数据结构中的堆
一、树的重要知识点
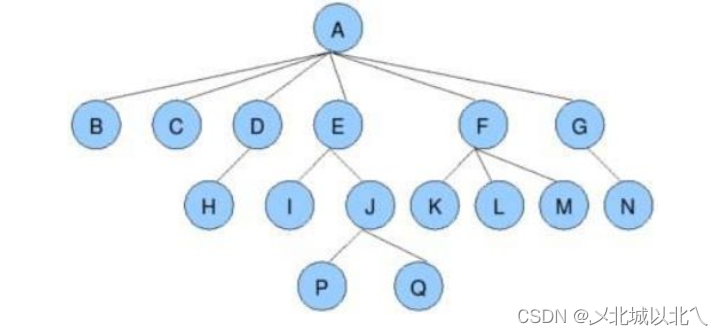
节点的度:一个节点含有的子树的个数称为该节点的度(有几个孩子)
叶节点或终端节点:度为0的节点称为叶节点;如上图:B、C、H、I...等节点为叶节点(0个孩子)
非终端节点或分支节点:度不为0的节点; 如上图:D、E、F、G...等节点为分支节点
父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 上图:A是B的父节点
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 上图:B是A的孩子节点
兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点(亲兄弟)
树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为6(最多有几个孩子)
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次; 如上图:树的高度为4(H表示,从1开始)
堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:H、I互为兄弟节点
节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
森林:由m(m>0)棵互不相交的树的集合称为森林;
二、二叉树

二叉树的度,孩子最多为2,可以是0、1、2,只有一个孩子是左/右孩子均可,上面是二叉树的所有可能组成部分。
1、完全二叉树&满二叉树

满二叉树有h层,且每层的结点都是满的。共 2^h-1个结点
完全二叉树有h层,前h-1层满,最后一层最少一个,结点n的范围是 2^(h-1)<=n<= 2^h-1
2、二叉树的性质 (几个公式)
首先,设孩子为0/1/2的结点总数分别为N0/N1/N2
可得 N0 = N2+1 该等式恒成立。 N1的数量是不确定的。
但是对于满二叉树。N1=0, 观察一下图就知道了。
对于完全二叉树,N1 = 0或1.
二叉树的深度H: H=logN(约等于),所以从上到下遍历一遍的时间复杂度为O(logN)
3、孩子与父亲的关系(互相查找)
假设将二叉树的结点,从上到下,从左到右,从0开始标记结点的个数,设孩子下标为child,父亲的下标为parent,则有以下关系
1、parent = (child-1)/ 2 左右孩子均满足
2、左孩子: child = 2*parent +1
3、右孩子: child = 2*parent +2
同时,如果结点总数为n,此时把n看作是下标,child必须<n,孩子结点才能存在,即 0~n-1
三、堆的概念
1、二叉树的顺序存储结构
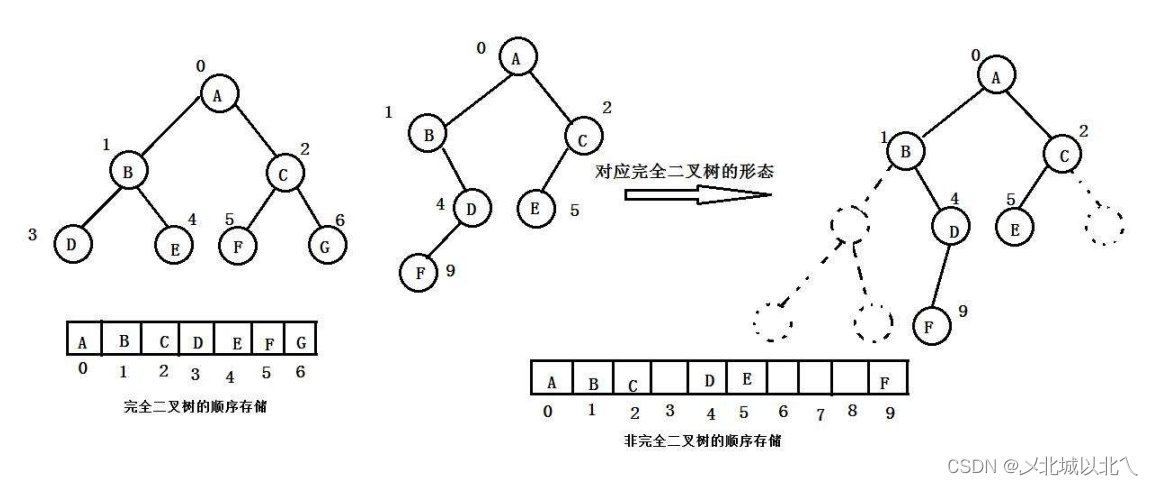
与链表类似,堆这种数据结构也是分为物理结构和逻辑结构。
逻辑结构上是一棵完全二叉树,物理结构上是顺序表。
上图中为普通二叉树的两种结构,如果不是完全二叉树,就会导致顺序表的空间浪费,例如:最下面一层如果只有最后一个结点存在,那么顺序表的一半左右大小的空间就会被浪费,而堆的产生,就是为了解决这种空间浪费的。完全二叉树的结构使其能更好的利用顺序的空间。
2、堆的分类

分为 大根堆和小根堆两种,即每个parent结点的val值的大小,都要比其child结点的val大或小。
四、堆的接口函数
typedef int HPDatatype;typedef struct Heap
{HPDatatype* a;int capacity;int size;
}HP;//堆的初始化
void HPInit(HP* php);
//堆的销毁
void HPDestroy(HP* php);
//入数据
void HPPush(HP* php, HPDatatype x);
//删除数据
void HPPop(HP* php);
//判断堆是否为空
bool HPEmpty(HP* php);
//返回堆中元素个数
int HPSize(HP* php);
//返回堆顶元素
HPDatatype HPTop(HP* php);
//交换2个数据
void Swap(HPDatatype* p1, HPDatatype* p2);
//向下调整
void AdjustDown(HPDatatype* a, int parent, int size);
//向上调整
void AdjustUp(HPDatatype* a, int child);
五、初始化
//堆的初始化
void HPInit(HP* php)
{assert(php);HPDatatype* tmp = (HPDatatype*)malloc(sizeof(HPDatatype) * 4);if (NULL == tmp){perror("malloc fail");return ;}php->a = tmp;php->capacity = 4;php->size = 0;}
堆的结构与顺序表类似,都是一个指针指向物理存储的数组,size表示现有数据的个数,capacity表示当前的容量。
malloc一段空间给指针a,然后调整size为0,capacity初始化为4个元素的大小。
六、插入数据

先判断物理空间上的存储是否足够,不够就增容。
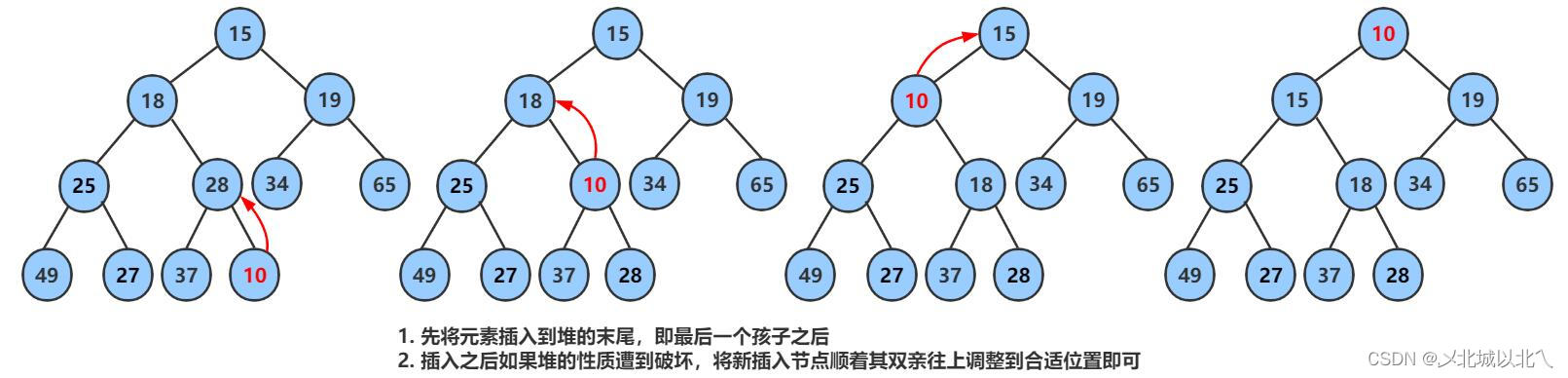
在size位置插入数据后,要对数据进行向上调整操作 (向上调整的原因是为了维持堆的结构,因为插入的数据的值的大小是不确定的,如果不调整就会破坏堆的结构,因此从第二个数据开始,就要不断向上调整)。
传入的参数为a指向的数组,以及刚刚插入的,要调整的数据的下标
七、向上调整函数

传入child下标,通过parent = (child-1)/2找到其父亲结点的下标位置,因为这里以大根堆为例,因此,只要a[child]>a[parent]就交换,交换完后,孩子变为原来的父亲,父亲继续找他的父亲,这样向上迭代,直到child变为0,即堆顶,它就是堆中最大的元素了,没有调整空间了。或者是不满足孩子大于父亲的条件,直接跳出了。
交换函数
只是实现简单的两个元素的数据交换,注意函数的返回值类型,以及传入的是地址。

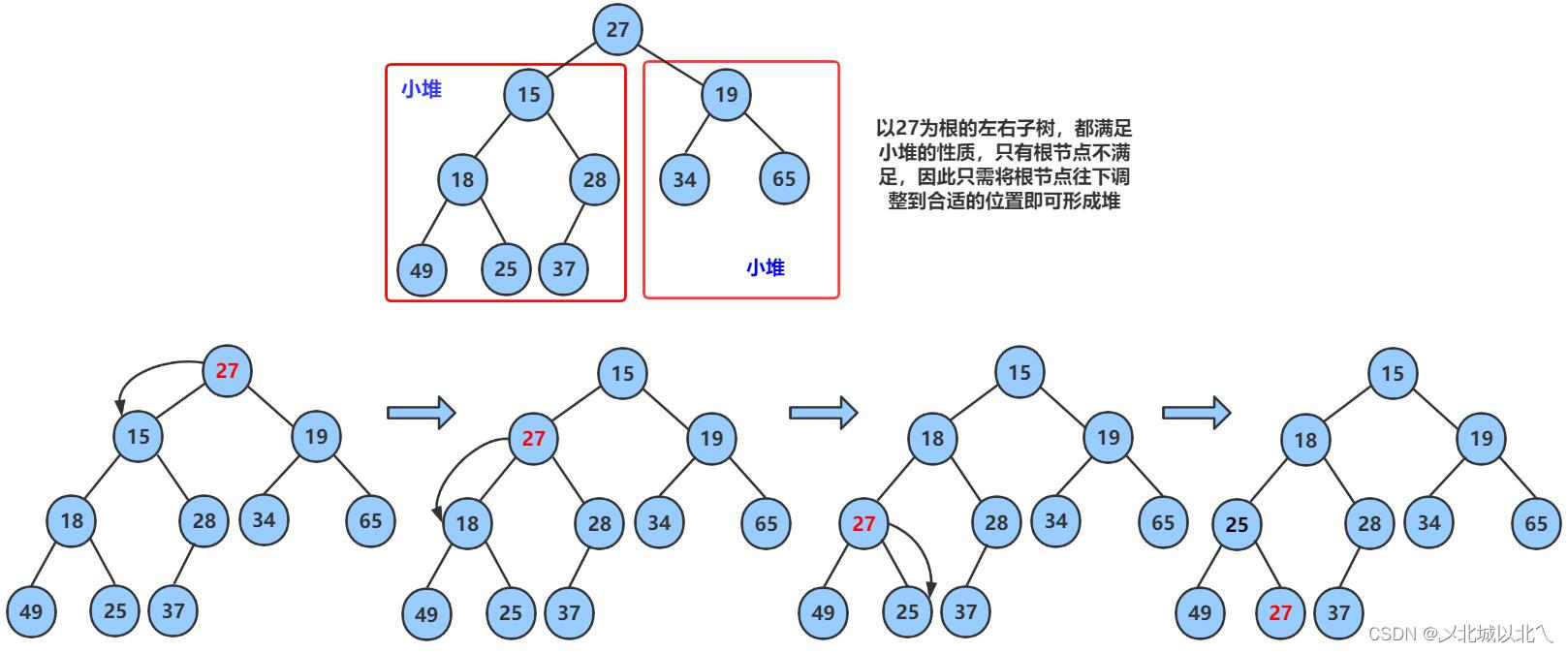
八、删除数据

一开始的size是删除前堆中元素的总数,我这里先让size--,使其指向被删除的那个元素,然后交换堆顶元素和要删除的元素,最后对堆顶的元素进行向下调整操作。
实现时可以改变顺序,但是一定要保证前后逻辑的统一,包括下面的向下调整函数的实现。
九、向下调整函数

这里的size接收的是pop函数中的size-1,即现在的size为向下调整的数据范围,共size个。
因为交换数据后,最大的数据来到数组的最后位置,我们只是通过size--来避免访问他,并没有真正的将它删除,因此原来在数组最后,现在在堆顶的那个元素,在向下调整时不能包含被删除的那个元素。
函数过程分析:parent为向下调整的那个元素,先通过 child = parent*2+1找到它的左孩子,进入循环后先判断一步,找出左右孩子中较大的那个,其中,child+1<size是为了保证右孩子也在数组范围内,如果不在,就默认为左孩子大了。
找出较大的孩子后,将其val值与parent比较,如果大于parent就交换,然后父亲变为孩子,孩子继续向下迭代找他的孩子,直到child>=size,超出数组范围。
十、返回个数、堆顶、销毁函数

这几个函数很简单,与前面的几种数据结构相似,这里不多陈述。
十一、测试结果

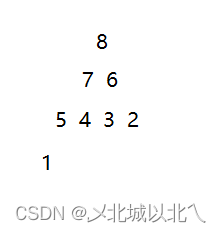
插入的结果为大堆。


由于删除后不会访问最后一个元素,所以除了原来的最大值8外,其它7个数字仍然满足大堆结构
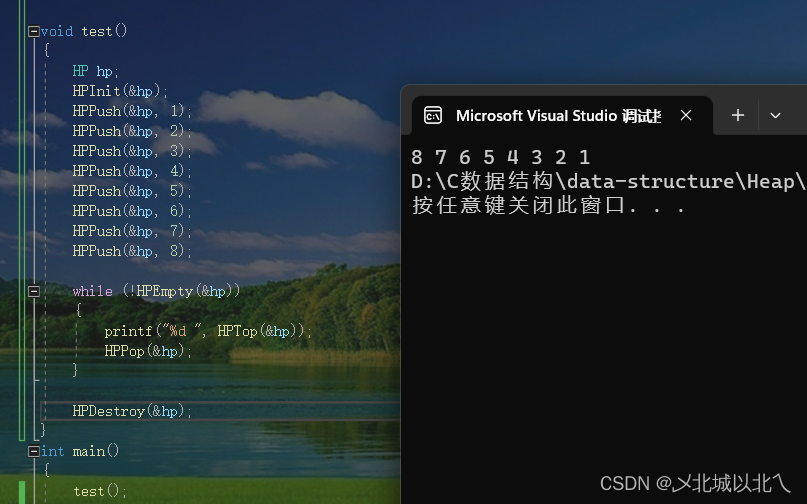
通过循环 取出堆顶元素+删除操作,可以获取所有堆顶元素。
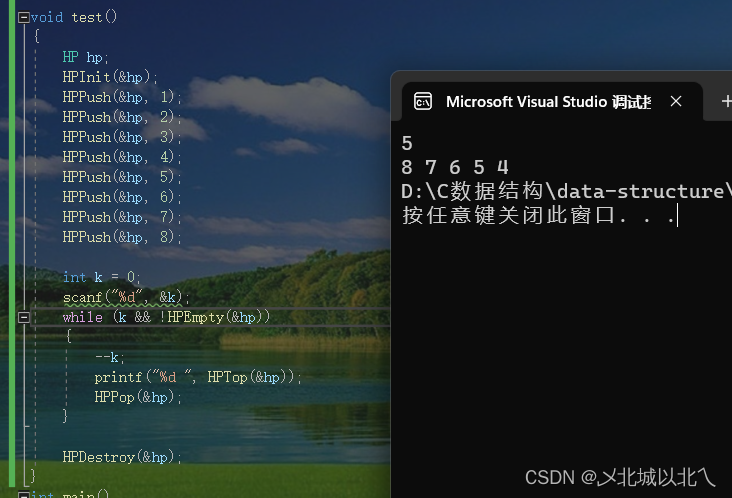 引入k变量可以取出k个堆顶元素,又因为堆顶元素都是堆中最大或最小的,因此可以解决后面的topk问题。
引入k变量可以取出k个堆顶元素,又因为堆顶元素都是堆中最大或最小的,因此可以解决后面的topk问题。
十二、函数实现具体代码
#include"Heap.h"//堆的初始化
void HPInit(HP* php)
{assert(php);HPDatatype* tmp = (HPDatatype*)malloc(sizeof(HPDatatype) * 4);if (NULL == tmp){perror("malloc fail");return ;}php->a = tmp;php->capacity = 4;php->size = 0;}//交换函数(交换父子数据)
void Swap(HPDatatype* p1, HPDatatype* p2)
{HPDatatype tmp = *p1;*p1 = *p2;*p2 = tmp;}//向上调整,任意传入一个下标,对它及其祖先进行向上调整,前提是左右子树都是 大/小堆
void AdjustUp(HPDatatype* a, int child)
{//chile 和 parent 都是下标的数字int parent = (child - 1) / 2;while (child > 0) //这里以大根堆为例(每个根都大于其子孙){if (a[child] > a[parent]){//若大于则向上调整交换Swap(&a[child], &a[parent]);//交换后,调整 父子下标,方便继续向上调整child = parent;parent = (child - 1) / 2;}else{break;}}}//入数据
void HPPush(HP* php, HPDatatype x)
{assert(php);//先判断是否需要增容,如需要则增容if (php->size == php->capacity){HPDatatype* tmp = (HPDatatype*)realloc(php->a, sizeof(HPDatatype) * 2 * (php->capacity));if (NULL == tmp){perror("realloc fail");return;}php->a = tmp;php->capacity *= 2;}//入数据 先插入到尾部,即物理存储上数组的最后,然后向上调整php->a[php->size] = x;AdjustUp(php->a,php->size);php->size++;}//判断堆是否为空
bool HPEmpty(HP* php)
{return php->size == 0;
}//向下调整,前提是左右子树都是 大/小堆
void AdjustDown(HPDatatype* a, int parent,int size)
{int child = parent * 2 + 1;while (child < size)//叶结点为止,叶节点没有孩子,即child下标超过数组范围{//先找出来2个子节点中较大的那一个,因为parent的值要和较大的比较//此时如果交换,值大的child变为parent,满足比他的兄弟大if ((child+1 < size) && a[child + 1]>a[child])//起始的child一定是左孩子,检查越界{child = child + 1;}//向下调整if (a[child] > a[parent]){Swap(&a[parent], &a[child]);parent = child;child = child * 2 + 1;//每次都从左边的节点开始}else{break;}}}//删除数据 删除堆顶的元素才有意义,根据大根堆和小根堆,可以得到top为max或min
void HPPop(HP* php)
{assert(php);assert(!HPEmpty(php));//删完之后还要保证为堆的结构//如果只是简单的向前覆盖,由于物理上是数组存储,就会导致堆的父子结构被打乱, 无法通过下标关系找父/子//无法进行后续删除,因此可以选择首尾元素交换,删除尾部后,堆顶元素向下调整php->size--;Swap(&php->a[0], &php->a[php->size]);AdjustDown(php->a, 0, php->size);}//返回堆中元素个数
int HPSize(HP* php)
{assert(php);return php->size;
}
//返回堆顶元素
HPDatatype HPTop(HP* php)
{assert(php);return php->a[0];
}//堆的销毁
void HPDestroy(HP* php)
{assert(php);php->capacity = 0;php->size = 0;free(php->a);
}//9 8 7 6 5 0 2 1 4 3今天讲的是堆的概念及其主要函数的实现,下一篇文章我将详细讲述堆的应用。如 堆排序、topk问题等,感谢各位看到最后。

相关文章:
数据结构中的堆
一、树的重要知识点 节点的度:一个节点含有的子树的个数称为该节点的度(有几个孩子)叶节点或终端节点:度为0的节点称为叶节点;如上图:B、C、H、I...等节点为叶节点(0个孩子)非终端节点或分支节点…...

Linux内核设备信息集合
本文结合设备信息集合的详细讲解来认识一下设备和驱动是如何绑定的。所谓设备信息集合,就是根据不同的外设寻找各自的外设信息,我们知道一个完整的开发板有 CPU 和各种控制器(如 I2C 控制器、SPI 控制器、DMA 控制器等)࿰…...
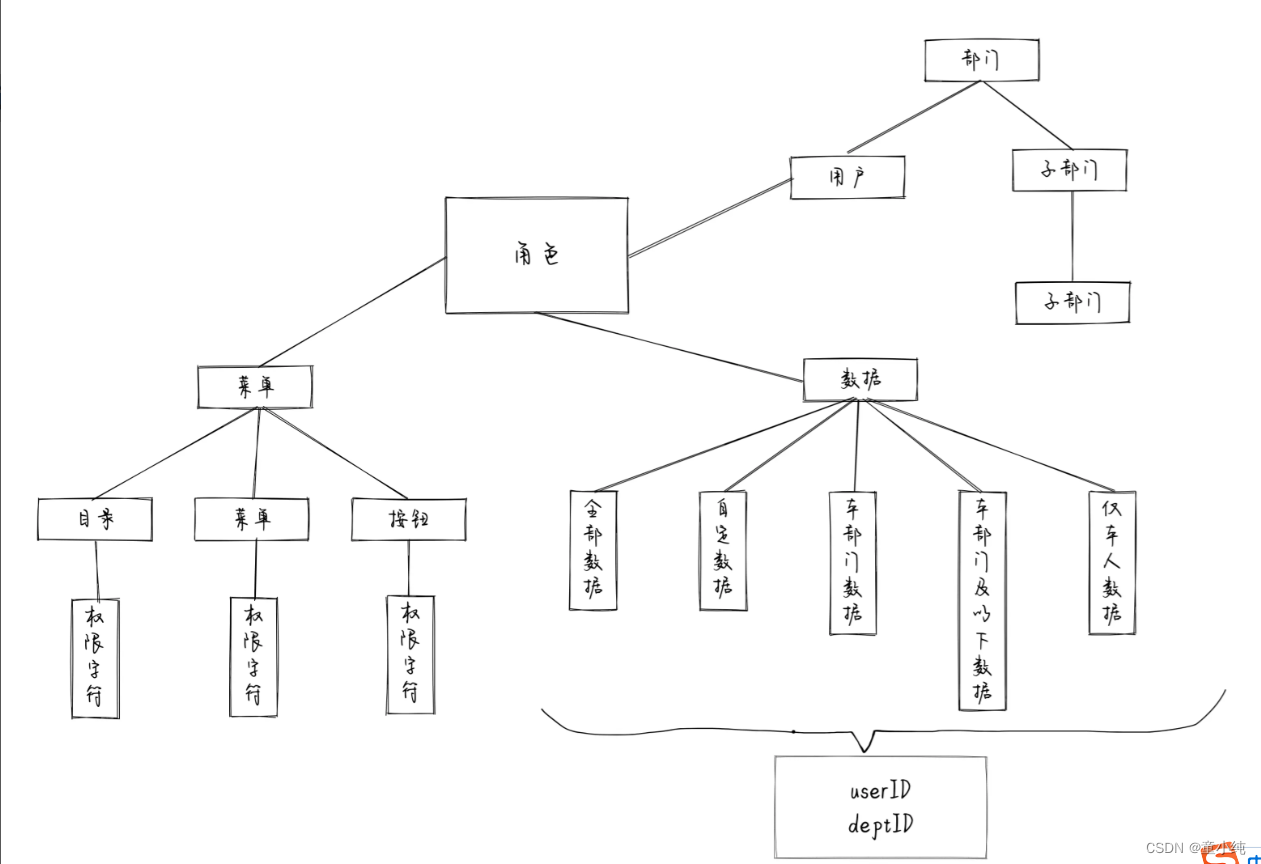
若依框架---权限管理设计
前言 若依权限管理包含两个部分:菜单权限 和 数据权限。菜单权限控制着我们可以执行哪些操作。数据权限控制着我们可以看到哪些数据。 菜单是一个概括性名称,可以细分为目录、菜单和按钮,以若依自身为例: 目录,就是页…...
——工厂模式)
Java设计模式(二)——工厂模式
当用户需要一个类的子类实例,且不希望与该类的子类形成耦合或者不知道该类有哪些子类可用时,可采用工厂模式;当用户需要系统提供多个对象,且希望和创建对象的类解耦时,可采用抽象工厂模式。 工厂模式一般分为简单工厂、…...
【Maven】
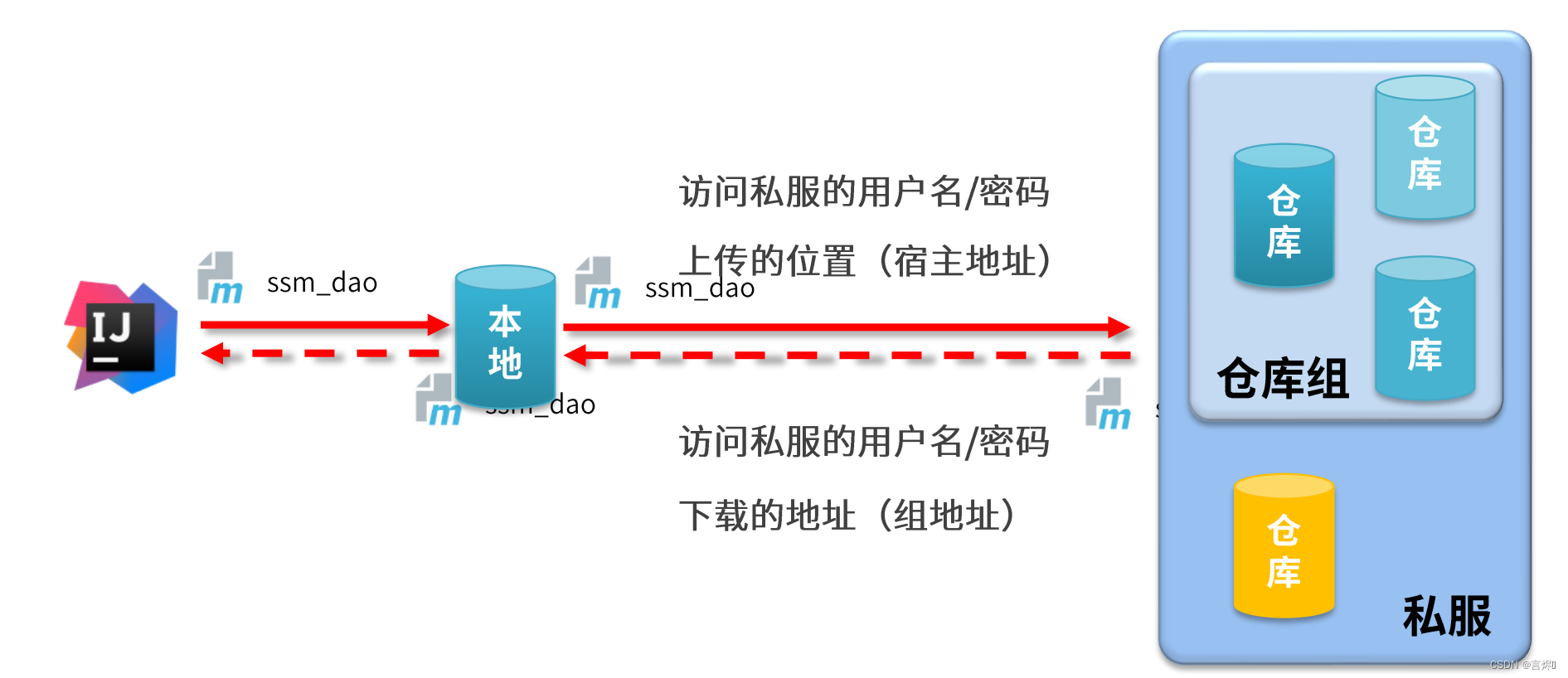
MavenMaven简介仓库坐标Maven项目构建依赖管理生命周期及插件插件模块拆分与开发聚合继承属性版本管理资源配置多环境开发配置跳过测试私服Maven简介 Maven的本质时一个项目管理工具,将项目开发和管理过程抽象成一个项目对象模型(POM) POM(Project Object Model)&a…...
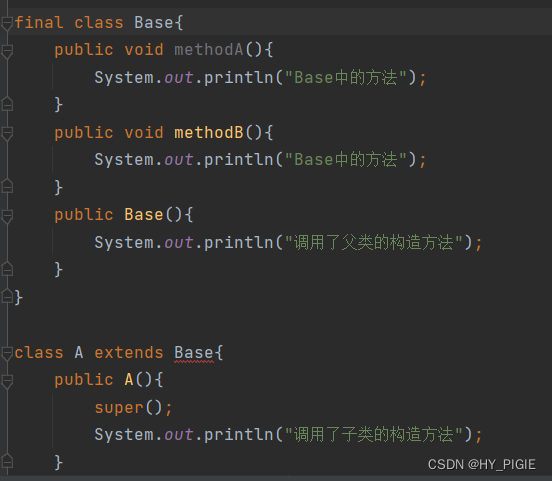
[JAVA]继承
目录 1.继承的概念 2.继承的语法 3.父类成员访问 3.1子类中访问父类成员变量 3.2子类中访问父类成员方法 4.super关键字 5.子类构造方法 6.继承方式 7.final关键字和类的关系 面向对象思想中提出了继承的概念,专门用来进行共性抽取,实现代码复…...
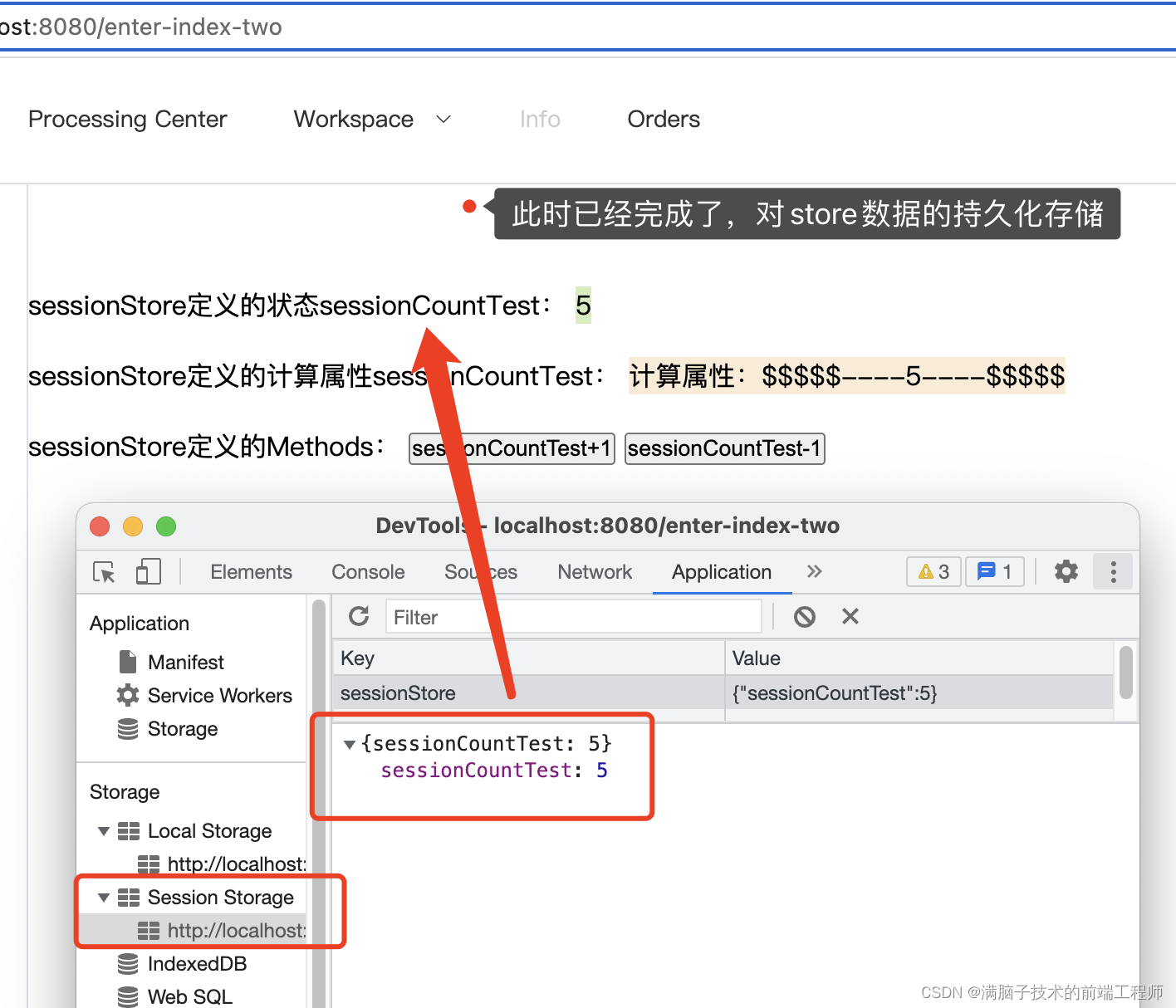
Vue3 pinia持久化存储(组合式Api案例演示)
pinia-plugin-persist( pinia持久化插件) 本文采用的是 组合式Api的方式来做Pinia的持久化存储演示 如果对pinia的持久化还是不是很了解的👨🎓|👩🎓,可以看一下笔者的上一篇文章…...

8个你一看就觉得很棒的Vue开发技巧
1.路由参数解耦 通常在组件中使用路由参数,大多数人会做以下事情。 export default {methods: {getParamsId() {return this.$route.params.id}} }在组件中使用 $route 会导致与其相应路由的高度耦合,通过将其限制为某些 URL 来限制组件的灵活性。 正…...
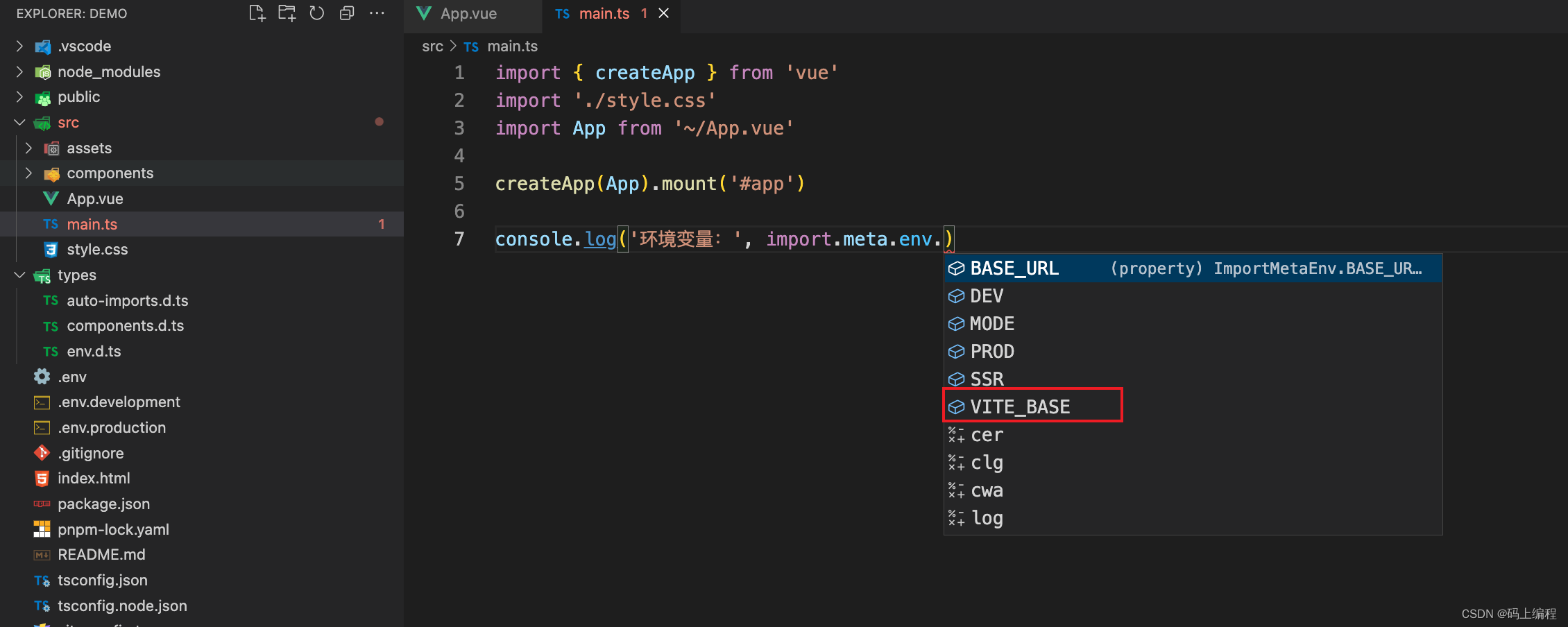
vue3+ts 开发效率提升
1、vite pnpm项目初始化 pnpm: 比npm或yarn快10倍 pnpm与其他包管理器(如npm和Yarn)的不同之处在于它使用一种称为“硬链接”的独特安装方法。当你使用PNPM安装一个包时,它并不会将包的文件复制到每个项目的node_modules目录中&a…...

【数据结构与算法】队列和栈的相互实现以及循环队列
目录🌔一.用队列实现栈🌙1.题目描述🌙2.思路分析🌙3.代码实现⛈二.用栈实现队列☔1.题目描述☔2.思路分析☔3.代码实现🌈三.实现循环队列🌔一.用队列实现栈 🌙1.题目描述 我们先看一下题目链接…...

mysql连接不上问题解决
公司新搭内网测试环境,mysql远程登录问题解决 远程登录: 1 修改host, mysql> select user,host,plugin from user; ---------------------------------------------------- | user | host | plugin | ------------------------…...

利用nginx实现动静分离的负载均衡集群实战
前言 大家好,我是沐风晓月,今天我们利用nginx来作为负载,实现两台apache服务器的动静分离集群实战; 本文收录于沐风晓月的专栏《linux基本功-系统服务实战》,更多内容可以关注我的博客: https://blog.csd…...

与chatGPT神聊,引领你深入浅出系统调用
在操作系统的教学中,系统调用的作用不言而喻,但是,对系统调用常常是雾里看花,似乎明白,又难以真正的触及,即使在代码中调用了系统调用,比如调用fork()创建进程࿰…...
自学大数据第十天~Hbase
随着数据量的增多,数据的类型也不像原来那样都是结构化数据,还有非结构化数据; Hbase时google 的bigtable的开源实现, BigtableHbase文件存储系统GFSHDFS海量数据处理MRMR协同管理服务chubbyzookeeper虽然有了HDFS和MR,但是对于数据的实时处理是比较困难的,没有办法应对数据的…...

vue更高效的工具-vite
目录 1.webpack 2.vite是什么 3.使用vite创建项目 4.最后总结 🐼webpack 简单来说,Webpack是一个打包工具。 站在2018年的角度,成为一个优秀的前端工程师,除了要会写页面样式和动态效果之外,还需要会用主流的单页…...
HFish蜜罐的介绍和简单测试(一)
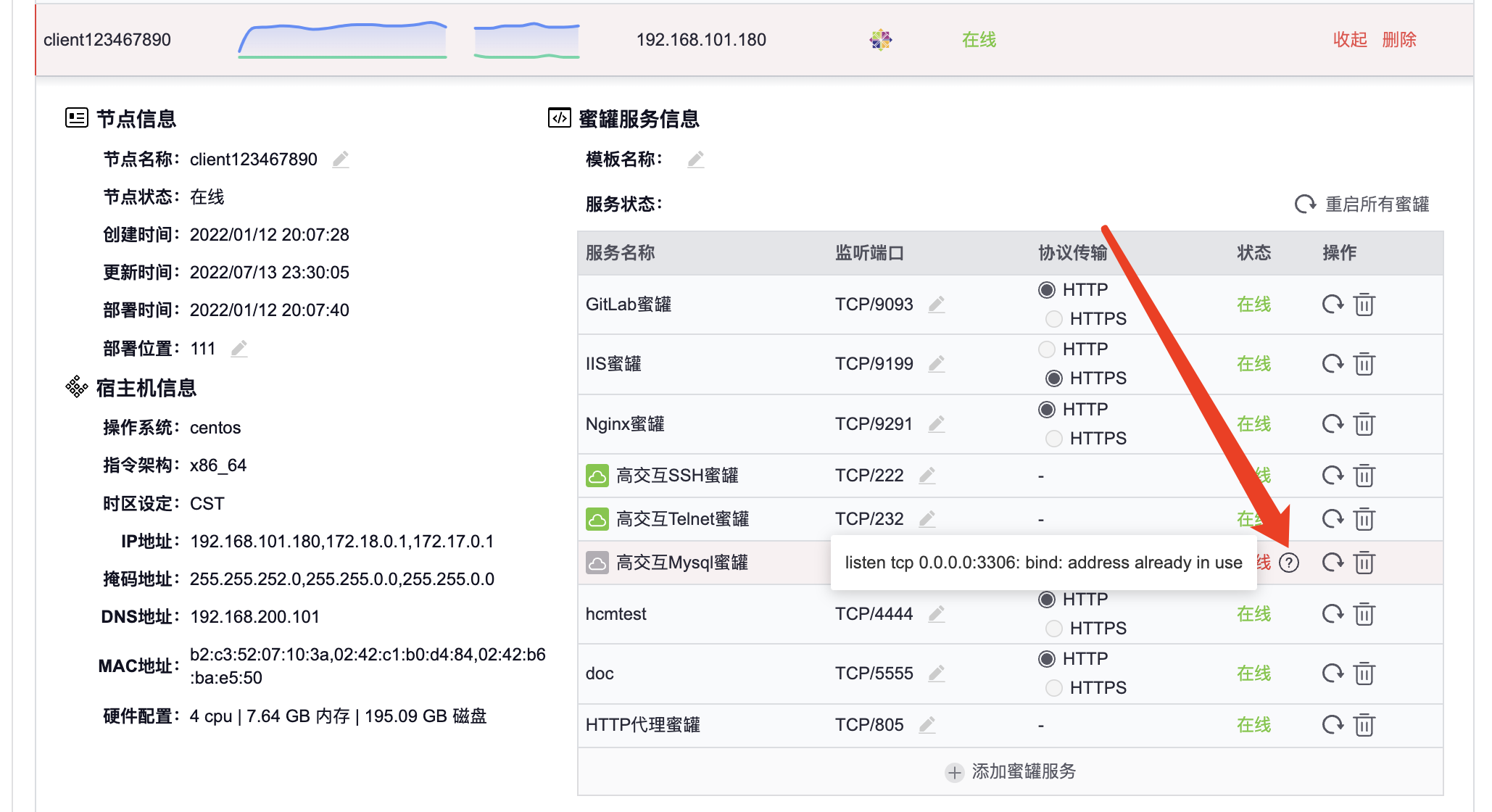
目录 0、什么是蜜罐 0.1、蜜罐的定义 0.2、蜜罐的优势 0.3、蜜罐与情报 1、HFish介绍 1.1、设计理念 1.2、HFish架构 1.3、HFish特点 1.4、常见蜜罐场景 2、快速部署 2.1、环境要求 2.2、联网环境,一键安装 2.3、安装效果 3、错误排查 3.1、管理端问题…...

2023面试题汇总二
一、CSS面试题 1. 清除浮动的方式有哪些? 为什么要清除浮动?因为浮动的盒子脱离标准流,如果父盒子没有设置高度的话,下面的盒子就会撑上来。 额外标签法(在最后一个浮动标签后,新加一个标签,给其设置cle…...

C# 支付宝接口在线收款退款
收款 在C#中使用支付宝在线支付功能,需要使用支付宝开放平台提供的SDK(软件开发工具包),通过SDK中提供的API(应用程序接口)实现在线支付功能。 以下是使用C#实现支付宝在线支付的大致步骤: 获…...

python例程:《企业编码生成系统》程序
目录《企业编码生成系统》程序使用说明主要代码演示源码及说明文档下载路径《企业编码生成系统》程序使用说明 在PyCharm中运行《企业编码生成系统》即可进入如图1所示的系统主界面。在该界面中可以选择要使用功能对应的菜单进行不同的操作。在选择功能菜单时,只需…...

基于EB工具的TC3xx_MCAL配置开发04_ADC模块软件触发Demo配置
目录 1.概述2. EB配置2.1 添加HwUnit2.2 AdcPrescale配置2.3 添加ADC通道2.4 添加Adc Group2.5 Adc Group配置2.5.1 AdcGroup->General2.5.2 AdcGroup->AdcNotification2.5.3 AdcGroup->AdcGroupDefinition2.5.4 AdcGroup->AdcResRegDefinition2.6 中断配置1.概述 …...

借助AI写教材,低查重实现,轻松打造符合需求的教材!
教材编写的挑战与AI工具解决方案 在教材编写的过程中,如何平衡原创性与合规性是一个重要的挑战。借鉴优秀教材的知识内容时,常常会担心重复率过高;而自己独立表述知识点,又得顾虑逻辑不严密、内容不准确等问题。引用他人研究成果…...

ShawzinBot技术解析:基于MIDI的Warframe乐器自动化演奏系统实现
ShawzinBot技术解析:基于MIDI的Warframe乐器自动化演奏系统实现 【免费下载链接】ShawzinBot Convert a MIDI input to a series of key presses for the Shawzin 项目地址: https://gitcode.com/gh_mirrors/sh/ShawzinBot ShawzinBot是一款专为《Warframe》…...

边缘AI算力模组实战:32TOPS性能解析与工业部署指南
1. 项目概述:当边缘计算遇上32TOPS的澎湃动力最近几年,如果你在工业质检、智慧交通或者机器人领域摸爬滚打过,一定会对“边缘智能”这个词深有感触。过去,我们总习惯把海量的视频流、传感器数据一股脑儿往云端服务器上送ÿ…...

3分钟搞定Windows苹果USB驱动安装:终极免费解决方案
3分钟搞定Windows苹果USB驱动安装:终极免费解决方案 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh_mirro…...

显卡驱动清理终极指南:为什么你的系统需要Display Driver Uninstaller深度清理?
显卡驱动清理终极指南:为什么你的系统需要Display Driver Uninstaller深度清理? 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirr…...

如何免费使用ColabFold进行蛋白质结构预测:面向新手的终极指南
如何免费使用ColabFold进行蛋白质结构预测:面向新手的终极指南 【免费下载链接】ColabFold Making Protein folding accessible to all! 项目地址: https://gitcode.com/gh_mirrors/co/ColabFold ColabFold蛋白质结构预测是生物信息学领域的一项革命性技术&a…...

从SysTick中断到任务就绪:深入追踪FreeRTOS一次Tick如何触发PendSV切换
从SysTick中断到任务就绪:深入追踪FreeRTOS一次Tick如何触发PendSV切换 在嵌入式实时操作系统的世界里,任务切换的精确性和可靠性直接决定了系统的实时性能。对于使用FreeRTOS的开发者而言,理解从SysTick中断到最终任务切换的完整链条&#x…...
)
保姆级教程:在Vue3项目中用ZLMediaKit+WebRTC实现超低延迟监控直播(附完整代码)
Vue3WebRTC超低延迟监控直播实战指南 在实时视频监控领域,延迟是衡量系统性能的核心指标之一。传统RTSP流媒体方案在Web端实现时,往往面临秒级甚至更长的延迟,这在对实时性要求极高的安防监控、工业检测等场景中成为致命短板。本文将深入探讨…...
)
从厨房小白到AI大模型高手:小白程序员也能轻松掌握大模型的秘密(收藏版)
本文旨在打破对AI大模型的刻板印象,用通俗易懂的语言解释AI大模型的工作原理,并通过实例教学,帮助读者从零开始掌握AI大模型的应用。文章涵盖了AI大模型的基本概念、提示词工程、RAG技术、函数调用、智能体构建、微调与部署等关键知识点&…...

东南大学论文模板终极指南:3步搞定毕业设计排版难题
东南大学论文模板终极指南:3步搞定毕业设计排版难题 【免费下载链接】SEUThesis 东南大学论文模板 项目地址: https://gitcode.com/gh_mirrors/seu/SEUThesis 对于每一位东南大学的学子来说,毕业季最头疼的往往不是论文内容本身,而是繁…...