什么是词向量?如何得到词向量?Embedding 快速解读
我第一次接触 Embedding 是在 Word2Vec 时期,那时候还没有 Transformer 和 BERT 。Embedding 给我的印象是,可以将词映射成一个数值向量,而且语义相近的词,在向量空间上具有相似的位置。
有了 Embedding ,就可以对词进行向量空间上的各类操作,比如用 Cosine 距离计算相似度;句子中多个词的 Embedding 相加得到句向量。
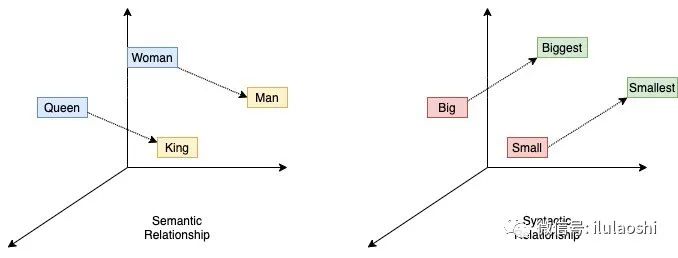 图1 Word2Vec 时期,Embedding 可以将词映射到向量空间,语义相似的词在向量空间里有相似的位置
图1 Word2Vec 时期,Embedding 可以将词映射到向量空间,语义相似的词在向量空间里有相似的位置
那 Embedding 到底是什么?Embedding 怎么训练出来的?
查询矩阵和One-Hot
Embedding 本质是一个查询矩阵,或者说是一个 dict 数据结构。以词向量为例, Embedding dict 的 Key 是词在词表中的索引位置(Index),Embedding dict 的 Value 是这个词的 dim 维的向量。假设我们想把“北京欢迎你”编码为向量。词表一共5个词(Token)(每个字作为一个词):“北”: 0、“京”: 1、“欢”: 2、“迎”: 3、“你”: 4。每个 Token 都有文字表示和在词表中的索引。BERT 等模型的 Token 是单个字,一些其他模型的 Token 是多个字组成的词。
深度学习框架都有一个专门的模块来表示 Embedding,比如 PyTorch 中 torch.nn.Embedding 就是一个专门用于做 Embedding 的模块。我们可以用这个方法将 Token 编码为词向量。

这里 Embedding 的参数中,num_embeddings 表示词表大小,即词表一共多少个词, embedding_dim 为词向量维度。在当前这个例子中,某个词被映射为3维的向量,经过 Embedding 层之后,输出是 Index 为1的 Token 的3维词向量。
Embedding 里面是什么?是一个权重矩阵:

输出是 Embedding 中的权重矩阵,是 num_embeddings * embedding_dim 大小的矩阵。
刚才那个例子,查找 Index 为1的词向量 ,恰好是 Embedding 权重矩阵的第2行(从0计数的话则为第1行)。
权重矩阵如何做查询呢?答案是 One-Hot 。
先以 One-Hot 编码刚才的词表。
为了得到词向量,torch.nn.Embedding 中执行了一次全连接计算:
One-Hot 会将词表中 Index=1 的词(对应的 Token 是“京”) 编码为 [0, 1, 0, 0, 0]。这个向量与权重矩阵相乘,只取权重矩阵第2行的内容。所以,torch.nn.Embedding 可以理解成一个没有 bias 的 torch.nn.Linear ,求词向量的过程是先对输入进行一个 One-Hot 转换,再进行 torch.nn.Linear 全连接矩阵乘法。全连接 torch.nn.Linear 中的权重就是一个形状为 num_embeddings * embedding_dim 的矩阵。
下面的代码使用 One-Hot 和矩阵相乘来模拟 Embedding :

那么可以看到, Embedding 层就是以 One-Hot 为输入的全连接层!全连接层的参数,就是一个“词向量表”!或者说,Embedding 的查询过程是通过 One-Hot 的输入,以矩阵乘法的方式实现的。
如何得到词向量
既然 Embedding 就是全连接层,那如何得到 Embedding 呢?Embedding 层既然是一个全连接神经网络,神经网络当然是训练出来的。只是在得到词向量的这个训练过程中,有不同的训练目标。
我们可以直接把训练好的词向量拿过来用,比如 Word2Vec、GloVe 以及 Transformer ,这些都是一些语言模型,语言模型对应着某种训练目标。BERT 这样的预训练模型,在预训练阶段, Embedding 是随机初始化的,经过预训练之后,就可以得到词向量。比如 BERT 是在做完形填空,用周围的词预测被掩盖的词。语料中有大量“巴黎是法国的首都”的文本,把“巴黎”掩盖住:“[MASK]是法国的首都”,模型仍然能够将“[MASK]”预测为“巴黎”,说明词向量已经学得差不多了。
预训练好的词向量作为己用,可以用于下游任务。BERT 在微调时,会直接读取 Embedding 层的参数。预训练好的词向量上可以使用 Cosine 等方式,获得距离和相似度,语义相似的词有相似的词向量表示。这是因为,我们在用语言模型在预训练时,有窗口效应,通过前n个字预测下一个字的概率,这个n就是窗口的大小,同一个窗口内的词语,会有相似的更新,这些更新会累积,而具有相似模式的词语就会把这些相似更新累积到可观的程度。苏剑林在文章中举了”忐忑“的例子,“忐”、“忑”这两个字,几乎是连在一起用的,更新“忐”的同时,几乎也会更新“忑”,因此它们的更新几乎都是相同的,这样“忐”、“忑”的字向量必然几乎是一样的。
预训练中,训练数据含有一些相似的语言模式。“相似的模式”指的是在特定的语言任务中,它们是可替换的,比如在一般的泛化语料中,“我喜欢你”中的“喜欢”,替换为“讨厌”后还是一个成立的句子,因此“喜欢”与“讨厌”虽然在语义上是两个相反的概念,但经过预训练之后,可能得到相似的词向量。
另外一种方式是从零开始训练。比如,我们有标注好的情感分类的数据,数据足够多,且质量足够好,我们可以直接随机初始化 Embedding 层,最后的训练目标是情感分类结果。Embedding 会在训练过程中自己更新参数。在这种情况下,词向量是通过情感分类任务训练的,“喜欢”与“讨厌”的词向量就会有差异较大。
一切皆可Embedding
Embedding 是经过了 One-Hot 的全连接层。除了词向量外,很多 Categorical 的特征也可以作为 Embedding。推荐系统中有很多 One-Hot 的特征,比如手机机型特征,可能有上千个类别。深度学习之前的线性模型直接对特征进行 One-Hot 编码,有些特征可能是上千维,上千维的特征里,只有一维是1,其他特征都是0,这种特征非常稠密。深度学习模型不适合这种稀疏的 One-Hot 特征,Embedding 可以将稀疏特征编码为低维的稠密特征。
一切皆可 Embedding,其实就是说 Embedding 用一个低维稠密的向量“表示”一个对象。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。
相关文章:
什么是词向量?如何得到词向量?Embedding 快速解读
我第一次接触 Embedding 是在 Word2Vec 时期,那时候还没有 Transformer 和 BERT 。Embedding 给我的印象是,可以将词映射成一个数值向量,而且语义相近的词,在向量空间上具有相似的位置。 有了 Embedding ,就可以对词进…...

AI视频创作应用
重磅推荐专栏: 《大模型AIGC》 《课程大纲》 《知识星球》 本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经…...
)
JAVA常见的工具类之Object类(超详细)
1、Java API简介 Java API(Java Application Programming Interface)是Java应用程序编程接口的缩写。Java中的API,就是JDK提供的具有各种功能的Java类,灵活使用Java API能够大大提高使用Java语言编写程序的效率。 Java API的帮助文档可到 http://docs.or…...

深度学习(YOLO、DETR) 十折交叉验证
二:交叉验证 在 K 折验证之前最常用的验证方法就是交叉验证,即把数据划分为训练集、验证集和测试集。一般的划分比例为 7:1:2。但如何合理的抽取样本就成为了使用交叉验证的难点,不同的抽取方法会导致截然不同的训练性…...

基于php网上差旅费报销系统设计与实现
网上报销系统以LAMP(LinuxApacheMySQLPHP)作为平台,涉及到PHP语言、MySQL数据库、JavaScript语言、HTML语言。 2.1 PHP语言简介 PHP,一个嵌套的缩写名称,是英文 “超级文本预处理语言”(PHP: Hypertext Preprocessor)的缩写。P…...

微服务及安全
一、微服务的原理 1.什么是微服务架构 微服务架构区别于传统的单体软件架构,是一种为了适应当前互联网后台服务的「三高需求:高并发、高性能、高可用」而产生的的软件架构。 单体式应用程序 与微服务相对的另一个概念是传统的单体式应用程序( Monolithic application ),…...

图文详解ThreadLocal:原理、结构与内存泄漏解析
目录 一.什么是ThreadLocal 二.ThreadLocal的内部结构 三.ThreadLocal带来的内存泄露问题 ▐ key强引用 ▐ key弱引用 总结 一.什么是ThreadLocal 在Java中,ThreadLocal 类提供了一种方式,使得每个线程可以独立地持有自己的变量副本,而…...

基于java的综合小区管理系统论文.doc
摘 要 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统综合小区管理系统信息管理难度大,容错率低&am…...

如何合理设置PostgreSQL的`max_connections`参数
合理设置PostgreSQL的max_connections参数对于数据库的稳定性和性能至关重要。这个设置值决定了允许同时连接到数据库的最大客户端数量。如果设置不当,可能导致资源浪费或系统过载。以下是设置max_connections时需要考虑的几个关键因素: 1. 评估系统硬件…...

Kubectl 常用命令汇总大全
kubectl 是 Kubernetes 自带的客户端,可以用它来直接操作 Kubernetes 集群。 从用户角度来说,kubectl 就是控制 Kubernetes 的驾驶舱,它允许你执行所有可能的 Kubernetes 操作;从技术角度来看,kubectl 就是 Kubernetes…...

【Linux】Linux环境基础开发工具使用之Linux调试器-gdb使用
目录 一、程序发布模式1.1 debug模式1.2 release模式 二、默认发布模式三、gdb的使用结尾 一、程序发布模式 程序的发布方式有两种,debug模式和release模式 1.1 debug模式 目的:主要用于开发和测试阶段,目的是让开发者能够更容易地调试和跟…...

clickhouse_driver
一、简介 clickhouse_driver是一个Python库,用于与ClickHouse数据库进行交互。ClickHouse是一个高性能的列式数据库管理系统(DBMS),它适用于实时分析(OLAP)场景。clickhouse_driver模块提供了与ClickHouse…...
BI分析实操案例分享:零售企业如何利用BI工具对销售数据进行分析?
在当下这个竞争激烈的零售市场,企业如何在波诡云谲的商场中站稳脚跟,实现销售目标的翻倍增长? 答案可能就藏在那些看似杂乱无章的数字里。 是的,你没有看错,答案正是那些我们日常接触的销售数据。它们就像是宝藏&…...

python : Requests请求库入门使用指南 + 简单爬取豆瓣影评
Requests 是一个用于发送 HTTP 请求的简单易用的 Python 库。它能够处理多种 HTTP 请求方法,如 GET、POST、PUT、DELETE 等,并简化了 HTTP 请求流程。对于想要进行网络爬虫或 API 调用的开发者来说,Requests 是一个非常有用的工具。在今天的博…...

宋红康JVM调优思维导图
文章目录 1. 概述2. JVM监控及诊断命令-命令行篇3. JVM监控及诊断工具-GUI篇4. JVM运行时参数5. 分析GC日志 课程地址 1. 概述 2. JVM监控及诊断命令-命令行篇 3. JVM监控及诊断工具-GUI篇 4. JVM运行时参数 5. 分析GC日志...

linux 网卡配置
linux网卡可以通过命令和配置文件配置,如果是桌面环境还可以通过图形化界面配置. 1.ifconfig(interfaces config)命令方式 通常需要以root身份登录或使用sudo以便在Linux机器上使用ifconfig工具。依赖于ifconfig命令中使用一些选项属性,ifconfig工具不仅可以被用来…...

IEEE |第五届机器学习与计算机应用国际学术会议(ICMLCA 2024)
第五届机器学习与计算机应用国际学术会议(ICMLCA 2024)定于2024年10月18-20日在中国杭州隆重举行。本届会议将主要关注机器学习和计算机应用面临的新的挑战问题和研究方向,着力反映国际机器学习和计算机应用相关技术研究的最新进展。 IEEE |第五届机器学习与计算机应…...

【网络安全】漏洞挖掘:IDOR实例
未经许可,不得转载。 文章目录 正文 正文 某提交系统,可以选择打印或下载passport。 点击Documents > Download后,应用程序将执行 HTTP GET 请求: /production/api/v1/attachment?id4550381&enamemId123888id为文件id&am…...

vue项目执行 cnpm install 报错证书过期的解决方案
拉下源码后执行依赖安装过程,报错 error Error: Certificate has expired,可以通过一下方发解决:npm config set strict-ssl false 再执行 cnpm 命令即可正常拉依赖...

XGboost的安装与使用
安装xgboost: conda install py-xgboost下载demo的数据: https://github.com/dmlc/xgboost 安装graphviz conda install python-graphviz数据 在demo/data里面: 训练集是:agaricus.txt.train、测试集是:agaricus…...

【2024最新】ElevenLabs日语模型v2.4深度评测:对比VoiceLab、OpenJTalk与Azure Custom Neural TTS的MOS分与实时吞吐数据
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs日语模型v2.4的核心演进与技术定位 ElevenLabs 日语模型 v2.4 并非简单语音合成能力的迭代,而是面向高保真、低延迟、多语境日语语音生成的一次系统性重构。其底层架构从基于 Gri…...

基于BLE信号强度的寻物游戏:用CircuitPython实现无线接近探测
1. 项目概述:一个用蓝牙信号“捉迷藏”的硬件游戏几年前我第一次接触Adafruit的Circuit Playground系列开发板时,就被它那种“开箱即玩”的理念吸引了。它把LED、按钮、传感器都集成在一块板子上,让你不用焊接就能快速验证想法。后来出的Circ…...

AI智能体分类学:从原理到实践,构建高效Agent系统的设计指南
1. 项目概述与核心价值最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的现象:大家聊起Agent,要么是“它能帮我写代码”,要么是“它能自动处理客服”,但很少有人能系统地说清楚ÿ…...

如何在Windows上高效使用酷安社区:UWP桌面客户端完全指南
如何在Windows上高效使用酷安社区:UWP桌面客户端完全指南 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 你是否经常在手机小屏幕上刷酷安,眼睛酸痛却停不下来&…...
)
C语言结构体:从‘学生信息管理‘到‘链表实现‘的保姆级跃迁指南(含typedef避坑)
C语言结构体:从学生信息管理到链表实现的实战进阶 在C语言的世界里,结构体就像是一个神奇的收纳盒,它能够将不同类型的数据打包成一个整体。想象一下,当你需要管理学生信息时,不再需要为姓名、学号、成绩等分别定义变量…...

基于LanceDB的AI记忆管理系统:从向量存储到智能记忆引擎
1. 项目概述:一个面向AI记忆管理的向量数据库解决方案最近在折腾AI应用,特别是那些需要长期记忆和上下文关联的智能体(Agent)时,我发现一个核心痛点:如何高效、低成本地存储和检索海量的对话历史、知识片段…...
)
告别手动点点点:用CAPL脚本实现CANoe诊断自动化测试(附VIN码读取与文件写入完整代码)
告别手动点点点:用CAPL脚本实现CANoe诊断自动化测试(附VIN码读取与文件写入完整代码) 在汽车电子测试领域,诊断功能验证是每个测试工程师的日常必修课。想象一下这样的场景:你需要反复验证几十个ECU的VIN码读取功能&am…...
)
告别python-pcl!用pclpy在Windows上轻松玩转PCL点云处理(Python 3.6/3.7保姆级教程)
告别python-pcl!用pclpy在Windows上轻松玩转PCL点云处理(Python 3.6/3.7保姆级教程) 在三维视觉和机器人领域,点云处理一直是核心技术难点之一。PCL(Point Cloud Library)作为开源领域的标杆工具库&#x…...

电商运营数字密码解析:0.01、50、0、8.8背后的用户增长与转化逻辑
1. 项目概述:一次电商运营的“数字密码”破译最近在复盘一些头部品牌的电商运营案例时,CYPRESS天猫旗舰店的一组数字引起了我的注意:0.01、50、0、8.8。乍一看,这像是几个毫无关联的随机数,但当你把它们放在电商运营的…...
)
告别SD卡!用Ubuntu主机给Jetson Orin Nano刷机,保姆级避坑指南(SDK Manager篇)
告别SD卡!用Ubuntu主机给Jetson Orin Nano刷机,保姆级避坑指南(SDK Manager篇) 当第一次拿到Jetson Orin Nano Developer Kit时,很多开发者会本能地选择SD卡刷机方案——毕竟这是最"傻瓜式"的操作。但经历过…...