【0基础学爬虫】爬虫基础之网络请求库的使用

大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶、逆向相关文章,为实现从易到难全方位覆盖,特设【0基础学爬虫】专栏,帮助小白快速入门爬虫,本期为网络请求库的使用。
网络请求库概述
作为一名爬虫初学者,熟练使用各种网络请求库是一项必备的技能。利用这些网络请求库,我们可以通过非常简单的操作来进行各种协议的模拟请求。我们不需要深入底层去关注如何建立通信与数据如何传输,只需要调用各种网络请求库封装好的方法。Python提供了很多功能强大的网络请求库,如urllib、requests、httpx、aiohttp、websocket等,下文中会对这些库做一一介绍。
urllib
安装与介绍
安装
urllib是Python的内置请求库,不需要再额外安装。
介绍
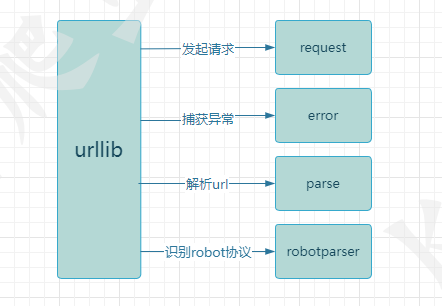
urllib库包含四个模块:
urllib.request: 向目标url发起请求并读取响应信息。
urllib.error: 负责异常处理,捕获urllib.request抛出的异常。
urllib.parse: 解析url,提供了一些url的解析方法。
urllib.robotparser: 解析网站robots.txt文件,判断网站是否允许爬虫程序进行采集。
使用方法
请求与响应
使用到了urllib.request模块中的urlopen方法来打开一个url并获取响应信息。urlopen默认返回的是一个HTTPResponse对象,可以通过read方法得到它的明文信息。
import urllib.requestresponse = urllib.request.urlopen('http://httpbin.org/get')print(response) #打印:<http.client.HTTPResponse object at 0x0000013D85AE6548>
print(response.read().decode('utf-8')) #响应信息
print(response.status) #返回状态码
print(response.getheaders()) #返回响应头信息设置请求头与参数
当请求需要设置请求头时,就需要用到urllib.request模块中的另一个方法Request,它允许传递如下几个参数:
def __init__(self, url, data=None, headers={},origin_req_host=None, unverifiable=False,method=None)url:目标url
data:请求参数,默认为None
headers:请求头信息,字典类型
origin_req_host:请求的主机地址
unverifiable:设置网页是否需要验证
method:请求方式
from urllib import request,parseurl = 'https://httpbin.org/post' #目标URL
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
} #请求头信息
params = {'test':'test01' #请求参数
}data = bytes(parse.urlencode(params),encoding='utf-8') #解析为bytes类型
res = request.Request(url,data=data,headers=headers,method='POST') #实例化Request
response = request.urlopen(res) #发起请求print(response.read().decode('utf-8')) #响应信息异常捕获
在发起请求时,可能会因为网络、url错误、参数错误等问题导致请求异常,程序报错。为了应对这种情况,我们需要添加异常处理功能。
from urllib import request,errortry:response = request.urlopen('http://httpbin.org/get')
except error.HTTPError as e: #捕获异常print(e) #打印异常信息requests
requests是Python爬虫开发中最常使用到的库,它提供了简单易用的API,使得在Python中发送HTTP请求变得非常容易,它比urllib模块更加简洁,使用更加方便。
安装与介绍
安装
requests是Python的第三方库,使用 pip install requests 进行安装
介绍
requests包含了许多模块,这里只介绍主要模块:
requests: 主模块,提供了HTTP请求方法。
requests.session: 会话模块,提供了Session类,用于多个请求中共享请求信息。
requests.adapters: 适配器模块,提供了不同协议的适配器类,用于处理不同协议的请求。
requests.cookie: Cookie模块,用于处理cookie信息。
requests.exceptions: 异常处理模块,用于处理请求中会出现的各种异常。
requests.status_codes: 状态码模块,提供了HTTP状态码常量和状态码解释。
使用方法
请求与响应
import requests #导入requests模块get_response = requests.get('http://httpbin.org/get') #发送get请求
post_response = requests.post('http://httpbin.org/post') #发送post请求print(get_response) #<Response [200]>
print(post_response) #<Response [200]>requests库发送请求非常简单,并支持多种请求方式,如:get、post、put、delete等。发起请求后requests会返回一个Response对象,可以使用多种方法来解析Response对象。
import requestsresponse = requests.get('http://httpbin.org/get')print(response.status_code) #返回响应状态码
print(response.encoding) #返回响应信息的编码
print(response.text) #返回响应的文本信息
print(response.content) #返回响应的字节信息
print(response.json()) #将JSON响应信息解析为字典,如果响应数据类型不为JSON则会报错
print(response.headers) #返回响应头信息
print(response.cookies) #返回响应cookie设置请求头与参数
request(self,method,url,params=None,data=None,headers=None,cookies=None,files=None,auth=None,timeout=None,allow_redirects=True,proxies=None,hooks=None,stream=None,verify=None,cert=None,json=None)requests中设置请求头可以通过headers参数来设置,headers是一个字典类型,键为请求头的字段名,值为对应请求头的值。
请求参数可以通过params方法进行设置,类型为字典。键为参数名,值为对应参数的值。
在网络请求中,携带的参数可以分为两个类型,它们在python中对应的字段名如下:
查询字符串参数: params
请求载荷: data/json
查询字符串参数params是拼接在url中的参数,常用于get请求,作为查询参数使用。而data与json一般使用与post请求中,它是要发送到服务器的实际数据。
import requestsheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}params = {'key':'value'}
data = {'username':'user','passowrd':'password'}get_response = requests.get(url,params=params,headers=headers)
post_response = requests.post(url,data=data,headers=headers)Session的使用
当一个网站我们需要多次请求时,如我需要登录 -> 请求个人页面,在面对这种场景时,我们可以使用到Session方法。因为通过requests发送到的请求是独立,我们请求登录接口与请求个人页面之间是没有联系的,我们需要请求登录接口后获取它返回的cookie,然后设置cookie进行下一次请求。每次请求后都需要设置一次cookie,如果请求流程更多的话那么过程就会显得很繁琐。使用Session方法就能更好的模拟一次请求流程,不需要频繁的设置cookie。
Session的作用类似于浏览器中的cookie与缓存,它可以用于在多次请求中维护一些状态信息,避免重复发送相同的信息和数据,使用Session可以优化HTTP请求的性能与可维护性,它的使用也非常简单。
import requestssession = requests.Session() #创建session对象
session.get('http://httpbin.org/cookies/set/username/test') #发起请求,模拟一次登录
response = session.get('http://httpbin.org/cookies') #获取cookieprint(response.text) #{"cookies": {"username": "test"}}异常捕获
requests.exceptions 中提供了一系列请求异常。
ConnectTimeout:连接超时
ReadTimeout:服务器在指定时间内没有应答
ConnectionError:未知的服务器
ProxyError:代理异常
URLRequired:无效URL
TooManyRedirects:重定向过多
MissingSchema:URL缺失,如缺少:http/https
InvalidSchema:提供的URL方案无效或不受支持
InvalidURL:提供的URL不知何故无效
InvalidHeader:提供的请求头无效
InvalidProxyURL:提供的代理URL无效
ChunkedEncodingError:服务器声明了编码分块,但发送了无效分块
ContentDecodingError:无法对响应信息解码
StreamConsumedError:此响应内容已被使用
RetryError:自定义重试逻辑错误
UnrewindableBodyError:请求在尝试倒带正文时遇到错误
HTTPError:出现HTTP错误
SSLError:发生SSL错误
Timeout:请求超时
httpx
前面讲到了requests库,它功能强大、使用简单,并且提供session会话模块,似乎requests库已经可以满足所有的应用场景了。但是requests也有一些致命的缺点:
- 同步请求,不支持异步,requests默认使用同步请求,在网络请求中同步请求到导致性能问题。
- 不支持HTTP2.0,如今已经有少部分网站采用HTTP2.0协议来进行数据传输,面对这类网站无法使用requests。
而httpx是一个基于异步IO的Python3的全功能HTTP客户端库,旨在提供一个快速、简单、现代化的HTTP客户端,它提供同步与异步API,而且支持HTTP1.1和HTTP2.0。并且httpx功能也很齐全,requests支持的功能httpx也基本同样支持。因此,在爬虫开发中使用httpx也是一个非常不错的选择。
安装与介绍
安装
httpx是Python的第三方库,使用 pip install httpx 进行安装
如果需要httpx支持https2.0,则需要安装它的可选依赖项, pip install httpx[http2]
介绍
httpx是建立在requests的成熟可用性之上的,提供的模块与requests大同小异,因此不做介绍。
使用方法
httpx用法与requests基本一致,这里主要介绍httpx的Client实例。
httpx Client
Client作用与requests的session方法一致,但用法有些区别。
常见用法是使用上下文管理器,这样可以确保在请求完成后能够正确清理连接。
import httpxwith httpx.Client() as client:response = client.get('https://httpbin.org/get')print(response) #<Response [200 OK]>在设置请求头、传递参数时也有新的写法。
import httpxheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
params = {'key':'value'}with httpx.Client(headers=headers,params=params) as client:response = client.get('https://httpbin.org/get')print(response)aiohttp
aiohttp是基于Python异步IO的HTTP客户端/服务器库,它与httpx相似,同样支持HTTP1.1和HTTP2.0协议,aiohttp是基于asyncio实现的,它支持WebSocket协议。
安装
aiohttp是Python的第三方库,使用 pip install aiohttp 进行安装
使用
import aiohttp
import asyncioasync def main():async with aiohttp.ClientSession() as session:async with session.get('https://httpbin.org/get') as response:print(response) #<ClientResponse(https://httpbin.org/get) [200 OK]>loop = asyncio.get_event_loop()
loop.run_until_complete(main())aiohttp不支持同步,需要与asyncio一起使用,与前文中讲到的库对比,aiohttp显得异常复杂,requests两行代码就能完成的功能aiohttp却需要5行。为什么aiohttp代码如此冗余我们却要使用它呢?因为aiohttp是异步的,它的api旨在充分利用非阻塞网络操作,在实例代码中,请求将阻塞三次,这为事件循环提供了三次切换上下文的机会。aiohttp可以实现单线程并发IO操作,它在处理大量网站请求时的速度远超于requests,但在涉及到文件读写操作时,它发挥的作用就没有预期的那么大,因此aiohttp库的使用需要爬虫开发者自行斟酌。
websocket
Python websocket库是专门用于创建WebSocket服务的库。WebSocket是一种在客户端与服务端之间进行双向通信的协议,服务端可以向客户端推送数据,客户端也可以向服务端推送数据,这样就能实现数据的及时通信,它与HTTP协议一样,由socket实现。WebSocket通常使用在直播、弹幕等场景中。
安装
websocket是Python的内置库,不需要手动安装。当你在运行下文中的实例时,如果报错cannot import name 'WebSocketApp' from 'websocket',你可以卸载现有的websocket库,安装websocket-client==0.53.0版本的包。
使用
websocket用于客户端与服务端通信,爬虫开发中一般只会进行客户端的开发,所有这里只介绍客户端的开发。
使用WebSocketApp可以快速的建立一个Websocket连接。
from websocket import WebSocketAppdef on_message(ws, message): #接收到消息时执行print(message)
def on_error(ws, error): #异常时执行print(error)
def on_close(ws): #关闭连接时执行print("WebSocket closed")
def on_open(ws): #开启连接时执行ws.send("Hello, WebSocket!") #发送信息if __name__ == "__main__":ws = WebSocketApp("ws://echo.websocket.org/",on_message=on_message,on_error=on_error,on_close=on_close)ws.on_open = on_openws.run_forever()可以看到websocket提供了四个模块:
on_message: 接收服务器推送来的数据
on_error: 连接异常时会触发on_error
on_close: 连接关闭时触发on_close
on_open: 连接开启时触发on_open
归纳
上文中讲到了urllib、requests、httpx、aiohttp、websocket这五个库的使用,这五个库基本能够满足爬虫开发中的请求需求。urllib是python的内置库,使用起来较为繁琐,可以只做了解。requests是爬虫开发中最常使用的库,功能齐全,使用简单,需要认真学习。httpx在requests的基础上支持异步处理、HTTP2.0与Websocket协议,requests的功能httpx都支持,但在性能方面httpx弱于其他请求库,httpx也需要爬虫初学者好好学习。aiohttp用于编写异步爬虫,开发效率低于其它库,但是执行效率远高与其它库,也是一个需要好好掌握的请求库。websocket是专门用于Websocket协议的库,使用也较为简单,可以在需要时再做了解。 
相关文章:
【0基础学爬虫】爬虫基础之网络请求库的使用
大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶、逆向相关文章,为实现从易到难全方位覆盖,特设【0基础学…...
超级实用,解密云原生监控技术,使用prometheus轻松搞定redis监控
前言 大家好,我是沐风晓月,本文收录于《 prometheus监控系列》 ,截止目前prometheus专栏已经更新到第8篇文章。 本文中的是prometheus已经安装好,如果你还未安装,可以参考 prometheus安装及使用入门 若你想监控其他…...

音视频开发—MediaCodec 解码H264/H265码流视频
使用MediaCodec目的 MediaCodec是Android底层多媒体框架的一部分,通常与MediaExtractor、MediaMuxer、AudioTrack结合使用,可以编码H264、H265、AAC、3gp等常见的音视频格式 MediaCodec工作原理是处理输入数据以产生输出数据 MediaCodec工作流程 Med…...

CVPR 2023|淘宝视频质量评价算法被顶会收录
近日,阿里巴巴大淘宝技术题为《MD-VQA: Multi-Dimensional Quality Assessment for UGC Live Videos》—— 适用于无参考视频质量评价的最新研究成果被计算机视觉领域顶级会议IEEE/CVF Computer Vision and Pattern Recognition Conference 2023(CVPR 20…...

【C++学习】继承
🐱作者:一只大喵咪1201 🐱专栏:《C学习》 🔥格言:你只管努力,剩下的交给时间! C是面向对象的编程语言,它有很多的特性,但是最重要的就是封装,继承…...

【03173】2020年8月高等教育自学考试-软件开发工具
一、单项选择题:1. 区别于一般软件,对软件开发工具而言,下列各项最重要的性能是 A. 效率 B. 响应速度C. 资源消耗 D. 使用方便2. 在软件开发过程的信息需求中,属于跨开发周期的信息是A. 有关系统环境的需求信息 B. 有关软件设计的…...

Java中的String类
String类1.String类1.1 特性1.2 面试题1.3 常用方法1.4 String与其他类型之间的转换2. StringBuilder类、StringBuffer类:可变字符序列1.String类 1.1 特性 String类为final类,不可被继承,代表不可变的字符序列; 实现了Serializ…...
【java】笔试强训Day3【在字符串中找出连续最长的数字串与数组中出现次数超过一半的数字】
目录 ⛳选择题 1.以下代码运行输出的是 2.以下程序的输出结果为 3.下面关于构造方法的说法不正确的是 ( ) 4.在异常处理中,以下描述不正确的有( ) 5.下列描述中,错误的是( ) 6.…...

一文7个步骤从0到1教你搭建Selenium 自动化测试环境
【导语】Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。本文详细介绍了搭建自动化测试环境所需的工具,让你学习自动化测试不…...

Oracle目录应急清理
Oracle目录应急清理清理错误位置的归档日志清理30天前的监听告警日志清理监听日志清理30天以前的trace文件清理30天以前的审计日志清理错误位置的归档日志 检查$ORACLE_HOME/dbs下是否有归档文件: ls $ORACLE_HOME/dbs/arch* | wc -l检查和修改归档位置࿱…...
使用 OBS 进行区域录制
1. OBS 与区域录屏 实际上 OBS 的使用场景可谓是与区域录屏格格不入的。 虽然我们依旧有一些办法在 OBS 中达到区域录屏的目的,但其操作实在过于繁琐,还不如直接使用 QQ 或者 Windows 最新的自带截屏录屏来进行区域录屏来的方便实在。 但若非常强烈的…...

aws eks 配置授权额外的用户和角色访问集群
参考资料 https://github.com/kubernetes-sigs/aws-iam-authenticator#full-configuration-formathttps://docs.amazonaws.cn/zh_cn/eks/latest/userguide/add-user-role.html 众所周知,aws eks使用 Authenticator 或者 aws 命令来进行账户级别的用户和角色的授权…...

MagicalCoder可视化开发平台:轻松搭建业务系统,为企业创造更多价值
让软件应用开发变得轻松起来,一起探索MagicalCoder可视化开发工具的魔力!你是否为编程世界的各种挑战感到头痛?想要以更高效、简单的方式开发出专业级的项目?MagicalCoder低代码工具正是你苦心寻找的产品!它是一款专为…...
8个不能错过的程序员必备网站,惊艳到我了!!!
程序员是一个需要不断学习的职业,不少朋友每天来逛CSDN、掘金等网站,但一直都抱着“收藏从未停止,学习从未开始”的态度,别骗自己了兄弟。在编程体系中,有很多不错的小工具,可以极大得提升我们的开发效率。…...
:实现“增删改查”)
Mybatis(二):实现“增删改查”
Mybatis(二):实现“增删改查”前言一、MyBatis的增删改查1、添加2、修改3、删除4、查询4.1 查询一个实体4.1 查询集合二、MyBatis获取参数值的两种方式(重点)1、单个字面量类型的参数2、多个字面量类型的参数3、map集合…...

Faster RCNN 对血液细胞目标检测
目录 1. 介绍 2. 工具函数介绍 utils 2.1 xml 文件的读取 get_label_from_xml 2.2 绘制边界框 draw_bounding_box...
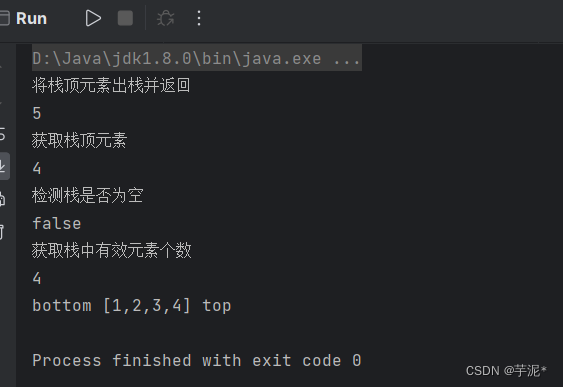
【数据结构】Java实现栈
目录 1. 概念 2. 栈的使用 3. 自己动手实现栈(使用动态数组实现栈) 1. 创建一个MyStack类 2. push入栈 3. pop出栈 4. 查看栈顶元素 5. 判断栈是否为空与获取栈长 6. toString方法 4. 整体实现 4.1 MyStack类 4.2 Test类 4.3 测试结果 1.…...
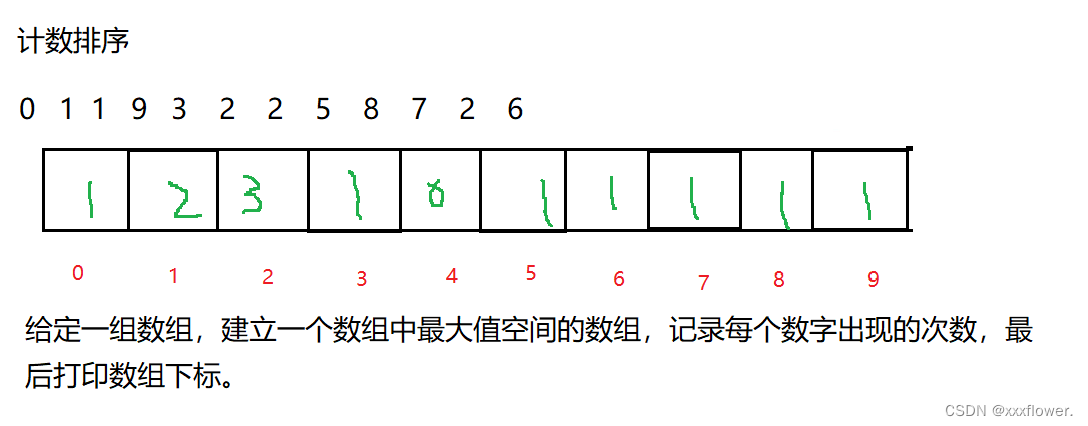
【数据结构】排序
作者:✿✿ xxxflower. ✿✿ 博客主页:xxxflower的博客 专栏:【数据结构】篇 语录:⭐每一个不曾起舞的日子,都是对生命的辜负。⭐ 文章目录1.排序1.1排序的概念1.2常见的排序算法2.常见排序算法2.1插入排序2.1.1直接插入…...

过拟合、验证集、交叉验证
过拟合 简单描述:训练集误差小,测试集误差大,模型评估指标的方差(variance)较大; 判断方式: 1、观察 train set 和 test set 的误差随着训练样本数量的变化曲线。 2、通过training accuracy 和…...

原力计划来了【协作共赢 成就未来】
catalogue🌟 写在前面🌟 新星计划持续上新🌟 原力计划方向🌟 原力计划拥抱优质🌟 AIGC🌟 参加新星计划还是原力计划🌟 创作成就未来🌟 写在最后🌟 写在前面 哈喽&#x…...

储能出海架构重构:摒弃传统x86工控机,基于ARM边缘节点的EMS策略下沉实战
摘要: 随着储能系统在全球范围的大规模部署,出海项目的硬件BOM成本压力与恶劣环境下的维护成本日益凸显。传统的“x86工控机下发控制 透传网关上传数据”的双体架构显得极度臃肿且易引发单点故障。本文从底层研发架构师视角出发,深度拆解符合…...

终极Markdown Viewer浏览器扩展完整指南:打造高效文档阅读环境
终极Markdown Viewer浏览器扩展完整指南:打造高效文档阅读环境 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer Markdown Viewer是一款功能强大的浏览器扩展࿰…...

VideoDownloadHelper深度解析:破解主流视频平台下载限制的技术实战
VideoDownloadHelper深度解析:破解主流视频平台下载限制的技术实战 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存…...

Nintendo Switch大气层系统:7步从零安装到精通优化完整指南
Nintendo Switch大气层系统:7步从零安装到精通优化完整指南 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 想要彻底释放你的Nintendo Switch游戏机潜力吗?Atmosphe…...

StofDoctrineExtensionsBundle的IpTraceable扩展:自动记录用户IP地址的简单实现指南 [特殊字符]
StofDoctrineExtensionsBundle的IpTraceable扩展:自动记录用户IP地址的简单实现指南 🚀 【免费下载链接】StofDoctrineExtensionsBundle Integration bundle for DoctrineExtensions by l3pp4rd in Symfony 项目地址: https://gitcode.com/gh_mirrors/…...

从混淆矩阵到mIOU:手把手解析语义分割核心评价指标
1. 从像素战场到成绩单:理解混淆矩阵 第一次接触语义分割任务时,我盯着那些五彩斑斓的分割图直发懵——怎么判断这个模型到底好不好?直到导师扔给我一张"混淆矩阵"的表格,才恍然大悟这就像学生时代的考试成绩单。想象你…...

芯片低功耗设计:从动态/静态功耗原理到DVFS与电源门控实战
1. 从“功耗”到“能效”:一个芯片工程师的视角在半导体行业摸爬滚打了十几年,我越来越深刻地体会到,芯片设计早已不是单纯追求性能的“百米冲刺”,而是一场关于“能效”的马拉松。性能决定了你的芯片能跑多快,而功耗则…...

从QR码到汉信码:除了日本标准,国产二维码在哪些场景更牛?
从QR码到汉信码:国产技术如何重新定义二维码应用边界 在数字化浪潮席卷全球的今天,二维码已成为连接物理世界与数字世界的隐形桥梁。当我们习惯性地掏出手机扫描各种黑白方块时,很少有人意识到这些看似简单的图案背后,隐藏着一场关…...

企者不立,跨者不行,在 SAP ABAP 开发里修一颗不踮脚、不跨步、不自矜的工程心
老子这句话放进 SAP ABAP 开发现场里,不是要我们把工程做得玄乎,也不是劝开发者不要进取。它讲的是一种很朴素的稳定性智慧,凡是靠踮脚维持的高度,站不久,凡是靠大跨步抢出来的进度,走不远,凡是只相信自己眼前判断的技术方案,容易看不清系统全貌,凡是过度相信自己经验…...

互联网音频播放器技术演进与Xilinx可编程逻辑应用
1. 互联网音频播放器的技术演进与市场背景2000年初,互联网音频播放器市场正处于爆发式增长的前夜。当时最引人注目的产品当属Diamond Multimedia推出的Rio PMP-300便携式MP3播放器,这款设备彻底改变了人们获取和欣赏音乐的方式。作为第一代互联网音频硬件…...