亚马逊云科技产 Amazon Neptune 图数据库服务体验
目录
- 图数据库
- 为什么使用图数据库
- Amazon Neptune
- 实践
- 登陆
- 创建 S3 存储桶
- notebook
- 图神经网络快速构建
- 加载数据
- 配置端点
- Gremlin 查询
- 删除环境
- 删除 S3 存储桶
- 总结
图数据库
图数据库是一种专门用于存储和处理图形数据结构的数据库管理系统。图形数据结构由节点(Node)和边(Edge)组成,节点代表实体,边代表实体之间的关系。
图形数据库经过优化,可以存储和查询数据项之间的关系。它们将数据项本身存储为图的顶点,将它们之间的关系存储为边。每条边都有一种类型,并且从一个顶点(起点)指向另一个顶点(终点)。关系可以称为谓词,也可以称为边,顶点有时也称为节点。在所谓的属性图中,顶点和边都可以具有 与之关联的其他属性。比如下图是一个表示社交网络中的朋友和爱好的图表:

为什么使用图数据库
在当今互联网飞速发展的背景下,传统的关系型数据库在处理复杂关系操作时显得力不从心。然而,图数据库通过存储数据和其相互关系,大大提升了对数据节点和关系操作的效率。图数据库能够在线性时间复杂度内访问数据节点和关系,甚至可以在一秒钟内遍历数百万级的关系边,表现出显著的性能优势。所以图数据库的优势越发明显,在开发过程中扮演着重要角色。
Amazon Neptune
亚马逊云科技产品Amazon Neptune 数据库是一个无服务器图形数据库,旨在实现卓越的可扩展性和可用性。Neptune 数据库提供内置安全性、持续备份以及与其他 AWS 服务的集成。Neptune 全球数据库为全球分布式应用程序提供跨区域数据复制,以实现低延迟读写、灾难恢复和可扩展性。其中Neptune具有优势极其显著,具体如下:
-
Neptune支持图形用例,例如推荐引擎、欺诈检测、知识图谱、药物发现和网络安全。 -
Neptune数据库具有高可用性,具有只读副本、时间点恢复、持续备份到 Amazon S3 以及跨可用区复制等功能。 -
Neptune提供数据安全功能,支持静态和动态加密。 -
Neptune是完全托管的,因此您不再需要担心数据库管理任务,例如硬件配置、软件修补、设置、配置或备份。
实践
接下来我们来体验一波!
登陆
首先需要打开亚马逊云科技官网,注册登录。
创建 S3 存储桶
控制台搜索cloudshell

然后切换一下节点,随便选择一个

接下来就可以创建 S3 存储桶了

cheetah-qing为自己的桶名,需要自定义。创建完成之后需要创建堆栈
aws cloudformation create-stack --stack-name get-started-neptune-ml --template-url https://s3.amazonaws.com/ee-assets-prod-us-east-1/modules/4f0f18a83e6148e895b10d87d4d89068/v1/gcr-buildon-selfpace/gcr-buildon-neptune-ml-nested-stack.json --capabilities CAPABILITY_IAM --region us-east-1 --disable-rollback
然后就需要等待服务启动。
notebook
在搜索栏输入neptune,点击进入,导航栏选择“笔记本”

紧接着点击右侧的“查看笔记本文档”。

注意:倘若没有 notebook,需确定地区是否选择正确,其次确认后台服务是否都启动完成。
图神经网络快速构建
我们在上方已经打开笔记,接着在控制台输入命令来检查集群是否已正确配置可以运行 Neptune ML。

加载数据
这里使用 Bulk Loader来加载数据,通过编写脚本可以实现自动执行从MovieLens网站下载数据,调整数据格式,并将数据载入Neptune的全过程。
s3_bucket_uri="s3://cheetah-qing"
# remove trailing slashes
s3_bucket_uri = s3_bucket_uri[:-1] if s3_bucket_uri.endswith('/') else s3_bucket_uri
执行response = neptune_ml.prepare_movielens_data(s3_bucket_uri)命令即可下载 MovieLens 数据,并将其调整为可被 Neptune 的 Bulk Loader 兼容的格式。
结果如下:
Completed Processing, data is ready for loading us
ing the s3 url below:
s3://cheetah-qing/neptune-formatted/movielens-100k
操作完成后,执行下面代码加载数据
%load -s {response} -f csv -p OVERSUBSCRIBE --run

配置端点
执行命令来创建端点,并获取到推理端点的端点名称。
setup_node_classification=True
setup_node_regression=True
setup_link_prediction=True
setup_edge_classification=True
setup_edge_regression=Trueendpoints=neptune_ml.setup_pretrained_endpoints(s3_bucket_uri, setup_node_classification, setup_node_regression, setup_link_prediction, setup_edge_classification, setup_edge_regression)node_classification_endpoint=endpoints['node_classification_endpoint_name']['EndpointName']
node_regression_endpoint=endpoints['node_regression_endpoint_name']['EndpointName']
link_prediction_endpoint=endpoints['prediction_endpoint_name']['EndpointName']
edge_classification_endpoint=endpoints['edge_classification_endpoint_name']['EndpointName']
edge_regression_endpoint=endpoints['edge_regression_endpoint_name']['EndpointName']Gremlin 查询
先执行下面代码,来验证图谱中,Forrest Gump 这个 movie 的 genre 不包含任何 genre 值

接下来我们修改这个查询。首先指定要在 Gremlin查询中使用的推理端点:g.with("Neptune#ml.endpoint","<INSERT ENDPOINT NAME>"),然后指定我们想要获取该属性的预测值:with("Neptune#ml.classification")。将这些内容结合在一起就可以得到下方的查询,该查询可通过我们的产品知识图谱 Forrest Gump 的 genre。执行下面命令
%%gremlin
g.with("Neptune#ml.endpoint","${node_classification_endpoint}").V().has('title', 'Forrest Gump (1994)').properties("genre").with("Neptune#ml.classification").value()结果如下:

查看结果可知,预测结果似乎是正确的,Forrest 似乎被正确预测为 Drama 类型。
删除环境
如果不需要这个服务,就把它删除掉,防止持续扣费。

删除 S3 存储桶
选择 cloudshell,执行aws s3 rb s3://cheetah-qing --force删除 S3 存储桶。

总结
Amazon Neptune 是一种高性能、可扩展且完全托管的图数据库服务,具有许多优势,使其在处理复杂关系数据时非常有效。
- 快速开发和部署:
Neptune提供灵活的开发和部署环境,支持快速原型设计和部署,减少开发时间和成本。 Neptune无缝集成 AWS 的其他服务,如AWS Lambda、Amazon CloudWatch、Amazon S3等,便于构建复杂的应用程序和数据管道。- 全球部署:通过
Amazon Neptune全球部署选项,可以在全球多个区域快速部署和访问图数据库,实现低延迟和高可用性。 - 高性能:
Neptune设计用于快速、低延迟的图查询,能够高效处理包含数十亿个关系和节点的图数据。其优化的存储引擎和查询引擎能提供快速的图遍历和查询性能。 - 完全托管:作为 AWS 的托管服务,
Amazon Neptune减少了用户管理数据库基础设施的负担。AWS 负责软件更新、补丁管理、备份和恢复等操作,使用户可以专注于应用开发。
当然Amazon Neptune 还有很多操作,期待在以后的使用过程中继续挖掘!
相关文章:
亚马逊云科技产 Amazon Neptune 图数据库服务体验
目录 图数据库为什么使用图数据库Amazon Neptune实践登陆创建 S3 存储桶notebook图神经网络快速构建加载数据配置端点Gremlin 查询删除环境删除 S3 存储桶 总结 图数据库 图数据库是一种专门用于存储和处理图形数据结构的数据库管理系统。图形数据结构由节点(Node&…...
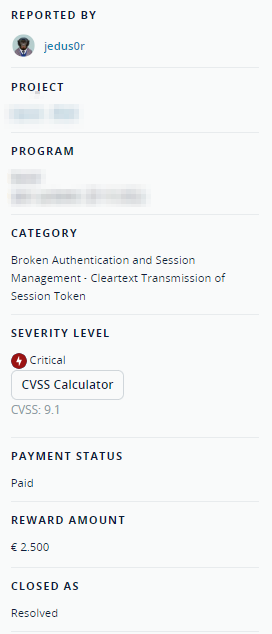
【网络安全】重置密码token泄露,实现账户接管
未经许可,不得转载。 文章目录 正文 正文 对某站点测试过程中,登录账户触发忘记密码功能点,其接口、请求及响应如下: PUT /api/v1/people/forgot_password 可以看到,重置密码token和密码哈希均在响应中泄露。 删除co…...

计算机基础知识复习8.13
cookie和session区别 cookie:是服务器发送到浏览器,并保存在浏览器端的一小块数据 浏览器下次访问服务时,会自动携带该块数据,将其发送给服务器 session:是javaEE标准,用于在服务端记录客户端信息 数据存放在服务端更加安全&a…...

Unity URP无光照下Shadow 制作 <二> 合批处理
闲谈 相信大家在日常工作中发现了一个问题 , urp下虽然可以做到3个Pass 去写我们想要的效果,但是,不能合批(不能合批,那不是我们CPU要干冒烟~!) 好家伙,熊猫老师的偏方来了 &#x…...

微乐校园pf
TOC springboot451微乐校园pf 绪论 1.1 研究背景 当前社会各行业领域竞争压力非常大,随着当前时代的信息化,科学化发展,让社会各行业领域都争相使用新的信息技术,对行业内的各种相关数据进行科学化,规范化管理。这…...

文件其他相关函数
symlink 链接文件: file.txt -> hello.c 软链接文件、符号链接文件 硬链接文件 命令行:ln -s 123 softlink 快捷方式 int symlink(const char *oldpath, const char *newpath); 功能: 创建一个链接向oldpath文件的新符号链接文件 参数: oldpath:被链接向…...

SQLALchemy ORM 的关联关系之 ORM 中的多对多
SQLALchemy ORM 的关联关系之 ORM 中的多对多 场景示例实现多对多关系定义模型插入和查询数据总结在 SQLAlchemy ORM 中,多对多(Many-to-Many)关联关系是一种常见的关系类型,它表示两个表中的行可以相互关联,即一个表中的多行可以与另一个表中的多行相关联。为了实现这种关…...

sdkman install慢,采用squid代理
(1)A机器,IP:yy.yy.yy.yy 安装squid yum install squidvi /etc/squid/squid.confacl allowed_ip src xx.xx.xx.xx http_access allow allowed_ip http_access deny allsystemctl restart squid 开放3128端口 (2)B机器,IP:xx.xx.xx.xx, export http_proxyhttp://y…...

实时监控Windows服务器:使用Prometheus和Grafana的终极方案
视频指南 【1】快速上手:在Windows系统上部署Prometheus与Grafana,实时监控性能指标 【2】快速上手:在Windows系统上部署Prometheus与Grafana,实时监控性能指标 1. 下载并安装 Prometheus 下载 Prometheus: 访问 Pro…...

【文科生能看懂的】牛顿二项式定理
牛顿二项式定理 简单的二项式整数次幂展开的结果中的规律结果中各项的指数结果中各项的系数 二项式定理 牛顿二项式定理就是用来求某个二项式的整数次幂的展开式的。 简单的二项式整数次幂 我们可以先从简单的情况开始,比如二项式 ( a b ) (ab) (ab)的整数次幂&a…...

Fly Catcher:通过监测恶意信号来检测飞机欺骗
Fly Catcher 的开发者 Angelina Tsuboi 是一名飞行员、网络安全研究员和发明家。 她决定着手一个将这三个不同兴趣结合起来的项目,以解决航空雷达系统的一个重大问题。 ADS-B 系统最初用于基本的飞机定位和跟踪,Tsuboi 对该系统的网络安全方面进行了深…...

计算机网络——HTTP协议详解(上)
一、HTTP协议简单介绍 1.1 什么是HTTP协议 HTTP(超文本传输协议)是一种用于在Web浏览器和Web服务器之间传输数据的应用层协议。它是一种无状态协议,即服务器不会保留与客户端的任何连接状态信息,每个请求都被视为一个独立的事务。…...

十九、中介者模式
文章目录 1 基本介绍2 案例2.1 Developer 抽象类2.2 FrontendDeveloper 类2.3 BackendDeveloper 类2.4 Mediator 接口2.5 ProjectManager 类2.6 Client 类2.7 Client 类的运行结果2.8 总结 3 各角色之间的关系3.1 角色3.1.1 Colleague ( 同事 )3.1.2 ConcreteColleague ( 具体的…...

编程参考 - 头文件中使用static inline
在Linux kernel的头文件中,经常使用static inline来声明一个函数。 比如include/linux/delay.h中, static inline void ssleep(unsigned int seconds) { msleep(seconds * 1000); } static Keyword * 范围限制: 当应用于函数或变量时&#…...

Uniapp使用antd组件库
组件库官网 https://www.antdv.com/docs/vue/introduce-cn 安装 在命令行终端输入 npm uni --save ant-design-vue配置 我这里用的是uniapp的vue3版本模板 在main.js里面引入 只要改下面带序号的地方即可 import App from ./App// #ifndef VUE3 import Vue from vue im…...

计算机毕业设计选题推荐-高校实验室管理系统-Java/Python项目实战
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…...

nest定义响应码message文本
需求 需要对接口的异常响应码,手动设置message文本!!! 例如:项目中使用multer中间件实现文件上传,multer设置了文件大小限制,该中间件校验文件时错误(文件超出)会自动响…...

Java | Leetcode Java题解之第342题4的幂
题目: 题解: class Solution {public boolean isPowerOfFour(int n) {return n > 0 && (n & (n - 1)) 0 && n % 3 1;} }...

【日常开发】java中一个list对象集合 将字段a为 大豆 小麦 玉米等元素放在最前面 并组成新集合
🎈边走、边悟🎈迟早会好 在Java中实现这个功能,可以使用Stream来筛选出符合条件的元素,将它们放在新集合的前面,同时保留其他元素在新集合的后面。以下是如何实现的代码示例: 代码示例: impo…...

C++ 设计模式——原型模式
原型模式 原型模式主要组成部分原型模式的使用步骤原型模式的 UML 图原型模式 UML 图解析优点和缺点适用场景总结 原型模式 原型(Prototype)模式是一种创建型模式。原型模式通过(原型对象)克隆出对个一模一样的对象。实际上,该模式与其说是一种设计模式,…...

强化学习优化文本生成:从原理到实战,打造可控AI创作工具
1. 项目概述:当强化学习遇上文本生成如果你玩过AI绘画,一定对“提示词工程”不陌生——通过精心设计的文字描述,让模型画出你想要的画面。但你是否想过,这个过程本身也可以被“优化”?比如,你希望模型生成一…...

职得Offer校园求职助手Pro深度评测:一个AI Agent陪你跑完求职全流程
一、 职得Offer是什么?—— 不止是工具,更是全程陪伴的AI求职伙伴 在AI应用爆发的今天,面对市面上众多的简历模板、面经题库和招聘平台,求职者尤其是学生群体,依然会陷入“信息过载却无从下手”的困境。“职得Offer校…...

STM32F429IGT6项目实战:基于STM32CubeMX的SDRAM配置与性能优化
1. 为什么需要SDRAM配置 在嵌入式开发中,尤其是使用STM32F429IGT6这类高性能MCU时,SDRAM(同步动态随机存取存储器)的配置往往成为项目成败的关键。我曾在多个图形界面项目中深刻体会到,当需要处理高分辨率图像或大量数…...

LizzieYzy围棋AI分析平台:从棋谱复盘到AI教练的完整指南
LizzieYzy围棋AI分析平台:从棋谱复盘到AI教练的完整指南 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy 围棋作为世界上最复杂的棋类游戏之一,其学习曲线一直被认为是陡峭而…...

告别GBIF官网卡顿!用R语言raster/dismo包5分钟搞定物种分布数据下载与清洗
告别GBIF官网卡顿!用R语言raster/dismo包5分钟搞定物种分布数据下载与清洗 当你在深夜赶论文,急需下载某个物种的全球分布数据时,GBIF官网却不断弹出"503 Service Unavailable";当你终于打开页面,却发现每页…...

AMD处理器硬件深度调试终极方案:SMUDebugTool完全实战手册
AMD处理器硬件深度调试终极方案:SMUDebugTool完全实战手册 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...
)
Simulink里三种TD微分器怎么选?用带噪声的正弦信号实测给你看(附模型)
Simulink中三种TD微分器的工程选型实战指南 从实验室到产线:为什么TD微分器如此重要 在电机控制、机器人导航和工业自动化领域,工程师们经常面临一个共同挑战:如何从带有噪声的传感器信号中准确提取速度信息。编码器、加速度计等传感器输出的…...

如何快速上手网易游戏NPK文件解包工具:新手3步完整教程
如何快速上手网易游戏NPK文件解包工具:新手3步完整教程 【免费下载链接】unnpk 解包网易游戏NeoX引擎NPK文件,如阴阳师、魔法禁书目录。 项目地址: https://gitcode.com/gh_mirrors/un/unnpk 你是否对网易游戏如《阴阳师》、《魔法禁书目录》中的…...

DellFanManagement终极指南:如何彻底掌控戴尔笔记本风扇噪音与散热平衡
DellFanManagement终极指南:如何彻底掌控戴尔笔记本风扇噪音与散热平衡 【免费下载链接】DellFanManagement A suite of tools for managing the fans in many Dell laptops. 项目地址: https://gitcode.com/gh_mirrors/de/DellFanManagement 还在为戴尔笔记…...

嵌入式Python库CI/CD实战:Travis CI自动化测试与发布
1. 项目概述与核心价值 如果你正在维护一个开源项目,或者在一个小团队里负责核心模块的开发,那么你一定对“这次改动会不会把别人的代码搞坏”这个问题感到头疼。尤其是在嵌入式开发领域,比如我们常用的CircuitPython库,代码最终要…...