Unity Shader变体优化与故障排除技巧
在 Unity 中编写着色器时,我们可以方便地在一个源文件中包含多个特性、通道和分支逻辑。在构建时,着色器源文件会被编译成着色器程序,这些程序包含一个或多个变体。变体是该着色器在满足一组条件后生成的版本,这通常会导致线性执行路径,而没有静态分支条件。
我们使用变体而不是将所有分支路径保留在一个着色器中的原因是,GPU 在并行处理可预测的代码时表现出色,且始终遵循相同路径的,从而实现更高的吞吐量。如果编译后的着色器程序中存在条件分支,GPU 将需要花费资源进行预测任务,等待其他路径完成,等等,从而导致效率低下。
虽然这相比动态分支显著提升了 GPU 性能,但也有一些缺点。随着变体数量的增加,构建时间会变得更长,有时每次构建甚至会增加多个小时。游戏启动时间也会更长,因为需要更多时间来加载和预热着色器。最后,如果变体管理不当,着色器在运行时可能会占用大量内存,有时甚至超过 1GB。
生成的变体数量取决于多种因素,包括定义的关键字和属性、质量设置、图形层级、启用的图形 API、后处理效果、活动的渲染管线、光照和雾效模式,以及是否启用了 XR 等。生成大量变体的着色器通常被称为超级着色器(uber shader)。在运行时,Unity 会加载与所需设置和关键字匹配的变体,这部分内容我们稍后会详细介绍。

如果考虑到我们经常看到有超过 100 个关键字的着色器,这将导致不可控的变体数量,也就是我们常说的着色器变体爆炸,这对我们的影响尤其大。在应用任何过滤之前,着色器的初始变体空间达到数百万的情况并不罕见。
为了解决这个问题,Unity 会尝试通过一些过滤步骤来减少生成的变体数量。例如,如果未启用 XR,那么所需的相关变体通常会被剥离。接下来,Unity 会考虑你在场景中实际使用的功能,如光照模式、雾效等。这些特别难以察觉,因为开发人员和艺术家可能会引入看似安全的更改,但实际上会显著增加着色器变体的数量,除非你在部署管道中设置一些保障措施,否则没有明显的方法可以检测到。
虽然这很有帮助,但这一过程并不完美,我们可以做很多事情,在不影响游戏视觉质量的情况下尽可能多地剥离变体。
在此,我想分享一些关于如何处理变体、理解它们的来源以及一些有效减少变体的实用技巧。这将显著缩短项目的构建时间并减少内存占用。
理解关键字对变体的影响
除其他因素外,着色器变体是根据着色器(Shader)中使用的 shader_feature 和 multi_compile 关键字的所有可能组合生成的。标记为 multi_compile 的关键字始终会包含在构建中,而标记为shader_feature 的关键字只有在被项目中的任何材质引用时才会包含进去。因此,应尽可能使用 shader_feature。
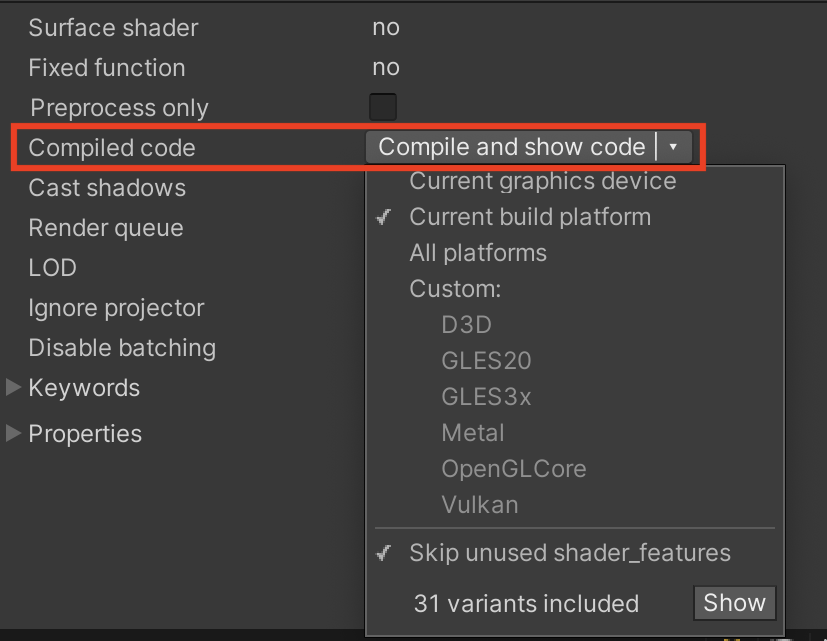
要查看着色器中定义的关键字,可以选择它并查看检视器(Inspector)。

*Shader Inspector 视图中的关键字
如你所见,关键字分为 Overridable(可覆盖)和 Not Overridable(不可覆盖)。具有全局作用域的本地关键字(即在实际着色器文件中定义的关键字)可以被具有相同名称的全局着色器关键字覆盖。如果它们是在局部作用域下定义的(通过使用 multi_compile_local 或 shader_feature_local),则不能被覆盖,并会显示在不可覆盖部分中。全局着色器关键字由 Unity 引擎提供,它们是可覆盖的。由于它们可以在构建过程的任何时候添加,因此并非所有全局关键字都会显示在此列表中。
通过在同一指令中定义关键字,可以将它们定义为相互排斥的组,称为集合。这样做可以避免为永远不会同时启用的关键字组合生成变体(例如两种不同类型的光照或雾效)。
#pragma shader_feature LIGHT_LOW_Q LIGHT_HIGH_Q
例如,要减少每个平台的关键字数量,可以使用预处理器宏,只为相关平台定义关键字:
#ifdef SHADER_API_METAL #pragma shader_feature IOS_FOG_FEATURE #else #pragma shader_feature BASE_FOG_FEATURE #endif
请注意,这些带有宏的表达式不能依赖于与构建目标无关的其他关键字或功能。
关键字也可以限定在特定的通道(pass)中,从而减少可能的组合数量。为此,你可以在指令后添加以下任意一个后缀:
-
vertex
-
fragment
-
hull
-
domain
-
geometry
-
raytracing
例如:
#pragma shader_feature_fragment FRAG_FEATURE_1 FRAG_FEATURE_2
根据使用的渲染器,某些指定给特定渲染器的后缀可能会被忽略或不起作用。例如,在 OpenGL 上,OpenGL ES 和 Vulkan 后缀将被忽略。
你可以使用指令 #pragma skip_variants 来定义在生成特定着色器的变体时应该排除的关键字。在构建运行版时,该着色器包含这些关键字的所有变体将被跳过。
你还可以选择使用 #pragma dynamic_branch 指令来定义关键字,这将强制 Unity 使用动态分支而不为这些关键字生成变体。虽然这样可以减少生成的变体数量,但根据着色器和游戏内容的不同,可能会导致GPU 性能下降。因此,在使用时建议进行适当的性能分析。
检查生成的着色器代码
通常情况下,着色器变体直到实际构建游戏时才会被编译。但你可以使用这个选项来检查针对特定构建平台或图形 API 生成的着色器变体。这样可以提前检查是否有错误。此外,你还可以将生成的代码粘贴到 GPU 着色器性能分析工具(如 PVRShaderEditor)中,以进一步的优化。
*Shader Inspector 视图中的关键字
在底部有一个条目,说明根据当前打开场景中的材质,在未应用任何脚本剥离的情况下,包含了多少变体。如果点击"显示 "按钮,就会显示一个临时文件,其中包含一些额外的调试信息,说明在不同平台上使用或剥离了哪些关键字,包括顶点阶段变体的数量。
上面的“Preprocess only(仅预处理)”复选框让你能够在编译后的着色器代码和预处理后的着色器源代码之间切换,以便更为轻松、快速地进行调试。
如果你正在使用 Built-in 内置渲染管线并且使用表面着色器(surface shader),你可以选择检查 Unity 在构建时将用来替换你简化的着色器源代码的生成代码。然后,你可以选择性地用生成的代码替换你的着色器源代码,如果你想要修改输出的话。
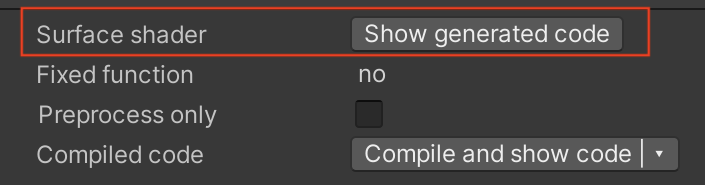
*表面着色器的显示生成代码(Show generated code)选项
确定在构建时生成哪些变体
在构建游戏时,Unity 会根据每个着色器的功能、引擎设置和其他因素的所有可能排列组合,确定每个着色器的变体空间。然后将这些组合传递给预处理器,进行多次剥离。可以使用 IPreprocessShaders 回调对其进行扩展,以创建自定义逻辑,从构建中剥离更多变体,如下所述。
在“Project Settings(项目设置)> Graphics(图形)”下的“始终包含的着色器(Always-included shaders)”列表中包含的着色器,其所有变体都会包含在构建中。因此,最好只在绝对必要的情况下使用这个选项,因为它很容易导致生成大量的着色器变体。
最后,构建管线会经过一个称为去重(deduplication)的过程,识别在同一通道(Pass)中的相同变体,并确保它们指向相同的字节码。这样可以减少磁盘上的空间占用,但相同的变体仍然会对构建时间、加载时间和运行时内存使用产生负面影响,因此它不能替代正确的变体剥离。
在成功构建后,我们可以查看 Editor.log 文件,收集一些关于构建中包含了哪些着色器变体的有用信息。要做到这一点,可以在日志文件中搜索 “Compiling shader” 和着色器名称。这是一个示例,看起来是这样的:
Compiling shader "GameShaders/MyShader" pass "Pass 1" (vp) Full variant space: 608 After settings filtering: 608 After built-in stripping: 528 After scriptable stripping: 528 Processed in 0.00 seconds starting compilation... finished in 0.02 seconds. Local cache hits 528 (0.16s CPU time), remote cache hits 0 (0.00s CPU time), compiled 0 variants (0.00s CPU time), skipped 0 variants
在某些情况下,你可能会发现经过设置过滤步骤后,变体数量有所增加,例如,如果项目启用了 XR。
如果游戏支持多个图形 API,你还会找到每个支持的渲染器的信息:
Serialized binary data for shader GameShaders/MyShader in 0.00s gles3 (total internal programs: 290, unique: 193) vulkan (total internal programs: 290, unique: 193)
最后,你会看到这些压缩日志,它们会指示特定图形 API 的着色器在磁盘上的最终大小。
Compressed shader 'GameShaders/MyShader' on vulkan from 1.35MB to 0.19MB
如果你正在使用通用渲染管线 (URP),可以选择是否只生成 SRP 着色器的日志、是否生成所有着色器的日志,或者禁用日志。要进行这些设置,请在项目设置中选择“图形(Graphics) > URP 全局设置 (URP Global Settings)”下的日志级别 (Log Level)。

*在 URP 全局设置(URP Global Settings)中设置日志级别(Log Level)
此外,如果你选择下面的“导出着色器变体 (Export Shader Variants)”选项,构建完成后将生成一个包含着色器变体编译报告的 JSON 文件。这在 Unity 2022.2 或更新版本中可用。
确定运行时使用哪些变体
要了解在运行时实际为 GPU 编译了哪些着色器,可以启用“记录着色器编译(Log Shader Compilation)”选项,位于项目设置(Project Settings)> 图形(Graphics)下。

*启用图形项目设置(Graphics Project Settings)中的记录着色器编译(Log Shader Compilation)选项
只要在游戏过程中编译了着色器,就会在玩家日志中打印出来。如工具提示所述,它仅适用于开发构建和 Debug 模式。
格式如下:
Compiled Shader: Folder/ShaderName, pass: PASS_NAME, stage: STAGE_NAME, keywords ACTIVE_KEYWORD_1 ACTIVE_KEYWORD_2
请注意,某些平台(如 Android)会缓存已编译的着色器。因此,在测试之前,你可能需要卸载并重新安装游戏,以捕获所有已编译的着色器。
最后,你可以使用内存分析器(Memory Profiler)包在游戏运行时捕获快照,然后概览当前加载到内存中的着色器及其大小。按大小排序通常可以很好地说明哪些着色器生成的变体最多,值得优化。

*内存分析器(Memory Profiler)中的着色器概览
基于图形设置的剥离
作为剥离过程的一部分,Unity 会移除与游戏未使用的图形功能相关的着色器变体。如果使用的是内置渲染管线(Built-in Render Pipeline)或通用渲染管线(URP),这个过程会有所不同。
要定义这些设置,可以进入项目设置(Project Settings)> 图形(Graphics)。在这里,使用内置渲染管线时,可以选择游戏支持的光照贴图(Lightmap)和雾效(Fog)模式。

*图形着色器剥离设置
将它们设置为“自动(Automatic)”让 Unity 根据构建中包含的场景确定需要剥离的着色器变体。
如果不确定正在使用哪些功能,也可以使用“从当前场景导入(Import from Current Scene)”按钮让 Unity 来确定需要哪些功能。当然,这只有在所有场景都使用相同设置的情况下才有帮助,因此在使用此选项时,请确保选择一个具有代表性的场景。
如果使用的是 URP,其中的一些选项将被隐藏。这时可以直接在管线设置(Pipeline Settings)配置文件中定义游戏所需的功能。
例如,禁用 Terrain Holes 会导致所有 Terrain Holes 着色器变体被剥离,虽然这样也会减少构建时间。
URP 提供了更精细的控制,可以选择在游戏中包含哪些功能,从而减少未使用的变体,实现更优化的构建。
根据图形层级进行剥离
注意:这仅适用于使用内置渲染管线的情况。当使用可编程渲染管线(如URP)时,这些设置将被忽略。
图形层级(Graphics tiers )用于根据游戏运行的硬件应用不同的图形设置(与质量设置( Quality Settings )不同)。当游戏启动时,Unity 会根据硬件能力、图形API 和其他因素确定设备的图形层级。
可以在项目设置(Project Settings)> 图形(Graphics)>层级设置(Tier Settings)中进行设置。
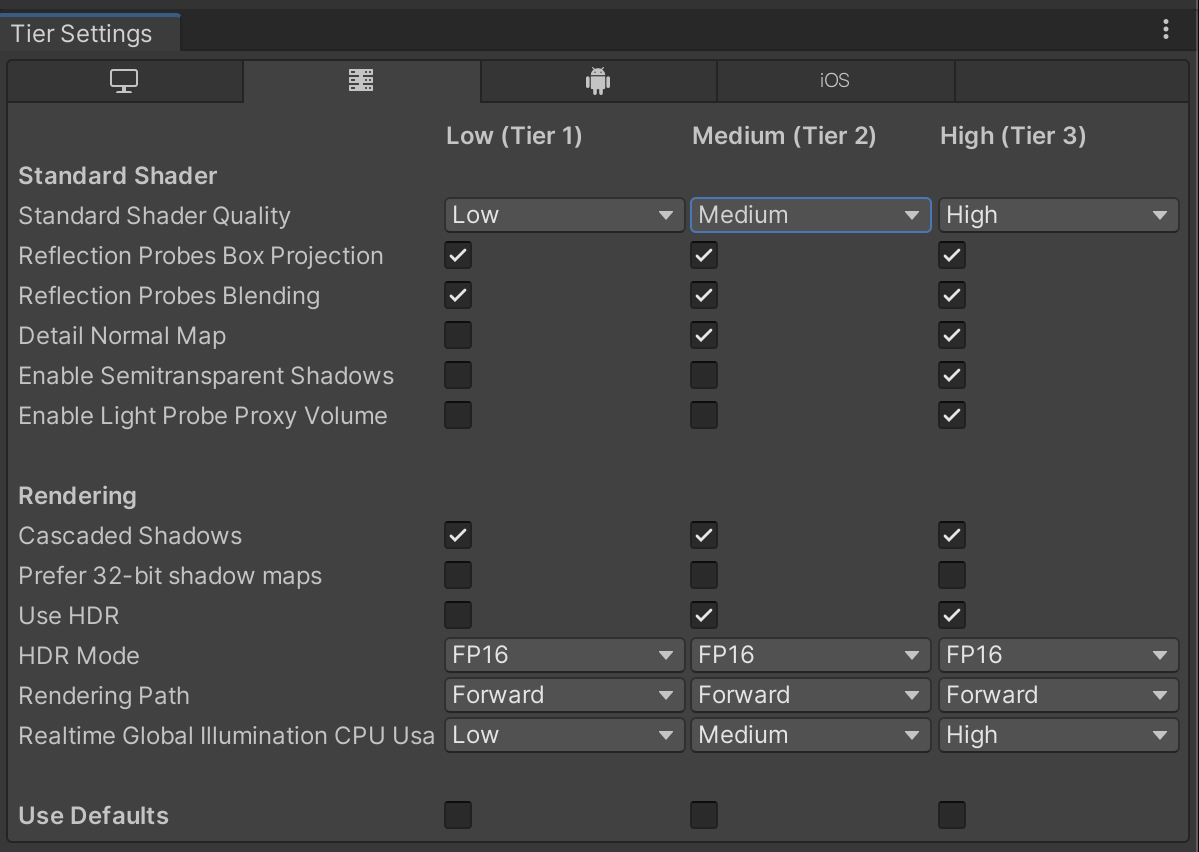
*图形层级设置
在此基础上,Unity 会为所有着色器添加了以下三个关键字:
UNITY_HARDWARE_TIER1
UNITY_HARDWARE_TIER2
UNITY_HARDWARE_TIER3
然后,它会为定义的每个图形层级生成着色器变体。如果不使用图形层级并希望避免使用相关的变体,则需要确保所有图形层级的设置完全相同,这样 Unity 就会跳过这些变体。
如前所述,Unity 会尝试删除重复的变体,因此,如果三个层级中有两个层级的设置相同,虽然仍会生成所有变体,但导致磁盘大小减小。你可以选择性地强制Unity 为特定的着色器和图形渲染 API 生成层级变体,例如使用以下方式指定:
// Direct3D 11/12 #pragma hardware_tier_variants d3d11
根据图形 API 进行剥离
Unity 会为构建中包含的每个图形 API 编译一套着色器变体,因此在某些情况下,手动选择并排除不需要的 API 是更好的选择。
要进行这样的设置,请前往 Project Settings > Player。默认情况下,“自动图形 API(Auto Graphics API)”会被选中,Unity 会包含一组内置的图形 API,并根据设备的能力在运行时选择其中一个。例如,在 Android 上,Unity首先尝试使用 Vulkan,如果设备不支持,则引擎会回退到 GLES3.2、GLES3.1 或 GLES3.0(尽管这些GLES 版本上的变体是相同的)。
否则为相关平台禁用“自动图形 API(Auto Graphics API)”,并手动选择要包含的 API。Unity会优先使用列表中排在第一位的 API。

*禁用“自动图形 API(Auto Graphics API)”以选择要优先使用的 API
缺点是可能会限制支持游戏的设备数量,因此在更改这个设置时,确保你知道自己在做什么,并在各种设备上进行测试。
严格的着色器变体匹配
通常在运行时,如果没有找到完全匹配的变体或者在运行版构建中已经被剥离,Unity 会尝试加载最接近所请求的关键字集合的变体。虽然这很方便,但这种做法也可能掩盖着色器关键字设置中的潜在问题。
从 Unity 2022.3 开始,你可以在 Project Settings > Player 中选择“严格的着色器变体匹配(Strict Shader Variant Matching)”选项,以确保 Unity 只尝试加载与所需本地和全局关键字组合完全匹配的变体。

*在项目设置(Project Settings)中启用“严格的着色器变体匹配(Strict Shader Variant Matching)”
如果没有找到匹配项,Unity 将使用 Error Shader 并在控制台中打印错误信息,包括着色器、子着色器索引、实际通道和请求的关键字。当需要追踪实际上需要但缺失的变体时,这非常方便。和其他剥离操作一样,这仅在 Player 中生效,对 Editor 没有影响。
将使用的变体导出到着色器变体集合(Shader Variants Collection)中
在编辑器中运行游戏时,Unity 会跟踪当前场景中使用的着色器和变体,并允许你将它们导出到一个集合中。要进行此操作,请导航到项目设置(Project Settings)> 图形(Graphics)。在底部,你会看到一个着色器加载部分,显示当前正在被使用的着色器数量。
集合链接:
https://docs.unity3d.com/Manual/shader-variant-collections.html
确保事先点击“清除(Clear)”按钮以获得更准确的样本,然后进入运行(Play)模式并与场景进行交互,确保所有需要特定着色器的游戏元素都能正常工作。这将增加被跟踪的计数器。然后,点击“保存到资产...(Save to asset…)”按钮,将所有这些保存到一个集合资产中。

*Save to asset 按钮
着色器变体集合(Shader Variants Collections)是包含着色器及其相关变体列表的资源。它们通常用于预定义要在构建中包含的变体以及预热着色器。

*将着色器添加到着色器变体集合(Shader Variants Collection)中
在一些项目中使用的一种方法是为游戏的每个关卡运行此操作,为每个关卡保存一个集合,然后通过使用 IPreprocessShaders 脚本(在下一节中介绍)剥离任何在这些列表中不存在的变体。尽管这种方法很方便,在我看来也容易出现错误。因为很难确保在单次游戏过程中用到所有需要的变体,有些功能可能仅在设备上加载并在特定情况下出现,导致生成的列表并不一定准确。随着游戏内容的变化和新元素添加到关卡或材质的变更,集合需要不断更新。因此,我建议主要将其用于调试和研究目的,而不是直接集成到构建流程中。
可编程着色器变体剥离
每当着色器即将编译到游戏构建中时,Unity 都会发出一个回调。运行版(Player)和 Asset Bundles 构建时都会发生这种情况。我们可以使用 IPreprocessShaders.OnProcessShader 和 IPreprocessComputeShaders.OnProcessComputeShader(用于计算着色器 compute shader)方便地监听这些回调,并添加自定义逻辑以剥离不必要的变体。这样,我们就能大大缩短构建时间、缩小构建规模,并减少进入构建的变体总数。
为此,请创建一个实现 IPreprocessShaders 接口的脚本,然后在 OnProcessShaders 中编写剥离逻辑。例如,下面的脚本将剥离发布版构建中所有包含 DEBUG 着色器关键字的变体:
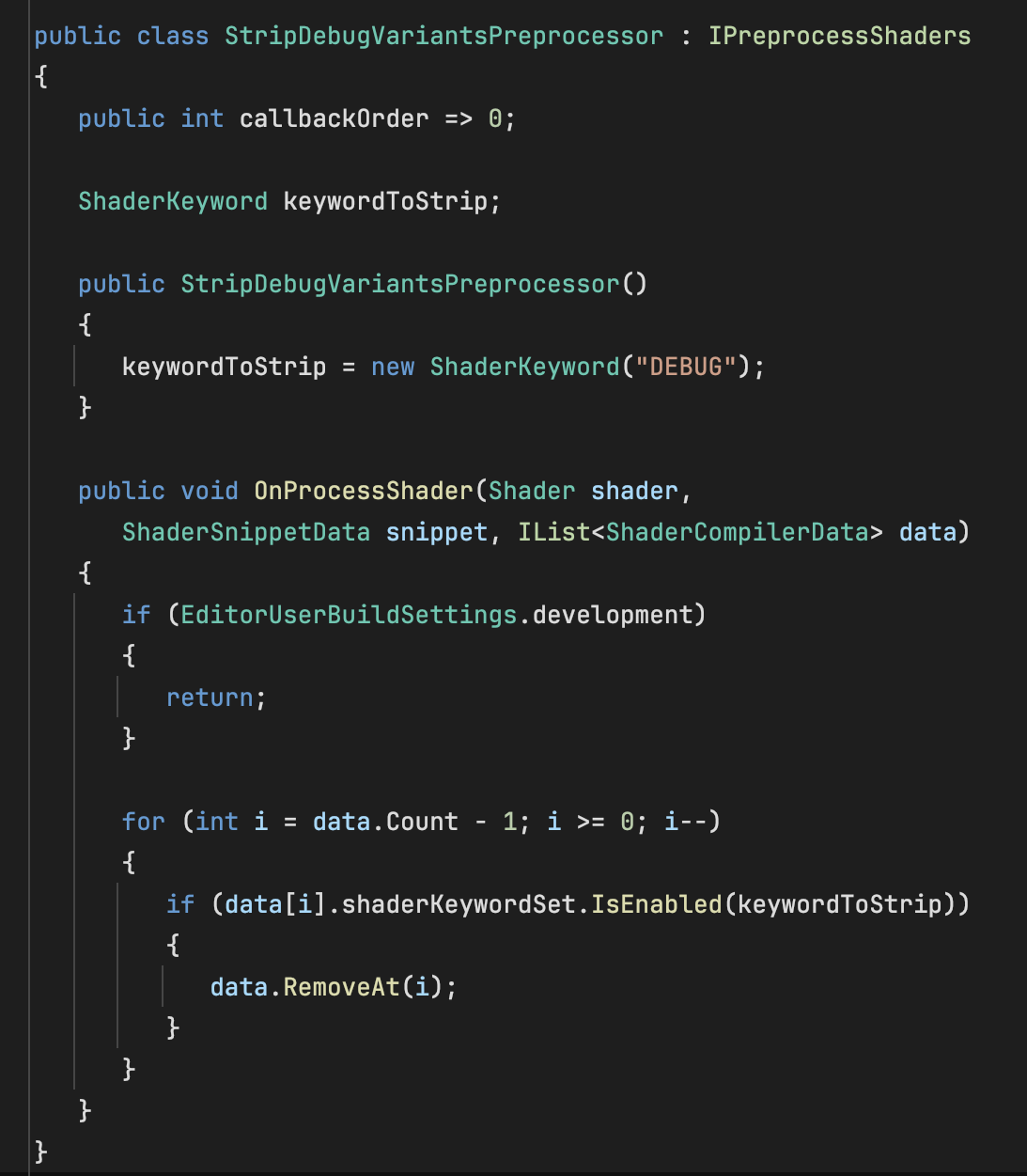
*剥离所有包含 DEBUG 着色器关键字变体的脚本
回调顺序让你能够定义预处理脚本的执行顺序,从而创建多步剥离过程。优先级较低的脚本将首先执行。
相关文章:
Unity Shader变体优化与故障排除技巧
在 Unity 中编写着色器时,我们可以方便地在一个源文件中包含多个特性、通道和分支逻辑。在构建时,着色器源文件会被编译成着色器程序,这些程序包含一个或多个变体。变体是该着色器在满足一组条件后生成的版本,这通常会导致线性执行…...

数据结构——时间复杂度和空间复杂度
目录 时间复杂度 什么是时间复杂度 常见时间复杂度类型 如何计算时间复杂度 空间复杂度 什么是空间复杂度 常见的空间复杂度类型 如何计算空间复杂度 时间复杂度和空间复杂度是评估算法性能的两个重要指标。 时间复杂度 什么是时间复杂度 时间复杂度描述了算法执行所需…...

(echarts) 饼图设置滚动图例
(echarts) 饼图设置滚动图例 效果: 代码: // 图例 legend: {type: scroll,orient: vertical,right: 10,top: 20,bottom: 20,data: data.legendData},参考:官网-可滚动的图例 https://echarts.apache.org/examples/zh/editor.html?cpie-leg…...

Java spring SSM框架--mybatis
一、介绍 Spring 框架是一个资源整合的框架,可以整合一切可以整合的资源(Spring 自身和第三方),是一个庞大的生态,包含很多子框架:Spring Framework、Spring Boot、Spring Data、Spring Cloud…… 其中Spr…...

Python知识点:如何使用Arduino与Python进行物联网项目
Arduino和Python是物联网(IoT)项目中常用的两种技术。Arduino是一个开源的硬件平台,而Python是一种高级编程语言,它们可以结合使用来创建各种智能设备和系统。以下是使用Arduino和Python进行物联网项目的一般步骤: 确定项目需求: …...

论文复现_从 CONAN 中收集 TPL 数据集
1. 概述 CONAN:Conan是一个用于C项目的开源包管理工具。 它的主要目标是简化C项目的依赖关系管理过程,使开发人员能够更轻松地集成、构建和分享C库。 其中有一些比较独特的功能,例如:版本管理、第三方库管理等。 TPL 数据集&…...

使用Docker将Java项目打包并部署到CentOS服务器的详细教程。
当然,让我们将上述步骤进一步细化,以便更好地理解整个过程。 前提条件 一个Java项目CentOS服务器,并且已安装DockerJava项目可以正常在本地运行具有服务器访问权限 ———————————————————————————————————…...

嘉立创eda布线宽度
https://prodocs.lceda.cn/cn/pcb/route-routing-width/#%E5%B8%83%E7%BA%BF%E5%AE%BD%E5%BA%A6...

硬件面试经典 100 题(31~50 题)
31、多级放大电路的级间耦合方式有哪几种?哪种耦合方式的电路零点偏移最严重?哪种耦合方式可以实现阻抗变换? 有三种耦合方式:直接耦合、阻容耦合、变压器耦合。直接耦合的电路零点漂移最严重,变压器耦合的电路可以实现…...

5G:下一代无线通信技术的全面解析
随着科技的不断进步,移动通信技术也在飞速发展。从2G到4G,我们见证了无线网络的巨大变革,而现在,5G已经悄然来临。作为下一代无线通信技术,5G不仅将带来更快的速度和更低的延迟,还将开启全新的应用场景和商…...

关于refresh_token
前文介绍过jwt的一般使用场景,用户登录成功后获得jwt,其中包含用户相关信息,主要是在前端要用到的属性(比如姓名、应用角色[这个前端后都用得着]等)、在后端要用到的属性(比如登录IP、终端唯一标识…...

Linux网络:基于OS的网络架构
Linux网络:OS视角下的网络架构 网络分层模型OSI 七层模型TCP/IP 五层模型 协议操作系统与网络网络相关命令ifconfigpingnetstat 本博客将基于操作系统,讲解计算机网络的设计理念,帮助大家理解操作系统与网络之间的关系。 网络分层模型 网络…...

UEC++学习(十六)变量添加中文注释、ui设置中文文本
(一)变量添加中文注释 在C 项目中创建变量,并在蓝图中显示变量的英文名同时附带中文注释,可以使用UPROPERTY 的 ToolTip 元数据属性来实现 UPROPERTY(EditAnywhere, meta (ToolTip "弹夹最大容量"))int32 MagCapacit…...

Redis延迟双删
1、何为延时双删 Redis延迟双删是一种在数据更新操作中确保缓存与数据库数据一致性的策略,通过两次缓存删除操作间隔一段延时来减少数据不一致的问题。 在并发环境下,多个请求同时对同一数据进行读写时,如果没有妥善处理,很容易…...

WO Mic 手机变身免费麦克风
目录 一、主要特点 1.支持多种连接方式 2.应用广泛 3.低延迟 4.简易配置 5.自动连接 6.音频格式 二、软件下载 三、软件安装 四、系统连接 五、测试 直播的时候,上课的时候,会议的时候……突然发现没有麦克风或者电脑麦克风有故障,这可怎么办呢?今天给大家介绍一…...

MQ死信对列
面试题:你们是如何保证消息不丢失的? 1、什么是死信 死信就是消息在特定场景下的一种表现形式,这些场景包括: 1. 消息被拒绝访问,即消费者返回 basicNack 的信号时 或者拒绝basicReject 2. 消费者发生异常࿰…...

springboot乡镇小区管理系统-计算机毕业设计源码73685
摘 要 过去使用手工的管理方式对乡镇小区进行管理,造成了管理繁琐、难以维护等问题,如今使用计算机对停车场停车的各项基本信息进行管理,比起手工管理来说既方便又简单,而且具有易于管理、搜索速度快、存储量大等多个优点。将其使…...

基于vue框架的4S店汽车维修保养管理系统28a7y(程序+源码+数据库+调试部署+开发环境)系统界面在最后面。
系统程序文件列表 项目功能:客户,技师,车辆信息,财务,客户维修,维修分配,维修订单,保养预约,保养分配,保养订单,维修费用,保养费用 开题报告内容 基于Vue框架的4S店汽车维修保养管理系统 开题报告 一、项目背景与意义 随着汽车产业的迅猛发展,4S店作…...
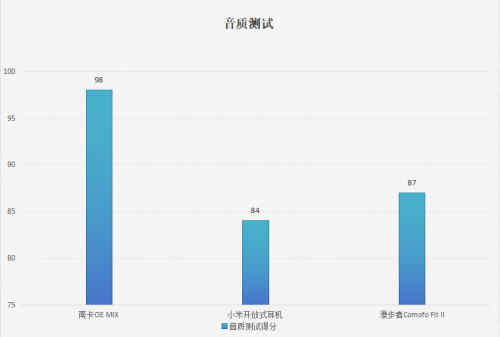
小米开放式耳机值得买吗?南卡、小米、漫步者一周横评
大家好,最近对开放式耳机比较感兴趣,作为一名数码博主以及多年的耳机发烧友,今天想给大家测评一下开放式耳机,这类耳机目前在数码圈非常火热!很多喜欢运动的小伙伴都选择了这款耳机,搭配运动场景听歌&…...

解决oracel锁表问题;SQL 错误 [54] [61000]: ORA-00054: 资源正忙
问题描述; SQL 错误 [54] [61000]: ORA-00054: 资源正忙, 但指定以 NOWAIT 方式获取资源, 或者超时失效 select session_id from v$locked_object;查看这些 session_id 对应的会话的详细信息,包括用户名、机器名、程序等,9596等是select se…...

PyTorch RMSprop优化器报错怎么办?教你一招避坑
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 PyTorch RMSprop优化器报错深度解析:一招解决常见陷阱目录PyTorch RMSprop优化器报错深度解析:一招解决常…...

Android多媒体开发避坑:深入理解DMABUF机制与RK3588上的常见泄漏点
Android多媒体开发中的DMABUF机制解析与RK3588内存泄漏实战指南 在RK3588这类高性能芯片上开发视频编解码、相机等多媒体应用时,追求零拷贝性能优化往往会引入DMABUF的使用。然而,这种看似完美的解决方案背后隐藏着复杂的内存管理陷阱。本文将带您深入理…...

Unity ShaderGraph环境搭建避坑指南:URP/HDRP渲染管线匹配
1. 为什么“环境搭建”是ShaderGraph学习路上第一个真坑 很多人点开Unity ShaderGraph教程,第一眼看到“创建Sub Graph”“连接Base Color节点”,心里一热:这不就是拖拖拽帖?比写HLSL简单多了!结果双击打开Shader Gra…...

基于周期性折射率调制的微型高分辨率光纤光谱仪技术解析
1. 项目概述:当光谱仪“瘦身”遇上“高能”挑战在材料分析实验室里,你可能会看到一台冰箱大小的光谱仪,它需要稳定的光学平台、恒温恒湿的环境,以及一位经验丰富的操作员。而在农田、生产线旁,或者野外环境监测站&…...

DataStore vs SharedPreferences 迁移指南:告别 ANR,拥抱类型安全
DataStore vs SharedPreferences 迁移指南:告别 ANR,拥抱类型安全 一句话收益:掌握从 SharedPreferences 迁移到 Jetpack DataStore 的完整路径,彻底消除主线程 I/O 阻塞与类型安全隐患。 适用版本:Android API 21&…...

90%的小程序死于“搜不到”:微信搜索排名优化全拆解
在微信生态里,小程序早已不是“有没有”的问题,而是“能不能被找到”的问题。用户搜索关键词时,你的小程序排在第几位,直接决定了流量的天花板。很多人以为排名靠运气,其实背后有一套可复制的优化逻辑。一、名称是最大…...

React Props:深入解析组件间的数据传递
React Props:深入解析组件间的数据传递 在React中,组件间的数据传递是构建复杂应用的关键。Props(属性)是React组件间数据传递的主要方式,它允许父组件向子组件传递数据。本文将深入探讨React Props的概念、使用方法以及注意事项。 一、Props的概念 Props是React组件的…...

Unity游戏运行时自动翻译引擎原理与实战配置
1. 为什么Unity游戏翻译不能只靠“改文本”——XUnity.AutoTranslator不是插件,而是运行时翻译引擎 你有没有试过打开一个Unity游戏的Assets文件夹,用文本编辑器搜索中文字符串,然后手动替换成英文?我试过三次,每次都在…...

【独家首发】DeepSeek-VL与R1双模型事实校验对照实验:1276条权威知识链验证,误差分布首次公开
更多请点击: https://kaifayun.com 第一章:DeepSeek事实准确性测试 为系统评估 DeepSeek-R1 模型在开放域事实性问答中的表现,我们构建了覆盖科学、历史、技术与常识四大领域的 1,200 条人工校验真值(ground-truth)测…...
3个步骤快速掌握Py Eddy Tracker:海洋中尺度涡旋识别与追踪的完整解决方案
3个步骤快速掌握Py Eddy Tracker:海洋中尺度涡旋识别与追踪的完整解决方案 【免费下载链接】py-eddy-tracker Eddy identification and tracking 项目地址: https://gitcode.com/gh_mirrors/py/py-eddy-tracker Py Eddy Tracker是一个专门用于海洋中尺度涡旋…...