【自然语言处理】 构建文本对话系统
构建文本对话系统的框架如下:

根据聊天系统目的功用的不同,可分成三大类型:
闲聊式机器人:较有代表性的有微软小冰、微软小娜、苹果的 Siri、小 i 机器人等,主要以娱乐为目的。
**知识问答型机器人:**知识问答型系统,比如 Watson 系统最早在 2011 年的问答节目 Jeopardy 上击败了所有人类选手,赢得百万美金的奖金(当然,Watson 不止有知识问答的功能)。
**任务型机器人:**以完成某一领域的具体任务为导向,在工业界上应用较广泛,如订票系统、订餐系统等。
任务型聊天机器人以帮助用户完成某项具体任务为导向,进行单轮或多轮对话。比较简单的场景,比如智能家居,机器人能理解并执行主人指令即可,无需进行多轮对话。而在一些比较复杂的场景下,比如预订餐馆、预订机票、预定电影票等,需要的关键信息较多,按照人类的用语习惯,也不太可能一言以概述,因此常常需要机器人与用户间多轮交互后才能完成任务。
对于基于任务型的多轮对话系统,一般有四大模块:
自然语言理解(Spoken Language Understanding,SLU)
对话状态追踪(Dialogue State Tracking,DST)
对话策略(Dialogue Policy Learning,DPL)
自然语言生成(Natural Language Generation,NLG)
SLU 模型的目标是识别用户的意图(Intention Detection)以及词槽填充(Slot Filling)。用通俗的语言来讲,就是获取一些完成任务的关键信息,比如“我想吃西餐,价位便宜点的”这句话,其意图是“找餐厅”,词槽是“菜系”和“价格”,词槽值分别是“西餐”和“便宜”。DST 的目的是保存并更新对话状态,包括一些历史对话信息、当前的词槽填充情况、数据库查询结果等等。DP很好理解,即基于当前的对话状态及用户输入作出合适的反馈,而 NLG 则是将这个反馈转化为自然语言的过程。在具体实践中,可以把这四个模块当作单独的子任务来做,也可以用端到端的方式将四者串行,用一些深度学习、强化学习的技术实现系统搭建。
另外,我们也可以基于公开的聊天机器人平台根据个人需要搭建对话系统。比较具备代表性的平台有:百度的 AI 开放平台、海森智能的 ruyi.ai 系统、脸书的 wit.ai 平台、亚马逊的 Lex 等。这些平台实现了基本的技术构建和封装,只需要用户根据特定任务做一些较简单的诸如意图及词槽定义、相关模型选择的工作即可快速搭建聊天系统。
对话系统的关键技术
检索技术
基于检索技术的问答设计思想很简单,即收集问答对,机器根据用户输入查找到相似度最高的相关问题,而后将其答案返回。比如用户输入“上火的时候能不能吃荔枝?”,机器通过在现有的问答集里检索到相似度最高的问题“上火了可以吃荔枝吗?”,并且返回其正确答案“上火的时候不宜吃荔枝”。 那么,如何找到相似的问题?一般分为两种方法:
基于字符串的相似度匹配:用于字母语言,具体方法有编辑距离计算、杰卡德距离算法或者基于 Lucene 提供的模糊查询方法。值得一提的是,虽然中文不是由字母构成,但也可以拆分成具体的有限数量的字根(比如五笔输入法所采用的字根拆解法),并且由于汉语作为表意语言,源于图画,很多字根蕴含了非常丰富的语义内容,从这个角度来讲,基于字根的中文相似度匹配也是一种值得尝试的方法。
基于语义的相似度匹配:主要从词向量的角度来考虑,基于 Word2Vec 模型或者效果更好 GloVe、ELMo、Bert 等将词向量化后再进行后续运算。由于最终目的是句子间的相似度匹配,在词向量的基础上,我们还需要用一定方法表征句向量。常见的方法有将句子里的所有词向量均值平均,或者加权平均(越常见的词权重越小),比如 SIF 加权模型、词移距离模型。另外,类似于 Word2Vec 训练词向量的方法,以三个相邻的句子为一个三元组,直接训练句向量,代表模型有 Skip-Thought Vector, Quick-Thought Vectors。而在有监督的框架下,人们也尝试用多任务学习的方法,从各个不同的任务角度对同一句话进行编码,得到迁移性比较强的句向量,比如谷歌在 2018 年推出的 Universal Sentence Encoder。
有了这些文本相似度匹配的方法后,系统搭建似乎很简单,看起来只要找到那个相近的句子就行了。而实际上,假如问答集里的数据量特别大,导致匹配过程耗时太长怎么办?为了提高系统效率,人们一般用一些粗粒度的算法得到一些候选句子(Ranked phrases),比如应用倒排索引 (Inverted Index) 找到存在输入句子中至少一个单词的所有句子作为候选项,之后再用更精细化的算法从候选者里找答案。这其实类似于一些大企业招聘人才,由于求职者众多,往往根据学校背景筛选出一批候选者,再从中作全面系统的考察后找到最合适的人才,这其中难免会遗漏掉一些真正的人才,但整体而言这是比较兼顾资源耗费与准确性的方式。
意图识别和词槽填充
对于用户的输入,任务型聊天系统的第一任务便是自然语言理解,一般包括意图识别和词槽填充。
所谓意图识别,即解析出说话者的目的为何,实际上就是一个文本分类问题。比如一个订餐馆的系统,对于用户输入而言,可以有咨询信息、提供信息、表示感谢、拒绝推荐等意图。在比较简单的任务中,依靠一些规则的定义便可以识别出相关意图。在场景较复杂,意图种类较多,用户输入多变的情况下,往往应用机器学习的方法预测意图。
词槽,即与意图相关的一些必要属性,我们需要从用户输入中找到这些属性值。比如“天气查询”这个意图的词槽或者说必要属性有两个:时间和地点,机器需要用户提供这两方面的信息之后才能给出准确的回答。词槽填充其实是一个序列标注任务,一般用 BIO 作为标记法,B 为词槽值的开始(Begin),I 为延续(Inside),O 为无关信息(Outside)。
应用于序列标注的概率图模型有隐马尔科夫模型(Hidden Markov Model, HMM)、最大熵马尔科夫模型(Maximum Entropy Markov Model, MEMM)、条件随机场(Conditional Random Field, CRF)。其中,虽然 CRF 训练代价大,复杂度高,但与前两者相比,特征设计灵活,考虑全局性,效果更好。另外,循环神经网络也常应用于序列标注,能够自动学习输入语句间的隐含特征,但也有可能忽略一些很明显的标注关系层面的特征。因此,很多研究者选择把将以上两类方式结合进行序列标注,以发挥各自的优势。
虽然意图识别和词槽填充看上去是两个单独的任务,但实际上两者的关联性较大,只设计一个模型同时获取这两方面的信息会有不错效果。比如,常见的设计结构有 Bi-LSTM+CRF,结合循环神经网络和条件随机场,其中序列的每一步输入经由 LSTM 层和 CRF 层后输出为标记,而序列最终输出为意图。
对于初次接触意图识别和词槽填充这两个术语的朋友而言,往往因为其“表达的专业性陌生性”而感到难以理解。简单地说,人与人之间的对话,涉及的便是两个层面,中心思想和具体细节,在双方得到这两方面信息的基础上,对话才能顺利进行。对应地,中心思想指的便是意图识别,具体细节则是词槽填充。其实所有的术语和白话文一样,都是符号,只要和生活场景联系上了,也就不难理解了。
对话管理
对话管理包括对话状态追踪以及对话策略,前者相当于人脑的记忆功能,用于存储及更新所有的对话信息,后者相当于人脑的语言反馈机制,根据当前情形做出合理的动作反应,这是任务型对话系统中最关键也是最难操作的部分。同样地,这里也涉及到一系列术语,比如对话追踪、对话策略等,这里不再举例讲解,读者们可以结合生活中的对话行为去思考,相信会有更深的体会。
首先,关于对话状态追踪,需要定义对话状态的组成成分,只要是有助于对话策略的信息都可以予以追踪。一般可以概括为四大方面的信息:历史对话信息、当前用户行为、词槽填充情况、数据库查询情况。其中词槽填充情况是至关重要的信息,直接决定了对话进行的程度,比如针对“天气查询”的意图,“地点”和“时间”两个词槽都已填充,那么马上就能回复天气情况以结束对话。
然而,词槽填充并不是件简单的事,这是由于自然语言存在极大的不确定性或者说多样性。来看这样一句话:“我想吃西餐,不过好像有点油,日餐也行,如果没有的话中餐也好。”
在这句话中“西餐”、“日餐”和“中餐”均有出现,用户到底想吃什么的目的也不是很明确,那么到底要选哪一个作为词槽“菜系”的值?这似乎很难判断。所以实际上词槽值的输出不应该是某一确定的单一值,而是所有可能值的概率分布,比如输出 [0.4,0.4,0.2] 分别作为想吃西餐、日餐和中餐的概率。由于用户在对话过程中也会改变主意,此概率还会随着对话的进行产生变化。
有了对话状态后,根据一定策略产生行为的机制就叫对话策略。最直观的方式是设定一系列的规则,比如用有限自动状态机的方式实现此模块。比如要完成某一意图需要填充三个词槽 slot1、slot2 和 slot3 的信息,那么可以制定诸如此类的状态转移规则:没有 slot 被填充的时候,机器询问 slot1 的情况;slot1 被填充的情况下,机器询问 slot2 的情况;slot1, slot2 被填充的情况下,询问 slot3 的情况……总而言之,规则需要覆盖所有可能情况,以保证测试的时候不出纰漏。
所以,当场景稍微复杂点的时候,规则设计就会变得很繁琐;当有新的意图或词槽时,更改规则也非常麻烦;另一方面,从用户体验来看,机器的回馈也显得很呆板。而如果用深度学习的方法来习得机器行为,显然数据是一个很大的障碍,在多轮对话领域,数据量少、质量不高、缺少标签等都是短时间内难以解决的问题。
对话设计
在任务型多轮对话任务中,一个架构完备的多轮对话体系的构建不只涉及到众多算法,还需要考虑很多业务上的细节,比如多轮对话可能的流程、有哪些意图、有哪些槽位等,因此需要对业务非常地熟悉。在这里,以槽的设计所需注意的要点为例进行说明。
刚接触多轮对话的有些朋友可能会觉得,槽的设计不是很简单嘛,把对话场景中涉及到的关键实体罗列出来不就可以了?比如做一个医疗方面的对话,那么应该就有疾病、食物、药物、症状等。事实上,槽的罗列整理是一方面,难点在于如何整理清楚槽的类型、填充方式以及槽之间的关系。
首先,槽可分为必填与非必填。比如在一个订餐的系统中,餐馆位置、菜品、人数等应该是必填槽,而顾客或者餐馆的更多其它情况并非必填槽,比如顾客性别年龄、餐馆装修风格等,这些信息对于订餐的完成并非必须。
再比如,槽又可以分为词槽与接口槽:
词槽:利用用户话中关键词填写的槽。
接口槽:利用用户画像以及其他场景信息填写的槽。
比如,在应用端已知一个在杭州登录的用户问:“明天天气怎么样?”那么机器助手可以默认问的是“杭州”的天气,这里就没有利用对话中的信息而是应用了场景信息。因此,同一个槽,可能会存在多种填槽方式,并且有优先级。比如,在应用端已知一个在杭州登录的用户问:“我后天要坐火车去上海,有票吗?”那么机器助手如何来获取出发地这个槽位的信息呢,能否直接默认为“杭州”呢?肯定不行。在这里涉及到订票这一施行动作,对准确度要求当然比天气高,因此需要进行确认:“您是从杭州出发么?”但如果是用户主动提供出发地为杭州,二次确认就会显得冗余。所以在这里,出发地信息可来源于用户主动提供的优先级高于用户默认所在地信息。
而对于槽之间的关系,可分为平级槽和依赖槽。举个例子,在订车票的场景中,需要知道用户“出发的时间”、“地点”、“目的地”、“座位种类”——这四个槽之间,没有任何依赖关系。而在旅游规划的场景中,比如去“海边”和“山里”,每一个选择都会有影响到后续对话发展(预定“海景房”还是“山景房”),也即每个槽的填写结果会影响其它槽的填写。如果错将平级槽采用依赖槽关系来管理,就会出现信息的丢失。比如 A、B、C,三者本为平级槽关系,但却将其用 A->B->C 的依赖槽关系来管理,那即便用户问句中包含填写 B、C 槽组的信息,也可能会由于 A 槽组的未填写而造成 B、C 槽组的填写失败。如果错将依赖槽采用平级槽的关系来管理,就会出现信息的冗余,比如 A、B、C三者的关系为 A、A1->B、A2->C,那即便用户将值 A1 填入槽组 A 后,却仍然需要向用户询问本不需要的 C 槽组的填写信息。
以上仅是对话设计中的一小部分工作,在真正的应用中还需要考虑横向广泛纵向深度的方面,因此想成为一个合格的算法工程师,对业务的理解必不可少。
写在最后:
NLP 各方面:https://github.com/fighting41love/funNLP
NLP 开源项目:https://github.com/yongzhuo/nlp_xiaojiang
相关文章:
【自然语言处理】 构建文本对话系统
构建文本对话系统的框架如下: 根据聊天系统目的功用的不同,可分成三大类型: 闲聊式机器人:较有代表性的有微软小冰、微软小娜、苹果的 Siri、小 i 机器人等,主要以娱乐为目的。 **知识问答型机器人:**知识…...

java: 程序包org.slf4j不存在
当在Java项目中遇到“程序包org.slf4j不存在”的错误时,这通常意味着你的项目没有正确地包含SLF4J(Simple Logging Facade for Java)的库。SLF4J是一个Java的日志门面(Facade),它允许你在后端使用不同的日志…...
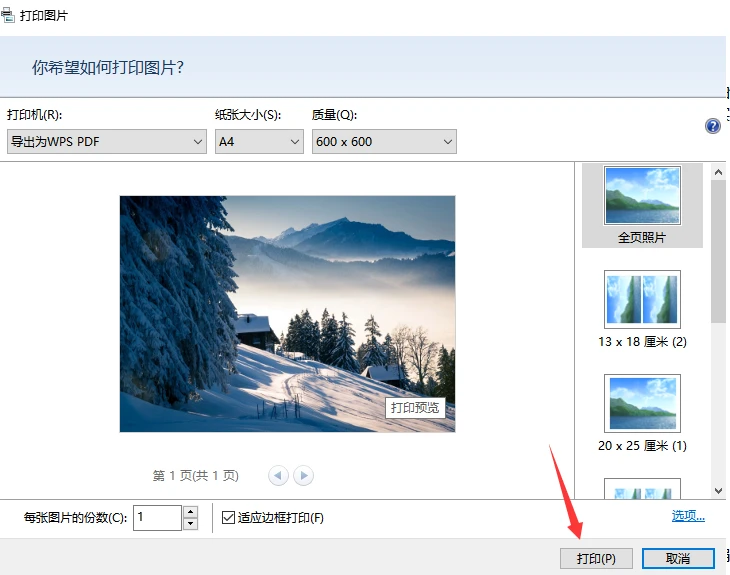
图片转PDF怎么转?教你3种快捷方便的jpg转pdf方法
图片文件以及PDF文档已经是我们工作当中不可或缺的一部分,我们在一些商务合作的场景下经常需要把拍摄下来的合同、企划书、画册等图片内容转换为PDF格式后再发送,这样能够极大程度的保证文件的安全性,那么图片应该如何转换成PDF文件呢?今天来…...

数据防泄密软件如何防止数据泄密?七大措施筑起数据安全壁垒
数据防泄密软件通过集成多种安全防护技术,旨在全面保护企业数据的安全性和保密性。以安企神软件为例,其实现全面防泄密的方式主要包括以下7个方面,为企业筑起数据安全壁垒。 1. 透明加密技术 安企神软件采用先进的透明加密技术,确…...

GNU/Linux - systemd介绍
systemd官网: System and Service Manager systemd systemd Github地址: https://github.com/systemd/systemd 首次发布 2010年3月30日 System and Service Manager systemd 是一套 Linux 系统的基本构件。它提供了一个系统和服务管理器,作为…...

如何理解递归
在二叉树的题目中,我们难免会用到递归方法,递归思想很简单,但运用起来却因为抽象而难以理解。 理解递归的关键在于认识到它是一种解决问题的方法,允许函数直接或间接地调用自身。以下是对递归的概述以及如何理解它的几个要点&…...

Spring Cache sync属性
在Spring Cache中,Cacheable注解用于标记一个方法,使其返回值可以被缓存。sync属性是Spring 4.3引入的一个新特性,用于控制缓存的同步行为。 sync 属性 sync属性的默认值是false,表示异步缓存。如果将sync设置为true,…...

【Unity】通用GM QA工具 运行时数值修改 命令行 测试工具
GM工具使用: GM工具通常用于游戏运行时修改数值(加钱/血量)、解锁关卡等,用于快速无死角测试游戏。一个通用型GM工具对于游戏项目是非常实用且必要的,但通用不能向易用妥协,纯命令行GM门槛太高,对QA不友好。 这类运行时命令行工具…...

[Spring] Spring原理(SpringBoot完结)
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

python | rq,一个无敌的 关于Redis 的Python 库!
本文来源公众号“python”,仅用于学术分享,侵权删,干货满满。 原文链接:rq,一个无敌的 Python 库! 大家好,今天为大家分享一个无敌的 Python 库 - rq。 Github地址:https://githu…...

Redis的缓存淘汰策略
1. 查看Redis 最大的占用内存 打开redis配置文件, 设置maxmemory参数,maxmemory 是bytes字节类型, 注意转换 2. Redis默认内存多少可以用 注意: 在64bit系统下, maxmemory 设置为 0 表示不限制Redis内存使用 3. 一般生产上如何配置 一般推荐Redis 设置内…...

【C++】深度解析:用 C++ 模拟实现 priority_queue类,探索其底层实现细节(仿函数、容器适配器)
目录 ⭐前言 ✨堆 ✨容器适配器 ✨仿函数 ⭐priority_queue介绍 ⭐priority_queue参数介绍 ⭐priority_queue使用 ⭐priority_queue实现 ✨仿函数实现 ✨堆的向上调整和向下调整 ✨完整代码 ⭐前言 ✨堆 堆是一种特殊的树形数据结构,通常以二叉树的…...

1个人躲,5个人抓!《极限竞速:地平线5》全新游戏模式“捉迷藏”即将推出
风靡全球的赛车竞速游戏《极限竞速:地平线5》即将推出全新游戏模式——捉迷藏(Hide & Seek)。 《极限竞速:地平线5》日前发布了全新预告,展示了即将于 9 月 10 日推出的捉迷藏模式游戏玩法。该预告是日前举办的2024 年科隆国际游戏展 Xb…...

ARCGIS XY坐标excel转要素面
1、准备好excel 坐标 excel文件转为csv才能识别,CSV只能保留第一个工作表并且,不会保留格式。 2、在ArcGis中导入XY事件图层 创建XY事件图层 图层要素赋对象ID 将导入的图层导出为先新的图层,这样就给每个要素附加了唯一的值 选择点集转线…...

MyBatis源码系列3(解析配置文件,创建SqlSessionFactory对象)
创建SqlSessionFactory; 首先读取配置文件,使用构造者模式创建SqlSessionFactory对象。 InputStream inputStream Resources.getResourceAsStream("mybatis-config.xml");SqlSessionFactory sqlSessionFactory new SqlSessionFactoryBuilder…...

企业级web应用服务器tomcat
目录 一、Web技术 1.1 HTTP协议和B/S 结构 1.2 前端三大核心技术 1.2.1 HTML 1.2.2 CSS(Cascading Style Sheets)层叠样式表 1.2.3 JavaScript 二、tomcat的功能介绍 2.1 安装 tomcat 环境准备 2.1.1 安装java环境 2.1.2 安装并启动tomcat …...

深入浅出,探讨IM(即时通讯-聊天工具)技术架构及用户界面设计
在数字化时代的浪潮中,即时通讯(IM)工具已然成为人们日常沟通的重要方式。从微信、QQ到飞信钉、喧喧IM、企业微信、钉钉、Slack,这些IM工具不仅为我们提供了便捷的沟通方式,更在技术架构和用户界面设计上展现了独特的魅…...

小米、友邦带领恒指大反攻!
港股三大指数反弹止步2连跌,恒生科技指数一度冲高至2%,恒指收涨1.44%。盘面上,大型科技股多数表现活跃,业绩超预期,小米大涨超8%表现尤其抢眼,京东涨约4%,百度涨1.71%,网易涨2.14%&a…...

中国植物性状数据库
中国植物性状的研究主要集中在植物的生理结构和功能,以及它们对环境的适应性上。中国植物性状的多样性体现在多个方面,包括植物的生理结构、生长习性、以及对环境的适应性等。 中国植物性状数据库,包含了来自140个样点的1529种植物…...

[数据集][目标检测]街灯路灯检测数据集VOC+YOLO格式1893张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1893 标注数量(xml文件个数):1893 标注数量(txt文件个数):1893 标注…...

西门子触摸屏报警处理:除了弹窗,用这个‘非中断式’方法让产线更丝滑
西门子HMI非中断报警系统设计:让产线效率提升30%的实战方案 在快节奏的工业现场,每一次操作中断都意味着产能的隐形流失。传统HMI报警弹窗就像突然按下的暂停键——操作员必须停下手中任务去点击确认,而流水线上的产品仍在流动。这种矛盾在汽…...

Windows下用C语言实现控制台鼠标交互:从获取坐标到点击响应全流程
Windows控制台鼠标交互开发实战:C语言实现精准坐标捕获与事件响应 引言:当命令行遇上图形交互 在大多数开发者印象中,控制台程序总是与键盘输入绑定在一起——那个闪烁的光标等待着用户键入命令,然后返回几行单调的文字输出。但Wi…...

别再手动算杂散了!用Keysight Genesys的WhatIF工具,5分钟搞定中频规划
射频工程师的中频规划革命:用Keysight Genesys WhatIF工具实现精准决策 在射频系统设计中,中频规划往往是最令人头疼的环节之一。传统的手动计算方法不仅耗时费力,还容易在复杂的混频杂散分析中出现疏漏。我曾亲眼见证一个团队因为中频选择不…...

Paste 轻量级剪贴板管理工具使用指南
Paste 轻量级剪贴板管理工具使用指南 【免费下载链接】paste A no-datastore, client-side paste service. 项目地址: https://gitcode.com/gh_mirrors/past/paste 一、场景化导入:当剪贴板成为你的效率瓶颈 想象一下这样的工作场景:你正在整理一…...
)
别再傻傻下载Gurobi软件了!Anaconda虚拟环境里一条conda命令搞定学术版安装(Win11实测)
颠覆认知的Gurobi安装指南:一条conda命令解锁学术版完整功能 每次看到同行们花半小时下载几个GB的Gurobi安装包,我就忍不住想分享这个被多数人忽略的高效方案。作为在运筹优化领域深耕多年的研究者,我发现90%的学术用户根本不需要走传统安装…...

DataWorks与PyODPS实战:MaxCompute数据处理高效技巧
1. 初识DataWorks与PyODPS:大数据处理的黄金搭档 第一次接触DataWorks和PyODPS时,我就像发现了一个新大陆。DataWorks作为阿里云的一站式大数据开发平台,而PyODPS则是连接Python和MaxCompute的桥梁,这个组合让大数据处理变得前所…...

从命令行工具到桌面体验:SyncTrayzor如何让Syncthing在Windows上焕然新生
从命令行工具到桌面体验:SyncTrayzor如何让Syncthing在Windows上焕然新生 【免费下载链接】SyncTrayzor Windows tray utility / filesystem watcher / launcher for Syncthing 项目地址: https://gitcode.com/gh_mirrors/sy/SyncTrayzor 你是否曾经在Window…...

论文省心了!2026年实力出众的专业AI论文写作工具
2026年AI论文写作工具已从“内容生成”进化为多维度学术支持系统,核心评价维度包括文献真实性、格式合规性、长文本逻辑、查重降重、AIGC合规与多语言适配能力。本次测评覆盖6款主流工具,涵盖中文与英文场景,支持全流程与专项功能,…...

3个核心维度解析iOS数据取证:iLEAPP从入门到精通
3个核心维度解析iOS数据取证:iLEAPP从入门到精通 【免费下载链接】iLEAPP iOS Logs, Events, And Plist Parser 项目地址: https://gitcode.com/gh_mirrors/il/iLEAPP 一、核心价值:iOS数据解析的全能工具 iLEAPP(iOS Logs, Events, …...

3步掌握Buzz字幕智能分割:从杂乱时间戳到专业级字幕的技术实现
3步掌握Buzz字幕智能分割:从杂乱时间戳到专业级字幕的技术实现 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Trending/buz/buzz Bu…...