C++11:右值引用、移动语义和完美转发
目录
前言
1. 左值引用和右值引用
2. 引用范围
3. 左值引用的缺陷
4. 右值引用的作用
5. 右值引用的深入场景
6. 完美转发
总结
前言
C++11作为一次重大的更新,引入了许多革命性的特性,其中之一便是右值引用和移动语义。本文将深入探讨其中引入的右值及其相关概念,帮助读者更好地理解这一特性,从而在编程实践中更有效地利用它。
1. 左值引用和右值引用
C++98中有引用的用法,而C++11中新增了右值引用的语法特性,之前学习的引用都是左值引用。不管是左值引用还是右值引用,都是给对象取别名。那什么左值和左值引用?还有右值和右值引用?
左值是一个表示数据的表达式。
- 具有固定的地址,可以获取它们的地址。
- 可以出现在赋值符号的左侧,对它进行赋值。
- 当用const修饰左值时,不能进行赋值,但是可以取地址。
左值引用就是对左值进行引用。
下面的例子中,有整型变量x,指针变量ptr,const修饰下整型变量y,字符串类变量s。上面的变量都是左值,都可以取地址。
int main()
{// 以下的x、y、ptr、s都是左值// 左值:可以取地址int x = 10;int* ptr = new int(0);const int y = 2;string s("11111");//左值引用int& r1 = x;int*& r2 = ptr;int& r3 = *ptr;const int& r4 = y;string& r5 = s;return 0;
}右值是一个表示数据的表达式,如字面常量、临时对象、表达式返回值、函数返回值(左值引用类型返回除外)。
- 没有固定的内存地址,不能够获取其地址。
- 可以出现在赋值符号的右边,但是不能出现在赋值符号的左边没有。
右值引用就是对右值进行引用。
int main()
{//右值:不能取地址double x = 2.5;//以下是常见的右值15; //字面常量x + 15; //表达式返回值fmin(x, y); //函数返回值string("11111"); //临时对象//右值引用int&& rr1 = 15;double&& rr2 = x + 15;double&& rr3 = fmin(x, y);string&& rr4 = string("1111111");return 0;
}2. 引用范围
左值引用范围
- 左值引用一般情况下只能引用左值。
- 但加上const修饰之后,左值引用可以引用左值,还可以引用右值。
字面常量15被引用为整型变量时需要转换类型,中间会产生临时变量,临时变量具有常性。如果使用普通引用,可以对此引用进行修改,会导致权限放大。
int main()
{//右值:不能取地址double x = 2.5;//以下是常见的右值15; //字面常量x + 15; //表达式返回值fmin(x, y); //函数返回值string("11111"); //临时对象//右值引用int&& rr1 = 15;double&& rr2 = x + 15;double&& rr3 = fmin(x, y);string&& rr4 = string("1111111");//const修饰后,可以引用右值const int& rx1 = 15;const double& rx2 = x + 15;const double& rx3 = fmin(x, y);const string& rx4 = string("1111111"); return 0;
}右值引用范围:
- 右值引用一般情况下只能引用右值。
- 但是右值引用可以引用move之后的左值。
int main()
{//右值引用int&& rr1 = 15;//无法引用左值,下面会报错int x = 10;int&& rr2 = x; //error//move之后,可以右值引用int&& rr3 = std::move(x);return 0;
}3. 左值引用的缺陷
既然已经有左值引用,为什么还要搞出一个右值引用的概念,这是为什么呢?下面是用C++简单实现的string类。如果对字符串类不熟悉,可以转到这篇文章http://t.csdnimg.cn/Znclr。构造函数,拷贝构造函数和赋值重载函数内部都有打印函数原型,方便查看函数调用情况。
#include <assert.h>namespace Rustle
{class string{public:typedef char* iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}typedef const char* const_iterator;const_iterator begin() const{return _str;}const_iterator end() const{return _str + _size;}string(const char* str = ""):_size(strlen(str)), _capacity(_size){cout << "string(char* str)" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}// s1.swap(s2)void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}// 拷贝构造string(const string& s):_str(nullptr){cout << "string(const string& s) -- 深拷贝" << endl;reserve(s._capacity);for (const auto& ch : s){push_back(ch);}}// 赋值重载string& operator=(const string& s){cout << "string& operator=(string s) -- 深拷贝" << endl;if (this != &s){_str[0] = '\0';_size = 0;reserve(s._capacity);for (auto& ch : s){push_back(ch);}}return *this;}~string(){delete[] _str;_str = nullptr;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];if (_str){strcpy(tmp, _str);delete[] _str;}_str = tmp;_capacity = n;}}void push_back(char ch){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}void append(const char* str){size_t len = strlen(str);if (_size + len > _capacity){reserve(_size + len);}strcpy(_str + _size, str);_size += len;}//s += 'a'string& operator+=(char ch){push_back(ch);return *this;}//s += "11111"string& operator+=(const char* str){append(str);return *this;}const char* c_str() const{return _str;}private:char* _str = nullptr;size_t _size = 0;size_t _capacity = 0; // 不包含最后做标识的\0};
}左值引用的场景
左值引用给左值取别名。传递函数参数或者返回函数值时,可以减少拷贝,提高效率。
- TestNonLeftRef函数参数类型是string类,函数参数是实参的临时拷贝,如果是自定义类型,会调用相应的拷贝构造,创建新的变量。
- 而TestLeftRef函数参数是string类引用,相当于给传过来的参数取别名,不会调用拷贝构造。
- operator[]函数返回值类型是字符类型的引用,对字符进行取别名,不用进行拷贝。
void TestNonLeftRef(Rustle::string s)
{}void TestLeftRef(Rustle::string& s)
{}int main()
{Rustle::string s("111111");TestNonLeftRef(s);TestLeftRef(s);Rustle::string s1("xxxxxx");//operator[]返回值类型是//Rustle::char& operator[](size_t n);s1[0];return 0;
}运行结果如下,main函数中创建s变量时调用了构造函数。接受参数为s的两个函数,只有TestNonLeftRef调用了拷贝构造。最后一个构造是创建s1变量调用的。

左值引用的缺陷
当函数返回的值是一个函数内的局部变量时,局部变量出了函数作用域就会被销毁,无法使用左值引用返回,只能进行传值返回。
Rustle::string GetStr(int flag)
{Rustle::string str;if (flag)str += "true";elsestr += "false";return str;
}int main()
{Rustle::string s1;s1 = GetStr(1);return 0;
}如上面代码所示,str是一个局部变量,出作用域就销毁,只能使用传值返回。下图中,一般情况下str变量传值返回时,会拷贝此变量来创建一个临时变量,如果是自定义类型就会调用拷贝构造函数。s1会调用拷贝构造函数,拷贝临时变量

但是某些编译器进行优化之后,只用进行一次拷贝构造函数,不产生中间的临时变量。

不过VS2022编译器对这个场景优化的十分厉害。下面是运行结果示意图,只调用了一次构造函数。说明编译器已经识别s1要使用GetStr返回值进行构造。相当于str跟s1是同一个变量。

但如果先创建string类,再使用赋值重载函数拷贝函数返回值。
int main()
{Rustle::string s2;s2 = GetStr(0);return 0;
}运行结果如下,调用了两次构造函数和一个赋值重载函数。mian函数内创建一个string类对象,GetStr函数内创建了一个string类对象。在返回该对象时,本来会产生一个临时对象,调用一个拷贝构造,不过编译器优化掉这一步骤,直接调用赋值重载函数。

4. 右值引用的作用
通过上面的讲述,我们知道左值引用不能解决传值返回的场景,大部分编译器起码至少会调用一次拷贝构造,这样会降低运行效率。右值引用的出现就是为了解决这种场景。
- 右值分为纯右值和将亡值。其中将亡值指的是那些即将被销毁的对象,函数返回值就是将亡值。右值引用可以引用将亡值,虽然左值引用不能当做返回类型,但是右值引用可以当做返回类型。
- 既然右值引用左为函数返回类型,string类就要重载一份右值引用版本的拷贝构造函数和赋值重载函数。这类函数分别叫做移动构造函数和移动赋值函数。
- 如下面代码,移动构造函数的本质是将右值的资源转移,或者叫做“窃取”。这样就不用做深拷贝了,所以叫做移动构造,就是转移别人的资源进行构造。
// 移动构造string(string&& s):_str(nullptr), _size(0), _capacity(0){cout << "string(string&& s) -- 移动构造" << endl;swap(s);}// 移动赋值string& operator=(string&& s){cout << "string& operator=(string&& s) -- 移动构造" << endl;swap(s);return *this;}增加了移动构造和移动赋值之后,我们测试一下刚才的代码。
Rustle::string GetStr(int flag)
{Rustle::string str;if (flag)str += "true";elsestr += "false";return str;
}int main()
{Rustle::string s2;s2 = GetStr(0);return 0;
}调用了两次构造函数,还有一次移动构造。

5. 右值引用的深入场景
前面我们提到右值引用无法直接引用左值,但是move函数可以将左值转换成右值,从而达到左值被引用。std::move函数实际上对左值没有转移任何资源,只是将左值强制转化成右值。
如下面的代码,string类对象正常使用同类进行拷贝构造,不会影响被拷贝的对象。但是被拷贝对象被move之后,强制转化成右值,就会调用移动版本的构造,窃取s1的资源,将s1置空。
int main()
{Rustle::string s1("xxxxxx");//调用普通构造函数Rustle::string s2(s1);s1[0];//识别s1为右值,调用移动构造,会转移s1的资源来构造s3//那么s1就被置空了,无法用[]访问Rustle::string s3(move(s1));s1[0]; //errorreturn 0;
}
左值引用和右值引用本质上都是给变量取别名。我们看下面的代码,s1为左值,通过强制转换成右值。匿名对象本身为右值,也可以通过强制转化成左值。
void func(const Rustle::string& s)
{cout << "void func(const Rustle::string& s)" << endl;
}void func(Rustle::string&& s)
{cout << "void func(Rustle::string&& s)" << endl;
}//左值和右值属性可以互相切换,在数据层没有差别
int main()
{//左值Rustle::string s1("1111111");func(s1);//强制转换成右值func((Rustle::string&&)s1);//右值func(Rustle::string("11111111"));//强制转换成左值func((Rustle::string&)Rustle::string("11111111"));return 0;
}运行结果如下:

下面是用C++简单实现的list容器,只包含插入函数相关的部分,其他接口函数已经省略。并且还提供了右值引用版本的插入函数。如果对list容器不熟悉,可以看这篇文章http://t.csdnimg.cn/WWsBs。
namespace Rustle
{template<class T>struct ListNode{ListNode<T>* _next;ListNode<T>* _prev;T _data;ListNode(const T& data = T())//匿名对象,调用的是默认构造:_next(nullptr),_prev(nullptr),_data(data){}};template<class T>class list{typedef ListNode<T> Node;public:list(){_head = new Node(T());_head->_next = _head;_head->_prev = _head;}void push_back(const T& x){insert(end(), x);}//移动插入void push_back(T&& x){insert(end(), x);}iterator insert(iterator pos, const T& x){Node* cur = pos._node;Node* newnode = new Node(x);Node* prev = cur->_prev;//prev newnode curprev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;return iterator(newnode);}iterator insert(iterator pos, T&& x){Node* cur = pos._node;Node* newnode = new Node(x);Node* prev = cur->_prev;//prev newnode curprev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;return iterator(newnode);}private:Node* _head;};我们尝试运行下面的代码。我把代码分为五个部分,每个部分都有对应的解释。
int main()
{//1.创建一个list类变量ltRustle::list<Rustle::string> lt;//2.显示对象插入Rustle::string s1("1111111111111111");lt.push_back(s1);//3.匿名对象lt.push_back(Rustle::string("1111111111111111"));//4.字符串类隐式类型转换为string类lt.push_back("1111111111111111");//5.通过move函数强制转化s1为右值lt.push_back(move(s1));return 0;
}- 运行结果如下。第一个string类的构造函数和拷贝构造函数,是创建list容器变量lt调用的。因为list容器有个哨兵位结点,内部不存储有效数据,用来简化list的插入和删除工作。
- list的默认构造函数会开辟一个ListNode类的结点,ListNode类的构造函数是全缺省的,如果没传参数,会使用缺省值,缺省值是调用string类的默认构造函数。参数列表中拷贝data创建ListNode的_data变量,会调用拷贝构造函数。
ListNode(const T& data = T())//匿名对象,调用的是默认构造:_next(nullptr),_prev(nullptr),_data(data){}list(){_head = new Node(T());_head->_next = _head;_head->_prev = _head;}- 正常来说,序号3之后的代码中push_back参数都是右值,应该调用string类中的移动构造才对,但是全部调用的是拷贝构造,进行深拷贝。这是为什么呢?

尝试运行下面的代码,观察结果。
void TestRightRef(Rustle::string&& str)
{cout << &str << endl;
}int main()
{TestRightRef(Rustle::string("111111111111111"));Rustle::string&& r1 = Rustle::string("1111111111111111");cout << &r1 << endl;//通过测试,发现右值引用本身属性是左值,那为什么会是左值呢?//因为只有右值引用本身的属性是左值,才能传递参数,转移他的资源return 0;
}观察运行结果,发现右值引用本身可以取地址,说明右值引用本身属性是左值。第一种是传递右值参数,TestRightRef函数用右值引用接受,可以取地址。第二种是直接对右值引用。
这两种方式都会导致右值被引用之后退化成左值。只有右值引用本身的属性是左值的情况下,才可以进行赋值,做函数参数和做函数返回值的操作。

所以说,函数用右值引用接收右值时,右值引用的属性会退化成左值。
当使用push_back函数,插入右值对象时,会调用移动插入函数。在移动插入函数中,右值引用参数x本身属性已经退化成左值。而移动插入函数主要是复用了insert函数完成尾插的操作,虽然重载了右值引用版本的insert函数,但是由于x属性为左值,还是会调用到左值引用版本的insert函数。
这就导致string类调用的是拷贝构造函数。
namespace Rustle
{template<class T>struct ListNode{//...ListNode(const T& data = T())//匿名对象,调用的是默认构造:_next(nullptr),_prev(nullptr),_data(data){}};template<class T>class list{//...public://移动插入void push_back(T&& x){insert(end(), x);}iterator insert(iterator pos, const T& x){Node* cur = pos._node;Node* newnode = new Node(x);Node* prev = cur->_prev;//...return iterator(newnode);}iterator insert(iterator pos, T&& x){Node* cur = pos._node;Node* newnode = new Node(x);Node* prev = cur->_prev;//...return iterator(newnode);}//...};那我们该怎么解决呢?根据右值被引用之后属性退化成左值的问题,每次函数使用右值引用参数接收右值后,如果需要使用右值引用,就必须使用move函数改变右值引用的属性。
那么list容器的push_back函数中需要加上move函数,insert函数中也要加上move函数,ListNode的构造函数也需要提供一个右值引用版本的。
namespace Rustle
{template<class T>struct ListNode{//...ListNode(const T& data = T())//匿名对象,调用的是默认构造:_next(nullptr),_prev(nullptr),_data(data){}ListNode(T&& data)//右值版本:_next(nullptr),_prev(nullptr),_data(move(data)){}};template<class T>class list{//...public://移动插入void push_back(T&& x){insert(end(), move(x));//加上move函数}iterator insert(iterator pos, const T& x){Node* cur = pos._node;Node* newnode = new Node(x);Node* prev = cur->_prev;//...return iterator(newnode);}iterator insert(iterator pos, T&& x){Node* cur = pos._node;Node* newnode = new Node(move(x));//加上move函数Node* prev = cur->_prev;//...return iterator(newnode);}//...};运行结果如下:

6. 完美转发
前面提到右值引用的属性是左值,所以一旦要使用右值引用,需要使用move函数强制转换属性。如list的push_back函数,一层一层传递右值,每一层都要重载左值引用和右值引用两个版本的函数,十分麻烦。有什么办法可以解决呢?那就要介绍C++11引入的新特性——完美转发。
完美转发(Perfect Forwarding)是C++11中引入的一个特性,它允许在函数模板中,将参数连同其类型信息一起不变地传递给其他函数。这意味着,无论是左值引用还是右值引用,都能保持其原有的引用类型,在传递过程中不会意外地变成左值引用。
使用完美转发时,尖括号里面是放变量类型,圆括号是放变量。
std::forward<T>(x)下面的代码就是使用完美转发的效果对比。其中模版中的&&不代表右值引用,而是万能引用,其既能接收左值又能接收右值。模版函数可以接收左值和右值,不过第一个模版函数没有使用完美转发,第二个函数使用了完美转发。
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }template<typename T>
void NonPerfectForward(T&& t)
{Fun(t);
}template<typename T>
void PerfectForward(T&& t)
{//模版实例化是左值引用,保持属性直接传参给Fun//模版实例化是右值引用,右值引用属性会退化成左值,转换成右值属性在传参给FunFun(forward<T>(t));
}void Test1()
{int a; const int b = 8;NonPerfectForward(a); // 左值NonPerfectForward(std::move(a)); // 右值NonPerfectForward(b); // const 左值NonPerfectForward(std::move(b)); // const 右值cout << endl;PerfectForward(a); // 左值PerfectForward(std::move(a)); // 右值PerfectForward(b); // const 左值PerfectForward(std::move(b)); // const 右值
}int main()
{Test1();return 0;
}运行结果如下,第一个模版函数接收右值后,右值引用属性退化成左值,调用的还是左值引用类型的函数。第二个函数使用了完美转发,如果模版实例化是左值引用,保持属性直接传参给Fun,如果实例化后是右值引用,会转换成右值属性在传参给Fun。

总结
经过长篇累牍的讲解,相信大家对右值引用和移动语义的概念有了初步的认识。通过对这些特性的学习,我们可以编写出更加高效和精炼的代码。如果亲自上手敲写上述示例代码,会有更加深刻的理解。
创作不易,希望这篇文章能给你带来启发和帮助,如果喜欢这篇文章,请留下你的三连,你的支持的我最大的动力!!!

相关文章:
C++11:右值引用、移动语义和完美转发
目录 前言 1. 左值引用和右值引用 2. 引用范围 3. 左值引用的缺陷 4. 右值引用的作用 5. 右值引用的深入场景 6. 完美转发 总结 前言 C11作为一次重大的更新,引入了许多革命性的特性,其中之一便是右值引用和移动语义。本文将深入探讨其中引入的…...

【大模型部署及其应用 】RAG检索技术和生成模型的应用程序架构:RAG 使用 Meta AI 的 Llama 3
目录 RAG检索技术和生成模型的应用程序架构1. **基本概念**2. **工作原理**3. **RAG的优势**4. **常见应用场景**5. **RAG的挑战**6. **技术实现**参考RAG 使用 Meta AI 的 Llama 3亲自尝试运行主笔记本与文档应用聊天关键架构组件1. 自定义知识库2. 分块3. 嵌入模型4. 矢量数据…...

python 速成指南
第一节. 过程式 python python 的一个特点是不通过大括号 {} 来划定代码块,而是通过缩进。如果和 C/C++ 类比的话,就是在左括号的地方不要换行,然后用一个冒号 (:) 替代, C/C++ 大括号内部的东西,缩进一个 tab 或者几个空格都可以(但需要保持一致),比如: if (x <…...

多重示例详细说明Eureka原理实践
Eureka原理(Eureka Principle)是指在长时间的思考和积累之后,通过偶然的瞬间获得灵感或发现解决问题的方法的一种认知现象。这个过程通常包括三个主要阶段:准备阶段、潜伏期以及突然的灵感爆发。下面详细说明Eureka原理的实践步骤…...

Qt下让程序只运行一个实例,避免重复打开
参考 【实现QT单例程序 QSystemSemaphore QSharedMemory】 做了一点点更改,主要是在openEuler上用时遇到的一点问题。 QSharedMemory *unimem nullptr; void checkExist() {QString memName "SingleApp"; // 注意这名字要每个工程不一样,否…...

考研交流平台设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图详细视频演示技术栈系统测试为什么选择我官方认证玩家,服务很多代码文档,百分百好评,战绩可查!!入职于互联网大厂,可以交流,共同进步。有保障的售后 代码参考数据库参…...

哈希表--有效的字母异位词
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。 注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。 示例 1: 输入: s "anagram", t "nagaram" 输出: true示例 2: 输…...
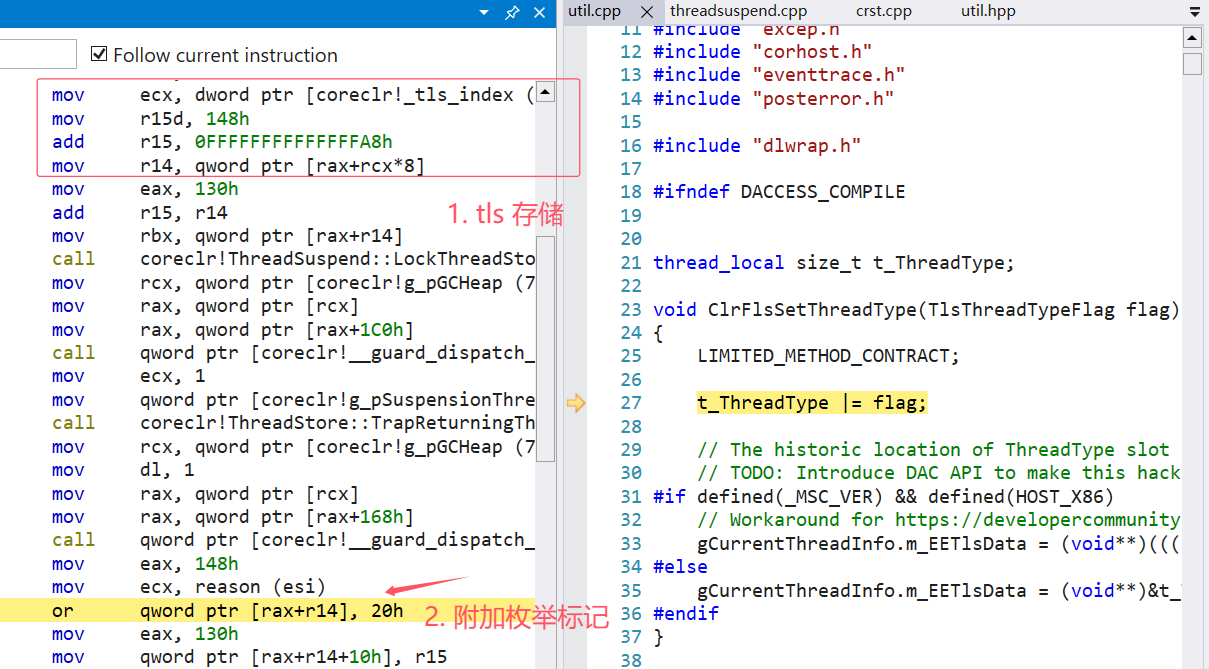
GC终结标记 SuspendEE 是怎么回事
一:背景 1. 讲故事 写这篇是起源于训练营里有位朋友提到了一个问题,在 !t -special 输出中有一个 SuspendEE 字样,这个字样在 coreclr 中怎么弄的?输出如下: 0:000> !t -special ThreadCount: 3 UnstartedTh…...

Ubuntu 中GCC交叉编译工具链安装
Ubuntu 自带的 gcc 编译器是针对 X86 架构的,如果要编译的是 ARM 架构的代码,就需要一个在 X86 架构的 PC 上运行,可以编译 ARM 架 构代码的 GCC 编译器,这个编译器就叫做交叉编译器,总结一下交叉编译器就是&#x…...
用法概览)
JEXL(Java Expression Language)用法概览
JEXL(Java Expression Language)是一个用于在Java应用程序中解析和执行表达式的库。JEXL的设计目的是通过提供一种类似于脚本语言的语法,使得可以在应用程序中动态地计算表达式的值。JEXL常用于模板引擎、规则引擎和配置文件等场景。 下面介…...

NC 完全二叉树结点数
系列文章目录 文章目录 系列文章目录前言 前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男女通用,看懂了就去分享给你的码吧。 描述 给定一棵完全…...

点灯案例优化(二) 利用位运算修改特定位
前面,我们对点灯代码进行了第一次优化,效果如下 尽管第一次优化以后代码可读性确实高了不少,也看起来更加简洁,但是,这里仍旧存在一个很严重的问题:就在每一个表达式右边,我们给寄存器的数据赋值…...

【C++备忘录】
记录一些C比较好用的代码块,方便自个查看。 使用std::copy 快速打印序列 #include <iostream> #include <algorithm> #include <iterator>int main() {int a[5] { 1, 2, 3, 4, 5 };copy(begin(a), end(a), ostream_iterator<int>(cout, …...

java编程 斐波拉契数列算法集锦【斐波拉契数列】【下】【集合类】【Stream函数式编程】
斐波那契数列(Fibonacci sequence),又称黄金分割数列,是一个非常经典的递归问题。斐波那契数列的算法描述: 斐波那契数列,一个令人着迷而又充满神秘色彩的数字序列,它以0和1作为起始ÿ…...

智慧园区三维可视化平台
背景 随着物联网、人工智能等新一代信息技术的发展,数字孪生技术逐渐成为实现这一目标的关键工具。数字孪生技术能够对物理世界进行高精度、全要素的映射,并实时动态反映其变化情况,从而为园区提供精准的管理和服务。 方案简介 智慧园区数字…...

Redis 有序集合【实现排行榜】
使用 Redis 的 Sorted Set 数据结构可以非常高效地实现实时排行榜功能。Sorted Set 允许将元素按分数进行排序,同时支持插入、删除和查询操作,且这些操作的时间复杂度较低,非常适合处理高并发的场景。 实现思路 插入操作:当用户…...

ORACLE数据库管理系统介绍
1.ORACLE的特点: 可移植性 ORACLE采用C语言开发而成,故产品与硬件和操作系统具有很强的独立性。从大型机到微机上都可运行ORACLE的产品。可在UNIX、DOS、Windows等操作系统上运行。可兼容性 由于采用了国际标准的数据查询语言SQL,与IBM的SQL/DS、DB2等均兼容。并提供读取其它…...

C# 中Linq探讨 Or条件拼接
在C#中,没有直接内置于.NET Core或.NET Framework中的NuGet包能够直接“拼接”LINQ的OR条件,因为LINQ本身设计为一种声明式编程模型,用于查询数据集合。然而,你可以通过一些方式来实现多个条件以OR逻辑组合的效果,而不…...

有关应用层面试题有关库的思维导体
面试题目: TCP通信中3次握手和四次挥手? 答: 第一次握手:客户端发送SYN包(SYN1, seq0)给服务器,并进入SYN_SENT状态,等待服务器返回确认包。第二次握手:服务器接收到S…...

记一次 SAP BP 编号范围错误引发的一个问题 GET_NRIV_LINE
本来想着循着错误提示去排查,但是还是想看看业务发生了什么,他们的操作是否有问题,不经意间发现 号码段是有问题的,由此大概可以判断是他们编号范围和类型之间的问题 角色和分组是否一致的,如果不一致就发生了以上错误…...

G-Helper终极教程:华硕笔记本轻量级性能控制神器
G-Helper终极教程:华硕笔记本轻量级性能控制神器 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expertb…...

终极Photoshop图层批量导出指南:如何用免费脚本提升10倍工作效率
终极Photoshop图层批量导出指南:如何用免费脚本提升10倍工作效率 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Adobe. 项目…...
)
MongoDB 4.4+ 版本后,手把手教你搞定mongodump独立安装与配置(附环境变量设置)
MongoDB 4.4独立工具链部署指南:从零构建mongodump备份环境 当你在全新的Linux服务器上部署了MongoDB 4.4或更新版本,准备执行例行数据库备份时,在终端输入熟悉的mongodump命令却只得到command not found的响应——这不是你的操作失误&#…...

Steam-Economy-Enhancer多货币支持:全球交易定价策略
Steam-Economy-Enhancer多货币支持:全球交易定价策略 【免费下载链接】Steam-Economy-Enhancer Enhances the Steam Inventory and Steam Market. 项目地址: https://gitcode.com/gh_mirrors/st/Steam-Economy-Enhancer Steam-Economy-Enhancer是一款强大的S…...

书匠策AI毕业论文功能全拆解:一个教论文写作的博主,居然被它种草了
你还在对着空白文档发呆?这个AI工具让我"真香"了 各位同学,我是你们的论文写作科普博主。 说句大实话,这几年我教过上千个学生怎么写毕业论文,从选题到开题、从大纲到终稿,每个环节我都能给你掰碎了讲。但…...

iOS 27 开放 AI 生态@ACP#小型化扩展黄金风口,IX8008全面超越 ASM2806,铸就嵌入式 AI 扩展核心
苹果 iOS 27 系统全面开放第三方 AI 模型自由切换,支持 Claude、Gemini、DeepSeek 等主流大模型深度接入,iPhone/iPad 成为全球最大 AI 流量入口。这一变革引爆小型 AI 扩展坞、嵌入式 AI 终端、便携存储扩展、迷你主机、车载 AI五大硬件新机遇。作为连接…...

WinUtil:Windows系统优化与软件管理的终极免费解决方案
WinUtil:Windows系统优化与软件管理的终极免费解决方案 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 还在为Windows系统优化和软…...

如何用C++优雅地读写Excel文件?xlnt库的完整实用指南
如何用C优雅地读写Excel文件?xlnt库的完整实用指南 【免费下载链接】xlnt :bar_chart: Cross-platform user-friendly xlsx library for C11 项目地址: https://gitcode.com/gh_mirrors/xl/xlnt 还在为C项目中的Excel文件处理而烦恼吗?ǹ…...

GitHub中文界面极速解锁指南:5分钟告别英文困扰的终极方案
GitHub中文界面极速解锁指南:5分钟告别英文困扰的终极方案 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 你是否曾经面对…...

别再乱删注册表了!Windows 10/11 下 MySQL 8.0.32 保姆级卸载与重装避坑指南
MySQL 8.0 深度清理与重装实战手册:从根源解决安装冲突问题 当你在Windows系统上反复安装MySQL时,是否遇到过这些令人抓狂的提示?"Service already exists"、"Port 3306 already in use"或是安装程序莫名其妙回滚。这些问…...