Nginx: 缓存, 不缓存特定内容和缓存失效降低上游压力策略及其配置示例
概述
- 在负载均衡的过程中,有一个比较重要的概念,就是缓存
- 利用缓存可以很好协调Nginx在客户端和上游服务器之间的速度不匹配的矛盾
- 从而很好的解决整体系统的响应速度

- 如果用户需要通过Nginx获取某一些内容的时候,发起一个request请求
- 这个请求到了Nginx之后,静态内容会直接返回,动态内容会转发至应用程序服务器
- 后端应用服务器再处理完这样一个请求器,会封装响应包体,再返回给我们的Nginx
- Nginx 收到 response 包体之后,再一并的把这些内容返回给我们的用户
- 这里的问题在于,Nginx 处理能力很强,但是上游的服务器它是处理动态内容的
- 而且在后端通常情况下,可能还有一些数据库服务器
- 它还需要将请求再去找数据库服务器获取内容之后,就这段请求处理的时候是非常慢
- 因此就有一个矛盾,当用户发起请求的时候,很快到达Nginx
- 但这个内容返回之前,可能需要经经过长的时时间
- 用户体验并非取决于前一段,而是取决于整个系统中最慢的那一段
- 想要提升用户体验的话,缓存就做了这样一个思路
- Nginx 提供一些缓存能力
- 当第一次request的请求到达Nginx的时候
- Nginx可以依据一定的缓存策略发送请求给应用服务器
- 当应用服务器处理完请求封装包底返回给Nginx的时候
- Nginx 在返回给客户端之前,它会依据缓存的策略
- 将某一部分信息先缓存到Nginx自身的cache中(Nginx 服务器的内存中开辟的一段空间)
- 比如, 请求一个图片,或某一些动态内容,都可以把它缓存到这样一个cache中
- 当用户第一次请求的时候,可能在缓存中是没有对应的这样一些内容的
- 这个时候Nginx必须要发去请求到后端应用服务器获取
- 但是当第一次获取到这些内容之后,会把这些内容放到cache中
- 等到下一个用户请求的时候,发现你这个URL请求的是同样的内容
- Nginx不会再向后端应用服务器发送请求
- 而是直接将将自身内存中的cache中的一些信息,直接返回给客户端中
- 这对于提升整个用户体验来说是非常关键的
- 在互联网时代有一句话叫缓存为王,尤其是并发量很大的场景下
- 这已经不是一个策略问题,而是一个必须要做的事情
缓存分类
1 )客户端缓存

- 所谓客户端缓存,就是指我们的用户的浏览器
- 那客户端我们对于用户来说,它的浏览器就是一个客户端,它发送请求到Nginx服务器
- 我们先来看一下客户端缓存优点:直接在本地获取内容,没有网络消耗, 响应是最快的
- 用户和Nginx之间通常是经过运营商的网络的,这样很好的避免了这样一些网络请求
- 这样,它可以极大的减少我们网络消耗的开销
- 缺点也是很明显,当用户只启用了客户端缓存的时候,只有这个用户可以使用这些缓存
- 而且这些缓存也有可能造成一些数据不一致的问题
2 )服务端缓存

- 它的优势相比客户端来说,它就是对所有的用户都能够生效
- 另外一点它还可以有效的去降低上游应用服务器的一个压力,缓解并发能力差的问题
- 缺点就是仍然有一些网络消耗
3 )最佳实践
- 同时启用客户端缓存和服务端缓存
相关指令
1 )proxy_cache 指令
- 语法:proxy_cache zone | off;
- zone 是共享内存中开辟的空间
- 默认值:proxy_cache off;
- 上下文:http、server、location
2 )proxy_cache_path 指令
-
语法:proxy_cache_path path [ level=levels ] [ use_temp_path=on/off]
keys_zone=name:size [inactive=time] [max_size=size]
[manager_files=number] [manager_sleep=time]
[manager_threshold=time] [loader_files=number]
[loader_sleep=time] [loader_threshold=time]
[purger=on|off] [purger_files=number]
[purger_sleep=time] [purger_threshold=time]; -
默认值:proxy_cache_path off;
-
上下文:http
-
参数含义
可选参数 含义 path 缓存文件的存放路径 level path的目录层级 use_temp_path off直接使用path路径;on使用proxy_temp_path路径 keys_zone name是共享内存名称;size是共享内存大小 inactive 在指定时间内没有被访问缓存会被清理;默认10分钟 max_size 设定最大的缓存文件大小,超过将由CM(Cache Manager)清理 manager_files CM清理一次缓存文件,最大清理文件数;默认100 manager_sleep CM清理一次后进程的休眠时间;默认200毫秒 manager_threshold CM清理一次最长耗时;默认50毫秒 loader_files CL(Cache Loader) 载入文件到共享内存,每批最多文件数;默认100 loader_sleep CL加载缓存文件到内存后,进程休眠时间;默认200毫秒 loader_threshold CL每次载入文件到共享内存的最大耗时;默认50毫秒
3 )proxy_cache_key 指令
- 决定缓存内容,保存的key信息
- 语法:proxy_cache_key string;
- 默认值:proxy_cache_key $scheme $proxy_host $request_uri
- 上下文:http、server、location
4 )proxy_cache_valid 指令
- 语法:proxy_cache_valid [ code … ] time;
- 这里的 code 是 http 的状态码
- 默认值:-
- 上下文:http、server、location
- 配置示例:proxy_cache_valid 60m; # 只对200、301、302响应码缓存
5 )upstream_cache_status 变量
- 变量名:upstream_cache_status
- MISS: 未命中缓存
- HIT: 命中缓存
- EXPIRED: 缓存过期
- STALE: 命中了陈旧缓存
- REVALIDDATED: Nginx验证陈旧缓存依然有效
- UPDATING: 内容陈旧,但正在更新
- BYPASS: 响应从原始服务器获取
缓存基本指令配置示例
1 )环境准备
-
Nginx 服务器准备:192.168.184.240
proxy_cache_path /opt/nginx/cache_temp levels=2:2 keys_zone=cache_zone:30m max_size=32g inactive=60m use_temp_path=off;upstream cache_server {server 192.168.184.20:1010;server 192.168.184.20:1011; }server {listen 80;server_name cache.baidu.com;location / {proxy_cache cache zone; # 开启缓存功能proxy_cache_valid 200 5m; # 对200状态码的缓存 5分钟proxy_cache_key $scheme$proxy_host$request_uri # 这个是缓存文件中的 key 值,可以自行修改add_header Nginx-Cache-Status "$upstream cache status"; # 缓存是否命中的变量带到响应头上proxy_pass http://cache server;} }- levels=2:2 第一个2表示目录命名时字符串长度,第二个2表示目录的层次
- keys_zone=cache_zone:30m 这里的30m是可用的共享内存大小, 1m可缓存8000个key
- inactive=60m 60分钟内缓存没有被使用则清理
-
应用服务器准备:192.168.184.20
server {listen 1010;root /opt/html/1010;add_header X-Accel-Expires 5 # 告诉下游Nginx 只能缓存 5slocation / {index index.html index.htm;} }server {listen 1011;root /opt/html/1011;add_header X-Accel-Expires 5location / {index index.html index.htm;} }- 文件:/opt/html/1010/cache.txt 内容为:cc-1010
- 文件:/opt/html/1011/cache.txt 内容为:cc-1011
-
客户端访问测试
- 已经配置nginx服务器hosts 为 cache.baidu.com,可直接访问
- 多次执行,$
curl cache.baidu.com/cache.txt可知,只会分配到一台服务器上 - 执行 $
curl cache.baidu.com/cache.txt -I- 重启nginx后,也就是第一次访问,Nginx-Cache-Status: MISS,值是 MISS
- 到了第二次,这个值就是 HIT
- 在 cache_temp/ 目录中会发现一个两字符的两层级目录
- 例如:e4/97 在这个目录下还有一个hash文件,就是cache.txt的缓存文件
- 等到5s以后再次访问,就会失效, 值变成 EXPIRED
配置 Nginx 不缓存特定内容
1 )proxy_no_cache 指令
- 对于特定场景不去缓存,如购物网站,商品数量不缓存
- 语法: proxy_no_cache string;
- 引用某一个特定变量,有值则不缓存
- 默认值: -
- 上下文:http、server、location
2 )proxy_cache_bypass 指令
- 配置不使用缓存,而是路由到上游服务器
- 语法: proxy_cache_bypass string;
- 默认值: -
- 上下文:http、server、location
3 )Nginx 配置 proxy_cache示例
proxy_cache_path /opt/nginx/cache_temp levels=2:2 keys_zone=cache_zone:30m max_size=32g inactive=60m use_temp_path=off;upstream cache_server {server 192.168.184.20:1010;server 192.168.184.20:1011;
}server {listen 80;server_name cache.baidu.com;# 注意,这里if ($request_uri ~ \.(txt | text)$ ) {set $cookie_name "no cache";}location / {proxy_cache cache zone; # 开启缓存功能# 注意这里的添加 --- 开始proxy_no_cache $cookie_name; # 这里引用 cookie_name # 注意这里的添加 --- 结束proxy_cache_valid 200 5m; # 对200状态码的缓存 5分钟proxy_cache_key $scheme$proxy_host$request_uri # 这个是缓存文件中的 key 值,可以自行修改add_header Nginx-Cache-Status "$upstream cache status"; # 缓存是否命中的变量带到响应头上proxy_pass http://cache server;}
}
- 这类请求,会对 txt/text 的文件不适用缓存, 都是 MISS
- 对其他文件使用缓存,缓存的标志值是:MISS / HIT / EXPIRED
- 不再做测试说明
缓存失效降低上游压力策略
- 当缓存失效的时候,如何去降低请求直接穿透Nginx从而导致上游应用服务器压力大的这样一个场景
- 这里有两种处理机制:
- 合并源请求
- 启用陈旧缓存
1 )合并源请求

- 当用户发送很多并发请求到Nginx的时候,假定这个时候Nginx重启了
- 重启之后,假如缓存整体失效,导致请求经过 Nginx 直接透传给后端的应用服务器
- 当并发请求量很大的情形下,由于Nginx 处理能力和后端处理能力不匹配,可能会导致很多的请求穿透Nginx到达后端
- 这些并发请求很可能会直接导致上游的服务器瘫痪掉
- 为了避免这种情形的发生, 对于Nginx 也采取了一些机制
- proxy_cache_lock 指令
- 收到的多个请求会有一个请求进入应用服务器,其他请求原地等待缓存
- 语法:proxy_cache_lock on | off;
- 默认值:proxy_cache_lock off;
- 上下文:http、server、location
- 这个多个请求,指的是同一请求的多个请求

1.2 proxy_cache_lock_timeout 指令
- 这个和1.1 一起使用,设置锁定的超时时间
- 语法:proxy_cache_lock_timeout time;
- 默认值:proxy_cache_lock_timeout 5s;
- 上下文:http、server、location
- 比如,这里有一个场景,比如说你第一个请求过来之后三个请求
- 之前设定了 proxy_cache_lock,其中有一个请求到达了应用服务器
- 假如说,由于某些原因,长时间有应用服务器故障不返回
- 五秒钟到了之后,后端的这两个请求依然会经过Nginx转发两个请求到应用服务器
- 这个是 这个 proxy_cache_lock_timeout 指令的作用
- 但是,这个还会有弊端,比如,现在是三个请求是5W个
- 如果把第一个请求分发给后端的应用服务器,但超时了
- 接下来可能有四万九千九百九十九的这样请求会直接由Nginx再次分发给应用服务器
- 在这样一种场景下,它依然会对应用服务造成很大的压力
- 所以说, 这个设定,在某些特殊场景下就失去了意义
- 为了避免这样一种情形的发生,引入下面的指令
1.3 proxy_cache_lock_age 指令
- 这个和1.2不同,当一个请求超时后,再发另一个请求尝试,接着继续尝试
- 语法:proxy_cache_lock_age time;
- 默认值:proxy_cache_lock_age 5s;
- 上下文:http、server、location
1.4 总结
-
以上三个参数就是通过合并原请求来规避了穿透Nginx这样一种情形的发生,从而避免缓存失效时,给我们的应用服务造成极大的一个压力
-
在具体的环境配置中,我们直接这样写就可以了
proxy_cache_path /opt/nginx/cache_temp levels=2:2 keys_zone=cache_zone:30m max_size=32g inactive=60m use_temp_path=off;upstream cache_server {server 192.168.184.20:1010;server 192.168.184.20:1011; }server {listen 80;server_name cache.baidu.com;# 注意,这里if ($request_uri ~ \.(txt | text)$ ) {set $cookie_name "no cache";}location / {proxy_cache cache zone; proxy_no_cache $cookie_name;proxy_cache_valid 200 5m;proxy_cache_key $scheme$proxy_host$request_uriadd_header Nginx-Cache-Status "$upstream cache status";proxy_pass http://cache server;# 关注如下proxy_cache_lock on;proxy_cache_lock_timeout 5sproxy_cache_lock_age 5s} } -
以上三个指令一起加上就可以完成合并原请求的实践
2 ) 启用陈旧缓存
- 缓存失效是降低上游服务压力的另外一种方法: 启用陈旧缓存

- 因为 Nginx 直接转发这样一些并发请求的话,可能会对上面的应用服务器造成一个致命的压力
- 如果这么多并发请求过来,有可能后面的这个应用服务器就直接给摊掉了
- 因此我们可以这样来做
- 虽然Nginx的缓存已经失效了, 但是比如说我第一个请求过来以后
- Nginx 会把第一个请求转发给后面的应用服务器
- 这个时候去请求更新本地缓存,就获取内容了
- 这个时候假如后面又有很多的请求过来了
- 跟第一个请求都请求的是同一个资源, 后面的这样一些请求
- 就没必要再转发给后面应用服务器了, 暂时等待第一个请求结果
- 虽然这样得到的不是实时的,是有些陈旧的
- 但是可以尽量避免并发请求全部透传到后端给上网应用服务造成的压力
- 对于某一些对数据一致性要求没那么高的场景来说的话是可以的
2.1 proxy_cache_use_stale 指令
- 语法:proxy_cache_use_stale error| timeout | invalid_header | updating | http_500 | http_502 | http_503 | http_504 | http_403 | http_404 | http_429 | off …;
- 默认值:proxy_cache_use_stale off;
- 上下文:http、server、location
- 可选参数
可选参数 含义 error 与上游建立连接、发送请求、读取响应头出错时 timeout 与上游建立连接、发送请求、读取响应头超时时 invalid_header 无效头部时 updating 缓存过期,正在更新时 http_500 返回状态码500时 http_502 返回状态码502时 http_503 返回状态码503时 http_504 返回状态码504时 http_403 返回状态码403时 http_404 返回状态码404时 http_429 返回状态码429时 - 这个指令可以用来在特定的条件下去启用Nginx已有的陈旧的缓存
- 虽然可能这些缓存已经失效,但是对于某一些对数据一致性要求没有那么高的应用来说
- 能够返回一个结果, 远远比直接返回404,给客户的用户体验是要好的多
- 它后面有很多参数,每一个参数就是一种场景
- 比如说针对 error, timeout 或者是invalid_header, 以及 updating
- 后面还有很多不同的HTTP返回状态码的时候,都可启用陈旧缓存
- 这个指令和对上游应用服务进行容错指令 proxy_next_upstream 很相似
2.2 proxy_cache_background_update 指令
- 缓存更新时,在后台执行
- 语法:proxy_cache_background_update on | off;
- 设置为 off, 第一个请求过来,Nginx发现缓存失效
- 第一个请求被Nginx转发到上游服务器,等待获取结果并缓存
- 设置为 on, 第一个请求过来,会直接使用Nginx缓存
- 不管是否失效,Nginx自身会发起请求到应用服务器去更新资源
- 这种设置为 on 是用户体验比较好的
- 默认值:proxy_cache_background_update off;
- 上下文:http、server、location
2.3 配置示例
proxy_cache_path /opt/nginx/cache_temp levels=2:2 keys_zone=cache_zone:30m max_size=32g inactive=60m use_temp_path=off;upstream cache_server {server 192.168.184.20:1010;server 192.168.184.20:1011;
}server {listen 80;server_name cache.baidu.com;# 注意,这里if ($request_uri ~ \.(txt | text)$ ) {set $cookie_name "no cache";}location / {proxy_cache cache zone; proxy_no_cache $cookie_name;proxy_cache_valid 200 5m;proxy_cache_key $scheme$proxy_host$request_uriadd_header Nginx-Cache-Status "$upstream cache status";proxy_pass http://cache server;proxy_cache_lock on;proxy_cache_lock_timeout 5sproxy_cache_lock_age 5s# 关注如下proxy_cache_use_stale error timeout updating; # 这里配置三个proxy_cache_background_update on;}
}
相关文章:
Nginx: 缓存, 不缓存特定内容和缓存失效降低上游压力策略及其配置示例
概述 在负载均衡的过程中,有一个比较重要的概念,就是缓存利用缓存可以很好协调Nginx在客户端和上游服务器之间的速度不匹配的矛盾从而很好的解决整体系统的响应速度 如果用户需要通过Nginx获取某一些内容的时候,发起一个request请求这个请求…...

Python 全栈系列266 Kafka服务的Docker搭建
说明 在大量数据处理任务下的缓存与分发 这个算是来自顾同学的助攻1,我有点java绝缘体的体质,碰到和java相关的安装部署总会碰到点奇怪的问题,不过现在已经搞定了。测试也接近了kafka官方标称的性能。考虑到网络、消息的大小等因素࿰…...

集合框架,List常用API,栈和队列初识
回顾 集合框架 两个重点——ArrayList和HashSet. Vector/ArraysList/LinkedList区别 VectorArraysListLinkedList底层实现数组数组链表线程安全安全不安全不安全增删效率较低较低高扩容*2*1.5-------- (>>)运算级最低,记得加括号。 常…...
构建全景式智慧文旅生态:EasyCVR视频汇聚平台与AR/VR技术的深度融合实践
在科技日新月异的今天,AR(增强现实)和VR(虚拟现实)技术正以前所未有的速度改变着我们的生活方式和工作模式。而EasyCVR视频汇聚平台,作为一款基于云-边-端一体化架构的视频融合AI智能分析平台,可…...

C++结构体声明时初始化
提示:文章 文章目录 前言一、背景二、 2.1 2.2 总结 前言 前期疑问: 本文目标: 一、背景 最近 二、 2.1 c 结构体默认初始化 在C中,结构体的默认成员初始化可以通过构造函数来完成。如果没有为结构体提供构造函数&#x…...

基于微信的热门景点推荐小程序的设计与实现(论文+源码)_kaic
摘 要 近些年来互联网迅速发展人们生活水平也稳步提升,人们也越来越热衷于旅游来提高生活品质。互联网的应用与发展也使得人们获取旅游信息的方法也更加丰富,以前的景点推荐系统现在已经不足以满足用户的要求了,也不能满足不同用户自身的个…...

9、设计模式
设计模式 1、工厂模式 在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。工厂模式作为一种创建模式,一般在创建复杂对象时,考虑使用;在创建简单对象时&…...

数学专题.
数论 1.判断质数 定义:在大于1的整数中,如果只包含1和本身这两个约数,就称为质数or素数 Acwing 866.试除法判断质数 2.预处理质数(筛质数) Acwing 868.筛质数 3.质因数分解 Acwing 867.分解质因数 4.阶乘分解 5.因…...
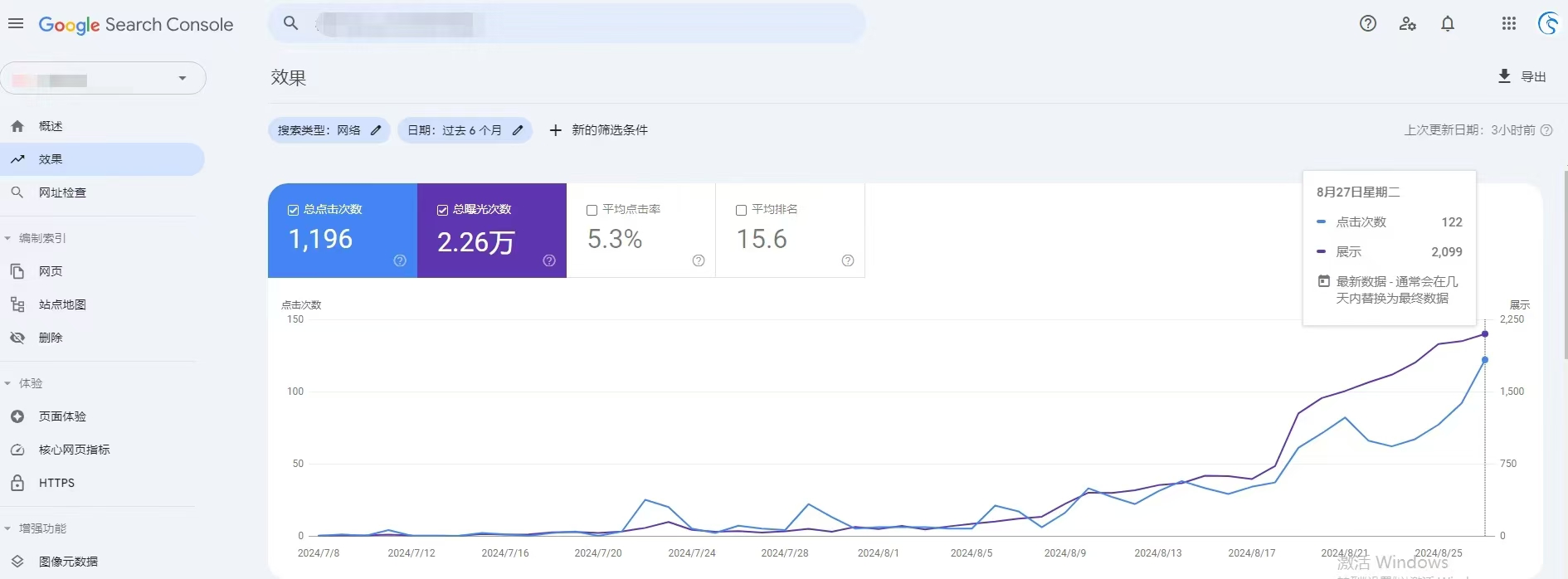
如何提升网站的收录率?
要提升网站的收录率,其中一个特别有效的工具就是GPC爬虫池,这个工具通过深度研究谷歌SEO算法,吸引谷歌爬虫。 GPC爬虫池的基本原理是构建一个庞大的站群系统,并创建复杂的内链和外链结构,以吸引并留住谷歌蜘蛛 使用GP…...

HALCON根据需要创建自定义函数
在HALCON中,根据需要创建自定义函数是扩展其图像处理和分析功能的有效方式。HALCON支持通过其高级编程接口(HDevelop和C/C、C#、Python等)来创建自定义函数。这里将主要讨论在HDevelop环境中如何创建自定义函数,因为HDevelop是HAL…...
)
力扣SQL仅数据库(196~569)
196. 删除重复的电子邮箱 题目:编写解决方案 删除 所有重复的电子邮件,只保留一个具有最小 id 的唯一电子邮件。 (对于 SQL 用户,请注意你应该编写一个 DELETE 语句而不是 SELECT 语句。) (对于 Pandas …...

网络基础:理解IP地址、默认网关与网段(IP地址是什么,默认网关是什么,网段是什么,IP地址、默认网关与网段)
前言 在计算机网络中,IP地址、默认网关和网段(也称为子网)之间有着密切的关系。它们是网络通信中的至关重要的概念,但它们并不相同。这里来介绍一下它们之间的关系,简单记录一下 一. IP地址 1. 介绍 IP 地址…...

windows安装php7.4
windows安装php7.4 1.通过官网下载所需的php版本 首先从PHP官网(https://www.php.net/downloads.php)或者Windows下的PHP官网(http://windows.php.net/download/)下载Windows版本的PHP安装包。下载后解压到一个路径下。 2.配…...

【代码随想录|图论part03之后】
代码随想录|数组 704. 二分查找,27. 移除元素 一、part031、101. 孤岛的总面积1.1 dfs版本1.2 BFS版本2.102. 沉没孤岛3、103. 水流问题4、104.建造最大岛屿二、part041、110. 字符串接龙2、105.有向图的完全可达性3、106. 岛屿的周长三、part05-06 并查集理论1、107. 寻找存在…...

【项目一】基于pytest的自动化测试框架day1
day1不涉及编写代码,只简单梳理接口测试相关的概念。 day1接口测试的本质:功能测试的一部分测试用例的设计与实现接口调试与自动化:从postman到持续集成补充概念 day1 接口测试的本质:功能测试的一部分 接口测试是功能测试的一部…...

如何下载和安装 Notepad++
Notepad 是一款功能强大的开源文本编辑器,广泛用于代码编写和文本编辑。以下是 Notepad 的下载安装教程: 下载 Notepad 访问官方网站 打开你的网络浏览器,访问 Notepad 的官方网站:https://notepad-plus-plus.org/ 选择下载选项…...

笔记:如何使用Process Explorer分析句柄泄露溢出问题
一、目的:如何使用Process Explorer分析句柄泄露溢出问题 使用 Process Explorer 分析句柄泄漏问题是一个非常有效的方法。句柄泄漏通常是由于应用程序在创建系统资源(如文件、注册表项、GDI 对象等)后没有正确释放这些资源。以下是使用 二、…...

HTTP/2
http相关知识点 HTTP/2是超文本传输协议(HTTP)的第二个主要版本,旨在解决HTTP/1.x版本中存在的一些性能限制和效率问题。HTTP/2由互联网工程任务组(IETF)的HTTP工作组开发,最终在2015年作为RFC 7540正式发…...

如何在算家云搭建ComfyUI(AI绘画)
一、ComfyUI简介 ComfyUI 是一个强大的、模块化的 Stable Diffusion 界面与后端项目。该用户界面将允许用户使用基于图形/节点/流程图的界面设计和执行高级稳定的扩散管道。该项目部分其它特点如下: 全面支持 SD1.x,SD2.x,SDXL,…...
公司的企业画册如何制作?
企业画册是公司形象和产品服务展示的重要载体,一个制作精良的企业画册不仅能展示公司的实力,也能提升客户对公司专业度的认可。以下是制作企业画册的步骤和要点,帮助你的公司画册既美观又实用。 1.要制作电子杂志,首先需要选择一款适合自己的…...

老马失前蹄,竟然在数据库外键上翻车了,重温外键级联巡
AI Agent 时代的沙箱需求 从 Copilot 到 Agent:执行能力的质变 在生成式 AI 的早期阶段,应用主要以“Copilot”形式存在,AI 仅作为辅助生成建议。然而,随着 AutoGPT、BabyAGI 以及 OpenAI Code Interpreter(现为 Advan…...

探索6种突破信息壁垒的创新方案
探索6种突破信息壁垒的创新方案 你是否曾因遇到付费墙而无法获取急需的信息?当知识被一道道"数字门锁"隔离,我们该如何智慧地开启信息之门?本文将带你探索突破信息壁垒的创新方案,让有价值的内容触手可及。 问题解析&am…...

Windows系统优化神器:Winhance中文版完全指南 - 让电脑重获新生的终极解决方案
Windows系统优化神器:Winhance中文版完全指南 - 让电脑重获新生的终极解决方案 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh…...
和谷歌地图(lyrs=s/m)的URL参数到底怎么用?一篇讲清所有地图瓦片服务调用细节)
天地图(T=img_w/c)和谷歌地图(lyrs=s/m)的URL参数到底怎么用?一篇讲清所有地图瓦片服务调用细节
天地图与谷歌地图URL参数全解析:从瓦片调用到坐标系实战 当你需要在项目中集成地图服务时,是否曾被各种URL参数搞得一头雾水?Timg_w和Timg_c有什么区别?lyrss和lyrsm又代表什么?本文将彻底拆解两大主流地图服务的URL设…...

XXMI启动器终极指南:一站式管理所有二次元游戏模组
XXMI启动器终极指南:一站式管理所有二次元游戏模组 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher 还在为《原神》、《崩坏:星穹铁道》、《鸣潮》、《绝区…...

时间序列平稳性:从理论到实战检验指南
1. 为什么时间序列需要平稳性? 想象一下你每天记录体重变化。如果体重在60kg上下小幅波动(比如59.5kg到60.5kg),我们很容易预测明天的体重大概率也在60kg附近。但如果体重每周增加1kg(从60kg持续增长到70kg)…...

忍者像素绘卷新手入门:5分钟学会复古像素画生成
忍者像素绘卷新手入门:5分钟学会复古像素画生成 1. 像素艺术新纪元:当忍者精神遇见16-Bit美学 想象一下,你正坐在一间充满怀旧气息的游戏工作室里。墙上贴着90年代经典游戏的像素海报,桌上摆着插满游戏卡带的NES主机。现在&…...

深度解析NxNandManager:Nintendo Switch NAND管理工具的技术实现
深度解析NxNandManager:Nintendo Switch NAND管理工具的技术实现 【免费下载链接】NxNandManager Nintendo Switch NAND management tool : explore, backup, restore, mount, resize, create emunand, etc. (Windows) 项目地址: https://gitcode.com/gh_mirrors/…...

Flowise AI工作流安全通关手册:从零基础入门到攻防专家,全链路守住你的AI核心资产
2026年4月,全球AI圈与网络安全界同步爆发了一场震动行业的大规模攻击事件:黑客利用开源AI工作流编排平台Flowise的CVE-2025-59528满分高危漏洞,对全球公网暴露的上万个AI工作流实例发起无差别攻击。短短一周内,数千个企业与开发者…...
入门:核心概念图解与首个AI应用创建)
Intv_AI_MK11人工智能(AI)入门:核心概念图解与首个AI应用创建
Intv_AI_MK11人工智能(AI)入门:核心概念图解与首个AI应用创建 1. 人工智能初体验:从零开始理解AI 想象一下,你正在教一个小朋友认识动物。刚开始,他可能分不清猫和狗的区别,但随着你不断展示图…...