24/8/15算法笔记 dp策略迭代 价值迭代
-
策略迭代:
- 策略迭代从某个策略开始,计算该策略下的状态价值函数。
- 它交替进行两个步骤:策略评估(Policy Evaluation)和策略改进(Policy Improvement)。
- 在策略评估阶段,计算给定策略下每个状态的期望回报。
- 在策略改进阶段,尝试找到一个更好的策略,该策略对于每个状态选择最优动作。
- 这个过程一直进行,直到策略收敛,即不再有改进的空间。
-
价值迭代:
- 价值迭代直接迭代状态价值函数,而不是策略。
- 它从任意状态价值函数开始,然后迭代更新每个状态的价值,直到收敛。
- 在每次迭代中,对所有状态使用贝尔曼最优性方程(Bellman Optimality Equation)来更新其价值。
- 价值迭代通常比策略迭代更快收敛到最优价值函数。
-
收敛性:
- 策略迭代保证在有限次迭代后收敛到最优策略和最优价值函数。
- 价值迭代也保证收敛,但收敛速度可能因问题而异。
-
计算复杂度:
- 策略迭代可能需要多次策略评估,每次评估都涉及对所有状态的操作,因此在某些情况下可能比较慢。
- 价值迭代每次迭代只更新一次所有状态的价值,但可能需要更多次迭代才能收敛。
-
适用性:
- 策略迭代在策略空间较大或状态转移概率较复杂时可能更有效。
- 价值迭代适用于状态空间较大且容易计算贝尔曼最优性方程的情况。
-
实现方式:
- 策略迭代通常使用循环,外部循环负责策略评估,内部循环负责策略改进。
- 价值迭代使用单一循环,每次迭代更新所有状态的价值。
策略迭代:
#获取一个格子的状态
def get_state(row,col):if row !=3:return'ground'if row ==3 and col ==0:return 'ground'if row==3 and col==11:return 'terminal'return 'trap'
get_state(0,0)地图上有平地,陷阱,终点
#在一个格子里做动作
def move(row,col,action):#如果当前已经在陷阱或者终点,则不能执行任何动作,反馈都是0if get_state(row,col)in['trap','terminal']:return row,col,0#向上if action==0:row-=1#向下if action ==1:row+=1#向左if action==2:col-=1#向右if action==3:col+=1#不允许走到地图外面去row = max(0,row)row = min(3,row)col =max(0,col)col =min(11,col)#是陷阱的话,奖励是-100,否则都是-1#这样强迫了机器尽快结束游戏,因为每走一步都要扣一分#结束最好是以走到终点的形式,避免被扣100分reward = -1if get_state(row,col)=='trap':reward -=100return row,col,reward
import numpy as np#初始化每个格子的价值
values = np.zeros([4,12])#初始化每个格子下采用动作的概率
pi = np.ones([4,12,4])*0.25values,pi[0]
#Q函数,求state,action的分数
#计算在一个状态下执行动作的分数
def get_qsa(row,col,action):#当前状态下执行动作,得到下一个状态和rewardnext_row,next_col,reward = move(row,col,action)#计算下一个状态分数,取values当中记录的分数即可,0.9是折扣因子value = values[next_row,next_col]*0.9#如果下个状态是终点或者陷阱,则下一个状态分数为0if get_state(next_row,next_col)in ['trap','terminal']:value = 0#动作的分数本身就是reward,加上下一个状态的分数return value + reward
get_qsa(0,0,0)-1.0
#策略评估
def get_values():#初始化一个新的values,重新评估所有格子的分数new_values = np.zeros([4,12])#遍历所有格子for row in range(4):for col in range(12):#计算当前格子4个动作分别的分数action_value = np.zeros(4)#遍历所有动作for action in range(4):action_value[action] = get_qsa(row,col,action)#每个动作的分数和它的概率相乘action_value *=pi[row,col]#最后这个格子的分数,等于该格子下所有动作的分数求和new_values[row,col] = action_value.sum()return new_values
get_values()
#策略提升函数
def get_pi():#重新初始化每个格子下采用动作的概率,重新评估new_pi = np.zeros([4,12,4])#遍历所有格子for row in range(4):for col in range(12):#计算当前格子4个动作分别的分数action_value = np.zeros(4)#遍历所有动作for action in range(4):action_value[action] = get_qsa(row,col,action)#计算当前状态下,达到最大分数的动作有几个count = (action_value == action_value.max()).sum()#让这些动作均分概率for action in range(4):if action_value[action]==action_value.max():new_pi[row,col,action] = 1/countelse:new_pi[row,col,action]=0return new_pi
get_pi()
#循环迭代策略评估和策略提升,寻找最优解
for _ in range(10):for _ in range(100):values = get_values()pi = get_pi()
values,pi
#打印游戏,方便测试
def show(row,col,action):graph=['','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','0','2','2','2','2','2', '2','2','2','2','2','1']action = {0:'上',1:'下',2:'左',3:'右'}[action]graph[row*12+col] = actiongraph=' '.join(graph)for i in range(0,4*12,12):print(graph[i:i+12])show(1,1,0)#测试函数
from IPython import display
import timedef test():#起点在0,0row = 0col = 0#最多玩N步for _ in range(200):#选择一个动作action = np.random.choice(np.arange(4),size = 1,p=pi[row,col])[0]#打印这个动作display.clear_output(wait = True)time.sleep(1)show(row,col,action)#执行动作row,col,reward = move(row,col,action)#获取当前状态,如果状态是终点或者掉到陷阱则终止if get_state(row,col) in ['trap','terminal']:break
test()价值迭代算法:
def get_values():#初始化一个新的values,重新评估所有格子的分数new_values = np.zeros([4,12])#遍历所有格子for row in range(4):for col in range(12):#计算当前格子4个动作分别的分数action_value = np.zeros(4)#遍历所有动作for action in range(4):action_value[action] = get_qsa(row,col,action)"""和策略迭代算法唯一的不同点"""#求每一个格子的分数,等于该格子下所有动作的最大分数new_values[row,col] = action_value.max()return new_values
get_values()
相关文章:
24/8/15算法笔记 dp策略迭代 价值迭代
策略迭代: 策略迭代从某个策略开始,计算该策略下的状态价值函数。它交替进行两个步骤:策略评估(Policy Evaluation)和策略改进(Policy Improvement)。在策略评估阶段,计算给定策略下…...

【MMdetection改进】换遍MMDET主干网络之SwinTransformer-Tiny(基于MMdetection)
OpenMMLab 2.0 体系中 MMYOLO、MMDetection、MMClassification、MMSelfsup 中的模型注册表都继承自 MMEngine 中的根注册表,允许这些 OpenMMLab 开源库直接使用彼此已经实现的模块。 因此用户可以在MMYOLO 中使用来自 MMDetection、MMClassification、MMSelfsup 的主…...

FL Studio21.2.4最新中文版免费下载汉化包破解补丁
🎉 FL Studio 21中文版新功能全解析!让你的音乐制作更加高效! 嘿,各位音乐制作的小伙伴儿们,今天我要安利一款你们绝对会爱上的神器——FL Studio 21中文版!这款软件不仅功能强大,而且操作简便…...

私域场景中的数字化营销秘诀
在当今的商业世界,私域场景的营销变得愈发重要。今天咱们就来深入探讨一下私域场景中的几个关键营销手段。 一、会员管理与营销 企业一旦拥有完善的会员体系,数字化手段就能大放异彩。它可以助力企业对会员进行精细划分,深度了解会员的消费…...

一键换肤(Echarts 自定义主题)
一键换肤(Echarts 自定义主题) 一、使用官方主题配置工具 官方主题配置工具:https://echarts.apache.org/zh/theme-builder.html 如果以上主题不满足使用,可以自己自定义主题 例如:修改背景、标题等,可…...
Unity 6 预览版正式发布
Unity 6 预览版发布啦,正式版本将于今年晚些时候正式发布! 下载链接: https://unity.com/releases/editor/whats-new/6000.0.0 Unity 6 预览版是 Unity 6 开发周期的最后一个版本,在去年 11 月 Unite 大会上,我们宣…...

如何跳过极狐GitLab 密钥推送保护功能?
极狐GitLab 是 GitLab 在中国的发行版,专门面向中国程序员和企业提供企业级一体化 DevOps 平台,用来帮助用户实现需求管理、源代码托管、CI/CD、安全合规,而且所有的操作都是在一个平台上进行,省事省心省钱。可以一键安装极狐GitL…...
Android高版本抓包总结
方案1 CharlesVirtualXposedJustTrustMe 推荐使用三星手机此方案 VirtualXposed下载链接:https://github.com/android-hacker/VirtualXposed/releases JustTrustMe下载链接:https://github.com/Fuzion24/JustTrustMe/releases/ 下载完成后使用adb命令…...
《AI视频类工具之五—— 开拍》
一.简介 官网:开拍 - 用AI制作口播视频用AI制作口播视频https://www.kaipai.com/home?ref=ai-bot.cn 开拍是一款由美图公司在2023年推出,利用AI技术制作的短视频分享应用。这款工具通过AI赋能,为用户提供了从文案创作、视频拍摄到视频剪辑、包装的一站式解决方案,极大地…...

面试经典算法150题系列-最后一个单词的长度
最后一个单词的长度 给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。 单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。 示例 1: 输入:s "Hello World&qu…...

RTT学习
电源管理组件 嵌入式系统低功耗管理的目的在于满足用户对性能需求的前提下,尽可能降低系统功耗以延长设备待机时间。 高性能与有限的电池能量在嵌入式系统中矛盾最为突出,硬件低功耗设计与软件低功耗管理的联合应用成为了解决矛盾的有效手段。 现在的各…...
|附赠完整面试流程)
前端面试题(二十五)|附赠完整面试流程
📝📝今日分享:前端面试题系列继续更新啦! 🤔🤔面试题是什么呢?这份前端面试题主要是上海某银行的中级前端面试题,面试时长属实没想到,挺短的!但从整个面试流程…...

【分布式系统】关于主流的几款分布式链路追踪工具
Jaeger 标准化与兼容性: Jaeger 支持 OpenTracing 和 OpenTelemetry 标准,这意味着它可以与各种微服务架构和应用框架无缝集成,提供了广泛的兼容性和灵活性。 数据存储选项: Jaeger 支持多种数据存储后端,如 Cassandra…...

【吸引力法则】探究人生欲:追求深度体验与宇宙链接
文章目录 什么是人生欲?唤醒人生欲:克服配得感的三大障碍1 第一大障碍:法执的压制2 第二大障碍:家庭的继承2.1 家庭创伤的代际传递2.2 家庭文化基因的传递2.2.1 “成年人最大的美德是让自己的生活过得更加精彩。”2.2.2 荷欧波诺波…...

REST framework-通用视图[Generic views]
Django’s generic views… were developed as a shortcut for common usage patterns… They take certain common idioms and patterns found in view development and abstract them so that you can quickly write common views of data without having to repeat yourself…...

行驶证OCR识别接口如何用Java调用
一、什么是行驶证OCR识别接口? 传入行驶证照片,行驶证图片上的文字信息,返回包括所有人、品牌型号、住址、车牌号、发动机号码、车辆识别代号、注册日期、发证日期等信息。 行驶证 OCR 接口的主要作用是代替手动输入,提高信息录…...
8月15日笔记
masscan安装使用 首先需要有c编译器环境。查看是否有c编译器环境: gcc -v如果系统中已经安装了 GCC,这个命令将输出 GCC 的版本信息。如果未安装,你会看到类似于 “command not found” 的错误消息。 如果没有下载,使用如下命令…...

CSS3 圆角
CSS3 圆角 引言 在网页设计中,圆角矩形是一种常见的设计元素,它们为页面带来了柔和的视觉体验。随着CSS3的推出,实现圆角矩形变得异常简单,无需依赖图片或复杂的JavaScript代码。本文将详细介绍CSS3中用于创建圆角矩形的border-…...
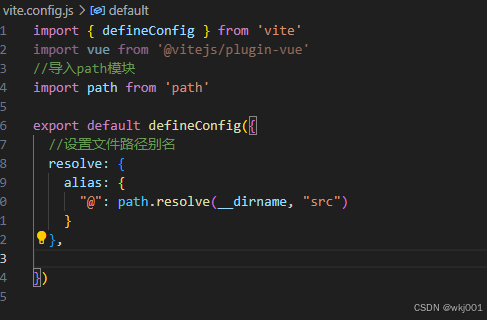
VUE项目中main.js中不能使用 @引入路径吗
VUE项目中main.js中不能使用 引入路径吗 vite.config已经配置了别名 但是在main.js中直接引入报错 修改成 相对路径后,保存消失 找到原因:vite.config 漏了引入 import { defineConfig } from ‘vite’ import vue from ‘vitejs/plugin-vue’ 导致…...

Spring日志
1.日志的作用 定位和发现问题(主要)系统监控数据采集日志审计...... 2.日志的使用 2.1 ⽇志格式的说明 2.2 打印日志 Spring集成了日志框架,直接使用即可 步骤: 1.定义日志对象 2.使⽤⽇志对象打印⽇志 RestController public class LoggerController {private static Logger…...

Claude Code 之父:2026 年我一行代码都没写,编程已被 AI 解决
2026 年,你还在一行一行敲代码吗?Claude Code 的创造者、Anthropic 核心人物 Boris Cherny,在公开访谈里抛出一句让整个行业震动的话:2026 年到现在,我没有写过一行代码。所有开发工作,100% 交给 AI 代理完…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

销售怎么通过各种方法获取电话号码
第一种就是那个用爬虫电话号码,然后再打电话给客户。第二种是在别人的挪车电话看车挪车电话,然后再打电话找客户。第三就是。扫楼一顿顿的扫,第四就是这个那种商店,一个个的去问陌拜地推一个个的问店子要不要贷款,去问…...

航空航天为什么离不开高强镁合金?国产替代到哪一步了
飞机每减重一千克,全年大约节省四千两百美元的燃油费用——这是航空工程师熟悉的经验值。在商业航空领域,这个数字还只是财务账;在战斗机、导弹和卫星的世界里,减重的收益被换算成更远的航程、更大的载荷、更高的机动性࿰…...

PCB虚焊/走线断裂/焊盘脱落工程师易漏判
PCB 故障中,30% 并非元件损坏,而是 PCB 本身的隐性故障—— 虚焊、走线断裂、焊盘脱落、过孔开路。这类故障外观隐蔽、时好时坏、排查难度大,很多工程师反复更换元件仍无法解决,最终误判为 “板报废”。一、PCB 隐性故障核心成因…...

2026年一键生成论文工具对比实测:5款神器从选题到格式全流程护航
写论文的焦虑,是每个科研人和学生都心照不宣的“隐形压力”。选题无从下手,文献检索耗时费力,逻辑框架反复推翻,格式排版让人抓狂,查重降重更是像在和系统玩“猫鼠游戏”。2026年的AI工具早已不是过去那种“打字机”&a…...

基于Arduino与433MHz射频的智能灯光定时系统设计与实现
1. 项目概述:告别机械定时器,打造智能灯光管家家里前后院的照明,还有出门度假时屋内的几盏灯,过去一直靠四个老旧的机械定时器来管理。说实话,这玩意儿用起来真是费劲。它的核心问题在于“死板”——你设定好晚上7点开…...

不止于绘图:用GMT 6.4的`grdtrack`和`project`命令玩转地形剖面分析与可视化
不止于绘图:用GMT 6.4的grdtrack和project命令玩转地形剖面分析与可视化 当我们谈论地理空间分析时,很多人首先想到的是绘制精美的地图。但GMT(Generic Mapping Tools)的真正魅力在于它强大的地理计算能力。本文将带你超越基础绘图…...

基于PIC32单片机实现Android USB音频转SPDIF输出的DIY方案
1. 项目概述:为Android设备打造一个高保真SPDIF音频接口作为一名长期折腾嵌入式音频和家庭影院的玩家,我经常遇到一个痛点:手头那些性能不错的Android手机或平板,其内置的3.5mm耳机孔或者USB-C口的音频输出质量,在连接…...