【c语言】整数在内存中的储存(大小端字节序)
整数在内存中的储存(大小端字节序)
1.整数在内存中的储存
2.大小端字节序
3.整数在内存中储存例子
4.字节序判断
5.死循环现象
文章目录
- 整数在内存中的储存(大小端字节序)
- 整数在内存中的储存
- 大小端字节序
- 什么是大小端
- 为什么会有大小端
- 整数在内存中储存例子
- 字节序判断
- 死循环现象
整数在内存中的储存
在学操作符的时候,我们就知道整数的2进制表示方法有3种,原码,反码,补码
对于有符号整型,这三种表示方法都由符号位和数值位组成,符号位,’0‘表示’正‘,’1‘表示’负‘。
最高位为符号位,其余的为数值位。
对于有符号整型
正整数原码,反码,补码相同
负整数:
原码:直接将数值按照正负形式翻译成二进制
反码:原码符号位不变,数值位取反
补码:反码加1
对于无符号数据
原码反码补码相同
对于整形数据来说:内存中存放的是数据的补码
因为补码可以对符号位和数值域统一处理,同样,加法减法也可以统一处理,补码与原码互相转换,他的运算过程是相同的,不需要额外的硬件电路
大小端字节序
在学习大小端字节序之前我们先来梳理几个小知识
1.一个字节——>8个二进制位
一个16进制位——>4个二进制位
两个16进制位——>8个二进制位
2.在计算机系统中,内存被分为一个个字节单元,字节单元的编号==地址
下面给一个代码,试着调试看一看
int main()
{int a = 0x11223344;//这里给出一个整型a,用16进制给初始化一下return 0;
}
调试看结果

我们不难看出a中的0X11223344这个数字是按照字节为单位,倒着存放的,这是为什么呢?
这就不得不提到大小端了。
什么是大小端
当我们在内存储存超过一个字节的数据时,就存在储存顺序的问题,我们分为大端字节序储存和小端字节序储存
大端储存:
是指数据的低字节内容保存在高地址处,而数据得高字节内容保存在低地址处。
小端储存:
是指数据得低字节内容保存在低地址处,而数据的高地址内容保存在高地址处。
上边使用的VS2022,他是小端储存模式,所以按照小端的储存模式规则,他在内存中字节序是倒着储存的。
为什么会有大小端
存在大小端模式之分的原因是,在计算机系统中,我们是以字节为单位的,每个地址单元都对应一个字节,一个字节为8个bit位,但在C语言中,除了8个bit位的char类型,还有16个bit的short型,32个bit的long型(看具体编译器了),此外,对于位数大于8的处理器,比如16位或32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题,这就导致了大端储存模式和小端储存模式。
比如,对于一个16个bit位的X,他在内存中的地址为0x0010,X的值是0x1122,那么0X11是高字节位,0X22是低字节位,在大端模式中,0x11应该放在低地址处,即0X0010,0X22应该放在高地址处,即0X0011中。小端模式,则恰好相反。
我们常用的X86结构是小端模式,而KEIL C51为大端模式。很多的ARM,DSP都是小端模式。有些ARM处理器还可以由硬件来选择大小端
整数在内存中储存例子
1.写一个程序来判断当前机器的字节序
分析一波
我们可以先创建一个整型变量,int a=1
这个数据在小端模式下储存的应该是
01 00 00 00
大端模式下储存的应该是
00 00 00 01,
因此想要判断当前机器是那种字节序,只需要拿出第一个字节比一比就行
如何把它取出来呢?
我们知道当我们对一个数据取地址时,得到的地址是较小的字节单元的地址,(这一点可以看一下博主的指针知识点总结,有讲到这里)而内存的储存是从低地址向高地址储存的,因此我们可以对a取地址就可以锁定到第一个字节,再将它强制类型转换成字符指针类型,然后解引用就可以得到第一个字节了
即
*(char *)&a;
由此,写出代码
int Check_c(int i)
{return *(char*)&i;
}
int main()
{int i = 5;int ret=Check_c(i);if (ret == 5)printf("小端\n");//如果当前的系统储存方式是小端,就能输出5,如果不是小端返回值就不会是5elseprintf("大端\n");return 0;
}
下面再通过几道题,再理解一下
2.
int main()
{char a = -1;signed char b = -1;unsigned char c = -1;printf("a=%d b=%d c=%d ", a, b, c);return 0;
}
再分析之前,先来复习一下整型提升的知识
对于有符号整数提升是按照变量的数据类型的符号位来提升
对于无符号整数提升,高位补0
分析一波
我们先写出-1的原码反码补码
-1
原码:10000000 00000000 00000000 00000001
反码:11111111 11111111 11111111 11111110
补码:11111111 111111111 11111111 1111111
又因为a,b,c均是char类型,这里截断一下,a,b,c都是
11111111
在输出的时候要以有符号整形输出,那么就要发生整型提升
对于a,他是有符号的char类型,高位补1,得到完整的补码,
11111111 11111111 11111111 11111111
对其补码取反加1,得到的原码为
10000000 00000000 00000000 00000001
输出仍为-1,而对于b,他也是有符号char类型,与a一样,输出-1
对于c,他是无符号类型,做完整型提升得到补码
00000000 00000000 00000000 11111111
同时这也是c的原码,输出255
看一下运行结果

3.
int main()
{char a = 128;char b = -128;printf("a=%u b=%u", a, b);return 0;
}
在分析之前,还是先来复习一下知识
char类型通常是一个8位的有符号整数,取值范围在-128~127
unsigned char 类型是8位的无符号整数,取值范围在0~255
这里我们分析a,b,他们的原反补码如下
-128
原码:10000000 00000000 00000000 10000000
反码:11111111 11111111 11111111 01111111
补码:11111111 11111111 11111111 10000000
a,b是char 类型,截断得到a,b是
10000000
对a,b整型提升后补码
11111111 11111111 11111111 10000000
因为输出的是无符号整型,a,b的原码反码补码一样,输出的是一个很大的数
看运行结果

在这里尽管a=128,已经超出char类型的取值范围,但并不影响,因为在char类型里边他总会把赋给它的值通过各种截断,让他在他的取值范围内
而我们看到在截断后,a,b的值是一样的,所以他整型提升后,结果也是一样的
4.
int main()
{unsigned char a = 200;unsigned char b = 100;unsigned char c = 0;c = a + b;printf(" % d % d", a + b, c);return 0;
}
先分别求出a,b的反码
a的反码:00000000 00000000 00000000 11001000
b的反码:00000000 00000000 00000000 01100100
那么在unsigned char的类型中
a:11001000
b:01100100
a+b:1 00101100
对他做整型提升高位补0
00000000 00000000 00000001 00101100(原码,反码,补码)——>对应的就是十进制的300
而c=a+b;,
虽然unsigned char 下的a+b仍为1 00101100,但c是char类型,要丢掉高位的1,c为 00101100,对其进行整型提升,高位补0,
00000000 00000000 00000000 00101100,对应十进制的44

字节序判断
1.
unsigned int a= 0x1234;
unsigned char b = *(unsigned char *)&a;
在32位大端模式处理器上变量b等于?
分析
对于a,a=0x00001234,前边的0被省略掉了,那么在大端模式下,他在内存中字节的储存顺序为
00 00 12 34
*(unsigned char *)&a;这个操作就是把低地址的字节00拿出来(在上边写个代码判断当前机器是大端小端的时候就已经介绍过了)
*(unsigned char *)&a;被赋值给b,b的值就是0x00
当以“%x"形式输出16进制时,0x,和前边的0都会被省略
如果想要输出0x,就以"%#x"形式输出
2.
//X86环境,小端字节序
int main()
{int arr[4] = { 1,2,3,4 };int* ptr1 = (int*)(&arr + 1);int* ptr2 = (int*)((int)arr + 1);printf("%x, %x", ptr1[-1], *ptr2);return 0;
}
在小端模式下,数组元素在内存中字节的储存顺序是

对ptr1
&arr+1,对整个数组取地址加1,跳过整个数组
ptr1[-1]=*(ptr1-1)
指向如图所示,04 00 00 00,那么对应的数据就是0x 00000004,0x,和前边的0省略掉,输出4
对于ptr2
arr指向的是arr首元素地址。假设arr=0x0000EF10,将他强制转换成整数类型,整数类型加1就是单纯加个1,(int)arr+1=)0x0000EF11,跳过一个地址(字节)跳到下一个字节,这时对ptr2解引用指向的是
00 00 00 02
对应的数据是0x 02 00 00 00,输出2000000

死循环现象
这里我们在学习一个知识

我们通过这个图片可以明白,在char类型中,他的取值范围是形成一个圆环一直在循环的,(其他类型也是如此)也就是说,比如我们给char a=500,很显然,他超出了char的取值范围,可是根据这个规律,当他截断后放在char类型里边的数就是500%256=244,对应的就是-12。
再例如unsigneg char b=400,也超出了unsigned char 的范围,根据这个规律,当他截断后放在unsigned char类型里的数是400%256=144,对应的就是144

运行的结果也是如此
学习过这个之后,就可以看几道题了
1.
#include<stdio.h>
#include<string.h>
int main()
{char arr[1000];int u = 0;for (u = 0; u < 1000; u++){arr[u] = -1 - u;}printf("%d", strlen(arr));return 0;
}分析一波
strlen计算数组元素的个数,并且必需要碰到‘\0’才能结束,
在上边代码中,初始化arr数组,如果不考虑arr的类型,他的初始化值是从-1到-999,可是他受到char类型的限制,char类型的取值范围在-128~127,这时候就要发生截断,总之char类型会想办法让初始化的值在他的取值范围内。那么arr的初始化值就会是
-1,-2,-3,…-127,-128,-129这时候-129已经超出char的范围,char想办法让他满足自己的范围,那么根据上边学习的规律-129放在char类型里就是127,
在接下来就是127,126,125…2,1,0,-128,-127.就这样循环下去
因为’\0’对应的ASCII码是0,所以strlen会计算’\0’之前的字符个数为128+127=255

2.
int main()
{unsigned int i = 0;for (i = 0; i <= 255; i++){printf("haha\n");}return 0;
}
int main()
{unsigned int j = 0;for (j = 12; j >= 0; j--){printf("hehe\n");}return 0;
}
这两段代码,无一例外他们的结果最后都是死循环。
分析
对第一个
unsigned int类型的取值范围0到255,在第一个循环中,i加到266时,超出unsigned int的范围,unsigned int将他转化成符合自己范围的数值即根据规律计算出是0,这样循环条件恒成立,就陷入了死循环
同理第二段代码
当j 减到0时,再减变为-1,不满足unsigned int的取值范围,unsigned int将他转化成符合自己范围的值,根据上边学习的内容计算出时255,循环条件恒成立,陷入死循环
作者有话说:作者只是一只小白,以上解释均是作者对已学知识的理解,巩固,复习。希望可以帮到大家,如有错误,感谢指出
相关文章:
【c语言】整数在内存中的储存(大小端字节序)
整数在内存中的储存(大小端字节序) 1.整数在内存中的储存 2.大小端字节序 3.整数在内存中储存例子 4.字节序判断 5.死循环现象 文章目录 整数在内存中的储存(大小端字节序)整数在内存中的储存大小端字节序什么是大小端为什么会有…...

浅谈SIMD、向量化处理及其在StarRocks中的应用
前言 单指令流多数据流(SIMD)及其衍生出来的向量化处理技术已经有了相当的历史,并且也是高性能数据库、计算引擎、多媒体库等组件的标配利器。笔者在两年多前曾经做过一次有关该主题的内部Geek分享,但可能是由于这个topic离实际研发场景比较远࿰…...

【ML】Image Augmentation)的作用、使用方法及其分类
图像增强(Image Augmentation)的作用、使用方法及其分类 1. 图像增强的定义2. 图像增强的作用3. 什么时候使用图像增强?4. 图像增强详细方法分类梳理4.1 图像增强方法列表4.2 边界框增强方法5. 参考资料 yolov3(一:模型…...
--单一职责原则)
设计模式六大原则(一)--单一职责原则
1. 简介 1.1. 概述 一个类或模块应该只负责完成一项任务或承担一个责任。如果一个类或模块承担了多个职责,那么当需要修改其中一个职责的功能时,就可能会对其他职责产生影响,从而导致代码耦合度增加,维护起来更加困难。 1.2. 主要特点 单一职责原则(Single Responsibi…...

c语言学习,malloc()函数分析
1:malloc() 函数说明: 申请配置size大小内存空间 2:函数原型: void *malloc(size_t size) 3:函数参数: 参数size,为申请内存大小 4:返回值: 配置成功则返回指针&#…...

【运维项目经历|041】上云项目-物理机迁移到阿里云
🍁博主简介: 🏅云计算领域优质创作者 🏅2022年CSDN新星计划python赛道第一名 🏅2022年CSDN原力计划优质作者 🏅阿里云ACE认证高级工程师 🏅阿里云开发者社区专家博主 💊交流社区:CSDN云计算交流社区欢迎您的加入! 目录 项目名称 项目背景 项目目标 项…...
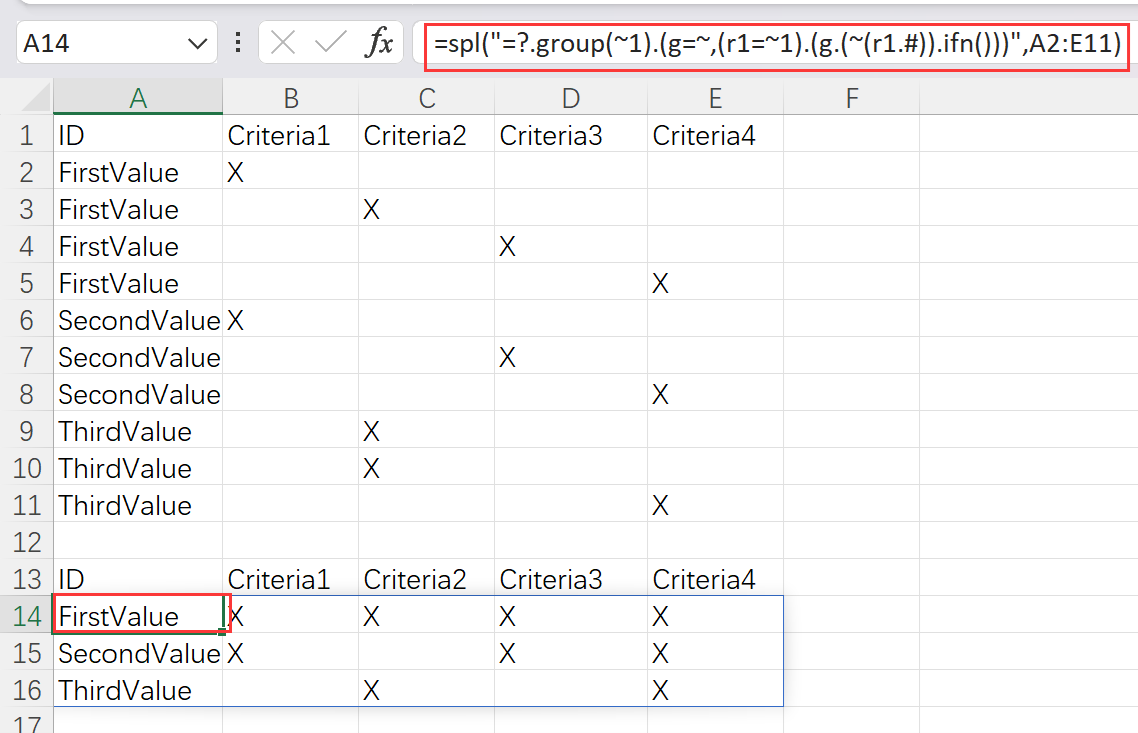
分组并合并其它列的非空值 --Excel难题#83
Excel第1列是分类,第2-42列是平行的多个数据项列,下表用部分列示例。数据有X或null两种情况,同一个分类的同一列数据偶尔有重复。 ABCDE1IDCriteria1Criteria2Criteria3Criteria42FirstValueX3FirstValueX4FirstValueX5FirstValueX6SecondVa…...

VM相关配置及docker
NAT——VMnet8网卡 桥接——WLAN/网线 仅主机——VMnet1网卡 docker与虚拟机的区别 启动docker服务 systemctl start docker 重启 systemctl start docker关闭docker服务 systemctl stop docker.servicedocker的两大概念 镜像:images,应用程序的静态文…...

Redis中Set数据类型常用命令
目录 1. 添加元素 2. 移除元素 3. 检查成员是否存在 4. 获取集合成员 5. 获取集合成员数量 6. 随机获取集合中的一个成员 7. 集合运算 8. 集合的移值 9. 提供集合的随机元素 在Redis中,Set是一种无序且不重复的字符串集合。 1. 添加元素 SADD key member [member ..…...

mysql误删数据恢复记录
背景 1、数据库版本 5.7.36,由于误操作删掉了表的所有数据,但是数据库备份每天凌晨进行、只能从备份恢复昨日的全量数据,当日的数据将会丢失 查看binlog配置 binlog配置 [mysqld] #设置日志三种格式:STATEMENT、ROW、MIXED 。 bi…...

论文阅读:Real-time Controllable Denoising for Image and Video
这篇文章是 CVPR 2023 的一篇文章,探讨了在图像与视频降噪中,如何实时控制降噪强度的问题。 Abstract 图像或者视频降噪,是在细节与平滑度之间的一个微妙的平衡,因为噪声与细节都属于高频信息,降噪在去除噪声的同时&…...

【Kubernetes】虚拟 IP 与 Service 的代理模式
虚拟 IP 与 Service 的代理模式 1.userspace 代理模式2.iptables 代理模式3.IPVS 代理模式 由于 Service 的默认发布类型是 ClusterlP,因此也可以把 ClusterIP 地址叫作 虚拟 IP 地址。在 Kubernetes 创建 Service 时,每个节点上运行的 kube-proxy 会自动…...

深度学习·Pytorch
以下代码源自李沐 自定义模块类 继承module类 继承nn.Module重写构造函数前向传播 class MLP(nn.Module):# 用模型参数声明层。这里,我们声明两个全连接的层def __init__(self):# 调用MLP的父类Module的构造函数来执行必要的初始化。# 这样,在类实例…...

fastzdp_sqlmodel新增get_first和is_exitsts方法
说明 经过fastzdp_login的整合,我们发现,fastzdp_sqlmodel还可以继续封装两个便捷的方法。 get_first:获取查询结果集中的第一条数据is_exitsts:判断数据是否已存在 封装get_first方法 def get_first(engine, model, query_di…...

嵌入式软件--数电基础 DAY 3
一、二进制 (1)文字表述 二进制数只能取0,1两个数字,逢二进一。 通过二进制表达文字。如战争时代的电报。 通过电灯泡的亮灭传递出信息。可以对灯亮和灯灭富裕一些含义,就能传达出想要的消息。 这就是编码和解码两…...

【生成式人工智能-十五-经典的影像生成方法-GAN】
经典的影像生成方法-GAN GANDiscriminatorGenerator还需要加入额外信息么 GAN可以加在其他模型上面我们可以用影像生成模型做什么? 前面讲过VAE和Flow-based以及diffusion Model ,今天讲最后一种经典的生成方法GAN。 GAN 前面讲的几种模型都是用加入额外…...

python 已知x+y=8 求x*y*(x-y)的最大值
先用导数求解 已知xy8 求xy(x-y)的最大值 令y8-x 则 f(x)x⋅(8−x)⋅(x−(8−x))x⋅(8−x)⋅(2x−8) 导数方程为 f(x)-3x^2 24x - 32 求方程 − 3 x 2 24 x − 32 0 -3x^2 24x - 32 0 −3x224x−320 的根。 首先,我们可以尝试对方程进行因式分解。观察…...

windows平台的postgresql主从数据库流备份
主: 操作系统:windows10 数据库版本:postgresql-16.2 ip:192.168.3.254 从: 操作系统:windows10 数据库版本:postgresql-16.2 ip:192.168.3.253 配置主库 配置 pg_hba.conf 文件 在 pg 的安装目录下,找到 …...

Spring 常见设计模式
什么是设计模式? 设计模式(Design pattern)是为解决软件设计中通用问题而被提出的一套指导性思想。它是一种被反复验证、经过实践证明并被广泛应用的代码设计经验和思想总结,可以帮助开发者通过一定的模式来快速的开发高质量、可维…...

优化大量数据导出到Excel的内存消耗(二):如果数据超出Excel单表上限,则进行分表
优化前:优化大量数据导出到Excel的内存消耗_大文件异步导出 内存占用高-CSDN博客 写Excel文件报错:Invalid row number (1048576) outside allowable range (0..1048575) 写入Excel时遇到IllegalArgumentException,原因是超出允许的最大行数…...

AI技能库实战:模块化设计赋能博客创作自动化工作流
1. 项目概述:一个面向AI时代的博客技能开源库最近在GitHub上闲逛,发现了一个挺有意思的项目,叫inblog-inc/inblog-ai-skills。光看这个名字,就透着一股子“务实”的味道。它不是又一个教你如何调参炼丹的AI模型库,也不…...

构建思想知识图谱:NLP与Elasticsearch在结构化资料库中的应用
1. 项目概述与核心价值最近在整理一些历史资料和思想研究时,我接触到了一个名为“mao-zedong-perspective”的项目。这个项目名直译过来就是“毛泽东视角”,它并非一个传统的软件应用,而更像是一个数字化的思想资料库或研究框架。作为一名长期…...

Armv8-A内存模型特性寄存器详解与应用
1. Armv8-A内存模型特性寄存器概述在Armv8-A架构中,内存模型特性寄存器(Memory Model Feature Registers,简称MMFR)是一组关键的系统寄存器,用于描述处理器实现的内存管理功能特性。这些寄存器采用只读访问模式&#x…...

Rust构建的跨平台数据备份工具relic:安全高效的快照管理与自动化策略
1. 项目概述:一个面向未来的跨平台数据备份与同步工具最近在整理个人工作流时,我一直在寻找一个能让我在不同设备、不同操作系统之间无缝同步项目配置、文档和代码片段的工具。市面上的云盘虽然方便,但总感觉不够“程序员友好”——要么同步粒…...

5分钟快速上手Ketcher:免费开源的Web分子绘图神器
5分钟快速上手Ketcher:免费开源的Web分子绘图神器 【免费下载链接】ketcher Web-based molecule sketcher 项目地址: https://gitcode.com/gh_mirrors/ke/ketcher Ketcher是一款功能强大的开源化学绘图工具,专为化学家、生物学家和研究人员设计。…...

DevUI布局系统完全指南:响应式设计的终极解决方案
DevUI布局系统完全指南:响应式设计的终极解决方案 【免费下载链接】ng-devui Angular UI Component Library based on DevUI Design 项目地址: https://gitcode.com/DevCloudFE/ng-devui DevUI布局系统是Angular UI组件库中的核心功能,为开发者提…...

TestDisk与PhotoRec:免费开源的数据恢复双雄终极指南
TestDisk与PhotoRec:免费开源的数据恢复双雄终极指南 【免费下载链接】testdisk TestDisk & PhotoRec 项目地址: https://gitcode.com/gh_mirrors/te/testdisk 在数字时代,数据丢失是每个人都会遇到的噩梦。无论是误删除重要文件、分区表损坏…...

重磅!国家首部NAD⁺抗衰共识发布,这11条建议必读!
2026年4月,国内首个《NAD⁺在衰老相关疾病中的作用及临床应用中国专家共识(2026版)》正式发布!这份由中华医学会老年医学分会牵头、汇聚全国衰老医学、代谢病、心血管病及神经病学等领域权威专家共同制定的国家级共识,…...

NumPy 使用指南
一、为什么选择 NumPy 而非 Python 列表Python 原生列表(list)虽能存储数组形式的数据,但存在显著性能缺陷:内存效率低:列表存储的是对象指针,即使存储简单数值(如 [0,1,2])…...

用TensorFlow 2.0复现Mask R-CNN:从ResNet主干到ROI Align的保姆级代码解读
TensorFlow 2.0实现Mask R-CNN核心技术解析:从ResNet到ROI Align的工程实践 在计算机视觉领域,实例分割一直是最具挑战性的任务之一。它不仅需要精确地定位物体,还要在像素级别上区分不同实例。本文将深入探讨如何用TensorFlow 2.0实现Mask R…...