【深度学习】【分布式训练】Collective通信操作及Pytorch示例
相关博客
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
大模型时代,单机已经无法完成先进模型的训练和推理,分布式训练和推理将会是必然的选择。各类分布式训练和推断工具都会使用到Collective通信。网络上大多数的教程仅简单介绍这些操作的原理,没有代码示例来辅助理解。本文会介绍各类Collective通信操作,并展示pytorch中如何使用。
一、Collective通信操作
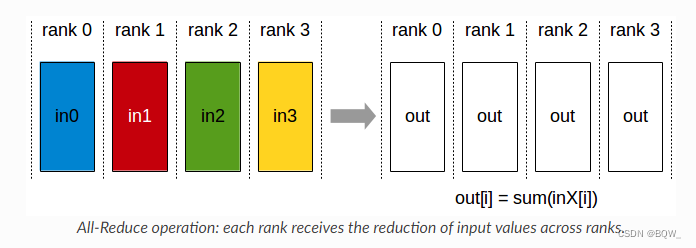
1. AllReduce
将各个显卡的张量进行聚合(sum、min、max)后,再将结果写回至各个显卡。
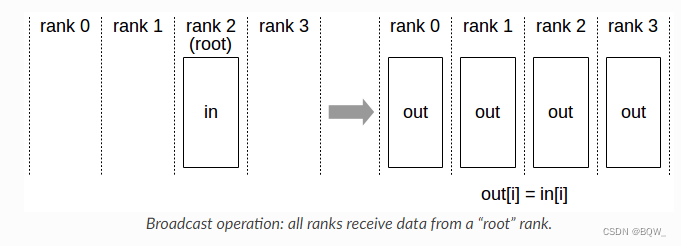
2. Broadcast
将张量从某张卡广播至所有卡。
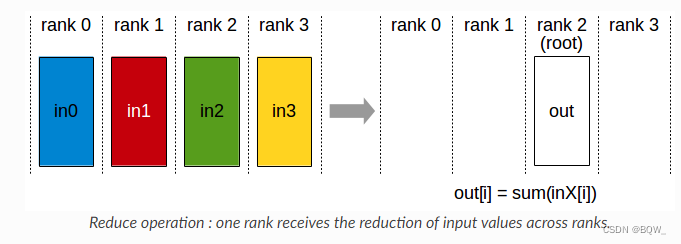
3. Reduce
执行同AllReduce相同的操作,但结果仅写入具有的某个显卡。
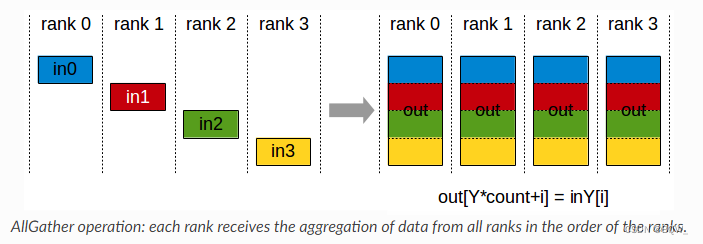
4. AllGather
每个显卡上有一个大小为N的张量,共有k个显卡。经过AllGather后将所有显卡上的张量合并为一个N×kN\times kN×k的张量,然后将结果分配至所有显卡上。
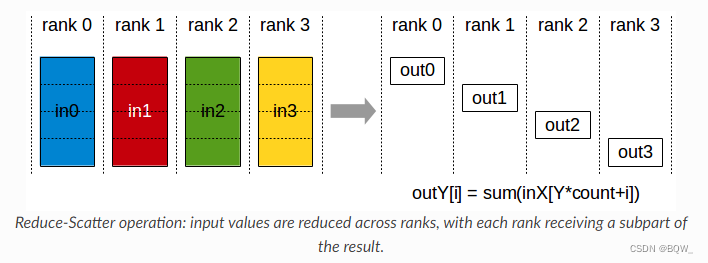
5. ReduceScatter
执行Reduce相同的操作,但是结果会被分散至不同的显卡。
二、Pytorch示例
pytorch的分布式包torch.distributed能够方便的实现跨进程和跨机器集群的并行计算。本文代码运行在单机双卡服务器上,并基于下面的模板来执行不同的分布式操作。
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mpdef init_process(rank, size, fn, backend='nccl'):"""为每个进程初始化分布式环境,保证相互之间可以通信,并调用函数fn。"""os.environ['MASTER_ADDR'] = '127.0.0.1'os.environ['MASTER_PORT'] = '29500'dist.init_process_group(backend, rank=rank, world_size=size)fn(rank, size)def run(world_size, func):"""启动world_size个进程,并执行函数func。"""processes = []mp.set_start_method("spawn")for rank in range(world_size):p = mp.Process(target=init_process, args=(rank, world_size, func))p.start()processes.append(p)for p in processes:p.join()if __name__ == "__main__":run(2, func) # 这里的func随后会被替换为不同的分布式示例函数pass
先对上面的模板做一些简单的介绍。
- 函数
run会根据传入的参数world_size,生成对应数量的进程。每个进程都会调用init_process来初始化分布式环境,并调用传入的分布式示例函数。 torch.distributed.init_process_group(),该方法负责各进程之间的初始协调,保证各进程都会与master进行握手。该方法在调用完成之前会一直阻塞,并且后续的所有操作都必须在该操作之后。调用该方法时需要初始化下面的4个环境变量:- MASTER_PORT:rank 0进程所在机器上的空闲端口;
- MASTER_ADDR:rank 0进程所在机器上的IP地址;
- WORLD_SIZE:进程总数;
- RANK:每个进程的RANK,所以每个进程知道其是否是master;
1. 点对点通信
在介绍其他collective通信之前,先看一个简单的点对点通信实现。
def p2p_block_func(rank, size):"""将rank src上的tensor发送至rank dst(阻塞)。"""src = 0dst = 1group = dist.new_group(list(range(size)))# 对于rank src,该tensor用于发送# 对于rank dst,该tensor用于接收tensor = torch.zeros(1).to(torch.device("cuda", rank))if rank == src:tensor += 1# 发送tensor([1.])# group指定了该操作所见进程的范围,默认情况下是整个worlddist.send(tensor=tensor, dst=1, group=group)elif rank == dst:# rank dst的tensor初始化为tensor([0.]),但接收后为tensor([1.])dist.recv(tensor=tensor, src=0, group=group)print('Rank ', rank, ' has data ', tensor)if __name__ == "__main__":run(2, p2p_block_func)
p2p_block_func实现从rank 0发送一个tensor([1.0])至rank 1,该操作在发送完成/接收完成之前都会阻塞。
下面是一个不阻塞的版本:
def p2p_unblock_func(rank, size):"""将rank src上的tensor发送至rank dst(非阻塞)。"""src = 0dst = 1group = dist.new_group(list(range(size)))tensor = torch.zeros(1).to(torch.device("cuda", rank))if rank == src:tensor += 1# 非阻塞发送req = dist.isend(tensor=tensor, dst=dst, group=group)print("Rank 0 started sending")elif rank == dst:# 非阻塞接收req = dist.irecv(tensor=tensor, src=src, group=group)print("Rank 1 started receiving")req.wait()print('Rank ', rank, ' has data ', tensor)if __name__ == "__main__":run(2, p2p_unblock_func)
p2p_unblock_func是非阻塞版本的点对点通信。使用非阻塞方法时,因为不知道数据何时送达,所以在req.wait()完成之前不要对发送/接收的tensor进行任何操作。
2. Broadcast
def broadcast_func(rank, size):src = 0group = dist.new_group(list(range(size)))if rank == src:# 对于rank src,初始化tensor([1.])tensor = torch.zeros(1).to(torch.device("cuda", rank)) + 1else:# 对于非rank src,初始化tensor([0.])tensor = torch.zeros(1).to(torch.device("cuda", rank))# 对于rank src,broadcast是发送;否则,则是接收dist.broadcast(tensor=tensor, src=0, group=group)print('Rank ', rank, ' has data ', tensor)if __name__ == "__main__":run(2, broadcast_func)
broadcast_func会将rank 0上的tensor([1.])广播至所有的rank上。
3. Reduce与Allreduce
def reduce_func(rank, size):dst = 1group = dist.new_group(list(range(size)))tensor = torch.ones(1).to(torch.device("cuda", rank))# 对于所有rank都会发送, 但仅有dst会接收求和的结果dist.reduce(tensor, dst=dst, op=dist.ReduceOp.SUM, group=group)print('Rank ', rank, ' has data ', tensor)if __name__ == "__main__":run(2, reduce_func)
reduce_func会对group中所有rank的tensor进行聚合,并将结果发送至rank dst。
def allreduce_func(rank, size):group = dist.new_group(list(range(size)))tensor = torch.ones(1).to(torch.device("cuda", rank))# tensor即用来发送,也用来接收dist.all_reduce(tensor, op=dist.ReduceOp.SUM, group=group)print('Rank ', rank, ' has data ', tensor)if __name__ == "__main__":run(2, allreduce_func)
allreduce_func将group中所有rank的tensor进行聚合,并将结果发送至group中的所有rank。
4. Gather与Allgather
def gather_func(rank, size):dst = 1group = dist.new_group(list(range(size)))# 该tensor用于发送tensor = torch.zeros(1).to(torch.device("cuda", rank)) + rankgather_list = []if rank == dst:# gather_list中的tensor数量应该是size个,用于接收其他rank发送来的tensorgather_list = [torch.zeros(1).to(torch.device("cuda", dst)) for _ in range(size)]# 仅在rank dst上需要指定gather_listdist.gather(tensor, gather_list=gather_list, dst=dst, group=group)else:# 非rank dst,相当于发送tensordist.gather(tensor, dst=dst, group=group)print('Rank ', rank, ' has data ', gather_list)if __name__ == "__main__":run(2, gather_func)
gather_func从group中所有rank上收集tensor,并发送至rank dst。(相当于不进行聚合操作的reduce)
def allgather_func(rank, size):group = dist.new_group(list(range(size)))# 该tensor用于发送tensor = torch.zeros(1).to(torch.device("cuda", rank)) + rank# gether_list用于接收各个rank发送来的tensorgather_list = [torch.zeros(1).to(torch.device("cuda", rank)) for _ in range(size)]dist.all_gather(gather_list, tensor, group=group)# 各个rank的gather_list均一致print('Rank ', rank, ' has data ', gather_list)if __name__ == "__main__":run(2, allgather_func)
allgather_func从group中所有rank上收集tensor,并将收集到的tensor发送至所有group中的rank。
5. Scatter与ReduceScatter
def scatter_func(rank, size):src = 0group = dist.new_group(list(range(size)))# 各个rank用于接收的tensortensor = torch.empty(1).to(torch.device("cuda", rank))if rank == src:# 在rank src上,将tensor_list中的tensor分发至不同的rank上# tensor_list:[tensor([1.]), tensor([2.])]tensor_list = [torch.tensor([i + 1], dtype=torch.float32).to(torch.device("cuda", rank)) for i in range(size)]# 将tensor_list发送至各个rank# 接收属于rank src的那部分tensordist.scatter(tensor, scatter_list=tensor_list, src=0, group=group)else:# 接收属于对应rank的tensordist.scatter(tensor, scatter_list=[], src=0, group=group)# 每个rank都拥有tensor_list中的一部分tensorprint('Rank ', rank, ' has data ', tensor)if __name__ == "__main__":run(2, scatter_func)
scatter_func会将rank src中的一组tensor逐个分发至其他rank上,每个rank持有的tensor不同。
def reduce_scatter_func(rank, size):group = dist.new_group(list(range(size)))# 用于接收的tensortensor = torch.empty(1).to(torch.device("cuda", rank))# 用于发送的tensor列表# 对于每个rank,有tensor_list=[tensor([0.]), tensor([1.])]tensor_list = [torch.Tensor([i]).to(torch.device("cuda", rank)) for i in range(size)]# step1. 经过reduce的操作会得到tensor列表[tensor([0.]), tensor([2.])]# step2. tensor列表[tensor([0.]), tensor([2.])]分发至各个rank# rank 0得到tensor([0.]),rank 1得到tensor([2.])dist.reduce_scatter(tensor, tensor_list, op=dist.ReduceOp.SUM, group=group)print('Rank ', rank, ' has data ', tensor)if __name__ == "__main__":run(2, reduce_scatter_func)
参考资料
https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/collectives.html
https://pytorch.org/tutorials/intermediate/dist_tuto.html#collective-communication
https://pytorch.org/docs/stable/distributed.html#collective-functions
相关文章:
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
相关博客 【深度学习】【分布式训练】Collective通信操作及Pytorch示例 【自然语言处理】【大模型】大语言模型BLOOM推理工具测试 【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型 【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介…...

Spring常用注解说明
目录 1.常用注解 2.特别说明 3.xml及注解方式 1.常用注解 (1) SpringBootApplication (2) ControllerRestControllerRequestMappingRequestParamPathVariableGetMappingPostMappingPutMappingDeleteMappingResponseBodyRequestBodyCrossOrigin (3) ConfigurationBeanServ…...
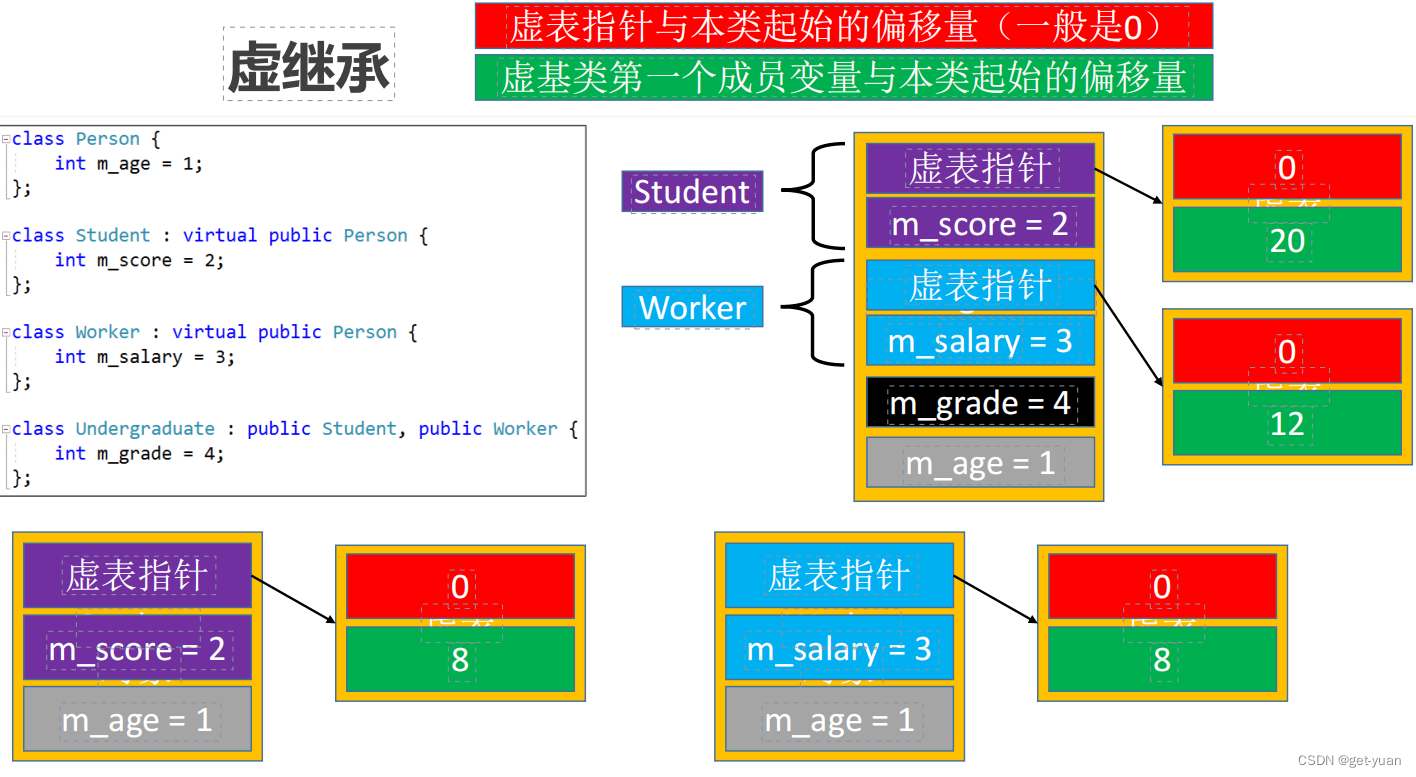
13-C++面向对象(纯虚函数(抽象类)、多继承、多继承-虚函数、菱形继承、虚继承、静态成员)
虚析构函数 存在父类指针指向子类对象的情况,应该将析构函数声明为虚函数(虚析构函数) 纯虚函数 纯虚函数:没有函数体且初始化为0的虚函数,用来定义接口规范 抽象类: 含有纯虚函数的类,不可以实…...
Android DataBinding 自定义View实现数据双向绑定
看不懂的可以先看看单向数据绑定:Android DataBinding数据变化时自动更新界面_皮皮高的博客-CSDN博客 然后再确定已经启动了dataBinding的情况下,按下面的顺序来: 首先创建一个自定义View: import android.content.Context imp…...

网络安全中的渗透测试主要那几个方面
渗透测试中主要有软件测试和渗透测试。 1、测试对象不同 软件测试:主要测试的是程序、数据、文档。 渗透测试:对象主要为网络设备、主机操作系统、数据库系统和应用系统。 2、测试内容不同 软件测试:主要工作内容是验证和确认,发…...
Cursor:GPT-4 驱动的强大代码编辑器
Cursor (https://www.cursor.so/)是 GPT-4 驱动的一款强大代码编辑器,可以辅助程序员进行日常的编码。下面通过一个实际的例子来展示 Cursor 如何帮助你编程。这个例子做的事情是网页抓取。抓取的目标是百度首页上的百度热搜,如下…...
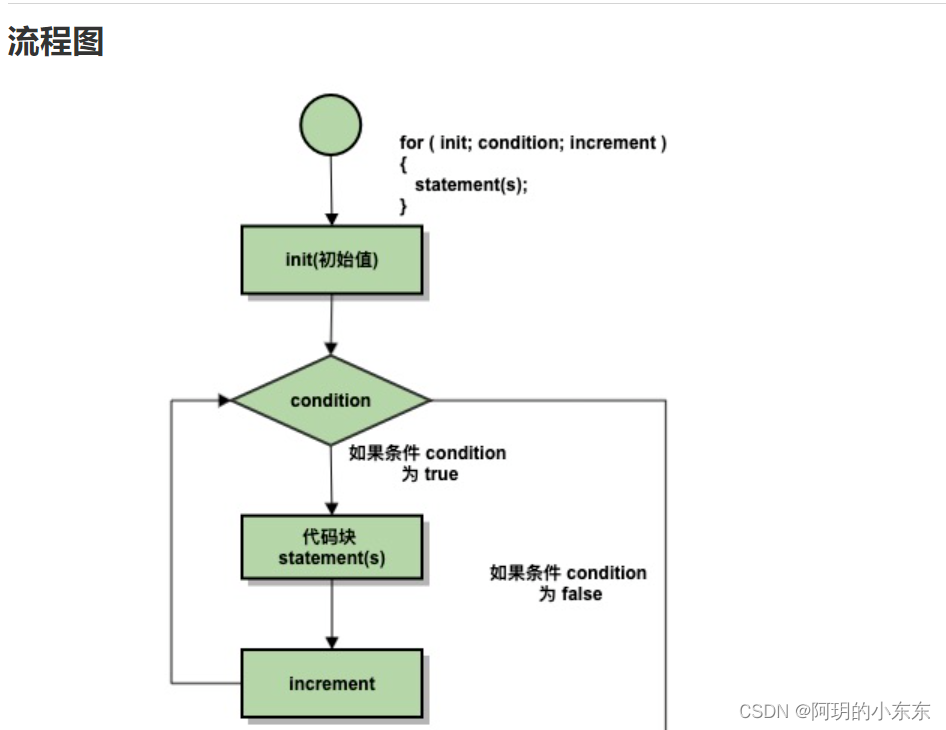
C/C++中for语句循环用法及练习
目录 语法 下面是 for 循环的控制流: 实例 基于范围的for循环(C11) 随堂笔记! C语言训练-计算1~N之间所有奇数之和 题目描述 输入格式 输出格式 样例输入 样例输出 环形方阵 干货直达 for 循环允许您编写一个执行特定次数的循环的重复控制结构。…...
AnimatorOverrideController说明
unity-AnimatorOverrideControllerhttps://docs.unity.cn/cn/current/ScriptReference/AnimatorOverrideController.html 用于控制动画器重写控制器的接口。 动画器重写控制器的用途是重写某个控制器的动画剪辑,从而为给定化身定制动画。 在运行时基于相同的 Anim…...

1.4、第三阶段 MySQL数据库
root数据库技术 一、数据库理论 1 什么是数据库技术 数据库技术主要研究如何组织、存储数据,并如何高效地提取和处理数据。 2 什么是SQL SQL(Structured Query Language)结构化查询语言 SQL是操作数据库的命令集,也是功能齐全的…...

LeetCode:202. 快乐数
🍎道阻且长,行则将至。🍓 🌻算法,不如说它是一种思考方式🍀算法专栏: 👉🏻123 一、🌱202. 快乐数 题目描述:编写一个算法来判断一个数 n 是不是快…...
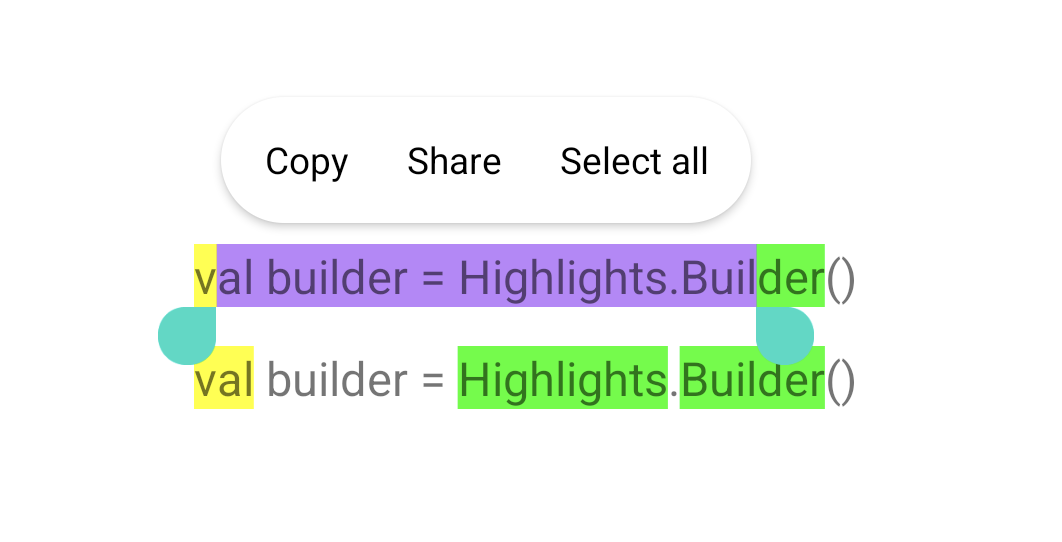
Android 14 新功能之 HighLights:快速实现文本高亮~
日常开发中可能会遇到给 TextView 的全部或部分文本增加高亮效果的需求,以前可能是通过 Spannable 或者 Html 标签实现。 升级 Android 14 后就不用这么迂回了,因其首次引入直接设置高亮的 API:HighLights。需要留意的是 HighLights API 和 …...
[渗透教程]-004-嗅探工具-Nmap
文章目录 Nmap介绍基本操作进阶操作Nmap介绍 nmap是一个网络扫描和主机检测工具,它可以帮助用户识别网络上的设备和服务。获取主机正在运行哪些服务,nmap支持多种扫描,UDP,TCP connect(),TCP SYN(半开扫描) ftp代理,反向标志,ICMP,FIN,ACK扫描,ftp代理,反向标志,ICMP. 可以用于…...
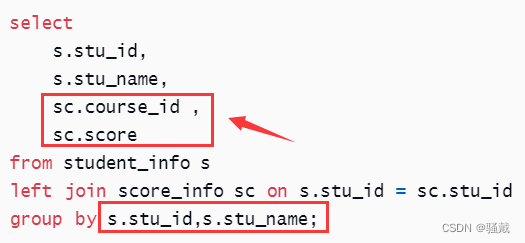
大数据技术之Hive SQL题库-初级
第一章环境准备1.1 建表语句hive>-- 创建学生表 DROP TABLE IF EXISTS student; create table if not exists student_info(stu_id string COMMENT 学生id,stu_name string COMMENT 学生姓名,birthday string COMMENT 出生日期,sex string COMMENT 性别 ) row format delim…...

常见HTTP状态码汇总
文章目录1xx: 信息2xx: 成功3xx: 重定向4xx: 客户端错误5xx: 服务器错误1xx: 信息 状态码描述100 Continue服务器仅接收到部分请求,但是一旦服务器并没有拒绝该请求,客户端应该继续发送其余的请求。101 Switching Protocols服务器转换协议:服…...

蓝桥杯刷题冲刺 | 倒计时15天
作者:指针不指南吗 专栏:蓝桥杯倒计时冲刺 🐾马上就要蓝桥杯了,最后的这几天尤为重要,不可懈怠哦🐾 文章目录1.年号字串2.裁纸刀3.猜生日1.年号字串 题目 链接: 年号字串 - 蓝桥云课 (lanqiao.c…...
【差分数组】
差分数组一维差分差分数组的作用差分矩阵结语一维差分 输入一个长度为 n 的整数序列。接下来输入 m个操作,每个操作包含三个整数 l,r,c,表示将序列中 [l,r] 之间的每个数加上 c ,请你输出进行完所有操作后的序列。 输入格式 第一行包含两个…...
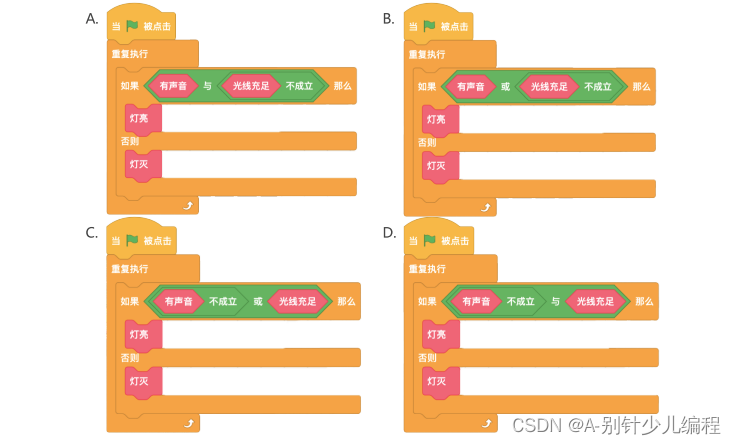
2022年NOC软件创意编程(学而思)决赛小学高年级组scratch
2022NOC决赛图形化小高组 一、选择题 1.运行下面的程序,最终“我的变量”的值是多少? 2.希望定义一个函数如下,可以让角色旋转指定的圈数。里面空缺的地方填上什么数字比较合适? 3.运行程序,在舞台上可以看见几个角色 ? 4.运行程序,角色会依次说什么 ? 5.我们都知…...
[JAVA]一步接一步的一起开发-图书管理系统(非常仔细,你一定能看懂)[1W字+]
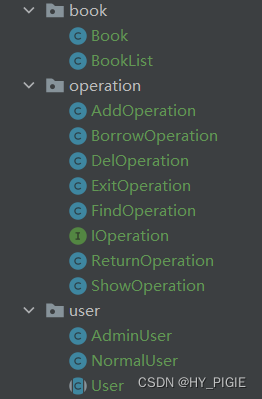
目录 1.想法 2.框架的搭构 2.1图书 2.1.1Book类 2.1.2BookList类 2.2用户 2.2.1User抽象类 2.2.2AdminUser类(管理者) 2.2.3NormalUser 2.3操作 操作接口 借阅操作 删除操作 查询操作 归还图书 展示图书 退出系统 2.4小结 3.主函数的编…...

大数据周会-本周学习内容总结07
目录 01【hadoop】 1.1【编写集群分发脚本xsync】 1.2【集群部署规划】 1.3【Hadoop集群启停脚本】 02【HDFS】 2.1【HDFS的API操作】 03【MapReduce】 3.1【P077- WordCount案例】 3.2【P097-自定义分区案例】 历史总结 01【hadoop】 1.1【编写集群分发脚本xsync】…...

搭建一个双系统个人服务器
搭建一个双系统个人服务器0.前言一、双系统安装1.磁盘划分2.windows安装3.ubuntu安装二、系统启动项美化:1. refind引导2. 美化 grub 界面三、系统代理0.前言 年后找了份工作,忙于适应新环境所以更新也减缓了,最近闲暇时间给个人电脑进行了整…...

手把手教你给老旧JLink V8“续命”:AT91-ISP搭配SAM-PROG刷机全记录
手把手教你给老旧JLink V8“续命”:AT91-ISP搭配SAM-PROG刷机全记录 当你的JLink V8突然罢工,电脑反复提示"无法识别的USB设备",先别急着给它判死刑。这款经典调试工具采用的AT91SAM7S64主控芯片,其实有着惊人的"复…...

OpenPose编辑器:解锁AI绘画中人体姿态的精准控制秘诀 [特殊字符]
OpenPose编辑器:解锁AI绘画中人体姿态的精准控制秘诀 🎨 【免费下载链接】openpose-editor Openpose Editor for AUTOMATIC1111s stable-diffusion-webui 项目地址: https://gitcode.com/gh_mirrors/op/openpose-editor 在AI绘画创作的世界里&…...

Tidal-Media-Downloader:3分钟掌握终极Tidal音乐下载方案
Tidal-Media-Downloader:3分钟掌握终极Tidal音乐下载方案 【免费下载链接】Tidal-Media-Downloader Download TIDAL Music On Windows/Linux/MacOs (PYTHON/C#) 项目地址: https://gitcode.com/gh_mirrors/ti/Tidal-Media-Downloader 还在为无法随时随地畅享…...

AI 会取代测试工程师吗?来看看最新“AI程序员”Devine的翻车现场
引言:一条被炒得过热的赛道 2024年3月,Cognition Labs发布了Devin——一款被官方冠以“世界首位AI软件工程师”头衔的产品。演示视频中,Devin自主浏览文档、编写代码、运行测试、提交PR,甚至能在Upwork上接单挣钱。资本市场迅速反应:Cognition Labs在A轮融资中拿到了2100…...

10个Tunasync配置技巧:从基础到高级应用
10个Tunasync配置技巧:从基础到高级应用 【免费下载链接】tunasync Mirror job management tool. 项目地址: https://gitcode.com/gh_mirrors/tu/tunasync Tunasync 是一款强大的镜像作业管理工具,能够帮助用户轻松配置和管理各种镜像同步任务。…...

如何在Windows系统中创建虚拟游戏手柄?vJoy开源项目完全指南
如何在Windows系统中创建虚拟游戏手柄?vJoy开源项目完全指南 【免费下载链接】vJoy Virtual Joystick 项目地址: https://gitcode.com/gh_mirrors/vj/vJoy 你是否曾因缺少物理游戏手柄而无法体验某些经典游戏?或者需要为专业软件创建自定义控制方…...

联想笔记本BIOS解锁神器:3分钟开启隐藏硬件性能
联想笔记本BIOS解锁神器:3分钟开启隐藏硬件性能 【免费下载链接】LEGION_Y7000Series_Insyde_Advanced_Settings_Tools 支持一键修改 Insyde BIOS 隐藏选项的小工具,例如关闭CFG LOCK、修改DVMT等等 项目地址: https://gitcode.com/gh_mirrors/le/LEGI…...

新手入门指南,五分钟完成Taotoken账号注册与第一个API调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手入门指南,五分钟完成Taotoken账号注册与第一个API调用 对于初次接触大模型API的开发者来说,如何快速上…...

MPV_lazy终极指南:3分钟打造专业级Windows视频播放体验
MPV_lazy终极指南:3分钟打造专业级Windows视频播放体验 【免费下载链接】mpv_PlayKit 🔄 mpv player 播放器折腾记录 Windows conf | 中文注释配置 汉化文档 快速帮助入门 | mpv-lazy 懒人包 Win11 x64 config | 着色器 shader 滤镜 filter 整合方案 项…...

为什么很多扩音设备总是啸叫?这块语音模组可能就是答案
做过扩音器、对讲机、会议设备的人,大概率都被这些问题折磨过:一开大音量就啸叫环境太吵听不清对讲时回音严重麦克风离远一点声音就没了最近看到一款 A-59F 语音处理模组,思路挺有意思。它把:AI降噪回音消除扩音防啸叫双麦定向拾音…...