爬虫架构(一):爬虫中的去重处理
目录
- 一、概要
- 二、去重应用场景以及基本原理
- 2.1 爬虫中什么业务需要使用去重
- 2.2 去重实现的基本原理
- 2.3 根据原始数据进行去重判断
- 2.4 根据原始数据的特征值进行去重判断
- 2.5 临时去重容器与持久化去重容器
- 2.6 常用几种特殊的原始数据特征值计算
- 三、基于信息摘要算法的去重
- 3.1 信息摘要 hash 算法介绍
- 3.2 信息摘要 hash 算法去重方案实现
- 3.3 基于 simhash 算法的去重
- 3.3.1 Simhash 介绍以及应用场景
- 3.3.2 Simhash 的特征
- 3.3.3 Simhash 值得比对
- 3.3.4 示例代码
- 四、布隆过滤器原理与实现
- 4.1 布隆过滤器 (bloomfilter) 原理
- 4.2 布隆过滤器实现
一、概要
- 去重应用场景以及基本原理
- 基于信息摘要算法的去重
- 基于 simhash 算法的去重
- 布隆过滤器原理与实现
二、去重应用场景以及基本原理
2.1 爬虫中什么业务需要使用去重
- 防止发出重复的请求
- 防止存储重复的数据
2.2 去重实现的基本原理
根据给定的 判断依据 和给定的 去重容器,将原始数据逐一进行判断,判断去重容器中是否有该数据。如果没有那就把该数据对应的判断依据添加去重容器中,同时标记该数据是不重复数据;如果有就不添加,同时标记该数据是重复数据。
重点:
- 判断依据(原始数据、原始数据特征值)
- 去重容器(存储判断数据) set()
2.3 根据原始数据进行去重判断

2.4 根据原始数据的特征值进行去重判断
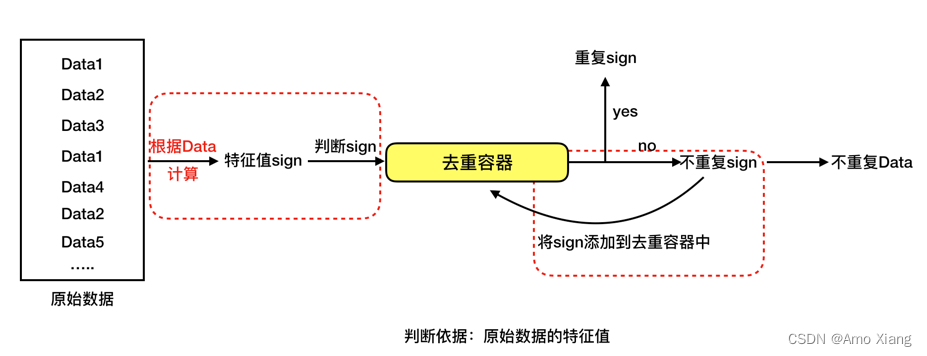
思考:为什么要用原始数据的特征值进行判断?
理解:1、节省存储空间 2、比对更加快捷高效
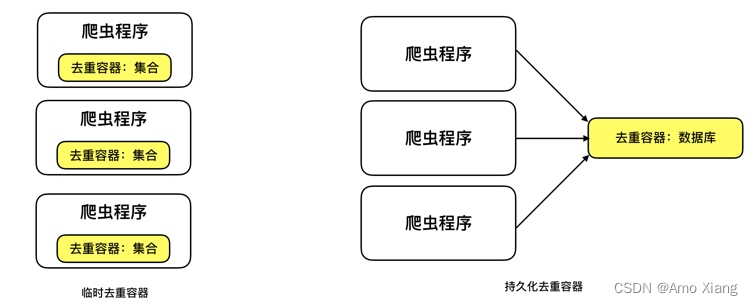
2.5 临时去重容器与持久化去重容器
临时去重容器:指如利用 list、set 等编程语言的数据结构存储去重数据,一旦程序关闭或重启后,去重容器中的数据就被回收了。使用与实现简单方便;但无法共享、无法持久化。
持久化去重容器指如利用 redis、mysql 等数据库存储去重数据。持久化、共享;但使用与实现相对复杂
2.6 常用几种特殊的原始数据特征值计算
- 信息摘要 hash 算法(指纹)
- SimHash 算法
- 布隆过滤器方式
三、基于信息摘要算法的去重
3.1 信息摘要 hash 算法介绍
信息摘要 hash 算法指可以将任意长度的文本、字节数据,通过一个算法得到一个固定长度的文本。如 MD5(128位)、SHA1(160位) 等。
特征:只要源文本不同,计算得到的结果,必然不同(摘要)。 摘要:摘要算法主要用于比对信息源是否一致,因为只要源发生变化,得到的摘要必然不同;而且通常结果要比源短很多,所以称为
摘要。正因此,利用信息摘要算法能大大降低去重容器的存储空间使用率,并提高判断速度,直由于其强唯—性的特征,几乎不存在误判。
注意: hash 算法得出的结果其实本质上就是一串数值,如 md5 的128位指的是二进制的长度,十六进制的长度是32位。一个十六进制等于四个二进制。
3.2 信息摘要 hash 算法去重方案实现
基类的实现:
# 基于信息摘要算法进行数据的去重判断和存储# 1. 基于内存的存储
# 2. 基于redis的存储
# 3. 基于mysql的存储import hmacclass BaseFilter(object):'''基于信息摘要算法进行数据的去重判断和存储'''def __init__(self,digest_mod="MD5",redis_host="localhost",redis_port=6379,redis_db=0,redis_key="filter",mysql_url=None,mysql_table_name="filter"):self.redis_host = redis_hostself.redis_port = redis_portself.redis_db = redis_dbself.redis_key = redis_keyself.mysql_url = mysql_urlself.mysql_table_name = mysql_table_name# self.key =self.digest_mod = digest_modself.storage = self._get_storage()def _safe_data(self, data):''':param data: 给定的原始数据:return: 二进制类型的字符串数据'''if isinstance(data, bytes):return dataelif isinstance(data, str):return data.encode()else:raise Exception("please provide a string...")def _get_hash_value(self, data):'''根据给定的数据,返回的对应信息摘要hash值:param data: 给定的原始数据(二进制类型的字符串数据):return: hash值'''data = self._safe_data(data)key = 'amoxiang666'.encode("utf8")hash_obj = hmac.new(key, data, digestmod=self.digest_mod)hash_value = hash_obj.hexdigest()return hash_valuedef save(self, data):'''根据data计算出对应的指纹进行存储:param data: 给定的原始数据:return: 存储的结果'''hash_value = self._get_hash_value(data)return self._save(hash_value)def _save(self, hash_value):'''存储对应的hash值(交给对应的子类去继承):param hash_value: 通过信息摘要算法求出的hash值:return: 存储的结果'''passdef is_exists(self, data):'''判断给定的数据对应的指纹是否存在:param data: 给定的原始数据:return: True or False'''hash_value = self._get_hash_value(data)return self._is_exists(hash_value)def _is_exists(self, hash_value):'''判断对应的hash值是否已经存在(交给对应的子类去继承):param hash_value: 通过信息摘要算法求出的hash值:return: 判断的结果(True or False)'''passdef _get_storage(self):'''返回对应的一个存储对象(交给对应的子类去继承):return:'''passfrom .mysql_filter import MySQLFilter
from .memory_filter import MemoryFilter
from .redis_filter import RedisFilter
普通内存版本:
# 基于python中的 集合数据结构进行去重判断依据的存储
from . import BaseFilterclass MemoryFilter(BaseFilter):'''基于python中的 集合数据结构进行去重判断依据的存储'''def _get_storage(self):return set()def _save(self, hash_value):'''利用set进行存储:param hash_value::return:'''return self.storage.add(hash_value)def _is_exists(self, hash_value):if hash_value in self.storage:return Truereturn False
Redis 持久化版:
# 基于redis的持久化存储的去重判断依据的实现
import redisfrom . import BaseFilterclass RedisFilter(BaseFilter):'''基于redis的持久化存储的去重判断依据的实现'''def _get_storage(self):'''返回一个redis连接对象'''pool = redis.ConnectionPool(host=self.redis_host, port=self.redis_port, db=self.redis_db)client = redis.StrictRedis(connection_pool=pool)return clientdef _save(self, hash_value):'''利用redis的无序集合进行存储:param hash_value::return:'''return self.storage.sadd(self.redis_key, hash_value)def _is_exists(self, hash_value):'''判断redis对应的无序集合中是否有对应的判断依据'''return self.storage.sismember(self.redis_key, hash_value)
MySQL 持久化版本:
# 基于mysql的去重判断依据的存储from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_basefrom . import BaseFilterBase = declarative_base()class MySQLFilter(BaseFilter):'''基于mysql的去重判断依据的存储'''def __init__(self, *args, **kwargs):self.table = type(kwargs["mysql_table_name"],(Base,),dict(__tablename__=kwargs["mysql_table_name"],id=Column(Integer, primary_key=True),hash_value=Column(String(40), index=True, unique=True)))BaseFilter.__init__(self, *args, **kwargs)def _get_storage(self):'''返回一个mysql连接对象(sqlalchemy的数据库连接对象)'''engine = create_engine(self.mysql_url)Base.metadata.create_all(engine) # 创建表、如果有就忽略Session = sessionmaker(engine)return Sessiondef _save(self, hash_value):'''利用redis的无序集合进行存储:param hash_value::return:'''session = self.storage()filter = self.table(hash_value=hash_value)session.add(filter)session.commit()session.close()def _is_exists(self, hash_value):'''判断redis对应的无序集合中是否有对应的判断依据'''session = self.storage()ret = session.query(self.table).filter_by(hash_value=hash_value).first()session.close()if ret is None:return Falsereturn True
测试:
# python3
from information_summary_filter import MemoryFilter
from information_summary_filter import RedisFilter
from information_summary_filter import MySQLFilter# filter = MemoryFilter()
# filter = RedisFilter(redis_key="test1")
mysql_url = "mysql+pymysql://root:123456@127.0.0.1:3306/db_admin?charset=utf8"
filter = MySQLFilter(mysql_url=mysql_url, mysql_table_name="test20230319")data = ["111", "qwe", '222', "333", "111", "qwe", "中文", "qwer"]for d in data:if filter.is_exists(d):print("发现重复的数据: ", d)else:filter.save(d)print("保存去重的数据:", d)
3.3 基于 simhash 算法的去重
3.3.1 Simhash 介绍以及应用场景
Simhash 算法是一种局部敏感哈希算法,能实现 相似 文本内容的去重。比如下列两篇新闻数据:

3.3.2 Simhash 的特征
与信息摘要算法的区别:
- 信息摘要算法:如果原始内容只相差一个字节,所产生的签名也很可能差别很大。
- Simhash 算法:如果原始内容只相差一个字节,所产生的签名差别非常小。
Simhash 值比对:通过两者的 simhash 值的二进制位的差异来表示原始文本内容的差异。差异个数又被称为 海明距离。
注意:Simhash 对长文本
500字+比较适用,短文本可能偏差较大。在google的论文给出的数据中,64位simhash值,在海明距离为3的情况下,可认为两篇文档是相似的或者是重复的。当然这个值只是参考值,针对自己的应用可能有不同的测试取值。
3.3.3 Simhash 值得比对
Python 实现的 simhash 算法。该模块得出的 simhash 值长度正是64位。https://github.com/leonsim/simhash
如对比前面列出的人民网和中国网的两篇相似新闻(以下值仅供参考)。128位MD5值:

64位simhash值:

3.3.4 示例代码
import re
from simhash import Simhash, SimhashIndexdef get_features(s):width = 3s = s.lower()s = re.sub(r'[^\w]+', '', s)return [s[i:i + width] for i in range(max(len(s) - width + 1, 1))]data = {"key1": u'How are you? I Am fine. blar blar blar blar blar Thanks.',"key2": u'How are you i am fine. blar blar blar blar blar than',"key3": u'This is simhash test.',"4": u'How are you i am fine. blar blar blar blar blar thank'
}
objs = [(str(k), Simhash(get_features(v))) for k, v in data.items()
]
print(objs)
index = SimhashIndex(objs, k=4) # k相当于海明距离print(index.bucket_size()) # 11s1 = Simhash(get_features(u'How are you i am fine. blar blar blar blar blar thank'))
print(index.get_near_dups(s1)) # ['1']index.add('4', s1)
print(index.get_near_dups(s1)) # ['4', '1']# 二进制位的比对 只能在内存中进行
# 序列化工具: 将一个对象转换为二进制的一个数据
# 反序列化:二进制--> 对象
四、布隆过滤器原理与实现
4.1 布隆过滤器 (bloomfilter) 原理
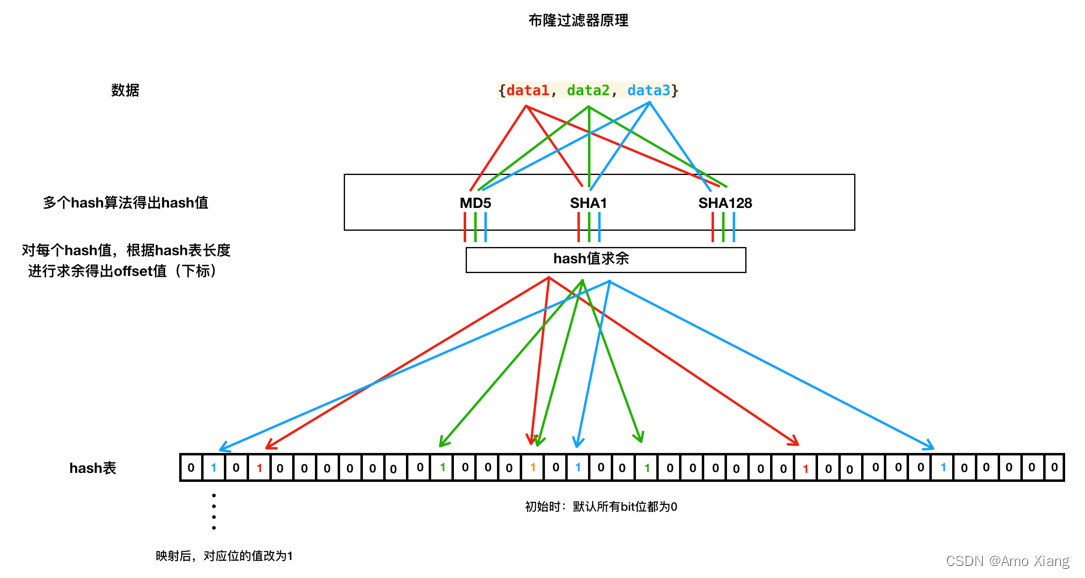
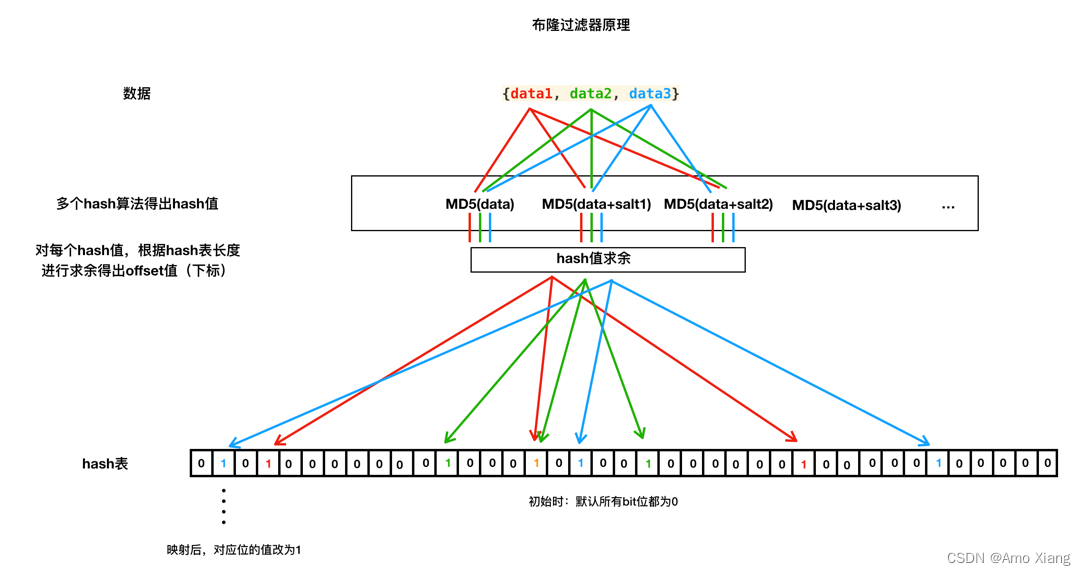
4.2 布隆过滤器实现
Python 实现的内存版布隆过滤器 pybloom,参考地址:https://github.com/jaybaird/python-bloomfilter
手动实现的 redis 版布隆过滤器,示例代码如下:
# -*- coding: utf-8 -*-
# @Time : 2023-03-23 23:28
# @Author : AmoXiang
# @File : test.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680# 布隆过滤器 redis版本实现
import hashlibimport redis
import six# 1. 多个hash函数的实现和求值
# 2. hash表实现和实现对应的映射和判断class MultipleHash(object):'''根据提供的原始数据,和预定义的多个salt,生成多个hash函数值'''def __init__(self, salts, hash_func_name="md5"):self.hash_func = getattr(hashlib, hash_func_name)if len(salts) < 3:raise Exception("please give three salt at least....")self.salts = saltsdef get_hash_values(self, data):'''根据提供的原始数据, 返回多个hash函数值'''hash_values = []for i in self.salts:hash_obj = self.hash_func()hash_obj.update(self._safe_data(data))hash_obj.update(self._safe_data(i))ret = hash_obj.hexdigest()hash_values.append(int(ret, 16))return hash_valuesdef _safe_data(self, data):''':param data: 给定的原始数据:return: 二进制类型的字符串数据'''if isinstance(data, bytes):return dataelif isinstance(data, str):return data.encode()else:raise Exception("please give string....") # 建议使用英文来描述class BloomFilter(object):def __init__(self, salts, redis_host="localhost", redis_port=6379, redis_db=0, redis_key="bloomfilter"):self.redis_host = redis_hostself.redis_port = redis_portself.redis_db = redis_dbself.redis_key = redis_keyself.client = self._get_redis_client()self.multiple_hash = MultipleHash(salts)def _get_redis_client(self):'''返回一个redis连接对象'''pool = redis.ConnectionPool(host=self.redis_host, port=self.redis_port, db=self.redis_db)client = redis.StrictRedis(connection_pool=pool)return clientdef save(self, data):''''''hash_values = self.multiple_hash.get_hash_values(data)for hash_value in hash_values:offset = self._get_offset(hash_value)self.client.setbit(self.redis_key, offset, 1)return Truedef is_exists(self, data):hash_values = self.multiple_hash.get_hash_values(data)for hash_value in hash_values:offset = self._get_offset(hash_value)v = self.client.getbit(self.redis_key, offset)if v == 0:return Falsereturn Truedef _get_offset(self, hash_value):# 2**8 = 256# 2**20 = 1024 * 1024# (2**8 * 2**20 * 2*3) 代表hash表的长度 如果同一项目中不能更改return hash_value % (2 ** 8 * 2 ** 20 * 2 * 3)if __name__ == '__main__':data = ["asdfasdf", "123", "123", "456", "asf", "asf"]bm = BloomFilter(salts=["1", "2", "3", "4"], redis_host="172.17.0.2")for d in data:if not bm.is_exists(d):bm.save(d)print("映射数据成功: ", d)else:print("发现重复数据:", d)
相关文章:
爬虫架构(一):爬虫中的去重处理
目录一、概要二、去重应用场景以及基本原理2.1 爬虫中什么业务需要使用去重2.2 去重实现的基本原理2.3 根据原始数据进行去重判断2.4 根据原始数据的特征值进行去重判断2.5 临时去重容器与持久化去重容器2.6 常用几种特殊的原始数据特征值计算三、基于信息摘要算法的去重3.1 信…...

算法刷题总结 (二) 回溯与深广搜算法
算法总结2 回溯与深广搜算法一、理解回溯算法1.1、回溯的概念1.2、回溯法的效率1.3、回溯法问题分类1.4、回溯法的做题步骤二、经典问题2.1、组合问题2.1.1、77. 组合 - 值不重复2.1.2、216.组合总和III - 值不重复且等于目标值2.1.3、17. 电话号码的字母组合 - 双层回溯2.1.4、…...

Linux 总结9个最危险的命令,一定要牢记在心!
rm -rf 命令 该命令可能导致不可恢复的系统崩坏。 rm -rf / #强制删除根目录下所有东西。 rm -rf * #强制删除当前目录的所有文件。 rm -rf . #强制删除当前文件夹及其子文件夹。 执行rm -rf 一定要想半天,搞明白自己在干什么. fork 炸弹 😦) { 😐:&am…...
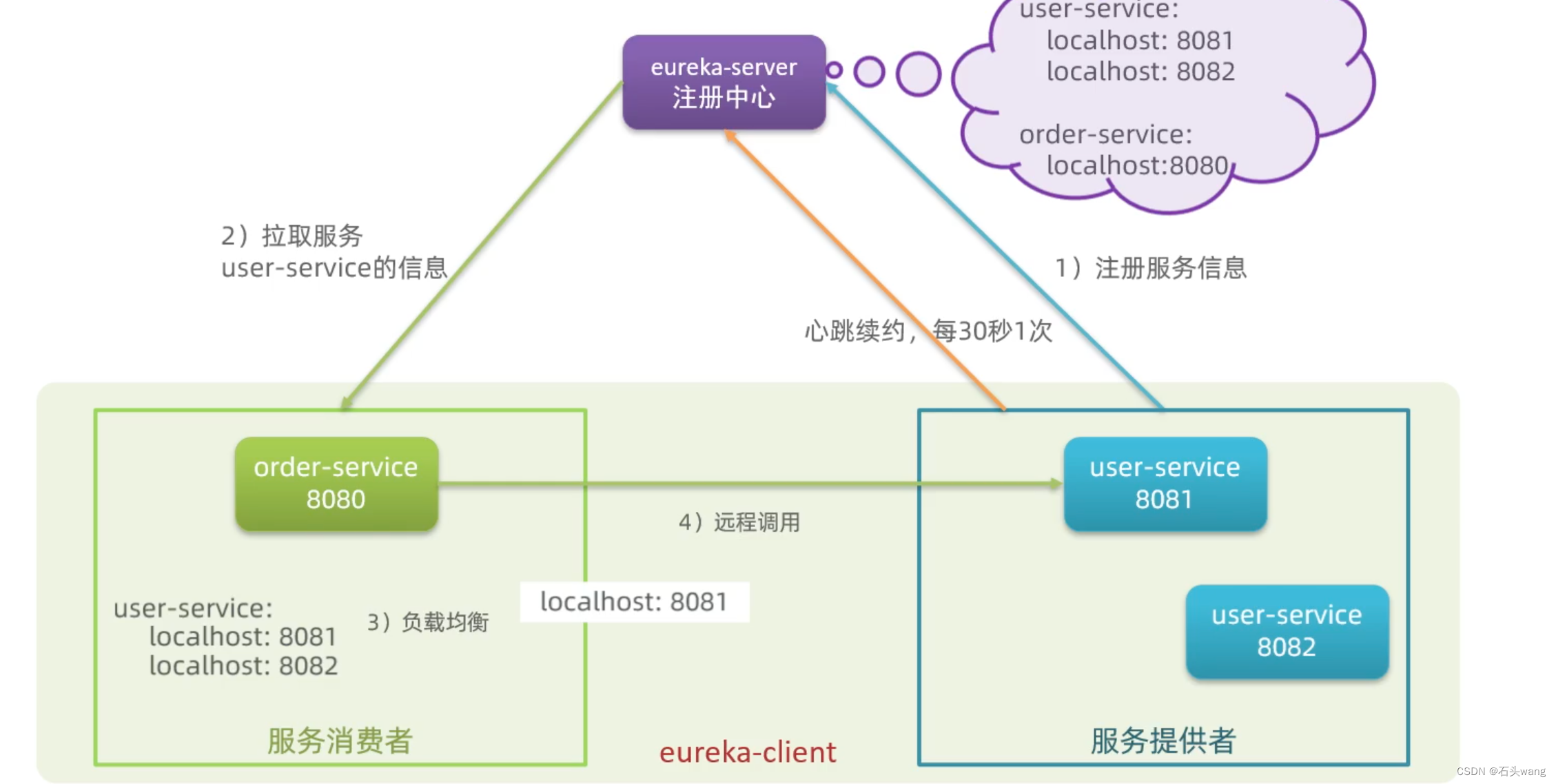
spring cloud
spring cloud 分享 springboot:可以说是spring cloud的基础,是springMVC框架的简化,约定大于配置(在使用上、非功能上的简化) 可以说每个MPO Digital api就是springboot project(springboot项目) spring cloud…...

【9】核心易中期刊推荐——图像视觉与图形可视化
🚀🚀🚀NEW!!!核心易中期刊推荐栏目来啦 ~ 📚🍀 核心期刊在国内的应用范围非常广,核心期刊发表论文是国内很多作者晋升的硬性要求,并且在国内属于顶尖论文发表,具有很高的学术价值。在中文核心目录体系中,权威代表有CSSCI、CSCD和北大核心。其中,中文期刊的数…...

0108Bean销毁-Bean生命周期详解-spring
Bean使用阶段,调用getBean()得到bean之后,根据需要,自行使用。 1 销毁Bean的几种方式 调用org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#destroyBean调用org.springframework.beans.factory.config.Conf…...

微信小程序可以进行dom操作吗?
小程序不能使用各种浏览器暴露出来的 DOM API,进行 DOM 选中和操作 原因:在小程序中,渲染层和逻辑层是分开的,分别运行在不同的线程中,逻辑层运行在 JSCore 中,并没有一个完整浏览器对象,因而缺…...

昇腾AI深耕沽上:港口辐射力之后,天津再添基础创新辐射力
作者 | 曾响铃 文 | 响铃说 AI计算正在以新基建联动产业集群的方式,加速落地。 不久前,天津市人工智能计算中心正式揭牌,该中心整体规划300P算力,2022年底首批100P算力上线投入运营,并实现上线即满载。 这是昇腾AI…...
基于YOLOv5的疲劳驾驶检测系统(Python+清新界面+数据集)
摘要:基于YOLOv5的疲劳驾驶检测系统使用深度学习技术检测常见驾驶图片、视频和实时视频中的疲劳行为,识别其闭眼、打哈欠等结果并记录和保存,以防止交通事故发生。本文详细介绍疲劳驾驶检测系统实现原理的同时,给出Python的实现代…...

【Linux】-- 进程优先级和环境变量
目录 进程的优先级 基本概念 如何查看优先级 PRI与NI NI值的设置范围 NI值如何修改 修改方式一 : 通过top指令修改优先级 修改方式二 : 通过renice指令修改优先级 进程的四个重要概念 环境变量 基本概念 常见的环境变量 查看环境变量 三种…...
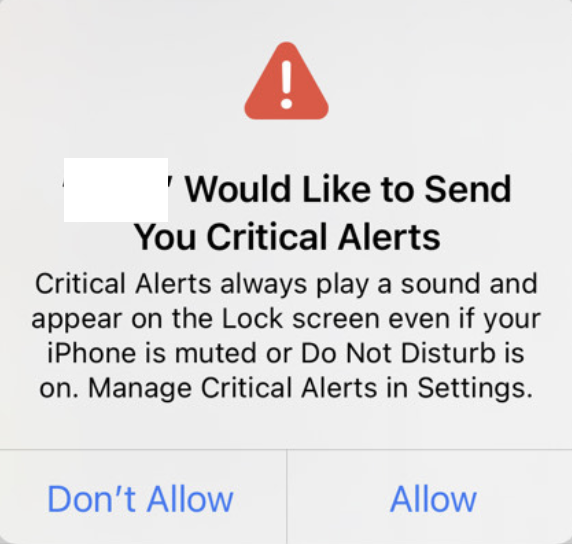
iOS 紧急通知
一般通知 关于通知的各种配置和开发,可以参考推送通知教程:入门 – Kodeco,具有详细步骤。 紧急通知表现 紧急通知不受免打扰模式和静音模式约束。当紧急通知到达时,会有短暂提示音量和抖动(约2s)。未锁…...

即时零售:不可逆的进化
“人们经常问我,这个世界还是平的吗?我经常跟他们说,亲爱的,它真的是平的,比以前更平了。”2021年3月,《世界是平的》作者托马斯弗里德曼在演讲时说。如他所说,尽管逆全球化趋势加剧,…...

零售数据总结经验:找好关键分析指标和维度
各位数据的朋友,大家好,我是老周道数据,和你一起,用常人思维数据分析,通过数据讲故事。 每逢月末、季末、年终,运营部门的同事又要开始进行年终总结分析。那么,对零售连锁企业来说,…...
从零开始搭建游戏服务器 第一节 创建一个简单的服务器架构
目录引言技术选型正文创建基础架构IDEA创建项目添加Netty监听端口编写客户端进行测试总结引言 由于现在java web太卷了,所以各位同行可以考虑换一个赛道,做游戏还是很开心的。 本篇教程给新人用于学习游戏服务器的基本知识,给新人们一些学习…...

C++中那些你不知道的未定义行为
引子 开篇我们先看一个非常有趣的引子: // test.cpp int f(long *a, int *b) {*b 5;*a 1;return *b; }int main() {int x 10;int *p &x;auto q (long *)&x;auto ret f(q, p);std::cout << x << std::endl;std::cout << ret <&…...
)
java基础面试题(四)
Mysql索引的基本原理 索引是用来快速寻找特定的记录;把无序的数据变成有序的查询把创建索引的列数据进行排序对排序结果生成倒排表在倒排表的内容上拼接上地址链在查询时,先拿到倒排表内容,再取出地址链,最后拿到数据聚簇索引和非…...

@PropertySource使用场景
文章目录一、简单介绍二、注解说明1. 注解源码① PropertySource注解② PropertySources注解2. 注解使用场景3. 使用案例(1)新增test.properties文件(2)新增PropertySourceConfig类(3)新增PropertySourceTe…...

【C语言进阶:刨根究底字符串函数】strtok strerror函数
本节重点内容: 深入理解strtok函数的使用深入理解strerror函数的使用⚡strtok Returns a pointer to the first occurrence of str2 in str1, or a null pointer if str2 is not part ofstr1sep参数是个字符串,定义了用作分隔符的字符集合。第一个参数指…...

西安石油大学C语言期末重点知识点总结
大一学生一周十万字爆肝版C语言总结笔记 是我自己在学习完C语言的一次总结,尽管会有许多的瑕疵和不足,但也是自己对C语言的一次思考和探索,也让我开始有了写作博客的习惯和学习思考总结,争取等我将来变得更强的时候再去给它优化出…...

读《Multi-level Wavelet-CNN for Image Restoration》
Multi-level Wavelet-CNN for Image Restoration:MWCNN摘要一. 介绍二.相关工作三.方法摘要 存在的问题: 在低级视觉任务中,对于感受野尺寸与效率之间的平衡是一个关键的问题;普通卷积网络通常以牺牲计算成本去扩大感受野&#…...

抖音视频无水印下载:3分钟快速上手免费工具完整指南
抖音视频无水印下载:3分钟快速上手免费工具完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...

终极鼠标革命:如何用Mac Mouse Fix让你的普通鼠标超越苹果触控板体验
终极鼠标革命:如何用Mac Mouse Fix让你的普通鼠标超越苹果触控板体验 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 还在为macOS上…...

宝塔面板登录教程
1买个服务器2连接ssh-宝塔或者xshell都行3在xshell下载宝塔面板4在服务器主页--在哪里订购的就在有个管理点进去-加入安全组或者添加nat转发。如果不行用bt命令重置端口号再访问,最后重置之后重启一下-bt 15使用nat转发的要用外网端口,宝塔显示的是内网的…...

别再用示波器死磕了!用Python+RC积分电路,5分钟搞定充放电曲线模拟与可视化
别再用示波器死磕了!用PythonRC积分电路,5分钟搞定充放电曲线模拟与可视化 在电子工程实践中,RC积分电路的充放电特性分析是基础中的基础。传统方法往往依赖示波器观测,不仅耗时耗力,还受限于硬件条件。今天ÿ…...

Flutter × Harmony6.0 打造高颜值优惠商城页面:跨端 UI 构建与组件化实践
Flutter Harmony6.0 打造高颜值优惠商城页面:跨端 UI 构建与组件化实践 前言 随着 HarmonyOS NEXT 与 Harmony6.0 生态逐渐成熟,越来越多开发者开始关注 Flutter 在鸿蒙平台上的跨端落地能力。相比传统 Android/iOS 双端分别维护的开发模式,…...

44《实车CAN总线报文ID含义与数据初步解读》
001、CAN总线基础与实车网络拓扑概述 从一次凌晨三点的“丢帧”说起 去年冬天,某主机厂的新能源车型在做冬季标定。凌晨三点,测试工程师打来电话,语气里带着疲惫和焦躁:“VCU发的车速信号,BMS偶尔收不到,但用CANoe监控又一切正常。”我赶到现场,第一件事不是看代码,而…...

WinForm + Modbus 上位机温湿度数据采集系统
前言工业自动化和环境监控领域,实时掌握现场的温湿度数据至关重要。传统的监控方式往往依赖人工记录或简单的报警装置,缺乏直观性和连续性。本文推荐一个基于WinForm开发的上位机温湿度采集系统,通过Modbus通信协议与下位机进行数据交互&…...

system24高级功能探索:透明背景、模糊效果和自定义窗口控制
system24高级功能探索:透明背景、模糊效果和自定义窗口控制 【免费下载链接】system24 a tui-style discord theme 项目地址: https://gitcode.com/gh_mirrors/sy/system24 system24是一款tui风格的Discord主题,它通过简约的设计和强大的自定义功…...

把轻量接口做成真正可用的业务入口,聊透 ABAP HTTP Service Editor 的开发节奏
做 ABAP 集成时,经常会碰到这样一类需求,外部系统只想调用一个很轻的 URL,拿一段文本、一个健康检查结果、一个简单的回调响应,或者把某个小型业务动作推到 ABAP 后端里。这个时候,很多人脑子里冒出来的还是 RAP、Service Binding、Gateway,甚至直接跳到 SICF 手工找节点…...

PIC18F4550微控制器实现USB大容量存储设备设计
1. USB大容量存储设备设计概述USB大容量存储设备(Mass Storage Device,MSD)已成为现代数字生活中不可或缺的组成部分。从U盘到移动硬盘,这类设备的核心都是基于USB Mass Storage Class协议实现的。本文将深入探讨如何利用PIC18F45…...