LLM之基于llama-index部署本地embedding与GLM-4模型并初步搭建RAG(其他大模型也可,附上ollma方式运行)
前言
日常没空,留着以后写
llama-index简介
官网:https://docs.llamaindex.ai/en/stable/
简介也没空,以后再写
注:先说明,随着官方的变动,代码也可能变动,大家运行不起来,可以进官网查查资料
加载本地embedding模型
如果没有找到 llama_index.embeddings.huggingface
那么:pip install llama_index-embeddings-huggingface
还不行进入官网,输入huggingface进行搜索
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import SettingsSettings.embed_model = HuggingFaceEmbedding(model_name=f"{embed_model_path}",device='cuda')加载本地LLM模型
还是那句话,如果以下代码不行,进官网搜索Custom LLM Model
from llama_index.core.llms import (CustomLLM,CompletionResponse,CompletionResponseGen,LLMMetadata,
)
from llama_index.core.llms.callbacks import llm_completion_callback
from transformers import AutoTokenizer, AutoModelForCausalLMclass GLMCustomLLM(CustomLLM):context_window: int = 8192 # 上下文窗口大小num_output: int = 8000 # 输出的token数量model_name: str = "glm-4-9b-chat" # 模型名称tokenizer: object = None # 分词器model: object = None # 模型dummy_response: str = "My response"def __init__(self, pretrained_model_name_or_path):super().__init__()# GPU方式加载模型self.tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path, device_map="cuda", trust_remote_code=True)self.model = AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path, device_map="cuda", trust_remote_code=True).eval()# CPU方式加载模型# self.tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path, device_map="cpu", trust_remote_code=True)# self.model = AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path, device_map="cpu", trust_remote_code=True)self.model = self.model.float()@propertydef metadata(self) -> LLMMetadata:"""Get LLM metadata."""# 得到LLM的元数据return LLMMetadata(context_window=self.context_window,num_output=self.num_output,model_name=self.model_name,)# @llm_completion_callback()# def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:# return CompletionResponse(text=self.dummy_response)## @llm_completion_callback()# def stream_complete(# self, prompt: str, **kwargs: Any# ) -> CompletionResponseGen:# response = ""# for token in self.dummy_response:# response += token# yield CompletionResponse(text=response, delta=token)@llm_completion_callback() # 回调函数def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:# 完成函数print("完成函数")inputs = self.tokenizer.encode(prompt, return_tensors='pt').cuda() # GPU方式# inputs = self.tokenizer.encode(prompt, return_tensors='pt') # CPU方式outputs = self.model.generate(inputs, max_length=self.num_output)response = self.tokenizer.decode(outputs[0])return CompletionResponse(text=response)@llm_completion_callback()def stream_complete(self, prompt: str, **kwargs: Any) -> CompletionResponseGen:# 流式完成函数print("流式完成函数")inputs = self.tokenizer.encode(prompt, return_tensors='pt').cuda() # GPU方式# inputs = self.tokenizer.encode(prompt, return_tensors='pt') # CPU方式outputs = self.model.generate(inputs, max_length=self.num_output)response = self.tokenizer.decode(outputs[0])for token in response:yield CompletionResponse(text=token, delta=token)基于本地模型搭建简易RAG
from typing import Anyfrom llama_index.core.llms import (CustomLLM,CompletionResponse,CompletionResponseGen,LLMMetadata,
)
from llama_index.core.llms.callbacks import llm_completion_callback
from transformers import AutoTokenizer, AutoModelForCausalLM
from llama_index.core import Settings,VectorStoreIndex,SimpleDirectoryReader
from llama_index.embeddings.huggingface import HuggingFaceEmbeddingclass GLMCustomLLM(CustomLLM):context_window: int = 8192 # 上下文窗口大小num_output: int = 8000 # 输出的token数量model_name: str = "glm-4-9b-chat" # 模型名称tokenizer: object = None # 分词器model: object = None # 模型dummy_response: str = "My response"def __init__(self, pretrained_model_name_or_path):super().__init__()# GPU方式加载模型self.tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path, device_map="cuda", trust_remote_code=True)self.model = AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path, device_map="cuda", trust_remote_code=True).eval()# CPU方式加载模型# self.tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path, device_map="cpu", trust_remote_code=True)# self.model = AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path, device_map="cpu", trust_remote_code=True)self.model = self.model.float()@propertydef metadata(self) -> LLMMetadata:"""Get LLM metadata."""# 得到LLM的元数据return LLMMetadata(context_window=self.context_window,num_output=self.num_output,model_name=self.model_name,)# @llm_completion_callback()# def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:# return CompletionResponse(text=self.dummy_response)## @llm_completion_callback()# def stream_complete(# self, prompt: str, **kwargs: Any# ) -> CompletionResponseGen:# response = ""# for token in self.dummy_response:# response += token# yield CompletionResponse(text=response, delta=token)@llm_completion_callback() # 回调函数def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:# 完成函数print("完成函数")inputs = self.tokenizer.encode(prompt, return_tensors='pt').cuda() # GPU方式# inputs = self.tokenizer.encode(prompt, return_tensors='pt') # CPU方式outputs = self.model.generate(inputs, max_length=self.num_output)response = self.tokenizer.decode(outputs[0])return CompletionResponse(text=response)@llm_completion_callback()def stream_complete(self, prompt: str, **kwargs: Any) -> CompletionResponseGen:# 流式完成函数print("流式完成函数")inputs = self.tokenizer.encode(prompt, return_tensors='pt').cuda() # GPU方式# inputs = self.tokenizer.encode(prompt, return_tensors='pt') # CPU方式outputs = self.model.generate(inputs, max_length=self.num_output)response = self.tokenizer.decode(outputs[0])for token in response:yield CompletionResponse(text=token, delta=token)if __name__ == "__main__":# 定义你的LLMpretrained_model_name_or_path = r'/home/nlp/model/LLM/THUDM/glm-4-9b-chat'embed_model_path = '/home/nlp/model/Embedding/BAAI/bge-m3'Settings.embed_model = HuggingFaceEmbedding(model_name=f"{embed_model_path}",device='cuda')Settings.llm = GLMCustomLLM(pretrained_model_name_or_path)documents = SimpleDirectoryReader(input_dir="home/xxxx/input").load_data()index = VectorStoreIndex.from_documents(documents,)# 查询和打印结果query_engine = index.as_query_engine()response = query_engine.query("萧炎的表妹是谁?")print(response)
ollama
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.ollama import Ollamadocuments = SimpleDirectoryReader("data").load_data()# bge-base embedding model
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")# ollama
Settings.llm = Ollama(model="llama3", request_timeout=360.0)index = VectorStoreIndex.from_documents(documents,
)欢迎大家点赞或收藏
大家的点赞或收藏可以鼓励作者加快更新哟~
参加链接:
LlamaIndex中的CustomLLM(本地加载模型)
llamaIndex 基于GPU加载本地embedding模型
官网文档
官网_starter_example_loca
官网_usage_custom
相关文章:
)
LLM之基于llama-index部署本地embedding与GLM-4模型并初步搭建RAG(其他大模型也可,附上ollma方式运行)
前言 日常没空,留着以后写 llama-index简介 官网:https://docs.llamaindex.ai/en/stable/ 简介也没空,以后再写 注:先说明,随着官方的变动,代码也可能变动,大家运行不起来,可以进…...

Python 异步爬虫:高效数据抓取的现代武器
标题:“Python 异步爬虫:高效数据抓取的现代武器” 在当今信息爆炸的时代,网络爬虫已成为数据采集的重要工具。然而,传统的同步爬虫在处理大规模数据时往往效率低下。本文将深入探讨如何使用 Python 实现异步爬虫,以提…...
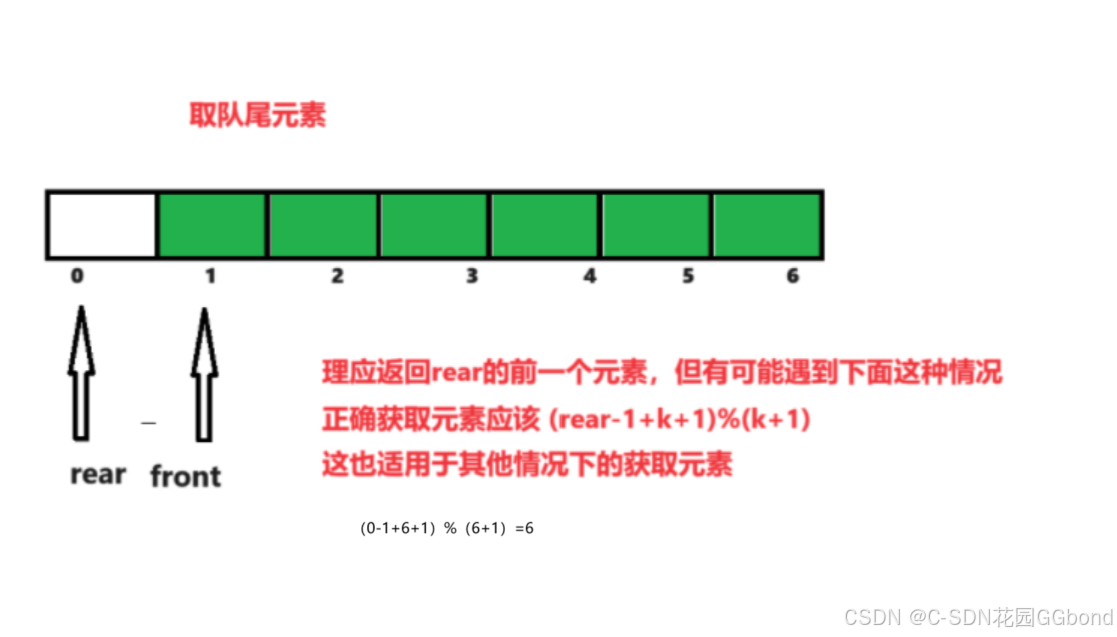
【数据结构算法经典题目刨析(c语言)】使用数组实现循环队列(图文详解)
💓 博客主页:C-SDN花园GGbond ⏩ 文章专栏:数据结构经典题目刨析(c语言) 目录 一.题目描述 二.解题思路 1.循环队列的结构定义 2.队列初始化 3.判空 4.判满 5.入队列 6.出队列 7.取队首元素 8.取队尾元素 三.完整代码实…...

PTA L1-005 考试座位号
L1-005 考试座位号(15分) 每个 PAT 考生在参加考试时都会被分配两个座位号,一个是试机座位,一个是考试座位。正常情况下,考生在入场时先得到试机座位号码,入座进入试机状态后,系统会显示该考生…...
软件测试3333
禅道? 学习正则表达式 目标: 能说出软件测试缺陷判定标准 能说出项目中缺陷的管理系统 能使用Excel对于缺陷进行管理 能使用工具管理缺陷 一、用例执行 说明:用例执行不通过,执行结果与用例的期望结果不一致(含义&…...
))
JJJ:结构体定义中常加的后缀:attribute ((packed))
__attribute__ ((packed)): 的作用就是告诉编译器取消结构体在编译过程中的优化对齐,按照实际占用字节数进行对齐,是GCC特有的语法。这个功能是跟操作系统没关系,跟编译器有关 在GCC下:struct my{ char ch; int a;} sizeof(int)4…...

【HTML】DOCTYPE作用
<!DOCTYPE html> DOCTYPE是document type(文档类型)的缩写。是HTML5中一种标准通用标记语言的文档类型声明,告诉浏览器文档的类型,便于解析文档。不同渲染模式会影响浏览器对CSS代码甚至JS脚本的解析。它必须声明在第一行。…...
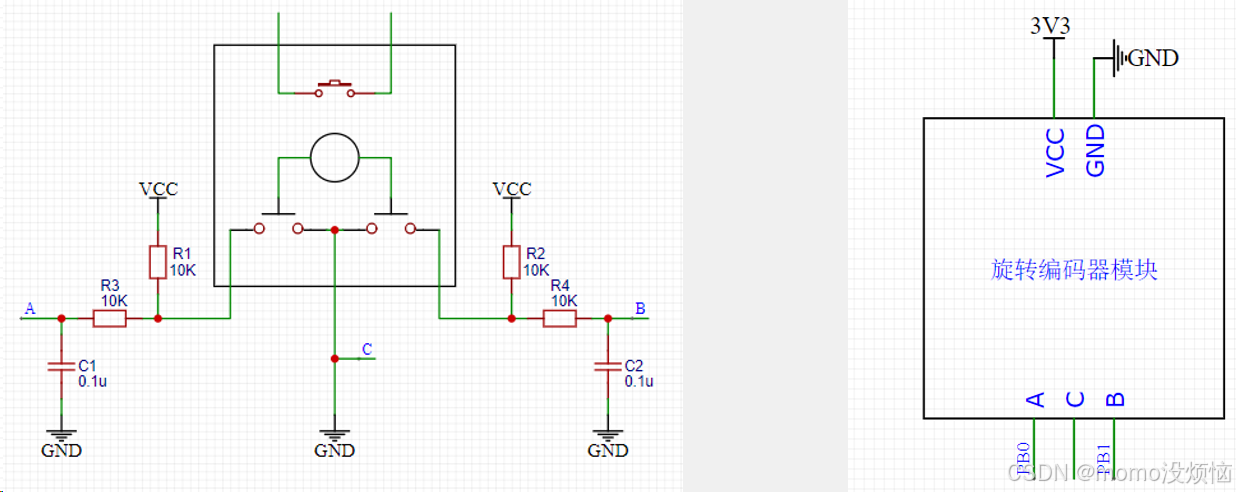
STM32学习记录-04-EXTI外部中断
1 中断系统 (1)中断:在主程序运行过程中,出现了特定的中断触发条件(中断源),使得CPU暂停当前正在运行的程序,转而去处理中断程序,处理完成后又返回原来被暂停的位置继续…...
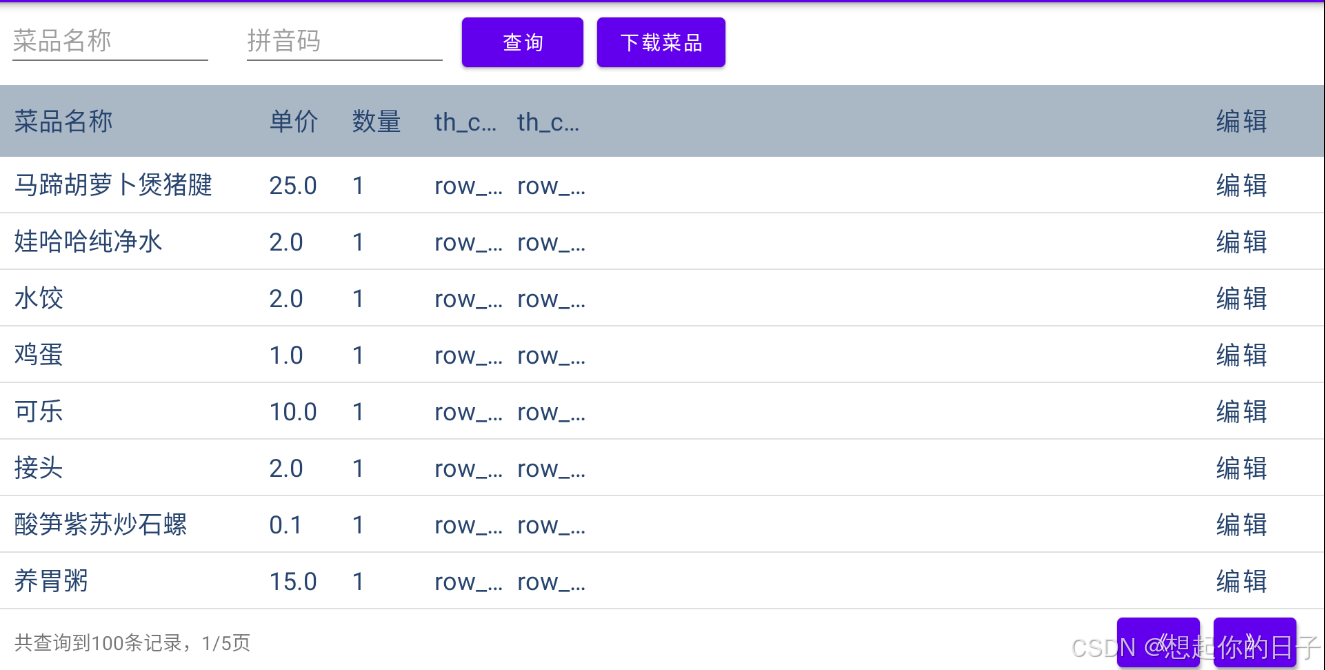
Android Studio 动态表格显示效果
最终效果 一、先定义明细的样式 table_row.xml <?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_h…...

Python 全栈系列264 使用kafka进行并发处理
说明 暂时考虑的场景是单条数据处理特别复杂和耗时的场景。 场景如下: 要对一篇文档进行实体处理,然后再对实体进行匹配。在这个过程当中,涉及到了好几部分服务: 1 实体识别服务2 数据库查询服务3 es查询服务 整个处理包成了服…...

【安全靶场】-DC-7
❤️博客主页: iknow181 🔥系列专栏: 网络安全、 Python、JavaSE、JavaWeb、CCNP 🎉欢迎大家点赞👍收藏⭐评论✍ 一、收集信息 1.查看主机是否存活 nmap -T4 -sP 192.168.216.149 2.主动扫描 看开放了哪些端口和功能 n…...

0065__windows开发要看的经典书籍
windows开发要看的经典书籍_window编程书籍推荐-CSDN博客...

第133天:内网安全-横向移动域控提权NetLogonADCSPACKDC永恒之蓝
案例一:横向移动-系统漏洞-CVE-2017-0146 这个漏洞就是大家熟悉的ms17-010,这里主要学习cs发送到msf,并且msf正向连接后续 原因是cs只能支持漏洞检测,而msf上有很多exp可以利用 注意msf不能使用4.5版本的有bug 这里还是反弹权…...

【IoTDB 线上小课 06】列式写入=时序数据写入性能“利器”?
【IoTDB 视频小课】更新来啦!今天已经是第六期了~ 关于 IoTDB,关于物联网,关于时序数据库,关于开源... 一个问题重点,3-5 分钟,我们讲给你听: 列式写入到底是? 上一期我们详细了解了…...

【机器学习】小样本学习的实战技巧:如何在数据稀缺中取得突破
我的主页:2的n次方_ 在机器学习领域,充足的标注数据通常是构建高性能模型的基础。然而,在许多实际应用中,数据稀缺的问题普遍存在,如医疗影像分析、药物研发、少见语言处理等领域。小样本学习(Few-Shot Le…...

2024.08.14 校招 实习 内推 面经
地/球🌍 : neituijunsir 交* 流*裙 ,内推/实习/校招汇总表格 1、校招 | 理想汽车2025“理想”技术沙龙开启报名 校招 | 理想汽车2025“理想”技术沙龙开启报名 2、校招 | 紫光国芯2025校园招聘正式启动 校招 | 紫光国芯2025校园招聘正式…...

国产双通道集成电机一体化应用的电机驱动芯片-SS6951A
电机驱动芯片 - SS6951A为电机一体化应用提供一种双通道集成电机驱动方案。SS6951A有两路H桥驱动,每个H桥可提供较大峰值电流4.0A,可驱动两个刷式直流电机,或者一个双极步进电机,或者螺线管或者其它感性负载。双极步进电机可以以整…...

32 - II. 从上到下打印二叉树 II
comments: true difficulty: 简单 edit_url: https://github.com/doocs/leetcode/edit/main/lcof/%E9%9D%A2%E8%AF%95%E9%A2%9832%20-%20II.%20%E4%BB%8E%E4%B8%8A%E5%88%B0%E4%B8%8B%E6%89%93%E5%8D%B0%E4%BA%8C%E5%8F%89%E6%A0%91%20II/README.md 面试题 32 - II. 从上到下打…...

總結熱力學_3
參考: 陈曦<<热力学讲义>>http://ithatron.phys.tsinghua.edu.cn/downloads/thermodynamics.pdf 4 热力学量的测量 4.3 主温度计 常用的气体温度计有等体积气体温度计、声学气体温度计和介电常数气体温度计。很多气体在水的三相点附近都接近理想气体。但真正的理…...

TypeScript学习笔记1---认识ts与js的异同、ts的所有数据类型详解
前言:去年做过几个vue3js的项目,当时考虑到时间问题,js更加熟悉,学习成本低一点,所以只去了解了vue3。最近这段时间补了一下ts的知识点,现今终于有空来码文章了,做个学习总结,方便以…...

挑战复杂功能,让快马AI成为你微信小程序开发的智能编程搭档
最近在开发一个微信小程序时,遇到了一个比较复杂的自定义组件需求:一个可以左右滑动切换日期、并显示对应日程的周视图日历。这个功能看似简单,但实际开发中涉及到日期计算、滑动事件处理、数据绑定等多个难点。好在发现了InsCode(快马)平台&…...

如何解决bilibili-api中BV号与AV号转换的技术难题?
如何解决bilibili-api中BV号与AV号转换的技术难题? 【免费下载链接】bilibili-api 哔哩哔哩常用API调用。支持视频、番剧、用户、频道、音频等功能。原仓库地址:https://github.com/MoyuScript/bilibili-api 项目地址: https://gitcode.com/gh_mirrors…...

乙巳马年春联生成终端效果展示:扫码下载功能在微信生态中的无缝流转
乙巳马年春联生成终端效果展示:扫码下载功能在微信生态中的无缝流转 1. 引言:当传统年俗遇见现代科技 春节贴春联,是刻在我们文化基因里的仪式感。但你想过吗,这个传承千年的习俗,也能和今天最前沿的AI技术碰撞出火花…...

MozJPEG终极指南:如何用开源工具将JPEG压缩效率提升30%以上
MozJPEG终极指南:如何用开源工具将JPEG压缩效率提升30%以上 【免费下载链接】mozjpeg Improved JPEG encoder. 项目地址: https://gitcode.com/gh_mirrors/mo/mozjpeg 在当今图像密集的互联网时代,JPEG格式仍然是网页图片的主流选择,但…...

实战演练:基于快马平台codex构建可一键部署的智能api接口生成器
今天想和大家分享一个特别实用的开发技巧——如何用AI快速生成可用的API接口代码。这个项目我是在InsCode(快马)平台上完成的,整个过程非常顺畅,尤其是最后的一键部署功能,让我省去了很多配置环境的麻烦。 项目背景与需求 最近在做一个内部…...

重要提醒:2026年6月PMP考试报名时间已确定
2026年4月2日,中国国际人才交流基金会与PMI(项目管理协会)联合发布官方通知,明确中国大陆地区2026年第二期PMP认证考试将于6月14日正式举办,且本次考试中文报名将分地区、分批次开放,核心报名时间为4月16日…...

JNI内存泄漏吞噬GPU显存,Java AI服务OOM频发,一线工程师紧急封堵的4类隐蔽陷阱
第一章:Java AI 推理调试Java 在 AI 推理场景中常通过 ONNX Runtime、Deep Java Library(DJL)或 TensorFlow Java API 集成模型。调试过程需聚焦于输入张量形状匹配、数据类型一致性、设备绑定状态及推理结果可信度验证。启用详细日志输出 DJ…...

2026届最火的六大AI辅助论文平台实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 基于自然语言处理技术的智能工具是AI写作软件,它能够辅助用户快速生成各类不同的…...

Paperless-ng多语言文档管理终极指南:如何实现国际化支持的完整解决方案
Paperless-ng多语言文档管理终极指南:如何实现国际化支持的完整解决方案 【免费下载链接】paperless-ng A supercharged version of paperless: scan, index and archive all your physical documents 项目地址: https://gitcode.com/gh_mirrors/pa/paperless-ng …...

iOS 15+ 设备越狱实战指南:A8-A11 芯片全流程适配方案
iOS 15 设备越狱实战指南:A8-A11 芯片全流程适配方案 【免费下载链接】palera1n Jailbreak for A8 through A11, T2 devices, on iOS/iPadOS/tvOS 15.0, bridgeOS 5.0 and higher. 项目地址: https://gitcode.com/GitHub_Trending/pa/palera1n 一、问题诊断&…...