Python 全栈系列264 使用kafka进行并发处理
说明
暂时考虑的场景是单条数据处理特别复杂和耗时的场景。
场景如下:
要对一篇文档进行实体处理,然后再对实体进行匹配。在这个过程当中,涉及到了好几部分服务:
- 1 实体识别服务
- 2 数据库查询服务
- 3 es查询服务
整个处理包成了服务,在单线程处理增量的时候非常正常,但尝试进行并行调用的时候出现了问题。每次报错的时候都是显示Connection Reset By Peer,感觉像是服务端连接的问题。由于每一部分都可能是瓶颈,我没(时间)法准确定位问题所在,很有可能是同时起了5个实体识别,GPU的抢占导致的问题(负载经常在100%)。
所以,这个事有两个启示:
- 1 对于One处理的设计,是否可以保存中间关键步骤的跟踪?
- 2 系统资源瓶颈。服务资源是瓶颈(GPU、网络、数据库IO),如果目标是瓶颈资源(Server模式),很容易出现失败。反过来,如果从瓶颈资源出发,尽力而为(Worker)反而会有更高的资源利用率。但是,Server模式是面向消费者的,而Worker模式则是面向生产者的,如果我们要把工作交出去,还是应该采用Server模式。
所以要解决的问题是:在保证逻辑正确的情况下,且有大量miss的情况下,如何尽快的完成业务上的任务。
内容
在数据处理架构中,可靠性与效率也是一对钳制指标,这类型指标混在一起是不行的,必须要分开。所以在机器学习里有:
- 1 精确率与召回率。是分开来研究的,当然也有最终融合的指标(F1Score)
- 2 TCP/IP。
TCP/IP 协议栈中的两个核心协议是:
TCP(传输控制协议):提供可靠的、面向连接的通信服务,确保数据包按顺序到达且无错误。
IP(互联网协议):负责将数据包从源地址传输到目的地址,但不保证传输的可靠性。
在我的业务场景下,TCP可以视为数据库+比对,而IP则视为队列+处理。
(TCP模式)数据库的设计目的就是为了可靠、长期地保存大量的数据,我们把任务、结果以及里程碑节点(中间过程)保存在数据库中是合适的。现在假设只有两个节点:任务和结果。(虽然我发现,在有明显瓶颈的地方是实体识别,这里应该独立一个里程碑节点出来)
(IP模式)队列的设计目的则是缓冲和分发。缓冲是解决生产者的困扰,这样不需要知道机器的能力是多少,把要做的任务发完就好了。然后还可以解决“众包”问题,通过多个worker进行任务分摊,尽可能快的执行任务。在这个过程中,必然会产生大量的不确定问题,导致worker处理、交付失败的。这也是快所要付出的代价。
通过数据库 + 队列的组合,就可以做到既快又好。
1 任务数据入库
简单起见,暂时还是采用mysql。
先将原始数据灌到source表。
之前用离线方式跑了一部分数据,将这部分数据搬到 result表。
right_files = list_file_names_without_extension(right_path)
res_file_list = []
get_right_file_names = []
for the_file in list(right_files):the_tem_data = from_pickle(the_file, './right/')get_right_file_names.append(the_file)res_file_list.append(the_tem_data)res_file_list1 = flatten_list(res_file_list)
# 过滤掉失败的
res_file_list2 = [x for x in res_file_list1 if x !='detail']
right_res_df = pd.DataFrame(res_file_list2)# 引入与数据库表规范对接的数据模型
from pydantic import BaseModel,field_validator
class DocEnt(BaseModel):doc_id : strent_list : list maaped_ent: list @propertydef ent_list_str(self):return ','.join(self.ent_list)@propertydef mapped_list_str(self):return ','.join(self.maaped_ent)def dict(self):data_dict = {}data_dict['doc_id'] = self.doc_iddata_dict['ent_list_str'] = self.ent_list_strdata_dict['mapped_list_str'] = self.mapped_list_strreturn data_dictfrom typing import Listclass DocEnt_list(BaseModel):data_list: List[DocEnt]# 将结果数据转为可被数据库接受的字段模式
docent_list = DocEnt_list(data_list = right_res_df.to_dict(orient='records'))
docent_list1 = [x.dict() for x in docent_list.data_list]
将合法的数据结果与ORM对接,先引入数据模型。
from sqlalchemy import create_engine, Column, Integer, String, Float, DateTime, func, Text, Index
from sqlalchemy.orm import sessionmaker,declarative_base
from datetime import datetimem7_24013_url = f"mysql+pymysql://xxx:xxx@172.17.0.1:24013/mydb"# from urllib.parse import quote_plus
# the_passed = quote_plus('!@#*')
# # 创建数据库引擎
m7_engine = create_engine(m7_24013_url)# 创建基类
Base = declarative_base()# 定义数据模型
class DocEntMap(Base):__tablename__ = 'doc_ent_map'id = Column(Integer, primary_key=True)# CompileError: (in table 'users', column 'name'): VARCHAR requires a length on dialect mysqldoc_id = Column(String(50))ent_list_str = Column(Text)mapped_list_str = Column(Text)create_time = Column(DateTime, default=lambda: datetime.now())# 创建索引__table_args__ = (Index('idx_doc_id', doc_id),Index('idx_create_time', create_time),)Base.metadata.create_all(m7_engine)
# 创建会话
Session = sessionmaker(bind=m7_engine)
分批次存储数据
ent_map_lb = ListBatchIterator(docent_list1, 1000)
import tqdm
with Session() as session:for i,some_list in tqdm.tqdm(enumerate(ent_map_lb)):test_list = [DocEntMap(**x) for x in some_list]# 一次性添加到会话中session.add_all(test_list)# 提交会话session.commit()
因为是mysql,我按照每批1000来操作,每秒能存2批,这个速度也能接受了。
2 比较差集
方式一:mysql不支持
SELECT id FROM table1
EXCEPT DISTINCT
SELECT id FROM table2;
方式2:left join
-- 查找在 table1 中存在但在 table2 中不存在的 id
SELECT t1.id FROM table1 t1
LEFT JOIN table2 t2 ON t1.id = t2.id
WHERE t2.id IS NULL;
我使用Sqlalchmey进行比较并获取数据,稍慢,但方法简单
from sqlalchemy import create_engine, Column, Integer, String, Float, DateTime, func, Text, Index
from sqlalchemy.orm import sessionmaker,declarative_base
from datetime import datetimem7_24013_url = f"mysql+pymysql://xxx:xxx@172.17.0.1:24013/mydb"# from urllib.parse import quote_plus
# the_passed = quote_plus('!@#*')
# # 创建数据库引擎
m7_engine = create_engine(m7_24013_url)# 创建基类
Base = declarative_base()# 定义数据模型
class DocEntMap(Base):__tablename__ = 'doc_ent_map'id = Column(Integer, primary_key=True)# CompileError: (in table 'users', column 'name'): VARCHAR requires a length on dialect mysqldoc_id = Column(String(50))ent_list_str = Column(Text)mapped_list_str = Column(Text)create_time = Column(DateTime, default=lambda: datetime.now())# 创建索引__table_args__ = (Index('idx_doc_id', doc_id),Index('idx_create_time', create_time),)# 定义模型类
class SourceData(Base):__tablename__ = 'source_data'id = Column(Integer, primary_key=True)mid = Column(String(50))content = Column(Text)created = Column(String(50))def dict(self):data_dict = {}data_dict['doc_id'] = self.middata_dict['text'] = self.contentreturn data_dict# 创建表(如果表已经存在,这一步将忽略)
Base.metadata.create_all(m7_engine)# 创建会话
Session = sessionmaker(bind=m7_engine)# 分页查询
page = 1
page_size = 1000while True:offset = (page - 1) * page_sizeresult = session.query(SourceData).filter(~SourceData.mid.in_(session.query(DocEntMap.doc_id))).offset(offset).limit(page_size).all()if not result:breakif page % 10 ==0:print(page)resent_task_list = [x.dict() for x in result]produces = Producer(servers = 'KAFKASERVER',raw_msg_list = resent_task_list, topic='the_topic' )resp = req.post('http://agent:port/send_msg/',json = produces.dict()).json()page += 1
翻页到后面还是慢的,不过确实比较简单,省事。
如果使用clickhouse,选取列的速度还是非常快的。要做好索引之后再取数应该效率会比较高。后续再看吧,我现在都倾向先用lazy版的。
sql="""SELECT mid FROM sourceEXCEPTSELECT doc_id FROM target
;
"""
data=chc._exe_sql(sql)
3 kafka 消费
消费也是通过kafka agent来做的,但是比我之前在本机跑慢。我猜是因为worker在处理完任务,请求下一个时,无论多快,都要进行序列化。而且因为通过agent进行,消费者需要对数据进行两次序列化,这个还是会比较耗时的。
我的想法是,通过一个专门的数据拉取程序,事先将数据从kafka上拉下来,以short_uuid命名,然后存在本地的left。然后本地的worker从left中取数。
为什么要大费周章从kafka取,而不是直接从数据库取?
主要目的是为了更好的分发。例如此时又要加另外两台机器协同处理,难道我还要在手工分配数据吗?
纯粹取数的程序,消费速度一定比处理程序快多了,这样就避免了每次要处理时才进行序列化。
相关文章:

Python 全栈系列264 使用kafka进行并发处理
说明 暂时考虑的场景是单条数据处理特别复杂和耗时的场景。 场景如下: 要对一篇文档进行实体处理,然后再对实体进行匹配。在这个过程当中,涉及到了好几部分服务: 1 实体识别服务2 数据库查询服务3 es查询服务 整个处理包成了服…...

【安全靶场】-DC-7
❤️博客主页: iknow181 🔥系列专栏: 网络安全、 Python、JavaSE、JavaWeb、CCNP 🎉欢迎大家点赞👍收藏⭐评论✍ 一、收集信息 1.查看主机是否存活 nmap -T4 -sP 192.168.216.149 2.主动扫描 看开放了哪些端口和功能 n…...

0065__windows开发要看的经典书籍
windows开发要看的经典书籍_window编程书籍推荐-CSDN博客...

第133天:内网安全-横向移动域控提权NetLogonADCSPACKDC永恒之蓝
案例一:横向移动-系统漏洞-CVE-2017-0146 这个漏洞就是大家熟悉的ms17-010,这里主要学习cs发送到msf,并且msf正向连接后续 原因是cs只能支持漏洞检测,而msf上有很多exp可以利用 注意msf不能使用4.5版本的有bug 这里还是反弹权…...

【IoTDB 线上小课 06】列式写入=时序数据写入性能“利器”?
【IoTDB 视频小课】更新来啦!今天已经是第六期了~ 关于 IoTDB,关于物联网,关于时序数据库,关于开源... 一个问题重点,3-5 分钟,我们讲给你听: 列式写入到底是? 上一期我们详细了解了…...

【机器学习】小样本学习的实战技巧:如何在数据稀缺中取得突破
我的主页:2的n次方_ 在机器学习领域,充足的标注数据通常是构建高性能模型的基础。然而,在许多实际应用中,数据稀缺的问题普遍存在,如医疗影像分析、药物研发、少见语言处理等领域。小样本学习(Few-Shot Le…...

2024.08.14 校招 实习 内推 面经
地/球🌍 : neituijunsir 交* 流*裙 ,内推/实习/校招汇总表格 1、校招 | 理想汽车2025“理想”技术沙龙开启报名 校招 | 理想汽车2025“理想”技术沙龙开启报名 2、校招 | 紫光国芯2025校园招聘正式启动 校招 | 紫光国芯2025校园招聘正式…...

国产双通道集成电机一体化应用的电机驱动芯片-SS6951A
电机驱动芯片 - SS6951A为电机一体化应用提供一种双通道集成电机驱动方案。SS6951A有两路H桥驱动,每个H桥可提供较大峰值电流4.0A,可驱动两个刷式直流电机,或者一个双极步进电机,或者螺线管或者其它感性负载。双极步进电机可以以整…...

32 - II. 从上到下打印二叉树 II
comments: true difficulty: 简单 edit_url: https://github.com/doocs/leetcode/edit/main/lcof/%E9%9D%A2%E8%AF%95%E9%A2%9832%20-%20II.%20%E4%BB%8E%E4%B8%8A%E5%88%B0%E4%B8%8B%E6%89%93%E5%8D%B0%E4%BA%8C%E5%8F%89%E6%A0%91%20II/README.md 面试题 32 - II. 从上到下打…...

總結熱力學_3
參考: 陈曦<<热力学讲义>>http://ithatron.phys.tsinghua.edu.cn/downloads/thermodynamics.pdf 4 热力学量的测量 4.3 主温度计 常用的气体温度计有等体积气体温度计、声学气体温度计和介电常数气体温度计。很多气体在水的三相点附近都接近理想气体。但真正的理…...

TypeScript学习笔记1---认识ts与js的异同、ts的所有数据类型详解
前言:去年做过几个vue3js的项目,当时考虑到时间问题,js更加熟悉,学习成本低一点,所以只去了解了vue3。最近这段时间补了一下ts的知识点,现今终于有空来码文章了,做个学习总结,方便以…...

华为数通方向HCIP-DataCom H12-821题库(更新单选真题:1-10)
第1题 1、下面是一台路由器的部分配置,关于该配置描述正确的是? [HUAWEllact number 2001 [HUAWEl-acl-basic-2001]rule 0 permit source 1.1.1.1 0 [HUAWEl-acl-basic-2001]rule 1 deny source 1.1.1.0 0 [HUAWEl-acl-basic-2001]rule...

【车载开发系列】单片机烧写的文件
【车载开发系列】单片机烧写的文件 【车载开发系列】单片机烧写的文件 【车载开发系列】单片机烧写的文件一. 什么是bin二. 什么是Hex三. 什么是Motorola S-record(S19)四. ELF格式五. Bin与Hex文件的比对六. 单片机烧写文件的本质 一. 什么是bin bin是…...

pyqt 用lamada关联信号 传递参数 循环
在PyQt中,使用lambda函数来关联信号并传递参数是一个常见的做法,尤其是在需要为不同的对象实例关联不同的槽函数参数时。但是,需要注意的是,直接使用lambda可能会导致一些不易察觉的错误,尤其是当它在循环中使用时。这…...

adb命令
adbclient adbserver adbd 三者之间的关系 adbclient, adbserver, 和 adbd 是 Android Debug Bridge (ADB) 组件中的三个主要组成部分。它们各自扮演着不同的角色,共同协作来实现设备调试和管理的功能。下面我将详细介绍这三个组件之间的关系: adbd (A…...

Spring Boot项目热部署
Spring Boot项目热部署是什么 Spring Boot项目热部署是一种开发时的优化技术,可以使开发人员在修改代码后不需要重新启动应用程序即可实时看到修改的效果。在传统的开发模式中,每次修改代码后都需要重新编译、打包和部署应用程序,这样会浪费大…...
Chat App 项目之解析(八)
Chat App 项目介绍与解析(一)-CSDN博客文章浏览阅读340次,点赞7次,收藏3次。Chat App 是一个实时聊天应用程序,旨在为用户提供一个简单、直观的聊天平台。该应用程序不仅支持普通用户的注册和登录,还提供了…...
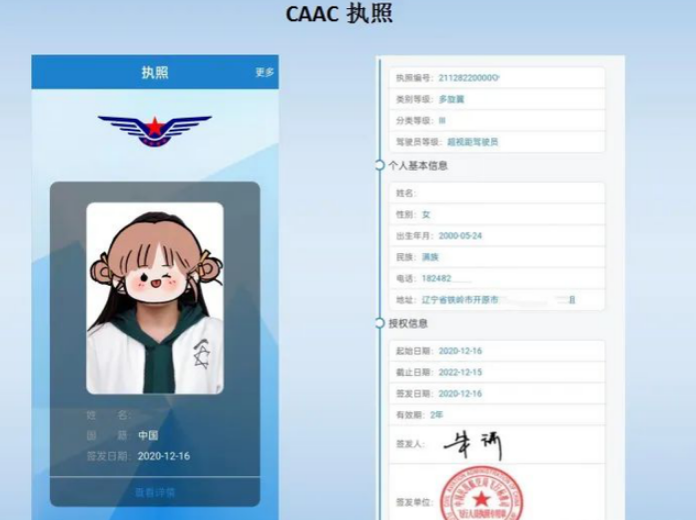
CAAC无人机飞行执照:学习内容与考试流程详解
CAAC无人机飞行执照的学习内容与考试流程是无人机爱好者及从业者必须了解的重要信息。以下是对这两方面的详细解析: 学习内容 CAAC无人机飞行执照的学习内容涵盖了多个方面,以确保学员能够全面掌握无人机飞行和应用的技能。主要学习内容包括:…...
苹果手机怎么连接蓝牙耳机?3个方案,3秒连接
在快节奏的现代生活中,无线蓝牙耳机因其便捷性和自由度成为了许多人的首选。那么,苹果手机怎么连接蓝牙耳机呢?本文将为您介绍3种快速连接苹果设备与蓝牙耳机的方案,让您在享受音乐、通话或观看视频时,不再受线缆束缚&…...

CAD图纸加密软件有哪些?10款超级好用的CAD图纸加密软件推荐
在数字化设计日益普及的今天,CAD图纸作为企业的核心资产,其安全性变得尤为重要。为了防止图纸被非法获取、篡改或泄露,使用专业的CAD图纸加密软件成为了许多企业和设计师的首选。本文将为您推荐10款在2024年表现突出的CAD图纸加密软件&#x…...

【LLM】RL基本概念
On-policy Off-policy 在强化学习(Reinforcement Learning, RL)中,理解 On-policy(同策略)和 Off-policy(异策略)的核心在于区分两个概念: 行为策略 (Behavior Policy, 记为 μ\muμ…...

提示词架构设计:从字符串到组件化系统的工程实践
1. 项目概述:当提示词也需要“架构师”在AI应用开发,尤其是大语言模型(LLM)驱动的项目中,我们常常面临一个核心矛盾:一方面,我们希望提示词(Prompt)足够强大、灵活&#…...

2026年3月 电子学会青少年软件编程机器人技术七级等级考试试卷真题【实际操作】
答案和更多内容请查看网站:【试卷中心 ----->电子学会 ---->机器人技术 ----> 七级】 网站链接 青少年软件编程历年真题模拟题实时更新 青少年机器人技术等级考试实际操作试卷(七级) 2026年3月 一、实操试题 主题࿱…...
面试题:Transformer 模型详解——核心创新、编码器解码器结构、位置编码、因果掩码与大模型基础全解析
1. 为什么 Transformer 是面试里的“必问题”?1.1 它不只是一个模型,而是一条技术主线Transformer 的重要性,不在于它只是机器翻译时代的一篇论文,而在于它几乎重塑了后来的 NLP 乃至大模型架构。无论是 BERT 这类理解模型&#x…...

基于MCP协议构建个人AI助手:本地化读取Mac消息数据库实践
1. 项目概述:一个让AI助手“读懂”你Mac消息的桥梁如果你和我一样,是个重度依赖Mac原生“信息”应用(也就是iMessage)来沟通的人,同时又希望自己的AI助手(比如Claude、Cursor里的AI)能更深入地了…...

Adafruit 3.5寸TFT触摸屏驱动指南:SPI与8位并行模式详解
1. 项目概述与核心价值如果你正在为你的Arduino、树莓派Pico或者任何一款微控制器项目寻找一块足够大、足够亮、还能用手指戳戳点点的屏幕,那么Adafruit这块3.5英寸的320x480彩色TFT触摸屏绝对是一个让人眼前一亮的选择。我手头经手过不少显示屏,从单色O…...
)
【限时解密】Midjourney企业级印相私有化部署方案:Rust服务集群+硬件加速印相网关+审计级水印注入(文档已归档至NIST合规目录)
更多请点击: https://intelliparadigm.com 第一章:Midjourney企业级印相私有化部署全景概览 企业级印相(Print-on-Demand Imaging)在AI生成内容场景中正从公有云服务向高合规、低延迟、强可控的私有化架构演进。Midjourney虽未官…...

JDspyder:3步实现京东抢购自动化的Python脚本解决方案
JDspyder:3步实现京东抢购自动化的Python脚本解决方案 【免费下载链接】JDspyder 京东预约&抢购脚本,可以自定义商品链接 项目地址: https://gitcode.com/gh_mirrors/jd/JDspyder 在电商促销和限量商品抢购的激烈竞争中,京东抢购自…...

3分钟学会使用Chrome文本替换插件:让网页编辑效率提升500%
3分钟学会使用Chrome文本替换插件:让网页编辑效率提升500% 【免费下载链接】chrome-extensions-searchReplace 项目地址: https://gitcode.com/gh_mirrors/ch/chrome-extensions-searchReplace 还在为网页上的重复文本修改而烦恼吗?想象一下&…...

告别城通网盘限速:三步获取高速直连地址的终极方案
告别城通网盘限速:三步获取高速直连地址的终极方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘下载时的漫长等待和龟速下载而烦恼吗?每次打开分享链接&#x…...