掌握PyTorch的加权随机采样:WeightedRandomSampler全解析
标题:掌握PyTorch的加权随机采样:WeightedRandomSampler全解析
在机器学习领域,数据不平衡是常见问题,特别是在分类任务中。PyTorch提供了一个强大的工具torch.utils.data.WeightedRandomSampler,专门用于处理这种情况。本文将详细介绍如何在PyTorch中使用WeightedRandomSampler进行加权随机采样,以提高模型对少数类的识别能力。
一、加权随机采样的重要性
数据不平衡可能导致模型偏向于多数类,忽略少数类。加权随机采样通过赋予少数类更高的采样权重,增加这些类别在训练过程中的出现频率,从而帮助模型更好地学习。
二、WeightedRandomSampler的工作原理
WeightedRandomSampler根据提供的权重对数据集中的样本进行采样。权重列表中的每个元素对应数据集中的一个样本,权重越高的样本在训练过程中被选中的概率越大。
三、使用WeightedRandomSampler
以下是使用WeightedRandomSampler的基本步骤:
- 计算权重:根据样本的类别分布计算每个样本的权重。
- 创建采样器:使用计算得到的权重和样本总数创建
WeightedRandomSampler实例。 - 应用采样器:将采样器应用于
DataLoader,以实现加权随机采样。
四、代码示例
假设我们有一个数据集,其中某些类别的样本数量较少,我们可以按如下方式使用WeightedRandomSampler:
import torch
from torch.utils.data import DataLoader, Dataset, WeightedRandomSampler# 假设我们有一个数据集
class CustomDataset(Dataset):def __init__(self, data, labels):self.data = dataself.labels = labelsdef __len__(self):return len(self.labels)def __getitem__(self, idx):return self.data[idx], self.labels[idx]# 计算权重
labels = [0, 1, 1, 0, 1] # 示例标签
weights = [1 / (len(list(filter(lambda x: x == i, labels))) + 1e-5) for i in labels]# 创建WeightedRandomSampler
sampler = WeightedRandomSampler(weights, len(labels), replacement=True)# 创建数据集和DataLoader
dataset = CustomDataset(data, labels)
data_loader = DataLoader(dataset, batch_size=3, sampler=sampler)# 在训练循环中使用DataLoader
for data, labels in data_loader:# 训练模型pass
五、注意事项
- 权重不需要总和为1,PyTorch会根据权重自动调整以进行概率采样。
replacement=True表示允许重复采样,这在样本总数较少时非常有用。
六、总结
通过使用WeightedRandomSampler,我们可以有效地解决数据不平衡问题,提高模型对少数类的识别能力。这种方法简单、灵活,且易于集成到现有的训练流程中。
七、进一步学习建议
- 深入理解数据不平衡问题及其对模型性能的影响。
- 学习如何根据具体问题调整权重计算方法,以获得最佳训练效果。
- 实践使用
WeightedRandomSampler处理不同类型的数据集,并观察模型性能的变化。
通过本文的学习,你将能够更加自信地在PyTorch项目中使用加权随机采样技术,为你的模型训练增添一份保障。
相关文章:

掌握PyTorch的加权随机采样:WeightedRandomSampler全解析
标题:掌握PyTorch的加权随机采样:WeightedRandomSampler全解析 在机器学习领域,数据不平衡是常见问题,特别是在分类任务中。PyTorch提供了一个强大的工具torch.utils.data.WeightedRandomSampler,专门用于处理这种情况…...

网络丢包深度解析:影响、原因及优化策略
摘要 网络丢包是数据在传输过程中未能成功到达目的地的现象,它对网络通信的性能有着显著的影响。本文将深入探讨网络丢包的定义、原因、对性能的影响,以及如何通过技术手段进行检测和优化。 1. 网络丢包的定义 网络丢包发生在数据包在源和目的地之间的…...

Hadoop入门基础(一):深入探索Hadoop内部处理流程与核心三剑客
在大数据的世界里,处理海量数据的需求越来越多,而Hadoop作为开源的分布式计算框架,成为了这一领域的核心技术之一。 一、Hadoop简介 Hadoop是Apache Software Foundation开发的一个开源分布式计算框架,旨在使用简单的编程模型来…...

【扒代码】dave.py
COTR 模型是一个用于少样本或零样本对象检测和计数的神经网络。它结合了特征提取、Transformer 编码器和解码器、密度图预测和边界框预测等多个组件。该模型特别适用于在只有少量标注数据或完全没有标注数据的情况下进行对象检测和计数任务。通过使用 Transformer 架构…...

一个人真正的成熟,体现在这六个字上
你好,我是腾阳。 在这个快节奏、高压力的社会中,我们每个人都在追求成长与进步,渴望成为一个更优秀的自己。 然而,成长的道路从不是一帆风顺,我们时常会面临自我怀疑、挫折感、外界的质疑和内心的挣扎。 但正是这些…...

【已成功EI检索】第五届新材料与清洁能源国际学术会议(ICAMCE 2024)
重要信息 会议官网:2024.icceam.com 接受/拒稿通知:投稿后1周内 收录检索:EI, Scopus 会议召开视频 见刊封面 EI检索页面 Scopus 检索页面 相关会议 第六届新材料与清洁能源国际学术会议(ICAMCE 2025) 大会官网&…...

介绍Python `AsyncIterable` 的使用方法和使用场景
介绍Python AsyncIterable 的使用方法和使用场景 一、什么是 AsyncIterable?二、如何使用 AsyncIterable三、使用场景四、总结 在Python异步编程中,AsyncIterable 是一个非常重要的概念,它代表了一个异步可迭代对象。异步可迭代对象允许我们在…...

抖音直播间通过星图风车跳转到微信小程序
注册并认证巨量星图账号:首先,你需要通过主体公司的资质注册巨量星图账号,并通过审核,以取得申请小风车链接跳转微信组件的资格。 使用链接生成工具:借助链接生成工具,如“省点外链”,生成一条…...

idea 修改背景图片教程
🌏个人博客主页:意疏-CSDN博客 希望文章能够给到初学的你一些启发~ 如果觉得文章对你有帮助的话,点赞 关注 收藏支持一下笔者吧~ 阅读指南: 开篇说明修改背景图片 开篇说明 给小白看得懂的修改图片教程&…...
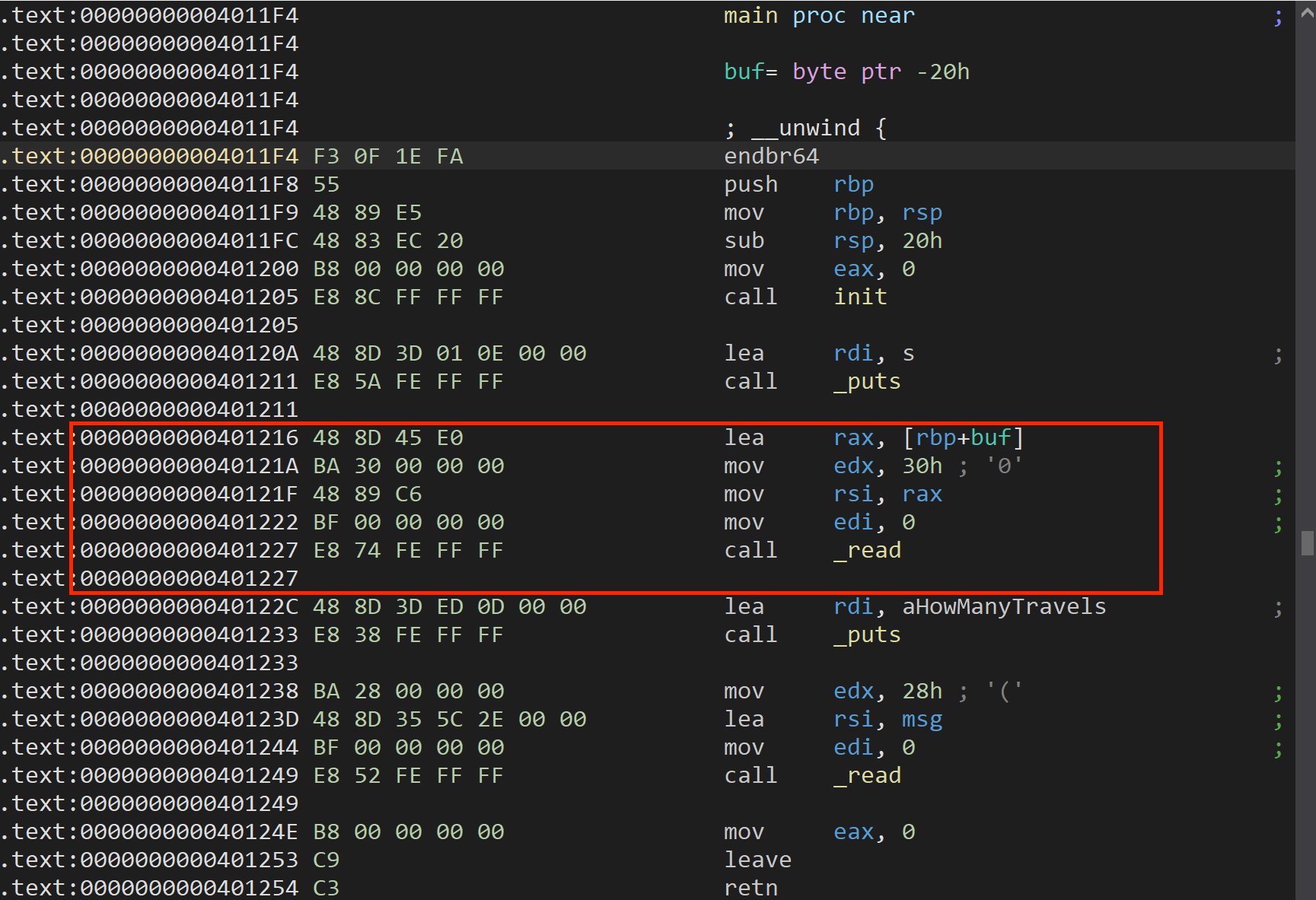
PWN练习---Stack_2
目录 srop源码分析exp putsorsys源码分析exp ret2csu_1源码分析exp traveler源码分析exp srop 题源:[NewStarCTF 2023 公开赛道]srop 考点:SROP 栈迁移 源码 首先从bss段利用 syscall 调用 write 读出数据信息,然后调用 syscall-read向栈中…...

springCloudAlibaba整合log4j2
文章目录 简介log4j2概述log4j2在springCloudAlibaba中的使用排除依赖引入log4j2依赖添加log4j配置文件修改项目配置文件中添加配置 对spring-cloud-alibaba相关组件比较感兴趣的小伙伴,可以看下spring-cloud-alibaba 练习项目 简介 日志主要是记录系统发生的动作&…...

你是如何克服编程学习中的挫折感的
一:心态调整 分解任务:将大的编程任务分解成小的可管理的部分,逐步完成每个部分,逐渐提升自信心。 接受挑战:挑战自己解决一些难题,这样可以提高技能并增强成就感。 寻找资源:利用网络资源、教…...

C++观察者模式:订阅博主~
目录 观察者模式步骤例子:订阅博主UML图1:定义观察者接口2:定义被观察者接口3:创建具体观察者类4:创建具体被观察者类5:使用执行结果 观察者模式 观察者模式允许我们定义一种订阅机制,可在对象…...

1-安装Elasticsearch
支持一览表 | Elastic 未完待续...

EmguCV学习笔记 VB.Net 4.2 二值化
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 教程VB.net版本请访问:EmguCV学习笔记 VB.Net 目录-CSDN博客 教程C#版本请访问:EmguCV学习笔记 C# 目录-CSD…...

Spark大数据分析案例
目录 案例概述环境搭建1. Spark单机环境2. Spark集群环境 数据集数据预处理 Spark作业编写提交Spark作业 数据可视化可能遇到的问题及解决方法结论 案例概述 本案例将介绍如何在单机和集群环境下使用Apache Spark进行大数据分析,最终使用Python实现数据的可视化。我…...

【数据结构】关于Java对象比较,以及优先级队列的大小堆创建你了解多少???
前言: 🌟🌟Hello家人们,这期讲解对象的比较,以及优先级队列堆,希望你能帮到屏幕前的你。 🌈上期博客在这里:http://t.csdnimg.cn/MSex7 🌈感兴趣的小伙伴看一看小编主页&…...

HQChart使用教程101-创建内置键盘精灵
HQChart使用教程101-创建内置键盘精灵 键盘精灵步骤1. 创建键盘精灵实例2. 设置事件回调3. 初始化键盘精灵4. 设置码表数据5. 监听"keydown","mousedown" 交流QQ群HQChart代码地址键盘精灵源码 完整实例 键盘精灵 键盘精灵是一种便捷操作软件的功能工具&a…...

nginx基础配置
1. https配置 首先在nginx.conf中配置https 2. 重定向 rewrite ^/(.*)$ https://www.sxl1.com/$1 permanent;3. 自动索引 autoindex on;4. 缓存 Nginx expire缓存配置: 缓存可以降低网站带宽,加速用户访问location ~ .*\.(gif|jpg|png)$ {expires 365d;roo…...

怿星科技与您相约——2024 Testing Expo
汽车测试及质量监控博览会(中国)Testing Expo China-Automotive 怿星科技展位路线 届时欢迎莅临2057号展台!...

xgboost 训练一个 限制各个因素相关性的模型
XGB/LGB调参秘籍,解锁新高度! 在机器学习特别是风控模型的应用中,XGBoost和LightGBM因其出色的性能而备受青睐。然而,要充分发挥这些模型的潜力,合理的参数调校至关重要。今天,我们就来深入探讨XGBoost/Lig…...

Phi-4-mini-reasoning vLLM服务加固:限流熔断、输入清洗、输出长度约束配置
Phi-4-mini-reasoning vLLM服务加固:限流熔断、输入清洗、输出长度约束配置 1. 模型服务概述 Phi-4-mini-reasoning 是一个基于合成数据构建的轻量级开源模型,专注于高质量、密集推理的数据,并进一步微调以提高更高级的数学推理能力。该模型…...

若依管理系统实战:基于Vuex的用户角色权限与动态菜单路由解析
1. 若依管理系统权限控制核心逻辑解析 若依管理系统作为一款基于SpringBoot和Vue的企业级中后台解决方案,其权限控制体系设计得非常精巧。我在实际项目中使用这套方案时,发现它通过前后端协同工作,实现了细粒度的权限管理。整个流程可以概括为…...

ComfyUI-Custom-Scripts:20+实用功能全面解析与安装指南
ComfyUI-Custom-Scripts:20实用功能全面解析与安装指南 【免费下载链接】ComfyUI-Custom-Scripts Enhancements & experiments for ComfyUI, mostly focusing on UI features 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-Custom-Scripts Comfy…...

Kandinsky-5.0-I2V-Lite-5s实战:基于Dify平台构建无代码视频生成应用
Kandinsky-5.0-I2V-Lite-5s实战:基于Dify平台构建无代码视频生成应用 1. 引言:让图片动起来的零门槛方案 最近遇到不少朋友在问:有没有什么简单的方法,能让静态图片变成动态视频?传统方案要么需要专业视频编辑技能&a…...

S2-Pro模型部署在CentOS7生产环境:系统调优与安全加固
S2-Pro模型部署在CentOS7生产环境:系统调优与安全加固 1. 引言 在AI模型生产环境部署中,系统调优和安全加固往往是被忽视却至关重要的环节。很多团队花费大量精力优化模型性能,却因为基础环境配置不当导致服务不稳定或安全漏洞。本文将手把…...

基于MCGS嵌入版7.7的全自动洗车机组态仿真程序编写与流程图详解
MCGS洗车程序 MCGS嵌入版7.7组态仿真程序 全自动洗车机,脚本程序编写 有完整的流程图"这洗车机PLC程序怎么又卡在喷淋环节了?"凌晨两点的工控车间里,我盯着MCGS嵌入版的仿真界面直挠头。全自动洗车机的脚本调试真是个磨人的小妖精&…...

AI中混淆矩阵及其核心评估指标案例
AI中混淆矩阵及其核心评估指标案例...

Phi-4-mini-reasoning开源模型优势:轻量级+高精度+低GPU资源占用实测
Phi-4-mini-reasoning开源模型优势:轻量级高精度低GPU资源占用实测 1. 模型概述 Phi-4-mini-reasoning是一款专注于推理任务的文本生成模型,特别擅长处理数学题、逻辑题、多步分析和简洁结论输出。与通用聊天模型不同,它采用了"题目输…...

YOLO12快速部署指南:Gradio界面已配好,启动就能用
YOLO12快速部署指南:Gradio界面已配好,启动就能用 1. 为什么选择YOLO12镜像 YOLO12作为2025年最新发布的目标检测模型,带来了革命性的注意力为中心架构。这个预配置好的镜像让您无需任何复杂操作,就能立即体验最先进的目标检测技…...