三十八、【人工智能】【机器学习】【监督贝叶斯网络(Bayesian Networks)学习】- 算法模型

系列文章目录
第一章 【机器学习】初识机器学习
第二章 【机器学习】【监督学习】- 逻辑回归算法 (Logistic Regression)
第三章 【机器学习】【监督学习】- 支持向量机 (SVM)
第四章【机器学习】【监督学习】- K-近邻算法 (K-NN)
第五章【机器学习】【监督学习】- 决策树 (Decision Trees)
第六章【机器学习】【监督学习】- 梯度提升机 (Gradient Boosting Machine, GBM)
第七章 【机器学习】【监督学习】-神经网络 (Neural Networks)
第八章【机器学习】【监督学习】-卷积神经网络 (CNN)
第九章【机器学习】【监督学习】-循环神经网络 (RNN)
第十章【机器学习】【监督学习】-线性回归
第十一章【机器学习】【监督学习】-局部加权线性回归 (Locally Weighted Linear Regression, LWLR)
第十二章【机器学习】【监督学习】- 岭回归 (Ridge Regression)
十三、【机器学习】【监督学习】- Lasso回归 (Least Absolute Shrinkage and Selection Operator)
十四、【机器学习】【监督学习】- 弹性网回归 (Elastic Net Regression)
十五、【机器学习】【监督学习】- 神经网络回归
十六、【机器学习】【监督学习】- 支持向量回归 (SVR)
十七、【机器学习】【非监督学习】- K-均值 (K-Means)
十八、【机器学习】【非监督学习】- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)十九、【机器学习】【非监督学习】- 层次聚类 (Hierarchical Clustering)二十、【机器学习】【非监督学习】- 均值漂移 (Mean Shift)
二十一、【机器学习】【非监督学习】- 谱聚类 (Spectral Clustering)
目录
系列文章目录
一、基本定义
(一)、监督学习
(二)、监督学习的基本流程
(三)、监督学习分类算法(Classification)
二、 贝叶斯网络(Bayesian Networks)
(一)、定义
(二)、基本概念
(三)、训练过程
(四)、训练过程详解
(五)、特点
(六)、适用场景
(七)、扩展
三、总结
一、基本定义
(一)、监督学习
监督学习(Supervised Learning)是机器学习中的一种主要方法,其核心思想是通过已知的输入-输出对(即带有标签的数据集)来训练模型,从而使模型能够泛化到未见的新数据上,做出正确的预测或分类。在监督学习过程中,算法“学习”的依据是这些已标记的例子,目标是找到输入特征与预期输出之间的映射关系。
(二)、监督学习的基本流程
数据收集:获取包含输入特征和对应正确输出标签的训练数据集。
数据预处理:清洗数据,处理缺失值,特征选择与转换,标准化或归一化数据等,以便于模型学习。
模型选择:选择合适的算法,如决策树、支持向量机、神经网络等。
训练:使用训练数据集调整模型参数,最小化预测输出与实际标签之间的差距(损失函数)。
验证与调优:使用验证集评估模型性能,调整超参数以优化模型。
测试:最后使用独立的测试集评估模型的泛化能力,确保模型不仅在训练数据上表现良好,也能在未见过的新数据上做出准确预测。
(三)、监督学习分类算法(Classification)
定义:分类任务的目标是学习一个模型,该模型能够将输入数据分配到预定义的几个类别中的一个。这是一个监督学习问题,需要有一组已经标记好类别的训练数据,模型会根据这些数据学习如何区分不同类别。
例子:垃圾邮件检测(垃圾邮件 vs. 非垃圾邮件)、图像识别(猫 vs. 狗)。
二、 贝叶斯网络(Bayesian Networks)
(一)、定义
Bayesian Networks(贝叶斯网络),也称为信念网络或概率有向无环图模型,是一种用于表示变量间的条件依赖性的图形化概率模型。它通过有向边连接节点来描述随机变量之间的关系,每个节点代表一个变量,边的方向表示因果关系或影响的方向。贝叶斯网络利用概率论和图论的结合,能够有效地处理不确定性问题,尤其是在知识推理和决策制定中。
(二)、基本概念
- 节点(Node):代表随机变量,可以是离散的也可以是连续的。
- 有向边(Directed Edge):表示从一个节点到另一个节点的条件依赖关系,意味着后者(子节点)的概率分布依赖于前者(父节点)的状态。
- 条件概率表(Conditional Probability Table, CPT):对于每一个节点,CPT 描述了给定其所有父节点状态时该节点可能状态的概率分布。
- 联合概率分布(Joint Probability Distribution):贝叶斯网络能够完整地表达一组随机变量的联合概率分布,这是通过节点的局部条件概率分布组合而成的。
(三)、训练过程
- 结构学习(Structure Learning):确定网络的拓扑结构,即哪些变量之间存在直接的依赖关系。这可以通过专家知识或者数据驱动的方法完成。
- 参数学习(Parameter Learning):一旦网络结构确定,就需要估计每个节点的条件概率分布。如果结构已知,参数学习相对简单,可以使用最大似然估计或贝叶斯估计等方法。
- 验证与优化:通过交叉验证或其他评估方法检查模型的准确性,并根据需要调整结构或参数。
(四)、训练过程详解
贝叶斯网络的训练主要涉及两个核心部分:结构学习和参数学习。以下是这两个过程的详细说明:
-
结构学习 (Structure Learning)
结构学习的目标是确定贝叶斯网络的拓扑结构,即节点间的连接方式,它反映了变量间的依赖关系。结构学习可以分为监督学习和非监督学习两种情况:
-
监督学习:在这种情况下,我们通常拥有带有标签的数据集,可以用来学习网络结构。常见的结构学习算法包括分数和搜索算法,如BIC(Bayesian Information Criterion)、AIC(Akaike Information Criterion)评分,以及基于约束的算法,如PC算法(基于条件独立测试)。
-
非监督学习:没有标签数据时,可以采用无监督的方法来推断结构,这通常涉及到更复杂的模型和算法,比如使用EM算法(Expectation-Maximization)来迭代估计结构和参数。
结构学习是一个NP难问题,因此实际应用中往往使用启发式算法或近似算法,如贪心算法、遗传算法、模拟退火等。
-
参数学习 (Parameter Learning)
一旦确定了网络结构,下一步就是估计节点的条件概率分布。参数学习通常分为以下几种情况:
-
完全数据:当数据集中没有缺失值时,参数学习较为直接。可以使用最大似然估计(MLE)或贝叶斯估计来更新条件概率表(CPT)。MLE是最常用的方法,它假设先验概率均匀分布;而贝叶斯估计则引入了先验概率,使得估计更加稳健。
-
不完全数据:当数据集中存在缺失值时,可以使用EM算法来迭代估计缺失值和参数。EM算法交替进行期望步(E-step)和最大化步(M-step),逐步逼近参数的最优估计。
-
正则化:为了防止过拟合,可以加入正则化项,如L1或L2正则化,以限制参数空间。
-
验证与优化
在训练完成后,需要对模型进行验证,以确保其泛化能力。这通常通过交叉验证或保留一部分数据作为测试集来完成。根据验证结果,可能需要返回修改网络结构或调整参数,直到达到满意的性能为止。
-
其他考虑因素
- 先验知识:在结构学习中,可以融入领域专家的知识,指导算法优先考虑某些结构,避免不必要的探索。
- 计算效率:结构学习和参数学习都是计算密集型任务,特别是对于大规模数据集和复杂网络。因此,算法的选择和优化对于提高效率至关重要。
- 模型评估:除了传统的准确率指标外,还应考虑模型的可解释性、鲁棒性等其他因素。
贝叶斯网络的训练是一个复杂但灵活的过程,它要求数据科学家既要有坚实的统计学基础,又要有良好的领域知识和算法选择技巧。
(五)、特点
- 明确的因果关系表示:贝叶斯网络直观地展示了变量之间的因果关系。
- 处理不确定性:能够处理不确定性和不完全信息,适用于各种复杂的决策问题。
- 可解释性强:模型结构易于理解和解释,便于专家介入和调整。
- 高效推理:通过局部计算实现全局推理,大大减少了计算复杂度。
(六)、适用场景
- 诊断系统:例如医学诊断、设备故障诊断等,通过观察症状预测潜在原因。
- 推荐系统:基于用户的偏好历史和行为预测未来兴趣。
- 风险评估:在金融领域评估贷款违约风险、保险索赔可能性等。
- 生物信息学:基因调控网络分析、疾病预测等。
- 自然语言处理:如文本分类、情感分析等任务中的语义理解。
(七)、扩展
- 动态贝叶斯网络(DBN):用于处理随时间变化的序列数据,如时间序列预测。
- 隐马尔可夫模型(HMM):可以看作是DBN的一个特例,常用于语音识别和自然语言处理。
- 混合贝叶斯网络:允许同时包含离散和连续变量,通过高斯混合模型等方法处理连续变量。
- 非参数贝叶斯模型:如Dirichlet过程,允许模型自动适应数据的复杂性,无需预设固定数量的参数。
三、总结
贝叶斯网络是一个强大的工具,在许多领域都有广泛的应用,它的灵活性和可解释性使其成为处理复杂不确定性问题的理想选择。
四、相关书籍介绍
《Python机器学习算法》这本书是由赵志勇编写,由电子工业出版社出版的一本关于机器学习的入门书籍,出版时间为2017年7月。该书的特点是结合理论与实践,旨在帮助读者不仅理解机器学习算法的理论基础,而且能够动手实践,最终熟练掌握算法的应用。以下是本书的主要内容和适用读者群体的总结:
内容概览
本书分为六个主要部分:
- 基本概念:介绍监督学习、无监督学习和深度学习的基本概念。
- 分类算法:包括Logistic回归、Softmax Regression、Factorization Machine、支持向量机(SVM)、随机森林和BP神经网络等。
- 回归算法:涵盖线性回归、岭回归和CART树回归。
- 聚类算法:如K-Means、Mean Shift、DBSCAN和Label Propagation算法。
- 推荐算法:基于协同过滤、矩阵分解和基于图的推荐算法。
- 深度学习:介绍AutoEncoder和卷积神经网络(CNN)。
此外,本书还特别安排了一章来讲解算法在具体项目中的实践案例,以及附录部分介绍了Python语言、numpy库和TensorFlow框架的使用方法。
适用读者
这本书适合以下几类读者:
- 机器学习初学者:书中从算法原理出发,逐步深入,适合没有机器学习背景的读者入门。
- 具有一定项目经验的读者:书中不仅有理论介绍,还有大量实践代码,可以帮助已有一定经验的读者深化理解,提升技能。
- 对推荐系统、广告算法和深度学习感兴趣的读者:书中详细介绍了这些领域的实用算法,有助于读者在这些方向上进行深入研究。
总之,《Python机器学习算法》是一本全面介绍机器学习算法的书籍,它兼顾理论与实践,无论是对初学者还是有一定经验的读者,都能从中找到适合自己的内容。
书籍下载链接:
链接:https://pan.baidu.com/s/1ngX9yoC1HMZ2ORmHvSEtlA?pwd=0qbm
提取码:0qbm
相关文章:
三十八、【人工智能】【机器学习】【监督贝叶斯网络(Bayesian Networks)学习】- 算法模型
系列文章目录 第一章 【机器学习】初识机器学习 第二章 【机器学习】【监督学习】- 逻辑回归算法 (Logistic Regression) 第三章 【机器学习】【监督学习】- 支持向量机 (SVM) 第四章【机器学习】【监督学习】- K-近邻算法 (K-NN) 第五章【机器学习】【监督学习】- 决策树…...

[书生大模型实战营][L0][Task1] Linux 远程连接 InternStudio
[书生大模型实战营][Task1] Linux 远程连接 InterStudio 1. 申请 InterStudio 账号 https://studio.intern-ai.org.cn/console/dashboard 2. ssh 生成公匙与密匙 使用 ssh-gen 生成公匙与密匙 # 1. ssh-gen ssh-gen# 2. 查看生成的文件 ls ~/.ssh# 3. 打开生成的公匙&#…...
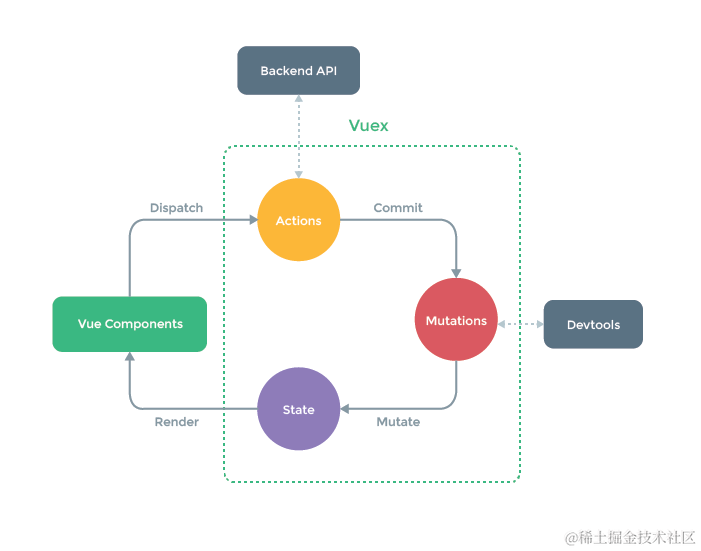
【vue教程】六. Vue 的状态管理
目录 往期列表本章涵盖知识点回顾Vuex 的基本概念什么是 Vuex?为什么需要 Vuex? Vuex 的核心概念stategettersmutationsactionsmodules Vuex 的安装和基本使用安装 Vuex创建 store在 Vue 应用中使用 store在组件中访问和修改状态 Vuex 的模块化模块化的好…...

无人机电子调速器详解!!!
电子调速器是无人机动力系统中的关键组件,主要负责将电池提供的直流电转换为交流电,并精确控制电机的转速,从而实现对无人机飞行状态的精确控制。以下是对无人机电子调速器的详细解析: 一、基本功能与原理 功能: 直…...
)
Clichouse数据导出导入(数据迁移)
背景:因为clickhouse数据持续增加,导致服务器磁盘不够使用,云服务器的系统盘不能扩容,所以只能进行迁移 连接clickhouse查看要迁移那些数据库 rootjcdata:~/buckup/clickhouse# clickhouse-client -udefault --password 123456…...
 源码剖析及使用)
Java基础——IService.class 中查询数据方法list() 源码剖析及使用
下面详细介绍Mybatis-plus 的默认服务IService.class 中的查询数据的方法及使用。 方法定义及其详细介绍 default List<T> list(Wrapper<T> queryWrapper) default List<T> list(Wrapper<T> queryWrapper) {return this.getBaseMapper().selectList(q…...

MySQL库表的基本操作
目录 1.库的操作1.1 创建数据库1.2字符集和校验规则①查看系统默认字符集以及校验规则②查看数据库支持的字符集③查看数据库支持的字符集校验规则④校验规则对数据库的影响 1.3操纵数据库①查看数据库②显示创建的数据库的语句③修改数据库④数据库删除⑤备份和恢复⑥还原注意…...

基于ResNeSt50神经网络模型的蘑菇分类设计与实现,使用注意力机制,分别对应8种蘑菇进行训练预测
该项目旨在利用卷积神经网络(Convolutional Neural Networks, CNN)实现蘑菇的自动识别。通过对蘑菇图片进行分类,可以有效地将不同类型的蘑菇进行辨别,对于蘑菇的研究、食用安全及自然保护等方面具有重要意义。本文将详细描述项目…...

[论文翻译]使用 BERT 检测安卓恶意软件
Android Malware Detection Using BERT Souani B, Khanfir A, Bartel A, et al. Android malware detection using bert[C]//International Conference on Applied Cryptography and Network Security. Cham: Springer International Publishing, 2022: 575-591. 摘要 在本文…...

LabVIEW滚动轴承故障诊断系统
滚动轴承是多种机械设备中的关键组件,其性能直接影响整个机械系统的稳定性和安全性。由于轴承在运行过程中可能会遇到多种复杂的工作条件和环境因素影响,这就需要一种高效、准确的故障诊断方法来确保机械系统的可靠运行。利用LabVIEW开发的故障诊断系统&…...

【论文分享】通过社交媒体图片和计算机视觉分析城市绿道的使用情况
城市街道为路面跑步提供了环境。本次给大家带来一篇SCI论文的全文翻译!该论文提出了一种非参数方法,使用机器学习模型来预测路面跑步强度。该论文提供了关于路面跑步的实证证据,并突出了规划者、景观设计师和城市管理者在设计适于跑步的城市街…...

MySQL 在 Windows 和 Ubuntu 上的安装与远程连接配置简介
MySQL 是一个广泛使用的开源关系型数据库管理系统,它提供了多用户、多线程的数据库服务。本文将介绍如何在 Windows 和 Ubuntu 操作系统上安装 MySQL,并配置远程连接。 Windows 上的 MySQL 安装 1. 下载 MySQL Installer 访问 MySQL 官方网站下载 Win…...

博达网站群管理平台 v6.0使用相关问题解决
1 介绍 最近受人所托,需要用博达网站群管理平台创建一个网站。该平台的内部版本为9.8.2。作为一个能直接从代码创建网站系统的人,初次使用本平台,刚开始感觉摸不着头脑。因为该平台存在的目的,就是让不懂代码的人能快速创建网站&…...

C++—>STL中vector使用篇
文章目录 🚩前言1、vector容器的概述2、vector构造函数的使用3、vector遍历方式4、vector中Capacity相关接口5、vector插入和删除的使用 🚩前言 前面描述了字符串string的相关知识,接下来描述第二个常用容器——vector,即顺序表。…...

pyinstaller打包vnpy项目
因为我写的软件主要是自己用,很少有打包的习惯,直接源代码部署,导致打包,以下记录一下给一个朋友做的,对vnpy的改写,实现实时读取信号文件,发现文件中信号改变就做出相应的交易动作,…...

kafka 消费组 分区分配策略
一、前提 kafka的版本是 2.6.2 一般我们消费kafka的时候是指定消费组,是不会指定消费组内部消费kafka各个分区的分配策略,但是我们也可以指定消费策略,通过源码发现,我们可以有三种分区策略: RangeAssignor (默认&am…...

AQS原理解析
1. 什么是AQS AQS的全称是AbstractQueuedSynchronizer,即抽象队列同步器,这个类在java.uitl.concurrent.locks包下面。 AQS就是一个抽象类,主要用来构建锁和同步器。 public abstract class AbstractQueuedSynchronizer extends AbstractOw…...

『 Linux 』利用UDP套接字实现简单群聊
文章目录 服务端通过传入命令处理实现远程命令执行使用Windows编辑UDP客户端实现Windows远程控制Linux接收套接字的其他信息UDP套接字简单群聊服务端UDP套接字简单群聊客户端运行测试及分离输入输出 参考代码 服务端通过传入命令处理实现远程命令执行 『 Linux 』利用UDP套接字…...

【数据结构与算法 | 图篇】最小生成树之Kruskal(克鲁斯卡尔)算法
1. 前言 克鲁斯卡尔算法(Kruskals algorithm)是一种用于寻找加权图的最小生成树(Minimum Spanning Tree, MST)的经典算法。这种算法是由约瑟夫克鲁斯卡尔(Joseph Kruskal)提出的,并且适用于所有…...

了解常用的代码检查工具
在软件开发领域,代码检查工具是确保代码质量、提高开发效率、促进团队协作的重要工具。这些工具通过自动化分析代码,帮助开发者发现潜在的错误、漏洞、代码异味等问题,并提供修复建议或重构方案。以下是一些常用的代码检查工具,它…...

基于python开发的送货上门系统
目录同行可拿货,招校园代理 ,本人源头供货商功能模块划分技术实现要点扩展功能建议部署与维护项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 功能模块划分 用户管理模块 用户注册与登录…...

Win11Debloat:让Windows 11系统轻盈如飞的优化工具
Win11Debloat:让Windows 11系统轻盈如飞的优化工具 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custo…...

Win11Debloat系统优化工具:全面提升Windows性能的技术指南
Win11Debloat系统优化工具:全面提升Windows性能的技术指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter an…...

Win11共享打印机连接失败?绕过安全策略的终极指南
1. Win11共享打印机连接失败的真相 最近帮朋友处理Win11共享打印机的问题时,发现这个看似简单的操作居然能卡住这么多人。明明按照传统方法一步步操作,却总是提示各种错误。其实这背后是微软在Win11 22H2版本后引入的新安全策略在作祟 - 他们默认关闭了S…...

大多数人手动给Agent加记忆 Meta HyperAgents却让AI自己发明了完整记忆系统
你是不是也这样造Agent:先搭好任务执行模块,再手动塞一个向量数据库或RAG当记忆,最后发现跨轮迭代时效果还是“每次从零开始”?性能没 compounding,跨任务迁移更是一团乱麻。明明AI已经能自我迭代了,为什么…...

Phi-4-mini-reasoning效果实测:在高考数学压轴题上的分步推导与结论匹配度
Phi-4-mini-reasoning效果实测:在高考数学压轴题上的分步推导与结论匹配度 1. 模型能力概述 Phi-4-mini-reasoning是一款专注于推理任务的文本生成模型,特别擅长处理需要多步逻辑推导的数学题和逻辑题。与通用聊天模型不同,它被设计为直接接…...
)
新手避坑指南:PX4飞控连接TFmini、LIDAR Lite V3等定高雷达的完整接线与参数配置(QGC实操)
PX4飞控与定高雷达实战:从接线到参数配置的避坑指南 刚拿到PX4飞控和一堆传感器的新手们,面对密密麻麻的接口和参数设置,是不是有种无从下手的感觉?特别是当你需要连接定高雷达时,不同品牌(北醒TFmini、LID…...

Linux 中的硬链接和软连接是什么,二者有什么区别?
在 Linux 文件系统中,**硬链接(Hard Link)和软链接(Soft Link,又称符号链接 Symbolic Link)**是两种不同的文件引用方式。它们都允许用户通过不同的路径访问同一个文件内容,但它们的实现机制、限…...

Qwen3.5-2B入门指南:WebUI中Clear Image按钮对多轮图文对话的影响
Qwen3.5-2B入门指南:WebUI中Clear Image按钮对多轮图文对话的影响 1. 认识Qwen3.5-2B轻量化多模态模型 Qwen3.5-2B是Qwen3.5系列中的轻量级版本,仅有20亿参数规模。这个模型特别适合在资源有限的设备上运行,比如个人电脑、边缘计算设备等。…...

B站成分检测器:3分钟快速识别评论区同好身份
B站成分检测器:3分钟快速识别评论区同好身份 【免费下载链接】bilibili-comment-checker B站评论区自动标注成分油猴脚本,主要为原神玩家识别 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-comment-checker 还在为B站评论区难以分辨用户…...