全网超详细攻略-从入门到精通haproxy七层代理
目录
一.haproxy概述
1.1 haproxy简介
1.2 haproxy的主要特性
1.3 haproxy的优缺点
二.负载均衡介绍
2.1 什么是负载均衡
2.2 为什么用负载均衡
2.3 负载均衡类型
2.3.1 四层负载均衡
2.3.2 七层负载均衡
2.3.3 四层和七层的区别
三.haproxy的安装及服务
3.1 实验环境
3.2 haproxy的基本配置信息
3.2.1 haproxy的基本部署
3.2.2 global配置
3.2.2.1 参数说明
3.2.2.2 haproxy的全局配置参数
3.2.2.3 定向haproxy日志
3.2.3 proxies配置
3.2.3.1 参数说明
3.3 socat 工具
四. haproxy的算法
4.1.静态算法
4.1.1 static-rr:基于权重的轮询调度
4.1.2 first
4.2 动态算法
4.2.1 roundrobin(常用)
4.2.2 leastconn
4.3 其他算法
4.3.1 source
4.3.1.1 map-base 取模法
4.3.1.2 一致性hash
4.3.2 uri
4.3.3 url_param
4.3.4 hdr
4.3.5 算法总结
五.高级功能及配置
5.1.1 配置选项
5.2 HAProxy状态页
5.2.1 状态页配置项
5.3 IP透传
5.3.2 七层IP透传
5.3.3 四层IP透传
5.4 ACL
利用ACL做动静分离等访问控制
一.haproxy概述
1.1 haproxy简介
haproxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。haproxy特别适用于那些负载特大的web站点, 这些站点通常又需要会话保持或七层处理。haproxy运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中, 同时可以保护你的web服务器不被暴露到网络上。
支持的功能:
- TCP 和 HTTP反向代理
- SSL/TSL服务器
- 可以针对HTTP请求添加cookie,进行路由后端服务器
- 可平衡负载至后端服务器,并支持持久连接
- 支持所有主服务器故障切换至备用服务器 keepalive
- 支持专用端口实现监控服务
- 支持停止接受新连接请求,而不影响现有连接
- 可以在双向添加,修改或删除HTTP报文首部字段
- 响应报文压缩
- 支持基于pattern实现连接请求的访问控制
- 通过特定的URI(url)为授权用户提供详细的状态信息
1.2 haproxy的主要特性
- 高性能负载均衡: HAProxy通过优化的事件驱动引擎,能够以最小的系统资源开销处理大量并发请求。它支持多种负载均衡算法,如轮询、最少连接、源IP哈希等,可根据实际业务需求灵活配置
- 健康检查与故障恢复: HAProxy具备完善的后端服务器健康检查机制,可以根据响应时间、错误率等因素自动剔除不健康的后端节点,并在节点恢复时重新将其加入到服务池中,确保服务连续性
- 会话保持与亲和性: 为了保证用户的会话一致性,HAProxy支持基于cookie或源IP地址的会话保持功能,确保同一客户端的请求被转发到同一台后端服务器进行处理
- 安全性与SSL卸载: HAProxy支持SSL/TLS加密传输,可对HTTPS流量进行解密并透明地分发至后端服务器,同时也能终止SSL连接以减轻服务器的加密计算压力
- 高级路由与策略: 根据HTTP请求头、URL路径、内容类型等条件,HAProxy可以执行复杂的路由规则和ACL策略,使得负载均衡更加智能化和精准化
- 日志记录与监控: HAProxy提供丰富的日志记录选项,可通过syslog、CSV格式输出等方式收集统计数据,便于运维人员实时监控系统状态和性能指标
1.3 haproxy的优缺点
- 优点
高性能:HAProxy是一个高性能的负载均衡器,可以处理大量的并发连接
灵活性:HAProxy支持多种负载均衡算法,如轮询、加权轮询、最少连接等,可以根据实际需求选择合适的算法
高可用性:HAProxy可以检测服务器的健康状态,如果某个服务器出现故障,它可以自动将
流量转移到其他健康的服务器,从而保证服务的高可用性
安全性:HAProxy可以作为反向代理,隐藏后端服务器的真实IP地址,提高系统的安全性。
- 缺点
单点故障:如果HAProxy本身出现故障,可能会导致整个系统的服务不可用
配置复杂:HAProxy的配置相对复杂,需要一定的学习成本
性能瓶颈:虽然HAProxy的性能很高,但在处理大量并发连接时,可能会成为系统的性能瓶颈
功能单一:只支持做负载均衡的调度服务器,不支持正则处理,不能实现动静分离,也不能
做web服务器
总的来说,HAProxy是一个强大的负载均衡器,可以提高系统的可用性、性能和安全性,但也需要注意其可能存在的缺点
二.负载均衡介绍
2.1 什么是负载均衡
负载均衡: Load Balance ,简称 LB ,是一种服务或基于硬件设备等实现的高可用反向代理技术,负载均衡将特定的业务(web 服务、网络流量等 ) 分担给指定的一个或多个后端特定的服务器或设备,从而提高了公司业务的并发处理能力、保证了业务的高可用性、方便了业务后期的水平动态
2.2 为什么用负载均衡
- Web服务器的动态水平扩展-->对用户无感知
- 增加业务并发访问及处理能力-->解决单服务器瓶颈问题
- 节约公网IP地址-->降低IT支出成本
- 隐藏内部服务器IP-->提高内部服务器安全性
- 配置简单-->固定格式的配置文件
- 功能丰富-->支持四层和七层,支持动态下线主机
- 性能较强-->并发数万甚至数十万
2.3 负载均衡类型
2.3.1 四层负载均衡

1. 通过 ip+port 决定负载均衡的去向。2. 对流量请求进行 NAT 处理,转发至后台服务器。3. 记录 tcp 、 udp 流量分别是由哪台服务器处理,后续该请求连接的流量都通过该服务器处理。4. 支持四层的软件
- lvs:重量级四层负载均衡器。
- Nginx:轻量级四层负载均衡器,可缓存。(nginx四层是通过upstream模块)
- Haproxy:模拟四层转发。
2.3.2 七层负载均衡
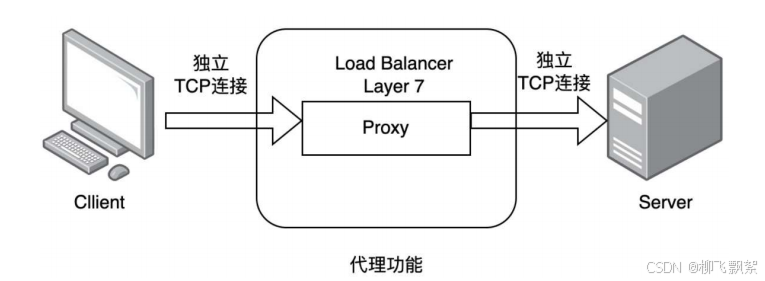
1. 通过虚拟 ur| 或主机 ip 进行流量识别,根据应用层信息进行解析,决定是否需要进行负载均衡。2. 代理后台服务器与客户端建立连接,如 nginx 可代理前后端,与前端客户端 tcp 连接,与后端服务器建立tcp 连接 ,3. 支持 7 层代理的软件:
- Nginx:基于http协议(nginx七层是通过proxy_pass)
- Haproxy:七层代理,会话保持、标记、路径转移等。
2.3.3 四层和七层的区别
所谓的四到七层负载均衡,就是在对后台的服务器进行负载均衡时,依据四层的信息或七层的信息来决定怎么样转发流量四层的负载均衡,就是通过发布三层的 IP 地址( VIP ),然后加四层的端口号,来决定哪些流量需要做负载均衡,对需要处理的流量进行NAT 处理,转发至后台服务器,并记录下这个 TCP 或者 UDP 的流量是由哪台服务器处理的,后续这个连接的所有流量都同样转发到同一台服务器处理。七层的负载均衡,就是在四层的基础上(没有四层是绝对不可能有七层的),再考虑应用层的特征,比如同一个Web 服务器的负载均衡,除了根据 VIP 加 80 端口辨别是否需要处理的流量,还可根据七层的URL、浏览器类别、语言来决定是否要进行负载均衡。1.分层位置:四层负载均衡在传输层及以下,七层负载均衡在应用层及以下
2.性能 :四层负载均衡架构无需解析报文消息内容,在网络吞吐量与处理能力上较高:七层可支持解析应用层报文消息内容,识别URL、Cookie、HTTP header等信息。、
3.原理 :四层负载均衡是基于ip+port;七层是基于虚拟的URL或主机IP等。
4.功能类比:四层负载均衡类似于路由器;七层类似于代理服务器。
5.安全性:四层负载均衡无法识别DDoS攻击;七层可防御SYN Cookie/Flood攻击
三.haproxy的安装及服务
3.1 实验环境
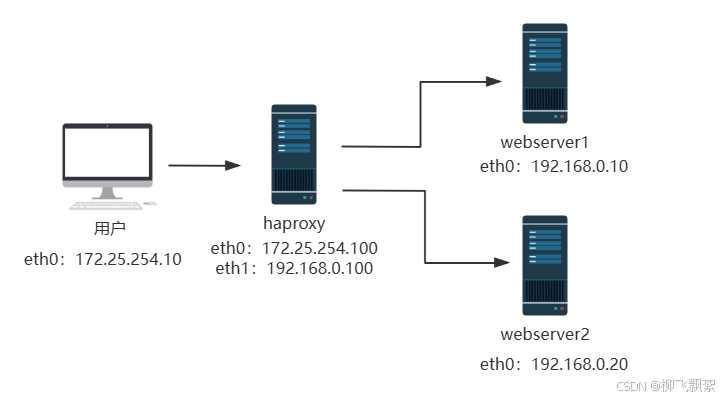
| 功能 | ip |
| client | nat-eth0:172.25.254.10 |
| haproxy | nat-eth0:172.25.254.100,仅主机-eth1:192.168.0.100 |
| webserver1 | 仅主机-eth0:192.168.0.10 |
| webserver2 | 仅主机-eth0:192.168.0.20 |
所有主机关闭防火墙和selinux
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
两台webserver安装nginx
#webserver1
[root@webserver1 ~]# yum install nginx -y
[root@webserver1 ~]# echo webserver1 - 192.168.0.10 > /usr/share/nginx/html/index.html
[root@webserver1 ~]# systemctl enable --now nginx
Created symlink /etc/systemd/system/multi-user.target.wants/nginx.service → /usr/lib/systemd/system/nginx.service.#webserver2
[root@webserver2 ~]# yum install nginx -y
[root@webserver2 ~]# echo webserver2 - 192.168.0.20 > /usr/share/nginx/html/index.html
[root@webserver2 ~]# systemctl enable --now nginx
Created symlink /etc/systemd/system/multi-user.target.wants/nginx.service → /usr/lib/systemd/system/nginx.service.#client访问
[root@client ~]# curl 192.168.0.10
webserver1 - 192.168.0.10
[root@client ~]# curl 192.168.0.20
webserver2 - 192.168.0.20
3.2 haproxy的基本配置信息
官方文档: http://cbonte.github.io/haproxy-dconv/HAProxy 的配置文件haproxy.cfg由两大部分组成,分别是:global:全局配置段
- 进程及安全配置相关的参数
- 性能调整相关参数
- Debug参数
proxies:代理配置段
- defaults:为frontend, backend, listen提供默认配置
- frontend:前端,相当于nginx中的server {}
- backend:后端,相当于nginx中的upstream {}
- listen:同时拥有前端和后端配置,配置简单,生产推荐使用
3.2.1 haproxy的基本部署
#在haproxy主机上安装haproxy
[root@haproxy ~]# yum install haproxy -y#编辑配置文件
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg
#上面内容忽略
#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend webcluster #设定前端bind *:80mode httpuse_backend webcluster-hostbackend webcluster-host #设定后端balance roundrobinserver web1 192.168.0.10:80server web2 192.168.0.20:80[root@haproxy ~]# systemctl restart haproxy.service
[root@haproxy ~]# systemctl enable haproxy.service #client访问测试
[root@client ~]# curl 172.25.254.100
webserver1 - 192.168.0.10
[root@client ~]# curl 172.25.254.100
webserver2 - 192.168.0.20
[root@client ~]# curl 172.25.254.100
webserver1 - 192.168.0.10#另一种方法,将前后端合并,将之前写的注释掉,写入新内容listen webclusterbind *:80mode httpbalance roundrobinserver web1 192.168.0.10:80server web2 192.168.0.20:80[root@haproxy ~]# systemctl restart haproxy.service #client访问,效果一样
[root@client ~]# curl 172.25.254.100
webserver1 - 192.168.0.10
[root@client ~]# curl 172.25.254.100
webserver2 - 192.168.0.20
[root@client ~]# curl 172.25.254.100
3.2.2 global配置
3.2.2.1 参数说明
| 参数 | 类 型 | 作用 |
| chroot | 全局 | 锁定运行目录 |
| deamon | 全局 | 以守护进程运行 |
| user, group, uid, gid | 全局 | 运行 haproxy 的用户身份 |
| stats socket | 全局 | 套接字文件 |
| nbproc N | 全局 | 开启的 haproxy worker 进程数,默认进程数是一个 |
| nbthread 1 (和 nbproc 互斥) | 全局 | 指定每个 haproxy 进程开启的线程数,默认为每个进程一个线程 |
| cpu-map 1 0 | 全局 | 绑定 haproxy worker 进程至指定 CPU ,将第 1 个 work 进程绑定至0 号 CPU |
| cpu-map 2 1 | 全局 | 绑定 haproxy worker 进程至指定 CPU ,将第 2 个 work 进程绑定至1 号 CPU |
| maxconn N | 全局 | 每个 haproxy 进程的最大并发连接数 |
| maxsslconn N | 全局 | 每个 haproxy 进程 ssl 最大连接数 , 用于 haproxy 配置了证书的场景下 |
| maxconnrate N | 全局 | 每个进程每秒创建的最大连接数量 |
| spread-checks N | 全局 | 后端 server 状态 check 随机提前或延迟百分比时间,建议 2- 5(20%-50%)之间,默认值 0 |
| pidfile | 全局 | 指定 pid 文件路径 |
| log 127.0.0.1 local2 info | 全局 | 定义全局的 syslog 服务器;日志服务器需要开启 UDP 协议,最多可以定义两个 |
3.2.2.2 haproxy的全局配置参数
[root@haproxy ~]# pstree -p | grep haproxy|-haproxy(32570)---haproxy(32572)---{haproxy}(32573) #只有一个进程,没有线程[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg ...........# utilize system-wide crypto-policiesssl-default-bind-ciphers PROFILE=SYSTEMssl-default-server-ciphers PROFILE=SYSTEMnbproc 2 # 启用多进程cpu-map 1 0 # 进程和CPU核心绑定 防止CPU抖动从而减伤系统资源消耗cpu-map 2 1 # 2表示第二个进程,0表示第一个CPU核心,1表示第二个CPU核心
.............
[root@haproxy ~]# systemctl restart haproxy.service
[root@haproxy ~]# pstree -p | grep haproxy|-haproxy(32625)-+-haproxy(32627)| `-haproxy(32628)# 查看多线程数量 32960为haproxy子进程的id
[root@haproxy ~]# cat /proc/32628/status | grep -i thread
Threads: 1 #现在线程数量为1
Speculation_Store_Bypass: thread vulnerablenbthread 设定多线程
# 多线程与多进程互斥,多进程与多线程同时设定重启服务的时候会报错
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg # utilize system-wide crypto-policiesssl-default-bind-ciphers PROFILE=SYSTEMssl-default-server-ciphers PROFILE=SYSTEM#nbproc 2#cpu-map 1 0#cpu-map 2 1nbthread 2[root@haproxy ~]# systemctl restart haproxy.service
[root@haproxy ~]# pstree -p | grep haproxy|-haproxy(32646)---haproxy(32648)---{haproxy}(32649)
[root@haproxy ~]# cat /proc/32649/status | grep -i thread
Threads: 2 #现在线程数量为2
Speculation_Store_Bypass: thread vulnerable
3.2.2.3 定向haproxy日志
[root@haproxy ~]# vim /etc/rsyslog.conf
#编辑下面两处[root@haproxy ~]# systemctl restart rsyslog.service 

3.2.3 proxies配置
3.2.3.1 参数说明
| 参数 | 类型 | 作用 |
| defaults [ ] | proxies | 默认配置项,针对以下的 frontend 、 backend 和 listen 生效,可以多个name也可以没有 name |
| frontend | proxies | 前端 servername ,类似于 Nginx 的一个虚拟主机 server 和 LVS 服务集群。 |
| backend | proxies | # 后端服务器组,等于 nginx 的 upstream 和 LVS 中的 RS 服务器 |
| listen | proxies | # 将 frontend 和 backend 合并在一起配置,相对于 frontend 和 backend配置更简洁,生产常用 |
Proxies配置-defaults
| 参数 | 作用 |
| mode http | HAProxy实例使用的连接协议 |
| log global | 指定日志地址和记录日志条目的syslog/rsyslog日志设备 |
| option httplog | 日志记录选项,httplog表示记录与 HTTP会话相关的各种属性值。包括HTTP请求、会话状态、连接数、源地址以及连接时间等 |
| option dontlognull | dontlognull表示不记录空会话连接日志 |
| option http-server-close | 等待客户端完整HTTP请求的时间,此处为等待10s。 |
| option forwardfor except 127.0.0.0/8 | 透传客户端真实IP至后端web服务器;在apache配置文件中加入: %{X-Forwarded-For}i;后在webserer中看日志即可看到地址透传信息 |
| option redispatch | 当server Id对应的服务器挂掉后,强制定向到其他健康的服务器,重新派发 |
| option http-keep-alive | 开启与客户端的会话保持 |
| retries 3 | 等待客户端请求完全被接收和处理的最长时间 |
| timeout queue 60s | 设置删除连接和客户端收到503或服务不可用等提示信息前的等待时间 |
| timeout connect 120s | 设置等待服务器连接成功的时间 |
| timeout client 600s | 设置允许客户端处于非活动状态,即既不发送数据也不接收数据的时间 |
| timeout server 600s | 设置服务器超时时间,即允许服务器处于既不接收也不发送数据的非活动时间 |
| timeout http-keep-alive 60s | session 会话保持超时时间,此时间段内会转发到相同的后端服务器 |
| timeout check 10s | 指定后端服务器健康检查的超时时间 |
| maxconn 3000 | 最大连接数量限制 |
| default-server inter 1000 weight 3 | 每隔 1000 毫秒对服务器的状态进行检查 |
frontend 配置参数:bind :指定 HAProxy 的监听地址,可以是 IPV4 或 IPV6 ,可以同时监听多个 IP 或端口,可同时用于 listen 字段中# 格式:bind [<address>]:<port_range> [, ...] [param*]# 注意:如果需要绑定在非本机的 IP ,需要开启内核参数: net.ipv4.ip_nonlocal_bind=1backlog <backlog> # 针对所有 server 配置 , 当前端服务器的连接数达到上限后的后援队列长度,注意:不支持backend
定义一组后端服务器, backend 服务器将被 frontend 进行调用。注意 : backend 的名称必须唯一 , 并且必须在 listen 或 frontend 中事先定义才可以使用 , 否则服务无法启动mode http|tcp # 指定负载协议类型 , 和对应的 frontend 必须一致option # 配置选项server # 定义后端 real server, 必须指定 IP 和端口
| 参数 | 作用 |
| check | 对指定real进行健康状态检查,如果不加此设置,默认不开启检查,只有check后面没有其它配置也可以启用检查功能;默认对相应的后端服务器IP和端口,利用TCP连接进行周期性健康性检查,注意必须指定端口才能实现健康性检查 |
| addr | 可指定的健康状态监测IP,可以是专门的数据网段,减少业务网络的流量 |
| port | 指定的健康状态监测端口 |
| inter | 健康状态检查间隔时间,默认2000 ms |
| fall | 后端服务器从线上转为线下的检查的连续失效次数,默认为3 |
| rise | 后端服务器从下线恢复上线的检查的连续有效次数,默认为2 |
| weight | 默认为1,最大值为256,0(状态为蓝色)表示不参与负载均衡,但仍接受持久连接 |
| backup | 将后端服务器标记为备份状态,只在所有非备份主机down机时提供服务,类似Sorry |
| disabled | 将后端服务器标记为不可用状态,即维护状态,除了持久模式 |
| redirect prefix http://www.baidu.com/ | \将请求临时(302)重定向至其它URL,只适用于http模式 |
| maxconn | 当前后端server的最大并发连接数 |
3.3 socat 工具
#下载socat包
[root@haproxy ~]# yum install socat -y#修改配置文件
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg
..........# turn on stats unix socketstats socket /var/lib/haproxy/stats mode 600 level admin[root@haproxy ~]# systemctl restart haproxy.service #查看haproxy状态
[root@haproxy ~]# echo "show info" | socat stdio /var/lib/haproxy/stats
Name: HAProxy
Version: 2.4.7-b5e51a5
Release_date: 2021/10/04
Nbthread: 2
Nbproc: 1
Process_num: 1
Pid: 32804
Uptime: 0d 0h02m26s
Uptime_sec: 146
Memmax_MB: 0
PoolAlloc_MB: 0
PoolUsed_MB: 0
PoolFailed: 0
Ulimit-n: 200035
........#查看集群状态
[root@haproxy ~]# echo "show servers state" | socat stdio /var/lib/haproxy/stats
1
# be_id be_name srv_id srv_name srv_addr srv_op_state srv_admin_state srv_uweight srv_iweight srv_time_since_last_change srv_check_status srv_check_result srv_check_health srv_check_state srv_agent_state bk_f_forced_id srv_f_forced_id srv_fqdn srv_port srvrecord srv_use_ssl srv_check_port srv_check_addr srv_agent_addr srv_agent_port
2 webcluster 1 web1 192.168.0.10 2 0 1 1 271 1 0 2 0 0 0 0 - 80 - 0 0 - - 0
2 webcluster 2 web2 192.168.0.20 2 0 1 1 271 1 0 2 0 0 0 0 - 80 - 0 0 - - 0
4 static 1 static 127.0.0.1 0 0 1 1 271 8 2 0 6 0 0 0 - 4331 - 0 0 - - 0
5 app 1 app1 127.0.0.1 0 0 1 1 271 8 2 0 6 0 0 0 - 5001 - 0 0 - - 0
5 app 2 app2 127.0.0.1 0 0 1 1 271 8 2 0 6 0 0 0 - 5002 - 0 0 - - 0
5 app 3 app3 127.0.0.1 0 0 1 1 270 8 2 0 6 0 0 0 - 5003 - 0 0 - - 0
5 app 4 app4 127.0.0.1 0 0 1 1 270 8 2 0 6 0 0 0 - 5004 - 0 0 - - 0#查看集群权重
[root@haproxy ~]# echo get weight webcluster/web1 | socat stdio
/var/lib/haproxy/stats
2 (initial 2)
[root@haproxy ~]# echo get weight webcluster/web2 | socat stdio
/var/lib/haproxy/stats
1 (initial 1)#设置权重
[root@haproxy ~]# echo "set weight webcluster/web1 1 " | socat stdio
/var/lib/haproxy/stats
[root@haproxy ~]# echo "set weight webcluster/web1 2 " | socat stdio /var/lib/haproxy/stats#下线后端服务器
[root@haproxy ~]# echo "disable server webcluster/web1 " | socat stdio
/var/lib/haproxy/stats#上线后端服务器
[root@haproxy ~]# echo "enable server webcluster/web1 " | socat stdio
/var/lib/haproxy/stats## 针对多进程处理方法
#如果开启多进程那么我们在对进程的sock文件进行操作时其对进程的操作时随机的
#如果需要指定操作进程那么需要用多soct文件方式来完成
haproxy ~]# vim /etc/haproxy/haproxy.cfg
...........
stats socket /var/lib/haproxy/stats1 mode 600 level admin process 1
stats socket /var/lib/haproxy/stats2 mode 600 level admin process 2
nbproc 2
cpu-map 1 0
cpu-map 2 1
...........
#这样每个进程就会有单独的sock文件来进行单独管理[root@haproxy ~]# ll /var/lib/haproxy/
总用量 0
srw------- 1 root root 0 8月 8 13:43 stats
srw------- 1 root root 0 8月 8 13:46 stats1
srw------- 1 root root 0 8月 8 13:46 stats2
四. haproxy的算法
HAProxy 通过固定参数 balance 指明对后端服务器的调度算法balance 参数可以配置在 listen 或 backend 选项中。HAProxy 的调度算法分为静态和动态调度算法有些算法可以根据参数在静态和动态算法中相互转换。
4.1.静态算法
静态算法:按照事先定义好的规则轮询公平调度,不关心后端服务器的当前负载、连接数和响应速度等,且无法实时修改权重( 只能为 0 和 1, 不支持其它值 ) ,只能靠重启 HAProxy 生效。
4.1.1 static-rr:基于权重的轮询调度
- 不支持运行时利用socat进行权重的动态调整(只支持0和1,不支持其它值)
- 不支持端服务器慢启动
- 其后端主机数量没有限制,相当于LVS中的 wrr
慢启动是指在服务器刚刚启动上不会把他所应该承担的访问压力全部给它,而是先给一部分,当没问题后在给一部分
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg .......
listen webclusterbind *:80mode httpbalance static-rrserver web1 192.168.0.10:80 check inter 2 fall 3 rise 5 weight 2server web2 192.168.0.20:80 check inter 2 fall 3 rise 5 weight 1
........[root@haproxy ~]# systemctl restart haproxy.service #client测试
[root@client ~]# for i in {1..10}; do curl 192.168.0.100; done
webserver1 - 192.168.0.10
webserver1 - 192.168.0.10
webserver2 - 192.168.0.20
webserver1 - 192.168.0.10
webserver1 - 192.168.0.10
webserver2 - 192.168.0.20
webserver1 - 192.168.0.10
webserver1 - 192.168.0.10
webserver2 - 192.168.0.20
webserver1 - 192.168.0.10
4.1.2 first
- 根据服务器在列表中的位置,自上而下进行调度
- 其只会当第一台服务器的连接数达到上限,新请求才会分配给下一台服务
- 其会忽略服务器的权重设置
- 不支持用socat进行动态修改权重,可以设置0和1,可以设置其它值但无效
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg .......
listen webclusterbind *:80mode httpbalance firstserver web1 192.168.0.10:80 check inter 2 fall 3 rise 5 weight 2server web2 192.168.0.20:80 check inter 2 fall 3 rise 5 weight 1
........[root@haproxy ~]# systemctl restart haproxy.service
4.2 动态算法
- 基于后端服务器状态进行调度适当调整,
- 新请求将优先调度至当前负载较低的服务器
- 权重可以在haproxy运行时动态调整无需重启
4.2.1 roundrobin(常用)
1. 基于权重的轮询动态调度算法,2. 支持权重的运行时调整,不同于 lvs 中的 rr 轮训模式,3. HAProxy 中的 roundrobin 支持慢启动 ( 新加的服务器会逐渐增加转发数 ) ,4. 其每个后端 backend 中最多支持 4095 个 real server ,5. 支持对 real server 权重动态调整,6. roundrobin 为默认调度算法 , 此算法使用广泛优先把流量给权重高且负载小的主机,以负载为主
4.2.2 leastconn
- leastconn加权的最少连接的动态
- 支持权重的运行时调整和慢启动(相当于LVS的wlc),即:根据当前连接最少的后端服务器而非权重进行优先调度(新客户端连接)【当两个主机的连接数都差不多的时候给权重高的,权重是次考虑的】
- 比较适合长连接的场景使用,比如:MySQL等场景。
4.3 其他算法
其它算法即可作为静态算法,又可以通过选项成为动态算法
4.3.1 source
源地址 hash ,基于用户源地址 hash 并将请求转发到后端服务器,后续同一个源地址请求将被转发至同一 个后端web 服务器。此方式当后端服务器数据量发生变化时,会导致很多用户的请求转发至新的后端服务器,默认为静态方式,但是可以通过hash-type 支持的选项更改这个算法一般是在不插入 Cookie 的 TCP模式下使用,也可给拒绝会话cookie 的客户提供最好的会话粘性,适用于 session 会话保持但不支持 cookie和缓存的场景源地址有两种转发客户端请求到后端服务器的服务器选取计算方式,分别是取模法和一致性hash
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg .......
listen webclusterbind *:80mode httpbalance sourceserver web1 192.168.0.10:80 check inter 2 fall 3 rise 5 weight 2server web2 192.168.0.20:80 check inter 2 fall 3 rise 5 weight 1
........[root@haproxy ~]# systemctl restart haproxy.service #测试
[root@client ~]# for i in {1..10}; do curl 192.168.0.100; done
webserver1 - 192.168.0.10
webserver1 - 192.168.0.10
webserver1 - 192.168.0.10
webserver1 - 192.168.0.10
webserver1 - 192.168.0.10
webserver1 - 192.168.0.10
webserver1 - 192.168.0.10
webserver1 - 192.168.0.10
webserver1 - 192.168.0.10
webserver1 - 192.168.0.10
4.3.1.1 map-base 取模法
map-based :取模法,对 source 地址进行 hash 计算,再基于服务器总权重的取模,最终结果决定将此请求转发至对应的后端服务器。此方法是静态的,即不支持在线调整权重,不支持慢启动,可实现对后端服务器均衡调度缺点是当服务器的总权重发生变化时,即有服务器上线或下线,都会因总权重发生变化而导致调度结果 整体改变 , hash-type 指定的默值为此算法所谓取模运算,就是计算两个数相除之后的余数, 10%7=3, 7%4=3map-based 算法:基于权重取模, hash(source_ip)% 所有后端服务器相加的总权重比如当源hash值时1111,1112,1113,三台服务器a b c的权重均为1,即abc的调度标签分别会被设定为 0 1 2(1111%3=1,1112%3=2,1113%3=0)1111 ----- > nodeb1112 ------> nodec1113 ------> nodea如果a下线后,权重数量发生变化1111%2=1,1112%2=0,1113%2=11112和1113被调度到的主机都发生变化,这样会导致会话丢失
#不支持动态调整权重值
[root@haproxy ~]# echo "set weight webserver_80/webserver1 2" | socat stdio
/var/lib/haproxy/haproxy.sock
Backend is using a static LB algorithm and only accepts weights '0%' and '100%'.#只能动态上线和下线
[root@haproxy ~]# echo "set weight webserver_80/webserver1 0" | socat stdio
/var/lib/haproxy/haproxy.sock
[root@haproxy ~]# echo "get weight webserver_80/webserver1" | socat stdio
/var/lib/haproxy/haproxy.sock
0 (initial 1)4.3.1.2 一致性hash
一致性哈希,当服务器的总权重发生变化时,对调度结果影响是局部的,不会引起大的变动hash (o) mod n
该hash算法是动态的,支持使用socat等工具进行在线权重调整,支持慢启动
- key1=hash(source_ip)%(2^32)
- keyA=hash(后端服务器虚拟ip)%(2^32) [0—4294967295]
- 将key1和keyA都放在hash环上,将用户请求调度到离key1最近的keyA对应的后端服务器
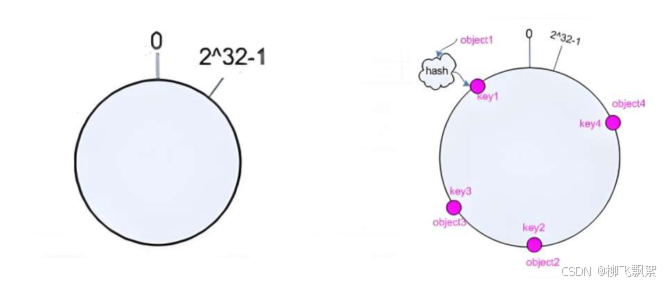
hash 环偏斜问题增加虚拟服务器 IP 数量,比如:一个后端服务器根据权重为 1 生成 1000 个虚拟 IP ,再 hash 。而后端服务器权 重为2 则生成 2000 的虚拟 IP ,再 bash, 最终在 hash 环上生成 3000 个节点,从而解决 hash 环偏斜问题
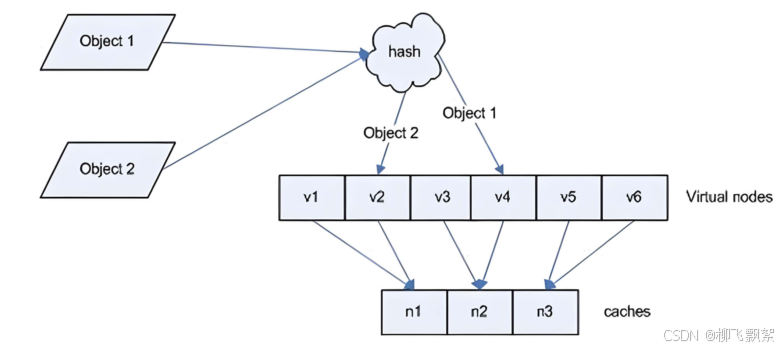
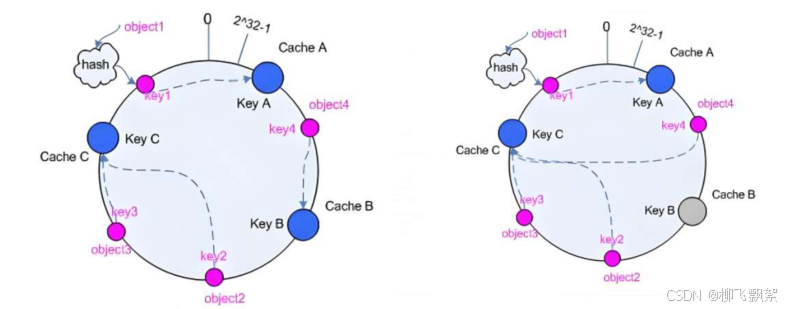
解决hash环偏斜问题
增加虚拟节点数量
首先,确定每个物理节点需要创建的虚拟节点数量。这个数量可以根据实际情况进行设定,通常会根据物理节点的数量、系统的规模和负载均衡的要求来决定。 然后,为每个物理节点生成相应数量的虚拟节点标识。这些标识可以通过在物理节点的标识基础上添加一些后缀或前缀来创建,以确保虚拟节点标识的唯一性。 接下来,计算虚拟节点的哈希值。使用与计算物理节点哈希值相同的哈希函数,对虚拟节点标识进行计算,得到对应的哈希值。 将虚拟节点的哈希值映射到一致性哈希环上。这些虚拟节点的哈希值会均匀地分布在哈希环上,从而增加了物理节点在哈希环上的“密度”。 在处理请求时,按照一致性哈希的规则,先计算请求的哈希值,然后在哈希环上顺时针查找最近的节点。由于虚拟节点的存在,请求更有可能被分配到不同的物理节点上,从而实现更均匀的负载分布。 例如,假设有 3 台物理服务器 A、B、C,决定为每台服务器创建 10 个虚拟节点。 服务器 A 的标识为 A,则生成的 10 个虚拟节点标识可以是 A-1、A-2、A-3 … A-10。 计算这些虚拟节点标识的哈希值,并映射到哈希环上。 当有新的请求到来时,计算其哈希值,在哈希环上查找最近的节点。此时,很可能会找到某个服务器 A 的虚拟节点,从而将请求分配到服务器 A 上。 通过这种方式,增加了服务器 A 在哈希环上的“存在范围”,提高了其获得请求分配的机会,使得负载能够在多台物理服务器之间更加均衡地分布。
4.3.2 uri
基于对用户请求的 URI 的左半部分或整个 uri 做 hash ,再将 hash 结果对总权重进行取模后根据最终结果将请求转发到后端指定服务器适用于后端是缓存服务器场景默认是静态算法,也可以通过 hash-type 指定 map-based 和 consistent ,来定义使用取模法还是一致性hash注意:此算法基于应用层,所以只支持 mode http ,不支持 mode tcp
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>左半部分: /<path>;<params>整个 uri : /<path>;<params>?<query>#<frag>
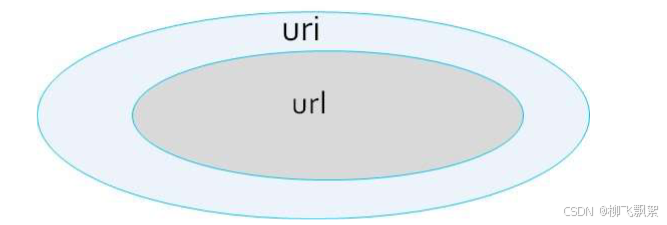
4.3.3 url_param
url_param 对用户请求的 url 中的 params 部分中的一个参数 key 对应的 value 值作 hash 计算,并由服务器总权重相除以后派发至某挑出的服务器, 后端搜索同一个数据会被调度到同一个服务器,多用与电商通常用于追踪用户,以确保来自同一个用户的请求始终发往同一个real server如果无没 key ,将按 roundrobin 算法
4.3.4 hdr
针对用户每个 http 头部 (header) 请求中的指定信息做 hash ,此处由 name 指定的 http 首部将会被取出并做 hash 计算,然后由服务器总权重取模以后派发至某挑出的服务器,如果无有效值,则会使用默认的轮询调度。
4.3.5 算法总结
# 静态static-rr--------->tcp/httpfirst------------->tcp/http# 动态roundrobin-------->tcp/httpleastconn--------->tcp/http# 以下静态和动态取决于 hash_type 是否 consistentsource------------>tcp/httpUri--------------->httpurl_param--------->httphdr--------------->http各算法使用场景first #使用较少static-rr #做了 session 共享的 web 集群roundrobin #做了 session 共享的 web 集群leastconn #数据库source #基于客户端公网IP的会话保持Uri--->http #缓存服务器, CDN 服务商,蓝汛、百度、阿里云、腾讯url_param--->http # 可以实现 session 保持hdr #基于客户端请求报文头部做下一步处理
五.高级功能及配置
5.1 基于cookie的会话保持
cookie value :为当前 server 指定 cookie 值,实现基于 cookie 的会话黏性,相对于基于 source 地址 hash调度算法对客户端的粒度更精准,但同时也加大了haproxy 负载,目前此模式使用较少, 已经被 session共享服务器代替注意:不支持 tcp mode ,使用 http mode
5.1.1 配置选项
cookie name [ rewrite | insert | prefix ][ indirect ] [ nocache ][ postonly ] [preserve ][ httponly ] [ secure ][ domain ]* [ maxidle <idle> ][ maxlife ]name : #cookie 的 key 名称,用于实现持久连接insert : # 插入新的 cookie, 默认不插入 cookieindirect : # 如果客户端已经有 cookie, 则不会再发送 cookie 信息nocache: # 当 client 和 hapoxy 之间有缓存服务器(如: CDN )时,不允许中间缓存器缓存 cookie: #因为这会导致很多经过同一个 CDN 的请求都发送到同一台后端服务器
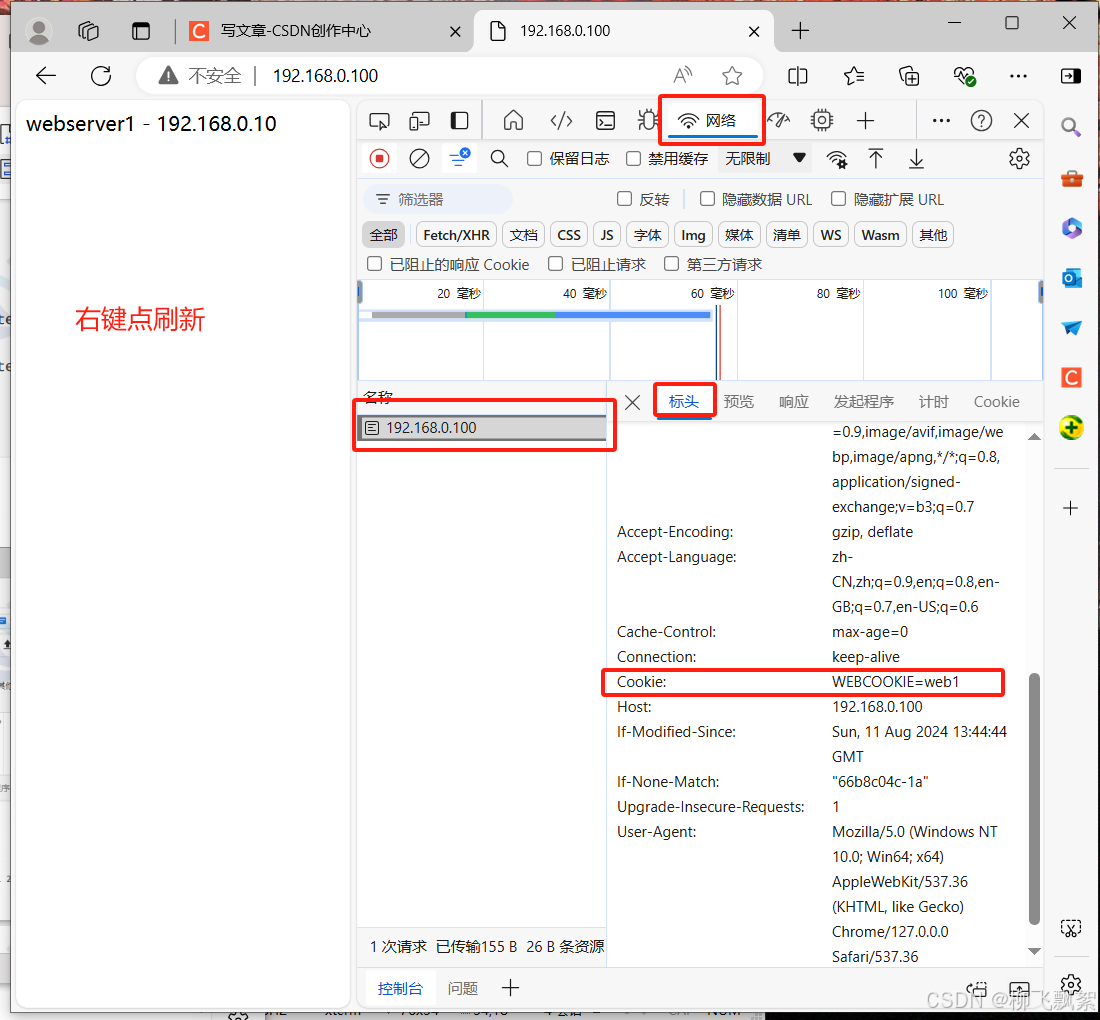
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg .......
listen webclusterbind *:80mode httpbalance roundrobincookie WEBCOOKIE insert nocache indirectserver web1 192.168.0.10:80 cookie web1 check inter 2 fall 3 rise 5 weight 2server web2 192.168.0.20:80 cookie web2 check inter 2 fall 3 rise 5 weight 1
........[root@haproxy ~]# systemctl restart haproxy.service #测试
[root@client ~]# curl -b WEBCOOKIE=web1 192.168.0.100
webserver1 - 192.168.0.10
[root@client ~]# curl -b WEBCOOKIE=web2 192.168.0.100
webserver2 - 192.168.0.20
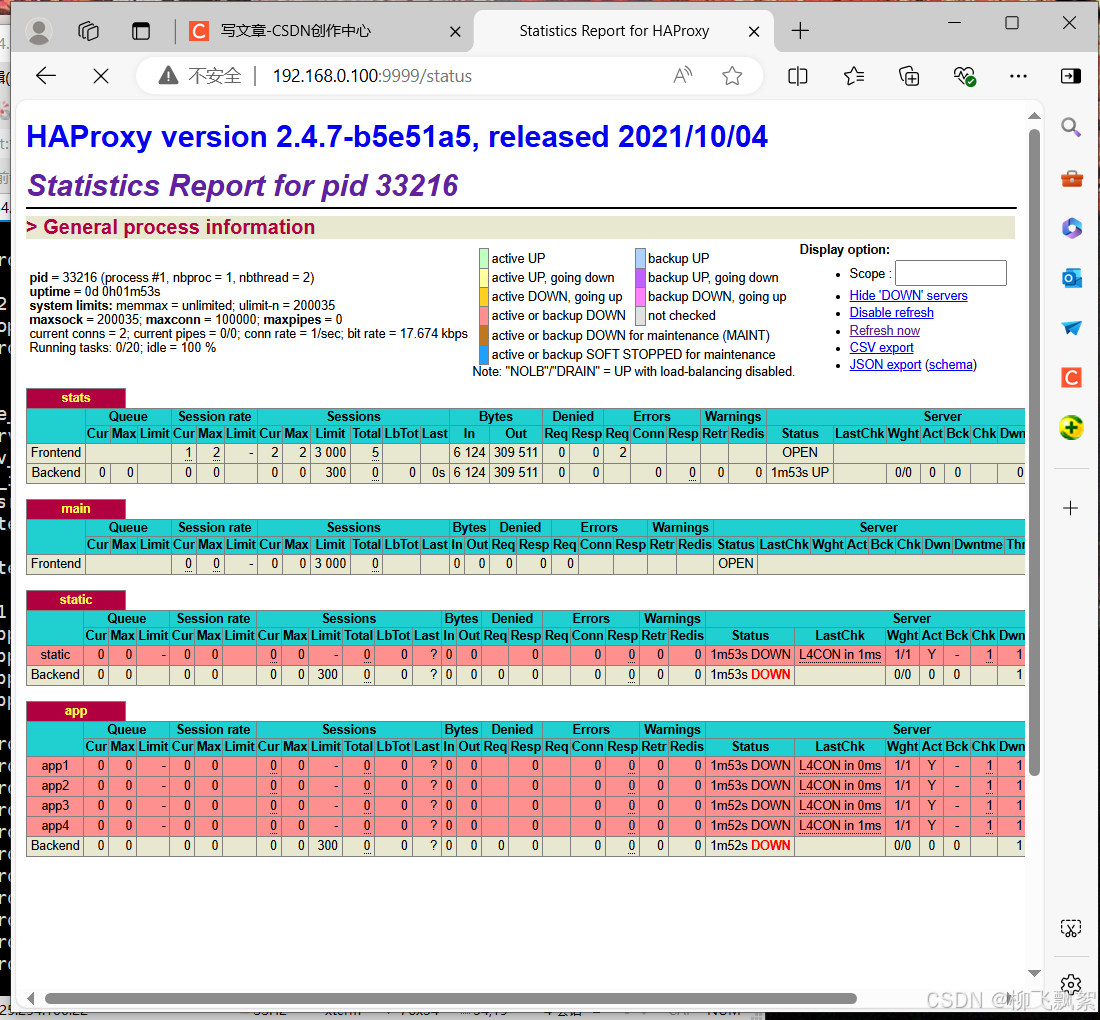
5.2 HAProxy状态页
5.2.1 状态页配置项
stats enable # 基于默认的参数启用 stats pagestats hide-version # 将状态页中 haproxy 版本隐藏stats refresh <delay> # 设定自动刷新时间间隔,默认不自动刷新stats uri <prefix> # 自定义 stats page uri ,默认值: /haproxy?statsstats auth <user>:<passwd> # 认证时的账号和密码,可定义多个用户 , 每行指定一个用户# 默认: no authenticationstats admin { if | unless } <cond> # 启用 stats page 中的管理功能
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg .....
listen statsmode httpbind *:9999stats enablestats refresh 1stats uri /statusstats auth redhat:123
.......
[root@haproxy ~]# systemctl restart haproxy.service 
浏览器测试
5.3 IP透传
IP 透传(IP Transparency)指的是在代理服务器处理请求和响应的过程中,能够将客户端的真实 IP 地址传递到后端服务器,使得后端服务器能够获取到客户端的原始 IP 而不是代理服务器的 IP 地址。web服务器中需要记录客户端的真实 IP 地址,用于做访问统计、安全防护、行为分析、区域排行等场景。
5.3.2 七层IP透传
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg
......
listen webclusterbind *:80mode httpbalance roundrobin server web1 192.168.0.10:80 check inter 2 fall 3 rise 5 weight 1 server web2 192.168.0.20:80 send-proxy check inter 2 fall 3 rise 5 weight 1[root@haproxy ~]# systemctl restart haproxy.service#webserver关闭nginx,安装httpd
[root@webserver1 ~]# systemctl stop nginx.service
[root@webserver1 ~]# systemctl disable nginx.service
[root@webserver1 ~]# yum install httpd -y
[root@webserver1 ~]# echo web1 - 192.168.0.10 > /var/www/html/index.html~
[root@webserver1 ~]# systemctl restart httpd
[root@webserver1 ~]# systemctl enable --now httpd[root@webserver1 ~]# vim /etc/httpd/conf/httpd.conf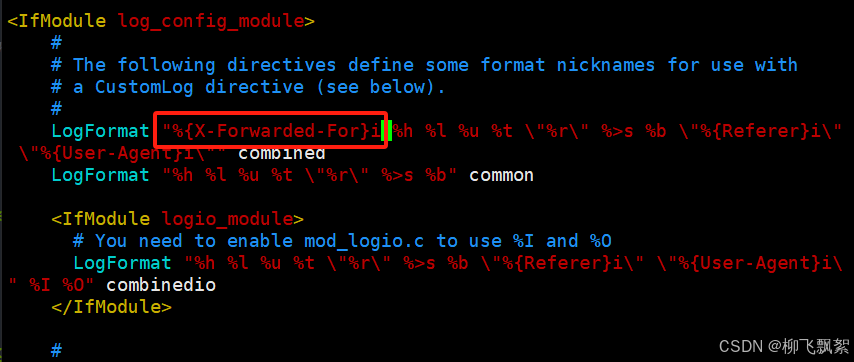
[root@webserver1 ~]# systemctl restart httpd[root@client ~]# curl 192.168.0.100
webserver1 - 192.168.0.10
[root@client ~]# curl 192.168.0.100
webserver2 - 192.168.0.20
[root@client ~]# curl 192.168.0.100
webserver1 - 192.168.0.10# 加上参数之后就可以在日志中查看客户端访问的真实IP
[root@webserver1 ~]# tail -n 5 /etc/httpd/logs/access_log
192.168.0.1 192.168.0.100 - - [12/Aug/2024:02:25:40 +0800] "GET / HTTP/1.1" 403 26 "-" "curl/7.76.1"
192.168.0.1 192.168.0.100 - - [12/Aug/2024:02:26:46 +0800] "GET / HTTP/1.1" 403 26 "-" "curl/7.76.1"
192.168.0.1 192.168.0.100 - - [12/Aug/2024:02:26:47 +0800] "GET / HTTP/1.1" 403 26 "-" "curl/7.76.1"
5.3.3 四层IP透传
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfg
......
listen webclusterbind *:80mode tcpbalance roundrobin server web1 192.168.0.10:80 check inter 2 fall 3 rise 5 weight 1 server web2 192.168.0.20:80 send-proxy check inter 2 fall 3 rise 5 weight 1[root@haproxy ~]# systemctl restart haproxy.service[root@client ~]# curl 192.168.0.100
webserver1 - 192.168.0.10
[root@client ~]# curl 192.168.0.100
webserver2 - 192.168.0.20# 此时看日志是看不到访问者的真实IP
[root@webserver1 ~]# tail -n 3 /etc/httpd/logs/access_log
- 192.168.0.100 - - [12/Aug/2024:02:37:06 +0800] "GET / HTTP/1.1" 403 26 "-" "curl/7.76.1"
- 192.168.0.100 - - [12/Aug/2024:02:37:48 +0800] "GET / HTTP/1.1" 403 26 "-" "curl/7.76.1"
- 192.168.0.100 - - [12/Aug/2024:02:37:49 +0800] "GET / HTTP/1.1" 403 26 "-" "curl/7.76.1"[root@webserver2 ~]# vim /etc/nginx/nginx.conf
# 查看日志内容[root@webserver2 ~]# tail -n 5 /var/log/nginx/access.log
192.168.0.100 - - [12/Aug/2024:03:01:49 +0800] "PROXY TCP4 192.168.0.100 192.168.0.20 47550 80" 400 0 "-" "-""-" "-"
192.168.0.100 - - [12/Aug/2024:03:01:49 +0800] "PROXY TCP4 192.168.0.100 192.168.0.20 47552 80" 400 157 "-" "-""-" "-"
192.168.0.100 - - [12/Aug/2024:03:01:49 +0800] "PROXY TCP4 192.168.0.100 192.168.0.20 47554 80" 400 0 "-" "-""-" "-"
192.168.0.100 - - [12/Aug/2024:03:01:49 +0800] "PROXY TCP4 192.168.0.100 192.168.0.20 47556 80" 400 0 "-" "-""-" "-"
192.168.0.100 - - [12/Aug/2024:03:01:49 +0800] "PROXY TCP4 192.168.0.100 192.168.0.20 47558 80" 400 0 "-" "-""-" "-"
5.4 ACL
访问控制列表 ACL , Access Control Lists )是一种基于包过滤的访问控制技术它可以根据设定的条件对经过服务器传输的数据包进行过滤 ( 条件匹配 ) 即对接收到的报文进行匹配和过滤,基于请求报文头部中的源地址、源端口、目标地址、目标端口、请求方法、URL 、文件后缀等信息内容进行匹配并执行进一步操作,比如允许其通过或丢弃
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfgfrontend webclusterbind *:80mode httpacl test hdr_dom(host) -i www.haha.orguse_backend webcluster-host if testdefault_backend default-hostbackend webcluster-hostmode httpserver web1 192.168.0.10:80 check inter 2 fall 2 rise 5backend default-hostmode httpserver web2 192.168.0.20:80 check inter 2 fall 2 rise 5[root@haproxy ~]# systemctl restart haproxy.service # 满足条件的时候访问webcluster-host,不满足条件默认访问default-host。在做这个之前记得把上面在webserver2上做的IP透传的代码给注释掉,不然访问的时候会报502的错误。在Windows上面也要做本地解析。
[root@client ~]# curl www.haha.org
webserver1 - 192.168.0.10
[root@client ~]# curl 192.168.0.100
webserver2 - 192.168.0.20
利用ACL做动静分离等访问控制
# 基于域名的访问控制
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfgfrontend webclusterbind *:80mode httpacl domain hdr_dom(host) -i www.haha.orguse_backend webcluster-host if domaindefault_backend default-hostbackend webcluster-hostmode httpserver web1 192.168.0.10:80 check inter 2 fall 2 rise 5backend default-hostmode httpserver web2 192.168.0.20:80 check inter 2 fall 2 rise 5[root@haproxy ~]# systemctl restart haproxy.service # 只有访问www.abc.org域名的时候才会去访问webserver1,否则访问webserver2
[root@client ~]# curl www.haha.org
webserver1 - 192.168.0.10
[root@client ~]# curl www.haha
webserver1 - 192.168.0.20# 基于IP的访问控制
[root@haproxy ~]# vim /etc/haproxy/haproxy.cfgfrontend webclusterbind *:80mode httpacl ctrl_ip src 192.168.0.1 192.168.0.20 192.168.0.0/24use_backend webcluster-host if ctrl_ipdefault_backend default-hostbackend webcluster-hostmode httpserver web1 192.168.0.10:80 check inter 2 fall 2 rise 5backend default-hostmode httpserver web2 192.168.0.20:80 check inter 2 fall 2 rise 5[root@haproxy ~]# systemctl restart haproxy.service # 符合条件的访问webserver1,不符合的访问webserver2
[root@client ~]# curl 192.168.0.100 #本机ip 172.25.254.10
webserver1 - 192.168.0.10
[root@webserver2 ~]# curl 192.168.0.100 #本机ip 192.168.0.20
webserver1 - 192.168.0.10相关文章:
全网超详细攻略-从入门到精通haproxy七层代理
目录 一.haproxy概述 1.1 haproxy简介 1.2 haproxy的主要特性 1.3 haproxy的优缺点 二.负载均衡介绍 2.1 什么是负载均衡 2.2 为什么用负载均衡 2.3 负载均衡类型 2.3.1 四层负载均衡 2.3.2 七层负载均衡 2.3.3 四层和七层的区别 三.haproxy的安装及服务 3.1 实验环…...
AI编程辅助工具:CodeGeeX 插件使用
CodeGeeX 插件使用 前言1.支持的平台2.安装步骤3.启用插件4.代码生成5.代码优化 前言 CodeGeeX 是一款基于 AI 技术的编程助手插件,旨在帮助开发者提高编程效率和代码质量。它能够智能生成代码、优化现有代码、自动生成文档以及回答编程相关的问题。无论您是初学者…...

sql注入实战——thinkPHP
sql注入实战——thinkPHP sql注入实战——thinkPHPthinkPHP前期环境搭建创建数据库开始寻找漏洞点输入SQL注入语句漏洞分析 实验错误 sql注入实战——thinkPHP thinkPHP前期环境搭建 下载thinkPHP文件 解压,将framework关键文件放到think-5.0.15中,改…...

MySQL 迁移 OceanBase 的 Oracle模式中,实现自增主键的方法
本文作者:赵黎明,爱可生 MySQL DBA 团队成员,熟练掌握Oracle、MySQL等数据库系统,擅长对数据库性能问题的诊断,以及事务与锁机制的分析等。负责解决客户在MySQL及爱可生自主研发的DMP平台日常运维中所遇到的各种问题&a…...

【C++ 面试 - 基础题】每日 3 题(十一)
✍个人博客:Pandaconda-CSDN博客 📣专栏地址:http://t.csdnimg.cn/fYaBd 📚专栏简介:在这个专栏中,我将会分享 C 面试中常见的面试题给大家~ ❤️如果有收获的话,欢迎点赞👍收藏&…...

ESP8266在线升级OTA固件
OTA的基本实现方式: ESP8266 的 OTA 实现有几种方式,常用的方式包括: 1、Arduino OTA:使用Arduino IDE提供的OTA功能,可以直接通过Arduino IDE上传固件到ESP8266。 2、Web OTA:ESP8266运行一个简易的Web服…...

精通C++ STL(六):list的模拟实现
目录 类及其成员函数接口总览 结点类的模拟实现 构造函数 迭代器类的模拟实现 迭代器类存在的意义 迭代器类的模板参数说明 构造函数 运算符的重载 --运算符的重载 运算符的重载 !运算符的重载 *运算符的重载 ->运算符的重载 list的模拟实现 默认成员函数 构造函数 拷贝…...

《雅思口语真经总纲1.0》话题实战训练笔记part1——6. Music
《雅思口语真经总纲1.0》笔记——第四章:口语素材大全(part1、part2、part3回答准则及练习方法,不包括范例答案)★★★★★ 文章目录 MusicWhen do you listen to music?20240804答评价注意事项1、在说到“no music”时ÿ…...

Python之赋值语句(多重赋值和交换赋值)
这是《Python入门经典以解决计算问题为导向的Python编程实践》73-74页关于赋值的内容。讲了Python中几种赋值方式。 赋值语句 1、最简单的赋值:ab2、多重赋值:a,b,c1,2,33、交换:a,bb,a 1、最简单的赋值:ab b可以是数字、字符串…...

网络协议七 应用层 HTTP 协议
应用层常见的协议 HTTP协议 1. 如何查看我们的http 协议全部的内容有哪些呢? 一种合理的方法是 通过 wireshark 软件,找到想要查看的HTTP --->追踪流--->HTTP流 来查看 结果如下:红色部分 为 发送给服务器的,蓝色部分为服务…...

uniapp vue 在适配百度小程序平台动态:style
uniapp vue 在适配百度小程序平台动态:style踩坑报错Unexpected string concatenation of literals 抖快平台动态style写法基本是 <view :style"{width: 686rpx, height: (setHeight 96) rpx}"> </view>这种写法在百度上会又解析报错: Une…...
 Kruskal 算法)
【最小生成树】(二) Kruskal 算法
题目: 寻宝 题目描述 在世界的某个区域,有一些分散的神秘岛屿,每个岛屿上都有一种珍稀的资源或者宝藏。国王打算在这些岛屿上建公路,方便运输。 不同岛屿之间,路途距离不同,国王希望你可以规划建公路的方案…...

haproxy最强攻略
1、负载均衡 负载均衡(Load Balance,简称 LB)是高并发、高可用系统必不可少的关键组件,目标是 尽力将网络流量平均分发到多个服务器上,以提高系统整体的响应速度和可用性。 负载均衡的主要作用如下: 高并发…...

XetHub 加入 Hugging Face!
我们非常激动地正式宣布,Hugging Face 已收购 XetHub 🔥 XetHub 是一家位于西雅图的公司,由 Yucheng Low、Ajit Banerjee 和 Rajat Arya 创立,他们之前在 Apple 工作,构建和扩展了 Apple 的内部机器学习基础设施。XetH…...

在编程学习的海洋中,如何打造高效的知识宝库
目录 在编程学习的海洋中,如何打造高效的知识宝库一、笔记记录的重要性:为知识设立灯塔二、快速记录的策略:抓住知识的核心三、系统化的整理:构建个人知识体系四、实用工具推荐:为知识管理添砖加瓦五、保持条理性的秘诀…...

string详解(1)
1.C语言中的字符串 C语言中,字符串是以\0结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理&…...

Linux云计算 |【第二阶段】NETWORK-DAY4
主要内容: NAT 原理与配置(私有IP地址、静态NAT转换、Easy IP)、VRRP解析(主路由器、备份路由器、虚拟路由器、优先级) 一、NAT概述 NAT 网络地址转换(Network Address Translation)是一种网络…...

amazon linux使用密码登录或者root登陆
1. 首先要把创建root密码,如果原来的密码不记得了,可以直接用 sudo passwd -d root 删除原来的密码 然后创建root密码 sudo passwd root 2. 修改 sshd_config 文件 vim /etc/ssh/sshd_config 允许使用密码登录 PasswordAuthentication yes 允许root…...

集智书童 | CNN 与 Transformer 的强强联合:AResNet-ViT在图像分析中的优势 !
本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。 原文链接:CNN 与 Transformer 的强强联合:AResNet-ViT在图像分析中的优势 ! 作者针对残差CNN分支的注意力引导设计进行了消融实验。同时&a…...

Ubuntu基础使用指南
Ubuntu基础使用指南 Ubuntu作为一款流行的开源操作系统,以其稳定性、安全性和易用性著称。无论是作为服务器操作系统还是桌面操作系统,Ubuntu都能满足用户的各种需求。下面,我们将从Ubuntu的基础使用开始,带你深入了解这个强大的…...

Claude in Excel:原生集成的AI表格协作者
1. 项目概述:这不是插件,是Excel里长出来的AI同事“Claude in Excel”这个标题刚看到时,我下意识点开几个技术社区翻了一圈,发现多数人第一反应是:“又一个AI插件?”——其实完全不是。它根本没走传统Offic…...

FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程
FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程 【免费下载链接】fceux FCEUX, a NES Emulator 项目地址: https://gitcode.com/gh_mirrors/fc/fceux FCEUX是一款功能强大的开源NES模拟器,让你在现代电脑上完美重温经典红白机游戏。无论…...

论文创新点像挤牙膏?导师强推这几个AI论文平台
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

FM3773 低功耗离线式恒流/恒压 PSR 控制器
概述 FM3773 是一种高性能的交流/直流用于电池充电器和适配器的电源控制器,内置 850V 功率三极管。该设备采用脉冲频率调制(PFM)的方法来建立非连续导通模式(DCM)反激式电源。 FM3773 提供精确的恒定电压,恒…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

rk35xx 通过recovery升级问题
Firefly 的 recovery 库是一个核心组件,它构建了一个独立的微型 Linux 系统,专门用于在设备主系统之外执行高可靠性的固件升级。简单来说,它的工作流程是:主系统通过命令触发,将升级指令写入特定分区并重启;…...

sngan_projection论文解读:ICLR2018两大GAN技术的完美结合
sngan_projection论文解读:ICLR2018两大GAN技术的完美结合 【免费下载链接】sngan_projection GANs with spectral normalization and projection discriminator 项目地址: https://gitcode.com/gh_mirrors/sn/sngan_projection sngan_projection是一个实现了…...
)
手把手教你用Mind+和Blynk,让手机轻松遥控掌控板(含自建服务器避坑指南)
从零搭建物联网控制平台:Mind与Blynk深度整合实战 当你第一次尝试用手机控制硬件设备时,那种"隔空取物"的奇妙感总会让人兴奋不已。想象一下,躺在沙发上就能调节书桌上的智能台灯亮度,或者在外出时随时查看家中的温湿度…...
)
【2025】AWVS安装保姆级教程(最新25.1.2可用)
【2025】AWVS安装保姆级教程(最新25.1.2可用) 文章目录 工具下载Host 重定向AWVS安装AWVS查看安装失败原因 工具下载 点击下载即可 下载完的工具后缀格式为.apk,需要将其改为.zip,然后将其解压得到以下工具后续安装使用 Host 重…...

Claude Agent SDK 从 0 到 1 快速上手教程
Claude Agent SDK 从 0 到 1 快速上手教程 什么是 Claude Agent SDK? Claude Agent SDK 是 Anthropic 官方推出的用于构建 AI 智能体的开发工具包。它基于 Claude Code 构建,让开发者能够以编程方式创建、扩展和定制由 Claude 驱动的应用程序。与简单的聊天机器人不同,基于…...