高基数 GroupBy 在 SLS SQL 中的查询加速
作者:顾汉杰(执少)
什么是高基数 GroupBy
简单来说,想要分析的数据,拥有超多的“唯一值计数”(Distinct Count),而我们需要对这些数据进行分组分析(如统计次数、排名、计算均值、分位值等)。
高基数聚合计算在很多运营分析场景中都是刚需,它涉及对值不一样的海量数据进行分组聚合计算,以洞察用户行为、游戏玩家路径、市场趋势或产品表现等运营分析的关键指标。例如,在电商平台上,分析一段时间内不同商品类别在各个地区的销量分布,或者在游戏运营分析场景中,追踪玩家在游戏中的独特操作行为和路径,这些都需要处理基数极高的数据(如 ItemId、RequestId、TraceId 等,动辄上千万甚至亿级别的基数)。
现在的问题是,用户在进行此类分析时,由于数据量和复杂度的不同,SQL 执行耗时往往可能从数秒到数分钟甚至数小时不等,“高基数 GroupBy 执行太慢”,几乎成为用户的普遍认知,也是众多数据库和 OLAP 引擎重点关注的对象。SLS SQL 也持续关注这一点,并对此进行了相应的性能优化,本文即旨在向用户介绍 SLS 中的实现原理、查询加速手段以及适用场景。
GroupBy 的实现原理
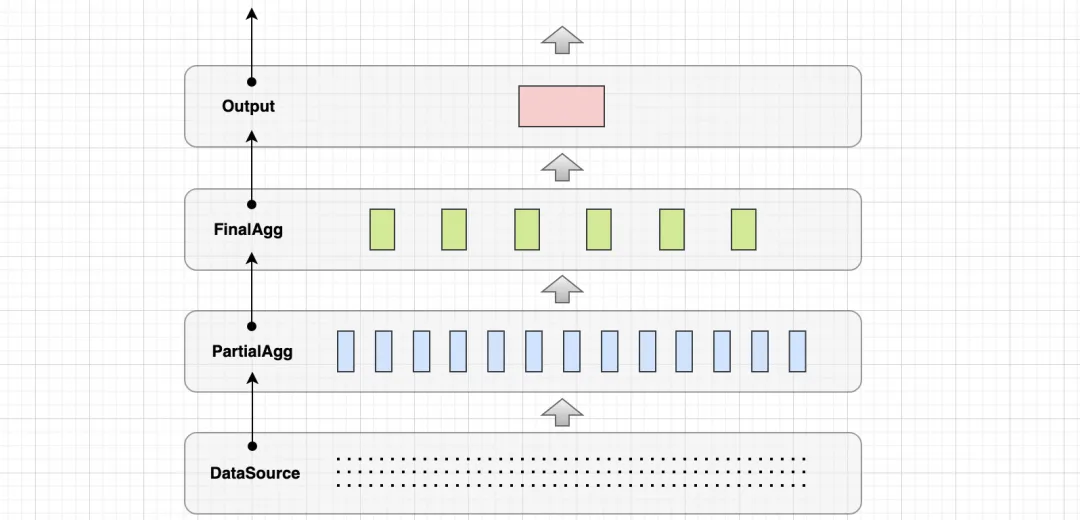
GroupBy 是几乎所有 OLAP 引擎必备的基础聚合能力,分布式计算引擎一般将海量数据以 Hash 散列的方式分布到不同节点进行分组(分桶)计算,每个分组内对数据进行聚合,然后再基于堆(往往使用 PriorityQueue)进行排序或 Limit,最终输出给用户需要的数据,比如 TopN 排行结果等。
这个过程中,我们可能还会用到预聚合技术:利用数据的局部性原理,对原始数据进行预聚合(PartialAgg),然后再发往最终聚合节点(FinalAgg),以减少网络间数据传输开销。
所以,总体来说,GroupBy 聚合计算大致会经历以下四个过程:DataSource -> PartialAgg -> FinalAgg -> Output。
其中,DataSource 和 PartialAgg 一般是绑定在一起执行,而 FinalAgg 以及 Output 则由分布式网络中的另外一些节点执行。
体验 SLS 高基数 GroupBy 查询加速
有了上面的基础知识和了解后,我们开门见山,直接带大家来感受一下 SLS 中的上亿级别高基数 GroupBy 的查询加速体验。
为了更客观地评估和分析下面的性能变化,我们必须先讲清楚我们的测试数据和测试用例情况。
测试数据
我们采用了模拟的类似 Nginx 服务访问日志,保存在一个 Project/Logstore 中,SQL独享版 CU 数设置为 5000。测试数据 Schema 如下:
{ RequestId: varchar, /*测试数据会确保每个请求ID确保全局唯一*/ ClientIP: varchar, Method: varchar, Latency: int, Status: int, ...}
测试用例
我们准备了 3 种测试用例,分别对应 3 种不同的业务分析场景:
- 高基单列聚合:对 28 亿条请求日志,按 RequestId 字段进行 GroupBy 统计计数(实际基数为 28 亿)
- 高基多列聚合:对 45 亿条请求日志,按 ClientIp、Status、Latency 字段进行 3 列 GroupBy 统计计数(实际基数为 15 亿)
- 低基数值聚合:对 1.5 万亿条请求日志,按 Latency 字段统计 Top100 的频次(实际基数为 735 万)
测试说明
- 由于我们系统中设计有多级缓存,为了避免缓存对于测试的影响干扰,我们会在每次查询时通过添加 not <不存在的keyword> 过滤条件来避开缓存,以确保每次查询都进行完整的物理执行,公平地对比整体执行性能。
- 测试过程使用的是真实线上服务(地域为上海),测试数据真实存储在 SLS Logstore 中,但因分片数以及数据分布特征不尽相同,因此不同用户的数据实测结果可能略有差异,但相同量级应该大同小异。
🚗 走,上车!
案例 1:
高基单列聚合,对 28 亿条请求日志,按 RequestId 字段进行 GroupBy 统计计数(实际基数为 28 亿)
第一步,进行基准测试,使用普通 SQL 模式,查询大约需要 17s。

第二步,切换到增强 SQL 模式,并设置 session 参数 set session hash_partition_count=40(此值默认最大为 20),查询降到 10s。
这是什么魔法操作?
上文提到底层并行度已经足够分散,但我们面对的是一个 28 亿条绝对高基的测试数据集(每一个 RequestId 都不一样),即使底层并行度足够,FinalAgg 阶段仍将面临极大的聚合计算压力,而我们默认 FinalAgg 阶段的并行度与 shard 分片数相关但最大为 20,这里我们将这个能力开放给用户结合自身情况可以进行动态调整。

第三步,设置 session 参数 set session hash_partition_count=64/128/200,查询进一步降到 7s/4.5s/3.7s。



加速效果还不错。。。
通过增加 FinalAgg 阶段的并行度,我们看到查询从原来的 17s 降低到了 3.7s!同时,我们也看到并行度的增加对于查询延时的加速效果也逐渐收敛,这是因为在增加并行度的同时,也增加了额外的网络通信和调度开销。所以我们为该 session 参数设置了系统上限为 200,再往上其实可能也不会带来太大的加速收益。
以为这样就收工了,并没有!
第四步,设置 session 参数 set session high_cardinality_agg=true,查询降到 2.1s!

这又是发生了什么?
针对高基数场景的数据特征,我们将数据在底层走了一个不同的流转模式进行数据聚合,大幅提高效率。我们同样开放了相应的 session 参数供用户按需使用。
最终,高基单列聚合,我们将查询从原来的 17s 降至 2s,体验到了 8 倍的加速快感。
案例 2:
高基多列聚合,对 45 亿条请求日志,进行多列 GroupBy 统计计数(实际多列组合维基为 15 亿)
第一步,进行基准测试,使用普通 SQL 模式,查询大约需要 24s。

第二步,切换到增强 SQL 模式,并设置 session 参数 set session hash_partition_count=40(此值默认最大为 20),查询降 到11s。

第三步,提升并行度 set session hash_partition_count=64/128/200,查询进一步降到 7.3s/5.9s/5.8s。



第四步,设置 session 参数 set session high_cardinality_agg=true,查询降到 2.9s!

最终,高基多列聚合,我们将查询从原来的 24s 降至 3s,同样也体验到了 8 倍的加速快感。
案例 3:
低基数值聚合,对 1.5 万亿条请求日志,按 Latency 字段统计 Top100 的频次(实际基数为 735 万)
第一步,进行基准测试,使用普通 SQL 模式,查询虽然只有 4.3s,但是因数据量大小限制被截断而结果不精确。

第二步,切换到增强 SQL 模式,查询只需 23.4s 即可精确查询,此时增强 SQL 体现出在面对超大规模数据量时的威力。

第三步,设置 session 参数 set session hash_partition_count=40/64/128/200(此值默认最大为 20),查询延时维持到 22-23s 之间,可以看到,在低基聚合场景中,通过提升 FinalAgg 并行度来加速查询,效果十分有限。
通过系统的监控分析,可以发现此时计算压力主要在 PartialAgg,FinalAgg 并不存在计算瓶颈,因此对它的提升,并不会对整体查询有明显的加速效果。




第四步,让我们再试试高基优化参数 set session high_cardinality_agg=true,结果是执行超时。
这说明,高基优化参数并不适用于低基聚合场景,在低基维度下,面对超大规模数据(测试数据超过 1.5 万亿)的聚合计算,默认的预聚合技术(PartialAgg+FinalAgg)能够有效发挥计算效能,仍然是不二之选。
结论和建议
本文主要介绍了 SLS 中的高基数 GroupBy 查询加速原理,并设计了 3 种典型场景的测试用例,通过 SLS 线上服务的实际测试表现,带大家体验了高基聚合计算 8 倍查询加速、万亿数据 20s 查询的极致快感。
在测试过程中,也一一向读者解释了其中的具体细节和原理,为什么会这样?为什么能加速?为什么加速不明显等等。以下是给 SLS 用户关于此方面的查询实践和建议:
- 数据规模不大时,使用默认模式即可;
- 数据规模很大而数据分片不多时,建议开启增强 SQL 模式,可以极大提升数据底层并行度;
- 高基聚合时,可以尝试以下两个 session 参数,可能带来数倍查询加速效果:
- set session hash_partition_count= 设置多少合适?建议 20-64 以内,过犹不及
- set session high_cardinality_agg=true/false 是否设置取决于数据离散度
- 低基聚合,以上两个 session 参数并不十分适用,通过默认增强 SQL 模式即可实现查询加速和精确。
相关文章:
高基数 GroupBy 在 SLS SQL 中的查询加速
作者:顾汉杰(执少) 什么是高基数 GroupBy 简单来说,想要分析的数据,拥有超多的“唯一值计数”(Distinct Count),而我们需要对这些数据进行分组分析(如统计次数、排名、…...

TP5队列和TP5 使用redis 等相关
TP5.thinkphp之门面(facade类)面试_thinkphp facade-CSDN博客 TP5中的消息队列_tp 5.0 队列 release 时间单位-CSDN博客 thinkphp-queue自带的队列包使用分析_php think queue:listen-CSDN博客TP5 使用redis_tp5 redis-CSDN博客...

【R语言速通】1.数据类型
文章目录 0. 变量名1.基本数据类型1.1 数值型1.2 整型1.3 复数型1.4 逻辑型1.5 字符型 2.复合数据类型2.1 向量向量操作向量的常用函数 2.2 矩阵矩阵操作矩阵的常用函数 2.3 数组数组的操作数据的运算数组的访问数组的维度操作 数组的常用函数 2.4 数据框数据框操作数据框的常用…...
创建型模式:单例模式)
【C++设计模式】(三)创建型模式:单例模式
文章目录 (三)创建型模式:单例模式饿汉式懒汉式饿汉式 v.s. 懒汉式 (三)创建型模式:单例模式 单例模式在于确保一个类只有一个实例,并提供一个全局访问点来访问该实例。在某些情况下࿰…...

基于Android Studio的行程记录APK开发指南(三)---界面设计及两种方法获取用户位置
前言 本系列教程我们来看看如何使用Android Studio去开发一个APK用于用户的实时行程记录 第一期:基于Android Studio的用户行程记录APK开发指南(一):项目基础配置与速通Kotlin-CSDN博客第二期:基于Android Studio的行程记录APK开发指南(二):…...

大厂趋势:低代码不等于低能力,赋能高效开发新纪元
大厂趋势:低代码不等于低能力,赋能高效开发新纪元 在数字化转型的浪潮中,科技巨头(大厂)作为行业的引领者,不断探索和创新,以应对日益复杂多变的市场需求和技术挑战。其中,“低代码…...
CentOS全面停服,国产化提速,央国企信创即时通讯/协同门户如何选型?
01. CentOS停服带来安全新风险, 国产操作系统迎来新的发展机遇 2024年6月30日,CentOS 7版本全面停服,于2014年发布的开源类服务器操作系统——CentOS全系列版本生命周期画上了句号。国内大量基于CentOS开发和适配的服务器及平台,…...

如何确定Kubernetes是在采用哪种方式进行部署的?
这里写目录标题 1. 查看 Kubernetes 安装方式的常见文件和工具2. 检查 Kubernetes 的节点信息3. 检查 Kubernetes API 服务器的版本信息4. 检查系统服务和容器5. 查看安装文档或管理员笔记为什么可以确定是 kubeadm 部署?下一步确认 如果存在多个master节点…...

【PostgreSQL】地理空间数据的数据类型定义、索引优化、查询优化策略
PostgreSQL 是开源关系型数据库,对于地理空间数据的处理提供了很好的支持。在处理地理空间数据时,优化索引和查询的性能至关重要,因为地理空间操作通常涉及大量的数据计算和复杂的几何形状比较。 一、地理空间数据类型 注意geometry和geogra…...

RocketMQ广播消费消息
1、 基础概念 RocketMQ 支持两种消息模式:集群消费( Clustering )和广播消费( Broadcasting )。 集群消费模式(Cluster): 在集群消费模式下,同一个消费者组(…...
枚举)
C#基础(2)枚举
前言 我们其实在前面已经了解过枚举到底有什么作用,但是那毕竟是概念性的语言,理解起来很抽象,今天我们会具体来讲一讲枚举,并谈一谈它的应用。 希望你能从今天的C#基础中有所收获。 基本概念 1.枚举:是一个比较特…...

Linux之MySQL日志
前言 数据库就像一个庞大的图书馆,而日志则是记录这个图书馆内每一本书的目录。正如在图书馆中找到特定书籍一样,数据库日志帮助我们追溯数据的变更、定位问题和还原状态。 在MySQL中,日志是非常重要的一个组成部分,它记录了数据…...

Redis集群模式—主从集群、哨兵集群、分片集群
主从集群 主从模式中,包括一个主节点(Master)和一个或多个从节点(Slave)。主节点负责处理所有写操作和读操作,而从节点则复制主节点的数据,并且只能处理读操作。当主节点发生故障时,…...

并发工具类(二):CyclicBarrier
1、CyclicBarrier 介绍 从字面上看 CyclicBarrier 就是 一个循环屏障,它也是一个同步助手工具,它允许多个线程 在执行完相应的操作后彼此等待共同到达一个屏障点。 CyclicBarrier可以被循环使用,当屏障点值变为0之后,可以在接下来…...

Spring Cloud全解析:负载均衡之Ribbon简介
Ribbon简介 Ribbon是一种客户端的软件负载均衡算法,将Netflix的中间层服务连接在一起,提供了一系列完善的配置如连接超时、重试等,Ribbon会自动的帮助基于某种规则(如简单轮询、随机连接等)去连接那些机器,也可以自定义的负载均衡…...

Kettle安装与使用指南
1. 介绍 什么是Kettle? Kettle,全称Pentaho Data Integration (PDI),是Pentaho BI套件的一部分。它提供了一个可视化的ETL工具,允许用户通过图形界面设计复杂的数据集成流程。Kettle支持多种数据源,包括关系型数据库…...
教育行业解决方案:智能PPT在教育行业的创新应用
在信息化时代,教育行业面临着巨大的变革。随着人工智能技术的不断发展,传统教学方式正在被重新定义。彩漩科技作为 AI 技术的先行者,推出了歌者 PPT &彩漩 PPT,为教师、学生和家长提供了一种全新的教育体验,实现了…...

Matlab程序练习
Part1 1.求 [100,999] 之间能被 21整除的数的个数。 程序: 主文件:main.m clear; start_num 100; end_num 999; div_num 21; res div(start_num,end_num,div_num); fprintf("[%d,%d]之间能被%d整除的数的个数为%d个\n",start_num,end_…...

cesium可不可以改变影像底图颜色,如何给地球底图影像添加一层滤镜蒙版?
废话:你的球是不是很丑?是不是没有科技感?是不是没有好看的影像? 因果: 因:客户问,底图可不可以改变颜色,想让球更漂亮一些。 答:可以改变影像饱和度,透明度…...

MyBatis-MappedStatement什么时候生成?QueryWrapper如何做到动态生成了SQL?
通过XML配置的MappedStatement 这部分MappedStatement主要是由MybatisXMLMapperBuilder进行解析,核心逻辑如下: 通过注解配置的MappedStatement 核心逻辑就在这个里面了: 继承BaseMapper的MappedStatement 我们看看这个类,里…...

Z-Image-GGUF开发利器:IntelliJ IDEA远程调试与项目管理
Z-Image-GGUF开发利器:IntelliJ IDEA远程调试与项目管理 你是不是也遇到过这种情况?本地跑一个图像生成模型,要么显卡带不动,要么环境配置折腾半天。好不容易在云端服务器上部署好了Z-Image-GGUF服务,结果开发调试又成…...

告别复杂配置:用Chainlit前端5分钟体验Qwen3-14B文本生成
告别复杂配置:用Chainlit前端5分钟体验Qwen3-14B文本生成 1. 为什么选择Qwen3-14B_int4_awq 如果你正在寻找一个既强大又易于部署的文本生成模型,Qwen3-14B_int4_awq绝对值得考虑。这个模型基于Qwen3-14B进行int4的awq量化,通过AngelSlim技…...

告别“以刊评文”,中国顶刊《Vita》启航:一份不收费的CNS挑战者正式来了
如果有一天,发论文不用交几万块版面费,评价论文不再看影响因子;你会觉得,这是理想,还是趋势?2026年,这件事,开始变成现实。2026年的春天,中国学术界连续打出两记“重拳”…...

没有后台服务的鸿蒙应用,算不算“半成品”?——本地 Service Extension 开发真香指南
大家好,我是[晚风依旧似温柔],新人一枚,欢迎大家关注~ 本文目录:前言一、ExtensionAbility 类型:先搞清“职业分工”,再谈用谁干活1️⃣ ExtensionAbility 大家族速览二、后台服务场景:哪些事儿…...

Claude频发Bug,AI安全引担忧
近日,Claude被爆出存在严重Bug,分不清用户与系统发言,甚至将恶意指令当合法请求。此问题在Hacker News引发热议,也暴露出大模型的安全隐患。Claude现身份识别障碍Claude 3.5和Claude 4系列在处理复杂或恶意上下文时,出…...

MediaPipe人体姿态识别避坑指南:从环境配置到模型调优
MediaPipe人体姿态识别避坑指南:从环境配置到模型调优 人体姿态识别技术正在重塑人机交互的边界——从虚拟健身教练的实时动作纠正,到影视特效中的精准动作捕捉,这项技术正在多个领域展现惊人潜力。作为Google推出的跨平台解决方案࿰…...

ANSYS APDL循环建模中的高效数据交互技巧
1. ANSYS APDL循环建模与MATLAB数据交互的核心价值 在工程仿真领域,ANSYS APDL的循环建模能力堪称自动化分析的利器。我曾在某型风力发电机叶片参数化分析项目中,用循环建模一次性完成了178组不同翼型参数的强度计算,整个过程从原来的两周缩短…...
)
Linux 文本处理三剑客(日志 / 配置分析)
前言 在 Linux 服务器工作中,90% 的问题都要靠看日志、改配置解决。面对动辄几万行的日志文件,手动翻阅效率极低,而 grep、sed、awk 这三个工具,就是 Linux 下处理文本的 “终极三剑客”。掌握它们,你就能实现快速过滤…...

深入解析IceCMS开源源码:轻量高效,新手也能上手的内容管理系统
在开源CMS领域,各类系统层出不穷,有的功能庞杂难以驾驭,有的过于简易无法满足多样化需求,而IceCMS凭借轻量、高效、易拓展的特点,成为许多个人站长和中小企业搭建网站的优选。作为一款开源内容管理系统,其源…...

CANoe离线回放与Trace回放:场景选择与实战配置全解析
1. CANoe回放功能概述:从数据文件到场景复现 第一次接触CANoe的回放功能时,我完全被各种专业术语搞晕了。直到有一次需要复现一个偶发的总线故障,才发现这个功能简直是汽车电子测试工程师的"时光机"。简单来说,CANoe的离…...