Mac平台M1PRO芯片MiniCPM-V-2.6网页部署跑通
Mac平台M1PRO芯片MiniCPM-V-2.6网页部署跑通
契机
⚙ 2.6的小钢炮可以输入视频了,我必须拉到本地跑跑。主要解决2.6版本默认绑定flash_atten问题,pip install flash_attn也无法安装,因为强制依赖cuda。主要解决的就是这个问题,还有 BFloat16 is not supported on MPS问题解决。
环境
- macos版本:版本15.0 Beta版(24A5279h) || 版本15.1 Beta版(24B5009l)
- 芯片:m1 pro
- 代码仓库:https://github.com/OpenBMB/MiniCPM-V.git
- 分支:main
- 代码版本:b0125d8a yiranyyu 2606375857@qq.com on 2024/8/9 at 10:25
- python版本:3.9
解决问题
#拉下这个仓库
git clone [https://github.com/OpenBMB/MiniCPM-V.git](https://github.com/OpenBMB/MiniCPM-V.git) #把requirements.txt安装下
#modelscope需要手动安装
pip install http://thunlp.oss-cn-qingdao.aliyuncs.com/multi_modal/never_delete/modelscope_studio-0.4.0.9-py3-none-any.whl
#dcord如果安装有问题,参考我LAVIS博客#找到根目录web_demo_2.6.py运行
#首先添加环境变量,mps参数,见下图
--device mps
PYTORCH_ENABLE_MPS_FALLBACK=1

#第一次运行web_demo_2.6.py报错如下
ImportError: This modeling file requires the following packages that were not found in your environment: flash_attn. Run `pip install flash_attn`#直接修改代码
from typing import Union
from transformers.dynamic_module_utils import get_imports
from unittest.mock import patch
# fix the imports
def fixed_get_imports(filename: Union[str, os.PathLike]) -> list[str]:imports = get_imports(filename)if not torch.cuda.is_available() and "flash_attn" in imports:imports.remove("flash_attn")return imports#79行左右修改为
with patch("transformers.dynamic_module_utils.get_imports", fixed_get_imports):model = AutoModel.from_pretrained(model_path, trust_remote_code=True, torch_dtype=torch.bfloat16)model = model.to(device=device)
完整代码如下
#!/usr/bin/env python
# encoding: utf-8
import torch
import argparse
from transformers import AutoModel, AutoTokenizer
import gradio as gr
from PIL import Image
from decord import VideoReader, cpu
import io
import os
import copy
import requests
import base64
import json
import traceback
import re
import modelscope_studio as mgr
from typing import Union
from transformers.dynamic_module_utils import get_imports
from unittest.mock import patch# README, How to run demo on different devices# For Nvidia GPUs.
# python web_demo_2.6.py --device cuda# For Mac with MPS (Apple silicon or AMD GPUs).
# PYTORCH_ENABLE_MPS_FALLBACK=1 python web_demo_2.6.py --device mps# Argparser
parser = argparse.ArgumentParser(description='demo')
parser.add_argument('--device', type=str, default='cuda', help='cuda or mps')
parser.add_argument('--multi-gpus', action='store_true', default=False, help='use multi-gpus')
args = parser.parse_args()
device = args.device
assert device in ['cuda', 'mps']# fix the imports
def fixed_get_imports(filename: Union[str, os.PathLike]) -> list[str]:imports = get_imports(filename)if not torch.cuda.is_available() and "flash_attn" in imports:imports.remove("flash_attn")return imports# Load model
model_path = 'openbmb/MiniCPM-V-2_6'
if 'int4' in model_path:if device == 'mps':print('Error: running int4 model with bitsandbytes on Mac is not supported right now.')exit()model = AutoModel.from_pretrained(model_path, trust_remote_code=True)
else:if args.multi_gpus:from accelerate import load_checkpoint_and_dispatch, init_empty_weights, infer_auto_device_mapwith init_empty_weights():model = AutoModel.from_pretrained(model_path, trust_remote_code=True, attn_implementation='sdpa', torch_dtype=torch.bfloat16)device_map = infer_auto_device_map(model, max_memory={0: "10GB", 1: "10GB"},no_split_module_classes=['SiglipVisionTransformer', 'Qwen2DecoderLayer'])device_id = device_map["llm.model.embed_tokens"]device_map["llm.lm_head"] = device_id # firtt and last layer should be in same devicedevice_map["vpm"] = device_iddevice_map["resampler"] = device_iddevice_id2 = device_map["llm.model.layers.26"]device_map["llm.model.layers.8"] = device_id2device_map["llm.model.layers.9"] = device_id2device_map["llm.model.layers.10"] = device_id2device_map["llm.model.layers.11"] = device_id2device_map["llm.model.layers.12"] = device_id2device_map["llm.model.layers.13"] = device_id2device_map["llm.model.layers.14"] = device_id2device_map["llm.model.layers.15"] = device_id2device_map["llm.model.layers.16"] = device_id2#print(device_map)model = load_checkpoint_and_dispatch(model, model_path, dtype=torch.bfloat16, device_map=device_map)else:with patch("transformers.dynamic_module_utils.get_imports", fixed_get_imports):model = AutoModel.from_pretrained(model_path, trust_remote_code=True, torch_dtype=torch.bfloat16)model = model.to(device=device)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model.eval()ERROR_MSG = "Error, please retry"
model_name = 'MiniCPM-V 2.6'
MAX_NUM_FRAMES = 64
IMAGE_EXTENSIONS = {'.jpg', '.jpeg', '.png', '.bmp', '.tiff', '.webp'}
VIDEO_EXTENSIONS = {'.mp4', '.mkv', '.mov', '.avi', '.flv', '.wmv', '.webm', '.m4v'}def get_file_extension(filename):return os.path.splitext(filename)[1].lower()def is_image(filename):return get_file_extension(filename) in IMAGE_EXTENSIONSdef is_video(filename):return get_file_extension(filename) in VIDEO_EXTENSIONSform_radio = {'choices': ['Beam Search', 'Sampling'],#'value': 'Beam Search','value': 'Sampling','interactive': True,'label': 'Decode Type'
}def create_component(params, comp='Slider'):if comp == 'Slider':return gr.Slider(minimum=params['minimum'],maximum=params['maximum'],value=params['value'],step=params['step'],interactive=params['interactive'],label=params['label'])elif comp == 'Radio':return gr.Radio(choices=params['choices'],value=params['value'],interactive=params['interactive'],label=params['label'])elif comp == 'Button':return gr.Button(value=params['value'],interactive=True)def create_multimodal_input(upload_image_disabled=False, upload_video_disabled=False):return mgr.MultimodalInput(upload_image_button_props={'label': 'Upload Image', 'disabled': upload_image_disabled, 'file_count': 'multiple'},upload_video_button_props={'label': 'Upload Video', 'disabled': upload_video_disabled, 'file_count': 'single'},submit_button_props={'label': 'Submit'})def chat(img, msgs, ctx, params=None, vision_hidden_states=None):try:print('msgs:', msgs)answer = model.chat(image=None,msgs=msgs,tokenizer=tokenizer,**params)res = re.sub(r'(<box>.*</box>)', '', answer)res = res.replace('<ref>', '')res = res.replace('</ref>', '')res = res.replace('<box>', '')answer = res.replace('</box>', '')print('answer:', answer)return 0, answer, None, Noneexcept Exception as e:print(e)traceback.print_exc()return -1, ERROR_MSG, None, Nonedef encode_image(image):if not isinstance(image, Image.Image):if hasattr(image, 'path'):image = Image.open(image.path).convert("RGB")else:image = Image.open(image.file.path).convert("RGB")# resize to max_sizemax_size = 448*16if max(image.size) > max_size:w,h = image.sizeif w > h:new_w = max_sizenew_h = int(h * max_size / w)else:new_h = max_sizenew_w = int(w * max_size / h)image = image.resize((new_w, new_h), resample=Image.BICUBIC)return image## save by BytesIO and convert to base64#buffered = io.BytesIO()#image.save(buffered, format="png")#im_b64 = base64.b64encode(buffered.getvalue()).decode()#return {"type": "image", "pairs": im_b64}def encode_video(video):def uniform_sample(l, n):gap = len(l) / nidxs = [int(i * gap + gap / 2) for i in range(n)]return [l[i] for i in idxs]if hasattr(video, 'path'):vr = VideoReader(video.path, ctx=cpu(0))else:vr = VideoReader(video.file.path, ctx=cpu(0))sample_fps = round(vr.get_avg_fps() / 1) # FPSframe_idx = [i for i in range(0, len(vr), sample_fps)]if len(frame_idx)>MAX_NUM_FRAMES:frame_idx = uniform_sample(frame_idx, MAX_NUM_FRAMES)video = vr.get_batch(frame_idx).asnumpy()video = [Image.fromarray(v.astype('uint8')) for v in video]video = [encode_image(v) for v in video]print('video frames:', len(video))return videodef check_mm_type(mm_file):if hasattr(mm_file, 'path'):path = mm_file.pathelse:path = mm_file.file.pathif is_image(path):return "image"if is_video(path):return "video"return Nonedef encode_mm_file(mm_file):if check_mm_type(mm_file) == 'image':return [encode_image(mm_file)]if check_mm_type(mm_file) == 'video':return encode_video(mm_file)return Nonedef make_text(text):#return {"type": "text", "pairs": text} # # For remote callreturn textdef encode_message(_question):files = _question.filesquestion = _question.textpattern = r"\[mm_media\]\d+\[/mm_media\]"matches = re.split(pattern, question)message = []if len(matches) != len(files) + 1:gr.Warning("Number of Images not match the placeholder in text, please refresh the page to restart!")assert len(matches) == len(files) + 1text = matches[0].strip()if text:message.append(make_text(text))for i in range(len(files)):message += encode_mm_file(files[i])text = matches[i + 1].strip()if text:message.append(make_text(text))return messagedef check_has_videos(_question):images_cnt = 0videos_cnt = 0for file in _question.files:if check_mm_type(file) == "image":images_cnt += 1else:videos_cnt += 1return images_cnt, videos_cntdef count_video_frames(_context):num_frames = 0for message in _context:for item in message["content"]:#if item["type"] == "image": # For remote callif isinstance(item, Image.Image):num_frames += 1return num_framesdef respond(_question, _chat_bot, _app_cfg, params_form):_context = _app_cfg['ctx'].copy()_context.append({'role': 'user', 'content': encode_message(_question)})images_cnt = _app_cfg['images_cnt']videos_cnt = _app_cfg['videos_cnt']files_cnts = check_has_videos(_question)if files_cnts[1] + videos_cnt > 1 or (files_cnts[1] + videos_cnt == 1 and files_cnts[0] + images_cnt > 0):gr.Warning("Only supports single video file input right now!")return _question, _chat_bot, _app_cfgif params_form == 'Beam Search':params = {'sampling': False,'num_beams': 3,'repetition_penalty': 1.2,"max_new_tokens": 2048}else:params = {'sampling': True,'top_p': 0.8,'top_k': 100,'temperature': 0.7,'repetition_penalty': 1.05,"max_new_tokens": 2048}if files_cnts[1] + videos_cnt > 0:params["max_inp_length"] = 4352 # 4096+256params["use_image_id"] = Falseparams["max_slice_nums"] = 1 if count_video_frames(_context) > 16 else 2code, _answer, _, sts = chat("", _context, None, params)images_cnt += files_cnts[0]videos_cnt += files_cnts[1]_context.append({"role": "assistant", "content": [make_text(_answer)]})_chat_bot.append((_question, _answer))if code == 0:_app_cfg['ctx']=_context_app_cfg['sts']=sts_app_cfg['images_cnt'] = images_cnt_app_cfg['videos_cnt'] = videos_cntupload_image_disabled = videos_cnt > 0upload_video_disabled = videos_cnt > 0 or images_cnt > 0return create_multimodal_input(upload_image_disabled, upload_video_disabled), _chat_bot, _app_cfgdef fewshot_add_demonstration(_image, _user_message, _assistant_message, _chat_bot, _app_cfg):ctx = _app_cfg["ctx"]message_item = []if _image is not None:image = Image.open(_image).convert("RGB")ctx.append({"role": "user", "content": [encode_image(image), make_text(_user_message)]})message_item.append({"text": "[mm_media]1[/mm_media]" + _user_message, "files": [_image]})else:if _user_message:ctx.append({"role": "user", "content": [make_text(_user_message)]})message_item.append({"text": _user_message, "files": []})else:message_item.append(None)if _assistant_message:ctx.append({"role": "assistant", "content": [make_text(_assistant_message)]})message_item.append({"text": _assistant_message, "files": []})else:message_item.append(None)_chat_bot.append(message_item)return None, "", "", _chat_bot, _app_cfgdef fewshot_respond(_image, _user_message, _chat_bot, _app_cfg, params_form):user_message_contents = []_context = _app_cfg["ctx"].copy()if _image:image = Image.open(_image).convert("RGB")user_message_contents += [encode_image(image)]if _user_message:user_message_contents += [make_text(_user_message)]if user_message_contents:_context.append({"role": "user", "content": user_message_contents})if params_form == 'Beam Search':params = {'sampling': False,'num_beams': 3,'repetition_penalty': 1.2,"max_new_tokens": 2048}else:params = {'sampling': True,'top_p': 0.8,'top_k': 100,'temperature': 0.7,'repetition_penalty': 1.05,"max_new_tokens": 2048}code, _answer, _, sts = chat("", _context, None, params)_context.append({"role": "assistant", "content": [make_text(_answer)]})if _image:_chat_bot.append([{"text": "[mm_media]1[/mm_media]" + _user_message, "files": [_image]},{"text": _answer, "files": []}])else:_chat_bot.append([{"text": _user_message, "files": [_image]},{"text": _answer, "files": []}])if code == 0:_app_cfg['ctx']=_context_app_cfg['sts']=stsreturn None, '', '', _chat_bot, _app_cfgdef regenerate_button_clicked(_question, _image, _user_message, _assistant_message, _chat_bot, _app_cfg, params_form):if len(_chat_bot) <= 1 or not _chat_bot[-1][1]:gr.Warning('No question for regeneration.')return '', _image, _user_message, _assistant_message, _chat_bot, _app_cfgif _app_cfg["chat_type"] == "Chat":images_cnt = _app_cfg['images_cnt']videos_cnt = _app_cfg['videos_cnt']_question = _chat_bot[-1][0]_chat_bot = _chat_bot[:-1]_app_cfg['ctx'] = _app_cfg['ctx'][:-2]files_cnts = check_has_videos(_question)images_cnt -= files_cnts[0]videos_cnt -= files_cnts[1]_app_cfg['images_cnt'] = images_cnt_app_cfg['videos_cnt'] = videos_cntupload_image_disabled = videos_cnt > 0upload_video_disabled = videos_cnt > 0 or images_cnt > 0_question, _chat_bot, _app_cfg = respond(_question, _chat_bot, _app_cfg, params_form)return _question, _image, _user_message, _assistant_message, _chat_bot, _app_cfgelse:last_message = _chat_bot[-1][0]last_image = Nonelast_user_message = ''if last_message.text:last_user_message = last_message.textif last_message.files:last_image = last_message.files[0].file.path_chat_bot = _chat_bot[:-1]_app_cfg['ctx'] = _app_cfg['ctx'][:-2]_image, _user_message, _assistant_message, _chat_bot, _app_cfg = fewshot_respond(last_image, last_user_message, _chat_bot, _app_cfg, params_form)return _question, _image, _user_message, _assistant_message, _chat_bot, _app_cfgdef flushed():return gr.update(interactive=True)def clear(txt_message, chat_bot, app_session):txt_message.files.clear()txt_message.text = ''chat_bot = copy.deepcopy(init_conversation)app_session['sts'] = Noneapp_session['ctx'] = []app_session['images_cnt'] = 0app_session['videos_cnt'] = 0return create_multimodal_input(), chat_bot, app_session, None, '', ''def select_chat_type(_tab, _app_cfg):_app_cfg["chat_type"] = _tabreturn _app_cfginit_conversation = [[None,{# The first message of bot closes the typewriter."text": "You can talk to me now","flushing": False}],
]css = """
video { height: auto !important; }
.example label { font-size: 16px;}
"""introduction = """## Features:
1. Chat with single image
2. Chat with multiple images
3. Chat with video
4. In-context few-shot learningClick `How to use` tab to see examples.
"""with gr.Blocks(css=css) as demo:with gr.Tab(model_name):with gr.Row():with gr.Column(scale=1, min_width=300):gr.Markdown(value=introduction)params_form = create_component(form_radio, comp='Radio')regenerate = create_component({'value': 'Regenerate'}, comp='Button')clear_button = create_component({'value': 'Clear History'}, comp='Button')with gr.Column(scale=3, min_width=500):app_session = gr.State({'sts':None,'ctx':[], 'images_cnt': 0, 'videos_cnt': 0, 'chat_type': 'Chat'})chat_bot = mgr.Chatbot(label=f"Chat with {model_name}", value=copy.deepcopy(init_conversation), height=600, flushing=False, bubble_full_width=False)with gr.Tab("Chat") as chat_tab:txt_message = create_multimodal_input()chat_tab_label = gr.Textbox(value="Chat", interactive=False, visible=False)txt_message.submit(respond,[txt_message, chat_bot, app_session, params_form],[txt_message, chat_bot, app_session])with gr.Tab("Few Shot") as fewshot_tab:fewshot_tab_label = gr.Textbox(value="Few Shot", interactive=False, visible=False)with gr.Row():with gr.Column(scale=1):image_input = gr.Image(type="filepath", sources=["upload"])with gr.Column(scale=3):user_message = gr.Textbox(label="User")assistant_message = gr.Textbox(label="Assistant")with gr.Row():add_demonstration_button = gr.Button("Add Example")generate_button = gr.Button(value="Generate", variant="primary")add_demonstration_button.click(fewshot_add_demonstration,[image_input, user_message, assistant_message, chat_bot, app_session],[image_input, user_message, assistant_message, chat_bot, app_session])generate_button.click(fewshot_respond,[image_input, user_message, chat_bot, app_session, params_form],[image_input, user_message, assistant_message, chat_bot, app_session])chat_tab.select(select_chat_type,[chat_tab_label, app_session],[app_session])chat_tab.select( # do clearclear,[txt_message, chat_bot, app_session],[txt_message, chat_bot, app_session, image_input, user_message, assistant_message])fewshot_tab.select(select_chat_type,[fewshot_tab_label, app_session],[app_session])fewshot_tab.select( # do clearclear,[txt_message, chat_bot, app_session],[txt_message, chat_bot, app_session, image_input, user_message, assistant_message])chat_bot.flushed(flushed,outputs=[txt_message])regenerate.click(regenerate_button_clicked,[txt_message, image_input, user_message, assistant_message, chat_bot, app_session, params_form],[txt_message, image_input, user_message, assistant_message, chat_bot, app_session])clear_button.click(clear,[txt_message, chat_bot, app_session],[txt_message, chat_bot, app_session, image_input, user_message, assistant_message])with gr.Tab("How to use"):with gr.Column():with gr.Row():image_example = gr.Image(value="http://thunlp.oss-cn-qingdao.aliyuncs.com/multi_modal/never_delete/m_bear2.gif", label='1. Chat with single or multiple images', interactive=False, width=400, elem_classes="example")example2 = gr.Image(value="http://thunlp.oss-cn-qingdao.aliyuncs.com/multi_modal/never_delete/video2.gif", label='2. Chat with video', interactive=False, width=400, elem_classes="example")example3 = gr.Image(value="http://thunlp.oss-cn-qingdao.aliyuncs.com/multi_modal/never_delete/fshot.gif", label='3. Few shot', interactive=False, width=400, elem_classes="example")# launch
demo.launch(share=False, debug=True, show_api=False, server_port=8885, server_name="0.0.0.0")#第一次运行web_demo_2.6.py报错如下
File "/Usxxxxxxxckages/torch/nn/modules/module.py", line 1158, in convert
return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
TypeError: BFloat16 is not supported on MPS#重装依赖
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cpu#再次运行就没问题了
#这里下载模型20g可能会等一段时间,最后借助魔法下载,看这网速在疯狂跑就没问题
#成功运行输出如下
Loading checkpoint shards: 100%|██████████| 4/4 [00:21<00:00, 5.33s/it]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Running on local URL: http://0.0.0.0:8885To create a public link, set `share=True` in `launch()`.
IMPORTANT: You are using gradio version 4.22.0, however version 4.29.0 is available, please upgrade.
--------
效果展示
图片理解
Sampling解码

Beam Search解码

视频理解
Sampling解码

Beam Search解码

系统占用

总结
- 解决flash_attn强制依赖问题
- 解决bfloat16在mps无法使用问题
- 看系统占用是没走mps,添加的环境变量也可以看出
- Sampling瞎回答,Beam Search回答很惊喜
- Beam Search处理视频4秒,在m1pro下,当前代码中需要230s左右
- ollama部署还在研究中…
写到最后

相关文章:
Mac平台M1PRO芯片MiniCPM-V-2.6网页部署跑通
Mac平台M1PRO芯片MiniCPM-V-2.6网页部署跑通 契机 ⚙ 2.6的小钢炮可以输入视频了,我必须拉到本地跑跑。主要解决2.6版本默认绑定flash_atten问题,pip install flash_attn也无法安装,因为强制依赖cuda。主要解决的就是这个问题,还…...

MyBatis:Maven,Git,TortoiseGit,Gradle
1,Maven Maven是一个非常优秀的项目管理工具,采用一种“约定优于配置(CoC)”的策略来管理项目。使用Maven不仅可以把源代码构建成可发布的项目(包括编译、打包、测试和分发),还可以生成报告、生…...

获取链表中间位置的两种方法方法
方法一: 我们可以计算链表节点的数量,然后遍历链表找到前半部分的尾节点。 方法二: 我们也可以使用快慢指针在一次遍历中找到:慢指针一次走一步,快指针一次走两步,快慢指针同时出发。当快指针移动到链表的末尾时&am…...
第二十天的学习(2024.8.8)Vue拓展
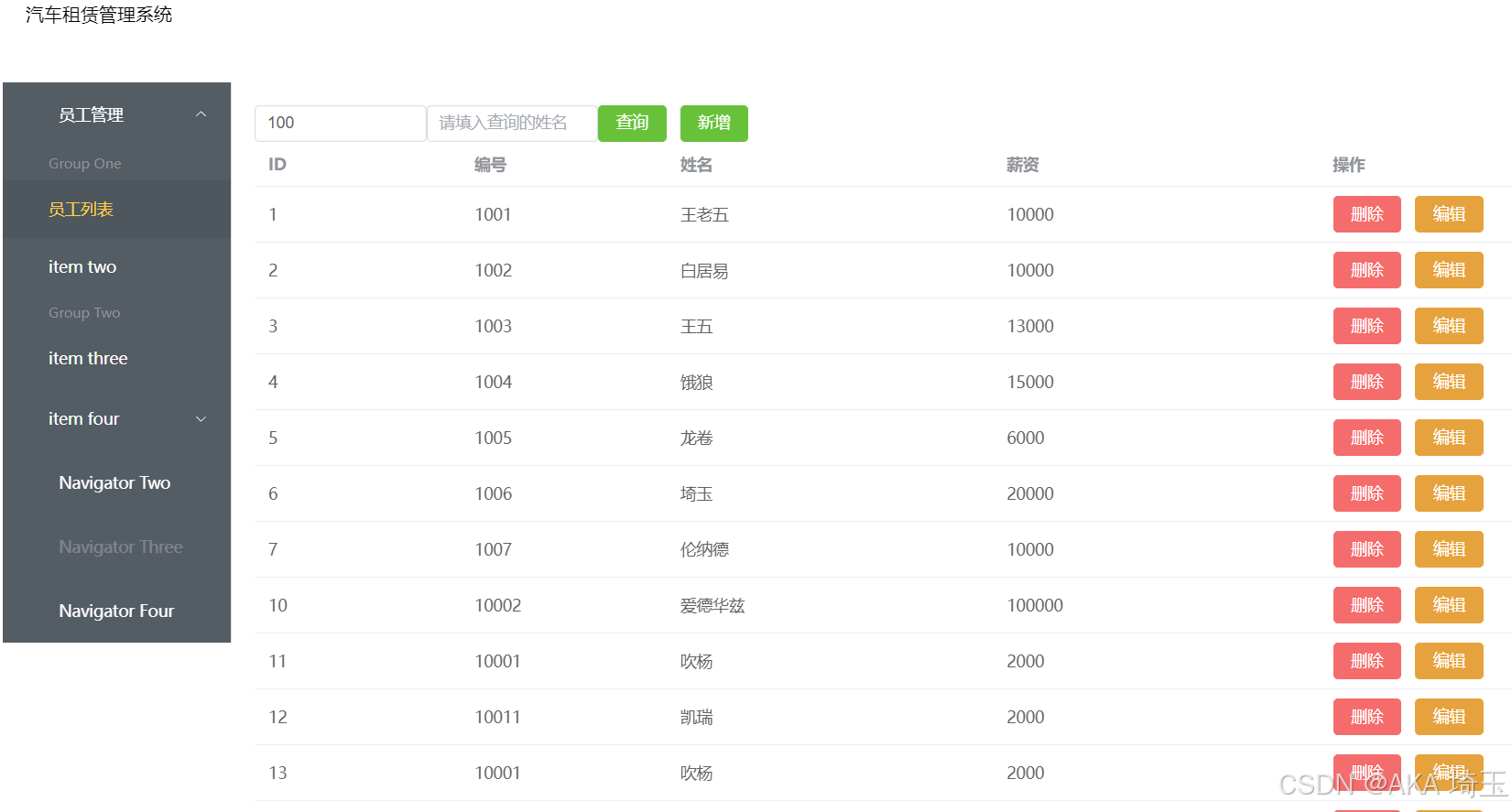
昨天的笔记中,我们进行的项目已经可以在网页上显示查询到数据库中的数据,今天的笔记中将会完成在网页上进行增删改查的操作 1.删除表中数据 现在网页上只能呈现出数据库中的数据,我们首先添加一个删除按钮,使其可以对数据库数据…...

微信小程序教程011:全局配置:Window
文章目录 1、window1.1、`window`-小程序窗口的组成部分1.2、了解 window 节点常用的配置项1.3、设置导航栏的标题1.4、设置导航栏的背景色1.5、设置导航栏的标题颜色1.6、全局开启下拉刷新功能1.7、设置下拉刷新时窗口的背景色1.8、设置下拉刷新时 loading 的样式1.9、设置上拉…...

Tomcat服务器和Web项目的部署
目录 一、概述和作用 二、安装 1.进入官网 2.Download下面选择想要下载的版本 3.点击Which version查看版本所需要的JRE版本 4.返回上一页下载和电脑和操作系统匹配的Tomcat 5. 安装完成后,点击bin目录下的startup.bat(linux系统下就运行startup.sh&…...

PCIe学习笔记(22)
Transaction Ordering Transaction Ordering Rules 表2-40定义了PCI Express Transactions的排序要求。该表中定义的规则统一适用于PCI Express上所有类型的事务,包括内存、I/O、配置和消息。该表中定义的排序规则适用于单个流量类(TC)。不同TC标签的事务之间没有…...

Vue3 依赖注入Provide / Inject
在实际开发中,我们经常需要从父组件向子组件传递数据,一般情况下,我们使用 props。但有时候会遇到深度嵌套的组件,而深层的子组件只需要父组件的部分内容。在这种情况下,如果仍然将 prop 沿着组件链逐级传递下去&#…...

Python | Leetcode Python题解之第332题重新安排行程
题目: 题解: class Solution:def findItinerary(self, tickets: List[List[str]]) -> List[str]:def dfs(curr: str):while vec[curr]:tmp heapq.heappop(vec[curr])dfs(tmp)stack.append(curr)vec collections.defaultdict(list)for depart, arri…...

React状态管理:react-redux和redux-saga(适合由vue转到react的同学)
注意:本文不会把所有知识点都写一遍,并不适合纯新手阅读 首先Redux是一种状态管理方案,本身和react并没有什么联系,redux也可以结合其他框架来用。 react-redux是基于react的一种状态管理实现,他不像vuex那样直接内置在…...

刷题技巧:双指针法的核心思想总结+例题整合+力扣接雨水双指针c++实现
双指针法的核心思想是通过同时操作两个指针来遍历数据结构,通常是数组或链表,以达到优化算法性能的目的。具体来说,双指针法能够减少时间复杂度、空间复杂度,或者简化逻辑结构。以下是双指针法的几个核心思想: ps 下面…...

什么是前端微服务,有何优势
随着互联网技术的发展,传统的单体应用架构已经无法满足复杂业务场景的需求。微服务架构的兴起为后端应用的开发和部署提供了灵活性和可扩展性。与此同时,前端开发也经历了类似的演变,前端微服务作为一种新兴的架构模式应运而生。 一、前端微服…...

小论文写作——02:编故事
一篇论文,可以发水刊,也可以发顶刊顶会,这两者的区别就是一个故事编的好不好。 你的论文ABC,但不能之说有ABC。创新就是看你故事编的怎么样?创新是编出来的。 我们要说:我发现了问题,然后准备…...

GIT企业开发使用介绍
0.认识git git就是一个版本控制器,记录每次的修改以及版本迭代的一个管理系统 至于为什么会有git的出现,主要是为了解决一份代码改了又改,但最后还是要第一版的情况 git 可以控制电脑上所有格式的文档 1.安装git sudo yum install git -y…...

文件上传-前端验证
查看源代码(找验证代码) 1、源代码直接找到验证代码 示例: function checkFileExt(filename){var flag false; //状态var arr ["jpg","png","gif"]; //允许上传的文件//取出上传文件的扩展名var index f…...

ROT加密算法login-RESERVE
ROT算法(字母轮换加密) 也称为Caesar加密,是一种简单的字母替换加密算法。它通过将字母表中的每个字母向后(或向前)移动固定的位置来加密文本。 加密步骤: 选择一个固定的偏移量(通常是1到25之间的整数)&…...
C++ 新特性 | C++20 常用新特性介绍
目录 1、模块(Modules) 2、协程(Coroutines) 3、概念(Concepts) 4、范围(Ranges) 5、三向比较符(three-way comparison) C软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)https…...

Java设计模式之策略模式实践
1、策略接口 /*** 策略接口*/ public interface DemoStrategy {Result execute(); } 2、策略工厂 /*** 策略工厂*/ Component public class DemoFactory {Resourceprivate final Map<String, DemoStrategy> demoStrategy new ConcurrentHashMap<>();public Demo…...

C语言——结构体数组、结构体指针、结构体函数与二级指针
C语言中的结构体(struct)是一种用户自定义的数据类型,它允许你将不同类型的数据项组合成一个单一的类型。结构体数组则是一种特殊的数组,其元素为结构体类型。这意味着你可以在一个数组中存储多个具有相同结构的记录。 定义结构体…...

【4】策略模式
如上图所示,如果要加入一个新的货币,那么就需要对类中的Calculate函数进行修改,这违背了封闭开放原则。 上图中的方式更加合适,搞一个抽象类(方法中可以用多态调用),然后每个货币自己是一个类&a…...

单片机实战:从ADC原理到DAC应用,构建精准数据采集系统
1. 从模拟到数字:ADC基础原理与实战配置 想象一下你正在用温度计测量室温,水银柱停在25.3℃的位置——这就是典型的模拟信号。而单片机作为数字世界的原住民,它只认识0和1。**ADC(模数转换器)**就是连接这两个世界的桥…...

快速排序与希尔排序实战解析
一、今天学习目标希尔排序(插入排序升级版)快速排序(最常用、面试必考)完整可运行代码复杂度对比二、希尔排序(Shell Sort)思想:分组做插入排序逐步缩小增量(gap)最后 ga…...

利用Knockd与iptables打造隐形SSH通道,黑客无从下手
1. 为什么你的SSH端口总被黑客盯上? 每次查看服务器日志,总能看到一堆陌生的IP地址在疯狂扫描你的22端口,这种感觉就像家门口整天有人转悠,让人浑身不自在。传统的SSH防护手段,比如修改默认端口或者设置fail2ban&#…...

VSCode搭配FTP-Sync实现宝塔FTP项目代码一键部署
1. 为什么你需要VSCodeFTP-Sync这套组合拳 每次修改完代码都要手动上传到服务器,是不是觉得特别麻烦?我以前用FileZilla这类传统FTP工具时,经常遇到这样的场景:改了三四个文件,结果上传时漏了一个;或者明明…...

如何利用Upscayl的GPU加速技术实现AI图像超分:完整指南
如何利用Upscayl的GPU加速技术实现AI图像超分:完整指南 【免费下载链接】upscayl 🆙 Upscayl - #1 Free and Open Source AI Image Upscaler for Linux, MacOS and Windows. 项目地址: https://gitcode.com/GitHub_Trending/up/upscayl Upscayl是…...

R语言时序分析实战:从ACF/PACF图到ARIMA模型定阶
1. 时序分析入门:为什么需要ACF/PACF图? 当你拿到一组时间序列数据时,第一反应可能是直接扔进ARIMA模型里跑结果。但就像医生不能只看症状就开药一样,数据分析师也需要先"把脉"——这就是ACF(自相关函数&…...

终极画中画扩展:Chrome多任务观影完整指南
终极画中画扩展:Chrome多任务观影完整指南 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 你是否曾在观看在线课程时需要同时查阅文档?是否想一边追剧…...

台达PLC与触摸屏程序模板:CANOPEN总线伺服运动轴控制解决方案,含操作与运动控制手册,支...
台达,AS228T,plc程序模板和触摸屏程序模板,目前6个总线伺服,采用CANOPEN,适用于运动轴控制,程序可以在自动的时候暂停进行手动控制,适用于一些中大型设备,可以防止某个气缸超时时&am…...
)
别再只测理论值了!手把手教你用ZCU104实测AXI DMA真实带宽(附Vivado工程与源码)
ZCU104实战:AXI DMA真实带宽测试与性能优化全解析 在FPGA开发中,AXI DMA的性能直接影响着视频流处理、高速数据采集等关键应用的实时性。很多开发者习惯依赖理论峰值带宽作为设计依据,却在实际部署时遭遇性能瓶颈。本文将带您深入ZCU104开发板…...

GitHub中文插件终极指南:3分钟让GitHub界面说中文的完整教程
GitHub中文插件终极指南:3分钟让GitHub界面说中文的完整教程 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 你是否曾经在…...