【深度学习】多层感知机的从零开始实现与简洁实现
可以说,到现在我们才真正接触到深度网络。最简单的深度网络称为多层感知机。
多层感知机由多层神经元组成,每一层与它的上一层相连,从中接收输入;同时每一层也与它的下一层相连,影响当前层的神经元。
和以前相同,先介绍它的基本内容,再从零开始实现,最后利用 Pytorch 框架简洁实现。
一、多层感知机
隐藏层
回想一下我们上一节中的 softmax 模型架构,该模型通过线性变换将输入映射为输出,然后进行 softmax 操作。
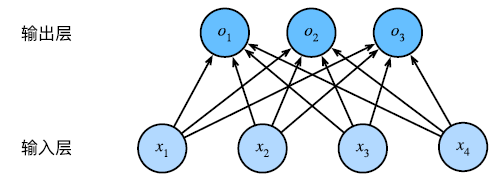
但是,这样的线性模型可能会出错。线性意味着单调,即如果权重为正的话,任何特征的增大都将引起输出的增大。
有时这样的模型是适合的,且我们还可以通过一些处理(如对数运算),使得线性模型能够起作用。
然而,现实生活中更多的是不单调的情况。例如,根据体温预测死亡率,对于高于 37 度的人来说,体温越高越危险;而对于低于 37 度的人来说,温度越高,风险越低。
再想想我们上一节实现的分类问题,一张 28 × 28 28\times28 28×28 的图片,我们将其视为了具有 784 个特征的输入,分别对应于 784 个像素点。
我们增强某个像素的强度,是否就能增大这张图片属于某个类别的概率呢?显然是不会的。
图像分类的结果与图片的像素强度具有更加复杂的关系,并且我们也难以通过一些简单的变换使得线性模型可行。
我们可以在网络中加入一个或多个隐藏层来克服线性模型的缺陷,使其能处理更复杂的函数关系。
其中一个简单的办法是将许多全连接层堆叠在一起。每一层输出的上面的层,直到生成最后的输出。这种架构通常称为多层感知机(multilayer perceptron, MLP)。
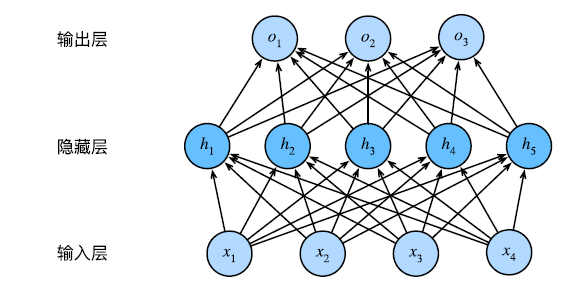
这个多层感知机有 4 个输入,3 个输出,其隐藏层包含 5 个 隐藏单元。
输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐层和输出层的计算,故该多层感知机的层数为 2。
但是,加入了一层隐藏层后,实际上输入和输出还是线性关系,因为线性关系嵌套还是线性的。
为了发挥多层架构的潜力,我们还需要一个额外的因素:在线性变换之后对每个隐藏单元应用非线性的激活函数(activation function)。激活函数的输出被称为活性值(activations)。
一般来说,有了激活函数,就不可能再将我们的多层感知机退化为线性模型。
激活函数
激活函数通过计算加权和并加上偏置来确定神经元是否应该被激活,它们将输入信号转换为输出的可微运算。常见的激活函数有:
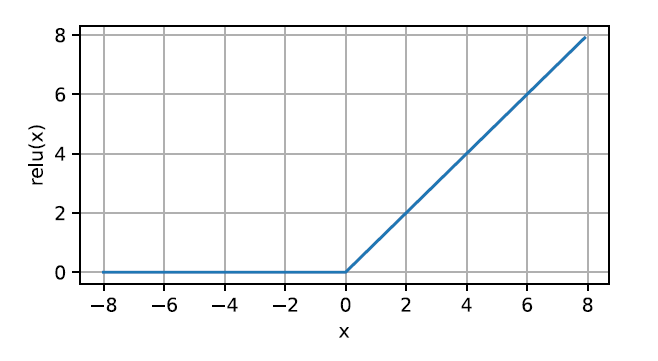
1. ReLU 函数
因为修正线性单元(Rectified linear unit, ReLU)实现简单,同时在各种预测任务中表现良好,因此它广受欢迎。
ReLU 提供了一种非常简单的非线性变换。给定元素 x x x,ReLU 函数被定义为该元素与 0 的最大值。
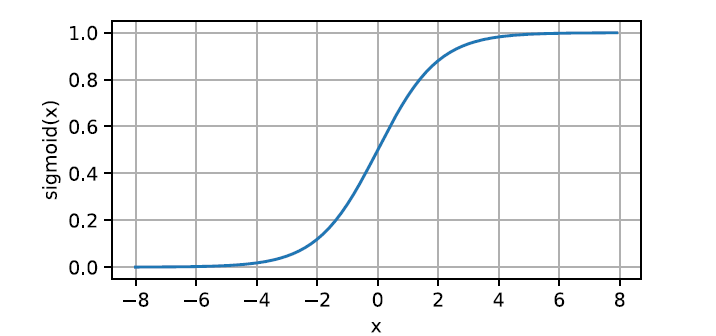
2. Sigmoid 函数
对于一个定义域在 R R R 中的输入,sigmoid 函数将输入变换为区间(0, 1)上的输出。因此,sigmoid 通常被称为挤压函数。
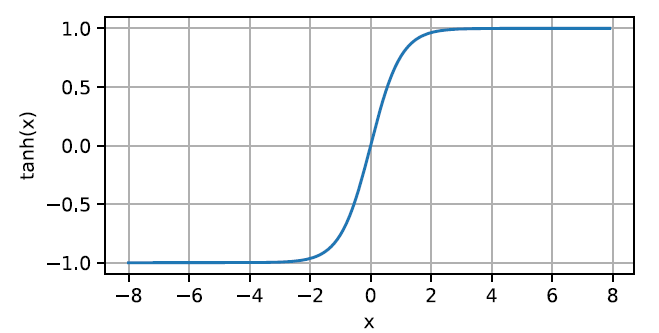
3. tanh 函数
与 sigmoid 函数类似,tanh(双曲正切)函数也能将其输入压缩转换到区间(-1, 1)上。
二、多层感知机的从零开始实现
我们继续研究上一节的分类问题,同样使用 Fashion-MNIST 数据集。
初始化模型参数
回想一下我们在 softmax 里的初始化,因为 softmax 回归只有一层,故只需要初始化一个权重向量和一个偏置即可。
多层感知机多了一层线性层,故共有 4 个模型参数,隐藏层的权重、偏置以及输出层的权重及偏置。
此外,隐藏层的宽度需要我们确定,其可视为一个超参数。一般我们取 2 的若干次幂,且介于输入大小和输出大小之间,这里我们选择 256。
隐层的参数形状为 784 × 256 784\times 256 784×256,而输出层参数的形状为 256 × 10 256\times10 256×10。
num_inputs, num_outputs, num_hiddens = 784, 10, 256W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))params = [W1, b1, W2, b2]
定义激活函数
这里我们选择 ReLU,用于处理隐层的输出,再出入输出层。
def relu(X): # 激活函数a = torch.zeros_like(X)return torch.max(X, a)
定义模型
有了激活函数后,模型的定义可直接使用矩阵乘法实现。
def net(X): # 模型X = X.reshape((-1, num_inputs)) # 展平H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法return (H@W2 + b2)
定义损失函数
这里我们通用采用交叉熵损失。值得一提的是,直接调用的 nn 模块里的交叉熵损失函数,它里面就包含了 softmax 操作。
loss = nn.CrossEntropyLoss(reduction='none') # 损失函数
训练
多层感知机的训练和 softmax 大差不差,直接用我们之前写好的那个训练函数。
num_epochs, lr = 10, 0.1optimizer = torch.optim.SGD(params, lr=lr)train(net, train_iter, test_iter, loss, num_epochs, optimizer)
得到的结果为如下。可以发现,加了激活函数后,训练损失倒小了不少,但测试集精度并未有明显提升。
第10轮的训练损失为0.3840572128295898
第10轮的训练精度为0.8638666666666667
第10轮的测试集精度为0.8394
有了前面线性回归和 softmax 回归的基础,这里实现起来是很轻松的,只是模型参数多了需要单独初始化有些麻烦。
下面我们看看简洁实现。
三、多层感知机的简洁实现
定义模型与初始化参数
调用框架的话,在定义模型调用 nn.Sequential 时,注意有 4 层,第一层展平,第二层隐层,第三层激活,第四层输出。
模型的初始化可以利用前面定义过的初始化权重函数init_weights()。
net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),nn.Linear(256, 10)) # 定义模型net = net.to(try_gpu())net.apply(init_weights) # 初始化模型参数
训练
可以直接把 softmax 回归的简洁实现代码复制过来,把定义模型和初始化参数的部分改了,就 OK 了。
训练情况如下:
第10轮的训练损失为0.3854055678049723
第10轮的训练精度为0.86335
第10轮的测试集精度为0.8503
两种实现方式的代码见资源。
相关文章:
【深度学习】多层感知机的从零开始实现与简洁实现
可以说,到现在我们才真正接触到深度网络。最简单的深度网络称为多层感知机。 多层感知机由多层神经元组成,每一层与它的上一层相连,从中接收输入;同时每一层也与它的下一层相连,影响当前层的神经元。 和以前相同&…...

4、Django Admin对自定义的计算字段进行排序
通常,Django会为模型属性字段,自动添加排序功能。当你添加计算字段时,Django不知道如何执行order_by,因此它不会在该字段上添加排序功能。 如果要在计算字段上添加排序,则必须告诉Django需要排序的内容。你可以通过在…...

rsync搭建全网备份
rsync搭建全网备份 1. 总体概述1.1 目标1.2 简易指导图1.3 涉及工具或命令1.4 环境 2. 实施2.1 配置备份服务器2.2 备份文件准备2.3 整合命令2.4 扩展功能 1. 总体概述 1.1 目标 本次搭建目标: 每天定时把服务器数据备份到备份服务器备份完成后进行校验把过期数据…...

网络安全售前入门09安全服务——安全加固服务
目录 1.服务概述 2.流程及工具 2.1服务流程 2.2服务工具 3.服务内容 4.服务方式 5.风险规避措施 6.服务输出 1.服务概述 安全加固服务是参照风险评估、等保测评、安全检查等工作的结果,基于科学的安全思维方式、长期的安全…...

【Android】GreenDao数据库的使用方式
需求 使用GreenDao数据库进行数据的存储。 介绍 GreenDao 是一个轻量级的对象关系映射(ORM)库,用于简化 Android 应用中的数据库操作。它提供了以下主要功能: 简化数据库操作:通过注解定义实体类,Green…...
)
搜索算法之线性搜索详细解读(附带Java代码解读)
1. 基本概念 线性搜索(Linear Search),也称为顺序搜索,是一种在列表中查找特定元素的算法。它从列表的第一个元素开始,逐个检查每个元素,直到找到目标元素或检查完所有元素。 2. 工作原理 线性搜索的操作…...

Quartz.Net_依赖注入
简述 有时会遇到需要在IJob实现类中依赖注入其他类或接口的情况,但Quartz的默认JobFactory并不能识别具有有参构造函数的IJob实现类,也就无法进行依赖注入 需要被依赖注入的类: public class TestClass {public TestClass(Type jobType, s…...

【系统架构设计师-2011年】综合知识-答案及详解
更多内容请见: 备考系统架构设计师-核心总结索引 文章目录 【第1题】【第2~4题】【第5~7题】【第8题】【第9题】【第10题】【第11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18~19题】【第20~21题】【第22题】【第23题】【第24题】【第25题】【第2…...

World of Warcraft [CLASSIC][80][Grandel]Sapphire Hive Drone
Sapphire Hive Drone 蓝玉虫巢雄蜂 蓝玉虫巢巨峰 索拉查盆地 实用性不强,好看是好看,模型很大,无奈栏位太少...

Unity 对接 Android 第三方广告,App 切换到后台后,再次打开时,第三方广告被销毁导致无法触发回调逻辑的问题
该问题是由发行进行游戏测试时遇到并反馈的。大致情况如下: 1. 当触发了插屏广告后,在关闭广告前将 App 切换到后台,之后再次打开 App,此时插屏广告消失,并切游戏卡死。 2. 当触发激励视频广告后,在广告展…...
,无法及时响应消费者的请求)
Kafka Broker处于高负载状态(例如消息处理量大或系统资源不足),无法及时响应消费者的请求
Caused by: org.apache.kafka.common.errors.TimeoutException: Timeout of 60000ms expired before the position for partition activity-0 could be determined。 出现这个错误的原因是Kafka消费者在尝试获取分区(activity-0)的位置信息时,超时了。在60秒内无法确…...

相关二叉树进阶面试题的讲解?看这一篇足矣
引子:我们在之前学过c语言的二叉树,但是c来做更好!本期要讲的题目如下(其实有点拖欠了,很久之前,就想写这个了,今天终于克服自己的欲望,达成了这个愿望) 1, 二叉树创建字…...

Nginx部署前端Vue项目的深度解析
目录 一、准备工作 1.1 开发环境 1.2 服务器环境 1.3 Nginx安装 二、构建Vue项目 三、上传静态文件到服务器 四、配置Nginx 五、测试并重新加载Nginx 六、访问Vue应用 七、高级配置 7.1 启用HTTPS 7.2 启用Gzip压缩 7.3 缓存控制 八、常见问题与解决方案 8.1 40…...
PHP一站式解决方案高级房产系统小程序源码
一站式解决方案,高级房产系统让房产管理更轻松 🏠【开篇:告别繁琐,迎接高效房产管理新时代】🏠 你是否还在为房产管理的繁琐流程而头疼?从房源录入、客户咨询到合同签订、售后服务,每一个环节…...

轻量级模型解读——EfficientNet系列
EfficientNet自2019年谷歌提出以来,经历了三个版本,2019EfficientNet ——> 2020EfficientNet-Lite——> 2021EfficientNetv2 文章目录 1、EfficientNet2、EfficientNetv23、EfficientNet-Lite 对于EfficientNet和EfficientNetv2的解读可见另外两篇…...
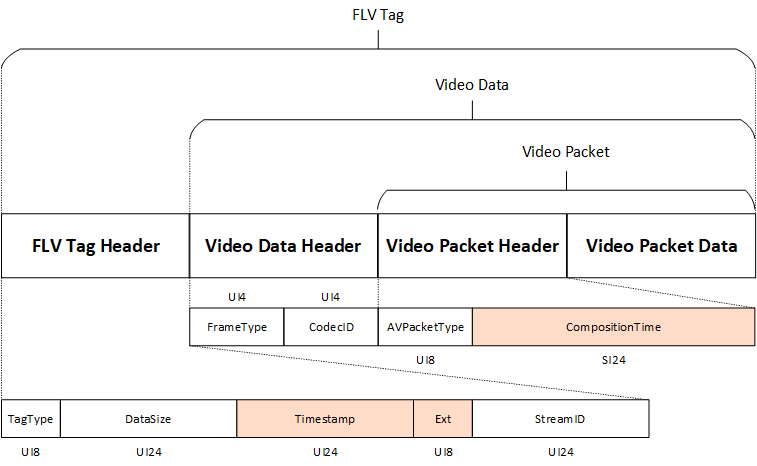
深入浅出SRS—RTMP实现
RTMP 直播是 SRS 最典型的使用场景,客户端使用 RTMP 协议向 SRS 推流,使用 RTMP 协议从 SRS 拉流,SRS 作为一个 RTMP 直播服务器实现媒体的转发。同时,RTMP 是 SRS 的中转协议,其他协议之间的互通需要先转为 RTMP&…...

睿赛德科技携手先楫共创RISC-V生态|RT-Thread EtherCAT主从站方案大放异彩
日前,在先楫HPM6E00技术日上,睿赛德科技(RT-Thread)向广大工业用户展示了多年来双方在RISC-V生态领域的合作历程和成果,同时睿赛德科技携手先楫半导体首次推出了基于HPM6800处理器的EtherCAT主站解决方案,吸…...

【Cesium实体创建】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 Cesium目录 前言一、Cesium二、点 线 实体1.点实体2.线实体 总结 前言 提示:这里可以添加本文要记录的大概内容: 例如:随着人工智能的不…...

为何一些包的Priority在apt-cache和deb文件当中的不一样
最近遇到一些问题,调查的时候发现是一些包的Priority在apt-cache和deb文件当中的不一样导致的,复现步骤如下: $ apt update $ apt download whiptail $ dpkg-deb -e whiptail_0.52.23-1b1_amd64.deb $ cat control | grep Prio Priority: op…...

CRUD的最佳实践,联动前后端,包含微信小程序,API,HTML等(三)
关说不练假把式,在上一,二篇中介绍了我心目中的CRUD的样子 基于之前的理念,我开发了一个命名为PasteTemplate的项目,这个项目呢后续会转化成项目模板,转化成项目模板后,后续需要开发新的项目就可以基于这…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...
)
蓝牙抓包不求人:从HCI日志里‘挖’出Link Key的两种实用方法(附安卓路径)
蓝牙安全逆向实战:从HCI日志中提取Link Key的深度解析在蓝牙协议安全研究领域,Link Key作为设备配对认证的核心凭证,其获取方式一直是逆向工程师关注的焦点。许多安全审计场景下,我们往往只能获得加密后的HCI通信日志,…...

D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳
D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破坏…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

贵阳婚礼西服定制攻略:面料、工艺、版型避坑指南
婚礼西装是男士婚礼造型的核心,区别于日常商务正装,婚礼西服更看重版型精致度、面料质感、上身挺拔感以及镜头适配度。在贵阳备婚的新人,大多会放弃成品西装,选择专属定制服务。但本地婚礼西服定制市场参差不齐,很多新…...
)
保姆级教程:Windows系统下Arcgis 10.2从下载、安装到汉化一次搞定(附常见License启动失败解决方案)
Windows系统下Arcgis 10.2完整安装与汉化实战指南第一次接触Arcgis的新手往往会被复杂的安装流程和神秘的License Manager搞得晕头转向。作为一款功能强大的地理信息系统软件,Arcgis在科研、城市规划、环境监测等领域有着广泛应用,但它的安装过程确实会让…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...

终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由
终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

从NLP到RAG:AI标书生成系统的技术架构与落地路径深度剖析
引言2026年2月,国家发改委等八部门联合印发《关于加快招标投标领域人工智能推广应用的实施意见》,明确到2026年底招标文件检测、智能辅助评标、围串标识别等重点场景在部分省市实现全覆盖。同一时期,《招标投标法》修订草案经国务院常务会议原…...

人工智能的伦理与安全:这3个问题,软件测试从业者必须重视
随着大语言模型、生成式AI的爆发式落地,人工智能已经从实验室走向千行百业的生产场景,深刻改变着软件开发与交付的逻辑。对于直接把控产品质量关口的软件测试从业者来说,我们的职责早已不再是单纯验证功能可用性、排查性能bug那么简单——AI系…...