学习大数据DAY41 Hive 分区表创建
目录
分区表
分区表应用场景
oracle 分区表种类
oracle 分区-范围分区
oracle 分区-列表分区
oracle 分区-散列分区
oracle 分区-组合分区
oracle 分区-分区表操作
hive 分区-创建分区表
hive 分区-分区表操作
hive 分区-动态分区表配置
上机练习
分区表
分区表应用场景

oracle 分区表种类
oracle 分区-范围分区
oracle 分区-列表分区
oracle 分区-散列分区
oracle 分区-组合分区
oracle 分区-分区表操作
hive 分区-创建分区表
hive 分区-分区表操作
hive 分区-动态分区表配置
上机练习

import pandas as pd
XlsxFile="D:\智云大数据\数据源\超市\超市数据.xlsx"
XlsxRead=pd.read_excel(XlsxFile)
# 选择要分组的列
group_column = '细分'
# 按照指定列分组
grouped = XlsxRead.groupby(group_column)
# 遍历每个分组,并将每个分组保存为单独的 xlsx 文件
# group_name: 分组名称
# group_df: 分组数据
for group_name, group_df in grouped:
output_file = f'D:\智云大数据\{group_name}超市数据.txt'
group_df.to_csv(output_file,
header=False,index=False,sep='\t')
print("文件拆分完成")create table if not exists supermarket_p (id string, -- 行 ID
ord_id string comment '订单 ID',
ord_date string comment '订单日期',
exch_date string comment '发货日期',
exch_type string comment '邮寄方式',
cust_id string comment '客户 ID
',
cust_name string comment '客户名称',
d_type string comment '细分',
city string comment '城市',
prov string comment '省/自治区',
country string comment'国家',
area string comment '地区',
pro_id string comment '产品 ID',
type1 string comment '类别',
type2 string comment '子类别',
pro_name string comment '产品名称',
sales float comment '销售额',
count1 int comment '数量 ',
discount float comment '折扣 ',
profit float comment '利润'
)
partitioned by (cd_type string)
row format delimited fields terminated by '\t'
lines TERMINATED by '\n'load data local inpath '/root/公司超市数据.txt' into table
supermarket_p
partition(cd_type='company');
load data local inpath '/root/消费者超市数据.txt' into table supermarket_p
partition(cd_type='consumer');
load data local inpath '/root/小型企业超市数据.txt' into table
supermarket_p partition(cd_type='enterprise');create table if not exists supermarket_p_ord_date (
id string, -- 行 ID
ord_id string comment '订单 ID',
--ord_date string comment '订单日期',
exch_date string comment '发货日期',
exch_type string comment '邮寄方式',
cust_id string comment '客户 ID
',
cust_name string comment '客户名称',
d_type string comment '细分',
city string comment '城市',
prov string comment '省/自治区',
country string comment'国家',
area string comment '地区',
pro_id string comment '产品 ID',
type1 string comment '类别',
type2 string comment '子类别',
pro_name string comment '产品名称',sales float comment '销售额',
count1 int comment '数量 ',
discount float comment '折扣 ',
profit float comment '利润'
)
partitioned by (ord_date_month string)
row format delimited fields terminated by '\t'
lines TERMINATED by '\n'insert into table supermarket_p_ord_date partition(ord_date_month)
select id,ord_id,date_format(ord_date,'YYYY-MM') as
ord_date_month,exch_date,exch_type,cust_id,cust_name,d_type,city,prov,
country,area,pro_id,type1,
type2,pro_name,sales,count1,discount,profit
from supermarket_p;
-开启动态分区(默认开启)
set hive.exec.dynamic.partition=true
--指定非严格模式 nonstrict 模式表示允许所有的分区字段都可以使用动态分区
set hive.exec.dynamic.partition.mode=nonstrict
--在所有执行 MR 的节点上,最大一共可以创建多少个动态分区。默认 1000
set hive.exec.max.dynamic.partitions=1000
--在每个执行 MR 的节点上,最大可以创建多少个动态分区(分区字段有多少种设多少个)
set hive.exec.max.dynamic.partitions.pernode=100
--整个 MR
Job 中,最大可以创建多少个 HDFS 文件。默认 100000
set hive.exec.max.created.files=100000
--当有空分区生成时,是否抛出异常
set hive.error.on.empty.partition=false
--打开正则查询模式`(dt|hr)?+.+`
set hive.support.quoted.identifiers=none相关文章:
学习大数据DAY41 Hive 分区表创建
目录 分区表 分区表应用场景 oracle 分区表种类 oracle 分区-范围分区 oracle 分区-列表分区 oracle 分区-散列分区 oracle 分区-组合分区 oracle 分区-分区表操作 hive 分区-创建分区表 hive 分区-分区表操作 hive 分区-动态分区表配置 上机练习 分区表 分区是将一…...

【三维目标检测模型】ImVoteNet
【版权声明】本文为博主原创文章,未经博主允许严禁转载,我们会定期进行侵权检索。 参考书籍:《人工智能点云处理及深度学习算法》 本文为专栏《Python三维点云实战宝典》系列文章,专栏介绍地址“https://blog.csdn.net/suiyin…...

力扣 | 背包dp | 279. 完全平方数、518. 零钱兑换 II、474. 一和零、377. 组合总和 Ⅳ
文章目录 一、279. 完全平方数二、518. 零钱兑换 II三、474. 一和零四、377. 组合总和 Ⅳ 一、279. 完全平方数 LeetCode:279. 完全平方数 朴素想法: 这个题目最简单的想法是,可以用 O ( n n ) O(n\sqrt{}n) O(n n)的动态规划解决&#x…...

【ECMAScript性能优化的技巧与陷阱】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...

Swift实时监听判断是否连接有网络WIFI和蜂窝数据
本章节讲解如何使用swift连接网络,实时的监听到网络的状态,在主界面中进行调用,网络包含Wi-Fi 和 蜂窝。 1.封装一个判断是否有网络的类 2.在封装类注册通知 3.主界面接收注册通知,并且调用封装的网络类 4.成功测试,有…...
Flink Source 数据源)
(三)Flink Source 数据源
Flink 数据源主要分为内置数据源和第三方数据源。其中内置数据源包含文件、Socket 连接、集合类型数据等,不需要引入其它依赖库。第三方数据源定义了 Flink 和外部系统数据交互的逻辑,Flink 提供了非常丰富的数据源连接器,例如 Kafka、Elasticsearch、RabbitMQ、JDBC 等。 …...

第四届机电一体化、自动化与智能控制国际学术会议(MAIC 2024)
目录 大会官网 会议简介 组织机构 大会主席 程序委员会主席 主讲嘉宾 征稿主题 参会说明 大会官网 http://www.icmaic.org 会议简介 第四届机电一体化、自动化与智能控制国际学术会议(MAIC 2024)将于2024年9月27-29日在中国成都召开。MAIC 20…...
leetcode 089 打家劫舍
leetcode 089 打家劫舍 题目 一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响小偷偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。 给定…...
)
等保测评基础知识(六)
《计算机病毒防治管理办法》51号令 第十四条 从事计算机设备或者媒体生产、销售、出租、维修行业的单位和个人,应当对计算机设备或者媒体进行计算机病毒检测、清除工作,并备有检测、清除的记录。 第十九条 计算机信息系统的使用单位有下列行为之一的,由公安机关处以警告…...
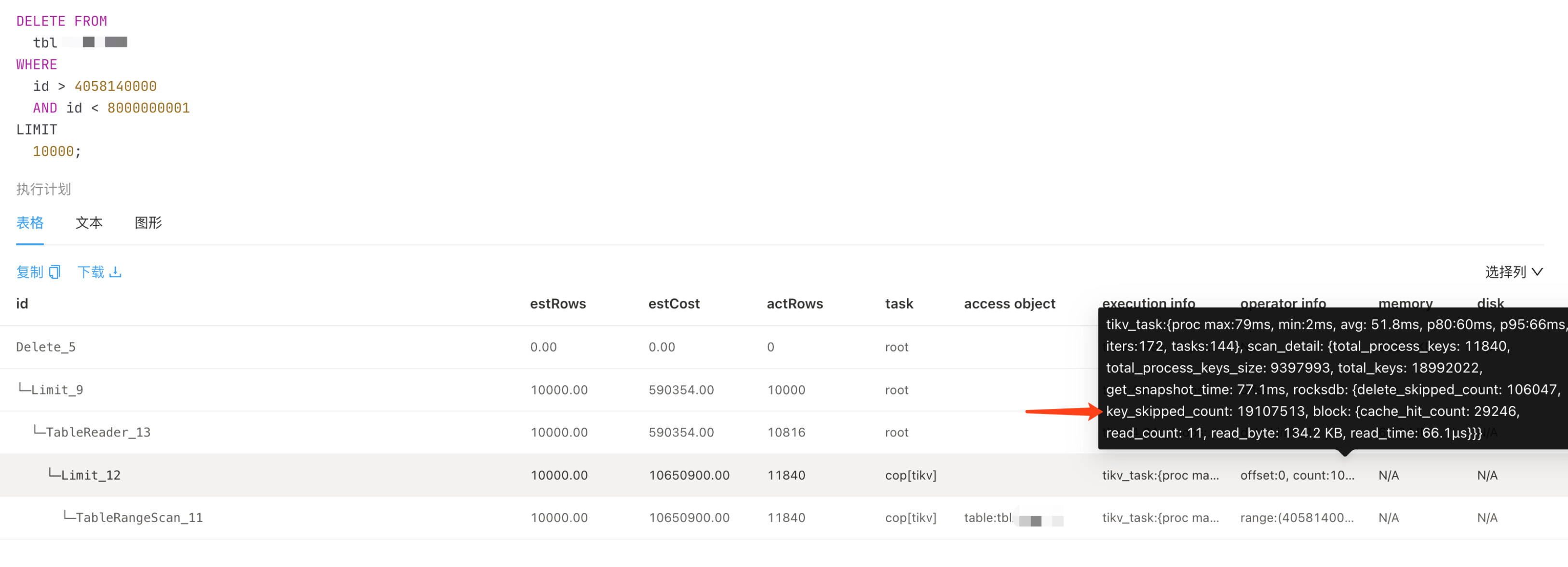
作业帮 TiDB 7.5.x 使用经验
作者: 是我的海 原文来源: https://tidb.net/blog/5f9784d3 近期在使用 TiDB 时遇到的一些小问题的梳理总结,大部分版本都在6.5.6和7.5.2 1、limit 导致的扫描量过大的优化 研发定时任务每天需要扫描大量数据,到时机器网卡被…...

c语言练习题1
1.输出Helloword /*输出Helloword*/ #include<stdio.h> int main() {printf("Hello word!");return 0; }2.整型变量的定义与使用 /*整型变量的定义与使用*/ #include <stdio.h> int main() {int a;int b;a 10;b 20;int c a b;int d a - b;printf(…...

嵌入式开发就业方向有哪些?前景未来可期!
在科技日新月异的今天,嵌入式系统几乎渗透到了我们生活的各个角落。从简单的家用电器到复杂的工业自动化设备,再到我们手中的智能手机,无一不体现出嵌入式技术的魅力。因此,嵌入式领域的就业前景广阔,为众多求职者提供…...

系列:水果甜度个人手持设备检测-github等开源库和方案
系列:水果甜度个人手持设备检测 -- github等开源库和方案 概述 通常来说,年纪轻轻的我们一般都喜欢走捷径,对于智能设备和算法软件领域来说,GitHub应该算为数不多的的捷径之一。就算因为效果不好/知识产权/方向不同等原因不用,…...

Visual Studio中 生成版本号
Visual Stuodio WPF项目 自动生成版本号 生成递增版本号 软件版本号主要标识了软件的版本,通过其可以了解软件、类库文件的当前版本,使得软件版本控制有所依据。 我们也可以在项目属性上可以看到相关设置的界面,对应的英文名称分别为&#…...

AI入门指南(四):分类问题、回归问题、监督、半监督、无监督学习是什么?
文章目录 一、前言二、分类问题、回归问题是什么?分类问题概念常见算法分类问题的实际应用:银行贷款审批案例 回归问题概念常见算法回归问题实际应用:线性回归模型预测房价 小结 三、监督、半监督、非监督学习是什么?监督学习非监…...

Linux下本地端口转发
在Linux下进行本地端口转发处理,可以进行如下操作: 1.确认NetFilter相关驱动编译到内核,并且CONFIG_IP_NF_TARGET_REDIRECTy; 2.开启转发功能:echo 1 > /proc/sys/net/ipv4/ip_forward; 3.设置转发规…...
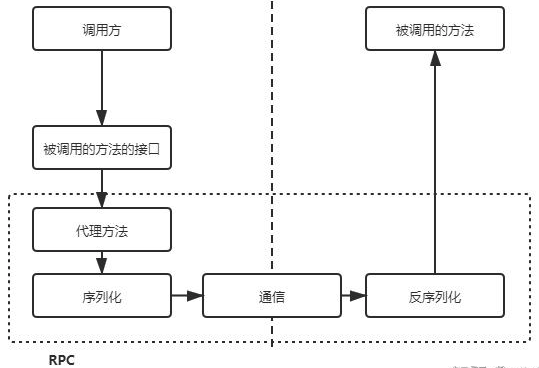
RPC 和 HTTP 理解
网上充斥着各类类似于这样的文章:rpc 比 http 快了多少倍?既然有了 http,为什么还要用 rpc 调用等等。遇到这类文章,说明对 http 和 rpc 是由理解误区的。 这里再次重复强调一遍,通信协议不是 rpc 最重要的部分&#x…...

Visual Studio 2022 v17.11 发布
Visual Studio 2022 版本 17.11 正式发布 (GA),此版本主要是基于用户反馈的各项改进。 “每项增强、每项修复和每项新功能均根据你的反馈而制定。无论你是在构建 Web、桌面、云还是游戏应用程序,Visual Studio 2022 v17.11 都旨在让你的开发体验更流畅、…...

通讯专题-RS232
1 概述 RS-232是一种点对点通信协议,这意味着每个数据信号沿一根导线传输(差分信号使用两根导线传输一个数据信号),RS-232为全双工方式运行(总线可同时发送和接收数据)。 根据新修订的标准为容性负载为2500…...

桥接模式详解
桥接模式 概念: 将抽象部分和实现部分分离, 使他们都可以独立的变化 概念很抽象, 难以理解, 我们举个例子 例子 设想三种不同品牌的汽车 大车 中车 小车 三种不同类型的引擎 纯电引擎 混动引擎 燃油引擎 如果我们把他们两两组合, 都继承同一个类的话,就会有9个类, 并且如果后…...

美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训
https://www.mckinsey.com/mgi/our-research/At-250-sustaining-Americas-competitive-edge 美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训 这一切始于一场惊天动地的反抗行动。 1776年7月,来自13…...

柔性LED灯丝DIY:从电路原理到创意饰品制作全攻略
1. 项目概述:当生日遇上柔性LED灯丝给孩子的生日派对准备一份独一无二的、会发光的惊喜,是很多家长和手工爱好者的心愿。这次,我们不买现成的塑料灯牌,而是亲手做一个能戴在头上或挂在脖子上的“生日数字灯冠”。这个项目的核心&a…...

别再只盯着wx.login了!SpringBoot后端实战:用getPhoneNumber接口搞定小程序用户手机号绑定
微信小程序用户手机号绑定:SpringBoot后端深度实践指南 在当今移动互联网生态中,微信小程序已成为连接用户与服务的重要桥梁。对于需要强实名认证或直接触达用户的业务场景(如电商交易、金融服务、政务办理等),仅依赖w…...

终极指南:如何使用Autoclick实现Mac自动点击900次/秒
终极指南:如何使用Autoclick实现Mac自动点击900次/秒 【免费下载链接】Autoclick A simple Mac app that simulates mouse clicks 项目地址: https://gitcode.com/gh_mirrors/au/Autoclick 你是否厌倦了重复性的鼠标点击工作?无论是游戏中的重复操…...

Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞!
Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Windows系统…...

Scarab空洞骑士模组管理器:2024年最完整的安装与使用指南
Scarab空洞骑士模组管理器:2024年最完整的安装与使用指南 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在为空洞骑士模组安装的复杂流程而烦恼吗?…...

GitClaw:基于Go的轻量级Git钩子服务器与集中式权限管理方案
1. 项目概述与核心价值如果你是一名开发者,尤其是经常在团队协作中处理Git仓库的工程师,那么你一定对“权限管理”这四个字又爱又恨。爱的是它能保障代码安全,恨的是它配置起来繁琐,尤其是在处理跨项目、跨团队的复杂权限矩阵时。…...

如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南
如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_…...

云原生安全工具:保护云原生环境
云原生安全工具:保护云原生环境 一、云原生安全工具概述 1.1 云原生安全工具的定义 云原生安全工具是指专为云原生环境设计的安全工具和解决方案。它们用于保护容器、Kubernetes集群、微服务和Serverless应用的安全。 1.2 云原生安全工具的价值 安全防护:…...

树莓派+Kali Linux+PiTFT打造便携式安全测试平台全攻略
1. 项目概述如果你和我一样,对网络安全和嵌入式硬件都抱有浓厚的兴趣,那么将Kali Linux与树莓派结合,再配上一块小巧的触摸屏,绝对是一个能让你兴奋起来的项目。这不仅仅是把两个热门技术拼在一起,更是打造一个真正便携…...