【数据结构】——十大排序详解分析及对比
【数据结构】——十大排序详解分析及对比
文章目录
- 【数据结构】——十大排序详解分析及对比
- 前言
- 1. 排序的概念及其运用
- 1.1 排序的概念
- 1.2 排序的应用
- 2. 插入排序
- 2.1 直接插入排序
- 2.2 希尔排序
- 3. 选择排序
- 3.1 选择排序
- 3.2 堆排序
- 4 交换排序
- 4.1 冒泡排序
- 4.2 快速排序
- 4.2.1 霍尔法
- 4.2.2 前后指针法
- 4.2.3 优化方法
- 4.3.4 快排(非递归)
- 5. 归并排序
- 5.1 归并(递归)
- 5.2 归并(非递归)
- 5.3 外排序
- 6. 非比较排序
- 6.1 计数排序
- 6.2 基数排序
- 6.3 桶排序
- 结语
前言
排序算法是《数据结构》中最基本的算法之一
我们先来大致简单了解一下排序算法吧
排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存
根据排序的特点可以将排序分为:直接插入排序、希尔排序、选择排序、堆排序、冒泡排序、快速排序、归并排序等

1. 排序的概念及其运用
1.1 排序的概念
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的
- 内部排序:数据元素全部放在内存中的排序
- 外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不断地在内外存之间移动数据的排序

1.2 排序的应用
排序在日常生活当中很常见
比如班级成绩排名,学校排名,地区GDP排名等等都是排序

这个就是学校排名的实列,像这样的排序例子还有非常多,咱就不一一介绍了哈
感兴趣的可以看看
2. 插入排序
2.1 直接插入排序
我们先来看看动图展示,认识一下直接插入排序
看动图是不是非常地简单,不就是一个一个比较大小嘛,接下来我们来看看直接插入排序的基本思想
基本思想
直接插入排序是一种简单的插入排序法,其基本思想是:
- 把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列
- 当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经排好序,此时用array[i]的排序码与array[i-1],array[i-2],…的排序码顺序进行比较,找到插入位置即将array[i]插入,原来位置上的元素顺序后移
其实不就是先将左边的第一数当作是有序的,然后把第二个数作为插入数从右往左与有序区间中的每个数做比较
这时会出现两种情况,如果插入数比该数小,则该数往后挪动,插入数继续向左比较;如果插入数比该数大,则说明插入数找到了插入有序区间的位置,直接插入。以此类推,直到最后一个数插入后就完成了排序
下面就是代码实现
void InserSort(int* a, int n)
{for (int i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];//保存插入数while (end >= 0)//对比直到最后一个数{if (a[end] > tmp)//比插入数大{a[end + 1] = a[end];//后移end--;//更新比较数}else{break; }}a[end + 1] = tmp;//插入数据}
}
算法分析
时间复杂度:
- 最坏情况:逆序每次插入的数都是有序数组最小的,比较次数:1+2+3…n1=(n-1)*n/2
- 大O渐进表示法0(N^2)
- 最好情况:顺序有序经有序遍历一次数组即可
- 大O渐进表示法O(N)
平均情况:介于**O(N)~((N^2)**之间
空间复杂度:
只开辟常数级别空间 O(1)
稳定性:
遇到相等的数放在后面,稳定
2.2 希尔排序
希尔排序其实就是对插入排序进行优化,也就是插入排序的pro max
我们先来看看动图展示,认识一下希尔排序

基本思想
先选定一个整数,把待排序文件中所有记录分成个组,所有距离为的记录分在同一组内,并对每一组内的记录进行排序。然后,取,重复上述分组和排序的工作。当到达=1时,所有记录在统一组内排好
前面我们说了当数组是有序的时候,插入排序的时间复杂度是O(N)
那我们可不可以想办法让数组接近有序呢?这样我们再进行一组插入排序的时候时间复杂度,也基本会接近O(N)
这时一个叫希尔的人就提出了预排序的概念
希尔排序也就是分为两步
- 预排序:目的是让数组接近有序
- 直接插入排序
那预排序如何做到让数组接近有序呢?
如果我们一组数据分成gap组。每组数据都是在数组中相隔gap位置的数据组合,如果我们让每一组都使用插入排序排好后那数组就会比原来更接近有序
举个例子,假如我们用希尔排序,排 6,2,4,1,8,0,3,9,7,5 这个数组
当 gap = 3 ,就把数组分为了三组,那第一组来说,第一组是 6,1,3,5 按照直接插入排序来排的话,结果就是 1,3,5,6
当 gap = 3 的所有分组都排序后数据就更接近有序
这时数组可能还是没那么有序,所以我们会进行多次分组排序

现在我们再来一次 gap = 2 的预排序看看,是不是发现预排序后数组已经非常接近有序了

这时候我们在来一次插入排序( gap = 1 就是直接插入排序)就完成数组的希尔排序

这时我们是不是感觉希尔排序要比直接插入排序好用一些呀
我们会发现又有一些新问题出现了,gap该怎么合理取值?我们会发现
- gap越大的话,大的数越快跳到后面,小的数越快跳到前面,但是这样就越不接近有序。例如:200个数据
gap=100这样每组的数据只有两个然后把每组的最大的放在前100个位置,最小的放在后100个位置,这样预排序的效果不太好,万一每组的两个数组是最大或第二大的数,那这样第二大数放在了最小数的位置。最大的数也才放在中间的位置 - gap越小的话,也接近有序,gap=1的时候就是插入排序。但是太小就达不到预排序让数组接近有序的目的了
因此我们希望gap是变化的,同时gap有两种取值
- gap=gap/2
- gap=gap/3
我们实验发现 gap/3 的时候,预排序的效果是比较好的,但是 gap/3 最后不一定能保证gap=1,怎么办呢
所以 gap=gap/3+1 这样一定能保证gap最后一定是1。为什么?大家想一个数一直除3,那么最后他一定会被除到0,那么0又是由 gap/3 得来的。所以最后一次/3前gap一定是1或2其中个取值;如果是1的话刚好是预排序,但是如果是2最后一次排序就不是预排序,但是我们+1就算最后一次是2。2/3+1=1 也能保证最后一次是1,当gap是1时就是插入排序就能保证最后一次排序一定是插入排序
下面就是代码实现
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){//+1保证最后一次一定等于1//gap>1是预排序//gap=1是插入排序gap = gap / 3 + 1;for (int i = 0; i < n - gap; i++)//多组一起排{int end = i;int tmp = a[end + gap];//保存插入数while (end >= 0)//对比直到最后一个数{if (a[end] > tmp)//比插入数大{a[end + gap] = a[end];//后移end--;//更新比较数}else{break;}}a[end + gap] = tmp;}}
}
算法分析
时间复杂度:
希尔排序的时间复杂度不好计算,因为gap是变化的。且前面都排序会对,导致很难去计算,因此在好多书中给出的希尔排序的时间复杂度都不固定,但是目前公认希尔排序的时间复杂度大概在 O(N^1.3) 左右

我们来简单证明看一下
这里为了方便证明我们先把gap看作 gap=gap/3 变化 n个数据排序

第一次:组数:gap = n/3 每组数据个数:n/gap = 3
最坏情况:逆序
插入比较次数:等差数列 1+2 = 3
所有组排完消耗:n/3*3=n
第二次:组数:gap = n/3/3 = n/9 每组数据个数:n/gap = n/n/9 = 9
最坏情况:逆序
插入比较次数:等差数列 1+2+3…8 = 36
所有组排完消耗:n/9*36 = 4n
……
那后面的组我们好像也可以按照这样的规律计算出来
因为排序每组消耗是等差数列,gap组数我们也可以算,但是问题在于我们第一次排序是逆序,排序完后他还可能是逆序吗?
显然不是,所以后面我们就不能按照最坏情况去算等差数列也就不存在了。这就需要涉及数学的概率论等更高深的知识了,已经超出我的数学水平了

所以我们只知道第一次排序和最后一次排序每趟排序消耗都是n,中间每趟排序只能猜测大概是先增后减,具体如何变化还需要涉及更深的数学知识。
不过经过一些测试,希尔排序的时间复杂度大概是 O(N^1.3) 左右
但是我们知道走了多少次预排序
- 如果gap/2那就是gap/2/2/2…=1结束
- 如果gap/3就是gap/3/3/3…=1结束
所以预排序的次数是对数级别
我们只能记住结论:希尔排序的时间复杂度大概在 O(N^1.3) 左右就好了
空间复杂度:
只用到常数级别空间,O(1)
稳定性:
相同的数据分到不同组时候,不可控制,不稳定
3. 选择排序
3.1 选择排序
我们先来看看动图展示,认识一下选择排序

看动图是不是有点了解了,接下来我带着大家看看选择排序的基本思想
基本思想
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完
在元素集合array[i]–array[n-1]中选择关键码最大(小)的数据元素若它不是这组元素中的最后一个(第一个)元素,则将它与这组元素中的最后一个(第一个)元素交换在剩余的array[i]–array[n-2](array[i+1]–array[n-1])集合中,重复上述步骤,直到集合剩余1个元素
简单来说就是遍历一遍数组,找出最小数,然后将未排序区间的第一个数与最小的数交换
以此类推,每次都能排序一个数,直到最后一个数,选择排序就完成了
下面就是代码实现
我们发现代码的时间复杂度太差了,所以代码实现我们做了一点优化,每一次遍历确定一个最小数和最大数,然后分别放在未排序区间的末尾和开始位置即可
void SelectSort(int* a, int n)
{int begin = 0, end = n - 1;while (begin < end){int max = begin, min = end;for (int i = begin + 1; i <= end; i++){if (a[i] > a[max])//找最大值{max = i;}if (a[i] < a[min])//找最小值{min = i;}}Swap(&a[begin], &a[min]);if (max == begin)//若max与begin重叠{max = min;}Swap(&a[max], &a[end]);begin++;end--;}
}
不过要注意的是如果我们先交换最小的数,如果max和begin位置重叠,begin被交换后。max也被交换了,所以要重新更新一下 max = min
算法分析
时间复杂度:
时间复杂度为 O(N^2)
每次遍历选出2个数遍历n/2次即可 n-1+n-3…1=(n-1+1)/2*n/2=n~2/4. 大O渐进表示法: O(N^2)
空间复杂度:
只用了常数级别空间,O(1)
稳定性:

如图,不稳定
3.2 堆排序
我们先来看看动图展示,认识一下堆排序

看完动图是不是感觉有点懵,别急我们来看看堆排的基本思想
基本思想
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆
将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了
堆排序就是利用堆顶数据是最大或最小这一特性进行排序,每次都把堆顶元素放在待排序区间后面,然后重新调整建堆,以此类推即可完成排序
下面就是代码实现
void AdjustDown(int* a, int size, int parent)
{int child = parent * 2 + 1;//孩子节点while (child < size){if (child + 1 < size && a[child] > a[child + 1])//孩子节点{child++;}//假设法if(a[child] < a[parent])//判断{Swap(&a[parent], &a[child]);//交换parent = child;child = parent * 2 + 1;}else{break;//调整完毕}}
}
void HeapSort(int* a, int n)
{for (int i = (n - 1 - i) / 2; i >= 0; i--)//向下调整建堆{AdjustDown(a, n, i);}int end = n - 1;//最后一个堆元素while (end > 0){Swap(&a[0], &a[end]);//交换堆顶元素和最后一个堆元素AdjustDown(a, end, 0);//交换堆顶元素和最后一个堆元素end--;//更新最后一个堆元素}
}
算法分析
时间复杂度:
堆排序的时间复杂度是 O(N*logN)
构建初始堆经推导复杂度为O(n),在交换并重建堆的过程中,需交换n-1次,而重建堆的过程中,根据完全二叉树的性质,[log(n-1),log(n-2)…1]逐步递减,近似为n*logn
我们来简单的证明一下

空间复杂度:
只用到常数级别空间,O(1)
稳定性:

如图,不稳定
4 交换排序
4.1 冒泡排序
我们先来看看动图展示,认识一下冒泡排序

看完动图,是不是感觉冒泡排序也是非常简单的,接下来我们看看冒泡排序的基本思想
基本思想
交换排序,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置,交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动
从左边开始两两比较,将大的数移到右边,再往后两两比较,这样每都选出一个待排序区间最大的数,进行n-1躺排序就能完成数组有序
接下来就是代码实现
void bubble_sort(int arr[],int sz)
{for (int i = 0; i < sz - 1; i++)//控制趟数{int flag = 0;for (int j = 0; j < sz - 1 - i; j++)//控制比较次数{if (arr[j] > arr[j + 1])//判断是否交换{flag = 1;Swap(arr[j], arr[j + 1]);//交换}}if (flag == 0)break;//已经排好序直接结束循环}
}
其实代码也没什么好说的,这里我们用flag做优化,如果发生交换就标记一下,然后每次循环判断一下标记,如果没有标记说明没发生交换,说明已经有序,直接break结束就可以了
算法分析
时间复杂度:
最坏情况下:比较总数:n-1+n-2+…1=(n-1+1)/2*(n-1),大O渐进表示法:O(N^2)
冒泡排序的时间复杂度是 O(N^2)
空间复杂度:
只开辟常数级别空间 O(1)
稳定性:
只让大的数交换到右边。相等的数不交换,稳定
4.2 快速排序
快速排序我们这里介绍两种快排的方法以及如何进行快排的优化方案
4.2.1 霍尔法
我们先来看看动图展示,认识一下快速排序(霍尔法)

其实看动图挺懵的,接下来让我们一起看看快速排序(霍尔法)的基本思想吧
基本思想
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止
对于一组数据,选择一个基准元素(key),通常选择第一个或最后一个元素,我们就选择第一个元素作为我们的基准元素,然后定义一个左指针和右指针,左指针往右找大,右指针往左找小。找到后交换左右指针的位置数据,直到左右指针相遇。然后将key与相遇数据位置交换。这样key左边都是小于key的数,右边都是大于key的数。就完成了key的排序,再有同样的方法递归排序左右区间,直到序列中所有数据均有序为止
但是得保证相遇位置一定比key小才可以保证左边区间有序,现在就有一个问题,如何证明相遇位置一定比key小呢?
我们可以简单说一下
第一个元素做key,右边先走可以保证相遇位置比key小
相遇只有两种场景
- L遇R
R先走,遇到比key小的位置停下,L再走找不到比key大的数遇到R结束,R的位置就是比key小的位置

- R遇L
R先走,找小,没有找到比key小的,直接和L相遇了,L的位置是上一轮交换的位置交换完后的位置,L的位置就是比key小的数。此时R和L相遇相遇的位置就是L的位置,也就是比key小的数位置

相反:当最后一个元素做key,左边left先走时能保证相遇的位置比key大
接下来就是代码实现
int PartSort1(int* a, int left, int right)//霍尔法
{int begin = left, end = right;int keyi = left;//keyi为左 右先走 keyi为右 左先走while (begin < end){while (begin < end && a[end] >= a[keyi]){--end;}while (begin < end && a[begin] <= a[keyi]){++begin;}Swap(&a[begin], &a[end]);//两个都找到,交换}Swap(&a[keyi], &a[begin]);//相遇交换keyi和相遇的数return begin;//keyi移动到相遇位置
}
void QuickSort(int* a,int left,int right)//递归
{if (left >= right)//区间不存在结束递归{return;}else{int keyi = PartSort1(a, left, right);QuickSort(a, left, keyi - 1);//递归左序列QuickSort(a, keyi + 1,right);//递归右序列}
}
我们这边也是用到了递归的方法,我们也就来顺便画一下递归展开图,加深一下理解

4.2.2 前后指针法
我们先来看看动图展示,认识一下快速排序(前后指针法)

观看动图我们依然能感觉到快排的思想,不过这个方法就比霍尔法容易理解得多,我们还是来看看基本思想,看看我说的对不对
基本思想
既然快排的每一趟都是分割好左右区间并且排好key,那我们就可以区间思想来完成这个事情,就是前后指针法目的分成左右区间

我们让slow指针维护<key区间,fast遍历扫描,遇到比key小的位置停下然后放到slow的位置,slow++,fast继续++扫描。这样就形成这样的区间

最后将key和slow交换即可

接下来就是代码实现
int PartSort2(int* a, int left, int right)//快慢指针法
{int slow = left, fast = slow + 1;int keyi = left;while (fast <= right){if (a[fast] < a[keyi] && slow!=fast ){slow++;//扩大区间Swap(&a[fast], &a[slow]);//交换}fast++;//扫描}Swap(&a[keyi], &a[slow]);//交换return slow;
}
void QuickSort(int* a,int left,int right)//递归
{if (left >= right)//区间不存在结束递归{return;}else{int keyi = PartSort2(a, left, right);QuickSort(a, left, keyi - 1);//递归左序列QuickSort(a, keyi + 1,right);//递归右序列}
}
算法分析
时间复杂度
二分区间递归 logN 层每层总和消耗可以看作遍历数组N,大O渐进表示法 O(N*logN)
快速排序的时间复杂度是 O(N*logN)
空间复杂度
递归深度 logN,开辟 O(logN) 栈空间。
稳定性
交换key和相遇位置时,相遇位置大小和左区间大小不确定,不稳定
4.2.3 优化方法
快排的基本代码实现,我们已经完成了,不过现在的快排在一些特殊场景下效率会降低,所以我们就给出了几个优化的方法
方法一:三数取中
当key趋近中间值时,每次基本都是二分区间,当区间二分为只剩一个数时就排好序了,我们把每层消耗都看作遍历一次数组(实际是往下一次减1),时间复杂度就是O(N*logN)

如果key的大小趋近最大或最小,会是什么情况呢

key趋近最大或最小,每层递归都只能确定一个数,需要递归N层每层消耗递减,也就是等差数列,时间复杂度O(N^2)
所以我们选key是要尽量避免key过大或过小的情况,然后就有大佬提出了三数取中的方法,其法就是在数组最左端和最右端和中间位置取三个数,然后选出三数的中间大小的那个数作为key即可,这样至少能保证选出的数不会是最大或最小的情况
这样也是在保证这三个数趋近于数组元素的大中小的情况下,如果这三个数都比较小或大,那效率也会很低,这样容易被针对,所以最优的做法是随机选出三个数在进行三数取中,这样适应性更强
接下来是代码实现
int GetMidi(int* a, int left, int right)
{int midi = (left + right) / 2;// left midi rightif (a[left] < a[midi]){if (a[midi] < a[right]){return midi;}else if (a[left] < a[right]) // a[midi] > a[right]{return right;}else{return left;}}else // a[left] > a[midi]{if (a[midi] > a[right]){return midi;}else if (a[left] < a[right]) // a[midi] < a[right]{return left;}else{return right;}}
}
方案二:小区间优化
我们会发现我们想让五个数有序还需要递归七次,还需要递归三层

我们知道最后一层递归大约占递归总数的50%,最后三层大约占了80%的递归,递归需要建立栈帧还是有消耗的
所以当递归区间只剩10个数左右我们就不需要再递归排序了,我们使用其他排序,希尔针对数据量小的时候预排序发挥不出作用,堆排序建堆就已经O(N)了,所以我们选择O(N^2)中最优的插入排序
这就是小区间优化,接下来是代码实现
void QuickSort(int* a,int left,int right)//递归
{if (left >= right){return;}//小区间优化if (right - left + 1 <= 10){InserSort(a + left, right - left + 1);}else{int keyi = PartSort2(a, left, right);QuickSort(a, left, keyi - 1);//递归左序列QuickSort(a, keyi + 1,right);//递归右序列}
}
方案三:三路划分
三路划分是什么意思?我们会发现当数据中有大量重复数据时,我们不论是三数取中还是随机数选key都有极大可能选到重复数据,这样就导致分割区间就会很偏,效率低下;其实要是很多重复数据,我们只要将重复数据放在一个区间,那就只需要完成其左右区间即可,效率就会大幅提升

当面对有大量跟key相同的值时,三路划分的核心思想有点类似hoare的左右指针和lomuto的前后指针的结合。核心思想是把数组中的数据分为三段【比key小的值】【跟key相等的值】【比key大的值】,所以叫做三路划分算法
结合一下图,理解一下实现思想:
- key默认取left位置的值
- left指向区间最左边,right指向区间最后边,cur指向left+1位置
- cur遇到比key小的值后跟left位置交换,换到左边,left++,cur++
- cur遇到比key大的值后跟right位置交换,换到右边,right–
- cur遇到跟key相等的值后,cur++
- 直到cur>right结束
void PartSort3(int* a, int begin, int end)//三路划分
{if (begin >= end){return;}//小区间优化if (begin - end + 1 <= 10){InserSort(a + begin, end - begin + 1);}else{int mid = GetMid(a, begin, end);//随机数三数取中Swap(&a[mid], &a[begin]);int left = begin, right = end;int cur = left + 1;int key = a[left];while (cur <= right){if (a[cur] < key){Swap(&a[left], &a[cur]);cur++;left++;}else if (a[cur] > key){Swap(&a[cur], &a[right]);right--;}else{cur++;}}PartSort3(a, begin, left - 1); // 递归左区间PartSort3(a, right + 1, end); // 递归右区间}
}
代码看看就好了,不用太过纠结,主要是体会其思想
4.3.4 快排(非递归)
我们说了上面两种方法都是通过递归实现的,那如果采用非递归的方式应该如何实现呢?
递归其实最重要的就是参数,其实只要我们知道的递归的参数并保存起来,那我们就只要对那段区间进行快排分割即可,那如何保存呢?这就可以借助栈和队列来做
- 栈:先把左右区间入栈然后快排分割区间后。将两个区间入栈(先后不影响)再去取栈顶的两个元素,就得到了一个待排序区间,继续快排分割,又得到两个区间,继续入栈。以此类推,知道栈为空结束就完成排序

- 队列:队列的思路和栈也是一样的,都是为了保存递归的参数。不同的是队列是一层一层的排序,就是栈的是先往深的排序,再回退到右边排序
接下来是代码实现
void QuickSortNonR(int* a, int left, int right)//非递归
{ST st;STInit(&st);STPush(&st, right); // 入栈STPush(&st, left); // 入栈while (!STEmpty(&st)) // 栈不为空{int begin = STTop(&st); // 右端点STPop(&st); // 出栈int end = STTop(&st); // 左端点STPop(&st); // 出栈int keyi = PartSort2(a, begin, end); // 分割if (keyi + 1 < end) // 判断区间存在{STPush(&st, end); // 区间入栈STPush(&st, keyi+1);}if (begin < keyi - 1) // 判断区间存在{STPush(&st, keyi - 1); // 区间入栈STPush(&st, begin);}}STDestroy(&st); // 销毁栈
}
5. 归并排序
5.1 归并(递归)
我们先来看看动图展示,认识一下归并排序

看完动图,我们发现归并排序还是挺简单的,接下来我说一下基本思想吧
基本思想
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序
简单来讲就是将数组看作两个有序区间,然后将两个有序区间合并成一个新的有序区间
我们可以新开辟一块原数组的大小空间,然后定义两个指针分别指向两个区间的开头保证两个都是该区间最小的数比较指向的两个数,把最小的尾插到新数组,然后小的数指针向前移动,继续比较,直到两个指针有一个越界。但是比较完后,另一个区间至少还有一个数,此时越界区间已经没有比另外一个区间最小的数还小的数又因为区间是有序的,所以将未越界区间剩余的数尾插到数组即可完成排序
至于刚开始的数组是乱序的,我们就可以选择一个合理的区间先递归左区间和右区间,再归并

接下来是代码实现
void _MergeSort(int* a, int* tmp, int begin, int end)
{if (begin >= end){return;}int mid = (begin + end) / 2;// 如果[begin, mid][mid+1, end]有序就可以进行归并了_MergeSort(a, tmp, begin, mid);_MergeSort(a, tmp, mid+1, end);// 归并int begin1 = begin, end1 = mid;int begin2 = mid+1, end2 = end;int i = begin;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}while(begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}memcpy(a+ begin, tmp+ begin, (end - begin + 1) * sizeof(int));
}
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}_MergeSort(a, tmp, 0, n - 1);free(tmp);tmp = NULL;
}
我们这边也是用到了递归的方法,我们也就来顺便画一下递归展开图,加深一下理解

哎,这时有小伙伴就要问了,分割区间的时候为什么是 [begin, mid] [mid+1, end] 呀,我觉得 [begin, mid-1] [mid, end] 这样分割区间也行啊
好,我们来假设区间是 [2, 3]

这样会更容易陷入死循环,为什么呢,让我们来好好分析一下

算法分析
时间复杂度
二分区间递归log层,每层消耗看作遍历一次数组N,大O渐进表示法 O(N*1ogN)
所以归并排序的时间复杂度是 O(N*1ogN)
空间复杂度
开辟N个数的空间, O(N)
稳定性
将数据相同的左区间数据尾插即可, 稳定
5.2 归并(非递归)
其实归并也可以用循环控制,我们把一个数看作一个区间,然后一一归并。这样就形成了若干个区间为二的有序区间,继续两两归并,又形成若干个区间为四的区间,四四归并……直到区间数大于原数组个数就完成了排序

接下来就是代码实现
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}// gap每组归并数据的数据个数int gap = 1;while (gap < n){for (int i = 0; i < n; i += 2 * gap){// [begin1, end1][begin2, end2]int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;// 第二组都越界不存在,这一组就不需要归并if (begin2 >= n){break;}// 第二的组begin2没越界,end2越界了,需要修正一下,继续归并if (end2 >= n){end2 = n - 1;}int j = i;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));}printf("\n");gap *= 2;}free(tmp);tmp = NULL;
}
算法分析
时间复杂度
二分区间递归log层每层消耗看作遍历一次数组N,大O渐进表示法 O(N*logN)
所以归并排序的时间复杂度是 O(N*logN)
空间复杂度
开辟N个数的空间,O(N)
稳定性
将数据相同的左区间数据尾插即可,稳定
5.3 外排序
其实归并排序在实践中是非常实用的,归并为什么实用,我们得首先了解一下外排序
归并排序既可以做内排序也可以做外排序
外排序是指能够处理极大量数据的排序算法。通常来说,外排序处理的数据不能⼀次装入内存,只能放在读写较慢的外存储器(通常是硬盘)上。外排序通常采⽤的是⼀种“排序-归并”的策略。在排序阶段,先读入能放在内存中的数据量,将其排序输出到⼀个临时文件,依此进行,将待排序数据组织为多个有序的临时文件。然后在归并阶段将这些临时⽂件组合为⼀个大的有序⽂件,也即排序结果
跟外排序对应的就是内排序,我们之前讲的常见的排序,都是内排序,他们排序思想适应的是数据在内存中,⽀持随机访问。归并排序的思想不需要随机访问数据,只要依次按序列读取数据,所以归并排序既是⼀个内排序,也是⼀个外排序
如果数据量很大,那么我们就不能再内存中排序了,毕竟内存大小有限,这时我们就可以借助归并排序的外排序思想在磁盘中读取文件排序,我们可以先读取n个数据的两个文件的数据,然后将两个文件排序后归并到新的文件。这样新的文件继续和读取n个数据的文件归并一次类推,当数据全部读取完完后,就得到一个排好序的文件了
文件归并排序基本思想
- 读取n个值排序后写到file1,再读取n个值排序后写到file2
- file1和file2利用归并排序的思想,依次读取比较,取小的尾插到mfile,mfile归并为一个有序文件将file1和file2删掉,mfile重命名为filel
- 再次读取n个数据排序后写到file2
- 继续走file1和file2归并,重复步骤2,直到文件中无法读出数据。最后归并出的有序数据放到了file1中

其实基本思想还是挺简单的,这个了解思想即可,至于代码实现的话,对于目前来说没有那么重要
6. 非比较排序
6.1 计数排序
我们先来看看动图展示,认识一下计数排序

其实动图的话计数排序还是挺好理解的,接下来我们来说说基本思想
基本思想
- 统计相同元素出现次数 count[a[i]]++
- 根据统计的结果将序列回收到原来的序列中 排序
本质上就是利用在count数组的自然序号排序
写代码之前我们还得注意一点小细节
像 0,1,2,3,4,5,6,7,8,9 这样的数组,我们只用开辟10个数组空间就行了
但是像 100,101,102,103,104,105,106,107,108,109 这样的数组,我们如果开辟110个数组空间会不会就显得非常浪费空间
所以我们采用相对映射的方式:找出最大值和最小值,开辟 [ 最大值 - 最小值 + 1 ] 个数据的空间遍历数组,数据存放到下标为 [ 数据 - 最小值 ] 的位置写数据时数据的大小就是 [ 数组下标 + 最小值 ]

接下来就是代码实现
void CountSort(int* a, int n)
{int min = a[0], max = a[0];for (int i = 1; i < n; i++){if (a[i] < min)min = a[i];if (a[i] > max)max = a[i];}int range = max - min + 1;int* count = (int*)calloc(range, sizeof(int));if (count == NULL){perror("calloc fail");return;}// 统计次数for (int i = 0; i < n; i++){count[a[i] - min]++;}// 排序int j = 0;for (int i = 0; i < range; i++){while (count[i]--){a[j++] = i + min;}}free(count);
}
算法分析
时间复杂度
遍历一遍数组,O(N)。同时再遍历一次开辟数组,同时写入N个元素元素,时间复杂度大O渐进法表示O(N)
所以计数排序的时间复杂度是 O(N)
空间复杂度
开辟N个空间, O(N)
再来两个几乎用不到的排序,讲一下思想即可
6.2 基数排序
我们先来看看动图展示,认识一下基数排序

看完动图来说还是比较简单的,接下来就简单讲一下基本思想吧
基本思想
将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数
6.3 桶排序
我们先来看看动图和图片的展示,认识一下基数排序


其实光看动图还是有点难以理解,但是有了图片的帮助就不一样了,感觉非常清晰,接下来我来简单讲讲基本思想
基本思想
- 设置一个定量的数组当作空桶
- 遍历输入数据,并且把数据一个一个放到对应的桶里去
- 对每个不是空的桶进行排序
- 从不是空的桶里把排好序的数据拼接起来
结语
我们最后来看看各个排序的对比吧

好了,感谢你能看到这里,本篇到这就结束了,希望对你有所帮助
溜了溜了,我们下篇文章再见吧
相关文章:
【数据结构】——十大排序详解分析及对比
【数据结构】——十大排序详解分析及对比 文章目录 【数据结构】——十大排序详解分析及对比前言1. 排序的概念及其运用1.1 排序的概念1.2 排序的应用 2. 插入排序2.1 直接插入排序2.2 希尔排序 3. 选择排序3.1 选择排序3.2 堆排序 4 交换排序4.1 冒泡排序4.2 快速排序4.2.1 霍…...
散点图适用于什么数据 thinkcell散点图设置不同颜色
在数据可视化的众多工具和技巧中,散点图是一种极为有效的方式,能够揭示变量之间的关系,尤其是在探索数据集的相关性、分布趋势、集群现象时。而在众多助力于制作高质量散点图的工具中,think-cell插件以其高效的操作和丰富的功能&a…...
1. windows搭建Kafka教程
目录 1. 部署zookeeper 1.1 下载地址 1.3 修改zoo配置 1.4 启动zookeepe服务 02 部署kafka 2.1 下载组件包 2.2 解压安装包 2.3 修改配置 2.4 启动kafka服务端 1. 部署zookeeper 1.1 下载地址 下载地址: kafka/zookeeper 下载地址 (qq.com) 1.2 解压 (…...

XSS复现
目录 XSS简单介绍 一、反射型 1、漏洞逻辑: 为什么有些标签可以触发,有些标签不能触发 可以触发的标签 不能触发的标签 为什么某些标签能触发而某些不能 二、DOM型 1、Ma Spaghet! 要求: 分析: 结果: 2、J…...

怎么利用XML发送视频彩信
传统的短信推广主要以文字为主,用户接收到的信息往往显得单调乏味。而视频彩信则不同,它结合了视频和音频的优势,通过生动的画面和悦耳的音乐,给用户带来强烈的视听冲击,从而极大地提高了用户的吸引力。 XML成功返回示…...

5G+工业互联网产教融合创新实训室解决方案
一、建设背景 随着第五代移动通信技术(5G)的快速普及和工业互联网的迅猛发展,全球制造业正面临着前所未有的深刻变革。5G技术凭借其超高的传输速率、极低的延迟以及大规模的连接能力,为工业自动化、智能制造等领域带来了革命性的…...

象棋布局笔记
文章目录 布局中炮(当头炮)当头炮的缺点如何应对平车压马平炮对车的理解中炮对屏风马急进中兵 中炮盘头马盘头马两翼突破 盖马三锤 反宫马克制反宫马 顺手炮 士角炮56炮破解56炮 小当头 屏风马7卒分支3卒分支屏风马红车二进六败招(黑未挺7卒前直接进车)马八进九变车三退一变马二…...

百度AI智能云依赖库OpenSSL库和Curl库及jsoncpp库安装
开发百度AI项目时,需要用到https协议,因此需要安装OpenSSl和curl库。 若只安装curl库,只支持http协议,不支持https协议。此外,还需要jsoncpp库,用以组包及解析与百度AI通信的json格式协议。 1.Ubuntu上安装…...

智慧空调离线语音控制方案:NRK3301芯片的深度解析与应用
随着AI技术的大爆发和智能家居的风潮,语音交互已成为智能家居产品的一项必备技能,在家电、音箱、穿戴设备乃至墙壁开关等贴近生活的产品中应用越来越广泛,智能语音识别是当前最热门的方案之一。 九芯智能顺应家居行业智能语音交互市场需求&a…...

基础第3关:LangGPT结构化提示词编写实践
提示词: # Role: 伟大的数学家 ## Profile - author: LangGPT - version: 1.0 - language: 中文 - description: 一个伟大的数学家,能够解决任何的数学难题 ## Goals: 根据关键词进行描述,避免与已有描述重复。 ## Background: 你正在被…...

Nginx系列-负载均衡
文章目录 Nginx系列-负载均衡1. 负载均衡基础1.1 负载均衡定义1.2 Nginx负载均衡原理 2. 负载均衡策略2.1 轮询(Round Robin)2.2 加权轮询(Weighted Round Robin)2.3 IP哈希(IP Hash)2.4 最少连接ÿ…...
中职物联网实训室
一、中职物联网实训室建设背景 在当今科技日新月异的浪潮中,物联网技术以其迅猛的发展势头,成为了撬动数字化转型的关键杠杆,深刻地重塑着经济社会的面貌。面对这一变革,社会对精通物联网技术的应用型人才需求激增。鉴于此&#x…...

Image-coloring的部署,在Ubuntu22.04系统下——点动科技
一、ubuntu22.04基本环境配置 1.1 更换清华Ubuntu镜像源 删除原来的文件 rm /etc/apt/sources.list开始编辑新文件 vim /etc/apt/sources.list先按i键,粘贴以下内容 # 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释 deb https:…...

Springboot 整合 Swagger3(springdoc-openapi)
使用springdoc-openapi这个库来生成swagger的api文档 官方Github仓库: https://github.com/springdoc/springdoc-openapi 官网地址:https://springdoc.org 目录题 1. 引入依赖2. 拦截器设置3. 访问接口页面3.1 添加配置项,使得访问路径变短…...

netty4报错:io.netty.util.IllegalReferenceCountException: refCnt: 0, decrement: 1
背景:netty执行链中有一串自定义的handler,目前我想要在中间再加上一个pingPonghandler来进行控制帧的处理,从而避免ng的读写超时(客户要求,与他们建立的通道一直连接,不进行断连,从而需要考虑n…...

2022年汽车软件行业产业细分及发展趋势分析
2022年汽车软件行业产业细分及发展趋势分析 连接 2022年汽车软件行业产业细分及发展趋势分析...

如何通过变更让 PostgreSQL 翻车
在开发应用程序和维护其后台数据库集群的过程中,我们经常会遇到实践与理论、开发环境与生产环境之间的差异。其中一个典型的例子就是变更数据库中的列类型。 对于在 PostgreSQL(及其他符合 SQL 标准的系统)中变更列类型的常规操作࿰…...

MySQL表涉及规范
MySQL表设计规范是为了确保数据库表结构的合理性、可读性和可维护性。以下是一些建议和规范: 1.使用InnoDB存储引擎:InnoDB存储引擎提供了事务支持、行级锁定和外键约束,有助于提高数据的完整性和性能。 2.表名和字段名命名规范:…...

服务器Ubuntu22.04系统 使用dcocker部署安装ollama和搭配open_webui使用
服务器Ubuntu22.04系统 使用dcocker部署安装ollama和搭配open_webui使用 一、ubuntu和docker基本环境配置 1.更新包列表: 打开终端,输入以下命令: sudo apt-get updatesudo apt upgrade更新时间较长,请耐心等待 2. 安装docke…...
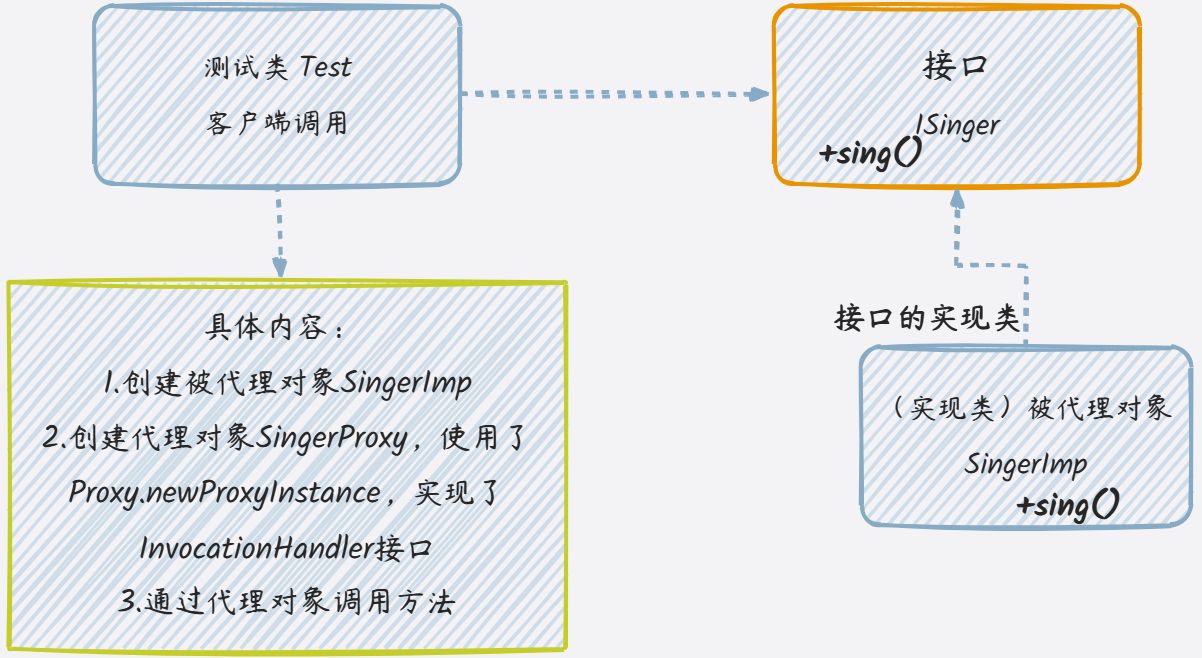
代理模式Proxy
一、代理模式(Proxy) 1.代理模式的定义 代理模式给某一个对象提供一个代理对象,并由代理对象控制对真实对象的访问,起到对代理对象已有功能的增强 通俗的来讲代理模式就是我们生活中常见的中介。 2.作用 中介隔离作用&#x…...

【免费下载】 探索三维世界的利器:Qt+OpenGL三维地形显示项目
探索三维世界的利器:QtOpenGL三维地形显示项目 项目介绍 在数字化的时代,三维地形显示技术已经成为地理信息系统(GIS)、游戏开发、虚拟现实等领域不可或缺的一部分。QtOpenGL三维地形显示项目 是一个开源的、跨平台的三维地形显示…...

探索未来Web交互:Unity与Vue的梦幻联动
探索未来Web交互:Unity与Vue的梦幻联动 【下载地址】Unity打包成WebGL与Vue交互Demo 本示例仓库演示了如何将Unity开发的游戏或应用打包成WebGL格式,并在基于Vue.js的前端应用中进行集成与交互。通过这个项目,开发者可以学习到Unity与现代Web…...

3大核心功能解析:LilToon如何让Unity卡通渲染变得简单又专业
3大核心功能解析:LilToon如何让Unity卡通渲染变得简单又专业 【免费下载链接】lilToon Feature-rich shaders for avatars 项目地址: https://gitcode.com/gh_mirrors/li/lilToon 如果你正在Unity中寻找一个既能满足专业需求又容易上手的卡通渲染解决方案&am…...

详解:XSS 攻击和 CSRF 攻击
一、先看看核心区别 XSS:偷你的身份-》在你的浏览器里面跑恶意JS ,主动拿你的Cookie,冒充你。CSRF:借你的身份-》不偷你的Cookie,而是利用浏览器自带Cookie 的属性,骗网站替你做事。 二、XSS 讲解 1、核心本…...

从‘秦皇岛今天晴空万里’到HMM:一文搞懂NLP分词中的序列标注到底在标什么
从天气报告到智能分词:解码序列标注在NLP中的魔法 秦皇岛的晴空万里不仅是气象术语,更是理解自然语言处理(NLP)中序列标注技术的绝佳入口。当我们看到"秦皇岛今天晴空万里"这行文字时,人脑能瞬间将其分解为有意义的词汇单元&#x…...

使用 TaoToken CLI 工具一键配置多开发环境接入参数
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 TaoToken CLI 工具一键配置多开发环境接入参数 在团队协作或个人多项目开发中,为不同的 AI 应用工具配置 API 密钥…...

3分钟上手Awoo Installer:Switch游戏安装终极指南
3分钟上手Awoo Installer:Switch游戏安装终极指南 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Switch游戏安装烦恼吗…...

CVPR 2023风向解读:多模态与扩散模型如何重塑计算机视觉
1. 从顶会风向标,看计算机视觉的“现在进行时”又到了年中盘点的时候,对于计算机视觉(CV)圈子的从业者、学生和研究者来说,每年CVPR的论文录用情况,就是一张最权威的“技术晴雨表”。它不只是一份论文列表&…...

基于Arduino与VS1053的宠物智能服装DIY:嵌入式系统集成实践
1. 项目概述与核心思路给宠物做一件会发光、会发声的智能服装,听起来像是科幻电影里的情节,但用今天触手可及的硬件和开源工具,这完全是一个可以亲手实现的周末项目。这个项目的核心,是将一个微小的“智能大脑”和一套声光系统&am…...

OpenSTA静态时序分析工具:从入门到精通的完整指南
OpenSTA静态时序分析工具:从入门到精通的完整指南 【免费下载链接】OpenSTA OpenSTA engine 项目地址: https://gitcode.com/gh_mirrors/op/OpenSTA OpenSTA静态时序分析工具是数字集成电路设计中不可或缺的开源时序验证解决方案。作为一款功能强大的门级静态…...