18S rRNA比值可用于评估RNA质量?
在分子生物学实验中,获得高质量RNA样本是基因表达分析、转录组测序等研究成功的关键前提。在众多RNA质量评估方法中,28S与18S核糖体RNA的比值长期被广泛用作实验室中的“黄金标准”。这一标准为何如此受重视?其背后有着明确的原理与判断依据。…...

手把手搓FPGA版W5500三合一驱动
FPGA W5500 3合一 驱动 UDP、TCP客户端、TCP服务端三合一,8个SOCKET都可用源代码,SPI时钟80m,无时序问题,上手即用 硬件实测,高速、稳定 verilog编写,纯逻辑实现 这块W5500芯片的驱动在项目里被我折腾了半个月…...

聊着天把虾队管了:用 HiClaw 正确打开多智能体协作方式【限时领 PPT】
作者:戴靖泽(静择) 本文整理自 DataWhale x HiClaw 直播分享,聊聊多 Agent 协作背后的工程思考。 点击此处,查看分享! 你有没有试过让一个 AI 同时写前端和后端?聊到后面它把自己定好的 API …...

YOLO26涨点改进| ICCV 2025 | 独家创新首发、注意力改进篇| 引入CBSM通道增强与智能空间映射模块,含多种创新改进,助力图像融合、红外小目标检测、图像分割、图像分类高效涨点
一、本文介绍 🔥本文给大家介绍使用 CBSM通道增强与智能空间映射模块 改进YOLO26网络模型,作用在于对输入特征进行通道增强与空间映射,使浅层图像信息能够更好地适配深层语义特征,从而提升特征表达质量并减少特征不匹配问题。其优势体现在能够有效抑制背景噪声、强化关键…...

UI-Grid 终极贡献指南:如何从零开始参与开源项目并提交完美代码
UI-Grid 终极贡献指南:如何从零开始参与开源项目并提交完美代码 【免费下载链接】ui-grid UI Grid: an Angular Data Grid 项目地址: https://gitcode.com/gh_mirrors/ui/ui-grid UI-Grid 作为一款基于 Angular 的数据表格组件,为开发者提供了强大…...
:多级放大电路与差动放大电路实战解析)
攻克模电难点(一):多级放大电路与差动放大电路实战解析
1. 多级放大电路的设计基础 第一次接触多级放大电路时,我被各种耦合方式绕得头晕。直到在实验室烧坏几个三极管后,才真正理解其中的门道。多级放大电路的核心思想很简单:把多个单级放大电路像搭积木一样连接起来,但实际设计时却要…...

Linux日志高效搜索:从基础grep到journalctl实战技巧
1. Linux日志搜索:运维工程师的必备技能 每次服务器出现异常,第一反应是什么?没错,就是查日志。作为在Linux系统摸爬滚打多年的老运维,我见过太多新手面对海量日志时的手足无措。其实日志排查就像破案,关键…...

基于DRAMsim3的扩散模型训练加速仿真:内存时延与能耗分析
基于DRAMsim3的扩散模型训练加速仿真:内存时延与能耗分析 摘要 扩散模型在生成式AI领域取得了巨大成功,但其训练过程极其昂贵,主要体现在对内存带宽的巨大需求(尤其是Attention机制和梯度存储)。本文聚焦于利用DRAMsim3模拟器,在系统架构层面仿真扩散模型(如DDPM)训练…...
)
ArcGIS Pro用户必看:解决CAD转SHP后坐标系丢失的完整配置流程(附Python脚本)
ArcGIS Pro用户必看:解决CAD转SHP后坐标系丢失的完整配置流程(附Python脚本) 当你从CAD图纸转换到SHP格式时,最令人头疼的问题莫过于坐标系信息的丢失。想象一下,你精心准备的规划图纸在GIS软件中变成了一堆无法定位的…...