机器学习:逻辑回归处理手写数字的识别
1、获取数据, 图像分割该数据有50行100列,每个数字占据20*20个像素点,可以进行切分,划分出训练集和测试集。

import numpy as np
import pandas as pd
import cv2
img=cv2.imread("digits.png")#读取文件
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#变成灰度图
#切分数据
x=np.array([np.hsplit(i,100) for i in np.vsplit(gray,50)])
train=x[:,:50]
test=x[:,50:100]2、每个数据的像素点为20*20,将其全部变成一列1*400格式,转换成数值特征

train_new=train.reshape(-1,400).astype(np.float32)
test_new=test.reshape(-1,400).astype(np.float32)3、总共有2500行特征对应着2500个标签,从0到9每个数字有250个
k=np.arange(10)
train_labels=np.repeat(k,250)[:,np.newaxis].ravel()
test_labels=np.repeat(k,250)[:,np.newaxis].ravel()4、导入逻辑回归库,采用交叉验证的方法找到最佳C值
#导入逻辑回归和交叉验证库
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
scores=[]
# 设置C的值进行交叉验证,找到最佳C
c_param_range=[0.01,0.1,1,10,100]
for i in c_param_range:lr = LogisticRegression(C=i, penalty='l2', solver='lbfgs', max_iter=10000)score = cross_val_score(lr, train_new, train_labels, cv=10, scoring='recall_macro')score_mean = sum(score) / len(score)scores.append(score_mean)
# 选择使得平均分数最高的C值
best_c = c_param_range[np.argmax(scores)]
lr = LogisticRegression(C=best_c, penalty='l2', max_iter=10000)
#使用最佳C值初始化逻辑回归模型并训练
lr.fit(train_new, train_labels)5、使用训练好的模型对测试集进行预测
from sklearn import metrics
train_predicted=lr.predict(test_new)
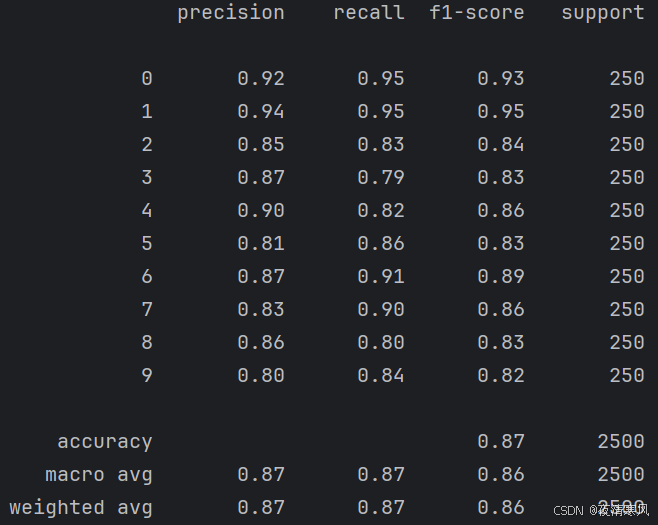
print(metrics.classification_report(test_labels,train_predicted))6、打印的分类报告
7、读取手写数字图像,并进行预测
p1=cv2.imread("p1.png")
gray_p1=cv2.cvtColor(p1,cv2.COLOR_BGR2GRAY)
tess=np.array(gray_p1)
tess_new=tess.reshape(-1,400).astype(np.float32)
# 使用训练好的模型进行预测
predicted_shouxie=lr.predict(tess_new)
print(predicted_shouxie)8、书写预测结果

完整代码
import numpy as np
import pandas as pd
import cv2
img=cv2.imread("digits.png")#读取文件
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#变成灰度图
#切分数据
x=np.array([np.hsplit(i,100) for i in np.vsplit(gray,50)])
train=x[:,:50]
test=x[:,50:100]
train_new=train.reshape(-1,400).astype(np.float32)
test_new=test.reshape(-1,400).astype(np.float32)
k=np.arange(10)
train_labels=np.repeat(k,250)[:,np.newaxis].ravel()
test_labels=np.repeat(k,250)[:,np.newaxis].ravel()#导入逻辑回归和交叉验证库
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
scores=[]
# 设置C的值进行交叉验证,找到最佳C
c_param_range=[0.01,0.1,1,10,100]
for i in c_param_range:lr = LogisticRegression(C=i, penalty='l2', solver='lbfgs', max_iter=10000)score = cross_val_score(lr, train_new, train_labels, cv=10, scoring='recall_macro')score_mean = sum(score) / len(score)scores.append(score_mean)
# 选择使得平均分数最高的C值
best_c = c_param_range[np.argmax(scores)]
lr = LogisticRegression(C=best_c, penalty='l2', max_iter=10000)
lr.fit(train_new, train_labels)
#使用最佳C值初始化逻辑回归模型并训练
from sklearn import metrics
train_predicted=lr.predict(test_new)
print(metrics.classification_report(test_labels,train_predicted))
# 读取新的手写数字图像,并进行预测
p1=cv2.imread("p1.png")
gray_p1=cv2.cvtColor(p1,cv2.COLOR_BGR2GRAY)
tess=np.array(gray_p1)
tess_new=tess.reshape(-1,400).astype(np.float32)
# 使用训练好的模型进行预测
predicted_shouxie=lr.predict(tess_new)
print(predicted_shouxie)相关文章:
机器学习:逻辑回归处理手写数字的识别
1、获取数据, 图像分割该数据有50行100列,每个数字占据20*20个像素点,可以进行切分,划分出训练集和测试集。 import numpy as np import pandas as pd import cv2 imgcv2.imread("digits.png")#读取文件 graycv2.cvtColor(img,cv2.COLOR_BGR2G…...

文件上传真hard
一、SpringMVC实现文件上传 1.1.项目结构 1.1.2 控制器方法 RequestMapping("/upload1.do")public ModelAndView upload1(RequestParam("file1") MultipartFile f1) throws IOException {//获取文件名称String originalFilename f1.getOriginalFilename(…...

精益管理|介绍一本专门研究防错法(Poka-Yoke)的书
在现代制造业中,如何确保产品在每个生产环节中不出现错误是企业追求的目标之一。而实现这一目标的关键技术之一就是防错法(Poka-Yoke)。作为一种简单而有效的精益管理、六西格玛管理工具,防错法帮助企业避免因人为错误或工艺不当导…...

面试题目:(4)给表达式添加运算符
目录 题目 代码 思路解析 例子 题目 题目 给定一个仅包含数字 0-9 的字符串 num 和一个目标值整数 target ,在 num 的数字之间添加 二元 运算符(不是一元)、- 或 * ,返回 所有能够得到 target 的表达式。1 < num.length &…...

[C#]将opencvsharp的Mat对象转成onnxruntime的inputtensor的3种方法
第一种方法:在创建tensor时候直接赋值改变每个tensor的值,以下是伪代码: var image new Mat(image_path);inpWidth image.Width;inpHeight image.Height;//将图片转为RGB通道Mat image_rgb new Mat();Cv2.CvtColor(image, image_rgb, Col…...

CTF入门教程(非常详细)从零基础入门到竞赛,看这一篇就够了!
一、CTF简介 CTF(Capture The Flag)中文一般译作夺旗赛,在网络安全领域中指的是网络安全技术人员之间进行技术竞技的一种比赛形式。CTF起源于1996年DEFCON全球黑客大会,以代替之前黑客们通过互相发起真实攻击进行技术比拼的方式。…...

数据链路层 I(组帧、差错控制)【★★★★★】
(★★)代表非常重要的知识点,(★)代表重要的知识点。 为了把主要精力放在点对点信道的数据链路层协议上,可以采用下图(a)所示的三层模型。在这种三层模型中,不管在哪一段…...

悟空降世 撼动全球
文|琥珀食酒社 作者 | 积溪 一只猴子能值多少钱? 答案是:13个小目标 这两天 只要你家没有断网 一定会被这只猴子刷屏 它就是咱国产的3A游戏 《黑神话:悟空》 这只猴子到底有多火? 这么跟你说吧 茅台见了它都…...

Swoole 和 Java 哪个更有优势呢
Swoole 和 Java 各有优势,在性能上不能简单地说哪一个更好,需要根据具体的应用场景来分析。 Swoole 优势:高并发:Swoole 是一个基于 PHP 的异步、协程框架,专为高并发场景设计,适用于 I/O 密集型应用&…...
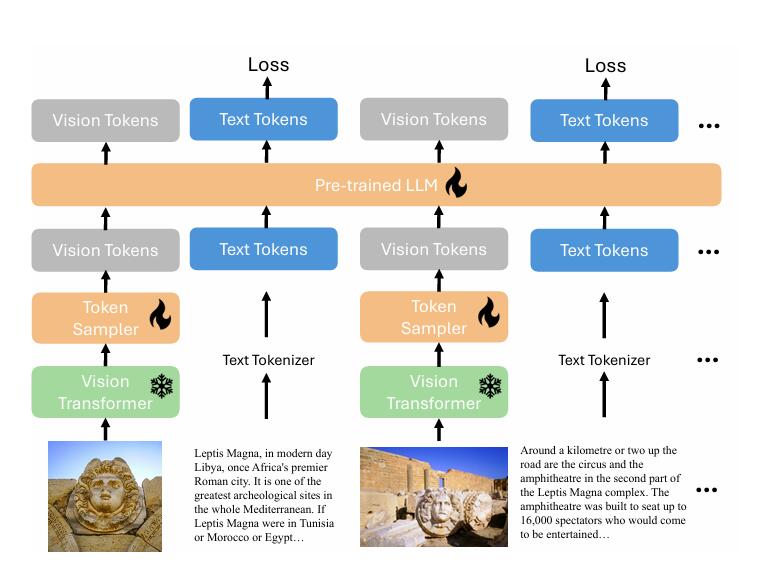
Salesforce 发布开源大模型 xGen-MM
xGen-MM 论文 在当今 AI 技术飞速发展的时代,一个新的多模态 AI 模型悄然崛起,引起了业界的广泛关注。这个由 Salesforce 推出的开源模型—— xGen-MM,正以其惊人的全能特性和独特优势,在 AI 领域掀起一阵旋风。那么,x…...

冒 泡 排 序
今天咱们单独拎出一小节来聊一聊冒泡排序昂 冒泡排序的核心思想就是:两两相邻的元素进行比较(理解思路诸君可看下图) 接下来我们上代码演示: 以上就是我们初步完成的冒泡排序,大家不难发现,不管数组中的元…...

采用先进的人工智能视觉分析技术,能够精确识别和分析,提供科学、精准的数据支持的智慧物流开源了。
智慧物流视频监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本可通过边缘计算技术…...

IAA游戏APP如何让合理地让用户观看更多广告,提高广告渗透率
广告变现已经成为休闲游戏开发者重要的收益方式之一,超50%国内休闲游戏已经采用广告变现的方式,游戏广告预算是游戏行业开发者广告变现的主要预算来源。 #深度好文计划#如何合理地提高广告渗透率? 广告渗透率能直接反映游戏中有广告行为用户…...

环网交换机的特殊作用是什么?
环网交换机作为现代网络建设的重要组成部分,具有独特而特殊的作用。在信息技术迅猛发展的今天,各类数据传输和网络连接需求日益增加,环网交换机的出现为解决这些问题提供了理想的方案。环网交换机通常将多个网络节点通过环形结构连接起来&…...

mac电脑安装Zsh并启用
安装 Zsh 1. 安装 Zsh 新版mac系统会默认安装并使用zsh,如没用,需在终端中安装: brew install zsh2. 安装 Oh My Zsh 克隆Oh My Zsh到你的目录: git clone https://github.com/robbyrussell/oh-my-zsh.git ~/.oh-my-zsh3. 复…...

【后续更新】python搜集上海二手房数据
源码如下: import asyncio import aiohttp from lxml import etree import logging import datetime import openpyxlwb = openpyxl.Workbook() sheet = wb.active sheet.append([房源, 房子信息, 所在区域, 单价, 关注人数和发布时间, 标签]) logging.basicConfig(level=log…...
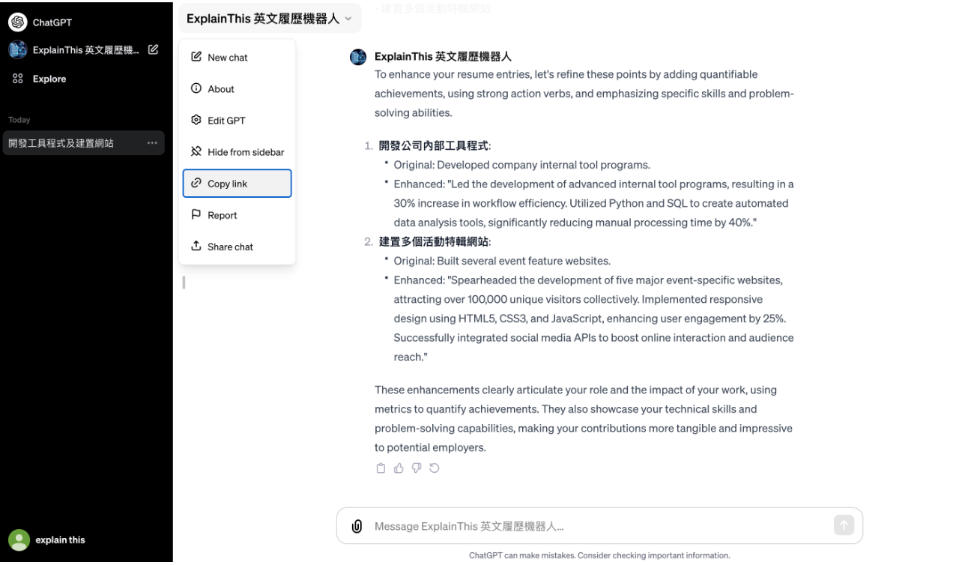
创建GPTs,打造你的专属AI聊天机器人
在2023年11月的「OpenAI Devday」大会上,OpenAI再度带来了一系列令人瞩目的新功能,其中ChatGPT方面的突破尤为引人关注。而GPTs的亮相,不仅标志着个性化AI时代的到来,更为开发者和普通用户提供了前所未有的便利。接下来࿰…...
)
深度学习 vector 之模拟实现 vector (C++)
1. 基础框架 这里我们有三个私有变量,使用 _finish - _start 代表 _size,_end_of_storage - _start 代表 _capacity,并且使用到了模版,可以灵活定义存储不同类型的 vector,这里将代码量较小的函数直接定义在类的内部使…...

关于LLC知识10
在LLC谐振腔中能够变化的量 1、输入电压 2、Rac(负载) 所以增益曲线为红色(Rac无穷大)已经是工作的最大极限了,LLC不可能工作在红色曲线之外 负载越重时,增益曲线越往里面 假设: 输入电压…...

最长的严格递增或递减子数组
给你一个整数数组 nums 。 返回数组 nums 中 严格递增 或 严格递减 的最长非空子数组的长度。 示例 1: 输入:nums [1,4,3,3,2] 输出:2 解释: nums 中严格递增的子数组有[1]、[2]、[3]、[3]、[4] 以及 [1,4] 。 nums 中…...

企业如何保护内部数据安全,防止信息泄密?
很多企业一提数据防泄密,第一反应就是上 DLP、上加密、上审计。但真正做过项目的人都知道,事情没这么简单。数据泄露大多数时候不是发生在机房,也不是因为多高级的攻击,而是发生在员工每天最普通的操作里。客户资料发错了…...

EVPN实战解析:分布式网关部署与关键配置精要
1. 为什么需要EVPN分布式网关? 在多租户数据中心网络环境中,虚拟机迁移和三层互通是刚需。传统集中式网关就像只有一个出入口的大型停车场,所有车辆必须绕道中央区域才能到达目的地,而分布式网关则相当于在每个楼层都设置了出入口…...

AI Agents 越智能,企业的人类判断力需求反而会爆炸式增长:Jevons 悖论在企业落地中的隐形反弹
在企业全面拥抱 AI Agents 的当下,最容易被忽略的不是模型能力,而是“智能变便宜”之后带来的责任边界扩张。产品团队让 Agent 自动起草客户邮件、更新工单、标记流失风险、总结销售通话、推荐代码变更、升级支持问题、准备决策材料——每一步都变得前所…...

涿州靠谱软体沙发家具城,为你打造舒适家居的理想之选!
在涿州,选择一家靠谱的软体沙发家具城至关重要,它不仅关系到家居的舒适度,还影响着生活品质。今天就为大家推荐涿州市雅木轩家具店(简称:旭日家具),并将它与其他大厂进行对比,让你更…...

从0到4倍:一次产品冷启动的完整复盘
近期终于有了大块的时间,打算把自己做开发者关系的一些经历都梳理出来。背景:我们做了一个类似 Windows 注册表的配置管理模块,并在上面增加了配置叠加和分层权限管控。它的核心价值是这样的:之前之后系统集成团队想改某个应用的行…...

Python异步编程中的上下文管理:Ctxo工具的设计原理与实战应用
1. 项目概述:一个轻量级、高可用的上下文管理工具最近在折腾一个需要处理大量异步任务和复杂状态流转的后台服务,遇到了一个老生常谈但又很棘手的问题:如何在不同的函数调用、异步协程之间,安全、高效地传递和共享一些“上下文”信…...

树莓派Pico W到手后,除了Wi-Fi,这几点硬件细节和Pico真不一样
树莓派Pico W硬件深度解析:超越Wi-Fi的工程细节 当我第一次拿到树莓派Pico W时,表面看起来它只是Pico的无线版本——同样的RP2040芯片、相似的引脚布局和几乎一致的尺寸。但当我开始实际项目开发时,才发现这些"看似相同"背后隐藏着…...

AI驱动编辑预设生成:从风格迁移到创意工作流的自动化实践
1. 项目概述:AI驱动的编辑预设库最近在折腾视频和图片后期,发现一个挺有意思的项目,叫kaushalrao/ai-editor-presets。这名字听起来有点技术范儿,但说白了,它就是一个用人工智能技术来生成和优化各类编辑软件预设文件的…...

Rust构建的轻量级文件搜索工具fltr:高性能文本检索新选择
1. 项目概述:一个轻量级、高性能的本地文件搜索工具在开发或日常文件管理工作中,我们常常面临一个看似简单却极其恼人的问题:如何在成千上万的文件中,快速、精准地找到包含特定关键词或符合特定模式的那一个?无论是定位…...

低延时RS译码器优化设计【附代码】
✨ 长期致力于RS码、低延时、功耗优化、译码器研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)改进型RiBM迭代展开算法加速关键方程求解: …...