爬虫案例4——爬取房天下数据
简介:个人学习分享,如有错误,欢迎批评指正
任务:从房天下网中爬取小区名称、地址、价格和联系电话
目标网页地址:https://newhouse.fang.com/house/s/
一、思路和过程
目标网页具体内容如下:

我们的任务是将上图中小区名称、地址、价格和联系电话对应爬下来。
1.定义目标URL
由于网页普遍具有反爬程序,不加修饰的直接访问网页可能会失败,所以第一步学会伪装自己。
如何伪装自己呢,可以通过找到正常访问网页时的访问状态,将自己的这次爬虫模拟成一次正常访问网页,因此我们的目标是找到正常访问网页时的User-Agent。User Agent中文名为用户代理,(简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等)。User-Agent就是你访问网页的身份证明。具体操作如下:
首先打开目标(/任意)网页,然后点击鼠标右键后选择检查打开网页的HTML 页面。

在HTML 页面里面依次点击网络,然后任意点一条网络请求(如果没有显示任何网络请求可以点击网页左上角的刷新),然后选择标头,下拉列表找到User-Agent,User-Agent后面那段内容就是我们用来伪装自己的身份码。

2.发送GET请求获取网页内容
通过上面的步骤我们获得了
url = ‘https://newhouse.fang.com/house/s/’
User-Agent:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0’
接下来发起网页访问请求,代码如下:
import requests # 引入requests库,用于发送HTTP请求
from lxml import etree # 引入lxml库中的etree模块,用于解析HTML文档# 定义目标URL,即要爬取的网页地址
url = 'https://newhouse.fang.com/house/s/'# 定义HTTP请求头,其中包括User-Agent信息,用于伪装成浏览器进行访问
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'
}# 发送GET请求获取网页内容,并将响应内容存储在resp变量中
resp = requests.get(url, headers=headers)
# 设置响应内容的编码格式为utf-8,确保中文字符正常显示
resq.encoding = 'utf-8'
# 打印响应内容,检查获取到的HTML文本
print(resp.text)
查看print结果,我们发现成功获得了网页相关的html表达,

3.分析网页内容
接下来对html进行解析获得我们目标内容。
这里,我们需要借助工具xpath来辅助内容解析,xpath安装教程
安装成功后,按Ctrl+Shift+Alt 启动 xpath,网页上方出现如下图所示框,

找到目标内容方法
例:我们的目标是找到小区名字在html中的位置。点击如下图左边标记(1),该命令的含义是在网页中选择一个元素以进行检查,即当你把鼠标放在网页的某一位置,下面也会自动定位到html中该内容所在位置,如图所示,把鼠标放在北京城建·星誉BEIJING(2),下面显示小区名在html中所在位置(3)。

明确目标内容的位置。具体的,如下图所示,小区名北京城建·星誉BEIJING,它位于div class="nlcd_name"中的a里面。

因此,我们可以通过这个层层关系来找到目标所有小区名,借助刚才安装的工具xpath,下面一步步演示层层查找过程。
首先,在query中添加//div[@class=“nlcd_name”],可以发现右边的results将所有小区的名字返回了。

其次,加上筛选条件a得

同理,query中添加//div[@class=“nlcd_name”],可以发现右边的results将所有小区的地址返回了。

同理,query中添加//div[@class=“nhouse_price”],可以发现右边的results将所有小区的价格返回了。

同理,query中添加//div[@class=“tel”]/p/text(),可以发现右边的results将所有小区的联系方式返回了。

但是,我们发现上面只能取到单页的内容,而整个网页如下有很多页。

对于上述问题,我们通过对比下图情况,发现url地址不同的页码的url仅仅换了最后一个数字,数字即对应页码。

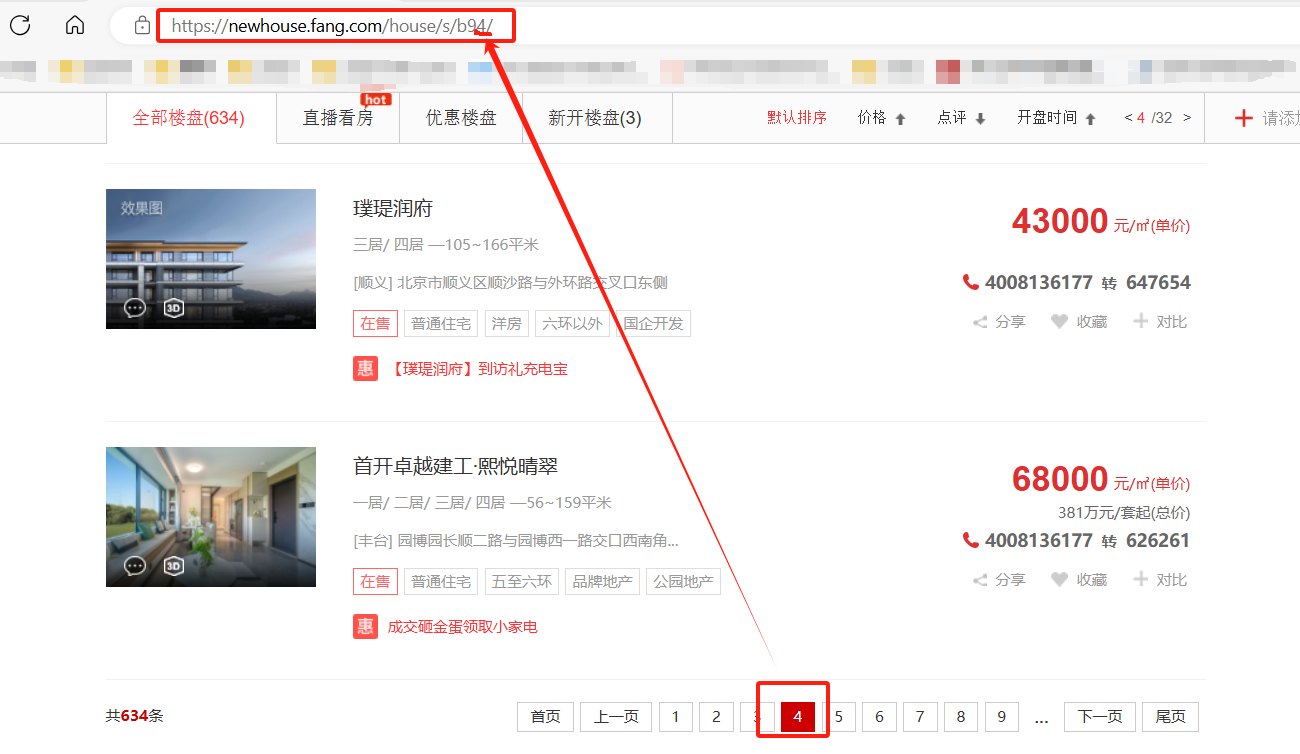
因此进一步添加一个for循环来取得所有页的url地址,代码如下:
for i in range(4):# 构建每一页的URLurl = f'https://newhouse.fang.com/house/s/b9{i}/'# 发送GET请求获取网页内容,并将响应内容存储在resq变量中resq = requests.get(url, headers=headers)# 设置响应内容的编码格式为utf-8,确保中文字符正常显示resq.encoding = 'utf-8'# 打印响应内容,检查获取到的HTML文本print(resq.text)
因此,通过xpath的可视化辅助,得上面地址
//div[@class="nlcd_name"]/a可以获取小区名称,//div[@class="address"]/a/@title可以获取小区地址,//div[@class="nhouse_price可以获取小区价格,//div[@class="tel"]/p/text()可以获取小区联系电话。
4.获取目标数据
上一步得到了目标数据的地址,接下来就是分别获得到目标数据,代码如下:
# 使用etree.HTML方法将HTML文本解析为一个HTML文档对象e = etree.HTML(resq.text)# 使用XPath语法从HTML文档中提取出小区名称,并去除字符串前后的空白字符names = [n.strip() for n in e.xpath('//div[@class="nlcd_name"]/a/text()')]# 使用XPath语法从HTML文档中提取出小区地址addreses = e.xpath('//div[@class="address"]/a/@title')# 使用XPath语法从HTML文档中提取出小区价格,并去除多余的空白字符price = [pr.xpath('string(.)').strip() for pr in e.xpath('//div[@class="nhouse_price"]')]# 使用XPath语法从HTML文档中提取出联系电话tel = e.xpath('//div[@class="tel"]/p/text()')
5.保存数据
存为一个txt文件
with open('fangtianxia.txt', 'w', encoding='utf-8') as f:# 使用zip函数将名称、地址、价格、电话数据组合在一起,逐行写入文件for na, ad, pr, te in zip(names, addreses, price, tel):# 写入格式为:红球号码:xxx 蓝球号码:xxxf.write(f'姓名:{na} 地址:{ad} 价格:{pr} 电话:{te}\n')二、完整python代码
import requests # 引入requests库,用于发送HTTP请求
from lxml import etree # 引入lxml库中的etree模块,用于解析HTML文档
import pandas as pd # 引入pandas库,用于处理和存储数据# 定义HTTP请求头,其中包括User-Agent信息,用于伪装成浏览器进行访问
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'
}# 初始化一个空列表,用于存储爬取的数据
data = []# 循环遍历4个页面,每个页面的URL末尾数字依次递增
for i in range(4):# 构建每一页的URLurl = f'https://newhouse.fang.com/house/s/b9{i}/'# 发送GET请求获取网页内容,并将响应内容存储在resq变量中resq = requests.get(url, headers=headers)# 设置响应内容的编码格式为utf-8,确保中文字符正常显示resq.encoding = 'utf-8'# 打印响应内容,检查获取到的HTML文本print(resq.text)# 使用etree.HTML方法将HTML文本解析为一个HTML文档对象e = etree.HTML(resq.text)# 使用XPath语法从HTML文档中提取出小区名称,并去除字符串前后的空白字符names = [n.strip() for n in e.xpath('//div[@class="nlcd_name"]/a/text()')]# 使用XPath语法从HTML文档中提取出小区地址addreses = e.xpath('//div[@class="address"]/a/@title')# 使用XPath语法从HTML文档中提取出小区价格,并去除多余的空白字符price = [pr.xpath('string(.)').strip() for pr in e.xpath('//div[@class="nhouse_price"]')]# 使用XPath语法从HTML文档中提取出联系电话tel = e.xpath('//div[@class="tel"]/p/text()')with open('fangtianxia.txt', 'w', encoding='utf-8') as f:# 使用zip函数将名称、地址、价格、电话数据组合在一起,逐行写入文件for na, ad, pr, te in zip(names, addreses, price, tel):# 写入格式为:红球号码:xxx 蓝球号码:xxxf.write(f'姓名:{na} 地址:{ad} 价格:{pr} 电话:{te}\n')结~~~
相关文章:
爬虫案例4——爬取房天下数据
简介:个人学习分享,如有错误,欢迎批评指正 任务:从房天下网中爬取小区名称、地址、价格和联系电话 目标网页地址:https://newhouse.fang.com/house/s/ 一、思路和过程 目标网页具体内容如下: …...
网络硬盘录像机NVR程序源码NVR全套运用方案
在当今社会,随着科技的飞速发展和人们对安全需求的日益增长,安防监控系统已成为保障公共安全、维护社会稳定的重要手段。其中,网络视频录像机(NVR)作为安防监控系统的核心设备,其智能化升级运用方案对于提高…...
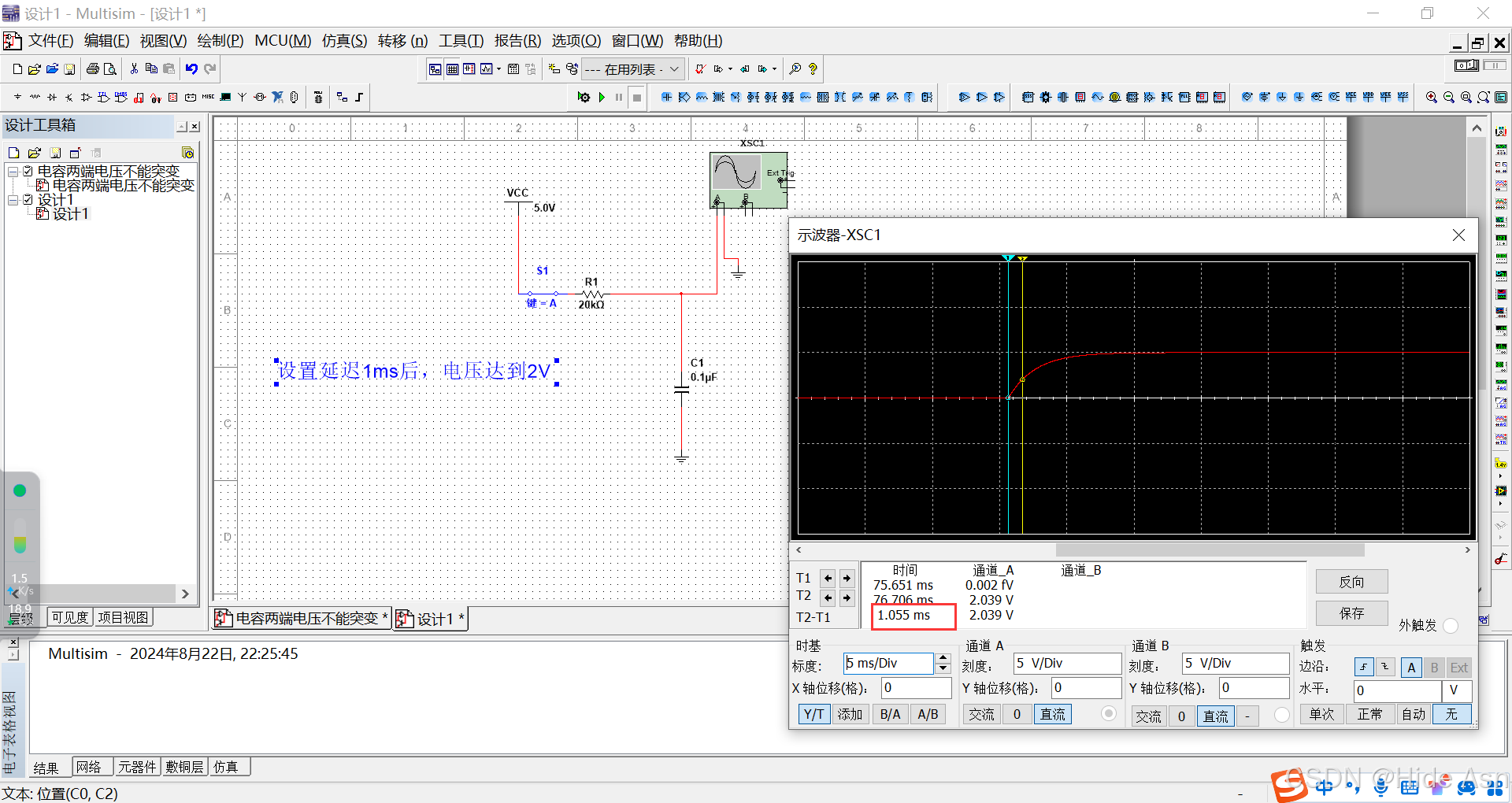
03:电容的充放电特性及应用举例
1.电容的基本特性:电容两端的电压不能突变 2.影响电容两端电压的参数:整个回路中电阻,电容大小 3.如何计算电容的电压变化时间? τRC R1k C1uF 则得到τ1ms的时间 应用:芯片使能延时...
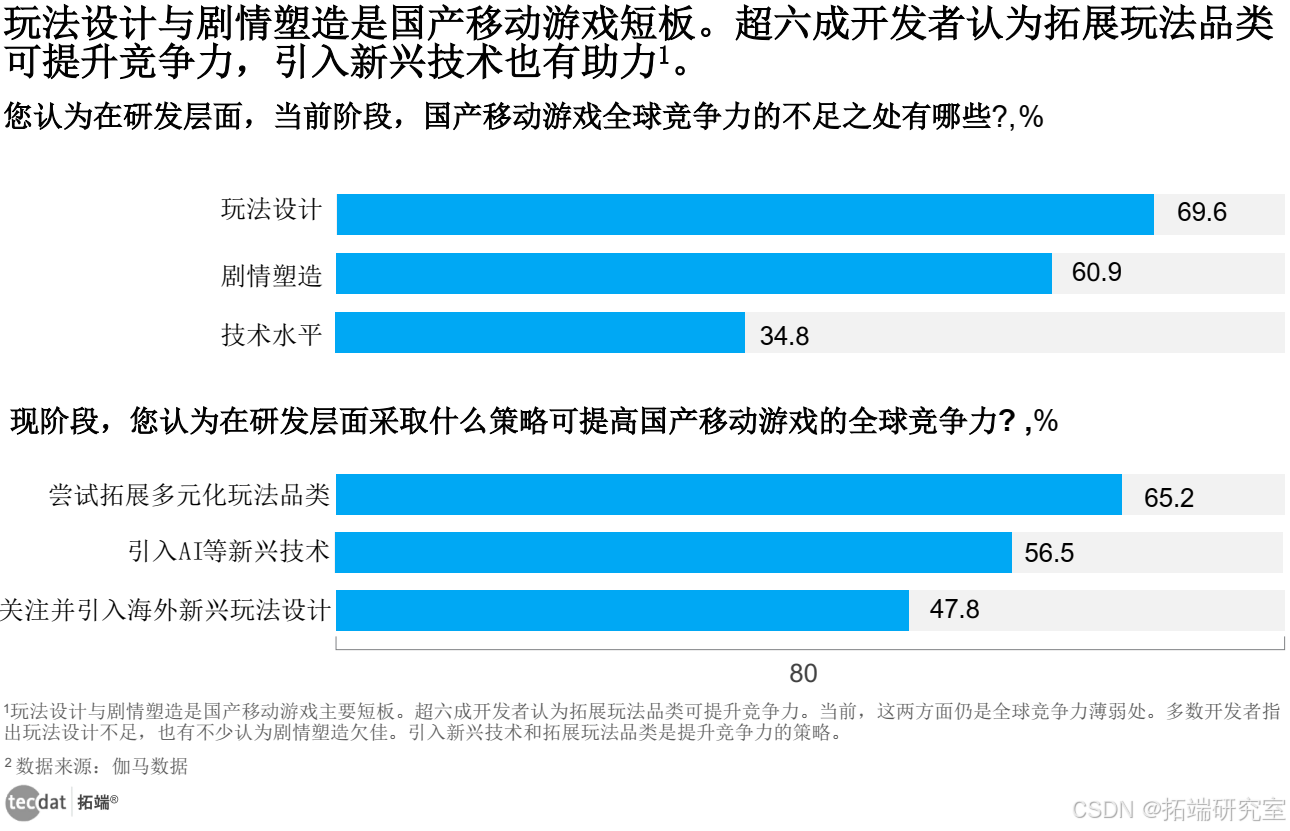
【专题】2023-2024中国游戏企业研发竞争力报告合集PDF分享(附原数据表)
原文链接: https://tecdat.cn/?p37447 在当今的数字时代,游戏产业已然成为经济与文化领域中一股不可忽视的重要力量。2023 年,中国自研游戏市场更是呈现出一片繁荣且复杂的景象,实际销售收入达到了令人瞩目的 2563.8 亿元&#x…...

会话跟踪方案:Cookie Session Token
什么是会话技术? Cookie 以登录为例,用户在浏览器中将账号密码输入并勾选自动登录,浏览器发送请求,请求头中设置Cookie:userName:张三 ,password:1234aa ,若登录成功,服务器将这个cookie保存…...
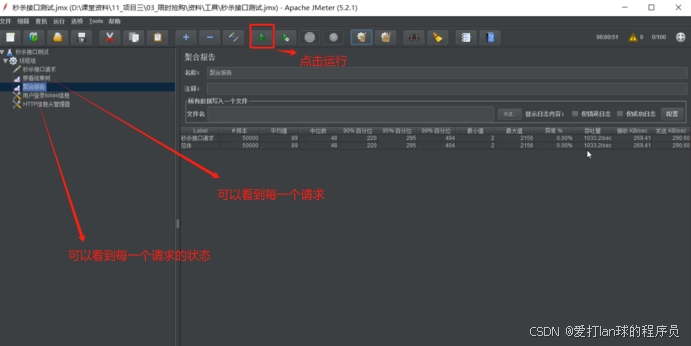
jemeter压力测试入门
1. 安装jemeter的压缩包并且解压 点击运行 2. 添加线程组 3. 线程组的参数设置 4. 添加http请求 5. 填写请求信息 添加监听器——结果树(结果),聚合报告(吞吐量报告) 6. 通过cvs数据文件设置,配置元件&…...
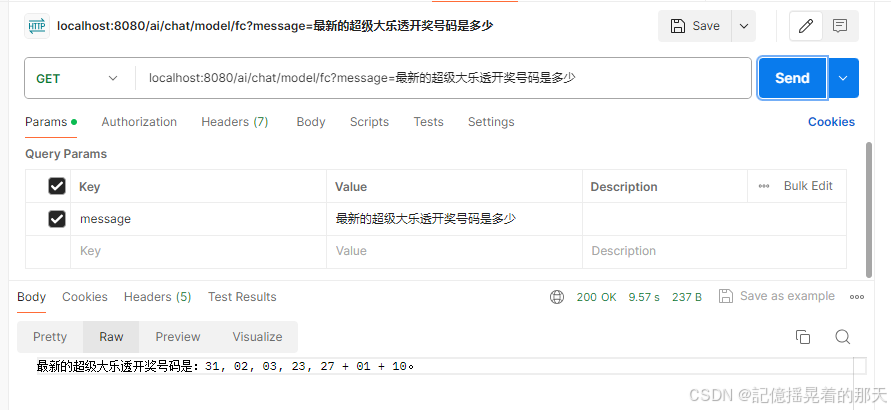
SpringBoot3 简单集成 Spring AI 并使用
文章目录 准备JDK17api key 创建项目编写配置文件创建controller启动并测试角色预设流式响应\异步响应ChatModel(聊天模型)ImageModel(文生图)文生语音语言翻译多模态Function Calling (函数调用第三方API)…...

【C/C++】程序设计基础知识(数据类型与表达式、控制语句、数组与结构)
【C/C】程序设计基础知识(数据类型与表达式、控制语句、数组与结构) 一、数据类型与表达式1.1C语言符号1.2C语言运算符1.3数据类型1.4常量与变量1.5基本运算1.6优先级和结合性1.7输入与输出 二、控制语句2.1顺序结构2.2选择结构2.3循环结构2.4break,cont…...

python库——sklearn的关键组件和参数设置
文章目录 模型构建线性回归逻辑回归决策树分类器随机森林支持向量机K-近邻 模型评估交叉验证性能指标 特征工程主成分分析标准化和归一化 scikit-learn,简称sklearn,是Python中一个广泛使用的机器学习库,它建立在NumPy、SciPy和Matplotlib这些…...

CAS-ViT实战:使用CAS-ViT实现图像分类任务(一)
摘要 在视觉转换器(Vision Transformers, ViTs)领域,随着技术的不断发展,研究者们不断探索如何在保持高效性能的同时,降低模型的计算复杂度,以满足资源受限场景(如移动设备)的需求。…...

处理数组下标的代码
以下是某个Ada编译器生成的一段汇编代码: mov ecx, eaxmov ebx, eaxsar ebx, 1Fhmov edx, ebxsar edx, 1Fhnot edxmov eax, edxsar eax, 1Fhand ecx, eax以上代码相当于以下C代码: ecx ((~(eax >> 62) >&…...

数学建模算法总结
数学建模常见算法总结 评价决策类模型 层次分析法 层次分析法根据问题的性质和要达到的总目的,将问题分解为不同的组成因素,并按照因素间的相互关联影响以及隶属关系将因素按不同层次聚集组合,形成一个多层次的分析结构模型,从…...

代码随想录算法训练营第五十五天 | 并查集理论基础、107. 寻找存在的路径
一、并查集理论基础 文章链接:并查集理论基础 | 代码随想录 (programmercarl.com) 二、107. 寻找存在的路径 题目连接:107. 寻找存在的路径 (kamacoder.com) 文章讲解:代码随想录 (programmercarl.com)——107. 寻找存在的路径...

ROS_package 、CMakeLists.txt、package.xml、ROS_node之间的关系
一、整体框架结构 二、关系描述 1、ROS.cpp 里面初始化了一个ROS节点,注意我的源文件里面只初始化了一个节点 // ROS.cpp #include "ros/ros.h"int main(int argc, char **argv) {ros::init(argc, argv, "node_name"); // 指定节点名称为 &…...

嵌入式学习----网络通信之TCP协议通信
TCP(即传输控制协议):是一种面向连接的传输层协议,它能提供高可靠性通信(即数 据无误、数据无丢失、数据无失序、数据无重复到达的通信) 适用情况: 1. 适合于对传输质量要求较高,以及传输大量数据 的通信。…...
×c的值)
【信息学奥赛一本通】1007:计算(a+b)×c的值
1007:计算(ab)c的值 时间限制: 1000 ms 内存限制: 65536 KB 提交数:184662 通过数: 150473 【题目描述】 给定3个整数a、b、c,计算表达式(ab)c的值。 【输入】 输入仅一行,包括三个整数a、b、c, 数与数之间以一个空格分开。(-10,…...

Linux系统之部署俄罗斯方块网页小游戏(三)
Linux系统之部署俄罗斯方块网页小游戏(三) 一、小游戏介绍1.1 小游戏简介1.2 项目预览二、本次实践介绍2.1 本地环境规划2.2 本次实践介绍三、检查本地环境3.1 检查系统版本3.2 检查系统内核版本3.3 检查软件源四、安装Apache24.1 安装Apache2软件4.2 启动apache2服务4.3 查看…...

XSS- - - DOM 破坏案例与靶场
目录 链接靶场: 第一关 Ma Spaghet 第二关 Jefff 第三关 Ugandan Knuckles 第四关 Ricardo Milos 第五关 Ah Thats Hawt 第六关 Ligma 第七关 Mafia 第八关 Ok, Boomer 链接靶场: XS…...

Arco Design,字节跳动出品的UI库
Arco Design是字节跳动出品的UI库,支持Vue和React。还是比较美观的。并且Arco Design还提供了中后台模版。但是通过提供的arco-cli连接了github,正常情况下无法构建。但效果还是挺好的,下面是效果图: 更新: 传送门可…...

常用API:object
文章目录 Object类toString()方法equals()方法总结其他方法 黑马学习笔记 Object类 是所有类的父类,所有的类都默认继承Object类。Java中所有的类的对象都可以直接使用Object类提供的一些方法。 toString()方法 equals()方法 默认是判断两个对象的地址 也是判断…...

LTspice仿真波形图看不清?这4个隐藏操作技巧让你效率翻倍
LTspice波形分析进阶指南:4个被低估的高效操作技巧 当电路仿真结果呈现在眼前时,多数用户会本能地拖动鼠标进行粗略查看。但真正的高手知道,波形分析阶段的细微操作差异,往往决定了问题定位的效率与设计迭代的速度。本文将揭示那些…...

技术人的“薪资锚点”策略:第一个报价为什么至关重要?
被低估的“第一印象”在软件测试领域,技术人习惯于与代码、逻辑和数据打交道,往往将薪资谈判视为一种非理性的“讨价还价”。然而,从行为经济学的视角审视,谈判的开局瞬间,其实已经为最终结果划定了无形的边界。那个最…...

3步完成HTML网页到Figma设计稿的终极转换指南
3步完成HTML网页到Figma设计稿的终极转换指南 【免费下载链接】figma-html Convert any website to editable Figma designs 项目地址: https://gitcode.com/gh_mirrors/fi/figma-html HTML转Figma工具是一个革命性的开源Chrome扩展程序,它能够将任何网页瞬间…...

利用Taotoken为内部知识库构建智能检索与摘要Agent
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken为内部知识库构建智能检索与摘要Agent 企业内部知识库的文档数量日益增长,员工在查找关键信息和快速理解文…...

Ganache 快速启动与 Truffle 项目集成实战
1. 为什么选择Ganache作为开发起点 刚接触区块链开发时,最头疼的就是如何在本地快速搭建测试环境。以太坊主网不仅需要真实ETH,每笔交易还要等待区块确认,完全不适合开发调试。这时候Ganache就像个贴心的开发助手,它能在本地一键生…...

AI应用网关ai-proxy:统一管理多模型API调用,实现路由、缓存与限流
1. 项目概述:一个为AI应用量身打造的智能代理网关如果你正在开发或部署基于大语言模型(LLM)的应用,比如一个聊天机器人、一个代码助手,或者一个内容生成工具,那么你大概率会遇到一个头疼的问题:…...

【Unity进阶实战】将PC端EXE打包与压缩一体化:从项目设置到单文件发布
1. Unity项目打包前的关键设置 第一次用Unity打包PC端应用时,我踩过不少坑。记得有个项目打包后死活运行不起来,折腾半天才发现是场景没正确添加。所以打包前的准备工作特别重要,咱们一步步来。 打开Build Settings窗口(File >…...

赛博朋克风格商业变现闭环:从DALL·E对比测试到Fiverr接单模板,7天打造高单价AI艺术IP
更多请点击: https://intelliparadigm.com 第一章:赛博朋克视觉语法与AI艺术IP的神经接口 赛博朋克视觉语法并非仅关乎霓虹、雨巷与义体——它是一套高度结构化的符号系统,其色彩模型(如青紫-品红双主调)、构图逻辑&a…...

AI智能体安全防护实战:基于AgentGuard构建可控Agent安全护栏
1. 项目概述:当AI智能体需要“安全护栏”最近在折腾AI智能体(Agent)的开发,一个绕不开的痛点就是“安全性”。我们费尽心思调教出一个能自主规划、调用工具、执行任务的智能体,结果它可能在用户一个刁钻的提问下&#…...

从理论到实践:深入解析STD激光SLAM回环检测算法的核心原理与实现
1. 为什么需要STD激光SLAM回环检测? 第一次接触激光SLAM的朋友可能会问:机器人建好的地图为什么会出现"漂移"?这个问题就像我们蒙着眼睛在操场上走路,走着走着就会偏离直线。激光SLAM系统在长时间运行时,由于…...