Linux入门——08 进程间通讯——管道
1.进程间通讯
1.1什么是通讯
- 进程具有独立性(每个进程都有自己的PCB,独立地址空间,页表)
- 但是要进行进程的通信,通信的成本一定不低,打破了独立性
进程间通信目的
- 数据传输:一个进程需要将它的数据发送给另一个进程
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
1.2为什么要有通讯
- 有时候需要多进程协同,完成某种业务! cat file | grep 'hello' //管道
1.3如何进行进程间通讯
两种通信方式
- System V进程间通信------聚焦在本地通信(共享内存,信号量,消息队列)(被主流排斥了)
- POSIX进程间通信-------让通讯过程可以跨主机(消息队列,共享内存,信号量,互斥量,条件变量,读写锁)
- 管道---------基于文件标准(匿名管道,命名管道)
1.3.1管道
管道是Unix中最古老的进程间通信的形式。我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”

该如何理解通讯的本质?
要把一个进程的数据保留到一个地方,让 另一个进程去读取,这个地方必须要第三方提供,不能是进程,进程是具有独立性的。
第三方就是操作系统,直接或间接为进程通讯提供”内存空间“
要通讯的进程,必须想看到一份公共的资源(OS直接或间接提供)
不同的通讯种类
本质就是:上面所说的资源,是OS中的哪一个模块提供的!
如果i这个资源是文件体统提供的就叫这种通讯为管道
通讯的成本:
- 1.把必须让不同的进程看到同一份资源
- 2.然后通讯
任何一个文件都有自己的操作方法和属于自己的内核缓冲区(struct Page{}缓冲区)
此时我们再看父子进程,他们两个是不是共同看到了同一份资源。是由文件管理系统提供的。
父进程 向文件缓冲区内写入,子进程向文件缓冲区内读取(这就是一个进程向文件中写数据,另一个进程向文件中读数据)
我们把这种通过文件的方式完成进程间的通讯的方式叫管道,操作系统提的内核级文件称为管道文件(本质就是文件)。
具有缓冲区就是为了不让文件再写入磁盘,再让另一个进程去磁盘里面读取,这样效率太慢了,需要在磁盘内存在该文件,
可以直接让OS创建struct file,只需要struct file的地址填入进程描述符表中就可以了,然后父进程创建子进程,拷贝文件描述符表,父子进程就可以直接在内存中进行通讯。
得到管道是内存级文件(不需要磁盘刷新)
如何让两个进程看到同一个管道文件呢?
fork创建子进程完成的。父子进程使用同一个文件描述符表
1.3.2匿名管道
前面我们说的管道文件,没有名称,所以称为匿名管道!
(pipe)管道函数

创建成功返回0,失败返回-1
int pipe(int pipefd[2]);//pipefd[2] 为输出型参数
调用pipe的时候,操作系统内部,帮你打开对应的文件(读和写的方式,同一个文件打开两次,得到两个文件描述符),填充到你当前进程的文件描述符表中,
然后把文件描述符表中的对应数组下标传给pipefd[2],这样就以读和写的方式,分别打开了同一文件#include <iostream>
#include <unistd.h>
#include <cassert>
#include <sys/types.h>
#include <sys/wait.h>
#include <string>
#include <cstdio>
#include <cstring>int main()
{// 1.创建管道通讯int fds[2];int n = pipe(fds);assert(n == 0);std::cout << "fds[0]:" << fds[0] << std::endl;std::cout << "fds[1]:" << fds[1] << std::endl;// 父进程读取,子进程写入// 2.fork()pid_t id = fork();assert(id >= 0);if(id == 0) //子进程{//子进程的通讯//子进程关闭读的描述符[0]close(fds[0]);//string msg = "hello,i am child!";const char *s = "我是子进程,我正在给你发消息";int cnt = 0;while(true){char buffer[1024];//只有子进程能看到!snprintf(buffer,sizeof(buffer),"child->parent say:%s[%d][%d]",s,cnt,getpid());// snprintf(buffer,sizeof(buffer),"child->parent say:[%d][%d]",cnt,getpid());write(fds[1],buffer,strlen(buffer)); //不用+1,\0只是在C语言中,这是系统sleep(1);//细节,我每隔1s写一次cnt ++;}exit(0);}//父进程的通讯代码//父进程关闭写的描述符[1]close(fds[1]);while(true){char buffer[1024]; //只有父进程能看到//ssize_t s = read(fds[0],buffer,sizeof(buffer)-1); //把读到的数据当作字符串来处理//这里用sizeof(buffer)//read 函数返回的是读取的字节数,如果读取成功,则返回值大于 0。//在读取前,需要清空 buffer 数组,以避免读取到之前的残留数据。//在判断是否有数据可读时,你使用了 strlen(buffer)-1,这可能导致读取的数据长度为负数,//因为 buffer 数组未初始化。应该使用 sizeof(buffer)。if(s > 0) buffer[s] = 0; //主动添加反斜杠0std::cout << "Get Message#" << buffer <<" | My Pid:"<< getpid() <<std::endl;//细节:父进程没有sleep}n = waitpid(id,nullptr,0);assert(n == id);return 0;}
//谁读谁写
fds[0]:3 ---》下标0对应读取0对应嘴(读)
fds[1]:4 ---》下标1对应写入1对应笔(写)管道的四种情况:
- 读慢写快
在进程通讯的时候,故意让子进程写的慢,sleep了一下,但当sleep的时间变长的时候,父进程读取的时间也变长,
那么在父进程读取前的时间,他在干什么?他在读取,read是一种阻塞,如果管道中没有了数据,读端在读,默认会直接阻塞当前正在读取的进程
- 读快写慢
相反 ,如果让子进程不sleep,父进程sleep(500);让子进程不断向管道中写,管道的总容量是有大小的,固定大小,
当写端向缓冲区写满的时候,写端会进入阻塞,等读端进行读取。缓冲区的数据不会被覆盖。
缓冲区的读写特点
当缓冲区有很多数据的时候,看似是一行一行写入,一行一行读取,其实是以二进制的形式指定大小进行读取
- 写关闭,读端读到0也会关闭。
当子进程写一条消息,直接break,这时写端的文件描述符已经关闭,只有读端还在读。总会过一段时间,将管道内的数据读完。
当读到0个字符的时候,将读的管道也关闭,读是为写作服务的,没有了写,读也没有意义。
- 读关闭,写就没有意义了,浪费资源,所以OS会给写进程发信号,终止写端!
1.3.3总结管道的特征
1.管道的生命周期进程就是进程的周期
2.管道可以用来进行具有血缘关系的进程之间的进程通信,常用于父子通讯。
3.管道是面向字节流的(网络部分)
4.半双工 ------ 单向通讯(特殊情况)
5.互斥与同步机制--------对共享资源进行保护的方案
1.4命名管道 两个没有血缘关系进程之间的通讯。
- 命令行命令 mkfifo

mkfifo name_pipe
出现以p开头的文件管道,
这个文件的特点,可以一个进程进行写入,另一个进程从管道中读取
ls > named_pipe //一个终端写
cat < named_pipe //另一个终端读
这是命令行式的两进程之间的管道通讯.但是管道文件的内容大小为0
- 当打开同一个文件两次,操作系统不会给我们创建两个struct file对象,而是公用一个对象。
- 这时候向这个文件写,并不会保存到磁盘,而是在内存让另一个线程去读取,这不就是一个管道吗。
请问命名管道,让把不同的进程看到同一文件呢?
- 让不同的进程,打开指定名称(路径+文件名(唯一性))的同一个文件。
- 这就是命名管道的规则,可以通过名字来标志唯一性的。
- 匿名管道是通过继承,继承地址,来保证唯一性的

-
mkfifo()函数创建有名管道

#include
#include
int mkfifo(constchar *filename, mode_t mode);
open(constchar *path, O_RDONLY);//1
open(constchar *path, O_RDONLY | O_NONBLOCK);//2
open(constchar *path, O_WRONLY);//3
open(constchar *path, O_WRONLY | O_NONBLOCK);//4
尽量使用阻塞方式打开
特点:
1有名管道可以使非亲缘的两个进程互相通信
2通过路径名来操作,在文件系统中可见,但内容存放在内存中
3 文件IO来操作有名管道
4 遵循先进先出规则
5 不支持leek操作
6 单工读写
注意事项:
1 程序不能以O_RDWR(读写)模式打开FIFO文件进行读写操作,而其行为也未明确定义,因为如一个管道以读/写方式打开,进程可以读回自己的输出,同时我们通常使用FIFO只是为了单向的数据传递
2 第二个参数中的选项O_NONBLOCK,选项O_NONBLOCK表示非阻塞,加上这个选项后,表示open调用是非阻塞的,如果没有这个选项,则表示open调用是阻塞的
3 对于以只读方式(O_RDONLY)打开的FIFO文件,如果open调用是阻塞的(即第二个参数为O_RDONLY),除非有一个进程以写方式打开同一个FIFO,否则它不会返回;如果open调用是非阻塞的的(即第二个参数为O_RDONLY | O_NONBLOCK),则即使没有其他进程以写方式打开同一个FIFO文件,open调用将成功并立即返回。
对于以只写方式(O_WRONLY)打开的FIFO文件,如果open调用是阻塞的(即第二个参数为O_WRONLY),open调用将被阻塞,直到有一个进程以只读方式打开同一个FIFO文件为止;如果open调用是非阻塞的(即第二个参数为O_WRONLY | O_NONBLOCK),open总会立即返回,但如果没有其他进程以只读方式打开同一个FIFO文件,open调用将返回-1,并且FIFO也不会被打开。
4.数据完整性,如果有多个进程写同一个管道,使用O_WRONLY方式打开管道,如果写入的数据长度小于等于PIPE_BUF(4K),那么或者写入全部字节,或者一个字节都不写入,系统就可以确保数据决不会交错在一起。
1.5实现命名管道的通讯
1.5.1comm.hpp
#ifndef COMM_HPP
#define COMM_HPP
#include <iostream>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <cassert>
#include <cerrno>
#include <unistd.h>
#include <fcntl.h>#define NAMED_PIPE "/home/lin/Desktop/Linux_learn/named_pipe/mypipe.lin"bool creatFifo(const std::string &path)
{umask(0);int n = mkfifo(path.c_str(),0666);if(n == 0) return true;else{std::cout<< "errno:"<< errno << "err string:" << strerror(errno) << std::endl;return false;}
}void removeFifo(const std::string &path)
{int n = unlink(path.c_str());//assert不要乱用,意料之中用assert,意料之外用if判断assert(n == 0); //debbug时是有效的,release的时候就没有了。//如果在release的时候,这个n就没有被使用,会walling ,加一个强制类型转换,会避免报错(void)n;
}#endif1.5.2client.cc
#include "comm.hpp"int main()
{std::cout << "client begin"<< std::endl;int wfd = open(NAMED_PIPE,O_WRONLY);std::cout << "client end"<< std::endl;if(wfd <0 ){exit(1); }//写char buffer[1024];while (true){std::cout << "Please Saying#";fgets(buffer,sizeof(buffer),stdin);//if(strlen(buffer)>0) buffer[strlen(buffer) - 1] = 0; ssize_t n = write(wfd,buffer,strlen(buffer) );assert(n == strlen(buffer));(void)n;}close(wfd);removeFifo(NAMED_PIPE);return 0;
}1.5.3server.cc
#include "comm.hpp"int main()
{bool r = creatFifo(NAMED_PIPE);assert(r);(void)r;std::cout << "server begin"<< std::endl;int rfd = open(NAMED_PIPE,O_RDONLY);std::cout << "server end"<< std::endl;if(rfd <0 ){exit(1); }//读取char buffer[1024];while(true){ssize_t s = read(rfd,buffer,sizeof(buffer));if(s > 0){buffer[s] = 0;std::cout << "client->server#"<< buffer;}else if(s == 0){std::cout << "client quit,me too!" << std::endl;}else{std::cout << "err string" << strerror(errno) << std::endl; }}close(rfd);removeFifo(NAMED_PIPE);return 0;
}相关文章:
Linux入门——08 进程间通讯——管道
1.进程间通讯 1.1什么是通讯 进程具有独立性(每个进程都有自己的PCB,独立地址空间,页表)但是要进行进程的通信,通信的成本一定不低,打破了独立性 进程间通信目的 数据传输:一个进程需要将它的数据发送给…...

深入探讨SD NAND的SD模式与SPI模式初始化
在嵌入式系统和存储解决方案中,SD NAND的广泛应用是显而易见的。CS创世推出的SD NAND支持SD模式和SPI模式,这两种模式在功能和实现上各有优劣。在本文中,我们将深入探讨这两种模式的初始化过程,并比较它们在不同应用场景下的优劣&…...

【jvm】栈和堆的区别
目录 1. 用途2. 线程共享性3. 内存分配和回收4. 生命周期5. 性能特点 1. 用途 1.堆:主要用于存储对象实例和数组。在Java中,所有通过new关键字创建的对象都会被分配到堆上。堆是一个大的内存池,用于存储所有的Java对象,包括实例变…...

智能的意义是降低世界的不确定性
世界充满着不确定性,而智能天生就追求一定的确定性,因为不确定性会危及智能的生存。智能本身是一种有序、相对确定的结构产生的,虽然也有一定的不确定性,而且这些不确定性有利于智能的进化,但是,相对而言&a…...

python实现指数平滑法进行时间序列预测
python实现指数平滑法进行时间序列预测 一、指数平滑法定义 1、指数平滑法是一种常用的时间序列预测算法,有一次、二次和三次平滑,通过加权系数来调整历史数据权重; 2、主要思想是:预测值是以前观测值的加权和,且对不同的数据给予不同的权数,新数据给予较大的权数,旧数…...

linux文件——用户缓冲区——概念深度探索、IO模拟实现
前言:本篇文章主要讲解文件缓冲区。 讲解的方式是通过抛出问题, 然后通过分析问题, 将缓冲区的概念与原理一步一步地讲解。同时, 本节内容在最后一部分还会带友友们模拟实现一下c语言的printf, fprintf接口,…...

Hive3:常用查询语句整理
一、数据准备 建库 CREATE DATABASE itheima; USE itheima;订单表元数据 1 1000000 100058 6 -1 509.52 0.00 28155.40 499.33 0 0 lisi shanghai 157 2019-06-22 17:28:15 2019-06-22 17:28:15 1 2 5000000 100061 72 -1 503.86 0.00 38548.00 503.86 1 0 zhangsan shangha…...
Ubuntu下载安装教程|Ubuntu最新长期支持(LTS)版本24.04 LTS下载安装
安装Ubuntu Ubuntu最新长期支持(LTS)版本24.04 LTS Ubuntu 24.04 LTS | 概览 Ubuntu长期支持(LTS)版本,LTS意为“长期支持”,一般为5年。LTS版本将提供免费安全和维护更新至 2029年4月。 Ubuntu 24.04 LTS(代号“Noble Numbat”,…...

通知:《自然语言及语音处理设计开发工程师》即将开课!
自然语言及语音处理设计开发工程师:未来职业的黄金选择 下面我们来看看证书颁发的背景: 为进一步贯彻落实中共中央印发《关于深化人才发展体制机制改革的意见》和国务院印发《关于“十四五”数字经济发展规划》等有关工作的部署要求,深入实…...

Vim youcompleteme Windows 安装保姆级教程
不说废话。 准备 检查 Vim 的 Python 配置 安装好 vim 和 python 后(python 必须 ≥ \ge ≥ 3.6),在 cmd 下运行 vim --version会弹出以下窗口。 如果发现 python/dyn 和 python3/dyn 都是 - (我不知道只有前者是 能不能运行…...

港迪技术IPO提交注册,拟募资6.56亿元
武汉港迪技术股份有限公司(下称“港迪技术”)拟在创业板IPO上市,并于近期在深交所提交招股书(注册稿),进入提交注册阶段。 港迪技术IPO招股书(注册稿)显示,公司是一家专…...
下使用tensorrt(c++)部署)
retinaface在ubuntu20.04(wsl2)下使用tensorrt(c++)部署
1. 参考博客: 1. Retinaface Tensorrt Python/C部署:https://blog.csdn.net/weixin_45747759/article/details/124534079 2. B站视频教程:https://www.bilibili.com/video/BV1Nv4y1K727/ 3. Retinaface_…...

vue打包设置 自定义的NODE_ENV
默认NODE_ENV 自定义process.env.NODE_ENV的值_process.node.env的值-CSDN博客 NODE_ENV开发环境下:NODE_ENVdevelopment(默认) 生产环境下:NODE_ENVproduction(默认) NODE_ENV 除了默认的 development 和 production 以外,确实可以自定义…...

python爬虫521
爬虫521 记录 记录 最近想学爬虫,尝试爬取自己账号下的文章标题做个词云 csdn有反爬机制 原理我就不说啦 大家都写了 看到大家结果是加cookie 但是我加了还是521报错 尝试再加了referer 就成功了(╹▽╹) import matplotlib import requests from wordcloud impor…...

CSS中flex:1是什么属性
flex: 1 是 CSS 中的一个简写属性,用于设置 Flex 项目的灵活伸缩比例(flex-grow)、收缩比例(flex-shrink)以及基础大小(flex-basis)。具体来说,flex: 1 实际上是以下三个属性的简写&…...

网络硬件升级指南:提升性能的策略与实践
随着企业对网络依赖程度的增加,网络性能的提升已成为信息技术部门的首要任务。本文将探讨如何通过升级网络硬件来提高网络性能,包括选择正确的硬件、实施升级策略和考虑未来网络的可扩展性。 一、网络性能的重要性 在数字化时代,网络是企业…...
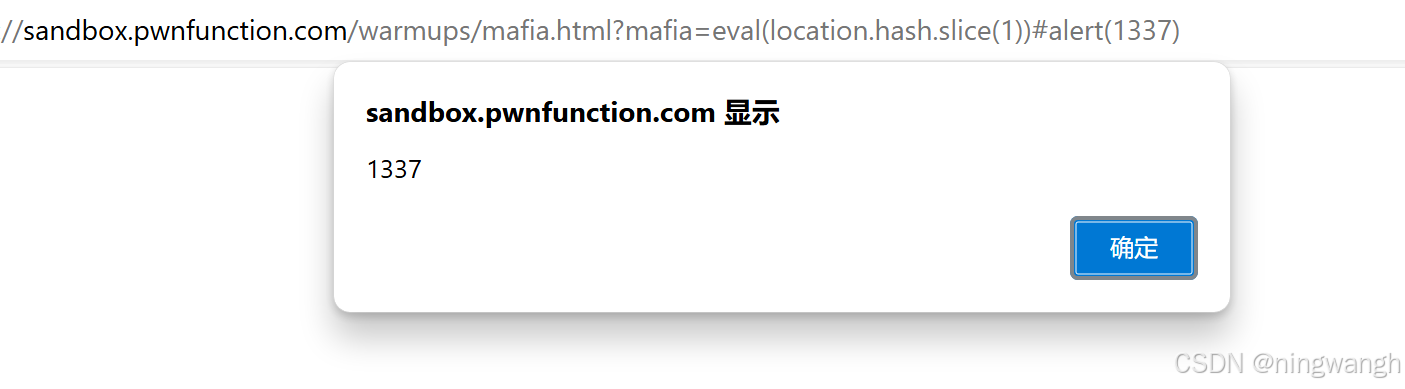
XSS-过滤特殊符号的正则绕过
目录 靶场练习地址:https://xss.pwnfunction.com/ 题目源码: 代码分析: 方法一:匿名函数 方法二:使用eval函数绕过限制 示例: 方法三:利用hash绕过 靶场练习地址:https://xs…...

CocosCreator3.8 IOS 构建插屏无法去除的解决方案
CocosCreator3.8 IOS 构建插屏无法去除的解决方案 在实际项目开发过程中,我们通常无需CocosCreator 自带的插屏,一般采用自定义加载页面。 然后在构建IOS 项目时,启用(禁用)插屏无法操作,如下图所示&#…...

Linux软件编程---数据库
目录 一、数据库 1.1.概念 1.2.类型 1.关系型数据库 2.非关系型数据库 1.3.SQL语言 1.4.如何在Linux安装sqlite数据库 1.确保虚拟机可以上网 2.配置apt-get工具集合 3.安装sqlite数据库 1.5.sqlite3 1.创建数据库 2.查看数据表 3.退出数据库 4.SQL语句 二、数…...

Spring 源码解读专栏:从零到一深度掌握 Spring 框架
前言 Spring 是 Java 世界中无可争议的王者框架,它以其灵活、轻量、强大而著称,成为企业级开发的首选工具。然而,很多开发者在使用 Spring 时,往往只停留在会用的层面,对于其内部实现和设计原理知之甚少。本专栏旨在通…...

懒人必备!OpenClaw 汉化版一键配置上手教程
一、Windows 11 安装 OpenClaw 必看说明 OpenClaw(国内用户昵称"小龙虾")是一款广受欢迎的开源本地AI助手,GitHub星标数已超28万。它集成了多项实用功能:电脑自动操控、智能文件管理、浏览器自动化以及办公流程自动化等…...

Go语言集成Ollama本地大模型:gollama库实战指南
1. 项目概述:当Go语言遇上本地大模型如果你是一名Go语言开发者,同时又对本地运行的大型语言模型(LLM)感兴趣,那么你很可能已经感受到了两者之间的“次元壁”。一方面,Go以其简洁、高效和强大的并发能力&…...

用STM32 HAL库和MPU6050 DIY平衡小车:PID参数整定实战与小车‘站起来’的调试日记
STM32平衡小车PID调参实战:从剧烈抖动到稳定站立的调试手记 1. 平衡小车的核心挑战 当我第一次按下电源开关,看着这个小家伙像醉汉一样左右摇摆然后轰然倒下时,才真正理解到平衡控制的精妙之处。基于STM32和MPU6050的平衡小车项目,…...

你的显卡真的在干活吗?Pycharm里用这行代码快速验证PyTorch GPU加速是否生效
你的显卡真的在干活吗?Pycharm里用这行代码快速验证PyTorch GPU加速是否生效 当你在Pycharm中完成了PyTorch GPU版的安装,torch.cuda.is_available()也返回了True,是否就意味着GPU加速已经完美运行?现实情况往往比这复杂得多。很多…...

1 个开发技巧,餐饮小程序加载速度飙升 70%
对于餐饮小程序而言,加载速度直接决定用户留存——据调研,用户打开小程序后,若加载时间超过3秒,流失率会高达80%。很多餐饮门店的小程序,明明功能完善、设计美观,却因为加载缓慢,导致用户刚打开…...

FanControl完全指南:Windows风扇智能控制的终极解决方案
FanControl完全指南:Windows风扇智能控制的终极解决方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/…...

告别闪烁!用STM32和Multisim搞定LED PWM调光,从仿真到实战保姆级教程
从零构建无频闪LED调光系统:STM32硬件PWM与Multisim滤波电路全解析 当你在深夜伏案工作时,台灯突然出现肉眼可见的闪烁;当你在实验室观察培养样本时,光源的不稳定导致数据出现偏差——这些恼人的场景背后,往往隐藏着L…...

Taotoken用量看板如何让我们清晰掌握各模型消耗与团队使用习惯
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何让我们清晰掌握各模型消耗与团队使用习惯 作为团队管理者,在引入大模型能力支持业务开发时&#…...

半导体光刻OPC技术:稀疏模型到网格模型的转换实践
1. 光学邻近效应校正(OPC)技术演进背景在半导体制造的光刻工艺中,光学邻近效应校正(Optical Proximity Correction, OPC)是一项至关重要的分辨率增强技术。随着制程节点不断微缩至65nm以下,传统的光学模型面…...

算法联盟·全域数学公理体系下黑洞标量毛发与LVK引力波O4全维理论、求导、证明、计算、验证、分析
算法联盟全域数学公理体系下黑洞标量毛发与LVK引力波O4全维理论、求导、证明、计算、验证、分析 算法联盟 全域数学公理体系下黑洞标量毛发与 LVK 引力波O4 全维理论、求导、证明、计算、验证、分析 所属体系:算法联盟 ROOT 全域数学网格第一性原理(AI科…...