深度学习每周学习总结N9:transformer复现
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
目录
- 多头注意力机制
- 前馈传播
- 位置编码
- 编码层
- 解码层
- Transformer模型构建
- 使用示例
本文为TR3学习打卡,为了保证记录顺序我这里写为N9
总结:
之前有学习过文本预处理的环节,对文本处理的主要方式有以下三种:
1:词袋模型(one-hot编码)
2:TF-IDF
3:Word2Vec(词向量(Word Embedding) 以及Word2vec(Word Embedding 的方法之一))
详细介绍及中英文分词详见pytorch文本分类(一):文本预处理
N1期介绍了one-hot编码
N2期主要介绍Embedding,及EmbeddingBag 使用示例(对词索引向量转化为词嵌入向量)
N3期主要介绍:应用三种模型的英文分类
N4期将主要介绍中文基本分类(熟悉流程)、拓展:textCNN分类(通用模型)、拓展:Bert分类(模型进阶)
N5期主要介绍Word2Vec,和nn.Embedding(), nn.EmbeddingBag()相比都是嵌入技术,用于将离散的词语或符号映射到连续的向量空间。
nn.Embedding 和 nn.EmbeddingBag 是深度学习框架(如 PyTorch)中的层,直接用于神经网络模型中,而 Word2Vec 是一种独立的词嵌入算法。
使用来说,如果需要在神经网络中处理变长序列的嵌入,可以选择 nn.EmbeddingBag;如果需要预训练词嵌入用于不同任务,可以选择 Word2Vec。
N6期主要介绍使用Word2Vec实现文本分类:
与N4文本分类的异同点总结
- 共同点
数据加载:都使用了PyTorch的DataLoader来批量加载数据。
模型训练:训练过程大同小异,都是前向传播、计算损失、反向传播和梯度更新。 - 不同点
分词处理:
BERT模型:使用专门的BERT分词器。
传统嵌入方法:通常使用jieba等工具进行分词。
Word2Vec模型:假设数据已经分词。
词向量表示:
BERT模型:使用BERT生成的上下文相关的词向量。
传统嵌入方法:使用静态预训练词向量。
Word2Vec模型:训练一个Word2Vec模型生成词向量。
模型结构:
BERT模型:使用预训练的BERT模型作为编码器。
传统嵌入方法:一般使用嵌入层+卷积/循环神经网络。
Word2Vec模型:使用Word2Vec词向量和一个简单的线性分类器。 - 值得学习的点
词向量的使用:了解如何使用Word2Vec生成词向量并将其用于下游任务。
数据预处理:不同方法的数据预处理方式,尤其是分词和词向量化的处理。
模型训练:标准的模型训练和评估流程,尤其是损失计算、反向传播和梯度更新等步骤。
超参数选择:注意学习率、批量大小和训练轮数等超参数的选择。
通过这些比较和分析,可以更好地理解不同文本分类方法的优缺点以及适用场景。
N7期,需要理解RNN 及 seq2seq代码,并在此基础上成功运行代码,理解代码流程
N8期,在上一期的基础上加入了注意力机制
N9期,transformer的代码复现,注释里加入了一些理解,但是对transformer的网络结构的理解还需加强
在之前的任务中我们学习了Seq2Seq,知晓了Attention为RNN带来的优点。那么有没有一种神经网络结构直接基于attention构造,并且不再依赖RNN、LSTM或者CNN网络结构了呢?答案便是:Transformer。Seq2Seq和Transformer都是用于处理序列数据的深度学习模型,但它们是两种不同的架构。
1,Seq2Seq:
- 定义: Seq2Seq是一种用于序列到序列任务的模型架构,最初用于机器翻译。这意味着它可以处理输入序列,并生成相应的输出序列。
- 结构: Seq2Seq模型通常由两个主要部分组成:编码器和解码器。编码器负责将输入序列编码为固定大小的向量,而解码器则使用此向量生成输出序列。
- 问题: 传统的Seq2Seq模型在处理长序列时可能会遇到梯度消失/爆炸等问题,而Transformer模型的提出正是为了解决这些问题。
2,Transformer:
- 定义: Transformer是一种更现代的深度学习模型,专为处理序列数据而设计,最初用于自然语言处理任务。它不依赖于RNN或CNN等传统结构,而是引入了注意力机制。
- 结构: Transformer模型主要由编码器和解码器组成,它们由自注意力层和全连接前馈网络组成。它使用注意力机制来捕捉输入序列中不同位置之间的依赖关系,同时通过多头注意力来提高模型的表达能力。
- 优势: Transformer的设计使其能够更好地处理长距离依赖关系,同时具有更好的并行性。
在某种程度上,可以将Transformer看作是Seq2Seq的一种演变,Transformer可以执行Seq2Seq任务,并且相对于传统的Seq2Seq模型具有更好的性能和可扩展性。
多头注意力机制
# 多头注意力机制
import math
import torch
import torch.nn as nndevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class MultiHeadAttention(nn.Module):# n_heads:多头注意力的数量# hid_dim:每个词输出的向量维度def __init__(self,hid_dim,n_heads):super(MultiHeadAttention,self).__init__()self.hid_dim = hid_dimself.n_heads = n_heads# 强制hid_dim 必须整除 hassert hid_dim % n_heads == 0# 定义W_q 矩阵self.w_q = nn.Linear(hid_dim,hid_dim) # nn.Linear(in_features, out_features) 是 PyTorch 中的线性变换层# 定义W_k 矩阵self.w_k = nn.Linear(hid_dim,hid_dim)# 定义W_v 矩阵self.w_v = nn.Linear(hid_dim,hid_dim)self.fc = nn.Linear(hid_dim,hid_dim)# 缩放self.scale = torch.sqrt(torch.FloatTensor([hid_dim // n_heads])) # 缩放因子,目的是防止注意力得分过大,从而使 softmax 函数过于饱和。hid_dim // n_heads 代表每个注意力头的维度,取平方根来缩放。def forward(self,query,key,value,mask=None):# 注意 Q,K,V的在句子长度这一个维度的数值可以一样,可以不一样。# K: [64,10,300], 假设batch_size 为 64,有 10 个词,每个词的 Query 向量是 300 维# V: [64,10,300], 假设batch_size 为 64,有 10 个词,每个词的 Query 向量是 300 维# Q: [64,12,300], 假设batch_size 为 64,有 12 个词,每个词的 Query 向量是 300 维bsz = query.shape[0] # 获取批次大小# 对输入的 query, key, value 进行线性变换。Q = self.w_q(query)K = self.w_k(key)V = self.w_v(value)# 这里把 K Q V 矩阵拆分为多组注意力# 最后一维就是是用 self.hid_dim // self.n_heads 来得到的,表示每组注意力的向量长度, 每个 head 的向量长度是:300/6=50# 64 表示 batch size,6 表示有 6组注意力,10 表示有 10 词,50 表示每组注意力的词的向量长度# K: [64,10,300] 拆分多组注意力 -> [64,10,6,50] 转置得到 -> [64,6,10,50]# V: [64,10,300] 拆分多组注意力 -> [64,10,6,50] 转置得到 -> [64,6,10,50]# Q: [64,12,300] 拆分多组注意力 -> [64,12,6,50] 转置得到 -> [64,6,12,50]# 转置是为了把注意力的数量 6 放到前面,把 10 和 50 放到后面,方便下面计算Q = Q.view(bsz,-1,self.n_heads,self.hid_dim//self.n_heads).permute(0,2,1,3)K = K.view(bsz,-1,self.n_heads,self.hid_dim//self.n_heads).permute(0,2,1,3)V = V.view(bsz,-1,self.n_heads,self.hid_dim//self.n_heads).permute(0,2,1,3)# 第 1 步:Q 乘以 K的转置,除以scale# [64,6,12,50] * [64,6,50,10] = [64,6,12,10]# attention:[64,6,12,10]attention = torch.matmul(Q,K.permute(0,1,3,2))/self.scale# 如果 mask 不为空,那么就把 mask 为 0 的位置的 attention 分数设置为 -1e10,这里用“0”来指示哪些位置的词向量不能被attention到,比如padding位置,当然也可以用“1”或者其他数字来指示,主要设计下面2行代码的改动。if mask is not None:attention = attention.masked_fill(mask == 0 , -1e10)# 第 2 步:计算上一步结果的 softmax,再经过 dropout,得到 attention。# 注意,这里是对最后一维做 softmax,也就是在输入序列的维度做 softmax# attention: [64,6,12,10]attention = torch.softmax(attention,dim=-1)# 第三步,attention结果与V相乘,得到多头注意力的结果# [64,6,12,10] * [64,6,10,50] = [64,6,12,50]# x: [64,6,12,50]x = torch.matmul(attention,V)# 因为 query 有 12 个词,所以把 12 放到前面,把 50 和 6 放到后面,方便下面拼接多组的结果# x: [64,6,12,50] 转置-> [64,12,6,50]x = x.permute(0,2,1,3).contiguous()# 这里的矩阵转换就是:把多组注意力的结果拼接起来# 最终结果就是 [64,12,300]# x: [64,12,6,50] -> [64,12,300]x = x.view(bsz,-1,self.n_heads * (self.hid_dim // self.n_heads))x = self.fc(x)return x
前馈传播
# 前馈传播
class Feedforward(nn.Module):"""这个 Feedforward 类实现了一个两层的前馈神经网络,是 Transformer 中的子层之一。每个 Transformer 层包括自注意力机制(Multi-Head Attention)和前馈神经网络。前馈层的作用是进一步处理每个位置(词向量)的信息,将特征从高维投影回输入的原始维度,同时保持全局信息。"""def __init__(self,d_model,d_ff,dropout=0.1):super(Feedforward,self).__init__()# 两层线性映射和激活函数ReLUself.linear1 = nn.Linear(d_model,d_ff)self.dropout = nn.Dropout(dropout)self.linear2 = nn.Linear(d_ff,d_model)def forward(self,x):x = torch.nn.functional.relu(self.linear1(x))x = self.dropout(x)x = self.linear2(x)return x
位置编码
# 位置编码
class PositionalEncoding(nn.Module):"""这是 Transformer 中实现位置编码(Positional Encoding)部分的实现。位置编码用于将输入序列中的位置信息引入到模型中,因为 Transformer 没有传统 RNN 中的时间顺序机制,所以需要用位置编码来帮助模型理解输入序列中各个位置之间的相对关系。"""def __init__(self,d_model,dropout,max_len=5000):super(PositionalEncoding,self).__init__()self.dropout = nn.Dropout(p = dropout)# 初始化Shape为(max_len, d_model)的PE (positional encoding)pe = torch.zeros(max_len,d_model).to(device) # pe: 一个形状为 [max_len, d_model] 的张量,用于存储所有位置的编码,初始化为全零张量。这个张量会在后续步骤中被填充上具体的位置信息。position = torch.arange(0,max_len).unsqueeze(1) # 生成位置索引 [0, 1, 2, ...], 形状为 [max_len, 1]# 这里就是sin和cos括号中的内容,通过e和ln进行了变换div_term = torch.exp(torch.arange(0,d_model,2) * -(math.log(10000.0) / d_model)) # 用于在位置编码中进行缩放的除法项pe[:, 0::2] = torch.sin(position * div_term) # 计算PE(pos, 2i) 计算偶数位置的 sin 编码pe[:, 1::2] = torch.cos(position * div_term) # 计算PE(pos, 2i+1) 计算奇数位置的 cos 编码pe = pe.unsqueeze(0) # 为了将其与输入张量相加,增加 batch 维度,形状变为 [1, max_len, d_model]# 如果一个参数不参与梯度下降,但又希望保存model的时候将其保存下来# 这个时候就可以用register_bufferself.register_buffer("pe", pe)def forward(self, x):"""x 为embedding后的inputs,例如(1,7, 128),batch size为1,7个单词,单词维度为128"""# 将位置编码与输入相加x = x + self.pe[:, :x.size(1)].requires_grad_(False) # 取出与输入序列长度相同的部分位置编码。如果输入序列的长度小于 max_len,只取前 x.size(1) 个位置的编码;之后禁止对位置编码进行梯度计算,因为位置编码是固定的,不需要更新。return self.dropout(x)
编码层
# 编码层
class EncoderLayer(nn.Module):def __init__(self, d_model, n_heads, d_ff, dropout=0.1):super(EncoderLayer, self).__init__()# 编码器层包含自注意力机制和前馈神经网络self.self_attn = MultiHeadAttention(d_model, n_heads)self.feedforward = Feedforward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, mask):# 自注意力机制attn_output = self.self_attn(x, x, x, mask)x = x + self.dropout(attn_output)x = self.norm1(x)# 前馈神经网络ff_output = self.feedforward(x)x = x + self.dropout(ff_output)x = self.norm2(x)return x
解码层
# 解码层
class DecoderLayer(nn.Module):def __init__(self, d_model, n_heads, d_ff, dropout=0.1):super(DecoderLayer, self).__init__()# 解码器层包含自注意力机制、编码器-解码器注意力机制和前馈神经网络self.self_attn = MultiHeadAttention(d_model, n_heads)self.enc_attn = MultiHeadAttention(d_model, n_heads)self.feedforward = Feedforward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, enc_output, self_mask, context_mask):# 自注意力机制attn_output = self.self_attn(x, x, x, self_mask)x = x + self.dropout(attn_output)x = self.norm1(x)# 编码器-解码器注意力机制attn_output = self.enc_attn(x, enc_output, enc_output, context_mask)x = x + self.dropout(attn_output)x = self.norm2(x)# 前馈神经网络ff_output = self.feedforward(x)x = x + self.dropout(ff_output)x = self.norm3(x)return x
Transformer模型构建
# Transformer模型构建
class Transformer(nn.Module):def __init__(self, vocab_size, d_model, n_heads, n_encoder_layers, n_decoder_layers, d_ff, dropout=0.1):super(Transformer, self).__init__()# Transformer 模型包含词嵌入、位置编码、编码器和解码器self.embedding = nn.Embedding(vocab_size, d_model)self.positional_encoding = PositionalEncoding(d_model, dropout)self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_encoder_layers)])self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_decoder_layers)])self.fc_out = nn.Linear(d_model, vocab_size)self.dropout = nn.Dropout(dropout)def forward(self, src, trg, src_mask, trg_mask):# 词嵌入和位置编码src = self.embedding(src)src = self.positional_encoding(src)trg = self.embedding(trg)trg = self.positional_encoding(trg)# 编码器for layer in self.encoder_layers:src = layer(src, src_mask)# 解码器for layer in self.decoder_layers:trg = layer(trg, src, trg_mask, src_mask)# 输出层output = self.fc_out(trg)return output
使用示例
# 使用示例
vocab_size = 10000 # 假设词汇表大小为10000
d_model = 512
n_heads = 8
n_encoder_layers = 6
n_decoder_layers = 6
d_ff = 2048
dropout = 0.1transformer_model = Transformer(vocab_size, d_model, n_heads, n_encoder_layers, n_decoder_layers, d_ff, dropout)# 定义输入,这里的输入是假设的,需要根据实际情况修改
src = torch.randint(0, vocab_size, (32, 10)) # 源语言句子
trg = torch.randint(0, vocab_size, (32, 20)) # 目标语言句子
src_mask = (src != 0).unsqueeze(1).unsqueeze(2) # 掩码,用于屏蔽填充的位置
trg_mask = (trg != 0).unsqueeze(1).unsqueeze(2) # 掩码,用于屏蔽填充的位置# 模型前向传播
output = transformer_model(src, trg, src_mask, trg_mask)
print(output.shape)
torch.Size([32, 20, 10000])
相关文章:
深度学习每周学习总结N9:transformer复现
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制 目录 多头注意力机制前馈传播位置编码编码层解码层Transformer模型构建使用示例 本文为TR3学习打卡,为了保证记录顺序我这里写…...

数据结构与算法(3)栈和队列
1.前言 哈喽大家好啊,今天博主继续为大家带来数据结构与算法的学习笔记,今天是关于栈和队列,未来博主会将上一章《顺序表与链表》以及本章《栈与队列》做专门的习题应用专题讲解,都会很有内容含量 ,欢迎大家多多支持&…...

11、Django Admin启用对计算字段的过滤
重新定义admin.py中的Hero管理模型如下: admin.register(Hero) class HeroAdmin(admin.ModelAdmin):list_display ("name", "is_immortal", "category", "origin", "is_very_benevolent")list_filter ("…...
问题)
xxl-job升级到springboot3.0 导致页面打不开报错)问题
原因:springboot3.0 因为移除了jsp 导致xxl-job不能访问,解决方法如下 1、修改PermissionInterceptor拦截器 package com.xxl.job.admin.controller.interceptor;import com.xxl.job.admin.controller.annotation.PermissionLimit; import com.xxl.job.…...

栈和队列.
目录 1. 栈(Stack) 2. 栈的模拟实现 3. 栈的应用场景 4. 队列(Queue) 5. 队列的模拟实现 6. 循环队列 7. 双端队列(Deque) 8. 面试题 1. 栈(Stack) 栈:一种特殊…...

Parallel.ForEach - 并行处理
Parallel.ForEach 是 C# 中 System.Threading.Tasks.Parallel 类提供的一个方法,用于并行地迭代集合中的每一个元素。Parallel.ForEach 方法允许多个线程同时处理集合中的元素,从而提高程序的执行效率,特别是在处理大量数据或执行耗时任务时。…...

【MySQL】初识MySQL—MySQL是啥,以及如何简单操作???
前言: 🌟🌟本期讲解关于MySQL的简单使用和注意事项,希望能帮到屏幕前的你。 🌈上期博客在这里:http://t.csdnimg.cn/wwaqe 🌈感兴趣的小伙伴看一看小编主页:GGBondlctrl-CSDN博客 目…...
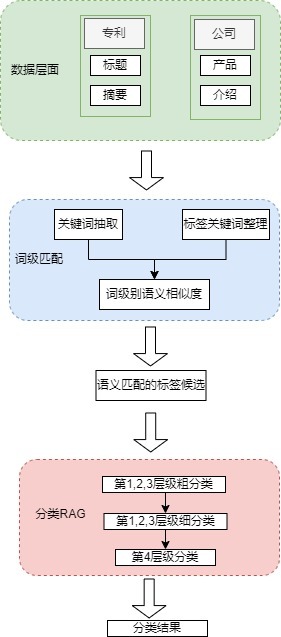
LLM应用实战: 产业治理多标签分类
数据介绍 标签体系 产业治理方面的标签体系共计200个,每个标签共有4个层级,且第3、4层级有标签含义的概括信息。 原始数据 企业官网介绍数据,包括基本介绍、主要产品等 企业专利数据,包括专利名称和专利摘要信息,且专…...

下载Mongodb 4.2.25 版本教程
1、MongoDB 安装包的下载链接 Download MongoDB Community Server | MongoDB 进入如下截图: 2、查找历史版本 往下拉,点击“...”,找到”Archived releases”,点击进入 、 3、下载Mongodb 4.2.25 版本 找到如下图4.2.25版本下载链接,点击就可…...

docker拉取redis5.0.5并建立redis集群
1.配置文件 mkdir -p redis-cluster/7001/ mkdir -p redis-cluster/7002/ mkdir -p redis-cluster/7003/ mkdir -p redis-cluster/7004/ mkdir -p redis-cluster/7005/ mkdir -p redis-cluster/7006/cd redis-clustervim 7001/redis.confbind 0.0.0.0port 7001cluster-enabled…...

React16新手教程记录
文章目录 前言一些前端面试题1. 搭建项目1. 1 cdn1. 2 脚手架 2. 基础用法2.1 表达式和js语句区别:2.2 jsx2.3 循环map2.4 函数式组件2.5 类式组件2.6 类组件点击事件2.6.1 事件回调函数this指向2.6.2 this解决方案2.6.2.1 通过bind2.6.2.2 箭头函数(推荐…...

怎么摆脱非自然链接?
什么是非自然链接? 非自然链接是人为创建的链接,用于操纵网站在搜索引擎中的排名。非自然链接违反了Google 的准则,网站可能会因此受到惩罚。 它们不是由网站所有者编辑放置或担保的。示例包括带有过度优化锚文本的链接、通过 PR 的广告、嵌…...

【2024数模国赛赛题思路公开】国赛B题第二套思路丨附可运行代码丨无偿自提
2024年数模国赛B题解题思路 B 题 生产过程中的决策问题 一、问题1解析 问题1的任务是为企业设计一个合理的抽样检测方案,基于少量样本推断整批零配件的次品率,帮助企业决定是否接收供应商提供的这批零配件。具体来说,企业需要依据两个不同…...

P1166 打保龄球
共可以投 1 局 一局10轮 在一局中,一共有十个柱,会出现很多种情况。 第1次把10个 打倒全部 >> 分数10后2次得分 --若是第10轮则还需另加两次滚球; 没全部打倒 >> 第2次把剩下的 打倒 >&g…...

[数据集][目标检测]西红柿成熟度检测数据集VOC+YOLO格式3241张5类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):3241 标注数量(xml文件个数):3241 标注数量(txt文件个数):3241 标注…...
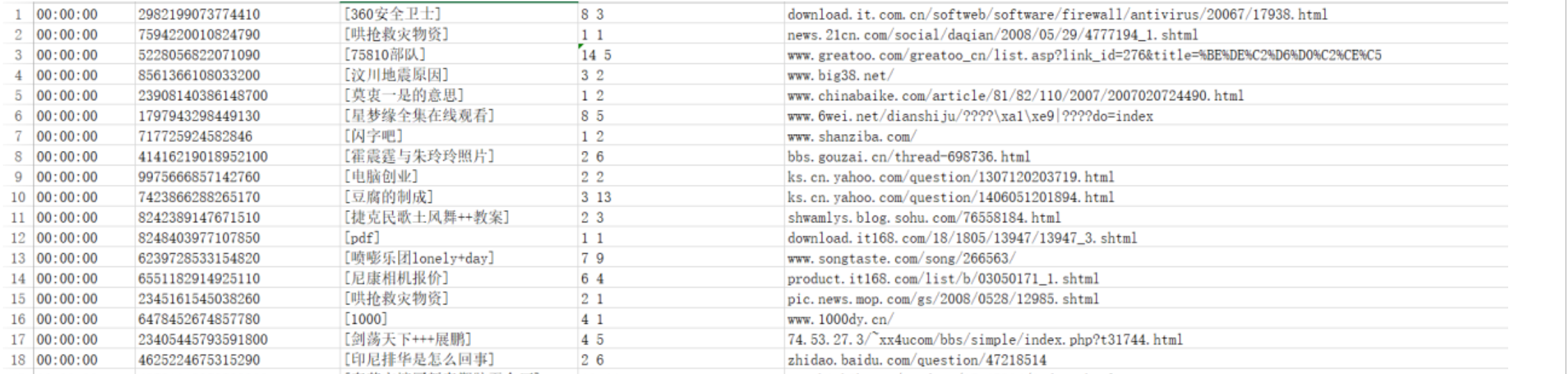
数仓工具—Hive语法之URL 函数
hive—语法—URL 函数 业务需求中,我们经常需要对用户的访问、用户的来源进行分析,用于支持运营和决策。例如我们经常对用户访问的页面进行统计分析,分析热门受访页面的Top10,观察大部分用户最喜欢的访问最多的页面等: 又或者我们需要分析不同搜索平台的用户来源分析,统…...

c#如何实现触发另外一个文本框的回车事件
一.需求 我需要实现listview中的一行双击后,将其中的一个值传给一个文本框,传完后,给文本框一个回车指令。 我的方法:后面加上 \rthis.txt_ID.Text this.listView1.SelectedItems[0].Text"\r" 结果无效。 二.问通义…...

Vue 中 nextTick 的最主要作用是什么,为什么要有这个 API
在 Vue.js 中,nextTick 是一个用于在 DOM 更新后执行代码的 API。它的主要作用是确保在某个操作完成后,DOM 已经更新且可以被访问或操作。这个 API 在处理需要等待 DOM 更新完成的逻辑时非常有用。 nextTick 的最主要作用 确保 DOM 更新完成: Vue 的响应…...

python科学计算:NumPy 数组的运算
1 数组的数学运算 NumPy 提供了一系列用于数组运算的函数和操作符,这些运算可以作用于数组的每个元素上。常见的数学运算包括加、减、乘、除等。 1.1 元素级运算 NumPy 支持对数组的每个元素进行逐元素运算。这些操作可以通过标准的数学符号或 NumPy 函数来完成。…...

SAP B1 基础实操 - 用户定义字段 (UDF)
目录 一、功能介绍 1. 使用场景 2. 操作逻辑 3. 常用定义部分 3.1 主数据 3.2 营销单据 4. 字段设置表单 4.1 字段基础信息 4.2 不同类详细设置 4.3 默认值/必填 二、案例 1 要求 2 操作步骤 一、功能介绍 1. 使用场景 在实施过程中,经常会碰见用户需…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

从分立逻辑到单片机:基于ATmega8的MIDI通道分析仪设计与实现
1. 项目概述:从分立逻辑到单片机的MIDI通道分析仪进化史二十年前,当我在《Elektor》杂志上发表第一版MIDI通道分析仪时,整个数字音乐世界还处于一个相当“硬核”的阶段。那个版本的设计,用今天的话来说,简直就是一场“…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...

《我看见的世界:李飞飞自传》第1-6章阅读笔记:从移民少女到AI教母的“看见“之旅
前言 当我们谈论人工智能时,我们谈论的是算法、数据、算力,是那些冰冷的代码和复杂的模型。但在《我看见的世界:李飞飞自传》中,李飞飞用她独特的视角告诉我们:AI的本质,是人类对"看见"世界的渴望…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...

举一个具体例子说明为什么索引不是越多越好,举具体字段
文章目录1. 核心舞台:笔记表 (t_note) 结构设计🚨 错误的操作:2. 结合具体字段,拆解三大翻车现场现场一:给 view_count(浏览量)加索引 —— 导致写放大,拖垮数据库现场二:…...

基于Arduino与nRF24L01+的无线传感器平台设计与部署指南
1. 项目概述与设计思路如果你和我一样,喜欢在阳台或者小院子里种点蔬菜瓜果,那你肯定也遇到过这样的烦恼:出门几天,心里总惦记着家里的番茄苗是不是缺水了,小温室里的温度会不会太高。传统的温湿度计只能让你在现场读数…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...

基于SMD与贝壳的微型音频装置:从电路设计到嵌入式开发的完整实践
1. 项目概述:一个藏在贝壳里的声音世界你小时候有没有捡起一个海螺壳,把它贴在耳边,然后听到里面传来“呜呜”的海风声?那个瞬间,仿佛整个海洋都被装进了小小的贝壳里。今天这个项目,就是把那个童年的魔法&…...