AI学习记录 - 如何快速构造一个简单的token词汇表
创作不易,有用的话点个赞
先直接贴代码,我们再慢慢分析,代码来自openai的图像分类模型的一小段
def bytes_to_unicode():"""Returns list of utf-8 byte and a corresponding list of unicode strings.The reversible bpe codes work on unicode strings.This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.This is a signficant percentage of your normal, say, 32K bpe vocab.To avoid that, we want lookup tables between utf-8 bytes and unicode strings.And avoids mapping to whitespace/control characters the bpe code barfs on."""bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))cs = bs[:]n = 0for b in range(2**8):if b not in bs:bs.append(b)cs.append(2**8+n)n += 1cs = [chr(n) for n in cs]return dict(zip(bs, cs))
openai觉得图像分类,就是输入文本,然后给你一张相似的照片,例如
a facial photo of a tabby cat

这其实对文本语义文本推理要求不是很高,所以我们不需要训练出一个太长的词汇表,例如gpt2的50000多个词汇,不需要。
我们只需要一些简单的词汇表,我们可以指定我们需要哪些词汇,首先26个英文字母,一些分隔符,或者你还想兼容其它语言,都可以加,这里兼容了英语法语西班牙语,你觉得重要的语言字符都给一个独立的下标index去对待这个字符,所以就有了如下代码:
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
print(list(range(ord("!"), ord("~")+1)))
print(list(range(ord("¡"), ord("¬")+1)))
print(list(range(ord("®"), ord("ÿ")+1)))
打印如下,ord("!")就是获取一个字符在unicode编码世界中的一个下标,可以看到对你重要的字符都在下面,你可以随意更改上面的字符。
[33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126]
[161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172]
[174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255]
但是实际上当你训练好模型之后,就算你要求用户使用英语法语西班牙语,但是用户可能会使用其它语言去提问,不在我们上面的区间,所以我们要兼容用户输入一些其他语言,我们想使用utf-8去实现这种兼容性。
这里讲一个东西:由于我们没有对其他语言独立给一个位置,所以当使用其他语言去跟模型提问的时候,效果可能不会很好,但我们针对的用户主要是英文法语西班牙语,这里主要是实现兼容性而已。
上面我们给下标的都只是单个字符,但是如果你觉得abc这个连词很重要,你也可以给abc一个单独的index,一个单独的index,意味着这个词有一个单独的词向量去训练,例如abc就有个单独的词向量,但是def没有,那么构成def的词向量是由三个单独的词向量组成,我认为,单独的一个词向量比多个组成的效果要好,表达意义要更准确,因为def是一个词汇,dbp也是一个词汇,他们是不同的意思,但是共享了d这个字符,d既要兼顾def的意思又要兼顾dbp的意思,很可能这两个词汇的意思又完全不相关不交集,那么d这个字符的词向量就被分散了,所以我们跟gpt问问题的时候,用英文问会更好,因为英文可以更准确表达我们的意思,而中文其实更像是很多无关的其他字符拼合起来的意思。
utf-8怎么表示文字?使用四种长度的数组表示一个符号,就是长度为1,2,3,4,每个位置取0到127中其中一个数字,可以表示计算机世界中所有词汇。如下:
【0-127】
【0-127,0-127】
【0-127,0-127,0-127】
【0-127,0-127,0-127,0-127】
原先已经拥有字符的下标,我们不去改它了,继续让他使用unicode编码的下标即可。
遍历 2的8次方 次,当缺少下标的时候,我们将最后一个字符顺序递增叠加上去,代码就是:
for b in range(2**8):if b not in bs:# 不存在的下标,就把下标append进去bs.append(b) cs.append(2**8+n) # 但是我append进去的字符却不是对应下标的unicode字符,因为我不喜欢......,我把第2**8+n字符叠加上去n += 1
打印bs
[33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96,97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183,184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255, 0, 1, 2, 3, 4, 5,6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 173]
打印cs
['!', '"', '#', '$', '%', '&', "'", '(', ')', '*', '+', ',', '-', '.', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':',
';', '<', '=', '>', '?', '@', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z', '[', '\\', ']', '^', '_', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '{', '|', '}', '~', '¡', '¢', '£', '¤', '¥', '¦', '§', '¨', '©', 'ª',
'«', '¬', '®', '¯', '°', '±', '²', '³', '´', 'µ', '¶', '·', '¸', '¹', 'º', '»', '¼', '½', '¾', '¿', 'À', 'Á', 'Â', 'Ã', 'Ä', 'Å',
'Æ', 'Ç', 'È', 'É', 'Ê', 'Ë', 'Ì', 'Í', 'Î', 'Ï', 'Ð', 'Ñ', 'Ò', 'Ó', 'Ô', 'Õ', 'Ö', '×', 'Ø', 'Ù', 'Ú', 'Û', 'Ü', 'Ý', 'Þ', 'ß',
'à', 'á', 'â', 'ã', 'ä', 'å', 'æ', 'ç', 'è', 'é', 'ê', 'ë', 'ì', 'í', 'î', 'ï', 'ð', 'ñ', 'ò', 'ó', 'ô', 'õ', 'ö', '÷', 'ø', 'ù',
'ú', 'û', 'ü', 'ý', 'þ', 'ÿ', 'Ā', 'ā', 'Ă', 'ă', 'Ą', 'ą', 'Ć', 'ć', 'Ĉ', 'ĉ', 'Ċ', 'ċ', 'Č', 'č', 'Ď', 'ď', 'Đ', 'đ', 'Ē', 'ē',
'Ĕ', 'ĕ', 'Ė', 'ė', 'Ę', 'ę', 'Ě', 'ě', 'Ĝ', 'ĝ', 'Ğ', 'ğ', 'Ġ', 'ġ', 'Ģ', 'ģ', 'Ĥ', 'ĥ', 'Ħ', 'ħ', 'Ĩ', 'ĩ', 'Ī', 'ī', 'Ĭ', 'ĭ',
'Į', 'į', 'İ', 'ı', 'IJ', 'ij', 'Ĵ', 'ĵ', 'Ķ', 'ķ', 'ĸ', 'Ĺ', 'ĺ', 'Ļ', 'ļ', 'Ľ', 'ľ', 'Ŀ', 'ŀ', 'Ł', 'ł', 'Ń'
]
这就是我们仅有256个词汇表的token。
相关文章:
AI学习记录 - 如何快速构造一个简单的token词汇表
创作不易,有用的话点个赞 先直接贴代码,我们再慢慢分析,代码来自openai的图像分类模型的一小段 def bytes_to_unicode():"""Returns list of utf-8 byte and a corresponding list of unicode strings.The reversible bpe c…...

JAVA中的数组流ByteArrayOutputStream
Java 中的 ByteArrayOutputStream 是一个字节数组输出流,它允许应用程序以字节的形式写入数据到一个字节数组缓冲区中。以下是对 ByteArrayOutputStream 的详细介绍,包括其构造方法、方法、使用示例以及运行结果。 一、ByteArrayOutputStream 概述 Byt…...

S3C2440中断处理
一、中断处理机制概述 中断是CPU在执行程序过程中,遇到急需处理的事件时,暂时停止当前程序的执行,转而执行处理该事件的中断服务程序,并在处理完毕后返回原程序继续执行的过程。S3C2440提供了丰富的中断源,包括内部中…...

《数据分析与知识发现》
《数据分析与知识发现》介绍 1 期刊定位 《数据分析与知识发现》(Data Analysis and Knowledge Discovery)是由中国科学院主管、中国科学院文献情报中心主办的学术性专业期刊。期刊创刊于2017年,由《现代图书情报技术》(1985-20…...
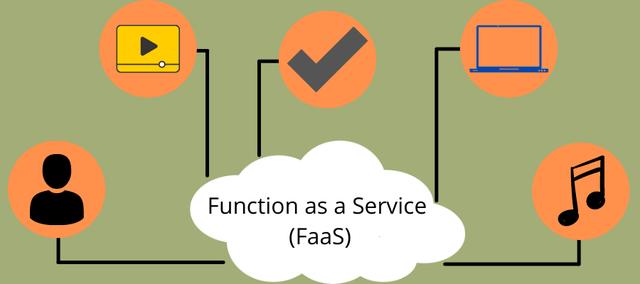
IaaS,PaaS,aPaaS,SaaS,FaaS,如何区分?
IaaS, PaaS,SaaS,aPaaS 还有一种 FaaS ,这几个都是云服务中常见的 5 大类型: IaaS:基础架构即服务,Infrastructure as a Service PaaS:平台即服务,Platform as a Service aPaaS&…...

软件测试工具分享
要想在测试中旗开得胜,趁手的“武器”那是相当重要(说人话,要保证测试质量和效率,测试工具也很重要)。现在,小酋打算亮一亮自己的武器库,希望不要闪瞎你的眼(天上在打雷,…...
word翻译工具有哪些?5个工具助你快速翻译Word文件
无论是商业沟通还是文化交流,都需要跨越语言障碍。而文档翻译则是这一过程中的重要环节之一。 想象一下,当你需要将一份重要的Word文档从一种语言翻译成另一种语言时,如果手动逐句翻译不仅耗时耗力,还可能因为文化差异导致误解。…...

【51单片机】ds18b20驱动,11.0592MHZ,使用DS18b20
文章目录 ds18b20.h #include <reg52.h> #include <intrins.h> #include <math.h>// 管脚定义 sbit DS18B20_DATA_PIN = P1 ^ 0; // DS18B20数据口定义/******************************************************************************* * 函 数 名 …...

Vue 导航条+滑块效果
目录 前言代码效果展示导航实现代码导航实现代码导航应用代码前言 总结一个最近开发的需求。设计稿里面有一个置顶的导航条,要求在激活的项目下面展示个下划线。我最先开始尝试的是使用 after 的伪类选择器,直接效果一样,但是展示的时候就会闪现变化,感觉不够自然,参考了一…...

Android:使用Gson常见问题(包含解决将Long型转化为科学计数法的问题)
一、解决将Long型转化为科学计数法的问题 1.1 场景 将一个对象转为Map类型时,调用Gson.fromJson发现,原来对象中的long类型的personId字段,被解析成了科学计数法,导致请求接口失败,报参数错误。 解决结果图 1.2、Exa…...

【Win开发环境搭建】Redis与可视化工具详细安装与配置过程
🎯导读:本文档提供了Redis的简介、安装指南、配置教程及常见操作方法。包括了安装包的选择与配置环境变量的过程,详细说明了如何通过修改配置文件来设置密码和端口等内容。同时,文档还介绍了如何使用命令行工具连接Redisÿ…...

Compose知识分享
前言 “Jetpack Compose 是一个适用于 Android 的新式声明性界面工具包。Compose 提供声明性 API,让您可在不以命令方式改变前端视图的情况下呈现应用界面,从而使编写和维护应用界面变得更加容易。” 以上是Compose官网中对于Compose这套全新的Androi…...

python-study-day5
urllib中handler的使用 import urllib.request url "http://www.baidu.com" headers {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0 } # 请求地址的定制 reques…...

Telegram mini app 本地开发配置
前言: 为了能在telegram里本地调试mini app,参考了网上很多方案,踩了不少坑。最后整了一个适合自己的方案,记录一下。 这个方案一定不是最好的,不过是目前适合我上手开发的方案了。 本文章适合需要在 telegram 本地…...

python发票查验接口助您拒绝做糊涂账、发票ocr
发票识别发票查验接口让发票真假立现。仅需一键上传发票图片,即可实现发票真伪的秒速、批量验证,操作简单方便,避免因人工核验失误所导致“错账”现象的发生,减轻财务工作负担,提升企业工作效率,降低因假票…...

【Linux】线程控制|POSIX线程库|多线程创建|线程终止|等待|线程分离|线程空间布局
目录 编辑 POSIX线程库 多线程创建 独立栈结构 获取线程ID pthread_self 线程终止 return终止线程 pthread_exit pthread_cancel 线程等待 退出码问题 线程分离 测试 线程ID及地址空间布局 编辑 POSIX线程库 pthread线程库是 POSIX线程库的一部分…...
JimuReport 积木报表 v1.8.0 版本发布,开源可视化报表
项目介绍 一款免费的数据可视化报表工具,含报表和大屏设计,像搭建积木一样在线设计报表!功能涵盖,数据报表、打印设计、图表报表、大屏设计等! Web 版报表设计器,类似于excel操作风格,通过拖拽完…...
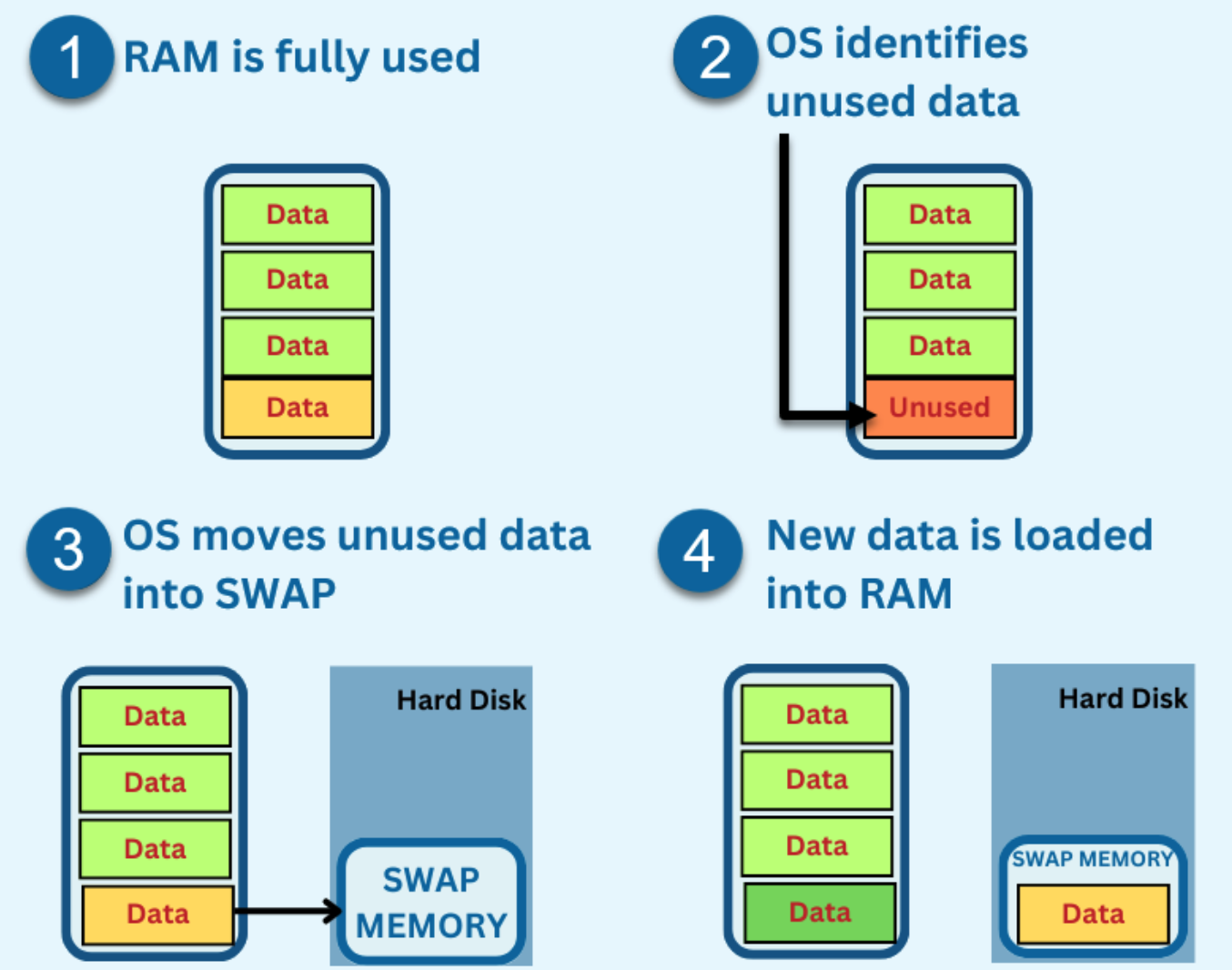
性能优化理论篇 | swap area是个什么东西
我们知道每台计算机的内存(RAM)都是有限的,而我们的应用程序需要加载到内存才能被运行,如果一台机器运行多个应用程序时,内存可能会耗尽。Linux 系统中的“交换空间(也称为交换分区)”可以帮助缓…...
下载安装win/mac版)
Photoshop (PS)下载安装win/mac版
目录 一、概述 下载 二、安装步骤 三、使用教程 四、快捷键汇总 一、概述 Adobe Photoshop,简称“PS”,是由Adobe Systems开发和发行的图像处理软件。它主要处理以像素所构成的数字图像,涵盖了诸多领域,如图像编辑、图像合成…...

初识redis:Set类型
Set有很多种含义,比如集合,比如设置(和get相对应)。 在这里我们说的set是指的redis中的集合,并且这里的集合是无序的,和之前的list是对应的。 List : [1,2,3] 和 [2,1,3] 是两个不同的listSe…...

POLYGON Military资源包:军事仿真级3D资产的精度逻辑与战术应用
1. 这个资源包不是“拿来就能用”的万能钥匙,而是军事仿真级资产的起点你刚在Unity Asset Store页面看到POLYGON Military资源包封面——几辆写实风格的装甲车停在沙尘弥漫的战壕边,一个全副武装的士兵正蹲姿持枪警戒,远处是半坍塌的混凝土掩…...

嵌入式工程师核心素养:从测试到系统构建的全链路能力模型
1. 从“明星评选”看嵌入式工程师的成长路径与价值塑造最近看到一篇关于某公司内部“品质与服务创建活动”的报道,评选了四位明星工程师。这让我感触颇深。在嵌入式这个行当里摸爬滚打了十几年,我见过太多技术扎实但默默无闻的同行,也见过一些…...

提示词失效?Midjourney印象派出图不稳的8大陷阱,资深AIGC架构师逐帧解析SD/MJ风格迁移差异
更多请点击: https://codechina.net 第一章:提示词失效的本质:当语义熵击穿Midjourney的隐空间边界 当“cyberpunk cat wearing neon sunglasses, ultra-detailed, 8k”生成结果突然坍缩为 a blurry humanoid silhouette with cat ears&…...
:仅支持至2024年Q3 API v2退役前)
【限时开放】ElevenLabs波斯文语音调试秘钥包(含Persian SSML扩展标签库、RTL音频波形对齐工具、实时音素诊断CLI):仅支持至2024年Q3 API v2退役前
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs波斯文语音支持的演进与技术边界 ElevenLabs自2022年推出多语言TTS服务以来,波斯文(Farsi)长期处于实验性支持阶段。早期版本仅能通过自定义音色音素级微调…...

本地能跑线上崩?MonkeyCode统一云端环境解决团队开发噩梦
行内深耕多年,深知绝大多数程序员都被开发环境问题绊住前行脚步,几大行业通病几乎人人都遇见过。换新设备就得全盘重搭开发环境,新电脑到手没空敲代码,反倒整日忙着安装各类工具、调配环境变量、适配项目依赖,耗费大把…...
)
Midjourney单色调风格失效诊断图谱(含8种典型失败案例+对应--no、--style、--seed三重校准方案)
更多请点击: https://intelliparadigm.com 第一章:Midjourney单色调风格失效诊断图谱(含8种典型失败案例对应--no、--style、--seed三重校准方案) 单色调(Monochrome)图像生成在Midjourney中高度依赖提示词…...

ElevenLabs陕西话语音落地实录:从零配置API到高保真秦腔语调还原,7步搞定方言TTS部署
更多请点击: https://kaifayun.com 第一章:ElevenLabs陕西话语音落地实录:从零配置API到高保真秦腔语调还原,7步搞定方言TTS部署 环境准备与API密钥获取 首先注册ElevenLabs账号并进入 Profile → API Keys页面,生成…...

边缘AI框架:在边缘设备上运行AI模型
边缘AI框架:在边缘设备上运行AI模型 一、边缘AI框架概述 1.1 边缘AI框架的定义 边缘AI框架是指用于在边缘设备上部署和运行AI模型的软件框架。它提供了模型优化、推理加速和设备适配等功能,使得AI模型能够在资源受限的边缘设备上高效运行。 1.2 边缘AI框…...

6款优质降AIGC平台 降痕效果拉满
写论文时不断攀升的AIGC率让人焦虑不已?别担心,这里整理了6款高效实用的降AIGC工具,堪称应对AI痕迹问题的"得力助手"。它们能有效识别并消除AI生成特征,降痕能力出众,助你轻松通过查重审核,彻底摆…...

PHP Intelephense项目结构解析:多工作区、虚拟工作区与远程开发
PHP Intelephense项目结构解析:多工作区、虚拟工作区与远程开发 【免费下载链接】vscode-intelephense PHP intellisense for Visual Studio Code 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-intelephense PHP Intelephense是一款为Visual Studio …...