数据结构----二叉树
小编会一直更新数据结构相关方面的知识,使用的语言是Java,但是其中的逻辑和思路并不影响,如果感兴趣可以关注合集。
希望大家看完之后可以自己去手敲实现一遍,同时在最后我也列出一些基本和经典的题目,可以尝试做一下。大家也可以自己去力扣或者洛谷牛客这些网站自己去练习,数据结构光看不敲是学不好的,加油,祝你早日学会数据结构这门课程。
有梦别怕苦,想赢别喊累。
目录
二叉树
二叉搜索树
相关题目
二叉树
树形结构就是由一个节点在最顶端,我们叫它根节点,它有很多分支指向下面的节点,同样下面的节点也会有分支指向它们下面的节点,我们只需要搞懂树形结构中的二叉树这一类就可以了。
概述
在计算机科学中,二叉树就是最多只有两个分支的树形结构,如下图所示,一个分支指向左子节点,也叫做这个节点的左孩子,一个分支指向当前节点的右子节点,也叫做右孩子,我们把当前节点叫做父节点,如果一个节点没有孩子节点,也就是没有分支,我们叫它叶子节点。其实通过我们前面学习优先级队列时我们已经对完全二叉树这种结构有所了解了。

对于二叉树的实现呢,可以像下面这样构造节点类来实现二叉树。
public class TreeNode {public int val;public TreeNode left;public TreeNode right;public TreeNode(int val) {this.val = val;}public TreeNode(TreeNode left, int val, TreeNode right) {this.left = left;this.val = val;this.right = right;}@Overridepublic String toString() {return String.valueOf(this.val);}
}同时还可以数组模拟实现二叉树,具体实现的细节我们已经在上一篇讲优先级队列时讲的很清楚了,如果还有不太了解的可以翻上一篇文章。
遍历
对于二叉树这种树形结构的遍历,我们分为两种遍历方式,一种叫做宽度优先遍历,一种叫做深度优先遍历。
宽度优先遍历
宽度优先遍历我们是从根节点开始,一层一层的往下遍历,遵从的是先遍历完当前层再遍历下一层,也很符合它的名字宽度优先,先遍历横向再遍历纵向,这个过程其实也是一层一层遍历,所以也叫做二叉树的层序遍历。

了解了这个过程后我们来看一下怎么实现对一棵二叉树进行宽度优先遍历,如果我们是通过树节点来构造的一颗二叉树,那我们要需要准备一个队列,由于我们一开始只知道树的根节点root,我们先把root放到队列中,然后一个while循环,条件就是当队列不为空时就一直循环下去,我先说明一下这个队列只有在遍历完整棵树后才会停止。在循环中做的事就是我们拿出队头节点,然后依次判断它是否有左右孩子,如果有就把它的左右孩子放到队列中,如此反复。对着上面图片上的二叉树,过程就是节点1先入队列,接着拿出节点1,将它左右孩子2,3入队列,然后拿出节点2,将它左孩子4入队列,接着拿出节点3,如此往复。
// 宽度优先遍历public void bfs(TreeNode root) {// 树为空,特殊处理if (root == null) {return;}Queue queue = new LinkedList();// 根节点入队queue.add(root);// 当前层的节点数
// int num = 1;while (!queue.isEmpty()) {// 下一层的节点数// int next = 0;// 表示循环遍历当前层的节点// for (int i = 0; i < num; i++) {// 取出队头元素TreeNode cur = (TreeNode) queue.poll();System.out.print(cur + " ");// 如果有左孩子就入队if (cur.left != null) {queue.add(cur.left);// 下一层节点个数+1// next++;}// 如果有右孩子就入队if (cur.right != null) {queue.add(cur.right);// 下一层节点个数+1// next++;}// }// 当前层遍历完,换行// System.out.println();
// num = next;}}其实上面的这种遍历方式是不知道当前遍历到的节点属于哪一层的,如果我们想改进,只需要增加两个变量来记录这一层和下一层的节点数就行了。把上面注释掉的代码放开,就是答案。
另外如果使用的是数组模拟实现的二叉树,我们只需要遍历数组就是二叉树的层序遍历。
深度优先遍历
深度优先遍历顾名思义就是先往深遍历再往宽遍历,也就是我们要先向下去遍历到叶子节点,但是接下来的操作的不同让深度优先遍历又分为了三种,前序遍历,中序遍历,后序遍历。
前序遍历
对于每一颗子树,先访问该节点,然后是左子树,最后是右子树。其实通俗来讲就是我们先打印自己的值再去遍历左子树,接着遍历右子树。
实现其实是分递归和迭代两种方式,如果我们写成递归其实非常简单,就是照着第一句话写代码就行了。
// 前序遍历preOrder 递归public void preOrder(TreeNode root) {// 递归终止的条件if (root == null) {return;}// 打印当前节点的值System.out.println(root.val);// 遍历左子树preOrder(root.left);// 遍历右子树preOrder(root.right);}迭代实现的话,我们可以模拟一下递归遍历的执行过程就会发现,其实它遍历时无论是前序中序还是后序,走过的路程都是先走左子树然后回到根节点,接着走右子树再回到根节点,对于任意一颗子树也是这样的。

接下来我们来尝试一下实现一下二叉树遍历过程中走过的路,由于当我们往左子树遍历时,我们是124的路线去的,我们还要421的路线出来,树节点并不存储父节点,所以我们需要一种数据结构记录来时经过的节点,我想你也已经想到了,我们可以用栈存储来时的节点,然后在到达叶子节点时我们就从栈中弹出元素不断往回走。
// 前序遍历preOrder 非递归public static void preOrder2(TreeNode root) {Stack st = new Stack();// 代表当前节点TreeNode cur = root;// 如果当前节点不为空并且栈不为空就一直循环while (cur != null || !st.isEmpty()) {// 没有来到叶子节点if (cur != null) {// 打印去的路线colorPrintln("去: " + cur.val, 31);st.push(cur);// 往左走cur = cur.left;} else { //来到叶子节点// 栈顶弹出节点TreeNode pop = (TreeNode) st.pop();// 打印回的路线colorPrintln("回: " + pop.val, 34);// 往右走cur = pop.right;}}}
前序遍历就是简单来说就是中左右,也就是优先处理当前节点在是左节点最后处理右节点。
所以我们来到一个节点时一定是优先处理这个节点,所以一定在刚到这个节点时打印,那么去的路线就是这棵树的前序遍历,也就是打印的红色的去的顺序
中序遍历
对于每一颗子树,先访问左子树,然后是该节点,最后是右子树。其实通俗来讲就是先去遍历左子树,再打印自己的值,最后遍历右子树。
递归的实现也是按照第一句话写代码就行了。
// 中序遍历inOrder 递归public void inOrder(TreeNode root) {// 递归终止的条件if (root == null) {return;}// 遍历左子树inOrder(root.left);// 打印当前节点的值System.out.println(root.val);// 遍历右子树inOrder(root.right);}迭代实现的话,我们中序遍历就是左中右的顺序,那么我们就应该是在回到这个节点的时候打印,也就是回来的路线,对应得就是控制台打印的蓝色回来路线。
后序遍历
对于每一颗子树,先访问左子树,然后是右子树,最后是该节点。其实通俗来讲就是先去遍历左子树,再遍历右子树,最后打印自己的值。
递归的实现也是按照第一句话写代码就行了。
// 后序遍历lastOrder 递归public void lastOrder(TreeNode root) {// 递归终止的条件if (root == null) {return;}// 遍历左子树lastOrder(root.left);// 遍历右子树lastOrder(root.right);// 打印当前节点的值System.out.println(root.val);}后序遍历的迭代实现其实就是左右中,最后再处理我们的当前节点,但是我们再来看看那段代码回来时的逻辑 ,在else这个分支中,我们是先处理了当前节点,再去到右子树,所以我们要在这里做一些修改,让它先去处理右子树,当一个节点左右子树都处理完了,我们再来处理当前节点。
else { //来到叶子节点// 栈顶弹出节点TreeNode pop = (TreeNode) st.pop();// 打印回的路线colorPrintln("回: " + pop.val, 34);// 往右走cur = pop.right;}当来到一个节点时,它可能没有右子树又或者它已经处理完它的右子树了,对于第二种情况我们就需要用一个变量去存储上一次处理的节点,然后就可以比较是已经处理完右子树了,还是还没有开始处理。
// 后序遍历lastOrder 非递归public static void lastOrder2(TreeNode root) {Stack st = new Stack();// 代表当前节点TreeNode cur = root;// 最近一次弹栈的元素TreeNode pop = null;// 如果当前节点不为空并且栈不为空就一直循环while (cur != null || !st.isEmpty()) {// 没有来到叶子节点if (cur != null) {// 打印去的路线//colorPrintln("去: " + cur.val, 31);st.push(cur);// 往左走cur = cur.left;} else { //来到叶子节点// 栈顶元素TreeNode peek = (TreeNode) st.peek();// 当前栈顶元素的右子树为null或者它的右子树为上一次处理的节点if (peek.right == null || peek.right == pop) {pop = (TreeNode) st.pop();colorPrintln("回:" + pop.val, 31);} else {// 往右走cur = peek.right;}}}}和前中序迭代的代码没什么两样就是多了一个变量记录上一次处理的节点以及在回来这条路上判断一下当前是否处理完右子树。
其实我们可以把前中后序遍历的迭代实现整合成一个模板,而每种遍历顺序只是处理时机不同罢了,看看下面的代码,配合注释我相信你可以看懂,其实和前面我们的实现大差不差。
public static void allIterations(TreeNode root) {Stack st = new Stack();// 代表当前节点TreeNode cur = root;// 最近一次弹栈的元素TreeNode pop = null;// 如果当前节点不为空并且栈不为空就一直循环while (cur != null || !st.isEmpty()) {// 没有来到叶子节点if (cur != null) {st.push(cur);colorPrintln("前:" + cur.val, 31);// 往左走处理左子树cur = cur.left;} else { //来到叶子节点// 栈顶元素TreeNode peek = (TreeNode) st.peek();// 没有右子树if (peek.right == null) {colorPrintln("中:" + peek.val, 36);pop = (TreeNode) st.pop();colorPrintln("后:" + pop.val, 34);} else if (peek.right == pop) { //右子树已经处理完成pop = (TreeNode) st.pop();colorPrintln("后:" + pop.val, 34);} else {colorPrintln("中:" + peek.val, 36);// 往右走处理右子树cur = peek.right;}}}}二叉树遍历这一块是重点,掌握了二叉树的遍历,其实树形结构的遍历也就掌握了。
二叉搜索树
概述
在计算机科学中,树形结构中我们规定了一种利于查找值的数据结构叫做二叉搜索树,它的结构在二叉树上有所不同,二叉搜索树的节点类新增一个key属性,用来比较节点之间的大小,key可以等于value,但是key不可以重复,同时对于任意一个树节点,它的key比左子树的key都大,同时也比右子树的key都小,也就是说比当前节点小的都在左子树,比当前节点大的都在右子树。下图所示就是一颗二叉搜索树。

这时如果我们要查找8,我们从根节点4开始,发现8大于4,所以我们去4的右子树上找,我们来到7,发现8大于7,所以我们来到7的右子树,这时我们发现当前节点就是8,所以对于一颗左右子树高度平衡的二叉树,它查找值的时间复杂度是O(logn)。
但是如果是下面这样一颗二叉搜索树那么它的时间复杂度就可能达到O(n)。

但是不要急,我们后面会有解决办法,我们先来学习一下二叉搜索树。
实现
结构
要实现二叉搜索树,我们就需要来构造我们的节点类,之前说过二叉搜索树就是多了一个key属性来比较大小,这里为了方便,我就直接规定为整型,省掉了写比较器。
static class BSTNode {int key;int value;BSTNode left;BSTNode right;public BSTNode(int key) {this.key = key;}public BSTNode(int key, int value) {this.key = key;this.value = value;}public BSTNode(int key, int value, BSTNode left, BSTNode right) {this.key = key;this.value = value;this.left = left;this.right = right;}}接着对于一个树形结构我们还需要一个根节点,这是必不可少的,当前还有一些地方你会看到有维护树的高度和树的节点数的,这里我们就从简单的开始就好了。
public class BSTTree {BSTNode root; //根节点static class BSTNode {int key;int value;BSTNode left;BSTNode right;public BSTNode(int key) {this.key = key;}public BSTNode(int key, int value) {this.key = key;this.value = value;}public BSTNode(int key, int value, BSTNode left, BSTNode right) {this.key = key;this.value = value;this.left = left;this.right = right;}}
}
查找
在之前我们已经知道了二叉搜索树的特性,所以现在实现二叉搜索树的查找功能我们直接根据特性写代码就行了,小的数去左子树找,大的数去右子树找,递归的代码就非常好实现
// 查找指定key对应节点的值public int get(int key) {return doGet(root, key);}private int doGet(BSTNode node, int key) {if (node == null) {return Integer.MIN_VALUE; // 没找到,返回一个特殊值}if (key < node.key) {doGet(node.left, key); // 向左找} else if (key > node.key) {doGet(node.right, key); // 向右找} else {return node.value; // 找到返回}}迭代的方法其中的逻辑也是一样。
public int get2(int key) {BSTNode node = root;while (node != null) {if (key < node.key) {node = node.left;} else if (key > node.key ) {node = node.right;} else {return node.value;}}return Integer.MIN_VALUE;}获得最小值
找到二叉搜索树中的最小值,只需要一直往左走,直到来到没有左孩子的节点,就是最小值。
// 获取树中最小的keypublic int min() {return doMin(root);}public int doMin(BSTNode node) {if(node == null){ // 树为空return Integer.MIN_VALUE;}if (node.left == null) { // 最小节点return node.value;}return doMin(node.left);}迭代实现逻辑也是一样的。
public int min2() {if (root == null) {return Integer.MIN_VALUE;}BSTNode node = root;while (node.left != null) {node = node.left;}return node.value;}
获得最大值
和最小值同理,只需要一直向右走,直到来到没有右孩子的节点,就是最大值。
// 获取树中最大的keypublic int max() {doMax(root);}public int doMax(BSTNode node) {if (node == null) { // 树为空return Integer.MIN_VALUE;}if (node.right == null) { // 最小节点return node.value;}return doMin(node.right);}迭代自己尝试一下吧,我相信你已经对递归改迭代有了一点体会了。
二叉搜索树的遍历和二叉树的遍历其实是一样的,所以自己测试吧,我就不贴了。
添加节点
添加节点分两种情况来实现,如果key已经存在,我们只要更新value值,如果没有存在,我们就新增节点,这次我用迭代来实现,递归的实现就交给你了。我们先要根据key来查找是否存在节点,这里我们可以直接复用get方法的代码,如果找到了,我们直接更新就好了,如果没有找到我们就需要新增节点,但是新增节点我们需要父节点,父节点我们只需要设置一个parent变量记录上一次操作的节点,其实也就是当前节点的父节点。
// 添加节点public void put(int key, int value) {BSTNode node = root;BSTNode parent = null; // 记录当前节点的父节点while (node != null) {parent = node;if (key < node.key) {node = node.left;} else if (key > node.key) {node = node.right;} else {// 1.更新node.value = value;return;}}// 树空if(parent == null){root = new BSTNode(key,value);return ;}// 2. 新增new BSTNode(key, value);if (key < parent.key) {parent.left = new BSTNode(key, value);} else {parent.right = new BSTNode(key, value);}}获得前任节点
先来讲一下什么是前任节点,通俗来说就是比它小的数中的最大值。如下图,4的前任节点是节点3,5的前任节点是节点4。其实对于二叉搜索树,当我们进行中序遍历时,顺序就是升序的,所以这时我们找前任节点非常简单,但是我们不用中序遍历这种方法,你可以自己尝试一下。

我们用另一种方法,这种方法前人已经总结好了,我们直接来看一下好了,这其实分为两种情况,有左子树和没有左子树,其实有左子树这种情况非常简单,逻辑和我们上面写的获得最大值其实是一样的。那第二种情况,我们就需要找到第一个从左而来的祖先节点,其实这时我们就可以用一个变量来记录最近的从左而来的祖先节点,当我们在向右走时,当前节点就是后面节点从左而来的祖先节点,最后如果这个节点不为null,我们返回这个节点的值就好了。

// 找到比它小的数中的最大值public int searchMaxButMin(int key) {BSTNode node = root;BSTNode ancestorFromLeft = null;while (node != null) {if (key < node.key) {node = node.left;} else if (key > node.key) {ancestorFromLeft = node;node = node.right;} else {break;}}// 没找到节点if (node == null) {return Integer.MIN_VALUE;}// 有左子树if (node.left != null) {return max(node.left);}// 没有左子树return ancestorFromLeft != null ? ancestorFromLeft.value : Integer.MIN_VALUE;}private int max(BSTNode node) {if (node == null) {return Integer.MIN_VALUE;}BSTNode p = node;while (p.right != null) {p = p.right;}return p.value;}获得后任节点
知道了前任节点,后任节点就是比它大的数中的最小值,中序遍历的方式交给你了。获得后任节点前人也是总结了两种规则,和上面那两条其实是对称的。

代码其实和上面是大同小异, 照着找前任的代码对称修改就好了,相信你可以完成的。
删除节点
对于二叉搜索树删除节点,就比较复杂,因为我们在删除一个节点后,我们得确保二叉搜索树得结构不能改变,就是左小右大。虽然复杂,但是不要慌,前人也已经帮我们总结了四种情况以及相应的解决办法,所以实现起来只要按着前人的规定敲代码就好了。

我们需要一个parent变量来记录当前操作的节点父节点,这样才可以实现托孤。对于情况一二三我们都很好实现, 情况三是包含在情况一二里的,我手写了一个托孤方法,实现起来也是简单,因为很多地方需要用到,所以还是把它抽取成一个方法最好。
if (node.left == null) {// 情况1shift(parent, node, node.right);} else if (node.right == null) {// 情况2shift(parent, node, node.left);} else {// 情况4}/*** 托孤儿方法* @param parent 待删除节点父亲* @param deleted 待删除节点* @param child 待删除节点的孩子*/private void shift(BSTNode parent, BSTNode deleted, BSTNode child) {// 删除节点为根节点if (parent == null) {root = child;} else if (deleted == parent.left) {parent.left = child;} else {parent.right = child;}}对于情况四我们可以发现当我们既存在左子树又存在右子树时,我们就来到了,情况四,那么有右子树我们要找它的后继节点,其实也是很简单的,在它右子树上一直往左走就好了 ,由于要判断后继节点的父节点是不是待删除节点,所以我们在找后继节点时,我们就需要记录后继节点的父节点。
// 情况4// 找到被删除节点的后继节点BSTNode s = node.right;BSTNode sParent = node; // 后继父亲while (s.left != null) {sParent = s;s = s.left;}因为我们在删除时是用后继节点来顶替被删除节点,所以我们删除之后还需要把后继节点的左右指针给调整好,赋值为待删除节点的左右指针。
// 后继节点即sif (sParent != node) { // 不相邻// 处理后继的后事shift(sParent, s, s.right); // 后继不可能有左孩子,托孤右孩子s.right = node.right;}// 后继取代被删除节点shift(parent, node, s);s.left = node.left;完整得代码如下,可以尝试多看几遍,把思路理清楚。
// 删除对应节点public int delete(int key) {// 找到待删除的节点BSTNode node = root;// 待删除节点的父节点BSTNode parent = null;while (node != null) {if (key < node.key) {parent = node;node = node.left;} else if (key > node.key) {parent = node;node = node.right;} else {break;}}if (node == null)return Integer.MIN_VALUE;// 删除操作// 情况1if (node.left == null) {shift(parent, node, node.right);} else if (node.right == null) {// 情况2shift(parent, node, node.left);} else {// 情况4// 找到被删除节点的后继节点BSTNode s = node.right;BSTNode sParent = node; // 后继父亲while (s.left != null) {sParent = s;s = s.left;}// 后继节点即sif (sParent != node) { // 不相邻// 处理后继的后事shift(sParent, s, s.right); // 后继不可能有左孩子,托孤右孩子s.right = node.right;}// 后继取代被删除节点shift(parent, node, s);s.left = node.left;}return node.value;}/*** 托孤方法* @param parent 待删除节点父亲* @param deleted 待删除节点* @param child 待删除节点的孩子*/private void shift(BSTNode parent, BSTNode deleted, BSTNode child) {// 删除节点为根节点if (parent == null) {root = child;} else if (deleted == parent.left) {parent.left = child;} else {parent.right = child;}}最后贴上递归实现,仅作了解。
public int delete2(int key) {ArrayList<Integer> result = new ArrayList<>(); // 保存被删除节点的值root = doDelete(root, key, result);return result.isEmpty() ? Integer.MIN_VALUE : result.get(0);}private BSTNode doDelete(BSTNode node, int key, ArrayList<Integer> result) {if (node == null) {return null;}if (key < node.key) {node.left = doDelete(node.left, key, result);return node;}if (key > node.key) {node.right = doDelete(node.right, key, result);return node;}result.add(node.value);// 情况一if (node.left == null) {return node.right;}// 情况二if (node.right == null) {return node.left;}// 情况四BSTNode s = node.right;while (s.left != null) {s = s.left;}s.right = doDelete(node.right, s.key, new ArrayList<>());s.left = node.left;return null;}最后给大家留下一个作业,看看自己能不能实现,就是给二叉搜索树添加一个范围查询,就是查找大于某个数的所有数或者小于某个数的所有数,或者位于某两个数中间的所有数,提示:可以用中序遍历。 可以尝试完成力扣938题,链接在下面相关题目中
相关题目
144. 二叉树的前序遍历 - 力扣(LeetCode)
145. 二叉树的后序遍历 - 力扣(LeetCode)
94. 二叉树的中序遍历 - 力扣(LeetCode)
101. 对称二叉树 - 力扣(LeetCode)
104. 二叉树的最大深度 - 力扣(LeetCode)
637. 二叉树的层平均值 - 力扣(LeetCode)
450. 删除二叉搜索树中的节点 - 力扣(LeetCode)
701. 二叉搜索树中的插入操作 - 力扣(LeetCode)
700. 二叉搜索树中的搜索 - 力扣(LeetCode)
98. 验证二叉搜索树 - 力扣(LeetCode)
938. 二叉搜索树的范围和 - 力扣(LeetCode)
235. 二叉搜索树的最近公共祖先 - 力扣(LeetCode)
如果不是天才,就请一步一步来。
相关文章:
数据结构----二叉树
小编会一直更新数据结构相关方面的知识,使用的语言是Java,但是其中的逻辑和思路并不影响,如果感兴趣可以关注合集。 希望大家看完之后可以自己去手敲实现一遍,同时在最后我也列出一些基本和经典的题目,可以尝试做一下。…...

通过python管理mysql
打开防火墙端口: 使用 firewall-cmd 命令在防火墙的 public 区域中永久添加 TCP 端口 7500(FRP 控制台面板端口)、7000(FRP 服务端端口)以及端口范围 6000-6100(一组客户端端口)。这些端口是 FR…...

Run the OnlyOffice Java Spring demo project in local
Content 1.Download the sample project in java2.Run the project3.Test the example document 1.Download the sample project in java Link: download the sample code in official website document properties setting spring 项目所在的服务器 server. Address192.168…...
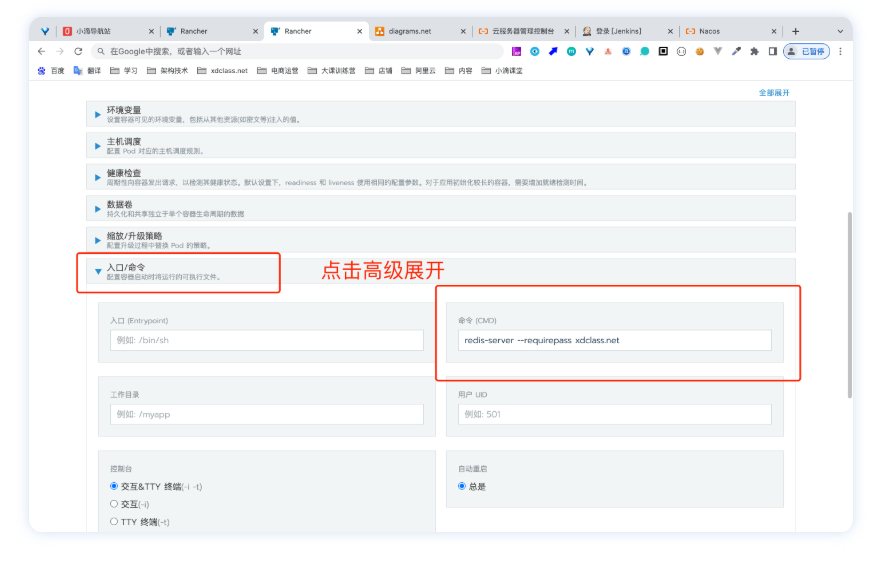
11. Rancher2.X部署多案例镜像
**部署springboot项目 : ** **部署中间件Mysql8.0 : ** 名称:service-mysql 端口 :3306:3306 镜像:mysql:8.0 环境变量: MYSQL_ROOT_PASSWORDxdclass.net168路径映射 /home/data/mysql/data /var/lib/mysql:rw /etc/localtime…...

探索Linux世界之Linux环境开发工具的使用
目录 一、yum -- Linux软件包管理器 1、什么是yum 2、yum的使用 2.1 yum一些经常见的操作 1.查看软件包 2. 安装软件包 3. 删除软件包 3、yum的周边知识 3.1 yum的软件包都是从哪里来的?是从哪里能下载到这些软件包? 3.2 yum的拓展软件源 二、…...

探索Spring Boot微服务架构的最佳实践
目录 引言 一、Spring Boot简介 二、微服务架构的关键要素 三、Spring Boot在微服务中的最佳实践 3.1 清晰的服务边界 3.2 自动化配置与依赖管理 3.3 服务注册与发现 3.4 配置管理 3.5 安全与认证 3.6 监控与日志 3.7 分布式事务 四、总结 引言 在当今快速迭代的软…...

[论文泛读]zkLLM: Zero Knowledge Proofs for Large Language models
文章目录 介绍实验数据实验数据1实验数据2实验数据3 介绍 这篇文章发在CCS2024,CCS是密码学领域的顶会。作者是来自加拿大的University of Waterloo。文章对大语言模型像GPT和LLM等大语言模型实现了零知识可验证执行,但不涉及零知识可验证训练。个人觉得…...

vscode插件中的图标怎么设置
首先在ts文件目录下和package.json同级的目录下加入一张图片,后缀是jpg、png、jpeg都可以。 然后package.json中加入该行 重新 vsce package即可 如果出现报错 The specified icon xxx/xxx/icon.jpg wasnt found in the extension. 那就是没有放正确文件夹的位…...

Study--Oracle-08-oracle数据库的闪回技术
一、闪回恢复区(Flash Recovery Area) 1、什么是闪回恢复区 闪回恢复区是Oracle数据库中的一个特殊存储区域,用于集中存放备份和恢复数据库所需的所有文件,包括归档日志和闪回日志。这个区域可以帮助数据库在遇到介质故障时进行完全恢复。通过将备份数…...
获取客户端真实IP
出于安全考虑,近期在处理一个记录用户真实IP的需求。本来以为很简单,后来发现没有本来以为的简单。这里主要备忘下,如果服务器处于端口回流(hairpin NAT),keepalived,nginx之后,如何取得客户端的…...

韩式告白土味情话-柯桥生活韩语学习零基础入门教学
你们韩国人别太会告白了! 1、너 얼굴에 뭐가 조금 묻었어! 你的脸上有点5376东西! 뭐가 조금 묻었1585757는데? 有点什么? 이쁨이 조금 묻었네. 有点漂亮。 2、돌잡이 때 뭐 잡았어요? 你抓周的时候抓了什么? 쌀 잡았…...
深入探讨Linux安全与高级应用)
Linux安全与高级应用(一)深入探讨Linux安全与高级应用
文章目录 深入探讨Linux安全与高级应用引言目录一、Linux安全与应用概述1.1 Linux的应用现状1.2 Linux的安全需求 二、构建LAMP企业网站平台2.1 LAMP平台简介2.2 安装和配置Apache服务器2.2.1 安装Apache2.2.2 配置Apache 2.3 安装和管理MySQL数据库2.3.1 安装MySQL2.3.2 配置M…...

【nginx 第二篇章】各个环境安装 nginx
一、Windows环境安装 1、下载 Nginx 访问Nginx官网(http://nginx.org/en/download.html)下载稳定版本的 Nginx 压缩包,如 nginx-1.xx.x.zip。下载后解压到指定的目录,例如 D:\nginx。 2、启动 Nginx 直接双击解压目录下的 ngi…...

在Spring Boot和MyBatis-Plus项目中,常见的错误及其解决方法2.0
1. org.springframework.beans.factory.BeanCreationException: Error creating bean with name requestMappingHandlerMapping 现象 在创建bean时发生错误,通常是因为存在重复的URL映射。 解决方法 检查所有控制器方法上的URL映射注解,确保没有重复…...

招聘信息数据清洗
文章目录 前言代码示例如下 前言 相关知识 为了完成本关任务,你需要掌握: 1.Spark 清洗数据的相关方法, 2.空值列怎么删除; 3.怎么数据切分才能达到想要的数据。 Spark清洗数据相关方法 一、将含有空值的数据删除 1.将含有空值的数据删除&a…...

机器学习——支持向量机(SVM)(1)
目录 一、认识SVM 1. 基本介绍 2. 支持向量机分类器目标 二、线性SVM分类原理(求解损失) 三、重要参数 1. kernel(核函数) 2 .C(硬间隔与软间隔) 四、sklearn中的支持向量机(自查&#…...

Elastic Observability 8.15:AI 助手、OTel 和日志质量增强功能
作者:来自 Elastic Alex Fedotyev, Tom Grabowski, Vinay Chandrasekhar, Miguel Luna Elastic Observability 8.15 宣布了几个关键功能: 新的和增强的原生 OpenTelemetry 功能: OpenTelemetry Collector 的 Elastic 分发:此版本…...

Unity3D ECS架构的优缺点详解
前言 Unity3D作为一款强大的游戏开发引擎,近年来在性能优化和架构设计上不断进化,其中ECS(Entity-Component-System)架构的引入是其重要的里程碑之一。ECS架构通过重新定义游戏对象的组织和处理方式,为开发者带来了诸…...

理解Go语言中多种并发模式
Go 的同步原语使实现高效的并发程序成为可能,并且选择合适的同步原语和并发模式可以更加容易地实现并发的可能,减少错误的发生。这里谈论的并发模式是只在 Go 语言中常见的并发的“套路” ,一种可解决某一类通用场景和问题的惯用方法。 1. 并发模式概述 我们先来回顾下同步…...

C++ primer plus 第17 章 输入、输出和文件:文件输入和输出03:文件模式:二进制文件
系列文章目录 17.4.5 文件模式 程序清单17.18 append.cpp 程序清单17.19 binary.cpp 文章目录 系列文章目录17.4.5 文件模式程序清单17.18 append.cpp程序清单17.19 binary.cpp17.4.5 文件模式1.追加文件来看一个在文件尾追加数据的程序。程序清单17.18 append.cpp2.二进制文…...

3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐
3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在使用功能单一的网易云音乐吗?想不想让你的播放器拥…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

Gofile批量下载自动化工具:5步实现高效文件管理解决方案
Gofile批量下载自动化工具:5步实现高效文件管理解决方案 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在当今数字化工作环境中,技术团队经常需要从…...

基于MaixCam的延时摄影系统:从硬件选型到Python编程全解析
1. 项目概述:用MaixCam打造你的专属延时摄影工坊延时摄影,这个听起来有点专业、甚至带点“魔法”色彩的词,其实离我们并不遥远。想想看,把一朵花从含苞到绽放的几天时间,压缩成十几秒的惊艳绽放;或者把一座…...

PCL 基于强度的双边滤波【2026最新版】
目录 一、算法原理 1、计算步骤 2、算法源码 3、函数解析 4、参考文献 二、代码实现 三、结果展示 四、滤波后未发生变化的原因 五、解决办法 六、结果展示 七、相关链接 本文由CSDN点云侠原创,博客长期更新,本文最近一次更新时间为:2026年5月24日。 一、算法原理 1、计算…...

Elden Ring帧率解锁终极指南:从60帧到144+的完整教程
Elden Ring帧率解锁终极指南:从60帧到144的完整教程 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/Elden…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...
)
ArduPilot飞行模式实战:从代码角度看Stabilize、Acro、Loiter模式如何切换(附避坑指南)
ArduPilot飞行模式深度解析:从状态机到实战避坑指南 在开源飞控领域,ArduPilot以其强大的飞行模式系统著称。不同于普通用户只需了解模式功能,开发者更需要掌握模式切换的底层机制——这直接关系到飞行安全与二次开发效率。本文将带您深入Sta…...

中小企无需重型数据中台:轻量化数据体系搭建完整方案
过去几年,“数据中台”一度成为企业数字化的标配热词。大量中小企业盲目跟风搭建重型数据中台,投入高额成本、耗费数月甚至数年周期,最终落地效果极差:功能冗余、运维复杂、使用率低、投入产出比失衡。大量项目最终沦为“摆设式中…...