【流媒体】RTMPDump—AMF编码
目录
- 1. AMF类型
- 2. AMF编码
- 2.1 AMF_Number (AMF_EncodeNumber)
- 2.2 AMF_BOOLEAN (AMF_EncodeBoolean)
- 2.3 AMF_STRING 和 AMF_LONG_STRING (AMF_EncodeString)
- 2.3.1 AMF_EncodeInt16
- 2.3.2 AMF_EncodeInt32
- 2.4 AMF_OBJECT (AMF_Encode)
- 2.4.1 AMF_EncodeInt24
- 2.5 AMF_ECMA_ARRAY (AMF_EncodeEcmaArray)
- 2.6 AMF_STRICT_ARRAY (AMF_EncodeArray)
- 3. AMF解码
- 3.1 AMF_Number (AMF_DecodeNumber)
- 3.2 AMF_BOOLEAN (AMF_DecodeBoolean)
- 3.3 AMF_STRING 和 AMF_LONG_STRING (AMF_DecodeString 和 AMF_DecodeLongString)
- 3.3.1 AMF_DecodeInt16
- 3.3.2 AMF_DecodeInt32
- 3.4 AMF_OBJECT (AMF_Decode)
- 3.4.1 AMF_DecodeInt24
- 3.4.2 AMFProp_Decode
- 3.5 AMF_STRICT_ARRAY (AMF_DecodeArray)
RTMP协议相关:
【流媒体】RTMP协议概述
【流媒体】RTMP协议的数据格式
【流媒体】RTMP协议的消息类型
【流媒体】RTMPDump—主流程简单分析
【流媒体】RTMPDump—RTMP_Connect函数(握手、网络连接)
【流媒体】RTMPDump—RTMP_ConnectStream(创建流连接)
【流媒体】RTMPDump—Download(接收流媒体信息)
【流媒体】RTMPDump—AMF编码
【流媒体】基于libRTMP的H264推流器
参考雷博的系列文章(可以从一篇链接到其他文章):
RTMPdump 源代码分析 1: main()函数
在看RTMPDump代码过程中,发现一个比较核心的地方还没有记录,即AMF编码。RTMP协议的数据很多都是以AMF格式进行编码的,也应该做重点记录。参考RTMPDump代码中的amf.c和amf.h两个文件。由于AMF编码会将数据转换成为大端存储,可以参考 数据存储:大端存储与小端存储
1. AMF类型
参考amf.h中的AMFDataType,AMF0一共有18种类型
typedef enum
{AMF_NUMBER = 0, // doubleAMF_BOOLEAN, // boolAMF_STRING, // stringAMF_OBJECT, // 对象类型,包括property和property numAMF_MOVIECLIP, /* reserved, not used */AMF_NULL,AMF_UNDEFINED,AMF_REFERENCE, // not supportedAMF_ECMA_ARRAY, // ECMAAMF_OBJECT_END,AMF_STRICT_ARRAY, // STRICTAMF_DATE, // AMF_LONG_STRING, // 32-bit stringAMF_UNSUPPORTED, AMF_RECORDSET, /* reserved, not used */AMF_XML_DOC,AMF_TYPED_OBJECT,AMF_AVMPLUS, /* switch to AMF3 */AMF_INVALID = 0xff
} AMFDataType;
AMF3一共有13种类型
typedef enum
{AMF3_UNDEFINED = 0, AMF3_NULL, AMF3_FALSE,AMF3_TRUE,AMF3_INTEGER, AMF3_DOUBLE, AMF3_STRING, AMF3_XML_DOC, AMF3_DATE,AMF3_ARRAY, AMF3_OBJECT, AMF3_XML, AMF3_BYTE_ARRAY
} AMF3DataType;
AMF自定义类型AVal,包括val内容和val长度
typedef struct AVal
{char* av_val; // val内容int av_len; // val长度
} AVal;
AMF自定义对象类型Object,
typedef struct AMFObjectProperty
{AVal p_name;AMFDataType p_type;union{double p_number;AVal p_aval;AMFObject p_object;} p_vu;int16_t p_UTCoffset;
} AMFObjectProperty;typedef struct AMFObject
{int o_num;struct AMFObjectProperty* o_props;
} AMFObject;
2. AMF编码
在进行AMF编码时,不同的数据类型编码的方式是不同的,需要分开讨论
2.1 AMF_Number (AMF_EncodeNumber)
AMF_NUMBER类型相当于double类型,在进行编码时,会首先写入一个AMF_NUMBER字段,随后会将输入数据转换成为大端存储
char*
AMF_EncodeNumber(char* output, char* outend, double dVal)
{if (output + 1 + 8 > outend)return NULL;// 写入AMF_NUMBER数据类型*output++ = AMF_NUMBER; /* type: Number */#if __FLOAT_WORD_ORDER == __BYTE_ORDER
#if __BYTE_ORDER == __BIG_ENDIANmemcpy(output, &dVal, 8);
#elif __BYTE_ORDER == __LITTLE_ENDIAN{unsigned char* ci, * co;ci = (unsigned char*)& dVal; // double类型8字节,逐个字节翻转co = (unsigned char*)output;co[0] = ci[7];co[1] = ci[6];co[2] = ci[5];co[3] = ci[4];co[4] = ci[3];co[5] = ci[2];co[6] = ci[1];co[7] = ci[0];}
#endif
#else
#if __BYTE_ORDER == __LITTLE_ENDIAN /* __FLOAT_WORD_ORER == __BIG_ENDIAN */{unsigned char* ci, * co;ci = (unsigned char*)& dVal;co = (unsigned char*)output;co[0] = ci[3];co[1] = ci[2];co[2] = ci[1];co[3] = ci[0];co[4] = ci[7];co[5] = ci[6];co[6] = ci[5];co[7] = ci[4];}
#else /* __BYTE_ORDER == __BIG_ENDIAN && __FLOAT_WORD_ORER == __LITTLE_ENDIAN */{unsigned char* ci, * co;ci = (unsigned char*)& dVal;co = (unsigned char*)output;co[0] = ci[4];co[1] = ci[5];co[2] = ci[6];co[3] = ci[7];co[4] = ci[0];co[5] = ci[1];co[6] = ci[2];co[7] = ci[3];}
#endif
#endifreturn output + 8;
}
2.2 AMF_BOOLEAN (AMF_EncodeBoolean)
AMF_BOOLEAN类型相当于bool类型,在编码时首先写入描述字段AMF_BOOLEAN,随后根据输入bVal来判定是写入0x01或0x00
char*
AMF_EncodeBoolean(char* output, char* outend, int bVal)
{if (output + 2 > outend)return NULL;*output++ = AMF_BOOLEAN;*output++ = bVal ? 0x01 : 0x00;return output;
}
2.3 AMF_STRING 和 AMF_LONG_STRING (AMF_EncodeString)
AMF_STRING和AMF_LONG_STRING两种类型同时使用AMF_EncodeString进行编码,分两种情况:
(1)如果av_len小于65536,先写入AMF_STRING标识字段,随后写入16位的string长度
(2)如果av_len大于65536,先写入AMF_LONG_STRING标识字段,随后写入32位的string长度
最后写入string的内容
char*
AMF_EncodeString(char* output, char* outend, const AVal * bv)
{if ((bv->av_len < 65536 && output + 1 + 2 + bv->av_len > outend) ||output + 1 + 4 + bv->av_len > outend)return NULL;if (bv->av_len < 65536) // 字符串长度小于65536,即16位{*output++ = AMF_STRING;// 写入字符串长度为16位output = AMF_EncodeInt16(output, outend, bv->av_len);}else{*output++ = AMF_LONG_STRING; // 写入AMF_LONG_STRING标识符字段// 写入字符串长度为32位output = AMF_EncodeInt32(output, outend, bv->av_len);}// 写入字符串内容memcpy(output, bv->av_val, bv->av_len);output += bv->av_len;return output;
}
2.3.1 AMF_EncodeInt16
原子函数,实现了AMF编码两个字节的功能,在很多地方都会用到
char*
AMF_EncodeInt16(char* output, char* outend, short nVal)
{if (output + 2 > outend) // 检查越界return NULL;output[1] = nVal & 0xff; // 取出低8位output[0] = nVal >> 8; // 取出高8位return output + 2;
}
2.3.2 AMF_EncodeInt32
原子函数,实现了AMF编码4个字节的功能
char*
AMF_EncodeInt32(char* output, char* outend, int nVal)
{if (output + 4 > outend) // 检查越界return NULL;output[3] = nVal & 0xff; // 取出第4个字节output[2] = nVal >> 8; // 取出第3个字节output[1] = nVal >> 16; // 取出第2个字节output[0] = nVal >> 24; // 取出第1个字节return output + 4;
}
2.4 AMF_OBJECT (AMF_Encode)
AMF_OBJECT描述了一个对象类型,使用AMF_Encode进行编码,这里和前面不同的是,Object是一个具有多个参数的数据类型,需要将其中的"属性" (props)也进行编码,最后还需要写入object_end的字段
char*
AMF_Encode(AMFObject * obj, char* pBuffer, char* pBufEnd)
{int i;if (pBuffer + 4 >= pBufEnd)return NULL;// 写入类型字段*pBuffer++ = AMF_OBJECT;for (i = 0; i < obj->o_num; i++){// 写入属性值char* res = AMFProp_Encode(&obj->o_props[i], pBuffer, pBufEnd);if (res == NULL){RTMP_Log(RTMP_LOGERROR, "AMF_Encode - failed to encode property in index %d",i);break;}else{pBuffer = res;}}if (pBuffer + 3 >= pBufEnd)return NULL; /* no room for the end marker */// 写入object结束字段pBuffer = AMF_EncodeInt24(pBuffer, pBufEnd, AMF_OBJECT_END);return pBuffer;
}
2.4.1 AMF_EncodeInt24
实现AMF编码3个字节功能
char*
AMF_EncodeInt24(char* output, char* outend, int nVal)
{if (output + 3 > outend)return NULL;output[2] = nVal & 0xff; // 取出第1字节output[1] = nVal >> 8; // 取出第2字节output[0] = nVal >> 16; // 取出第3字节return output + 3;
}
2.5 AMF_ECMA_ARRAY (AMF_EncodeEcmaArray)
AMF_ECMA_ARRAY类型进行编码时,与AMF_Encode看上去很相似,不同之处在于AMF_ECMA_ARRAY编码时还需要将num进行编码
char*
AMF_EncodeEcmaArray(AMFObject * obj, char* pBuffer, char* pBufEnd)
{int i;if (pBuffer + 4 >= pBufEnd)return NULL;*pBuffer++ = AMF_ECMA_ARRAY;pBuffer = AMF_EncodeInt32(pBuffer, pBufEnd, obj->o_num);for (i = 0; i < obj->o_num; i++){char* res = AMFProp_Encode(&obj->o_props[i], pBuffer, pBufEnd);if (res == NULL){RTMP_Log(RTMP_LOGERROR, "AMF_Encode - failed to encode property in index %d",i);break;}else{pBuffer = res;}}if (pBuffer + 3 >= pBufEnd)return NULL; /* no room for the end marker */pBuffer = AMF_EncodeInt24(pBuffer, pBufEnd, AMF_OBJECT_END);return pBuffer;
}
2.6 AMF_STRICT_ARRAY (AMF_EncodeArray)
AMF_STRICT_ARRAY类型进行编码时,也与前面两个编码函数很像。先编码字段类型AMF_STRICT_ARRAY,随后编码obj中的num字段,再写入属性值props。不过区别在于,这种类型最后不会写入AMF_OBJECT
char*
AMF_EncodeArray(AMFObject * obj, char* pBuffer, char* pBufEnd)
{int i;if (pBuffer + 4 >= pBufEnd)return NULL;*pBuffer++ = AMF_STRICT_ARRAY;pBuffer = AMF_EncodeInt32(pBuffer, pBufEnd, obj->o_num);for (i = 0; i < obj->o_num; i++){char* res = AMFProp_Encode(&obj->o_props[i], pBuffer, pBufEnd);if (res == NULL){RTMP_Log(RTMP_LOGERROR, "AMF_Encode - failed to encode property in index %d",i);break;}else{pBuffer = res;}}//if (pBuffer + 3 >= pBufEnd)// return NULL; /* no room for the end marker *///pBuffer = AMF_EncodeInt24(pBuffer, pBufEnd, AMF_OBJECT_END);return pBuffer;
}
3. AMF解码
3.1 AMF_Number (AMF_DecodeNumber)
基本就是编码过程反过来,double类型反过来
double
AMF_DecodeNumber(const char* data)
{double dVal;
#if __FLOAT_WORD_ORDER == __BYTE_ORDER
#if __BYTE_ORDER == __BIG_ENDIANmemcpy(&dVal, data, 8);
#elif __BYTE_ORDER == __LITTLE_ENDIANunsigned char* ci, * co;ci = (unsigned char*)data;co = (unsigned char*)& dVal;co[0] = ci[7];co[1] = ci[6];co[2] = ci[5];co[3] = ci[4];co[4] = ci[3];co[5] = ci[2];co[6] = ci[1];co[7] = ci[0];
#endif
#else
#if __BYTE_ORDER == __LITTLE_ENDIAN /* __FLOAT_WORD_ORER == __BIG_ENDIAN */unsigned char* ci, * co;ci = (unsigned char*)data;co = (unsigned char*)& dVal;co[0] = ci[3];co[1] = ci[2];co[2] = ci[1];co[3] = ci[0];co[4] = ci[7];co[5] = ci[6];co[6] = ci[5];co[7] = ci[4];
#else /* __BYTE_ORDER == __BIG_ENDIAN && __FLOAT_WORD_ORER == __LITTLE_ENDIAN */unsigned char* ci, * co;ci = (unsigned char*)data;co = (unsigned char*)& dVal;co[0] = ci[4];co[1] = ci[5];co[2] = ci[6];co[3] = ci[7];co[4] = ci[0];co[5] = ci[1];co[6] = ci[2];co[7] = ci[3];
#endif
#endifreturn dVal;
}
3.2 AMF_BOOLEAN (AMF_DecodeBoolean)
查看data是否为0
int
AMF_DecodeBoolean(const char* data)
{return *data != 0;
}
3.3 AMF_STRING 和 AMF_LONG_STRING (AMF_DecodeString 和 AMF_DecodeLongString)
对于AMF_STRING类型而言,先解析16位的length,随后解析val
void
AMF_DecodeString(const char* data, AVal * bv)
{bv->av_len = AMF_DecodeInt16(data);bv->av_val = (bv->av_len > 0) ? (char*)data + 2 : NULL;
}
对于AMF_LONG_STRING类型而言,先解析32位的length,随后解析val
void
AMF_DecodeLongString(const char* data, AVal * bv)
{bv->av_len = AMF_DecodeInt32(data);bv->av_val = (bv->av_len > 0) ? (char*)data + 4 : NULL;
}
3.3.1 AMF_DecodeInt16
unsigned short
AMF_DecodeInt16(const char* data)
{unsigned char* c = (unsigned char*)data;unsigned short val;val = (c[0] << 8) | c[1]; // c[0] << 8 是高8位return val;
}
3.3.2 AMF_DecodeInt32
unsigned int
AMF_DecodeInt32(const char* data)
{unsigned char* c = (unsigned char*)data;unsigned int val;/*c[0] << 24 表示第1字节c[1] << 16 表示第2字节c[2] << 8 表示第3字节c[3] 表示第4字节*/val = (c[0] << 24) | (c[1] << 16) | (c[2] << 8) | c[3];return val;
}
3.4 AMF_OBJECT (AMF_Decode)
在解析object过程中,先检查字段是否包括AMF_OBJECT_END,随后使用AMFProp_Decoe()来解析属性值 “prop”,最后使用AMF_AddProp()将属性值添加到传入进来的obj中
int
AMF_Decode(AMFObject * obj, const char* pBuffer, int nSize, int bDecodeName)
{int nOriginalSize = nSize;int bError = FALSE; /* if there is an error while decoding - try to at least find the end mark AMF_OBJECT_END */obj->o_num = 0;obj->o_props = NULL;while (nSize > 0){AMFObjectProperty prop;int nRes;// 先解析字段是否包括 AMF_OBJECT_ENDif (nSize >= 3 && AMF_DecodeInt24(pBuffer) == AMF_OBJECT_END){nSize -= 3;bError = FALSE;break;}if (bError){RTMP_Log(RTMP_LOGERROR,"DECODING ERROR, IGNORING BYTES UNTIL NEXT KNOWN PATTERN!");nSize--;pBuffer++;continue;}// 解码propnRes = AMFProp_Decode(&prop, pBuffer, nSize, bDecodeName);if (nRes == -1){bError = TRUE;break;}else{nSize -= nRes;if (nSize < 0){bError = TRUE;break;}pBuffer += nRes;// 将解析出来的prop添加到obj中AMF_AddProp(obj, &prop);}}if (bError)return -1;return nOriginalSize - nSize;
}
3.4.1 AMF_DecodeInt24
unsigned int
AMF_DecodeInt24(const char* data)
{unsigned char* c = (unsigned char*)data;unsigned int val;/*c[0] << 16 表示第1字节c[1] << 8 表示第2字节c[2] 表示第3字节*/val = (c[0] << 16) | (c[1] << 8) | c[2];return val;
}
3.4.2 AMFProp_Decode
int
AMFProp_Decode(AMFObjectProperty * prop, const char* pBuffer, int nSize,int bDecodeName)
{int nOriginalSize = nSize;int nRes;prop->p_name.av_len = 0;prop->p_name.av_val = NULL;if (nSize == 0 || !pBuffer){RTMP_Log(RTMP_LOGDEBUG, "%s: Empty buffer/no buffer pointer!", __FUNCTION__);return -1;}if (bDecodeName && nSize < 4){ /* at least name (length + at least 1 byte) and 1 byte of data */RTMP_Log(RTMP_LOGDEBUG,"%s: Not enough data for decoding with name, less than 4 bytes!",__FUNCTION__);return -1;}if (bDecodeName) // 解析prop名称{unsigned short nNameSize = AMF_DecodeInt16(pBuffer); // 解析prop名称长度if (nNameSize > nSize - 2){RTMP_Log(RTMP_LOGDEBUG,"%s: Name size out of range: namesize (%d) > len (%d) - 2",__FUNCTION__, nNameSize, nSize);return -1;}AMF_DecodeString(pBuffer, &prop->p_name); // 获取prop的具体名称nSize -= 2 + nNameSize;pBuffer += 2 + nNameSize;}if (nSize == 0){return -1;}nSize--;// 根据不同的type来确定如何进行AMF解码prop->p_type = *pBuffer++;switch (prop->p_type){case AMF_NUMBER:if (nSize < 8)return -1;prop->p_vu.p_number = AMF_DecodeNumber(pBuffer);nSize -= 8;break;case AMF_BOOLEAN:if (nSize < 1)return -1;prop->p_vu.p_number = (double)AMF_DecodeBoolean(pBuffer);nSize--;break;case AMF_STRING:{unsigned short nStringSize = AMF_DecodeInt16(pBuffer);if (nSize < (long)nStringSize + 2)return -1;AMF_DecodeString(pBuffer, &prop->p_vu.p_aval);nSize -= (2 + nStringSize);break;}case AMF_OBJECT:{int nRes = AMF_Decode(&prop->p_vu.p_object, pBuffer, nSize, TRUE);if (nRes == -1)return -1;nSize -= nRes;break;}case AMF_MOVIECLIP:{RTMP_Log(RTMP_LOGERROR, "AMF_MOVIECLIP reserved!");return -1;break;}case AMF_NULL:case AMF_UNDEFINED:case AMF_UNSUPPORTED:prop->p_type = AMF_NULL;break;case AMF_REFERENCE:{RTMP_Log(RTMP_LOGERROR, "AMF_REFERENCE not supported!");return -1;break;}case AMF_ECMA_ARRAY:{nSize -= 4;/* next comes the rest, mixed array has a final 0x000009 mark and names, so its an object */nRes = AMF_Decode(&prop->p_vu.p_object, pBuffer + 4, nSize, TRUE);if (nRes == -1)return -1;nSize -= nRes;break;}case AMF_OBJECT_END:{return -1;break;}case AMF_STRICT_ARRAY:{// 解析32位的array长度unsigned int nArrayLen = AMF_DecodeInt32(pBuffer);nSize -= 4;nRes = AMF_DecodeArray(&prop->p_vu.p_object, pBuffer + 4, nSize,nArrayLen, FALSE);if (nRes == -1)return -1;nSize -= nRes;break;}case AMF_DATE:{RTMP_Log(RTMP_LOGDEBUG, "AMF_DATE");if (nSize < 10)return -1;prop->p_vu.p_number = AMF_DecodeNumber(pBuffer);prop->p_UTCoffset = AMF_DecodeInt16(pBuffer + 8);nSize -= 10;break;}case AMF_LONG_STRING:case AMF_XML_DOC:{unsigned int nStringSize = AMF_DecodeInt32(pBuffer);if (nSize < (long)nStringSize + 4)return -1;AMF_DecodeLongString(pBuffer, &prop->p_vu.p_aval);nSize -= (4 + nStringSize);if (prop->p_type == AMF_LONG_STRING)prop->p_type = AMF_STRING;break;}case AMF_RECORDSET:{RTMP_Log(RTMP_LOGERROR, "AMF_RECORDSET reserved!");return -1;break;}case AMF_TYPED_OBJECT:{RTMP_Log(RTMP_LOGERROR, "AMF_TYPED_OBJECT not supported!");return -1;break;}case AMF_AVMPLUS:{int nRes = AMF3_Decode(&prop->p_vu.p_object, pBuffer, nSize, TRUE);if (nRes == -1)return -1;nSize -= nRes;prop->p_type = AMF_OBJECT;break;}default:RTMP_Log(RTMP_LOGDEBUG, "%s - unknown datatype 0x%02x, @%p", __FUNCTION__,prop->p_type, pBuffer - 1);return -1;}return nOriginalSize - nSize;
}
3.5 AMF_STRICT_ARRAY (AMF_DecodeArray)
调用了和AMF_Decode()函数类似的步骤
int
AMF_DecodeArray(AMFObject * obj, const char* pBuffer, int nSize,int nArrayLen, int bDecodeName)
{int nOriginalSize = nSize;int bError = FALSE;obj->o_num = 0;obj->o_props = NULL;while (nArrayLen > 0){AMFObjectProperty prop;int nRes;nArrayLen--;if (nSize <= 0){bError = TRUE;break;}nRes = AMFProp_Decode(&prop, pBuffer, nSize, bDecodeName);if (nRes == -1){bError = TRUE;break;}else{nSize -= nRes;pBuffer += nRes;AMF_AddProp(obj, &prop);}}if (bError)return -1;return nOriginalSize - nSize;
}
相关文章:

【流媒体】RTMPDump—AMF编码
目录 1. AMF类型2. AMF编码2.1 AMF_Number (AMF_EncodeNumber)2.2 AMF_BOOLEAN (AMF_EncodeBoolean)2.3 AMF_STRING 和 AMF_LONG_STRING (AMF_EncodeString)2.3.1 AMF_EncodeInt162.3.2 AMF_EncodeInt32 2.4 AMF_OBJECT (AMF_Encode)2.4.1 AMF_EncodeInt24 2.5 AMF_ECMA_ARRAY …...

Mysql双主双从
双主双从 1.安装Mysql1.1 查看linux版本1.2 下载Mysql安装包1.3 上传并解压1.4 安装Mysql1.5 编辑端口号1.6 Mysql启动命令1.7 更新密码 2.搭建Mysql主从复制2.1 搭建Master主服务器2.1.1 修改mysql配置文件2.1.2 重启Mysql服务2.1.3 创建Slave用户, 并授权2.1.4 查看主服务器当…...

安卓主板_MTK联发科主板定制开发|PCBA定制开发
MTK联发科安卓主板,采用MT6762八核平台方案,支持谷歌Android 11.0系统,MT6762采用ARM八核A53内核芯片、主频高达2.0GHz,GPU采用ARM PowerVR GE8329650MHZ,支持主流19201080分辨率,支持硬解H.264,…...
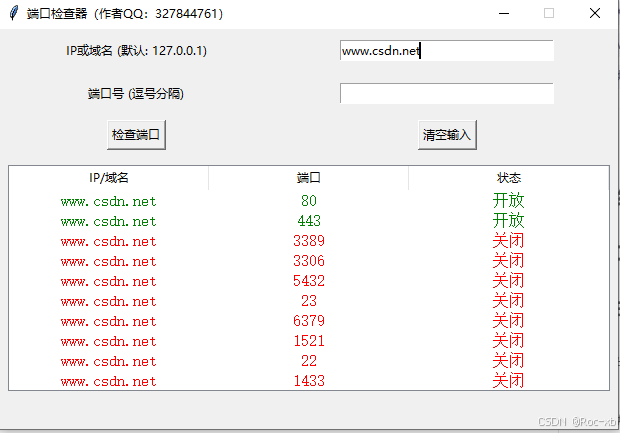
结合GPT与Python实现端口检测工具(含多线程)
端口检测器是一个非常实用的网络工具,它主要用于检测服务器或本地计算机上的特定端口是否处于开放状态。通过这个工具,你可以快速识别和诊断网络连接问题,确保关键服务的端口能够正常接收和处理数据。这对于网络管理员和开发者来说是一个不可…...

数字媒体产业发展现状剖析,洞悉数字产业园的创新之举
在当今数字化时代,数字媒体产业发展迅猛,呈现出一片繁荣景象。然而,在这繁荣的背后,数字媒体产业发展现状也存在着诸多挑战与机遇。 数字媒体产业发展现状的一个显著特点是技术的快速更新换代。从虚拟现实(VR…...

PDF文件转换为HTML文件
推荐使用 pdf2htmlEX(因为确实做的比较全) pdf2htmlEX 是一个开源工具,可以将PDF文件转换为HTML文件。你需要先安装pdf2htmlEX工具,并确保它在你的系统路径中可用。(花时间最多就是找包) 安装 pdf2htmlEX …...

简易版PHP软文发稿开源系统
软文发稿系统源码(软文发布系统)基于旧版本的媒介软文项目基础上整理出一套简易版,以满足不同客户群体。虽然是简易版 但麻雀虽小五脏俱全,基本能满足小众群体需求 具体功能如下: 大模块功能: 1、媒体发布 …...

React.createContext 的 多种使用方法 详细实现方案代码
React.createContext 是 React 的上下文 API 的核心方法之一,提供了一种无需通过组件树逐层传递 props 的方式来共享数据。它特别适合于全局状态的管理,比如用户信息、主题设置等。下面我将详细介绍 React.createContext 的多种使用方法,并提…...

计算机网络之IPv4深度解析
一.IP地址 IP地址的组成方式:网络号 主机号 可以这样理解,根据网络号找路由器,根据主机号找连着路由器的主机 早期分类的IP地址 表示如下: 其中,有些特殊的IP地址: 主机号全为0,表示本网…...

TinyGPT-V:微型视觉语言模型【VLM】
AI技术正在不断融入我们的日常生活。人工智能的一个应用包括多模态化,例如将语言与视觉模型相结合。这些视觉语言模型可以应用于视频字幕、语义搜索等任务。 本周,我将重点介绍一种名为 TinyGPT-V(Arxiv | GitHub)的最新视觉语言…...

pytorch自动微分
一、torch.autograd.backward(tensors, grad_tensorsNone, retain_graphNone, create_graphFalse)功能:自动求取梯度 grad_tensors:多梯度权重 # 自动求取梯度 # import torch # w torch.tensor([1.],requires_gradTrue) # x torch.tensor([2.],requir…...

TCP协议为什么是三次握手和四次挥手
1.一次握手&&二次握手 一次握手就能成功的话,也就代表着不需要进行确认,那么万一有恶意的服务器一直发送SYN,而服务器需要维护大量的连接,维护连接又需要成本,那么就很容易引发SYN洪水,导致服务器…...

利用ChatGPT提升学术论文撰写效率:从文献搜集到综述撰写的全面指南
大家好,感谢关注。我是七哥,一个在高校里不务正业,折腾学术科研AI实操的学术人。关于使用ChatGPT等AI学术科研的相关问题可以和作者七哥(yida985)交流,多多交流,相互成就,共同进步,为大家带来最酷最有效的智能AI学术科研写作攻略。 本文旨在介绍如何利用AI辅助工具,…...

智能、高效、安全,企业桌面软件管理系统,赋能企业数字化转型!提升工作效率不是梦!
为了在激烈的市场竞争中脱颖而出,实现可持续发展,数字化转型已成为企业不可或缺的战略选择!而在这一过程中,一款智能、高效、安全的企业桌面软件管理系统,如安企神,正逐步成为企业数字化转型的重要驱动力。…...

第N7周:调用Gensim库训练Word2Vec模型
本文为365天深度学习训练营 中的学习记录博客原作者:K同学啊 任务: ●1. 阅读NLP基础知识里Word2vec详解一文,了解并学习Word2vec相关知识 ●2. 创建一个.txt文件存放自定义词汇,防止其被切分 数据集:选择《人民的名义…...

基于Crontab调度,实现Linux下的定时任务执行。
文章目录 引言I 预备知识Crontab的基本组成Crontab的配置文件格式Crontab的配置文件Crontab不可引用环境变量杀死进程命令II Crontab实践案例Crontab工具的使用重启tomcat服务每分钟都打印当前时间到一个文件中30s执行一次III 常见问题并发冗余执行任务&& 和|| 和 ;的区…...

Centos系统中创建定时器完成定时任务
Centos系统中创建定时器完成定时任务 时间不一定能证明很多东西,但是一定能看透很多东西,坚信自己的选择,不动摇,使劲跑,明天会更好。 在 CentOS 上,可以使用 systemd 定时器来创建一个每十秒执行一次的任务…...
WLAN基础知识(1)
WLAN: 无线局域网,无线技术:Wi-Fi、红外、蓝牙等 WLAN设备: 胖AP: 适用于家庭等小型网络,可独立配置,如:家用Wi-Fi路由器 瘦AP: 适用于大中型企业,需要配合AC…...

网络安全实训第三天(文件上传、SQL注入漏洞)
1 文件上传漏洞 准备一句话文件wjr.php.png,进入到更换头像的界面,使用BP拦截选择文件的请求 拦截到请求后将wjr.php.png修改为wjr.php,进行转发 由上图可以查看到上传目录为网站目录下的upload/avator,查看是否上传成功 使用时间戳在线工具…...

Nginx 学习之 配置支持 IPV6 地址
目录 搭建并测试1. 下载 NG 安装包2. 安装编译工具及库文件3. 上传并解压安装包4. 编译5. 安装6. 修改配置7. 启动 NG8. 查看 IP 地址9. 测试 IP 地址9.1. 测试 IPV4 地址9.2. 测试 IPV6 地址 IPV6 测试失败原因1. curl: [globbing] error: bad range specification after pos …...

六通道HDMI/网络/文件混用一体录播机
——H.265硬编、16T存储、8方互动、智能导播,每个通道都能“按需切换” 它到底是什么? WHT-6H是一台6通道全高清录播主机,每个通道都可以在三种信号源之间自由切换: HDMI信号(4路物理接口,最高1080P60&am…...

TA6585替代品6586直流双向电机驱动芯片详解
在电机驱动领域,芯片的性能、稳定性与适配性决定着设备的运行效果与使用寿命。6586作为TA6585的替代品,是一款高性能直流双向电机驱动芯片,凭借其小巧的封装、全面的保护功能及广泛的适配场景,替代TA6585,成为玩具、智…...

3分钟免费搞定Axure RP中文汉化:完整语言包安装指南
3分钟免费搞定Axure RP中文汉化:完整语言包安装指南 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 还在为Axure RP的…...

突破3大核心优势:Path of Building革新流放之路Build规划体验
突破3大核心优势:Path of Building革新流放之路Build规划体验 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding 在《流放之路》复杂的角色构建系统中࿰…...

GHelper终极指南:免费解放华硕笔记本性能的完整解决方案
GHelper终极指南:免费解放华硕笔记本性能的完整解决方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, …...

手机怎么把deepseek对话导出
手机端 DeepSeek 对话怎么导出?原生功能缺口与三方工具全景对比摘要:根据 QuestMobile 2025年数据,DeepSeek 日活用户于2月1日突破3000万,成为史上最快达成该里程碑的应用。用户量激增后,“对话如何导出”"记录怎…...
Laravel Stats Tracker迁移升级指南:从旧版本平滑过渡到新版本的完整方案
Laravel Stats Tracker迁移升级指南:从旧版本平滑过渡到新版本的完整方案 【免费下载链接】tracker Laravel Stats Tracker 项目地址: https://gitcode.com/gh_mirrors/tr/tracker Laravel Stats Tracker是一款功能强大的Laravel统计跟踪工具,能够…...

ChilloutMix NiPrunedFp32Fix模型部署全攻略:从原理到实战
ChilloutMix NiPrunedFp32Fix模型部署全攻略:从原理到实战 【免费下载链接】chilloutmix_NiPrunedFp32Fix 项目地址: https://ai.gitcode.com/hf_mirrors/emilianJR/chilloutmix_NiPrunedFp32Fix 一、技术原理:模型架构与工作流程 1.1 核心组件…...

我用 Codex 一段时间后,才发现提示词真正该怎么写
(LetAiCode - AI 编程助手) 大家好呀,我是 Lazy熊。 最近这段时间,我越来越明显地感受到一件事。 很多人在聊 AI 编程的时候,关注点其实都差不多。看模型、看价格、看速度、看功能,或者看哪个工具最近更火。 这些当…...

【Axure教程】字母定位选择器
今天教大家用一个中继器制作字母分类定位选择器的原型模板,模版我们用中继器制作的,所以使用也很方便,只需要在中继器表格对应位置填写选项信息,即可自动生成交互效果,具体效果可以打开下方预览地址体验。 【原型效果…...