第N7周:调用Gensim库训练Word2Vec模型
- 本文为365天深度学习训练营 中的学习记录博客
- 原作者:K同学啊
任务:
●1. 阅读NLP基础知识里Word2vec详解一文,了解并学习Word2vec相关知识
●2. 创建一个.txt文件存放自定义词汇,防止其被切分
数据集:选择《人民的名义》的小说原文作为语料,在代码里命名为“in_the_name_of_people.txt”。
一、准备工作
-
安装Gensim库:
使用pip进行安装:!pip install gensim -
对原始语料分词
选择《人民的名义》的小说原文作为语料,先采用jieba进行分词。这里是直接添加的自定义词汇,没有选择创建自定义词汇文件。(任务2代码处)
因为在默认情况下,open() 函数在 Windows 系统上使用 gbk 编码,而文件可能是使用其他编码(例如 UTF-8)保存的,这导致了 UnicodeDecodeError的问题。
如果不确定“in_the_name_of_people.txt”文件的编码,可以尝试以下方法:可以使用 chardet 库来检测文件的编码。
import chardetwith open('./N7/in_the_name_of_people.txt', 'rb') as f:result = chardet.detect(f.read())print(result)
{'encoding': 'UTF-8-SIG', 'confidence': 1.0, 'language': ''}
检测到UTF-8-SIG编码后,再使用正确的编码打开文件。在下面的 open() 函数中显式指定UTF-8的文件编码打开文件。
当然也可以直接跳过上面的检测文件的代码,直接在open() 函数中显式指定UTF-8的文件编码打开文件。
import jieba
import jieba.analysejieba.suggest_freq('沙瑞金', True) # 加入一些词,使得jieba分词准确率更高
jieba.suggest_freq('田国富', True)
jieba.suggest_freq('高育良', True)
jieba.suggest_freq('侯亮平', True)
jieba.suggest_freq('钟小艾', True)
jieba.suggest_freq('陈岩石', True)
jieba.suggest_freq('欧阳菁', True)
jieba.suggest_freq('易学习', True)
jieba.suggest_freq('王大路', True)
jieba.suggest_freq('蔡成功', True)
jieba.suggest_freq('孙连城', True)
jieba.suggest_freq('季昌明', True)
jieba.suggest_freq('丁义珍', True)
jieba.suggest_freq('郑西坡', True)
jieba.suggest_freq('赵东来', True)
jieba.suggest_freq('高小琴', True)
jieba.suggest_freq('赵瑞龙', True)
jieba.suggest_freq('林华华', True)
jieba.suggest_freq('陆亦可', True)
jieba.suggest_freq('刘新建', True)
jieba.suggest_freq('刘庆祝', True)
jieba.suggest_freq('赵德汉', True)with open('./N7/in_the_name_of_people.txt',encoding='utf-8') as f:result_cut = []lines = f.readlines() for line in lines:result_cut.append(list(jieba.cut(line)))f.close()
代码输出:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\Administrator\AppData\Local\Temp\jieba.cache
Loading model cost 0.776 seconds.
Prefix dict has been built successfully.
# 添加自定义停用词
stopwords_list = [",","。","\n","\u3000"," ",":","!","?","…"]def remove_stopwords(ls): # 去除停用词return [word for word in ls if word not in stopwords_list]result_stop=[remove_stopwords(x) for x in result_cut if remove_stopwords(x)]
拿到了分词后的文件,在一般的NLP处理中,会需要去停用词。由于word2vec的算法依赖于上下文,而上下文有可能就是停词。因此对于word2vec,我们可以不用去停词,仅仅去掉一些标点符号,做一个简单的数据清洗。
现在我们可以直接读分词后的文件到内存。这里使用了word2vec提供的LineSentence类来读文件,然后套用word2vec的模型。在实际应用中,可以调参提高词的embedding的效果。
print(result_stop[100:103])
代码输出:
[['侯亮平', '也', '很', '幽默', '一把', '抓住', '了', '赵德汉', '的', '手', '哎', '赵', '处长', '我', '既', '来', '了', '还', '真', '舍不得', '和', '你', '马上', '就', '分手', '哩', '咱们', '去', '下', '一个点', '吧', '说', '罢', '从', '赵家', '桌上', '杂物', '筐', '里', '准确', '地', '拿出', '一张', '白色', '门卡', '插到', '了', '赵德汉', '的', '上衣', '口袋', '里'], ['赵德汉', '慌', '了', '忙', '把门', '卡往', '外', '掏', '这', '这', '什么', '呀', '这', '是'], ['你', '帝京', '苑', '豪宅', '的', '门', '卡', '啊', '请', '继续', '配合', '我们', '执行公务', '吧']]
二、训练Word2Vec模型
from gensim.models import Word2Vecmodel = Word2Vec(result_stop, # 用于训练的语料数据vector_size=100, # 是指特征向量的维度,默认为100。window=5, # 一个句子中当前单词和被预测单词的最大距离。min_count=1) # 可以对字典做截断,词频少于min_count次数的单词会被丢弃掉, 默认值为5。
三、模型应用
1.计算词汇相似度
可以使用similarity()方法计算两个词汇之间的余弦相似度。
# 计算两个词的相似度
print(model.wv.similarity('沙瑞金', '季昌明'))
print(model.wv.similarity('沙瑞金', '田国富'))
代码输出:
0.9991677
0.9992704
# 选出最相似的5个词
for e in model.wv.most_similar(positive=['沙瑞金'], topn=5):print(e[0], e[1])
代码输出:
这位 0.9998722076416016
有些 0.9997892379760742
这是 0.9997782707214355
情况 0.999778151512146
一位 0.9997725486755371
- 找出不匹配的词汇
使用doesnt_match()方法,我们可以找到一组词汇中与其他词汇不匹配的词汇。
odd_word = model.wv.doesnt_match(["苹果", "香蕉", "橙子", "书"])
print(f"在这组词汇中不匹配的词汇:{odd_word}")
代码输出:
在这组词汇中不匹配的词汇:书
- 计算词汇的词频
我们可以使用get_vecattr()方法获取词汇的词频。
word_frequency = model.wv.get_vecattr("沙瑞金", "count")
print(f"沙瑞金:{word_frequency}")
代码输出:
沙瑞金:353
相关文章:

第N7周:调用Gensim库训练Word2Vec模型
本文为365天深度学习训练营 中的学习记录博客原作者:K同学啊 任务: ●1. 阅读NLP基础知识里Word2vec详解一文,了解并学习Word2vec相关知识 ●2. 创建一个.txt文件存放自定义词汇,防止其被切分 数据集:选择《人民的名义…...

基于Crontab调度,实现Linux下的定时任务执行。
文章目录 引言I 预备知识Crontab的基本组成Crontab的配置文件格式Crontab的配置文件Crontab不可引用环境变量杀死进程命令II Crontab实践案例Crontab工具的使用重启tomcat服务每分钟都打印当前时间到一个文件中30s执行一次III 常见问题并发冗余执行任务&& 和|| 和 ;的区…...

Centos系统中创建定时器完成定时任务
Centos系统中创建定时器完成定时任务 时间不一定能证明很多东西,但是一定能看透很多东西,坚信自己的选择,不动摇,使劲跑,明天会更好。 在 CentOS 上,可以使用 systemd 定时器来创建一个每十秒执行一次的任务…...
WLAN基础知识(1)
WLAN: 无线局域网,无线技术:Wi-Fi、红外、蓝牙等 WLAN设备: 胖AP: 适用于家庭等小型网络,可独立配置,如:家用Wi-Fi路由器 瘦AP: 适用于大中型企业,需要配合AC…...

网络安全实训第三天(文件上传、SQL注入漏洞)
1 文件上传漏洞 准备一句话文件wjr.php.png,进入到更换头像的界面,使用BP拦截选择文件的请求 拦截到请求后将wjr.php.png修改为wjr.php,进行转发 由上图可以查看到上传目录为网站目录下的upload/avator,查看是否上传成功 使用时间戳在线工具…...

Nginx 学习之 配置支持 IPV6 地址
目录 搭建并测试1. 下载 NG 安装包2. 安装编译工具及库文件3. 上传并解压安装包4. 编译5. 安装6. 修改配置7. 启动 NG8. 查看 IP 地址9. 测试 IP 地址9.1. 测试 IPV4 地址9.2. 测试 IPV6 地址 IPV6 测试失败原因1. curl: [globbing] error: bad range specification after pos …...

springboot+伊犁地区游客小助手-小程序—计算机毕业设计源码无偿分享需要私信20888
摘 要 提起伊犁,很多人常说,不去新疆,你就不知道中国有多美,不去伊犁,你就不知道新疆有多美。在这里你可以看到中国最美的景色。如果可可托海海是一个野性和粗犷的战士,那么那拉提一定是一个温柔和玉般的绅…...
提升工作效率的五大神器
在这个信息爆炸、节奏加速的时代,高效工作已经成为了职场人士追求的目标。如何在短时间内完成更多的工作任务,同时保持高质量的输出?答案在于合理利用工具。以下是五个能够显著提升工作效率的软件推荐,它们各自在任务管理、团队协…...

想投资现货黄金?在TMGM开户需要多少钱?
最近,越来越多的人开始关注黄金投资,希望通过黄金来对冲风险、保值增值。而选择一家可靠的交易平台是进行黄金投资的第一步。TMGM作为全球知名的外汇交易商,也为投资者提供了黄金交易服务。那么,在TMGM开户投资黄金,需…...

“零拷贝”
1、python利用0拷贝提高效率 在Python中,“零拷贝”(Zero-Copy)通常是指一种数据处理技术,它允许数据从一个地方传输到另一个地方而不需要创建额外的数据副本。这可以显著减少内存带宽的使用并提高性能,尤其是在处理大…...

[ABC367C] Enumerate Sequences 题解
[ABC367C] Enumerate Sequences 搜索。 考虑使用 DFS 深搜,对于第 i i i 个数,从 1 1 1 到 r i r_i ri 枚举,将 a i a_i ai 设为当前枚举的数,并进行下一层递归。 对所有的数填完后,判断当前和是否为 k k …...

C语言 | Leetcode C语言题解之第336题回文对
题目: 题解: #define SIZE 9470 #define N 168000 #define P 13331typedef unsigned long long ULL; ULL p[301];//p[i]存储P^ivoid init()//初始化p进制次幂数组 {int i;p[0]1;for(i1;i<300;i){p[i]p[i-1]*P;} }int** palindromePairs(char**words,…...

【SQL】仅出现一次的最大数据
目录 题目 分析 代码 题目 MyNumbers 表: ------------------- | Column Name | Type | ------------------- | num | int | ------------------- 该表可能包含重复项(换句话说,在SQL中,该表没有主键)。…...

MySQL 数据类型详解及SQL语言分类-DDL篇
在数据库开发中,选择合适的数据类型和理解SQL语言的分类是非常重要的。今天详细介绍MySQL中的数据类型,包括数值类型、字符串类型和日期类型,并解释SQL语言的四大分类:DDL、DML、DQL和DCL。 1.MySQL 数据类型 SQL语言是不区分大…...

Leet Code 128-最长连续序列【Java】【哈希法】
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。 请你设计并实现时间复杂度为 O(n) 的算法解决此问题。 示例 1: 输入:nums [100,4,200,1,3,2] 输出:4 …...
)
网络协议(概念版)
通讯:首先要得知对方的IP地址。 最终是根据MAC地址(网卡地址),输送数据到网卡,被网卡接收。 如果网卡发现数据的目标MAC地址是自己,就会将数据传递给上一层进行处理;如果目标MAC地址不是自己,…...

Pulsar官方文档学习笔记——消息机制
pulsar 基于3.x最新官方文档学习记录 概念与架构 典型的推送订阅模式。生产者发送消息,消费者订阅topic消费信息并回应ACK。订阅创建后,Pulsar会保留所有消息。仅消息被所有订阅 成功消费了才会丢弃(可以配置消息保留机制保留一定量&#…...

PyTorch--残差网络(ResNet)在CIFAR-10数据集进行图像分类
完整代码 import torch import torch.nn as nn import torchvision import torchvision.transforms as transforms# Device configuration device torch.device(cuda if torch.cuda.is_available() else cpu)# Hyper-parameters num_epochs 80 batch_size 100 learning_rate…...
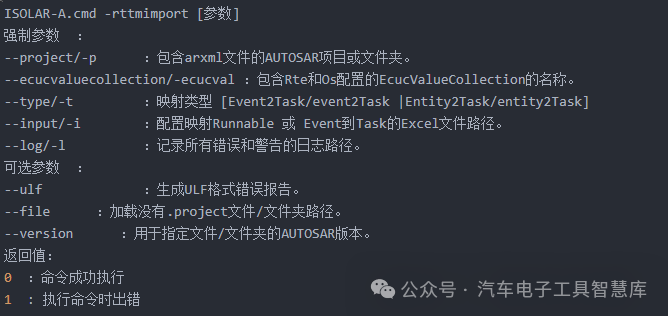
ETAS工具链自动化实战指南<一>
----自动化不仅是一种技术,更是一种思维方式,它将帮助我们在快节奏的工作环境中保持领先! 目录 往期推荐 场景一:SWC 之间 port自动连接 命令示例 参数说明 场景二:SWC与ECU 自动映射 命令示例 参数说明 场景三&…...

疫情期间我面试了13家企业软件测试岗位,一些面试题整理
项目的测试流程 拿到需求文档后,写测试用例 审核测试用例 等待开发包 部署测试环境 冒烟测试(网页架构图) 页面初始化测试(查看数据库中的数据内容和页面展示的内容是否一致,并且是否按照某些顺序排列)…...

重构缠论分析范式:四维动态识别引擎突破技术交易认知瓶颈
重构缠论分析范式:四维动态识别引擎突破技术交易认知瓶颈 【免费下载链接】Indicator 通达信缠论可视化分析插件 项目地址: https://gitcode.com/gh_mirrors/ind/Indicator 副标题:面向量化交易者的通达信可视化插件技术解析 揭示行业痛点&#…...

Qwen3-32B部署全攻略:3步搞定,零基础也能快速上手
Qwen3-32B部署全攻略:3步搞定,零基础也能快速上手 1. 为什么选择Qwen3-32B? Qwen3-32B是当前开源大模型领域的佼佼者,拥有320亿参数的强大能力。与市面上其他模型相比,它有三个突出优势: 推理能力卓越&a…...

大麦网抢票自动化工具:5分钟快速上手完整指南
大麦网抢票自动化工具:5分钟快速上手完整指南 【免费下载链接】damaihelper 支持大麦网,淘票票、缤玩岛等多个平台,演唱会演出抢票脚本 项目地址: https://gitcode.com/gh_mirrors/dam/damaihelper 你是否曾经因为抢不到心仪的演唱会门…...

SPSSPRO vs Python:皮尔逊相关系数分析的保姆级工具对比指南
SPSSPRO vs Python:皮尔逊相关系数分析的保姆级工具对比指南 当我们需要分析两个变量之间的线性关系时,皮尔逊相关系数是最常用的统计指标之一。但在实际应用中,研究人员常常面临工具选择的困扰:是使用SPSSPRO这样的无代码统计分…...

OpenClaw+Phi-3-vision-128k-instruct数据标注:半自动生成图像标签训练集
OpenClawPhi-3-vision-128k-instruct数据标注:半自动生成图像标签训练集 1. 为什么需要半自动数据标注 去年我在做一个宠物品种识别项目时,最头疼的就是数据标注环节。手动给5000多张猫狗图片打标签,不仅耗时耗力,还容易因为疲劳…...

从概念到应用:基于openclaw101.dev功能构思在快马平台构建实战项目
今天想和大家分享一个实战项目经验——如何快速将openclaw101.dev这类技术理念转化为可交互的实际应用。最近我在InsCode(快马)平台上尝试构建了一个任务管理中心SPA,整个过程意外地顺畅,特别适合想快速验证产品原型的开发者。 项目构思 我选择了任务管理…...

3个突破让你自由掌控数字阅读:fanqienovel-downloader全攻略
3个突破让你自由掌控数字阅读:fanqienovel-downloader全攻略 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 如何确保你钟爱的网络小说永不消失? 当你在通勤途中打…...

突破性QQ音乐加密文件解码工具:qmcdump让音乐自由播放的革新方案
突破性QQ音乐加密文件解码工具:qmcdump让音乐自由播放的革新方案 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump …...

Ostrakon-VL像素终端实战:用实时摄像头完成便利店突击巡检
Ostrakon-VL像素终端实战:用实时摄像头完成便利店突击巡检 1. 像素特工终端介绍 想象一下,你是一名便利店巡检员,每天需要检查几十家门店的商品陈列、价签准确性和店面整洁度。传统方法需要手动拍照记录、填写表格,既耗时又容易…...

ESTree节点遍历终极指南:深度优先与广度优先算法完整解析
ESTree节点遍历终极指南:深度优先与广度优先算法完整解析 【免费下载链接】estree The ESTree Spec 项目地址: https://gitcode.com/gh_mirrors/es/estree JavaScript开发者们,你们是否在构建代码分析工具时遇到过AST遍历的难题?&…...