SQL的连接查询与pandas的对应关系
在SQL和Pandas中,连接查询(join)是处理数据集之间关系的重要工具。下面是SQL中的各种连接查询类型及其与Pandas中相应操作的对应关系:
1. INNER JOIN
-
SQL:
INNER JOIN返回两个表中具有匹配值的行。
-
Pandas:
merge()方法的how参数设置为'inner'。- 示例代码:
merged_df = pd.merge(df1, df2, on='key', how='inner')
2. LEFT JOIN / LEFT OUTER JOIN
-
SQL:
LEFT JOIN返回左表中的所有行,并在右表中找到匹配项时返回相应的行。如果没有匹配项,则返回NULL。
-
Pandas:
merge()方法的how参数设置为'left'。- 示例代码:
merged_df = pd.merge(df1, df2, on='key', how='left')
3. RIGHT JOIN / RIGHT OUTER JOIN
-
SQL:
RIGHT JOIN返回右表中的所有行,并在左表中找到匹配项时返回相应的行。如果没有匹配项,则返回NULL。
-
Pandas:
merge()方法的how参数设置为'right'。- 示例代码:
merged_df = pd.merge(df1, df2, on='key', how='right')
4. FULL OUTER JOIN / FULL JOIN
-
SQL:
FULL OUTER JOIN返回两个表中的所有行。对于没有匹配项的行,缺失的列会被填充为NULL。
-
Pandas:
merge()方法的how参数设置为'outer'。- 示例代码:
merged_df = pd.merge(df1, df2, on='key', how='outer')
5. CROSS JOIN
-
SQL:
CROSS JOIN返回两个表的笛卡尔积,即所有可能的行组合。
-
Pandas:
merge()方法没有直接对应的方法,但可以通过设置on参数为None并将how设置为'outer'来实现。- 示例代码:
merged_df = pd.merge(df1, df2, how='outer')
6. SEMI JOIN
-
SQL:
SEMI JOIN返回左表中在右表中有匹配项的行。
-
Pandas:
merge()方法结合boolean indexing可以模拟SEMI JOIN。- 示例代码:
semi_joined_df = df1[df1['key'].isin(df2['key'])]
7. ANTI JOIN
-
SQL:
ANTI JOIN返回左表中在右表中没有匹配项的行。
-
Pandas:
merge()方法结合boolean indexing可以模拟ANTI JOIN。- 示例代码:
anti_joined_df = df1[~df1['key'].isin(df2['key'])]
示例代码
假设我们有两个DataFrame df1 和 df2,我们将演示这些连接操作:
import pandas as pd# 创建示例 DataFrame
data1 = {'key': ['A', 'B', 'C', 'D'],'value1': [1, 2, 3, 4]
}
df1 = pd.DataFrame(data1)data2 = {'key': ['B', 'D', 'E'],'value2': [5, 6, 7]
}
df2 = pd.DataFrame(data2)# INNER JOIN
inner_joined_df = pd.merge(df1, df2, on='key', how='inner')
print("INNER JOIN:")
print(inner_joined_df)# LEFT JOIN
left_joined_df = pd.merge(df1, df2, on='key', how='left')
print("\nLEFT JOIN:")
print(left_joined_df)# RIGHT JOIN
right_joined_df = pd.merge(df1, df2, on='key', how='right')
print("\nRIGHT JOIN:")
print(right_joined_df)# FULL OUTER JOIN
full_outer_joined_df = pd.merge(df1, df2, on='key', how='outer')
print("\nFULL OUTER JOIN:")
print(full_outer_joined_df)# CROSS JOIN
cross_joined_df = pd.merge(df1, df2, how='outer')
print("\nCROSS JOIN:")
print(cross_joined_df)# SEMI JOIN
semi_joined_df = df1[df1['key'].isin(df2['key'])]
print("\nSEMI JOIN:")
print(semi_joined_df)# ANTI JOIN
anti_joined_df = df1[~df1['key'].isin(df2['key'])]
print("\nANTI JOIN:")
print(anti_joined_df)
输出示例
假设 df1 和 df2 如下所示:
df1:key value1
0 A 1
1 B 2
2 C 3
3 D 4df2:key value2
0 B 5
1 D 6
2 E 7
输出结果将会是:
INNER JOIN:key value1 value2
1 B 2 5
3 D 4 6LEFT JOIN:key value1 value2
0 A 1 NaN
1 B 2 5.0
2 C 3 NaN
3 D 4 6.0RIGHT JOIN:key value1 value2
1 B 2.0 5.0
3 D 4.0 6.0
2 E NaN 7.0FULL OUTER JOIN:key value1 value2
0 A 1.0 NaN
1 B 2.0 5.0
2 C 3.0 NaN
3 D 4.0 6.0
4 E NaN 7.0CROSS JOIN:key_x value1 key_y value2
0 A 1 B 5
1 A 1 D 6
2 A 1 E 7
3 B 2 B 5
4 B 2 D 6
5 B 2 E 7
6 C 3 B 5
7 C 3 D 6
8 C 3 E 7
9 D 4 B 5
10 D 4 D 6
11 D 4 E 7SEMI JOIN:key value1
1 B 2
3 D 4ANTI JOIN:key value1
0 A 1
2 C 3
相关文章:

SQL的连接查询与pandas的对应关系
在SQL和Pandas中,连接查询(join)是处理数据集之间关系的重要工具。下面是SQL中的各种连接查询类型及其与Pandas中相应操作的对应关系: 1. INNER JOIN SQL: INNER JOIN 返回两个表中具有匹配值的行。 Pandas: merge() 方法的 how…...

【JS】中断和恢复任务序列
前言 封装processTasks函数,实现以下需求 /*** 依次顺序执行一系列任务* 所有任务全部完成后可以得到每个任务的执行结果* 需要返回两个方法,start用于启动任务,pause用于暂停任务* 每个任务具有原子性,即不可中断,只…...

CentOS系统下安装NVIDIA显卡驱动
一、安装显卡驱动 1.安装依赖项 yum -y install gcc pciutils yum -y install gcc yum -y install gcc-c yum -y install make2.查看内核版本 uname -a3.查看显卡版本 lspci | grep -i nvidia4.屏蔽系统自带的nouveau (1)查看nouveau lsmod | grep nouveau (2)打开blackl…...

Linux 与 Windows 服务器操作系统 | 全面对比
在服务器操作系统的领域,Linux 和 Windows 一直是两个备受关注的选择。 首先来看 Windows 操作系统。它由 Microsoft Corporation 开发,在桌面领域占据显著份额,其中 Windows 10 是使用最广泛的版本,广泛应用于个人计算机和企业桌…...

给既有exe程序添加一机一码验证
原文地址:李浩的博客 lihaohello.top 本科期间开发过一款混凝土基本构件设计程序,该程序是一个独立的exe可执行文件,采用VC静态链接MFC库编制而成。近期,需要为该程序添加用户注册验证的功能,从而避免任何用户获取该程…...

【Datawhale X 魔搭 】AI夏令营第四期大模型方向,Task2:头脑风暴会,巧灵脑筋急转弯(持续更新)
队伍名称:巧灵脑筋急转弯 队伍技术栈:python,LLM,RAG,大模型,nlp,Gradio,Vue,java 队友:知唐(队长),我真的敲不动…...

mysql 多个外键
在MySQL中,一个表可以有多个外键约束,它们分别关联到不同的主表。在创建表时,可以在每个外键约束上指定不同的外键名称。以下是一个简单的例子,演示如何在创建表时定义多个外键: CREATE TABLE orders (order_id INT AU…...

解决方案上新了丨趋动科技推出基于银河麒麟操作系统的异构算力池化解决方案
趋动科技携手麒麟软件打造基于银河麒麟操作系统的异构算力池化解决方案,共同探索AI领域新场景。 人工智能技术作为数字经济发展的重要推手,在各行业业务场景中落地需要大量AI算力资源的有效保障。在IT基础设施普遍云化的今天,AI算力一方面需…...

14.创建一个实战maven的springboot项目
项目核心主要部分 pom.xml文件 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://mave…...

docker部署LNMP
docker部署LNMP nginx 1.22 172.111.0.10 docker-nginx mysql 8.0.30 172.111.0.20 docker-mysql php 8.1.27 172.111.0.30 docker-php docker:单节点部署,只能在一台机器上部署,如果跨机器容器无法操作,无法通信。 做高可用…...

在Spring Boot应用中,如果你希望在访问应用时加上项目的名称或者一个特定的路径前缀
在Spring Boot应用中,如果你希望在访问应用时加上项目的名称或者一个特定的路径前缀 在Spring Boot应用中,如果你希望在访问应用时加上项目的名称或者一个特定的路径前缀,你可以通过配置server.servlet.context-path属性来实现。这通常在app…...

东南大学:Wi-Fi 6搭档全光以太,打造“数智东南”信息高速路
东南大学:Wi-Fi 6搭档全光以太,打造“数智东南”信息高速路 - 华为企业业务 打好ICT底座,平台和应用层面就会非常通畅了。首先,出海企业的需求既有普遍性,也有垂直性行业的特性需求。普遍性需求需要通信、沟通数据和传…...

C++:stack类(vector和list优缺点、deque)
目录 前言 数据结构 deque vector和list的优缺点 push pop top size empty 完整代码 前言 stack类就是数据结构中的栈 C数据结构:栈-CSDN博客 stack类所拥有的函数相比与string、vector和list类都少很多,这是因为栈这个数据结构是后进先出的…...

负载均衡、高可用
负载均衡 负载均衡(Load Balance):可以利用多个计算机和组合进行海量请求处理,从而获得很高的处理效率,也可以用多个计算机做备份(高可用),使得任何一个机器坏了整个系统还是能正常…...

从Retrofit支持suspend协程请求说开去
在现代Android开发中,异步请求已经成为不可或缺的一部分。传统的异步请求往往涉及大量的回调逻辑,使代码难以维护和调试。随着Kotlin协程的引入,异步编程得到了极大的简化。而作为最流行的网络请求库之一,Retrofit早在Kotlin协程的…...
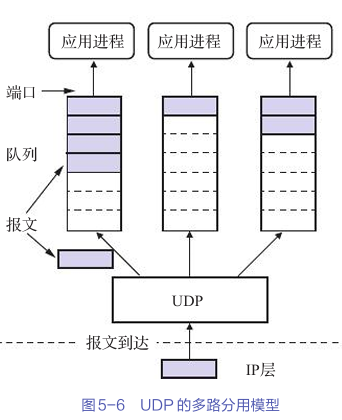
深入浅出:你需要了解的用户数据报协议(UDP)
文章目录 **UDP概述****1. 无连接性****2. 尽最大努力交付****3. 面向报文****4. 多种交互通信支持****5. 较少的首部开销** **UDP报文的首部格式****详细解释每个字段** **UDP的多路分用模型****多路分用的实际应用** **检验和的计算方法****伪首部的详细内容****检验和计算步…...

C++的Magic Static
什么是“Magic Static”? C 中,函数内部的静态变量只会在第一次执行该函数时被初始化,而且这种初始化在 C11 标准之后是线程安全的。这意味着即使多个线程同时第一次调用该函数,静态变量也只会被初始化一次,并且在初始…...

vscode添加宏定义
1 起因 在用vscode看项目代码时,如果源文件中的代码块被某个宏定义给包裹住了,则在vscode的默认配置下,不会高亮显示这块被包裹住的代码,如下图中229行开始的代码被STM32F40_41xxx所控制,没有高亮显示。 由于STM32F4…...

Postman接口关联
接口关联 接口之间存在依赖关系,接口B要依赖于接口A的返回值。 例如:现在有两个接口,接口1:获取接口统一鉴权码token接口,接口2:创建标签接口。接口2里的请求参数需要依赖接口1返回的值,即需要…...

用Python制作开心消消乐游戏|附源码
制作一个完整的“开心消消乐”风格的游戏在Python中是一个相对复杂的项目,因为它涉及到图形界面、游戏逻辑、动画效果以及用户交互等多个方面。不过,我可以为你提供一个简化的版本和概念框架,帮助你理解如何开始这个项目,并提供一…...

AI混音师登场:音频自动混音技术全景解读与实战展望
AI混音师登场:音频自动混音技术全景解读与实战展望 引言 在AIGC浪潮席卷内容创作的今天,音频制作领域正经历一场静默革命。从专业录音棚到手机直播间,“一键母带”、“智能平衡”功能已不再陌生。这背后,正是音频自动混音技术在驱…...

实时数据流处理实战:从滑动窗口算法到Docker部署
用 Python 造一个轻量级流处理引擎,顺便把 Git、Docker、CI/CD 全串起来 前言 你是否有过这样的需求:统计过去 5 秒内 API 的请求次数、监控传感器数据的突变、或者对直播间的弹幕进行限流?这些场景都离不开实时数据流处理。而流处理的核心&…...

FDS火灾动力学模拟器完整指南:从入门到精通建筑消防安全分析
FDS火灾动力学模拟器完整指南:从入门到精通建筑消防安全分析 【免费下载链接】fds Fire Dynamics Simulator 项目地址: https://gitcode.com/gh_mirrors/fd/fds 想要准确预测火灾中的烟雾扩散路径?需要科学评估建筑物的人员疏散时间?F…...

腾讯验证码攻防新篇:六宫格、滑块与文字识别的毫秒级破解实战
1. 腾讯验证码体系深度解析 腾讯验证码作为当前互联网安全防护的重要组成部分,已经发展出包括六宫格、图标点选、滑块验证和文字识别在内的多种形式。这些验证码在设计时充分考虑了人机交互的特点,通过视觉识别和行为分析双重机制来区分真实用户和自动化…...
)
别再死记硬背了!一文搞懂EtherCAT四种寻址方式(附FMMU配置实例)
深入解析EtherCAT四大寻址机制:从原理到实战配置 第一次接触EtherCAT的工程师,往往会被其复杂的寻址方式搞得晕头转向。位置寻址、节点寻址、逻辑寻址、广播寻址——这些术语听起来相似却又各具特点,死记硬背不仅效率低下,更会在实…...

为什么Stable Diffusion选择VQ-GAN?深入解析LDM背后的图像压缩技术
为什么Stable Diffusion选择VQ-GAN?深入解析LDM背后的图像压缩技术 在生成式AI领域,Stable Diffusion凭借其出色的图像生成质量和开源特性迅速成为行业标杆。但很少有人注意到,这个强大模型的核心竞争力之一,其实隐藏在它的第一阶…...

OpenBot开源代码平台:可视化编程与AI模块开发教程
OpenBot开源代码平台:可视化编程与AI模块开发教程 【免费下载链接】OpenBot OpenBot leverages smartphones as brains for low-cost robots. We have designed a small electric vehicle that costs about $50 and serves as a robot body. Our software stack for…...

如何在ComfyUI中玩转WanVideo:从零到一的视频生成魔法
如何在ComfyUI中玩转WanVideo:从零到一的视频生成魔法 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper 你是否曾经想过,如果能像搭积木一样轻松创作视频该有多好ÿ…...

3步掌握Qwen Code的中文编程体验:母语环境下的智能开发革命
3步掌握Qwen Code的中文编程体验:母语环境下的智能开发革命 【免费下载链接】qwen-code Qwen Code is a coding agent that lives in the digital world. 项目地址: https://gitcode.com/GitHub_Trending/qw/qwen-code Qwen Code是阿里云通义千问推出的智能编…...

自定义语音合成插件开发指南:从技术原理到创新应用
自定义语音合成插件开发指南:从技术原理到创新应用 【免费下载链接】tts-server-android 这是一个Android系统TTS应用,内置微软演示接口,可自定义HTTP请求,可导入其他本地TTS引擎,以及根据中文双引号的简单旁白/对话识…...