Mapreduce_csv_averageCSV文件计算平均值
csv文件求某个平均数据
查询每个部门的平均工资,最后输出
数据处理过程

employee_noheader.csv(没做关于首行的处理,运行时请自行删除)
EmployeeID,EmployeeName,DepartmentID,Salary
1,ZhangSan,101,5000
2,LiSi,102,6000
3,WangWu,101,5500
4,ZhaoLiu,103,7000
5,SunQi,102,6500
- pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.hadoop</groupId><artifactId>Mapreduce_csv_average</artifactId><version>1.0-SNAPSHOT</version><name>Mapreduce_csv_average</name><description>wunaiieq</description><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><!--版本控制--><hadoop.version>2.7.3</hadoop.version></properties><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-yarn-api</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-streaming</artifactId><version>${hadoop.version}</version></dependency></dependencies><!--构建配置--><build><plugins><plugin><!--声明--><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.3.0</version><!--具体配置--><configuration><archive><manifest><!--jar包的执行入口--><mainClass>com.hadoop.Main</mainClass></manifest></archive><descriptorRefs><!--描述符,此处为预定义的,表示创建一个包含项目所有依赖的可执行 JAR 文件;允许自定义生成jar文件内容--><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><!--执行配置--><executions><execution><!--执行配置ID,可修改--><id>make-assembly</id><!--执行的生命周期--><phase>package</phase><goals><!--执行的目标,single表示创建一个分发包--><goal>single</goal></goals></execution></executions></plugin></plugins></build></project>- Map_1
package com.hadoop;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;public class Map_1 extends Mapper<LongWritable, Text,IntWritable,IntWritable> {@Overrideprotected void map(LongWritable k1, Text v1, Context context)throws IOException, InterruptedException {//处理输入数据,类型转换//以 1,ZhangSan,101,5000 为例String data =v1.toString();//分词操作,csv用","进行分割//一般而言,分词操作大多使用String进行获取,后面可以附跟类型转换String[] words =data.split(",");//下文输出context.write(//K2:部门号输出new IntWritable(Integer.parseInt(words[2])),//K3:工资输出new IntWritable(Integer.parseInt(words[3])));}
}- Reduce_1
package com.hadoop;import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.io.IntWritable;
import java.io.IOException;
public class Reduce_1 extends Reducer<IntWritable,IntWritable,IntWritable,IntWritable>{@Overrideprotected void reduce(IntWritable k3, Iterable<IntWritable> v3, Context context)throws IOException, InterruptedException {//对v3进行求和,计算总额int total=0;int i=0;for (IntWritable v:v3){total+= v.get();i++;}int average=total/i;context.write(k3,new IntWritable(average));}
}- Main
package com.hadoop;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class Main {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {Job job = Job.getInstance(new Configuration());job.setJarByClass(Main.class);//mapjob.setMapperClass(Map_1.class);job.setMapOutputKeyClass(IntWritable.class);//k2job.setMapOutputValueClass(IntWritable.class);//v2//reducejob.setReducerClass(Reduce_1.class);job.setOutputKeyClass(IntWritable.class);job.setOutputValueClass(IntWritable.class);//输入和输出FileInputFormat.setInputPaths(job,new Path(args[0]));FileOutputFormat.setOutputPath(job,new Path(args[1]));//执行job.waitForCompletion(true);}
}- 运行
请自行上传至hdfs中
hadoop jar Mapreduce_average.jar /input/employee_noheader.csv /output/csv_average
- 效果
hdfs dfs -cat /output/csv_average/part-r-00000

相关文章:
Mapreduce_csv_averageCSV文件计算平均值
csv文件求某个平均数据 查询每个部门的平均工资,最后输出 数据处理过程 employee_noheader.csv(没做关于首行的处理,运行时请自行删除) EmployeeID,EmployeeName,DepartmentID,Salary 1,ZhangSan,101,5000 2,LiSi,102,6000…...

将UEC++项目转码成UTF-8
方法一 如果文件不多的话,可以手动一个一个进行修改。添加 “高级保存选项” 手动改为UTF-8 方法二 使用editorconfig文件,统一编码问题。通过:“工具” > “选项”>"文本编辑器" > "C/C" > "代码样式…...

深入探索MySQL C API:使用C语言操作MySQL数据库
目录 引言 一. MySQL C API简介 二. MySQL C API核心函数 2.1 初始化和连接 2.2 配置和执行 2.3 处理结果 2.4 清理和关闭 2.5 错误处理 三. MySQL使用过程 四. 实现CRUD操作 4.1 创建数据库并建立表 编辑 4.2 添加数据(Create) 编辑 …...

武汉流星汇聚:亚马逊助力跨境电商扬帆起航,海外影响力显著提升
在全球化浪潮的推动下,跨境电商已成为连接世界市场的重要桥梁。而在这场跨越国界的商业盛宴中,亚马逊作为全球电商的领军者,以其独特的商业模式、庞大的用户基础,为无数企业提供了前所未有的发展机遇。武汉流星汇聚电子商务有限公…...

C语言:设计模式
C语言和设计模式(总结篇) 书籍:《大话设计模式》 2、C语言和设计模式:原型模式(复制自己,生成另外一个实例对象) 17、C语言实现面向对象编程 : 封装、继承、多态 ---- C语言可:封…...

Pandas数据选择的艺术:深入理解loc和iloc
在数据科学领域,Pandas是处理和分析数据的瑞士军刀。掌握Pandas中的数据选择技巧,尤其是loc和iloc的使用,对于提高数据处理效率至关重要。本文将深入探讨loc和iloc的用法,通过丰富的示例,帮助你精确地选取所需的数据&a…...

<数据集>固定视角监控牧场绵羊识别数据集<目标检测>
数据集格式:VOCYOLO格式 图片数量:3615张 标注数量(xml文件个数):3615 标注数量(txt文件个数):3615 标注类别数:1 标注类别名称:[Sheep] 序号类别名称图片数框数1Sheep361529632 使用标注工具&#…...

浙大数据结构慕课课后题(06-图2 Saving James Bond - Easy Version)(拯救007)
题目要求: This time let us consider the situation in the movie "Live and Let Die" in which James Bond, the worlds most famous spy, was captured by a group of drug dealers. He was sent to a small piece of land at the center of a lake fi…...
:npn 和yarn ,pnpm安装依赖都是从那个源安装的啊,有啥优缺点呢)
前置(1):npn 和yarn ,pnpm安装依赖都是从那个源安装的啊,有啥优缺点呢
在使用 npm、yarn 或 pnpm 进行依赖管理和安装时,它们通常默认从 npm 的公共仓库(https://registry.npmjs.org/)获取包。不过,用户可以配置它们以从其他源获取,例如企业内部的私有仓库或镜像站点(如淘宝的 …...
视频融合项目中的平台抉择:6大关键要素助力精准选型
随着安防监控系统行业的快速发展,视频融合项目逐渐成为城市治理、企业管理及智能建筑等领域的重要组成部分。视频融合平台作为视频数据整合、管理和分析的核心,其选择直接影响到项目的成功与否。 在当前智慧业务类项目的集成过程中,我们不仅…...

微信小程序项目结构
微信小程序的项目结构相对清晰,主要包括以下几个部分: 一、项目根目录文件 app.js:小程序项目的入口文件,通过调用App()函数来启动整个小程序的生命周期。这个文件包含了小程序的全局数据、生命周期函数等。 app.json:…...

C++unordered_map的用法
unordered_map的简介 unordered_map是一种容器,可以把字符串当做数字,可以使用[]操作符来访问key值对应的值。 格式: unordered_map<要被转换的类型,转换的类型> 变量名{{要被转换的数或字符,转换的数或字符}}/…...

代码随想录算法训练营第三十六天| 188.买卖股票的最佳时机IV、309.最佳买卖股票时机含冷冻期、714.买卖股票的最佳时机含手续费
写代码的第三十六天 买股票,卡卡买股票,就爱买股票。。。 188.买卖股票的最佳时机IV 思路 本题是多次进行买卖,所以根据上题进行修改。 解决问题1:dp数组的含义以及定义?上题定义的事dp[i][0]初始状态,dp[i][1]第一…...

Golang | Leetcode Golang题解之第332题重新安排行程
题目: 题解: func findItinerary(tickets [][]string) []string {var (m map[string][]string{}res []string)for _, ticket : range tickets {src, dst : ticket[0], ticket[1]m[src] append(m[src], dst)}for key : range m {sort.Strings(m[key])…...

Spring Boot - 通过ServletRequestHandledEvent事件实现接口请求的性能监控
文章目录 概述1. ServletRequestHandledEvent事件2. 实现步骤3. 优缺点分析4. 测试与验证小结其他方案1. 自定义拦截器2. 性能监控平台3. 使用Spring Boot Actuator4. APM工具 概述 在Spring框架中,监控接口请求的性能可以通过ServletRequestHandledEvent事件实现。…...

Docker相关配置记录
Docker相关配置记录 换源 {"registry-mirrors": ["https://dockerhub.icu","https://docker.chenby.cn","https://docker.1panel.live","https://docker.awsl9527.cn","https://docker.anyhub.us.kg","htt…...
与INT(11))
MySQL中INT(3)与INT(11)
本文由 ChatMoney团队出品 开篇 在MySQL数据库设计的世界里,数据类型的选择是一项基础而又至关重要的任务。其中,INT数据类型因其广泛的应用和灵活性备受青睐。然而,围绕着INT(3)与INT(11)的具体差异,常常存在一些误解。本文旨在…...
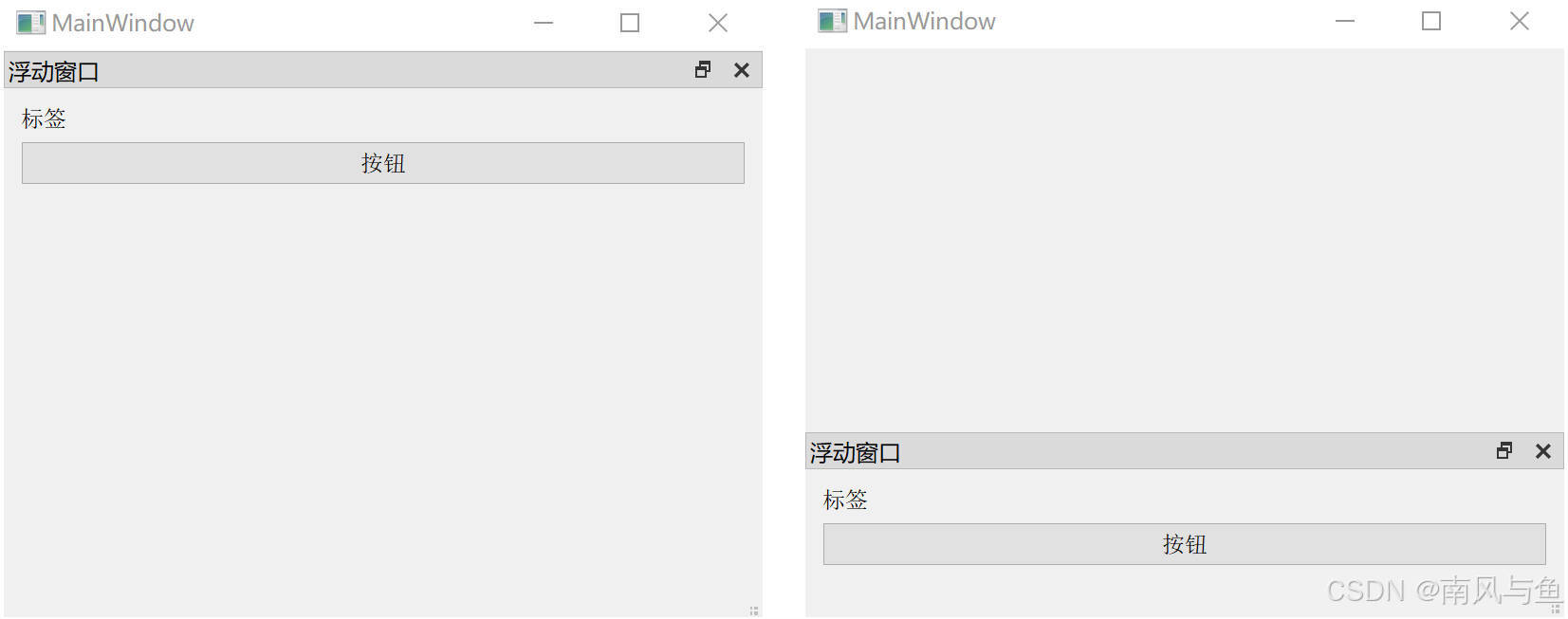
Qt 窗口:菜单、工具与状态栏的应用
目录 引言: 1. 菜单栏 1.1 创建菜单栏 1.2 在菜单栏中添加菜单 1.3 创建菜单项 1.4 在菜单项之间添加分割线 1.5 综合示例 2.工具栏 2.1 创建工具栏 2.2 设置停靠位置 2.3 设置浮动属性 2.4 设置移动属性 3. 状态栏 3.1 状态栏的创建 3.2 在状态栏中显…...
学习必备好物有哪些?高三开学季好物推荐合集
新学期即将开启,学习必备好物有哪些?以下是特别为高三学生朋友们精心挑选的一系列好物推荐,旨在帮助大家在更快更好的选择,快来看看都有哪些吧! 1、书客护眼大路灯Sun 书客是海内外知名的生物光学技术方案商…...

java的分类
目录 Java SE Java EE Java ME java主要分为三类,分别是Java SE,Java EE,Java ME。其中SE是EE和ME的基础。 Java SE 全名为Java Standard Edition,是 Java 平台的基础版本,为开发人员提供了构建和运行桌面应用程…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

工业云脑:06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例
06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例 今天第九篇06小节——现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例。新手照着做10分钟就能跑起来,老手一看就知道这玩意儿省了多少钱。以前想上AI检测,得花几万块买专业边缘盒子;现在?树莓派5(RPi 5)…...

超低功耗电池电压监控电路设计:从LM324到LPV324的硬件方案优化
1. 项目概述与核心需求解析在捣鼓各种电池供电的电子设备时,无论是自己做的无线传感器节点、便携式小工具,还是给孩子改装的玩具,有一个问题总是绕不开:你怎么知道电池快没电了?总不能每次都等到设备彻底罢工ÿ…...

天文时序数据分析:机器学习评估、半监督学习与无监督方法实战
1. 项目概述:当机器学习遇见星空 处理海量的天文时序数据,比如来自Kepler、TESS这些“巡天巨眼”的光变曲线,早已不是靠人眼一张张图去翻的时代了。数据量太大,噪声复杂,信号微弱,传统方法常常力不从心。这…...

不止于绘图:用GMT 6.4的`grdtrack`和`project`命令玩转地形剖面分析与可视化
不止于绘图:用GMT 6.4的grdtrack和project命令玩转地形剖面分析与可视化 当我们谈论地理空间分析时,很多人首先想到的是绘制精美的地图。但GMT(Generic Mapping Tools)的真正魅力在于它强大的地理计算能力。本文将带你超越基础绘图…...

ComfyUI-Manager完全指南:掌握AI工作流管理的核心技术
ComfyUI-Manager完全指南:掌握AI工作流管理的核心技术 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various custo…...

昇腾NPU模型服务化——从离线模型到高可用推理服务
模型训练完只是第一步。真正产生业务价值的是把模型部署成724小时在线服务——毫秒级延迟、支持动态Batching、能扛住流量洪峰,且具备高可用性。 这篇将手把手教你基于昇腾NPU构建生产级模型推理服务,涵盖框架选型、服务化架构、动态Batching优化、热加载…...

Unity项目实战:用TriLib插件动态加载FBX模型,5分钟搞定外部资源读取
Unity项目实战:用TriLib插件高效加载外部FBX模型的完整指南在VR展示、产品配置器等需要动态加载用户上传模型的场景中,如何快速实现外部FBX文件的读取是许多Unity开发者面临的挑战。传统的手动导入方式不仅效率低下,更无法满足运行时动态加载…...