MySQL第三次作业
1、显示所有职工的基本信息。
2、查询所有职工所属部门的部门号,不显示重复的部门号。
3、求出所有职工的人数。
4、列出最高工和最低工资。
5、列出职工的平均工资和总工资。
6、创建一个只有职工号、姓名和参加工作的新表,名为工作日期表。
7、显示所有女职工的年龄。
8、列出所有姓刘的职工的职工号、姓名和出生日期。
9、列出1960年以前出生的职工的姓名、参加工作日期。
10、列出工资在1000-2000之间的所有职工姓名。
11、列出所有陈姓和李姓的职工姓名。
12、列出所有部门号为2和3的职工号、姓名、党员否。
13、将职工表worker中的职工按出生的先后顺序排序。
14、显示工资最高的前3名职工的职工号和姓名。
15、求出各部门党员的人数。
16、统计各部门的工资和平均工资
17、列出总人数大于4的部门号和总人数。
CREATE TABLE `worker` (
`部门号` int(11) NOT NULL,
`职工号` int(11) NOT NULL,
`工作时间` date NOT NULL,
`工资` float(8,2) NOT NULL,
`政治面貌` varchar(10) NOT NULL DEFAULT '群众',
`姓名` varchar(20) NOT NULL,
`出生日期` date NOT NULL,
PRIMARY KEY (`职工号`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (101, 1001, '2015-5-4', 3500.00, '群众', '张三', '1990-7-1');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (101, 1002, '2017-2-6', 3200.00, '团员', '李四', '1997-2-8');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (102, 1003, '2011-1-4', 8500.00, '党员', '王亮', '1983-6-8');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (102, 1004, '2016-10-10', 5500.00, '群众', '赵六', '1994-9-5');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (102, 1005, '2014-4-1', 4800.00, '党员', '钱七', '1992-12-30');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (102, 1006, '2017-5-5', 4500.00, '党员', '孙八', '1996-9-2');
1、显示所有职工的基本信息。
select * from worker;
2、查询所有职工所属部门的部门号,不显示重复的部门号。
select distinct `部门号` from worker;
3、求出所有职工的人数。
select count(`姓名`) from worker;
4、列出最高工和最低工资。
# 最高 降序排序 取第一个
select `工资` from worker order by `工资` desc limit 0,1;
# 最低 升序排序 取第一个
select `工资` from worker order by `工资` asc limit 0,1;
5、列出职工的平均工资和总工资。
# 平均工资
select avg(`工资`) from worker;
# 总工资
select sum(`工资`) from worker;
select avg(`工资`) 平均工资,sum(`工资`) 总工资 from worker;
6、创建一个只有职工号、姓名和参加工作的新表,名为工作日期表。
create table `工作日期` (
`职工号` int(11) NOT NULL,
`姓名` varchar(20) NOT NULL,
`工作时间` date NOT NULL,
PRIMARY KEY (`职工号`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
7、列出1960年以前出生的职工的姓名、参加工作日期。
# datediff()用于计算两个日期之间的天数
-- datediff函数,返回值是相差的天数,不能定位到小时、分钟和秒
SELECT datediff(now(),`出生日期` ) as age FROM worker;
# TIMESTAMPDIFF函数,有参数设置,可以精确到天(DAY)、小时(HOUR),分钟(MINUTE)和秒(SECOND)
-- 使用起来比datediff函数更加灵活。对于比较的两个时间,时间小的放在前面,时间大的放在后面。
SELECT TIMESTAMPDIFF(year,`出生日期`,NOW()) as age FROM worker;
8、列出工资在1000-2000之间的所有职工姓名。
select `姓名` from worker where `工资` between 3000 and 5000;
select `姓名`,`工资` from worker where `工资` between 3000 and 5000;
9、列出所有陈姓和李姓的职工姓名。
select `姓名` from worker where (`姓名` like'陈%') or (`姓名` like'李%');
10、列出所有部门号为2和3的职工号、姓名、党员否。
select * from worker where find_in_set('党员',政治面貌);
select * from worker where locate('党员',政治面貌);
# locate() 查找某个字段里面是否有某个某个字符串 是(1)否(0)
select `职工号`,`姓名`,(locate('党员',政治面貌)) as `是(1)否(0)党员` from worker where `部门号`=102 or `部门号`=103;
11、将职工表worker中的职工按出生的先后顺序排序。
select * FROM worker ORDER BY `出生日期`;
12、显示工资最高的前3名职工的职工号和姓名。
select `职工号`,`姓名` from worker ORDER BY `工资` desc limit 0,3;
13、求出各部门党员的人数。
SELECT `部门号` from worker WHERE `政治面貌`='党员';
select `部门号`,count(`部门号`) from worker GROUP BY `部门号`;
# locate() 查找某个字段里面是否有某个某个字符串 是(1)否(0
select `部门号`,sum(locate('党员',政治面貌)) 党员数 from worker GROUP BY `部门号`;
14、统计各部门的工资和平均工资
select `部门号`,sum(工资) 总工资,avg(工资) 平均工资 from worker GROUP BY `部门号`;
15、列出总人数大于4的部门号和总人数。
select `部门号`,count(姓名) 总人数 from worker GROUP BY `部门号` HAVING count(姓名) >2 ;
select `部门号`,count(姓名) 总人数 from worker GROUP BY `部门号` HAVING count(姓名) >4 ;
相关文章:

MySQL第三次作业
1、显示所有职工的基本信息。 2、查询所有职工所属部门的部门号,不显示重复的部门号。 3、求出所有职工的人数。 4、列出最高工和最低工资。 5、列出职工的平均工资和总工资。 6、创建一个只有职工号、姓名和参加工作的新表,名为工作日期表…...
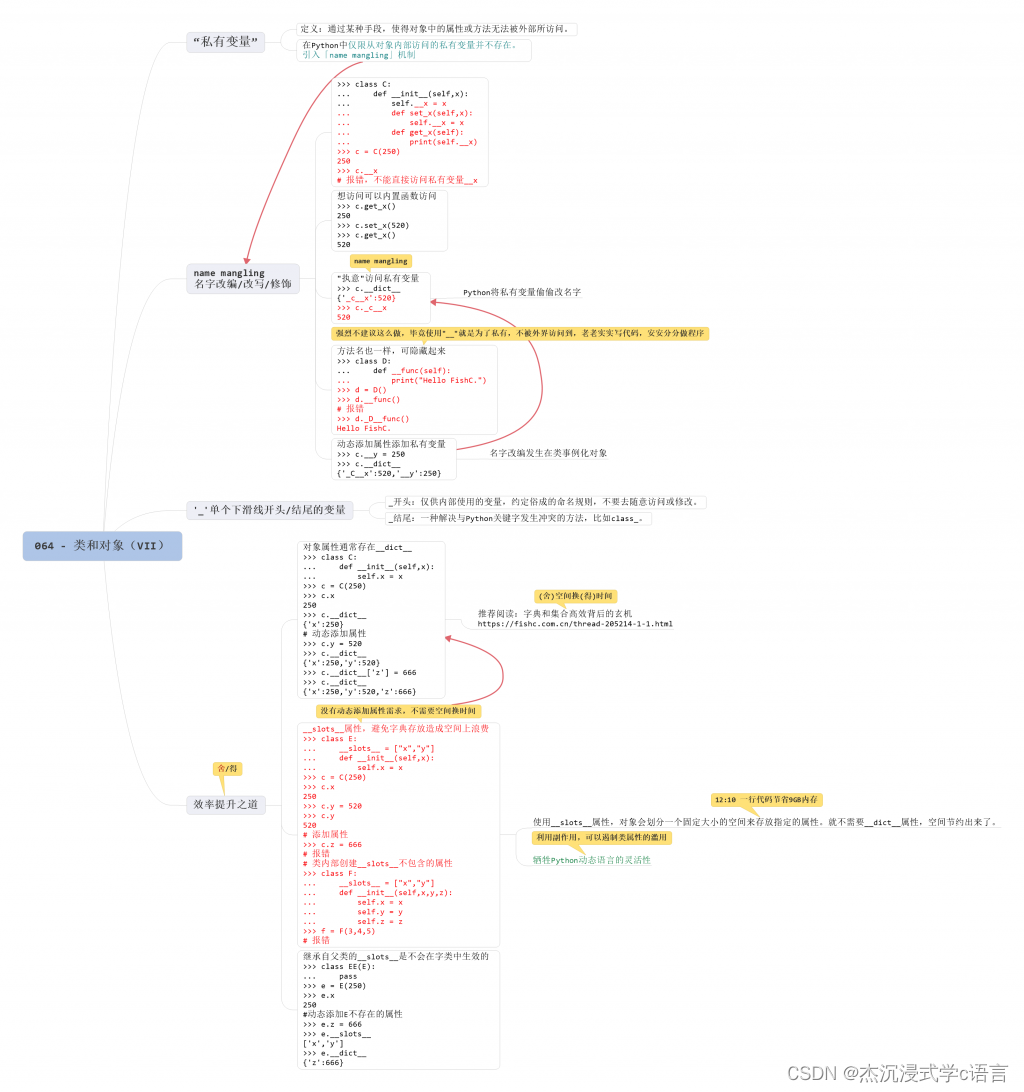
Python中的类和对象(7)
1.私有变量 在大多数面向对象的编程语言中,都存在着私有变量(private variable)的概念,所谓私有变量,就是指通过某种手段,使得对象中的属性或方法无法被外部所访问。 Python 对于私有变量的实现是引入了一…...
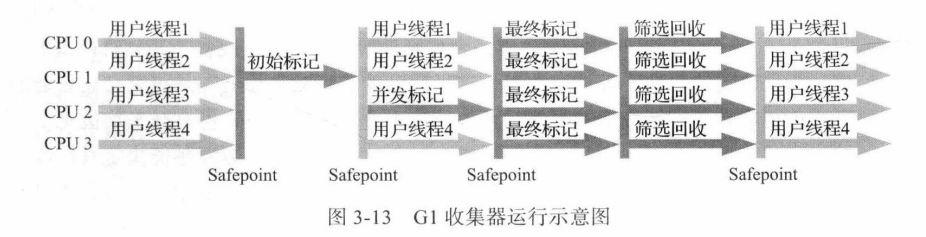
【JVM】7种经典的垃圾收集器
文章目录1. 垃圾收集器概述2. Serial 收集器3. ParNew 收集器4. Paraller Scavenge 收集器5. Serial Old收集器6. Parller Old收集器7. CMS 收集器8. Garbage First 收集器本文参考:深入理解Java虚拟机:JVM高级特性与最佳实践(第3版ÿ…...

2023/2/12总结
滑动窗口(1)滑动窗口是一种基于双指针的思想,两个指针指向的元素形成一个窗口。一般用于求取数组或字符串的某个子串、子序列、最长最短等最值或者求某个目标值时,并且该问题本身可以通过暴力解决。滑动窗口分为固定窗口和不定窗口…...

Linux之正则表达式
正则表达式是组成“操作”的基本语法,而这些“操作”是应用于Sed和Awk必备的能力。因此只有了解了正则表达式,才能学好Sed和Awk。正则表达式分为基础正则表达式(Regular Expression)与扩展正则表达式(Extended Regular…...
)
前端高频面试题-HTML和CSS篇(一)
💻 前端高频面试题-HTML和CSS篇(一) 🏠专栏:前端面试题 👀个人主页:繁星学编程🍁 🧑个人简介:一个不断提高自我的平凡人🚀 🔊分享方向…...

Redis 专题总结
1. 什么是Redis ? 处理:内容缓存,主要用于处理大量数据的高访问负载。Redis是一款高性能的NOSQL系列的非关系型数据库,NoSQL(NoSQL Not Only SQL),意即“不仅仅是SQL”,是一项全新的数据库理念࿰…...

【Python百日进阶-Web开发-Vue3】Day515 - Vue+ts后台项目2:登录页面
文章目录 一、创建登录路由1.1 安装 Vue VSCode Snippets插件1.2 处理路径引用的红色波浪线1.3 入口文件 main.ts1.4 主组件 App.vue1.5 路由文件 router/index.ts1.6 首页组件 views/HomeView.vue1.7 登录组件 views/LoginView.vue二、实现登录页面的表单展示2.1 element-plus…...

【博客620】prometheus如何优化远程读写的性能
prometheus如何优化远程读写的性能 场景 为了解决prometheus本地存储带来的单点问题,我们一般在高可用监控架构中会使用远程存储,并通过配置prometheus的remote_write和remote_read来对接 远程写优化:remote_write 远程写的原理:…...

redis可视工具AnotherRedisDesktopManager的使用
redis可视工具AnotherRedisDesktopManager的使用 简介 Another Redis DeskTop Manager 是一个开源项目,提供了以可视化的方式管理 Redis 的功能,可供免费下载安装,也可以在此基础上进行二次开发,主要特点有: 支持 W…...

【idea】idea生产类注释和方法注释
网上有很多类似的文章,但是我在按照他们的文章设置后,出现了一些问题,因此我这边在解决了问题后,总结一篇文章,发出来给大家借鉴一下。在此先说明一下idea的版本,是2020.1.3 设置动态模板,File…...

jenkins +docker+python接口自动化之jenkins容器安装python3(二)
jenkins dockerpython接口自动化之jenkins容器安装python3(二) 目录:导读 前提是在docker下已经配置好jenkins容器了,是将python安装在jenkins容器下的 1、先看你的jenkins是否安装好 2、以root权限进入jenkins容器࿱…...
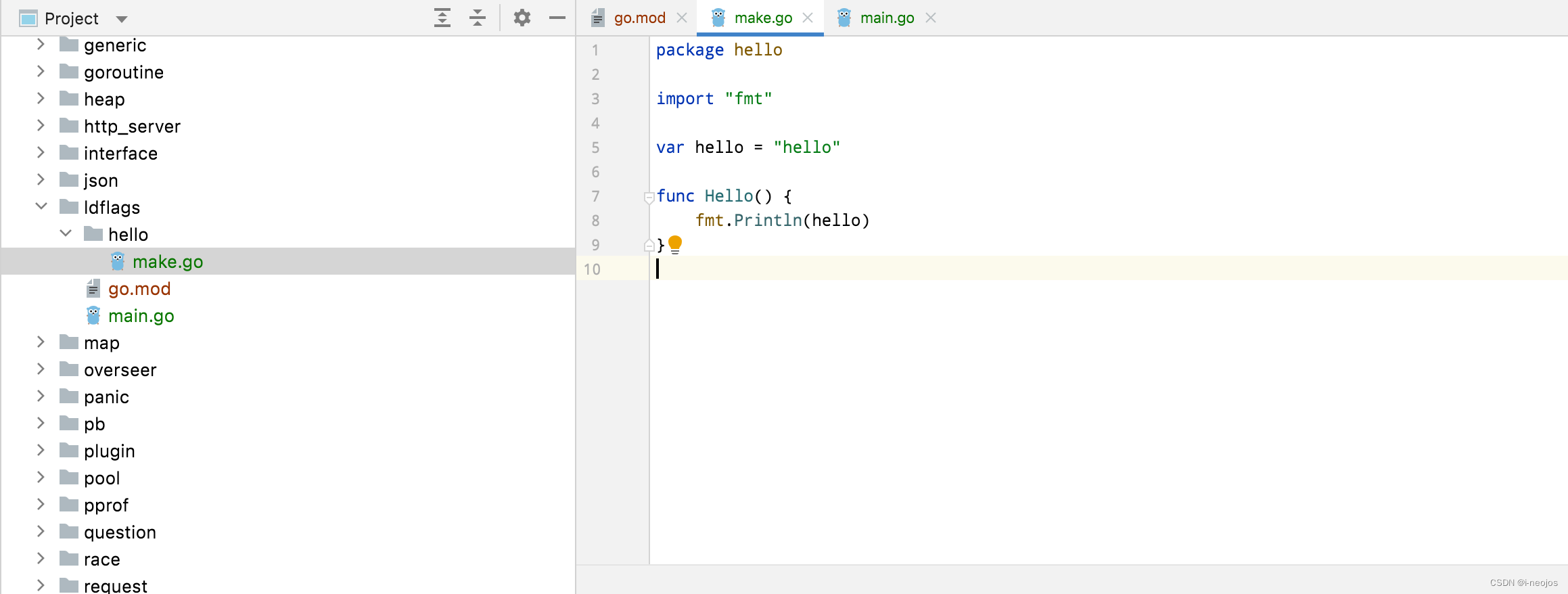
go 命令行工具整理
这里会整理可能会使用到的命令行参数,比如 go build、go run,诸如此类。了解这些内容对我们工作会有什么帮助吗?更多的时候,是能让我们理解代码编译的意图,或者,给我们一种排查问题的手段。 比方说&#x…...
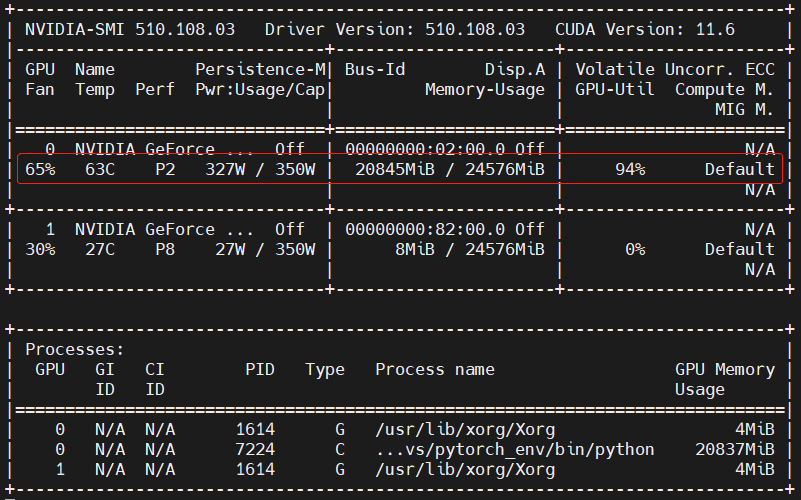
RuntimeError: CUDA out of memory
今天在训练模型的时候突然报了显存不够的问题,然后分析了一下,找到了解决的办法,这里记录一下,方便以后查阅。 注:以下的解决方案是在模型测试而不是模型训练时出现这个报错的! RuntimeError: CUDA out of…...

Kubernetes1.25中Redis集群部署实例
1、概述我们知道在 Kubernetes 容器编排平台中, 我们可以非常方便的进行应用的扩容缩, 同时也能非常方便的进行业务的迭代,本章主要讲解在Kubernetes1.25搭建Redis单实例和Redis集群主从同步的环境流程步骤, 如果是高频访问重要的线上业务我们最好是部署在物理机器上…...
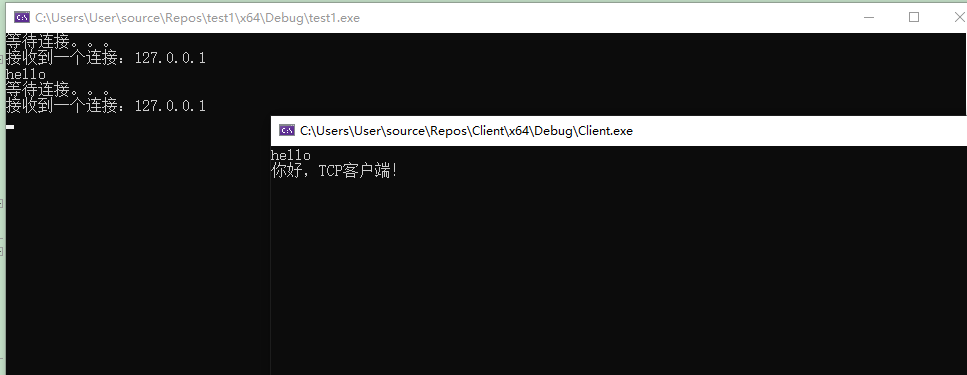
C++11实现计算机网络中的TCP/IP连接(Windows端)
目录引言1、TCP2、IP2.1 IP路由器3、TCP/IP4、TCP/IP协议C11实现参考文献引言 TCP/IP 指传输控制协议/网际协议(Transmission Control Protocol / Internet Protocol)。[1] 在TCP/IP协议簇中主要包含以下内容: TCP (传输控制协议) - 应用程序…...

Spring框架自定义实现IOC基础功能/IDEA如何手动实现IOC功能
继续整理记录这段时间来的收获,详细代码可在我的Gitee仓库Java设计模式克隆下载学习使用! 7.4 自定义Spring IOC 创建新模块,结构如图![[Pasted image 20230210173222.png]] 7.4.1 定义bean相关POJO类 7.4.1.1 定义propertyValue类 /** …...
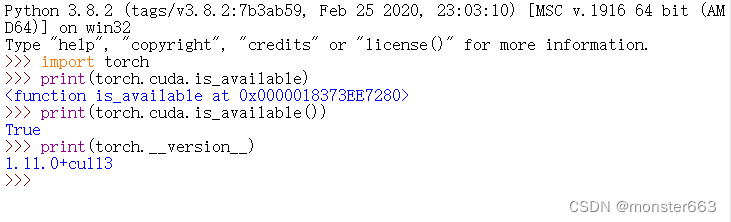
pip离线安装windows版torch
文章目录前言conda创建虚拟环境安装torchtorch官网在线安装离线手动安装测试是否安装成功后记前言 学习的时候遇到几个机器学习相关的项目,由于不同的项目之间用到的依赖库不太一样,于是想利用conda为不同的项目创建不同的环境方便管理和运行࿰…...

Redis核心知识点
Redis核心知识点Redis核心知识点大全五种数据类型redis整合SpringBoot序列化问题渐进式扫描慢查询缓存相关问题数据库和缓存谁先更新缓存穿透缓存雪崩缓存击穿实际应用超卖问题分布式锁全局唯一ID充当消息队列Feed流附近商户签到HyperLogLog实现UV统计持久化RDBAOF持久化小结事…...

14. 最长公共前缀
14. 最长公共前缀 一、题目描述: 编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 “”。 示例 1: 输入:strs [“flower”,“flow”,“flight”] 输出:“fl” 示例 2: …...

浏览器扩展革命:5分钟解锁微信网页版全功能访问
浏览器扩展革命:5分钟解锁微信网页版全功能访问 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为微信网页版的各种限制而烦恼吗&…...

基于Tauri与Bun的本地多智能体AI助手YouClaw:架构、配置与实战
1. 项目概述:一个桌面端的多智能体AI助手运行时 最近在折腾AI智能体(Agent)的本地化部署和集成,发现了一个挺有意思的开源项目——YouClaw。简单来说,它是一个基于Tauri 2构建的桌面应用,核心是一个支持多…...

5分钟快速上手PptxGenJS:用JavaScript轻松生成专业PPT的完整指南
5分钟快速上手PptxGenJS:用JavaScript轻松生成专业PPT的完整指南 【免费下载链接】PptxGenJS Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more. 项目地址: https://gitcode.com/gh_mirrors/pp/PptxGenJS 你…...

超长上下文处理能力翻倍,响应速度提升47%,API成本下降22%:Claude 3.5 Sonnet新功能落地实战手册,仅限本周内有效
更多请点击: https://intelliparadigm.com 第一章:Claude 3.5 Sonnet新功能概览与核心突破 Anthropic 正式发布的 Claude 3.5 Sonnet 在推理效率、多模态理解边界与开发者集成体验上实现了显著跃迁。相比前代,其上下文窗口稳定支持 200K tok…...

Windows驱动存储管理终极指南:DriverStore Explorer技术深度解析
Windows驱动存储管理终极指南:DriverStore Explorer技术深度解析 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer DriverStore Explorer(简称RAPR)是一…...

暗黑2存档编辑器:免费开源工具助你轻松修改角色与装备
暗黑2存档编辑器:免费开源工具助你轻松修改角色与装备 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 暗黑2存档编辑器是一款专门为《暗黑破坏神2》玩家设计的免费开源工具,让你能够轻松修改游戏存档&…...
)
华为eNSP模拟企业网:用VRRP+MSTP搞定500人公司的网络冗余与隔离(附排错记录)
华为eNSP实战:构建500人企业级网络的高可用架构 当一家企业发展到500人规模时,网络架构的稳定性和可靠性就成为业务连续性的关键保障。作为网络工程师,我们经常面临这样的挑战:如何在有限的预算下,设计出既满足部门隔离…...

训练稳定性技巧:Loss spike 的根因与症状压制
⚙️ 工程深度:L4 生产级 | 📖 预计阅读:28 分钟 一句话理解: 梯度裁剪是退烧药,Warmup 重启是疫苗——只吃退烧药,烧还会反复。 🎯 本文产出 Loss spike 根因诊断决策树(可直接用于排障,含 5 个判断节点) 梯度裁剪 + 学习率 Warmup 重启的生产级 PyTorch 实现(…...

WaveTools终极指南:免费解锁鸣潮120FPS帧率限制的完整方案
WaveTools终极指南:免费解锁鸣潮120FPS帧率限制的完整方案 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools WaveTools是一款专为《鸣潮》PC版设计的开源工具箱,通过创新技术方案帮助…...

AArch64内存屏障与缓存一致性机制详解
1. AArch64内存屏障机制深度解析在AArch64架构中,内存屏障(Memory Barrier)是确保多核系统中内存访问顺序性的关键机制。现代处理器普遍采用乱序执行和缓存技术来提升性能,但这会导致内存操作的可见性顺序与程序顺序不一致。内存屏…...